超并发示例视频
通过使用 RWKV-7 的推理引擎 Albatross,我们可实现极高的"超并发"推理效率,且永远恒定速度,永远恒定显存:
| 模型 | 精度 | 批大小 (Batch Size) | 速度 token/s | 阶段 | 硬件 |
|---|---|---|---|---|---|
| RWKV-7 7.2B | fp16 | 960 | 10250+ | 生成 (Decode) | RTX5090单卡 |
| RWKV-7 7.2B | fp16 | 320 | 9650+ | 生成 (Decode) | RTX5090单卡 |
| RWKV-7 7.2B | fp16 | 1 | 145+ | 生成 (Decode) | RTX5090单卡 |
| RWKV-7 7.2B | fp16 | 1 | 11289+ | 预填充 (Prefill) | RTX5090单卡 |
基于Albatross引擎,RWKV社区开发了多个实用的配套仓库:
Alic-Li 开发了 Python 版的懒人包 rwkv_lightning 和 C++ 版的懒人包 rwkv_lightning_libtorch,两个懒人包的用法基本一致,区别在于实现语言和部署流程。
Molly Sophia 开发了用于 RWKV 的 nano-vllm,不仅支持和 Albatross 相同速度的输出,还可以进行 Int8 量化的模型运行,不过该仓库目前仍在开发中,可直接调用的 API 接口将在不久后更新。
Dax 开源了一个高并发生成的前端示例 RWKV_High_Concurrency,可以进行并发流式生成的压力测试和可视化展示,结合 rwkv_lightning 可以实现开篇视频中的效果。
Moment 开源了一个批量网页生成前端项目 rwkv-vibe-code 和一个批量小说生成项目 RWKV-Parallel-Novel,结合 rwkv_lightning 可以一次性生成多个网页,实现一次抽多张卡的效果。
下面我们简单介绍 rwkv_lightning 的使用方法和实现开头视频效果的方法,并展示批量网页生成和小说生成的效果。
rwkv_lightning 的部署和使用
克隆仓库
git clone https://github.com/RWKV-Vibe/rwkv_lightning.git安装依赖
rwkv_lightning 同时支持 Nvidia 和 AMD 两个平台:
Nvidia 显卡
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu130
