引言
plain
# ===================== 内部深度思考 =====================
#
# 【输入 / 输出梳理】
# INPUT: 上传到 Azure Blob Storage 的 PDF / JPG / PNG 文档
# 用户在 Chainlit UI 输入的自然语言问题
# OUTPUT: 带实时流式输出的回答(含 [1][2] 内联引用)
# + 侧边栏展示的相关页面截图
#
# 【核心难点定位】
#
# 难点1: ColPali 的多向量嵌入天然具备极高维度
# 一页文档产出 ~1000+ 个 patch token embedding (128 dim each)
# 直接存入向量数据库:内存爆炸、检索极慢
# → 作者的 Engineering Trick:
# "三层嵌套向量策略" -- 按行/按列均值池化 + 层次池化
# 外层用二值量化的均值池化向量做高速 Prefetch
# 内层用 on-disk 的层次池化向量做精准 Rerank
# → 参考了 Qdrant 官方 PDF-at-scale 方案
#
# 难点2: 单次查询召回不稳定(语义漂移)
# → 作者的 Trick: LLM Query Expansion(生成 5 个变体)
# + asyncio.gather 并行查 Qdrant
# + (filename, page_number) 去重后按得分截断
#
# 难点3: 大量 PDF 的 ingestion 速度
# → Rolling Pipeline: 每个 page 独立流经
# ColPali_embed → Blob_upload → Qdrant_upsert
# 每个服务各自的 asyncio.Semaphore 控并发
# 拒绝"批次边界等待",最大化流水线吞吐
#
# 难点4: 文档更新时零停机重建索引
# → 先 upsert 新页、再 delete_orphan_pages(page_num > max)
# 基于 SHA256 的确定性 UUID,同一 (doc_id, page_num) 永远同一 point_id
#
# 【合理推测(原文资料不足处)】
# - ColQwen2/ColQwen3 是 ColPali 方法论的继任者
# 使用 Qwen2-VL 作为 backbone,patch 数量更大(因 vision encoder 不同)
# image_grid_thw 来自 Qwen 的 3D 视觉编码(temporal, height, width)
# - Hierarchical Token Pooler 来自 colpali_engine 库
# 原理是递归 MaxPool,每轮 pool_factor 倍压缩,最终保留语义摘要
# ==========================================================第一章:项目全局视角 (Overview)
业务痛点
在企业知识管理场景中,文档的价值往往不仅在于文字本身,更在于图表、表格、布局、手写批注、扫描件等视觉信息。传统 RAG 方案(PDF → OCR 文本 → 文本向量检索)面临三重硬伤:
| 痛点 | 具体表现 |
|---|---|
| OCR 精度损失 | 财务报表、公式、CAD 图被识别成乱码 |
| 布局语义丢失 | 双栏文档 OCR 后文字顺序混乱,上下文断裂 |
| 图表理解缺失 | 折线图、饼图的数值意义无法被文本检索到 |
该项目用 ColPali 视觉检索 + GPT-4o 多模态理解 的组合拳,从根本上绕开了 OCR 的全部问题------直接把文档页面渲染为图片截图,让模型"看图说话"。
系统核心指标与"胜负手"
胜负手 :三层向量池化的二阶段检索策略(
mean_pooledPrefetch +hierarchical_pooledRerank)+ 多查询并行扩展,使得系统在超大规模文档集上兼顾速度与精度。
第二章:多模态数据摄入与解析 (Data Ingestion & Parsing)
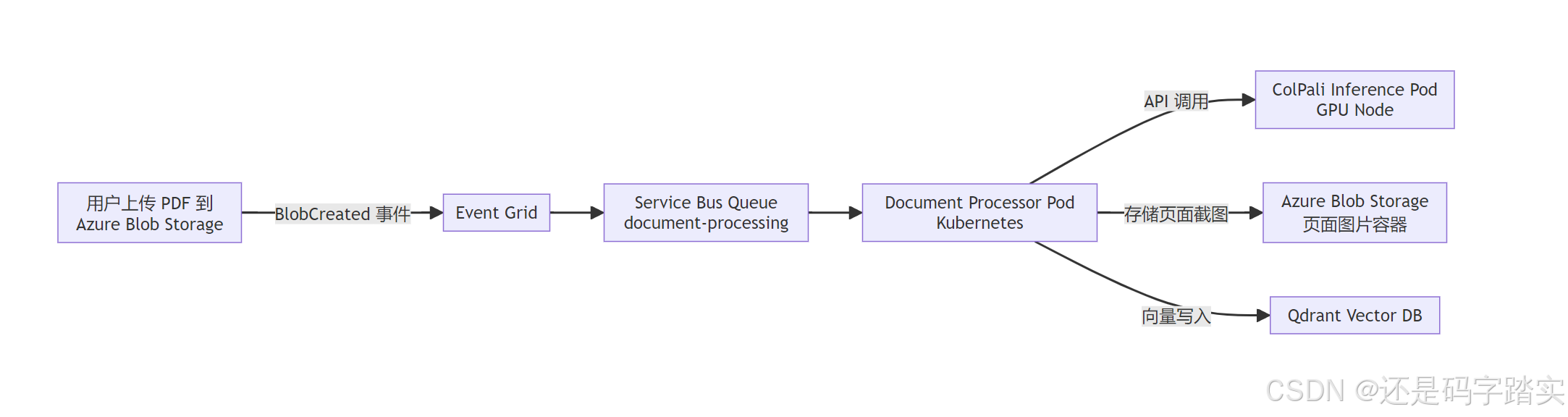
整体事件驱动架构
