Talk is cheap, let's explore。无界探索,有术而行。

中国开源大模型三国杀
中国开源大模型三国杀
今天,我在帮团队做技术选型时遇到了一个难题。
项目需要使用 OpenClaw,聊天工具初步选择了飞书,但是模型这块让我犯难了,按理说应该用地表最强 Claude,退而求其次也是 GPT-5.3。但是,团队倾向于用国产开源方案:毕竟数据安全是硬指标,而且三个主流选手各有各的说法:
GLM-5 说自己编程能力对标 Claude Opus 4.5;MiniMax-M2.1 拿出 VIBE Benchmark 数据,Web 开发 91.5 分;Kimi-K2.5 则强调原生多模态和 Agent Swarm 架构。
说实话,光看各家宣传材料,很难判断谁更适合我们的场景。所以我花了一周时间,把这三个模型的官方文档、技术报告、测评数据翻了个遍,还真的发现了一些有意思的东西。
这篇文章,就是我想分享给同样在做技术选型的你的参考答案。
三大模型核心参数:先看硬指标
先说结论:这三个模型走的技术路线完全不同。
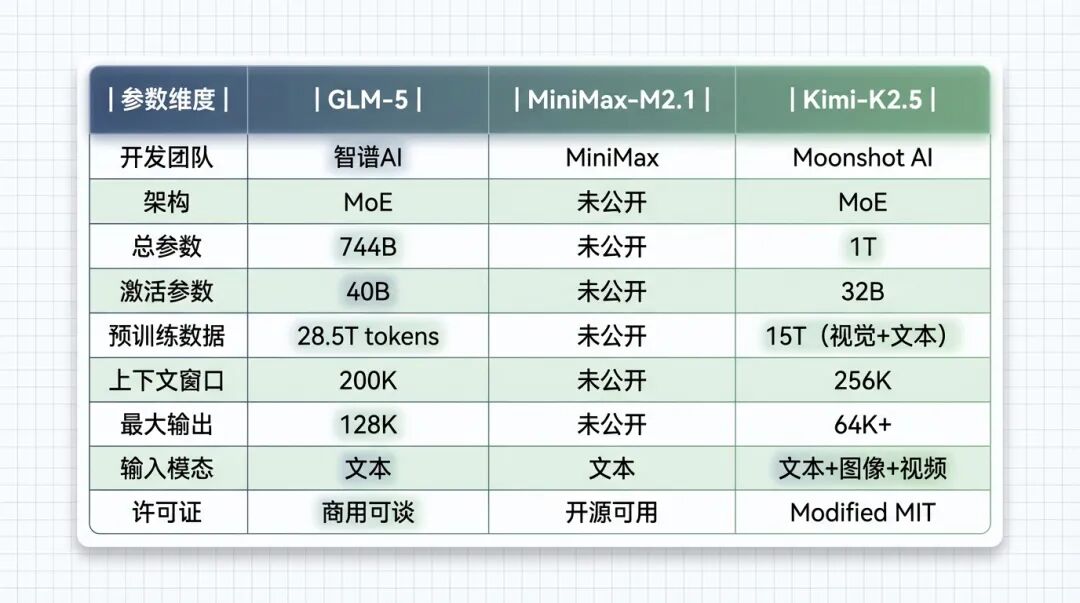
| 参数维度 | GLM-5 | MiniMax-M2.1 | Kimi-K2.5 |
|---|---|---|---|
| 开发团队 | 智谱AI | MiniMax | Moonshot AI |
| 架构 | MoE | 未公开 | MoE |
| 总参数 | 744B | 未公开 | 1T |
| 激活参数 | 40B | 未公开 | 32B |
| 预训练数据 | 28.5T tokens | 未公开 | 15T(视觉+文本) |
| 上下文窗口 | 200K | 未公开 | 256K |
| 最大输出 | 128K | 未公开 | 64K+ |
| 输入模态 | 文本 | 文本 | 文本+图像+视频 |
| 许可证 | 商用可谈 | 开源可用 | Modified MIT |
三大模型参数对比
三大模型参数对比
几个值得关注的点:
GLM-5 是参数最激进的------744B 总参数,40B 激活,预训练用了 28.5T tokens。这个数据量比很多闭源模型都大。它还首次集成了 DeepSeek 的稀疏注意力机制,号称能降低部署成本。
Kimi-K2.5 的架构设计很有意思------1T 参数,384 个专家,每个 token 只激活 8 个专家。更关键的是,它是三个模型中唯一支持原生多模态的,在 15 万亿混合视觉和文本 tokens 上做了预训练。
MiniMax-M2.1 比较神秘,官方没公开具体的参数规模,但从它的定位------"专为真实世界复杂任务打造"------来看,应该是针对 Agent 场景做了大量优化。
老实说,参数数字只是参考,真正重要的是实际表现。下面我分两个核心场景来说说实测对比。
编程能力深度对比:谁能真正帮你写代码?