pip install robyn pydantic ninja numpy
[可选] pip install flashinfer-pythonAMD 显卡
pip install torch torchvision --index-url https://download.pytorch.org/whl/rocm6.4
pip install robyn pydantic ninja numpy 启动应用
单 GPU 运行
python app.py --model-path <your model path> --port <your port number> --password rwkv7_7.2b多 GPU 运行
python app.py --model-path <your model path> --port <your port number> --password rwkv7_7.2b --pp-devices [0,1,2,3] 如果不需要密码,可以不添加 --password 参数。
API 调用方式
为了节省篇幅,我们在此处仅介绍一个 API 端口调用方式,更多的调用方式可以参考 RWKV 中文官网教程:https://www.rwkv.cn/tutorials/intermediate/rwkv_lightning
调用端口:big_batch/completions
调用方法示例:
curl -X POST 'http://localhost:8000/big_batch/completions' \
--header 'Content-Type: application/json' \
--data '{
"contents": [
"English: That night, a bolt of lightning splits the same chestnut tree under which Rochester and Jane had been sitting that evening.\n\nChinese:",
"English: That night, a bolt of lightning splits the same chestnut tree under which Rochester and Jane had been sitting that evening.\n\nChinese:"
],
"max_tokens": 1024,
"stop_tokens": [0, 261, 24281],
"temperature": 1.0,
"chunk_size": 8,
"stream": true,
