第04期 · Embedding 向量化:AI 理解语言的底层密码
系列 :每日 AI 知识点
期数 :第 04 期
主题 :Embedding 向量化
难度 :⭐⭐(入门)
一句话:Embedding 是把文字转成"语义坐标"的技术,让 AI 能理解文字含义,是语义搜索和知识库的核心基础。
一、计算机为什么需要 Embedding?
计算机本质上只能处理数字,不能直接理解文字。
传统的处理方式是"词袋模型"------给每个词分配一个 ID:
arduino
"猫" → 1
"狗" → 2
"汽车" → 3
"苹果" → 4这种方式有个致命问题:数字之间的关系无法反映词语之间的语义关系。
- "猫"(1) 和 "狗"(2) 数字相差 1,但它们语义很相近(都是宠物)
- "猫"(1) 和 "汽车"(3) 数字相差 2,但它们语义完全不相关
Embedding 的出现解决了这个问题 :不是给每个词分配一个数字,而是分配一个高维向量(一组数字) ,并且这组数字能够保留语义信息------语义相近的词,向量也相近。
二、直观理解:语义地图
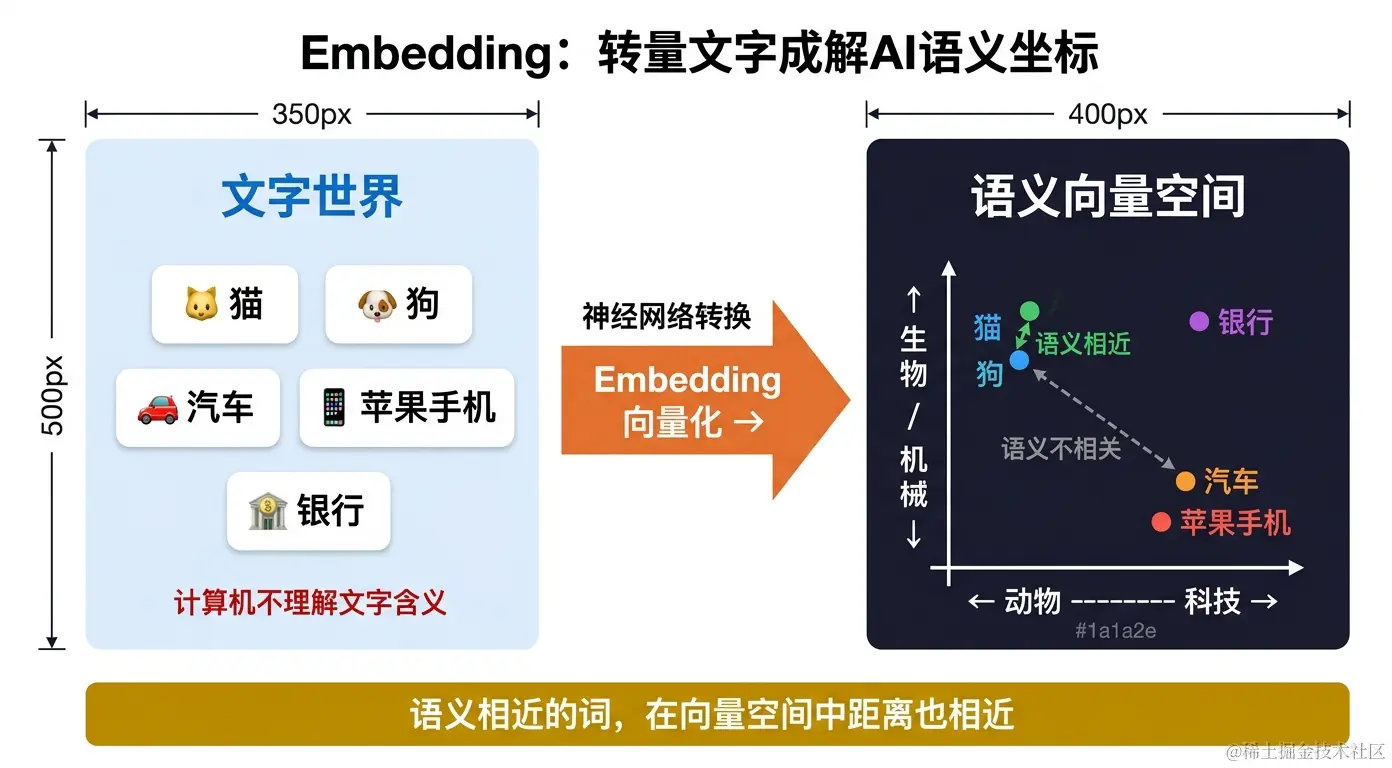
想象一张地图,每个词都有自己的"坐标":
markdown
向量空间示意(简化为2D):
生物类
↑
猫 • 狗 ← 动物区域(左上)
← 动物 --------------------------------------- 科技 →
汽车 • 苹果手机 ← 科技区域(右下)
