一、背景:两个函数,一个问题
学习分类模型时,大多数人都会分别接触两个函数:
- Sigmoid :用于二分类
- Softmax:用于多分类
但教材往往只告诉你"什么时候用哪个",却很少回答一个更本质的问题:它们为什么都能输出概率?两者之间到底是什么关系?
很多人直觉上认为它们"类似",但实际上Sigmoid 就是 Softmax 在二分类情况下的严格数学特例。不是类比,也不是近似,而是完全等价。理解这一点,你会发现,二分类与多分类,本质上是同一个问题的不同维度表达。
二、Softmax:多分类的概率化机制
给定 KKK 个类别的 logits z1,z2,...,zKz_1, z_2, \ldots, z_Kz1,z2,...,zK(输出层的原始值,未经归一化,可以取任意实数),Softmax 把它们转换为概率分布:
P(y=k)=ezk∑j=1Kezj P(y = k) = \frac{e^{z_k}}{\sum_{j=1}^{K} e^{z_j}} P(y=k)=∑j=1Kezjezk
Softmax 做了两件关键事情:指数映射和全局归一化。这样做,每个输出都在 (0,1)(0, 1)(0,1) 之间,且所有输出之和为 1。
2.1 指数映射(Exponentiation)
ezk>0 e^{z_k} > 0 ezk>0
保证所有输出为正值,可以解释为"强度"或"支持度"。
2.2 全局归一化(Normalization)
除以总和:
∑kP(y=k)=1 \sum_k P(y=k) = 1 k∑P(y=k)=1
于是输出成为合法概率分布。
直觉上,logit 越大,指数越大 ,占总和比例越高 ,概率越大。
三、当K=2K=2K=2 时,Softmax 退化为 Sigmoid
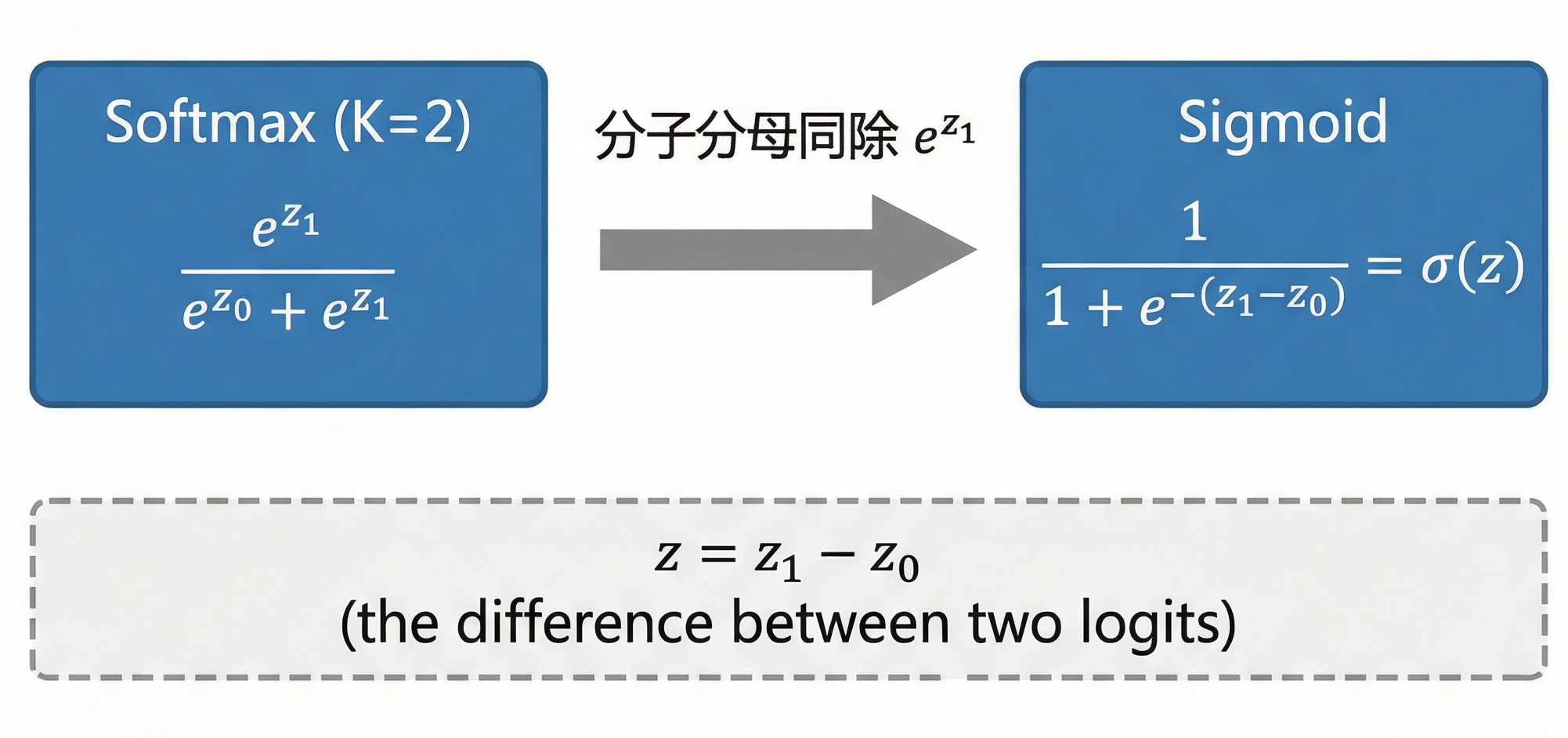
现在考虑二分类,设两个类别 logits:类别0为z0z_0z0,类别1为z1z_1z1。
Softmax 给出类别 1 的概率:
P(y=1)=ez1ez0+ez1 P(y=1)=\frac{e^{z_1}}{e^{z_0}+e^{z_1}} P(y=1)=ez0+ez1ez1
这是一个标准 Softmax,没有任何特殊处理。
3.1 化简
分子分母同时除以 ez1e^{z_1}ez1:
P(y=1)=1ez0−z1+1=11+e−(z1−z0) P(y=1) = \frac{1}{e^{z_0 - z_1} + 1} = \frac{1}{1 + e^{-(z_1 - z_0)}} P(y=1)=ez0−z1+11=1+e−(z1−z0)1
令z=z1−z0z = z_1 - z_0z=z1−z0,得到:
P(y=1)=σ(z) P(y=1)=\sigma(z) P(y=1)=σ(z)
这就是Sigmoid函数。
-
同理类别0的概率为:
P(y=0)=1−P(y=1)=1−σ(z) P(y=0) = 1-P(y=1)=1-\sigma(z) P(y=0)=1−P(y=1)=1−σ(z) -
因此,二分类 Softmax 经过简单的代数变形,就退化为对 logit 差值 z=z1−z0z = z_1 - z_0z=z1−z0 做 Sigmoid。
3.2 为什么二分类只需要一个输出神经元?