What: 通过 Azure Event Grid + Service Bus 实现完全解耦的事件驱动处理。
Why: 文档处理是重型计算(GPU 推理),必须通过消息队列缓冲,避免上游上传速度超过下游处理速度时系统崩溃。AutoLockRenewer 保证长文档(数百页 PDF)处理期间消息锁不超时。
How:
关键代码逻辑------Service Bus 消费循环,并发处理 + AutoLockRenewer:
python
# document_processor.py 关键片段
renewer = AutoLockRenewer(max_lock_renewal_duration=1800) # 30分钟锁续期
receiver = self.service_bus_client.get_queue_receiver(
queue_name=self.queue_name,
max_wait_time=60,
auto_lock_renewer=renewer,
max_lock_renewal_duration=1800,
)
# 批量接收 + asyncio.gather 并发处理
received_msgs = await receiver.receive_messages(
max_message_count=max_concurrent_messages, # 默认3条并发
max_wait_time=30,
)
tasks = [self._process_service_bus_message_safe(msg, receiver) for msg in received_msgs]
results = await asyncio.gather(*tasks, return_exceptions=True)死信队列保护机制 :delivery_count >= 2 时自动 dead-letter,避免毒消息无限循环。
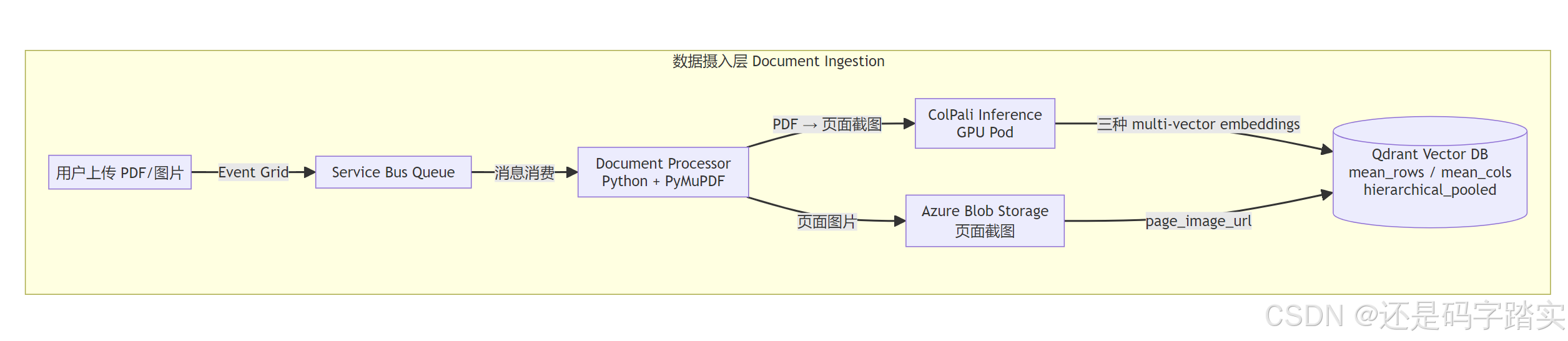
PDF 解析:PyMuPDF + 截图策略
What: 使用 fitz(PyMuPDF)进行 PDF 页面渲染,不做 OCR,直接输出 PIL Image。
Why: PyMuPDF 的核心价值不是文字提取,而是能以指定 DPI 精确渲染每一页为位图------包含所有图表、手写、复杂布局的视觉信息原汁原味保留。同时也附带提取了文本( **page.get_text()**),作为 fallback 或元数据存储。
How:
python
# document_processor.py,_process_pdf 核心逻辑
zoom_factor = self.pdf_image_dpi / 72.0 # 配置为72 DPI(可通过 COLPALI_IMAGE_DPI 调整)
pix = page.get_pixmap(matrix=fitz.Matrix(zoom_factor, zoom_factor))
page_image = Image.open(io.BytesIO(pix.tobytes("png")))
# 同时提取文字作为 text_content 备用
text = str(page.get_text())设计细节:DPI 选择
- 72 DPI 是默认值 ,对应 1024×768 左右分辨率------足以让 ColPali 的 SigLIP vision encoder 识别细节,又不至于产生过于庞大的 patch token 数量(高 DPI 直接导致 token 数爆炸)。
- 图片只降不升 (
scale_factor < 1.0时才 resize),避免对低分辨率扫描件过度放大。
切块策略 (Chunking)
What: 以"页"为粒度,无跨页切块。
Why: 这是 ColPali 方法论的根本性设计------ColPali 的嵌入单位就是整页截图。每一页产出一组 multi-vector patch embeddings。传统 RAG 的 512-token 滑动窗口切块在这里完全不适用。
How: DocumentPage 模型每个实例对应一页,page_number 字段唯一标识。处理完毕后每页独立进入流水线。
页级 ID 的巧妙实现:
使用 SHA256 截取 128 位生成 UUID5 风格的确定性 ID 。同一文档同一页,无论被处理多少次,Qdrant point ID 永远相同 → 幂等 upsert,天然支持文档更新。
python
@property
def page_id(self) -> str:
page_string = f"{self.document_id}_page_{self.page_number}"
hash_bytes = hashlib.sha256(page_string.encode("utf-8")).digest()[:16]
return str(uuid.UUID(bytes=hash_bytes))第三章:检索与召回引擎 (Retrieval & Reranking)
ColPali 嵌入生成:三种池化策略
What: ColPaliInference 服务支持三种 pooling type,一次推理可同时输出多种嵌入,存入 Qdrant 的不同命名向量槽。
Why: 这是整个系统最核心的工程创新,需要深度展开:
原始 Patch Embeddings(none pooling)
一张 PDF 页面图像被 SigLIP 的 patch encoder 切成若干 token。以 ColPali v1.2(PaliGemma backbone)为例,一页 768×1024 图像可产出 ~196 个 patch token(14×14 patches),每个 token 一个 128 维向量。
plain
一页文档 → [196 tokens × 128 dim] 的矩阵ColBERT 的 Late Interaction / MaxSim 机制在检索时计算:
plain
score = Σ_i max_j (q_i · d_j)即每个查询 token 在文档所有 token 中找到最相似的对应,求和。精度极高但计算量巨大。
Mean Pooling(行/列均值池化)
What: 把 [196 tokens × 128 dim] 的矩阵 reshape 成 [14 rows × 14 cols × 128 dim],然后分别对 row 方向和 col 方向求 mean:
python
# inference.py 核心池化逻辑
image_tokens = image_embedding[image_tokens_mask].view(x_patches, y_patches, embedding_dim)
pooled_by_rows = torch.mean(image_tokens, dim=0) # [14 cols × 128]
pooled_by_columns = torch.mean(image_tokens, dim=1) # [14 rows × 128]Why: 从 196 vectors 压缩到 14 vectors,内存/检索成本降低 14x,同时保留了行方向语义(适合找跨列文字)和列方向语义(适合找跨行图表)。
Hierarchical Pooling(层次池化)
What: 使用 colpali_engine 库中的 HierarchicalTokenPooler,以 pool_factor=3 递归压缩:
python
pooled_result = self.hierarchical_pooler.pool_embeddings(
embeddings,
pool_factor=3, # 每轮压缩3倍
padding=True,
)Why: 层次池化保留了不同粒度的语义:**粗粒度(文档大致主题)+ 细粒度(局部细节)**共存于一个 tensor,rerank 精度优于简单均值池化。
Qdrant 三层向量集合设计
python
# qdrant_index.py 核心 vectors_config
{
"hierarchical_pooled": VectorParams(
size=128,
distance=COSINE,
on_disk=True, # 放磁盘!只用于 rerank,不频繁访问
multivector_config=MultiVectorConfig(comparator=MAX_SIM),