↓
机械类关键特性:
- "猫"和"狗"的向量很接近(都是宠物动物)
- "汽车"和"苹果手机"的向量接近(都是科技产品)
- "猫"和"汽车"的向量距离很远(语义不相关)
更神奇的是,Embedding 还能捕捉词语之间的关系:
arduino
"国王" - "男人" + "女人" ≈ "女王"
"巴黎" - "法国" + "日本" ≈ "东京"这种"语义算术"是 Embedding 最令人惊叹的特性。
三、Embedding 的工作原理
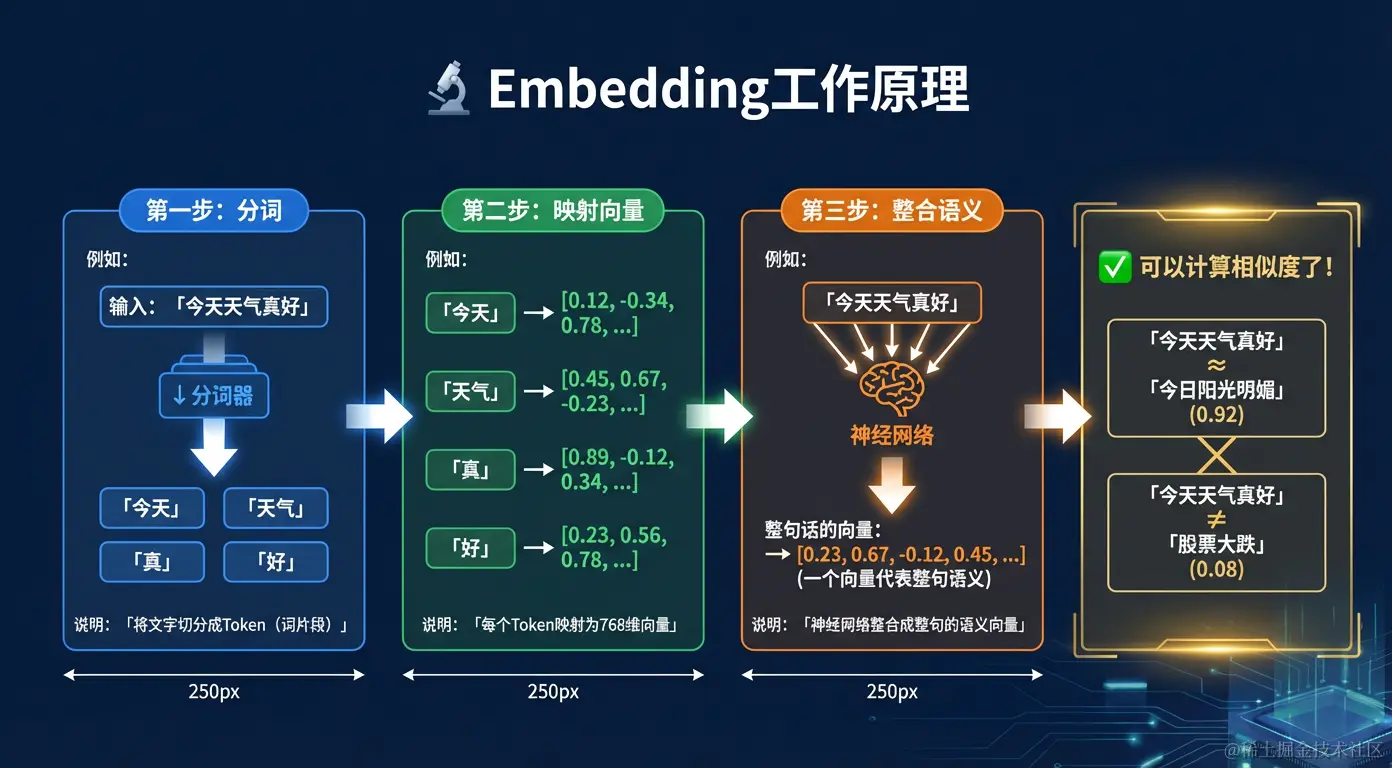
第一步:分词(Tokenization)
文字先被切分成 Token(词片段):
scss
中文:"今天天气真好"
→ ["今天", "天气", "真", "好"]
英文:"Hello World"
→ ["Hello", " World"]
代码:"print('hello')"
→ ["print", "('", "hello", "')"]注意:Token 不等于词,一个汉字可能是一个 Token,一个英文词可能被拆成多个 Token。
第二步:映射到高维向量
每个 Token 被映射成一个高维向量(通常 768 维或 1536 维):
python
# 示意(实际维度更高)
"今天" → [0.12, -0.34, 0.78, 0.05, 0.23, ...] # 768个数字
"天气" → [0.45, 0.67, -0.23, 0.89, 0.12, ...]
