目录
[1 · 数组名的理解](#1 · 数组名的理解)
[2 · 使用指针访问数组](#2 · 使用指针访问数组)
[3 · 一维数组传参的本质](#3 · 一维数组传参的本质)
[4 · 冒泡排序](#4 · 冒泡排序)
[5 · 二级指针](#5 · 二级指针)
[6 · 指针数组](#6 · 指针数组)
[7 · 指针数组模拟二维数组](#7 · 指针数组模拟二维数组)
[8 · 字符指针变量](#8 · 字符指针变量)
[9 · 数组指针变量](#9 · 数组指针变量)
[9 - 1 · 数组指针变量是什么](#9 - 1 · 数组指针变量是什么)
[9 - 2 · 数组指针变量怎么初始化](#9 - 2 · 数组指针变量怎么初始化)
[10 · 二维数组传参的本质](#10 · 二维数组传参的本质)
前言
上一篇中简单的介绍了指针的基本内容,本篇是对指针介绍的第二篇,将着重介绍指针与数组结合的内容。
1 · 数组名的理解
在上一篇中,我们提到过,在一般情况下,数组名就是首元素的地址
arr == &arr0
那现在我们可以测试一下:
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
printf("%p\n", &arr[0]);
printf("%p\n", arr);
return 0;
}运行一下看看:

可以看到,数组名的确就是数组首元素的地址。
一般情况下,这句话是正确的,但是我们也提到了,有两个例外,&arr 和 sizeof(arr)。
下面我们举个栗子
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("sizeof(arr) == %zd\n", sizeof(arr));
printf("sizeof(&arr[0]) == %zd\n", sizeof(&arr[0]));
printf("&arr[0] == %p\n", &arr[0]);
printf("arr == %p\n", arr);
printf("&arr[0]+1 == %p\n", &arr[0] + 1);
printf("&arr+1 == %p\n", &arr + 1);
return 0;
}运行一下看看:

可以看到,如果arr代表首元素地址,那么sizeof(arr)应该是4或8,而实际上是40。
&arr + 1 一步并不是跨4个字节,而是 2 * 16^1 + 8 * 16^0 == 40 个字节。
那我们可以得出结论:
sizeof(数组名) 计算的是整个数组的大小,单位是字节。
&数组名,取出的是整个数组的地址,一步的大小为整个数组。
除了这两个例外,其他地方数组名就是首元素的地址。
2 · 使用指针访问数组
了解了前面的内容,我们就可以很方便的用指针访问数组了
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
int i = 0;
for (i = 0; i < sz; i++)
{
scanf("%d", p + i);
}
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}现在我们可以思考一下:arr 在这里表示首元素的地址, arr 是可以赋值给p 的,那么此时p就等同于arr,那么我们可不可以对p 使用下标访问操作符来访问数组呢?
不妨试试:
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", p[i]);
}
return 0;
}运行一下看看:
可以看到,我们的想法是可行的,那么这是为什么呢
其实pi 与 *(p+i) 是等价的,同理,arri 与 *(arr+i) 也是等价的。数组的这种形式,编译器是会转换成指针这种去运算的,即 首元素地址 + 偏移量 求出地址,然后解引用。
那么这也就说明,arri 其实 与 iarr 的效果是一样的,它们分别会转换为 *(arr + i) 与 *(i + arr)。
当然,iarr 这种写法是不推荐的。
3 · 一维数组传参的本质
数组是可以作为实参传递给函数的,我们先来看一段代码:
cpp
void Test1(int arr[])
{
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
printf("Test1 中算出的 sz==%d\n", sz);
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void Test2(int* arr)
{
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
printf("Test2 中算出的 sz==%d\n", sz);
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
}
#include <stdio.h>
int main()
{
int arr[10] = { 0,1,2,3,4,5,6,7,8,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
printf("main 中算出的 sz==%d\n", sz);
Test1(arr);
Test2(arr);
return 0;
}运行一下看看:
首先我们可能会有疑惑,我们用数组名作为实参,数组名本质上就是一个地址,为什么Test1中用数组作为形参来接收传参呢,难道不应该是指针吗?