hnsw_config=HnswConfigDiff(m=0), # ← 禁用 HNSW!走精确暴力搜索
),
"mean_pooled_columns": VectorParams(
size=128,
distance=COSINE,
on_disk=False, # 放内存!用于高速 Prefetch
multivector_config=MultiVectorConfig(comparator=MAX_SIM),
quantization_config=BinaryQuantization(
binary=BinaryQuantizationConfig(always_ram=True)
),
),
"mean_pooled_rows": VectorParams(...), # 同上
}三层向量的分工:
| 向量类型 | 位置 | 用途 | 压缩手段 |
|---|---|---|---|
mean_pooled_columns |
RAM | 快速 Prefetch(候选召回) | 二值量化(float32 → 1bit) |
mean_pooled_rows |
RAM | 快速 Prefetch(多方向) | 二值量化 |
hierarchical_pooled |
Disk | 精确 Rerank | 无量化,全精度 |
二值量化为什么能行?
Binary Quantization 把每个 float32 按正负号转成 0/1,内存降低 32x,但余弦相似度的排序相关性(rank correlation)仍保持 ~0.95 以上------适合作为粗选阶段的候选过滤器。
二阶段检索:Qdrant Prefetch + Rerank
What: 使用 Qdrant 的 query_points + Prefetch 机制实现两阶段检索。
How:
python
# document_retriever.py,search_single_query 核心
prefetch_limit = top_k * 10 # Prefetch 多10倍候选
query_kwargs = {
"query": query_embeddings,
"prefetch": [
Prefetch(
query=query_embeddings,
limit=prefetch_limit,
using="mean_pooled_columns", # 第一阶段:列方向均值池化
params=SearchParams(
hnsw_ef=200,
quantization=QuantizationSearchParams(
ignore=False,
rescore=False, # Prefetch 不重新打分
oversampling=2.0, # 超采样2倍增加召回率
),
),
),
Prefetch(
query=query_embeddings,
limit=prefetch_limit,
using="mean_pooled_rows", # 第一阶段:行方向均值池化
params=...,
),
],
"using": "hierarchical_pooled", # 第二阶段:层次池化精确 Rerank
"limit": top_k,
}流程解析:
- Prefetch Stage: 用二值量化的行/列均值向量,在 RAM 中快速召回各
top_k × 10 × 2个候选(行方向 + 列方向各一批) - Rerank Stage: 对合并后的候选集,用磁盘上的全精度 hierarchical pooled 向量做精确打分,取最终
top_k - 两次 Prefetch 并联: 行/列方向分别召回,增大候选多样性,提升最终 recall
多查询并行扩展(Query Expansion)
What: 用 LLM 将 1 个原始查询扩展为最多 6 个语义变体,并行发起检索。
Why: 用户的自然语言问题往往与文档中的专业术语存在词汇鸿沟(vocabulary mismatch)。多查询扩展是一种无监督的方式来覆盖更多相关表达。
How:
yaml
# prompts.yaml query_generation 片段
Generate up to 5 different but related search queries...