我们团队的需求很明确:通过 openclaw 网关接入 AI 编程能力,让它能处理前端重构、后端调试、长程任务这几种场景。
先看基准测试数据:
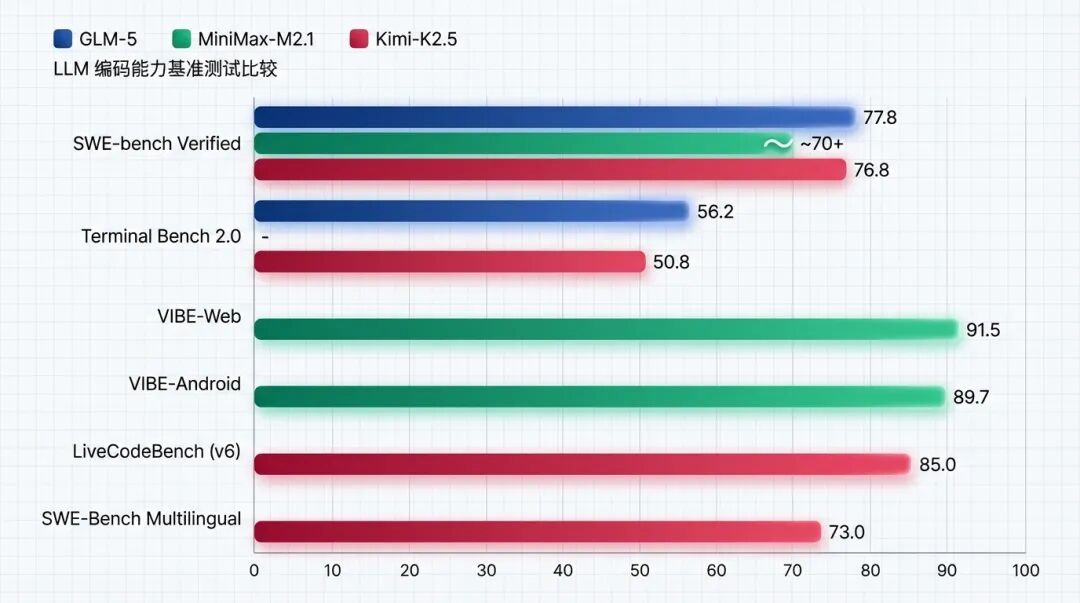
| 基准测试 | GLM-5 | MiniMax-M2.1 | Kimi-K2.5 | 备注 |
|---|---|---|---|---|
| SWE-bench Verified | 77.8 | ~70+ | 76.8 | 真实代码问题修复 |
| Terminal Bench 2.0 | 56.2 | - | 50.8 | 终端命令执行 |
| VIBE-Web | - | 91.5 | - | Web 开发专项 |
| VIBE-Android | - | 89.7 | - | 原生 Android |
| LiveCodeBench (v6) | - | - | 85.0 | 实时编程测试 |
| SWE-Bench Multilingual | - | - | 73.0 | 多语言编程 |
编程能力对比
编程能力对比
GLM-5 在 SWE-bench Verified 上拿了 77.8 分,Terminal Bench 2.0 是 56.2,两个都是开源 SOTA。官方的说法是"真实编程场景使用体感逼近 Claude Opus 4.5"。
我注意到一个细节:GLM-5 的内部评估显示,它在后端重构 和深度调试场景下,能以极少的人工干预自主完成任务。这个对我们这种需要长期维护老项目的团队来说,价值很大。
MiniMax-M2.1 的强项在多语言编程。它系统性地增强了 Rust、Java、Golang、C++、Kotlin、Objective-C、TypeScript、JavaScript 等语言能力。VIBE Benchmark 显示,它在 Web 开发(91.5)和 Android 开发(89.7)上表现突出。
有个数据挺有意思:MiniMax 官方拿它和 Claude Sonnet 4.5 做对比,在测试用例生成 、代码性能优化 、代码审查 、指令遵循这四个维度上,都显示"提升"。
Kimi-K2.5 的独特优势在视觉编程。它能从 UI 设计稿直接生成代码------这个能力在我们团队的前端开发中特别实用。SWE-Bench Multilingual 73.0 的分数,说明它的多语言能力也不弱。
我的判断:
如果你的场景是全栈 Web/App 开发 ,MiniMax-M2.1 的 VIBE 数据很亮眼;如果重点是后端重构和长期维护 ,GLM-5 的 SWE-bench 表现更稳;如果经常需要从设计稿生成代码,Kimi-K2.5 的视觉编程能力会是加分项。
智能体能力对比:谁能真正执行复杂任务?
