目录
一句话概括
论文:CLOSING THE LOOP: A CONTROL-THEORETIC FRAMEWORK FOR PROVABLY STABLE TIME SERIES FORECASTING WITH LLMS
作者:Xingyu Zhang, Hanyun Du, Zeen Song, Jianqi Zhang
单位:Institute of Software, Chinese Academy of Sciences Beijing, China
代码:请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
更多资讯

一段话总结
本文聚焦大语言模型(LLM)时间序列预测 中开环自回归推理 引发的误差累积(暴露偏差)与长视界轨迹漂移问题,从控制理论 视角提出F-LLM(Feedback-driven LLM)闭环预测框架 ;该框架通过可学习残差估计器(系统观测器)推断隐式误差、反馈控制器实时校正轨迹,配合局部利普希茨约束 实现预测误差一致有界 的理论保障;实验在7个真实多变量时序数据集上验证,F-LLM长时序预测MSE较最优基线降低5.6% ,保留LLM零样本泛化能力,兼容GPT-2、OPT、LLaMA等主干且仅增加不足5% 推理开销。
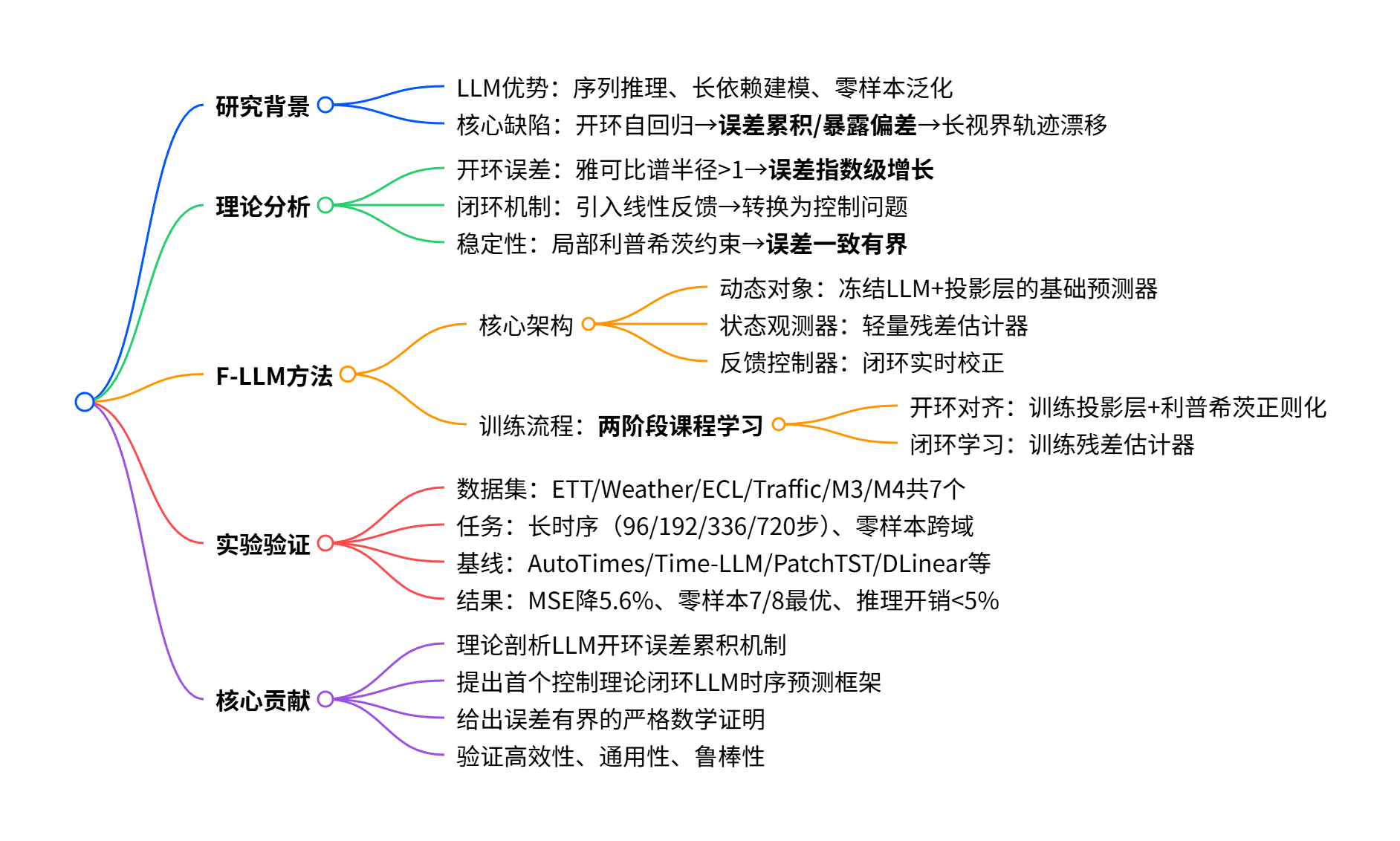
思维导图
详细总结
一、研究背景与核心问题
- 应用价值:时间序列预测(TSF)是能源、气象、交通等领域数据驱动决策的核心组件,LLM凭借序列推理能力成为时序预测新范式。
- 核心缺陷 :标准LLM采用开环自回归推理 ,训练阶段使用教师强制 (依赖真实历史值),推理阶段递归使用自身生成值,引发暴露偏差 ;早期微小误差逐级放大,导致长视界预测轨迹指数级漂移。
二、理论分析
- 开环误差动态
通过一阶泰勒展开推导误差演化公式:Δxₜ≈J_g(xₜ₋₁)Δxₜ₋₁+ϵₜ;若雅可比矩阵谱半径ρ(J_g)>1 ,预测误差随视界H指数级增长(O(ρ(J_g)^H)),最终轨迹发散。 - 闭环稳定机制
引入线性反馈校正项,将误差动态转换为:Δxₜ≈(J_g−L)Δxₜ₋₁+ϵₜ,通过学习反馈增益L使闭环算子满足收缩条件。 - 稳定性保证
满足局部利普希茨约束 时,累积误差一致有界,上界为γ/(1−q),从数学上杜绝误差无限发散。
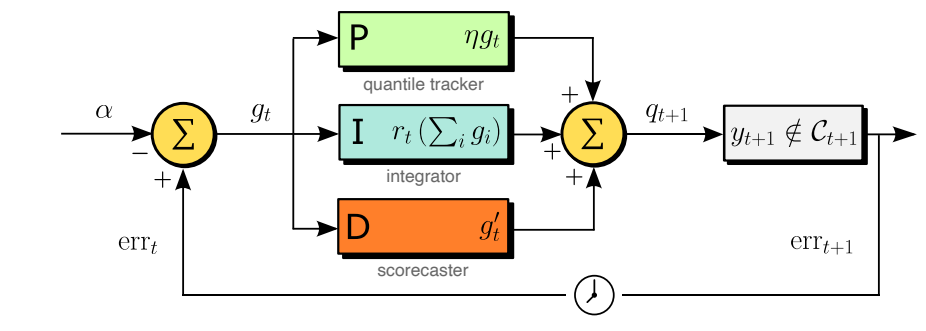
三、F-LLM方法设计
F-LLM是闭环控制型LLM时序预测框架,核心由三大模块与两阶段训练构成:
- 核心模块
- 动态对象(Plant):冻结LLM主干+可学习嵌入/反嵌入层,负责生成原始时序预测值。
- 状态观测器(Residual Estimator):轻量神经网络,基于历史残差推断当前误差校正量。