Consider:
- Different ways to phrase the same concept
- Related technical terms and synonyms
- Broader and narrower aspects of the topic
- Alternative perspectives on the subject
python
# agent.py,retrieve_documents_parallel
all_query_embeddings = await self._embed_queries(queries) # 一次 batch 调用
search_tasks = [
search_single_query(query, query_embeddings, i)
for i, (query, query_embeddings) in enumerate(
zip(queries, all_query_embeddings)
)
]
all_search_results = await asyncio.gather(*search_tasks, return_exceptions=True)
# 去重:以 (filename, page_number) 为 key
seen_docs = set()
for chunk in search_result:
doc_key = (chunk.source_file, chunk.page_number)
if doc_key not in seen_docs:
all_chunks.append(chunk)
seen_docs.add(doc_key)
all_chunks.sort(key=lambda x: x.score, reverse=True)
final_chunks = all_chunks[:top_k]关键细节: 多个查询的嵌入是一次 batch 请求 到 ColPali 推理服务,不是 N 次独立调用------避免重复的 GPU kernel launch 开销。
第四章:Agent 编排与防幻觉 (Agent Workflow & Anti-Hallucination)
Agent 执行链路
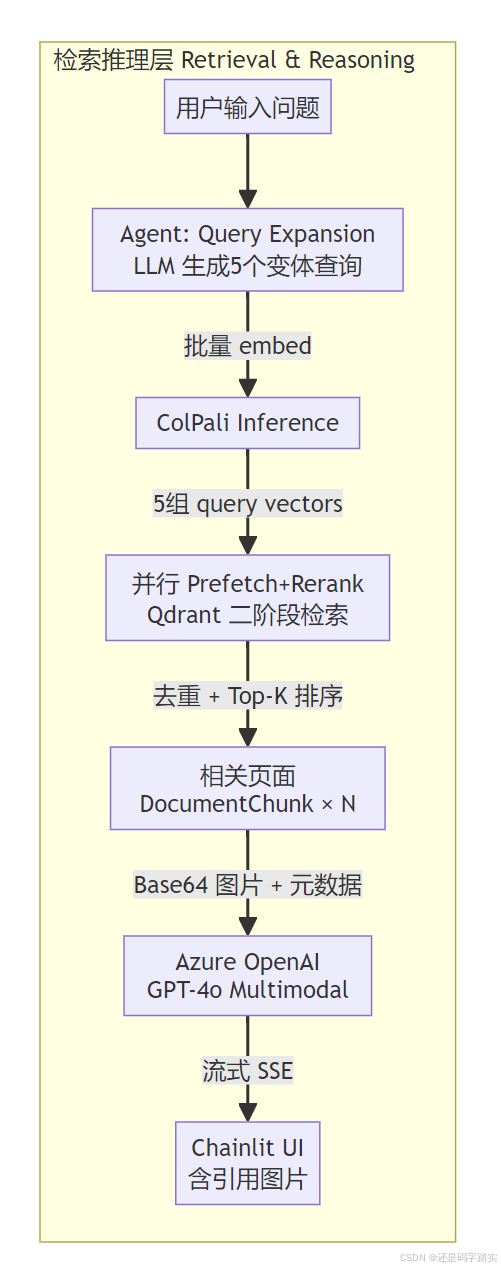
What: 单一 ColPaliAgent,无工具调用循环,固定五步顺序流水线。
Why: 这是一个"确定性 RAG Agent",而非 ReAct 风格的探索型 Agent。因为 document Q&A 场景的意图高度明确(找文档回答问题),不需要动态工具选择,确定性流水线更稳定、延迟更低、更容易 debug。
How(五步流水线):
plain
Step 1: Query Expansion
用 LLM 从原始问题生成变体查询(SSE 发送 step_start/step_end)
Step 2: Document Search
并行向量检索 → 合并去重 → Top-K 排序
(SSE 发送 step_start/step_end)
Step 3: Thinking(伪步骤)
向 UI 发送 "Analyzing retrieved documents..." 提示
增强用户感知(实际并无额外计算)
Step 4: 构建 Multimodal 消息
system_message: answer_generation prompt
user_message: 原始问题 + [TextContent(chunk_json) + DataContent(base64_image)] × N
Step 5: GPT-4o Streaming
流式接收 token 并通过 SSE 推送到前端
完成后正则提取 [1][2] 引用号,关联 source 图片多模态输入构建(核心防幻觉机制)
What: 每个文档块以双内容 形式注入 GPT-4o:JSON 元数据文本 + base64 图片。
Why: 这是防幻觉的关键设计。GPT-4o 既能看到结构化的 JSON(包含 source_file、page_number、score 等),又能直接"看"原始图片。两种信息互相校验,大幅减少模型编造(hallucination)。
How:
python
# agent.py,构建 ChatMessage 内容列表
contents = [TextContent(text=message)] # 原始问题
for i, chunk in enumerate(document_chunks):
citation_index = i + 1
# 1. 先注入结构化文本摘要(不含图片)
chunk_dict = chunk.model_dump(exclude={"page_image_base64"})
contents.append(TextContent(
text=f"Next document page (Citation {citation_index}):\n"