openclaw 作为一个多渠道 AI Agent 网关,对模型的 Agent 能力要求很高。我们希望模型能处理长程任务、调用工具、协调多个子任务。
先看测试数据:
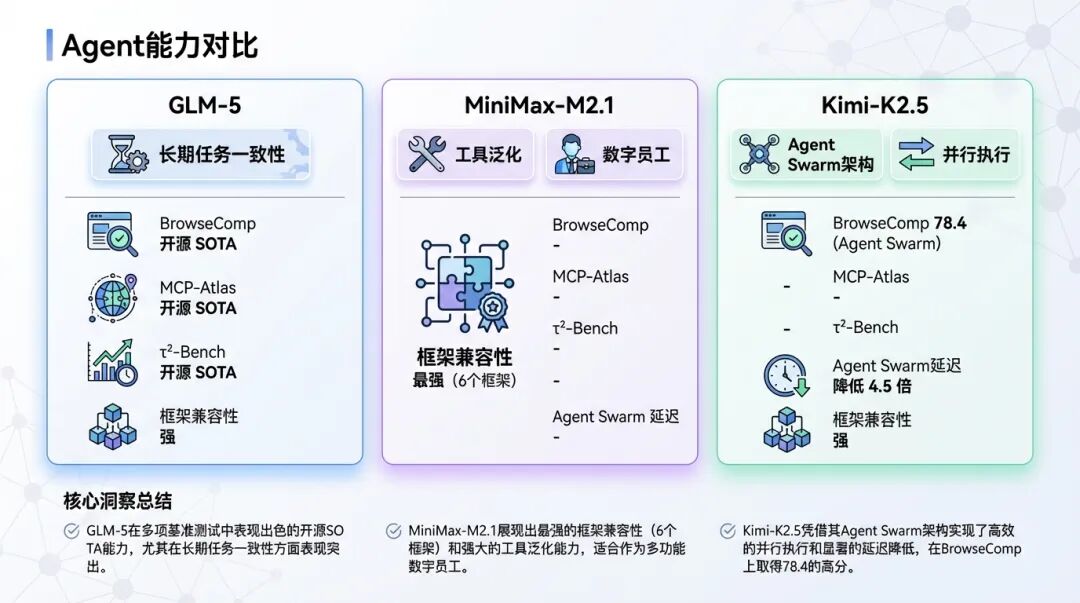
| 基准测试/能力维度 | GLM-5 | MiniMax-M2.1 | Kimi-K2.5 |
|---|---|---|---|
| BrowseComp | 开源 SOTA | - | 78.4(Agent Swarm) |
| MCP-Atlas | 开源 SOTA | - | - |
| τ²-Bench | 开源 SOTA | - | - |
| Agent Swarm | - | - | 延迟降低 4.5 倍 |
| 框架兼容性 | 强 | 最强 | 强 |
Agent能力对比
Agent能力对比
GLM-5 在 Agent 基准测试上表现抢眼------BrowseComp(联网检索)、MCP-Atlas(工具调用)、τ²-Bench(复杂多工具场景)都是开源 SOTA。官方强调它在长程任务中能保持目标一致性,这对我们的场景很重要。
MiniMax-M2.1 的亮点在工具泛化能力。官方列出了它在 6 个主流 Agent 框架中的兼容性:
| 框架 | 兼容性 |
|---|---|
| Claude Code | ✅ 稳定 |
| Cline | ✅ 稳定(平台热门模型) |
| Droid (Factory AI) | ✅ 稳定 |
| Kilo Code | ✅ 稳定 |
| Roo Code | ✅ 稳定 |
| BlackBox | ✅ 稳定 |
Cline CEO 的评价很有代表性:"Minimax M2 系列在 Cline 平台上迅速成为热门模型之一。"
MiniMax 还有一个Digital Employee(数字员工)功能,能通过文本命令控制鼠标点击和键盘输入,实现办公自动化。这个能力如果用在 openclaw 上,可以让 Agent 直接操作桌面软件。
Kimi-K2.5 的创新点在Agent Swarm(代理群)架构。它的思路是:把复杂任务分解为异构子问题,动态实例化领域特定代理,并行执行子任务。
数据很能说明问题:
- BrowseComp 单代理:60.6
- BrowseComp 单代理 + 上下文管理:74.9
- BrowseComp Agent Swarm:78.4
更关键的是,Agent Swarm 把延迟降低到了单代理基线的 4.5 倍。这意味着复杂任务的响应速度会明显提升。
我的判断:
如果你的场景是单代理长程任务 (比如持续监控、日志分析),GLM-5 的目标一致性更强;如果需要跨框架迁移 (比如先在 Claude Code 测试,再迁移到 Cline),MiniMax-M2.1 的兼容性最好;如果任务是高并发复杂任务(比如同时处理多个用户的请求),Kimi-K2.5 的 Agent Swarm 架构会更有优势。
openclaw 平台选型实战:代码怎么写?
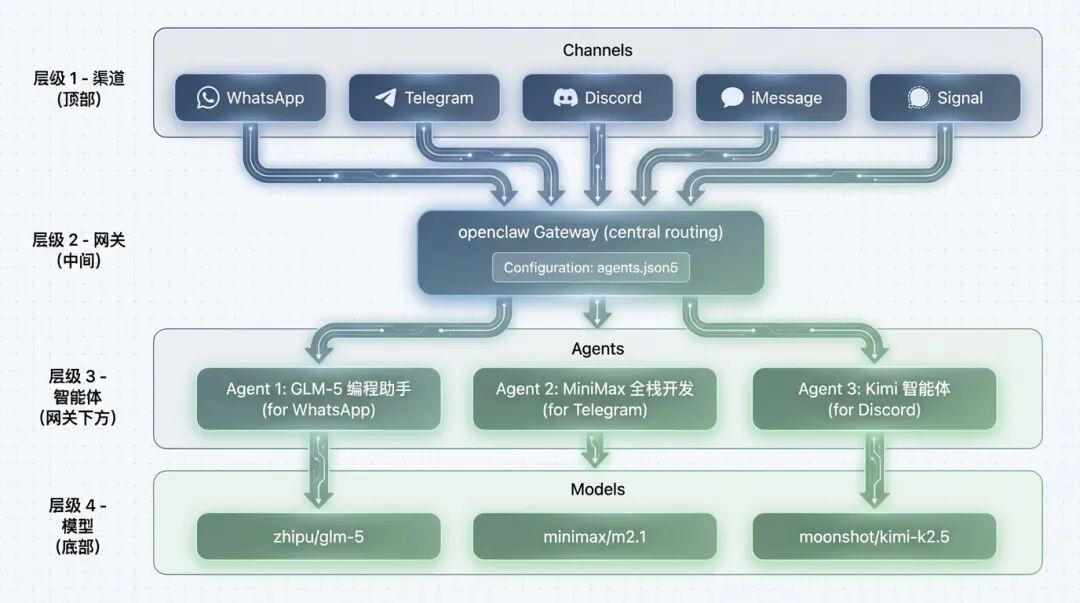
说了这么多理论,来看点实际的。openclaw 是一个自托管 AI Agent 网关,支持 WhatsApp、Telegram、Discord、iMessage、Signal 、飞书、企业微信、钉钉等多个渠道。
安装和启动# macOS/Linux** curl -fsSL https://openclaw.ai/install.sh | bash # Windows (PowerShell) iwr -useb https://openclaw.ai/install.ps1 | iex # 安装并配置 openclaw onboard --install-daemon # 检查 Gateway 状态 openclaw gateway status # 打开控制面板 openclaw dashboard
配置多个模型代理
openclaw 支持配置多个隔离的代理,每个代理可以使用不同的模型:{ agents: { list: [ { id: "glm5-coding", name: "GLM-5 编程助手", workspace: "~/.openclaw/workspace-glm5", model: "zhipu/glm-5", }, { id: "minimax-fullstack", name: "MiniMax 全栈开发", workspace: "~/.openclaw/workspace-minimax", model: "minimax/m2.1", }, { id: "kimi-agent", name: "Kimi 智能体", workspace: "~/.openclaw/workspace-kimi", model: "moonshot/kimi-k2.5", }, ], }, bindings: [ // WhatsApp 用 GLM-5 处理编程问题 { agentId: "glm5-coding", match: { channel: "whatsapp" } }, // Telegram 用 MiniMax 处理全栈开发 { agentId: "minimax-fullstack", match: { channel: "telegram" } }, // Discord 用 Kimi 处理复杂任务 { agentId: "kimi-agent", match: { channel: "discord" } }, ], }
