文章目录
-
- [到底什么是 RAG?](#到底什么是 RAG?)
- [宏观视角:RAG 的三大核心步骤](#宏观视角:RAG 的三大核心步骤)
-
- [步骤 1:数据准备与入库 (Indexing) ------ 把书按段落拆好](#步骤 1:数据准备与入库 (Indexing) —— 把书按段落拆好)
- [步骤 2:信息检索 (Retrieval) ------ 带着问题翻书](#步骤 2:信息检索 (Retrieval) —— 带着问题翻书)
- [步骤 3:增强生成 (Generation) ------ 结合资料写答案](#步骤 3:增强生成 (Generation) —— 结合资料写答案)
- [RAG vs 模型微调 (Fine-tuning):该怎么选?](#RAG vs 模型微调 (Fine-tuning):该怎么选?)
- 总结与下期预告
最近几年,ChatGPT、通义千问等大语言模型(LLM)的发展可谓是一日千里。我们惊叹于它们强大的自然语言理解和生成能力,但在实际开发和使用中,你一定会发现大模型有两个让人头疼的"致命缺陷":
- "一本正经地胡说八道":遇到知识盲区时,模型往往不会坦白说"我不知道",而是会凭空捏造出一个看似合理的假答案,也就是常说的**"幻觉"(Hallucination)**。
- 知识停留在过去,且不懂你的私有数据:模型的知识储备停留在了它训练完成的那一天。它不知道今天的新闻,更不可能知道你公司内部的 API 文档、个人的学习笔记或是某个未开源项目的代码。
为了解决这两个痛点,**RAG(Retrieval-Augmented Generation,检索增强生成)**技术应运而生。今天这篇文章,我们就来白话解析一下,到底什么是 RAG?
到底什么是 RAG?
如果用一句话来概括:RAG 就是给大模型装上了一个随时可以查阅的"外挂大脑"或"参考书"。
我们可以把大模型回答问题比作一场"考试":
- 没有 RAG(闭卷考试):模型只能单纯依靠在预训练阶段死记硬背下来的知识(肚子里的墨水)来硬答。遇到没背过或者忘了的题,就只能瞎蒙。
- 有了 RAG(开卷考试):我们给大模型发了一本"参考书"(你的本地知识库)。当被问到问题时,它不再急着直接作答,而是先去书里查阅相关的资料,然后再结合查到的资料进行作答。
这样一来,回答的准确率和时效性自然大幅提升。RAG = Retrieval(检索找资料) + Augmented(增强上下文) + Generation(大模型生成回答)。
宏观视角:RAG 的三大核心步骤
一个标准的 RAG 流程通常包含三个核心步骤:数据入库 、信息检索 、增强生成 。
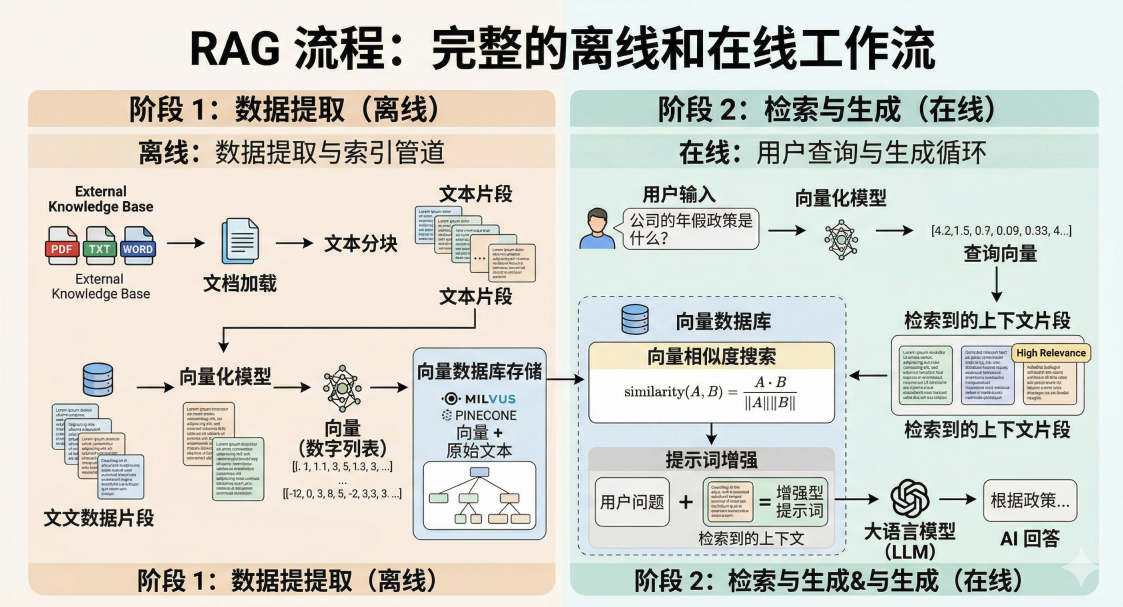
为了让大家更有实感,下面我会结合 Java 生态中非常火的 Spring AI 框架,用极简的伪代码来展示这三步是怎么跑起来的。
步骤 1:数据准备与入库 (Indexing) ------ 把书按段落拆好
就像我们平时写后端做 CRUD 操作,需要把业务数据存进 MySQL 一样,RAG 也需要先把你的私有数据"存起来"。
但问题是,大模型是有上下文长度限制的,它无法一次性吃下几十万字的长文档。所以我们需要把文档**"切碎"(Chunking),然后把文本转化成计算机能懂的 向量(Embedding),最后存进专门的向量数据库(Vector Store)**中。
用 Spring AI 表达这个过程:
java
// 1. 读取你的私有文档(比如一份内部业务手册)
List<Document> documents = new TextReader("classpath:/私有知识.txt").get();