其实就应该是指针,不过数组形式也可以,但本质上仍是指针变量,Test1的形参 int arr\[\] 本质上就是个 int* arr 。
然后我们发现:在函数内部是无法正确求出数组总元素个数的,这是因为 数组名是首元素的地址,我们传参传过去的是一个地址,那么sizeof(arr),求到的是一个地址的大小,而不是数组总元素的大小。
所以一维数组传参的本质是传递了首元素的地址
因此形参访问的数组和实参的数组是同一个数组,形参的数组也不会单独再开一个空间,所以形参的数组是可以省略掉数组的大小的。
4 · 冒泡排序
冒泡排序是用来解决排序的问题。
排序的算法有很多:冒泡 插入 选择 快排 希尔 堆排序。
冒泡排序的核心思想:两两相邻元素进行比较。
我们进行一趟比较,其实也就确定了 1 个元素的位置,因此如果总元素有n个,那么我们要进行n-1趟比较,首次两两比较的次数也是 n-1次。
随着我们进行完一趟比较,1 个元素的位置被确定,此时我们需要两两比较的次数也会随之 -1。
那么我们可以这么写:
cpp
#include <stdio.h>
void BubbleSort(int* arr, int sz)
{
int i = 1;
int j = 0;
int t = 0;
//趟数
for (i = 1; i <= sz - 1; i++)
{
//一次确定一个
for (j = 0; j <= sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
//从小到大排,前者大就交换
t = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = t;
}
}
}
}
int main()
{
int i = 0;
int arr[] = { 5,0,9,7,6,3,4,2,8,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
printf("原数组如下 :");
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
BubbleSort(arr, sz);
printf("排序后数组如下:");
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}运行一下试试:

这里我们是从小到大进行排序,如果想要从大到小排序,只需将 if(arrj > arrj+1) 改为 if(arrj < arrj+1) 。
上面我们给了一个比较无序的原数组,但如果我们给的原数组在一定程度上就已经有序了,比如:
9 0 1 2 3 4 5 6 7 8
那么对这个原数组,我们排一趟就足够了,但是按照我们上面的代码,仍会进行9趟,每一趟两两比较,这样显然是有浪费的,那么我们可以进行优化,如下:
cpp
void BubbleSort(int* arr, int sz)
{
int i = 1;
int j = 0;
int t = 0;
int flag = 1;
//趟数
for (i = 1; i <= sz - 1; i++)
{
int flag = 1;//判断是否提前排序完成
//一次确定一个
for (j = 0; j <= sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
//从小到大排,前者大就交换
t = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = t;
//如果发生交换,说明还在进行排序
flag = 0;
}
}
//如果一趟下来没发生交换,说明已排序完成
if (flag)