openclaw架构图
openclaw架构图
不同场景选型建议:我的推荐
说了这么多,最后给你一个明确的选型建议。我按场景来分:
场景 1:Agentic Coding(智能编程)
| 优先级 | 模型 | 理由 |
|---|---|---|
| 🥇 | GLM-5 | 编程能力开源 SOTA,真实场景体感逼近 Claude Opus 4.5 |
| 🥈 | MiniMax-M2.1 | 多语言编程强,框架兼容性好 |
| 🥉 | Kimi-K2.5 | 视觉编程独特,Agent Swarm 提升效率 |
我的推荐:如果你的团队主要做后端开发和代码重构,GLM-5 是更稳的选择。
场景 2:Web/App 全栈开发
| 优先级 | 模型 | 理由 |
|---|---|---|
| 🥇 | MiniMax-M2.1 | VIBE-Web 91.5,Android 89.7,美学表达强 |
| 🥈 | Kimi-K2.5 | 视觉编程能力强,从设计稿生成代码 |
| 🥉 | GLM-5 | 前后端开发能力稳定 |
我的推荐:如果你的项目涉及大量前端和移动端开发,MiniMax-M2.1 的 VIBE 数据更有说服力。
场景 3:智能体任务执行
| 优先级 | 模型 | 理由 |
|---|---|---|
| 🥇 | Kimi-K2.5 | Agent Swarm 延迟降低 4.5 倍,并行任务执行 |
| 🥈 | GLM-5 | 长程 Agent 任务开源 SOTA,目标一致性强 |
| 🥉 | MiniMax-M2.1 | Digital Employee 办公自动化,工具泛化能力强 |
我的推荐:如果你的场景是高并发、多任务并行,Kimi-K2.5 的 Agent Swarm 架构优势明显。
场景 4:视觉任务(图像/视频理解)
| 优先级 | 模型 | 理由 |
|---|---|---|
| 🥇 | Kimi-K2.5 | 原生多模态,15T 视觉+文本 tokens 预训练 |
| 🥈 | GLM-5 | 文本模型,视觉能力有限 |
| 🥉 | MiniMax-M2.1 | 文本模型,视觉能力有限 |
我的推荐:如果涉及图像或视频输入,Kimi-K2.5 是唯一选择。
场景 5:框架迁移和兼容性测试
| 优先级 | 模型 | 理由 |
|---|---|---|
| 🥇 | MiniMax-M2.1 | 6 个主流框架兼容,表现稳定 |
| 🥈 | GLM-5 | 主要框架兼容 |
| 🥉 | Kimi-K2.5 | 主要框架兼容 |
我的推荐:如果你需要在不同 Agent 框架之间迁移,MiniMax-M2.1 的兼容性更让人放心。
综合评分:谁才是真的王者?