// 2. 将长文档切分成小块 (Chunking 策略)
TextSplitter splitter = new TokenTextSplitter();
List<Document> splitDocs = splitter.apply(documents);
// 3. 变成向量并存入向量数据库 (Spring AI 底层会自动调用 Embedding 模型进行转换)
vectorStore.add(splitDocs);步骤 2:信息检索 (Retrieval) ------ 带着问题翻书
当用户提出一个问题时,系统会把这个"问题"也转换成向量。然后去刚才建好的向量数据库里"大海捞针",计算向量之间的相似度,找出发音、语义最匹配的前几个段落。这就是常说的 Top-K 召回。
用 Spring AI 表达这个过程:
java
String userQuestion = "请问系统最近一次更新修复了哪些支付 Bug?";
// 拿着问题去数据库里搜,返回最相关的 Top-K 个文档块(也就是参考资料)
List<Document> topKDocs = vectorStore.similaritySearch(userQuestion);步骤 3:增强生成 (Generation) ------ 结合资料写答案
这是最神奇,也是最终"出成果"的一步!我们把刚刚检索出来的"参考资料"和用户原本的"问题"像拼积木一样拼接在一起,做成一个完整的 Prompt(提示词),然后一股脑塞给大模型,让它结合资料给出答案。
用 Spring AI 表达这个过程:
java
// 1. 把搜出来的参考资料拼成一段长文本
String context = topKDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n"));
// 2. 组装最终的提示词 (Prompt 模板)
String finalPrompt = "你是一个智能助手,请基于以下【参考资料】回答用户的问题。如果资料中没有相关信息,请回答'我不知道'。\n"
+ "【参考资料】:" + context + "\n"
+ "【用户问题】:" + userQuestion;
// 3. 调用大模型 (配置好对应的 ChatClient 即可调用通义千问、ChatGPT 等)
String answer = chatModel.call(finalPrompt);
System.out.println(answer); // 输出基于私有知识生成的精准回答!RAG vs 模型微调 (Fine-tuning):该怎么选?
很多人刚接触大模型时会有个疑问:我想让模型懂我的业务,为什么不直接去"微调"它呢?
- 模型微调 (Fine-tuning):就像送大模型去重新"脱产进修"。成本极高,需要算力卡,而且一旦你的业务数据更新了,你还得重新训练它,非常不灵活。
- RAG (检索增强生成):就像给大模型插上了一个"随时更新的 U 盘"。模型本身不需要改变,你只需要维护好向量数据库里的知识就行了。即插即用,成本极低,是目前企业内部落地 AI 知识库最主流、性价比最高的方案。
总结与下期预告
今天我们理清了 RAG 的整体骨架:通过切分和向量化把私有知识存起来,通过相似度检索找到相关资料,最后通过拼装提示词让大模型生成准确的回答。这套机制以极低的成本解决了大模型"幻觉"和"缺乏私有知识"的难题。
但这仅仅是一张"鸟瞰图"。在实际的代码开发中,你会遇到很多有趣的挑战:
- 文本到底该怎么切分?按标点符号切,还是按语义切?(Chunking 策略)
- 如果数据库检索出来的 Top-K 资料根本不准,大模型跟着胡说八道怎么办?