"真" → [0.89, -0.12, 0.34, 0.67, 0.45, ...]
"好" → [0.23, 0.56, 0.78, -0.34, 0.90, ...]这些数字不是随机的,而是通过在海量文本上训练得到的,能够反映词语的语义特征。
第三步:整合句子语义
通过神经网络处理,把整句话的语义压缩成一个向量:
python
"今天天气真好" → [0.23, 0.67, -0.12, 0.45, ...] # 代表整句话的语义这个向量就是整句话的"语义指纹"------语义相近的句子,指纹也相近。
相似度计算:余弦相似度
有了向量,就可以计算两段文字的语义相似度:
python
from sklearn.metrics.pairwise import cosine_similarity
# 假设已获取向量
vec_a = embed("今天天气很好")
vec_b = embed("今日阳光明媚")
vec_c = embed("股票市场大跌")
# 余弦相似度(值域 0-1,越接近1越相似)
sim_ab = cosine_similarity(vec_a, vec_b) # ≈ 0.92(很相似)
sim_ac = cosine_similarity(vec_a, vec_c) # ≈ 0.08(不相似)四、Embedding 的 4 大核心应用
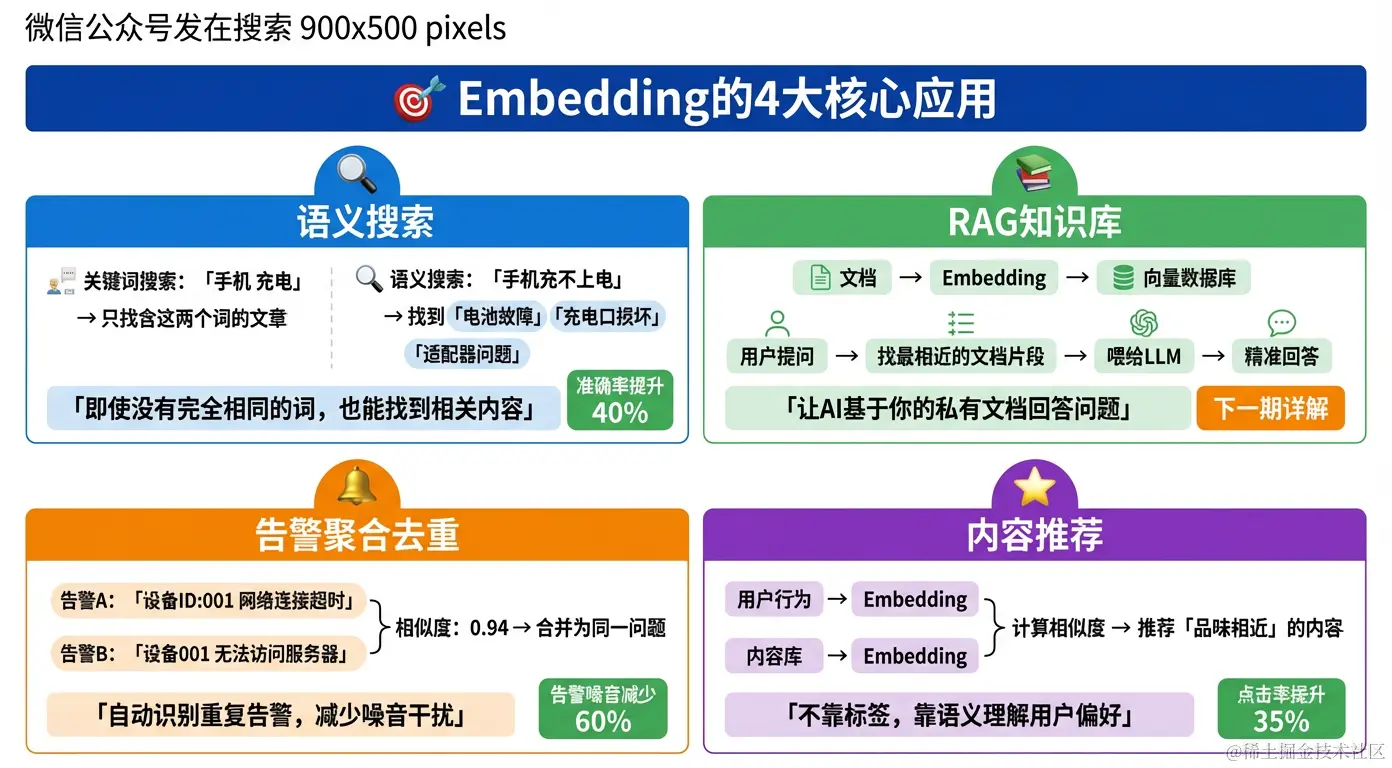
应用一:语义搜索(最重要)
传统关键词搜索的局限:
arduino
用户搜索:"手机充不上电"
关键词搜索:只返回包含"手机"+"充电"的文章
→ 可能漏掉"电池故障"、"充电口损坏"、"适配器问题"等相关文章语义搜索的优势:
arduino
用户搜索:"手机充不上电"
→ 系统计算搜索词的 Embedding
→ 与数据库中所有文章的 Embedding 计算相似度
→ 返回语义最相近的文章
结果:即使文章里没有"充不上电"这个词,
也能找到"电池容量骤降"、"充电接口氧化"等相关文章真实案例:某客服系统升级为语义搜索后,用户问题的自动匹配率从 42% 提升到 78%,人工干预量减少 45%。
应用二:RAG 知识库(下期详解)
Embedding 是 RAG(检索增强生成)的核心基础:
markdown
1. 把企业文档全部转成 Embedding 存入向量数据库
2. 用户提问 → 问题也转成 Embedding
3. 找到语义最相近的文档片段(Top-K 检索)
4. 把这些片段喂给 LLM 回答问题
5. AI 基于真实文档回答,而不是凭空想象这就是 Knot、ChatGPT 企业版、各类 AI 助手的知识库工作原理。
应用三:告警聚合去重
实际场景:刷掌终端出现网络问题,可能触发多条告警:
arduino
告警A:"设备ID:SN001 网络连接超时,错误码:TIMEOUT_ERR"
告警B:"SN001 无法访问支付服务器,请检查网络"
告警C:"设备SN001 心跳包丢失"
传统方式:3条独立告警,运维人员需要逐条处理Embedding 方案:
python
# 计算三条告警的相似度
sim(A, B) = 0.94 # 高度相似
sim(A, C) = 0.87 # 较高相似
→ 自动聚合为同一问题:"SN001 网络异常"