我把三个模型按 6 个维度做了个综合评分:
| 维度 | 权重 | GLM-5 | MiniMax-M2.1 | Kimi-K2.5 |
|---|---|---|---|---|
| 编程能力 | 25% | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Agent 能力 | 25% | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 多模态 | 15% | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 上下文长度 | 10% | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 部署便捷性 | 10% | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 框架兼容性 | 10% | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
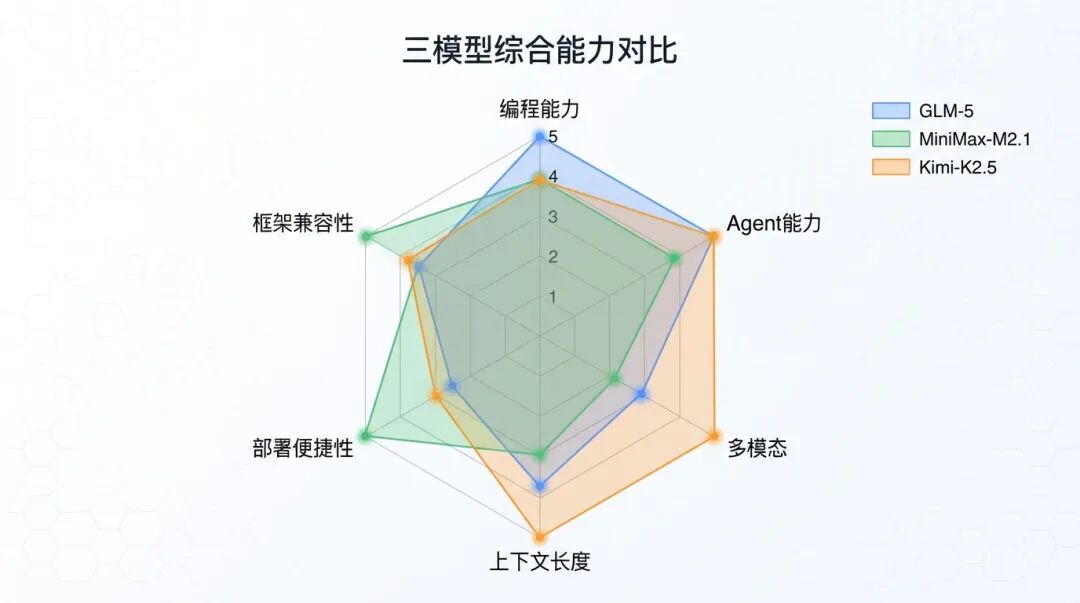
综合评分雷达图
综合评分雷达图
我的结论:
没有绝对的王者,只有最适合的选择。
- 编程能力优先 → 选 GLM-5
- Web/App 开发优先 → 选 MiniMax-M2.1
- 视觉任务/Agent 并发优先 → 选 Kimi-K2.5
对我自己的团队来说,我们的选择是组合使用:飞书机器人1 用 GLM-5 处理编程问题,飞书机器人2 用 MiniMax-M2.1 也做通用全栈开发,飞书机器人3 用 Kimi-K2.5 处理复杂任务、写文档。
openclaw 的多代理路由功能,让这种组合方案变得可行。
踩坑提醒:我遇到过的那些坑
老实说,选型只是第一步,真正用起来还会遇到不少坑。这里分享几个我踩过的:
坑 1:API 调用成本没算清楚
一开始我只看了单次调用成本,觉得三个模型都差不多。结果上线后发现,GLM-5 的思考模式(Thinking Mode)会消耗大量 token------有时候一个复杂任务能消耗掉普通模式 5 倍的 token。
教训:上线前一定要做成本估算,尤其是长程任务和高频调用场景。
坑 2:框架兼容性不是"完全兼容"
MiniMax-M2.1 虽然号称兼容 6 个主流框架,但实际用起来还是有坑。比如在 Cline 里,某些高级功能(比如流式输出的复杂控制)会失效。
教训:"兼容"不等于"功能完全一致",上线前一定要做完整的功能测试。
坑 3:多模态能力的边界没搞清
Kimi-K2.5 的多模态能力很强,但不是万能的。我们试过让它处理复杂的 UI 设计稿,结果生成的代码质量参差不齐。后来发现,它对简单的设计稿效果很好,但复杂的多层级布局就有点吃力。