原始 Softmax 形式需要两个神经元输出,即z0z_0z0和z1z_1z1。但推导告诉我们,模型真正关心的只有:z1−z0z_1 - z_0z1−z0。也就是说:绝对值不重要,只有相对差值重要。
从模型结构的角度看,在神经网络中,logit 来自输出层的线性变换:
zk=wkTx+bk z_k = w_k^T x + b_k zk=wkTx+bk
如果仍使用两个输出神经元,我们实际上在计算:
z1−z0=(w1Tx+b1)−(w0Tx+b0) z_1 - z_0 = (w_1^T x + b_1) - (w_0^T x + b_0) z1−z0=(w1Tx+b1)−(w0Tx+b0)
整理可得:
z1−z0=(w1−w0)Tx+(b1−b0) z_1 - z_0 = (w_1 - w_0)^T x + (b_1 - b_0) z1−z0=(w1−w0)Tx+(b1−b0)
将同类参数可以合并成一组:
z=z1−z0w=w1−w0b=b1−b0 z = z_1 - z_0 \\ w = w_1 - w_0 \\ b = b_1 - b_0 z=z1−z0w=w1−w0b=b1−b0
就得到:
z=wTx+b z = w^Tx+b z=wTx+b
这说明,两个输出神经元在数学上等价于一个输出神经元。
3.3 两种方式完全等价
两种方式数学上完全等价,但 Sigmoid 方式只需一个输出神经元,更简洁高效。
-
实现上的简化。 二分类不需要两个输出神经元分别输出 z0z_0z0 和 z1z_1z1,只需要一个神经元输出 z=z1−z0z = z_1 - z_0z=z1−z0,再过 Sigmoid 就够了。少一个神经元意味着少一行权重,计算更高效。
-
概率的互补性。 Sigmoid 输出 σ(z)\sigma(z)σ(z) 作为类别 1 的概率,1−σ(z)1 - \sigma(z)1−σ(z) 自动就是类别 0 的概率,两者之和恒为 1。这不是巧合,Softmax 本身就保证概率和为 1,退化到两类时这个性质自然保留。
-
损失函数的对应。 多分类用交叉熵 + Softmax,二分类用二元交叉熵 + Sigmoid,这两者也是同一个框架的不同实例。PyTorch 中
nn.CrossEntropyLoss内部包含了 Softmax,nn.BCEWithLogitsLoss内部包含了 Sigmoid,底层逻辑是一致的。
四、从 Sigmoid 反过来看 Softmax
反过来理解也有启发。Sigmoid 把一个标量映射到 (0,1)(0, 1)(0,1),可以看作在回答一个"是/否"问题。Softmax 把一个向量映射到概率单纯形(所有分量为正且和为 1),可以看作在回答一个"K 选 1"问题。
当"K 选 1"的 K 等于 2 时,就退化成了"是/否",那么一个标量就够了。
五、总结
| 二分类 | 多分类 | |
|---|---|---|
| 激活函数 | Sigmoid | Softmax |
| 输出神经元数 | 1 | K |
| 输出含义 | P(y=1)P(y=1)P(y=1) | P(y=k)P(y=k)P(y=k) for each kkk |
| 损失函数 | 二元交叉熵(BCE) | 交叉熵(CE) |
| 数学关系 | Softmax 在 K=2K=2K=2 时的特例 | 一般形式 |
Sigmoid 不是和 Softmax "类似"的函数,它就是 Softmax,只不过只有两个类别时可以简化成更紧凑的形式。