- 反馈控制器:将校正量注入预测值,闭环修正后作为下一步输入,阻断误差传播。
- 两阶段课程学习
- 阶段1(开环对齐) :冻结残差估计器,仅训练投影层,施加局部利普希茨正则化,约束模型输入敏感性。
- 阶段2(闭环反馈学习):冻结投影层,训练残差估计器,学习校正基础预测器的系统偏差。
四、实验结果
实验基于7个真实多变量时序数据集,覆盖长时序预测、零样本跨域预测两大任务,关键结果如下:
- 长时序预测性能
在ETTh1/ETTh2/ETTm1/ETTm2/ECL/Weather/Traffic数据集上,F-LLM的MSE/MAE均优于所有基线 ,长视界场景较最强基线MSE降低5.6%。 - 零样本泛化能力
M3↔M4跨域迁移的8个设置中7个SMAPE最低,完整保留LLM的零样本泛化特性。 - 通用性与效率
- 兼容GPT-2、OPT-6.7B、LLaMA-7B等主流LLM主干,性能一致提升;
- 推理时间较冻结LLM仅增加**<5%,LLaMA-7B版本可训练参数仅7.01M**,轻量高效;
- 5次独立实验标准差极小,鲁棒性优异。
五、核心贡献
- 首次从控制理论视角,严格剖析 LLM自回归时序预测的开环误差累积机制。
- 提出F-LLM闭环框架 ,首次将动态误差校正用于LLM时序预测,无需重训练主干模型。
- 给出数学证明 ,保证闭环机制下预测误差一致有界,提供理论安全保障。
- 实验验证F-LLM在长时序、零样本、多LLM兼容、计算效率上的全面优势。
关键问题与答案
问题1(理论侧重):LLM用于时间序列自回归预测的核心理论缺陷是什么?如何用数学解释?
答案 :核心缺陷是开环自回归推理导致的误差累积(暴露偏差) 。数学上,预测误差满足Δxₜ≈J_g(xₜ₋₁)Δxₜ₋₁+ϵₜ,若LLM雅可比矩阵的谱半径ρ(J_g)>1 ,误差会随预测视界H指数级增长,最终引发预测轨迹不可逆漂移。
问题2(方法侧重):F-LLM如何实现LLM时序预测的误差抑制?核心流程是什么?
答案 :F-LLM将预测重构为闭环控制系统 :①用残差估计器 (观测器)推断不可见的预测误差;②用反馈控制器 实时校正预测值,阻断误差传播;③通过两阶段课程学习先稳定基础预测器,再学习误差校正,配合局部利普希茨约束保证误差有界。
问题3(应用侧重):F-LLM相比现有LLM时序预测方法,核心实验优势有哪些?
答案 :①精度更高 :长时序预测MSE较最优基线降低5.6% ;②零样本保留 :跨域迁移8个设置中7个SMAPE最低;③通用性强 :兼容GPT-2、OPT、LLaMA等所有解码器型LLM;④高效轻量 :推理开销不足5%,可训练参数仅7.01M;⑤鲁棒稳定:多次实验标准差极小,性能无波动。
要不要我帮你把思维导图转换成可直接编辑的Markdown层级文本,方便你复制到笔记软件?