+ json.dumps(chunk_dict, indent=2)
))
# 2. 再注入原始图片(GPT-4o 可视觉理解)
contents.append(DataContent(
uri=f"data:image/png;base64,{chunk.page_image_base64}",
media_type="image/png",
))强制引用规范(Prompt Engineering 防幻觉)
What: System prompt 包含 7 条严格的引用规则。
How:
yaml
# prompts.yaml answer_generation 核心规则
CRITICAL CITATION RULES:
- Use numbered citations: [1], [2], [3], etc.
- Each number refers to ONE specific document page in the order provided
- EVERY sentence or paragraph that contains information from the documents MUST include at least one citation
- Do NOT invent citations or refer to pages that are not provided
- Do NOT include any uncited factual statements based on the documents
- DO NOT INCLUDE A LIST OF SOURCES AT THE END. # 避免重复Why: 强制引用的三重意义:
- 溯源验证:用户可以点击 1 查看对应页面截图,自行核实
- 减少编造:模型不得使用未在 context 中的信息
- UI 联动 :
<font style="color:#DF2A3F;">[数字]</font>引用号被 regex 解析后,与<font style="color:#DF2A3F;">source_delta</font>事件关联,在 Chainlit 侧边栏渲染图片
实时流式 SSE 架构
python
# app.py,SSE 事件流
@app.post("/chat/stream")
async def chat_stream(request: ChatRequest):
async def event_generator():
async for event in agent_instance.run_stream(...):
yield f"data: {json.dumps(event)}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")事件类型体系:
| 事件类型 | 触发时机 | UI 效果 |
|---|---|---|
step_start |
开始 Query Expansion / Document Search | 折叠式步骤展开 |
step_end |
步骤完成 | 步骤收起,显示摘要 |
text_delta |
GPT-4o 生成每个 token | 流式文字显示 |
source_delta |
处理完一个引用 | 侧边栏增加图片卡片 |
done |
全部完成 | 结束流 |
error |
任意异常 | 红色错误提示 |
UI 侧的 Token 缓冲优化:
python
# chainlit_ui.py,流式渲染缓冲
buffer_size = 8 # 积累 8 个字符再推送
min_stream_interval = 0.03 # 最小 30ms 间隔
max_buffer_time = 0.15 # 最大等待 150ms
should_stream = (
len(token_buffer) >= buffer_size
or time_since_last_stream >= min_stream_interval
or (token_buffer and time_since_last_stream >= max_buffer_time)
)这个三元判断保证:既不因每个 token 都刷 UI 导致卡顿,又不因缓冲太长导致肉眼可见的延迟。
第五章:大白话费曼延伸 (Feynman Explanation)
类比一:图书馆找书的"三重筛选机制"
想象你在一座超大图书馆里找资料,书库有 100 万本书:
- 第一关:门口的智能索引机(mean_pooled 向量 + 二值量化)
- 这台机器把每本书的内容压缩成一串 0/1 代码(二值量化)
- 你的问题也被压缩成 0/1 代码
- 机器在 1 秒内从 100 万本中筛出最相关的 100 本------很快,但不太精确
- 第二关:阅览室里的专业司书(hierarchical_pooled 向量,精确 Rerank)