教训:多模态能力有边界,不要过度期待,要根据实际场景测试。
坑 4:上下文长度不是越长越好
Kimi-K2.5 的 256K 上下文确实很强,但如果真的塞满 256K,响应速度会明显下降。而且,大量的上下文信息反而会干扰模型的判断。
教训:上下文长度要合理使用,不是塞得越多越好。
坑 5:开源≠免费部署
这三个模型虽然都叫"开源",但如果你要本地部署,成本其实不低。GLM-5 的 744B 参数,光显存就需要几百 GB。MiniMax-M2.1 的参数规模虽然没公开,但从它强调"真实世界复杂任务"来看,估计也不小。
教训:开源不等于免费,部署成本要提前算清楚。
我的最终选择
说了这么多,你可能会问:那你最后选了哪个?
说实话,我们没有"只选一个"。
我们的方案是这样的:
- GLM-5:用于编程相关任务,尤其是后端重构和代码审查
- MiniMax-M2.1:用于 Web 和移动端开发,以及需要跨框架迁移的场景
- Kimi-K2.5:用于复杂的多模态任务和高并发 Agent 场景
openclaw 的多代理路由功能让这种组合方案变得可行。不同渠道、不同任务类型,自动路由到最合适的模型。
这样做的好处是什么?
- 成本优化:简单任务用便宜模型,复杂任务用强模型
- 性能优化:不同模型擅长的领域不同,各取所长
- 风险控制:一个模型出问题,不影响其他场景
当然,这种方案也有缺点:
- 运维复杂度增加
- 需要维护多套配置
- 调试和排错更困难
但对于我们这种对成本和性能都有要求的团队来说,这是最务实的方案。
相关资源
GLM-5 官方文档:https://docs.bigmodel.cn/cn/guide/models/text/glm-5
GLM-5 ModelScope:https://www.modelscope.cn/models/ZhipuAI/GLM-5
MiniMax M2.1 官方公告:https://www.minimaxi.com/news/minimax-m21
MiniMax M2.1 ModelScope:https://www.modelscope.cn/models/MiniMax/MiniMax-M2.1
Kimi-K2.5 Hugging Face:https://huggingface.co/moonshotai/Kimi-K2.5
Kimi-K2.5 ModelScope:https://www.modelscope.cn/models/moonshotai/Kimi-K2.5
Kimi K2.5 论文:https://arxiv.org/abs/2602.02276
openclaw 官方文档:https://docs.openclaw.ai
本文数据来源:各模型官方文档、技术报告、基准测试公开数据。测评数据截至 2026 年 2 月,模型能力会持续更新,建议定期关注官方动态。