→ 运维人员只需处理1个聚合告警,而不是3个实测效果:某运维团队使用告警聚合后,每日处理的告警数量从 300+ 条降低到 80 条,告警处理时间减少 60%。
应用四:内容推荐
原理:
arduino
用户历史行为 → 行为 Embedding(用户偏好向量)
内容库 → 内容 Embedding(内容特征向量)
计算相似度 → 推荐"语义相近"的内容为什么比传统标签推荐好:
- 传统标签:商品打了"运动"标签,才会推荐给运动爱好者
- Embedding 推荐:即使没有标签,也能通过语义理解用户偏好
五、主流 Embedding 模型对比
| 模型 | 维度 | 最大 Token | 特点 | 适用场景 |
|---|---|---|---|---|
| text-embedding-3-small | 1536 | 8191 | 轻量快速,性价比高 | 日常语义搜索 |
| text-embedding-3-large | 3072 | 8191 | 精度最高 | 高精度检索 |
| BGE-M3 | 1024 | 8192 | 中文优化,多语言 | 中文文档检索 |
| nomic-embed-text | 768 | 8192 | 开源免费 | 本地部署 |
| jina-embeddings-v3 | 1024 | 8192 | 多语言,长文本 | 跨语言检索 |
选型建议:
- 中文场景:优先选 BGE-M3 或 text-embedding-3-large
- 成本敏感:text-embedding-3-small(比 large 便宜 5 倍,精度差距 5%)
- 私有化部署:BGE-M3 或 nomic-embed-text(开源可本地运行)
六、Embedding 的局限性
了解局限性和了解能力同样重要:
局限一:跨语言对齐问题
同一个意思的中英文,在不同模型中可能向量差距较大:
css
"苹果手机" → 向量A
"iPhone" → 向量B
sim(A, B) ≈ 0.65(不够高)解决方案:使用专门的多语言 Embedding 模型(如 BGE-M3)
局限二:超长文本处理
Embedding 模型有最大 Token 限制(通常 8192 Token),超出部分会被截断。
解决方案:长文档需要先切分成小块,分别 Embedding,再检索
局限三:实时性
Embedding 是在特定时间点生成的,如果原始文档更新了,需要重新生成 Embedding。
解决方案:建立文档更新触发重新 Embedding 的机制
七、一句话总结
Embedding = 把文字转成"语义坐标",让 AI 能理解文字的含义而不只是字符匹配。它是语义搜索、RAG 知识库、告警聚合、内容推荐等 AI 应用的核心基础技术。
延伸阅读
- 论文 :Word2Vec: Efficient Estimation of Word Representations --- Embedding 技术的奠基之作
- 工具 :Hugging Face MTEB Leaderboard --- Embedding 模型排行榜
- 实践:OpenAI Embeddings API --- 最易用的商业 Embedding 服务
下一期预告:第05期 · RAG 检索增强生成 --- 有了 Embedding,如何构建一个能基于你的私有文档回答问题的 AI 知识库?RAG 是当前企业 AI 落地最重要的技术路线。