- 司书拿到那 100 本候选,仔细阅读每本书的关键段落
- 根据"你的问题需要的到底是哪几章",精确排序,给你 10 本
- 第三关:你自己用放大镜看原文(GPT-4o 看截图)
- 最终你不只是读目录(文本摘要),而是亲眼看每页的原始图片
- 图表、手写、复杂表格你都能直接看,而不依赖别人帮你"翻译"
多查询扩展就像------你不只问"合同里的赔偿条款",还同时问"违约金"、"损失赔偿"、"breach penalty",让三个小助手同时去三个书架找,汇总后给你最相关的。
类比二:日本回转寿司的流水线(Rolling Pipeline)
传统方案(批处理):厨房做完 200 盘寿司,全部装盘,统一上流水线 → 你等 40 分钟才能看到第一盘。
本系统的 Rolling Pipeline:
- 第一盘 PDF 第 1 页:刚进厨房(ColPali 推理),第 2 页已经开始切鱼了
- 第一盘做完立刻上传图片到冰箱(Blob Storage),第 2 页还在推理中
- 第一盘图片上传完立刻写入 Qdrant,此时第 3 页才开始推理
每道菜(每一页)独立在流水线上滑行,厨房/冰箱/收银台(ColPali/Blob/Qdrant)各有自己的"并发上限"(asyncio.Semaphore),互不等待,最大化整体吞吐量。
第六章:降维打击与实战启发 (Actionable Takeaways)
Trick 1:确定性 UUID 实现幂等 Upsert
直接抄走,应用于任何**"要支持文档增量更新"**的向量数据库场景:
python
import hashlib
import uuid
def page_id(document_id: str, page_number: int) -> str:
"""
基于 document_id + page_number 生成确定性 UUID。
同一文档同一页,无论处理多少次,ID 永远相同。
→ Qdrant upsert 天然幂等,支持零停机文档更新。
"""
page_string = f"{document_id}_page_{page_number}"
hash_bytes = hashlib.sha256(page_string.encode("utf-8")).digest()[:16]
return str(uuid.UUID(bytes=hash_bytes))Zero-downtime 更新模式(可复用到任何场景):
python
# Step 1: 先 upsert 新版本页面(文档仍可搜索)
await qdrant_client.upsert(collection_name=..., points=new_pages, wait=True)
# Step 2: 再删除旧版本多余的页面(例如文档从100页缩减到80页)
await qdrant_client.delete(
collection_name=...,
points_selector=FilterSelector(
filter=Filter(must=[
FieldCondition(key="document_id", match=MatchValue(value=doc_id)),
FieldCondition(key="page_number", range=Range(gt=max_valid_page_number)),
])
)
)Trick 2:Qdrant 二阶段检索模板(可复用于任何多向量场景)
python
# 二阶段检索模板:快速召回 + 精确 Rerank
# 适用于任何 multi-vector embedding(ColPali / ColBERT / SPLADE 等)
from qdrant_client.models import Prefetch, QuantizationSearchParams, SearchParams
async def two_stage_search(
qdrant_client,
query_embeddings, # 查询的 multi-vector embeddings
collection_name: str,
top_k: int = 10,
prefetch_multiplier: int = 10, # 候选倍率,越大精度越高但越慢
oversampling: float = 2.0,
):
"""
二阶段向量检索:
Stage 1: 二值量化快速候选召回(RAM,速度优先)
Stage 2: 全精度 Rerank(Disk,精度优先)
"""
prefetch_limit = top_k * prefetch_multiplier
results = await qdrant_client.query_points(
collection_name=collection_name,
query=query_embeddings,