{
break;
}
}
}我们定义一个新变量 flag 用来判断排序是否完成,每一趟结束后进行判断,如果一趟当中进行了交换,说明排序还没完成,在交换后将flag置为0,使得一趟过后的 if 条件语句为假,进行下一次循环,并将flag重新置为1。如果一趟结束后没有发生交换,flag不会改变,为1,此时if 条件语句为真,跳出循环。
5 · 二级指针
指针变量也是变量,是变量就有地址,二级指针就是用来存放指针变量的地址的。
cpp
#include <stdio.h>
int main()
{
int a = 10;
int* p = &a;
int** pp = &p;
return 0;
}上面的 p 是指针,pp 是二级指针。
pp 的类型是 int**
int** 是二级指针类型,最后面的 * 是在说明这是个指针变量,前面的 int* 是说明这个指针变量指向的类型。
pp+1 跳过一个指针变量大小的字节,4或8。在x86环境是4个字节,x64环境是8个字节。
对二级指针 pp 进行解引用(*pp),访问的是指向的一级指针 p。
如果对 pp 进行两次解引用(**pp),访问的是指向的一级指针p 指向的变量 a。
6 · 指针数组
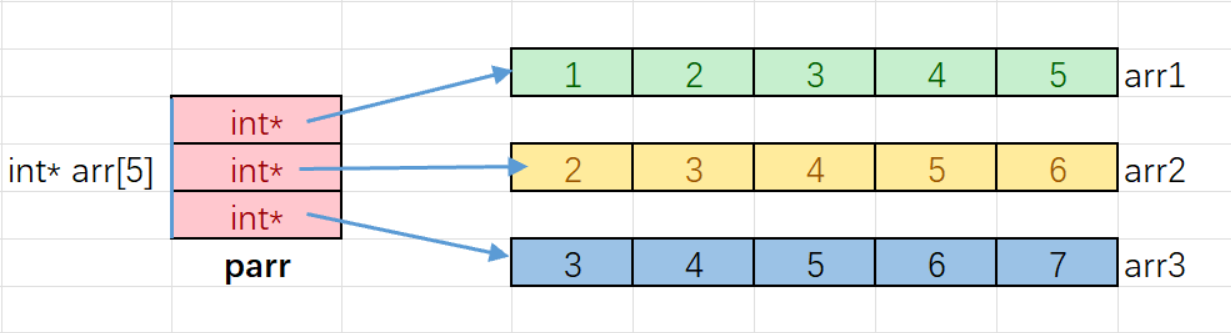
我们先要弄明白一件事:指针数组是指针还是数组。
我们不妨类比一下,整型数组 是存放整型数据的数组,那么显然 指针数组是存放指针的数组
指针数组的每个元素都是用来存放地址(指针)的
如图:

7 · 指针数组模拟二维数组
cpp
#include<stdio.h>
int main()
{
int i = 0;
int j = 0;
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
int* parr[] = { arr1,arr2,arr3 };
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}数组名是首元素地址 类型是 int* ,就可以放入我们的指针数组 parr中。
对parr 进行下标访问,找到的是parr 中的元素,再进行下标访问就找到了数组中的元素。
也可以这样理解,前面我们提到了 arri 等价 *(arr+i)
那么我们这里的 parrij 等价 *(*(parr+i)+j)
此时的 parrij本质上是一个指针运算。
需要注意的一点是:这里只是模拟了二维数组的功能,并不是真的二维数组,原因也很简单,我们不能保证arr1 arr2 arr3 三者之间是连续的。
8 · 字符指针变量
在指针的类型中我们知道有⼀种指针类型为字符指针 char*
一般这样使用:
cpp
int main()
{
char ch = 'w';
char *pc = &ch;
*pc = 'w';
return 0;
}还有一种使用方式如下:
cpp
#include <stdio.h>
int main()
{
const char* p = "abcdef";
printf("%s", p);
return 0;
}运行一下看看:

指针p可以指向一个字符串,很多人会误解是将字符串放进了指针变量中,但本质是将字符串首字符的地址放进了指针变量中。
%s 打印字符串时,需要提供起始地址。
由于字符串每个字符地址是连续的,所以也可以通过 指针+-整数来一个个访问。
我们这里的p 指向的是一个常量字符串,常量字符串的内容是不可更改的,所以我们加上了const,当然 不加const依然不能改。
常量字符串是存在代码段里的,既然它不能被修改,那么也没有必要存在两份,所以如果有两个指针变量p1 p2同时指向一个常量字符串,那么这两个指针变量 p1 p2 是共用一份的,都是这个常量字符串的首元素地址,此时 p1 == p2。
