在医学视觉-语言预训练 (Med-VLP) 领域,利用大模型自动解析三维CT扫描是一项关键的临床应用研究。
目前的挑战在于:真实CT病灶具有极强的空间稀疏性,同时长篇的医学报告由于句子分散,往往难以与医学图像中的局部解剖区域建立精确的细粒度特征对应。传统的全局**对比学习 (CL)**很难应对这种错位问题。本次解析的两篇最新论文从细粒度特征学习的角度出发,给出了创新方案:第一篇通过提取图像块的特征与句子进行相似度匹配并对齐;第二篇则通过将CT和报告解构为明确的解剖学子区域,直接执行器官级的精准识别。这两种方法均在多种下游医学分类和分割任务中取得了优异的性能表现。
我整理了医学分类+预训练大模型方向相关论文合集,感兴趣的dd!希望能帮到你
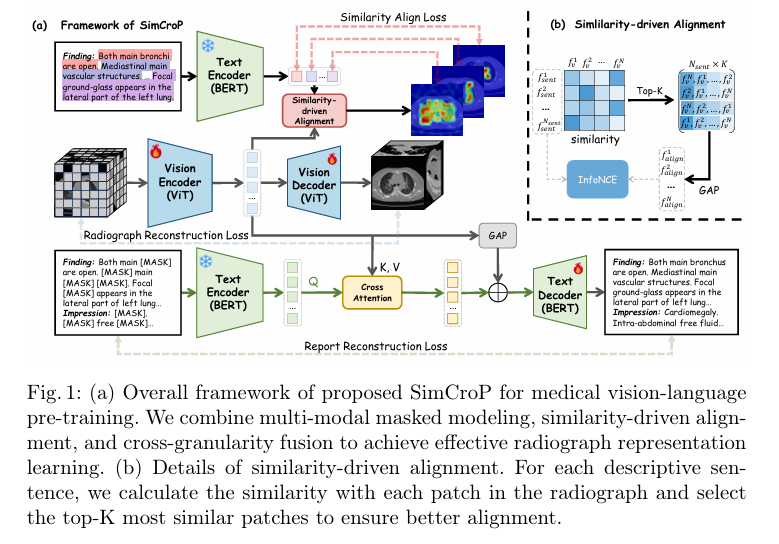
一、论文1:MICCAI 2025 SimCroP: Radiograph Representation Learning with Similarity-driven Cross-granularity Pre-training
方法:
-
本文提出了一个多模态框架SimCroP。首先通过多模态掩码建模 (MIM)提取底层语义;接着利用相似性驱动对齐 (SA) 技术,自适应地选择与报告病理句子具有最高相关性的三维图像块,将文本拉近相应的视觉子区域空间。
-
随后采用跨粒度融合设计,聚合实例级与词-块级别的特征重建报告。模型整体优化的核心损失函数如下:
创新点:
-
无需人工定位标注的自适应对齐:巧妙借助自动挖掘"报告句子"与"图像切块"的高置信度关联,成功克服了3D CT医学图像复杂的空间稀疏性问题。
-
层级特征融合机制:系统将局部精细解剖结构的特征(词-块级)和整体视角(实例级池化)融为一体,显著提升了多尺度病灶分类与分割的能力。
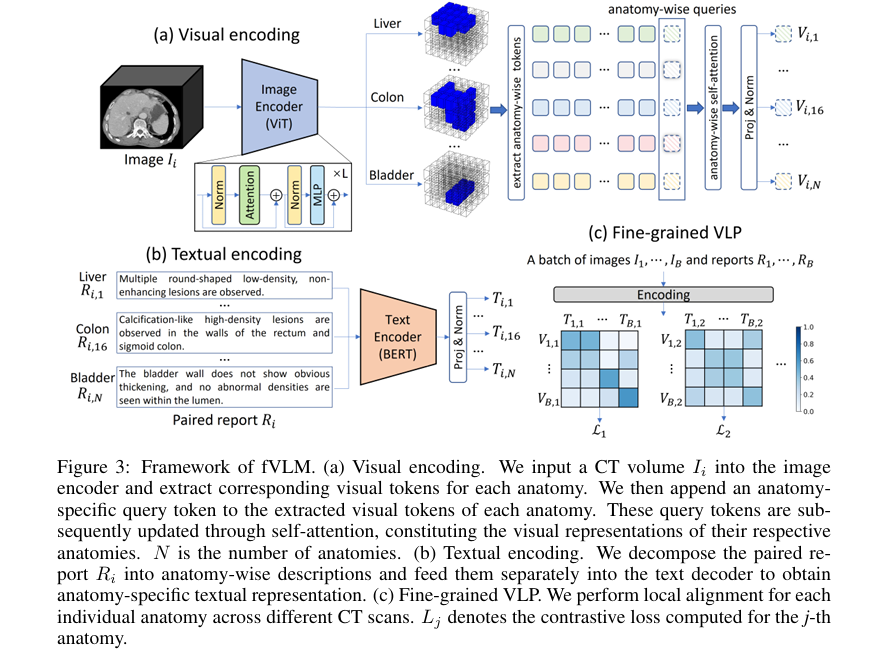
二、论文2:ICLR 2025 LARGE-SCALE AND FINE-GRAINED VISION-LANGUAGE PRE-TRAINING FOR ENHANCED CT IMAGE UNDERSTANDING
方法:
-
本研究构建了细粒度视觉-语言模型 (fVLM) 。将CT图像分割并与医疗"发现"和"印象"文本同时解构到具体的器官/解剖学层级,进行解剖部位的局部对比预训练。
-
为了解决同一批次遇到同种疾病导致的"假阴性"冲突,运用了由正常及异常样本引导的双重假阴性减少机制,并使用协同教学通过另一模型预测的概率向量来动态校正对齐目标:
创新点:
-
解剖层级特征精细对齐:彻底摒弃了主流的"整图-全篇报告"粗放匹配方案,极大地减少了医学多模态学习中的特征错位,提升了诊断可解释性。
-
独创的双重假阴性消除与海量数据验证 :自建并扩展了史上最大规模的CT分析数据集(MedVL-CT69K),配合创新的动态标签校正策略,全面刷新了54项重要疾病分类的零样本 (Zero-shot) 预测新纪录。