# === Stage 1: Prefetch(可以有多个,并联召回不同视角)===
prefetch=[
Prefetch(
query=query_embeddings,
limit=prefetch_limit,
using="fast_vector", # 二值量化的快速向量
params=SearchParams(
hnsw_ef=200,
quantization=QuantizationSearchParams(
ignore=False,
rescore=False, # Prefetch 不重打分,节省时间
oversampling=oversampling,
),
),
),
],
# === Stage 2: Rerank(基于精确向量,对 Prefetch 结果重排)===
using="accurate_vector", # 全精度、无 HNSW(m=0)的精确向量
limit=top_k,
with_payload=True,
)
return results.pointsTrick 3:多查询异步并行 + 去重排序(通用 RAG 召回增强模板)
python
import asyncio
from typing import List, Tuple, TypeVar, Generic
T = TypeVar("T")
async def multi_query_retrieve_and_deduplicate(
queries: List[str],
search_fn, # 单查询检索函数:async (query: str) -> List[Chunk]
dedup_key_fn, # 去重 key 函数:(chunk) -> hashable
score_key_fn, # 排序分数:(chunk) -> float
top_k: int = 10,
) -> list:
"""
多查询并行检索 + 去重 + 分数排序。
可抄走应用于任意 RAG 场景(文本/图片/混合均可)。
使用方式:
chunks = await multi_query_retrieve_and_deduplicate(
queries=["原始问题", "变体1", "变体2"],
search_fn=my_search,
dedup_key_fn=lambda c: (c.doc_id, c.page),
score_key_fn=lambda c: c.score,
top_k=5,
)
"""
# 并行执行所有查询
all_results = await asyncio.gather(
*[search_fn(q) for q in queries],
return_exceptions=True,
)
# 去重合并
seen = set()
merged = []
for result_set in all_results:
if isinstance(result_set, Exception):
continue
for chunk in result_set:
key = dedup_key_fn(chunk)
if key not in seen:
seen.add(key)
merged.append(chunk)
# 按得分排序
merged.sort(key=score_key_fn, reverse=True)
return merged[:top_k]架构全局流程图
技术亮点总结
| 维度 | 核心 Trick | 价值 |
|---|---|---|
| 嵌入压缩 | 行/列均值池化 + 二值量化 | 内存降低 ~32x,速度提升数十倍 |
| 检索精度 | 层次池化 Rerank(磁盘向量) | 无需全量高精度向量常驻内存 |
| 召回覆盖 | 5 查询变体并行 + 去重 | 解决词汇鸿沟,提升 Recall@K |
| 嵌入吞吐 | Rolling Pipeline + Semaphore | 最大化 GPU/Blob/DB 并发利用 |
| 更新幂等 | SHA256 确定性 UUID | 文档更新零停机,无脏数据 |
| 防幻觉 | 双内容注入(JSON+图片)+ 强制引用 | 可验证、可追溯的回答 |
| 用户体验 | SSE 多事件流 + Token 缓冲 | 流畅实时响应,步骤透明可见 |
参考资料
1This repository provides a multi-modal RAG (Retrieval-Augmented Generation) solution that processes documents visually using late interaction embedding techniques:
https://github.com/microsoft/multi-modal-rag-with-colpali
2ColPali:
https://huggingface.co/docs/transformers/v4.51.1/model_doc/colpali