9 · 数组指针变量
9 - 1 · 数组指针变量是什么
数组指针变量是指针变量。
类比我们所知道的整型指针变量,整型指针变量存放的是整型变量的地址,能指向整型数据的指针。
那么数组指针变量应该就是 存放的是数组的地址,能指向数组的指针
int (*p)[10]这里的 p 就是数组指针变量。
注意:圆括号()不能丢,因为 的优先级是比 * 高的,如果没有圆括号,p会优先与10结合,那样就是指针数组了。
之前我们提到过,去掉名字就是类型,所以数组指针变量的类型是
int (*)[10]9 - 2 · 数组指针变量怎么初始化
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 0,1,2,3,4,5,6,7,8,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
int (*p)[10] = &arr;
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", (*p)[i]);
}
return 0;
}要存放数组的地址,首先我们需要取到数组的地址,用 &arr 即可,然后放入数组指针变量中就完成了初始化。
需要注意的是:数组指针变量和指向的数组,类型和元素要一一对应,并且数组指针变量的 不能为空, 中需要用具体数字。
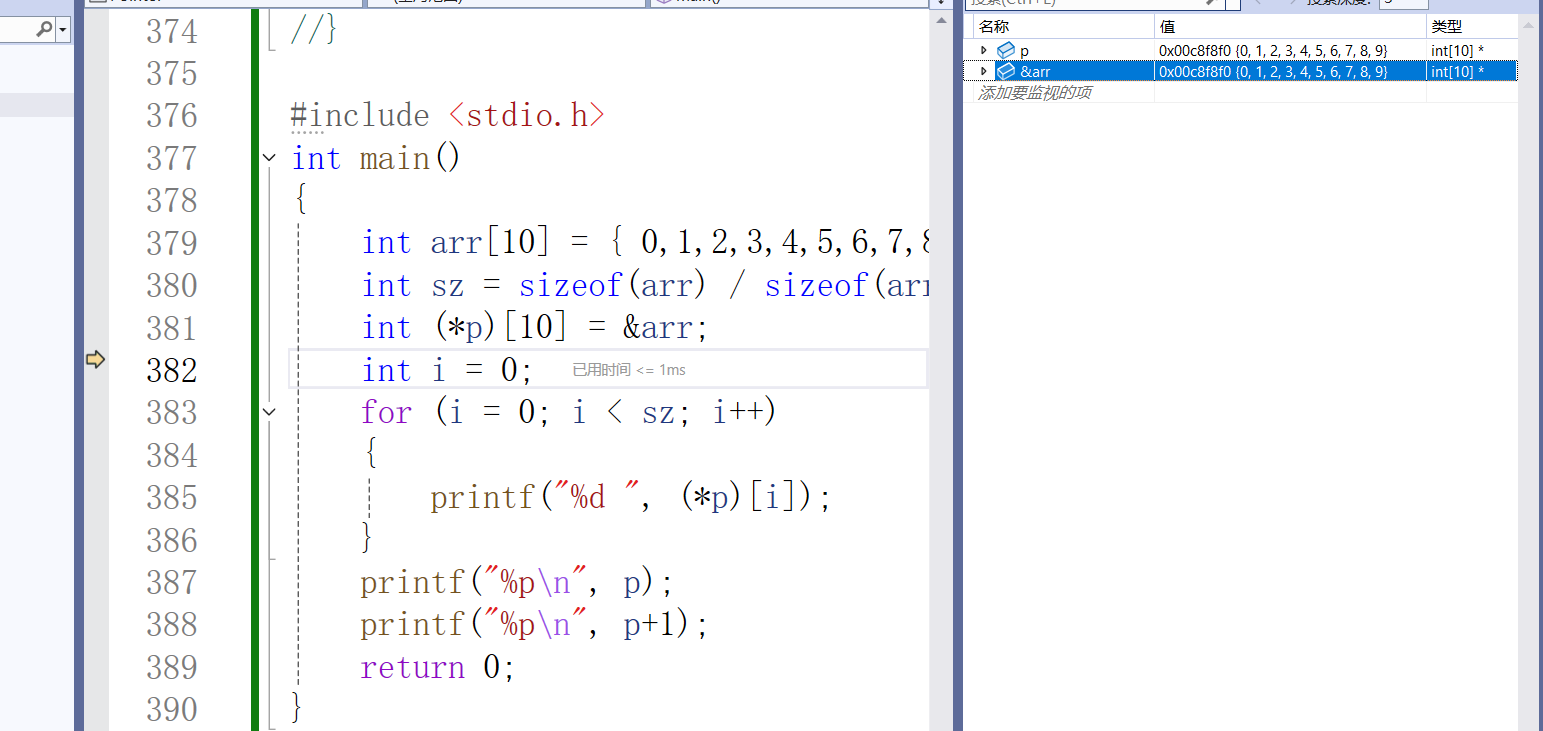
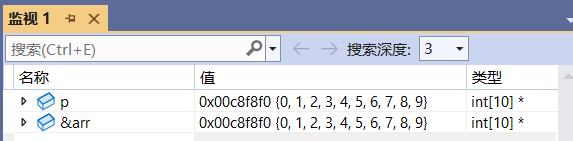
通过调试,我们可以看到 p 和 &arr 的类型是一致的
那么数组指针变量可以怎样应用呢?
上面我们举的例子虽然达到了我们的目标,但是肉眼可见的啰嗦,不够方便,不够简单。
那么数组指针变量可以应用在哪呢?可以应用在二维数组传参。
10 · 二维数组传参的本质
过去有一个二位数组需要传参给函数时,我们是这样写的:
cpp
#include <stdio.h>
void Print(int arr[3][5], int r, int c)
{
int i = 0;
int j = 0;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
Print(arr, 3, 5);
return 0;
}这里我们形参用的是二维数组的形式,还有没有其他的写法呢?
我们再次理解一下二维数组:二维数组可以看作是一个存放一维数组的数组,二维数组中的每个元素都是一维数组,那么二维数组的首元素也就是一个一维数组。
数组名表示首元素的地址,那么二维数组名表示的就是首一维数组的的地址。
按上面的例子来说,此时arr 的首元素是一个一维数组,类型是 int 5,那么这个一维数组的地址的类型就应该是 int (*)5
那么我们传参用的是二维数组名,其实也就是首元素地址,那么我们可以用指针来接收,根据地址的类型,我们应该用数组指针变量来接收。
可以写成:
cpp
void Print(int (*p)[5], int r, int c)
{
int i = 0;
int j = 0;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", *(*(p + i) + j));
}
printf("\n");
}
}所以二维数组传参的本质是传递了首元素的地址,二维数组的首元素是一个一维数组。
总结
以上简单介绍了指针相关的一部分内容,关于后续内容,请期待下一篇
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。