"password": "rwkv7_7.2b"
}'启动应用处的
--password参数为运行高并发推理前端要用到的API password,方法示例的第一行curl -X POST后的内容为前端要使用的API 地址。
对于 big_batch 端点的调用方法,解码参数和使用其他工具调用 RWKV 系列模型时一致;
进行批量推理时,要使用指定格式的批量输入,格式如方法示例中 contents 所示,使用 "" 包裹单条数据,数据间使用 , 分隔。
会得到如下格式的输出:
data: {"object": "chat.completion.chunk", "choices": [{"index": 0, "delta": {"content": "输出内容"}}]}此处的 index 参数为对应输入顺序的纯数字,content 对应模型具体的输出内容。
效果预览
下面是最新 RWKV-7 G1f 7.2B 模型,配合超并发 32 路推理,成功实现 3D 游戏效果。提示词为:
使用 Three.js 创建一个简单 3D 房间,用户可以用 WASD 控制摄像机在房间里移动。
可使用仓库根目录的 webui_rwkv.py 测试并发效果:

RWKV Concurrency Demo 的部署和视频效果的实现
安装依赖和启动
在进行本步骤操作前,请确定运行该项目的设备已经完成了 Node.js 的配置,然后再逐个运行下列指令:
git clone https://github.com/DaxYang-03/RWKV_High_Concurrency
npm install
npm run dev此时可以通过地址http://localhost:3000打开前端界面。
API 配置
首先我们需要安装上面的 rwkv_lightning 获得 API 地址和 API password。
API 地址为 rwkv_lightning 的调用方法示例 第一行的 POST 后面的内容,API password 为启动应用 时设置的 --password 对应的内容。
然后,需要给项目配置 API 地址和 API password,我们可以在如下图所示位置进行相关配置。
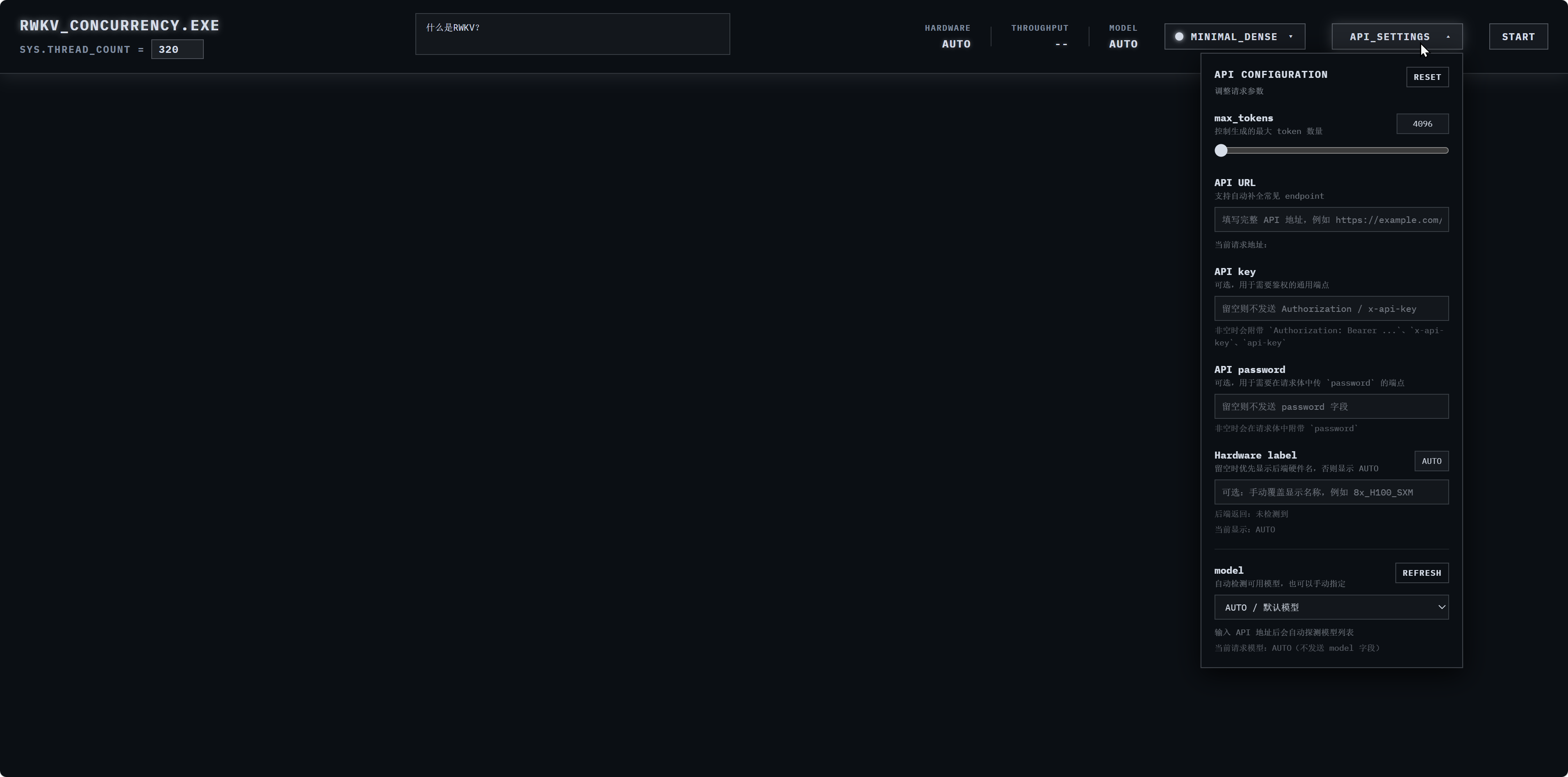
完成配置后,可以在上面的输入框进行输入,然后点击右上角的START开始批量生成。
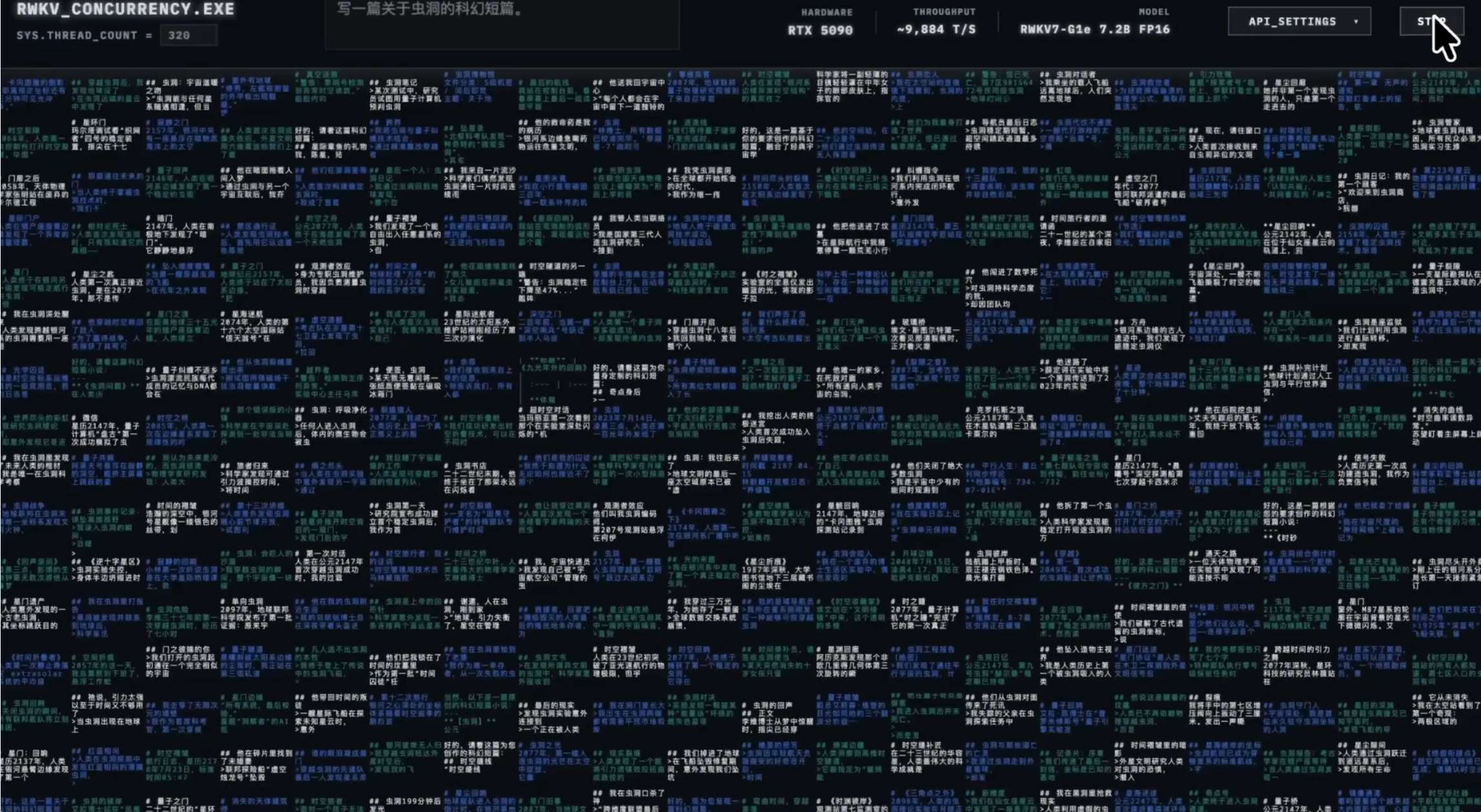
其他更多的使用和开发方法请进入项目仓库RWKV_High_Concurrency,参考项目介绍。
批量网页和小说生成效果示例
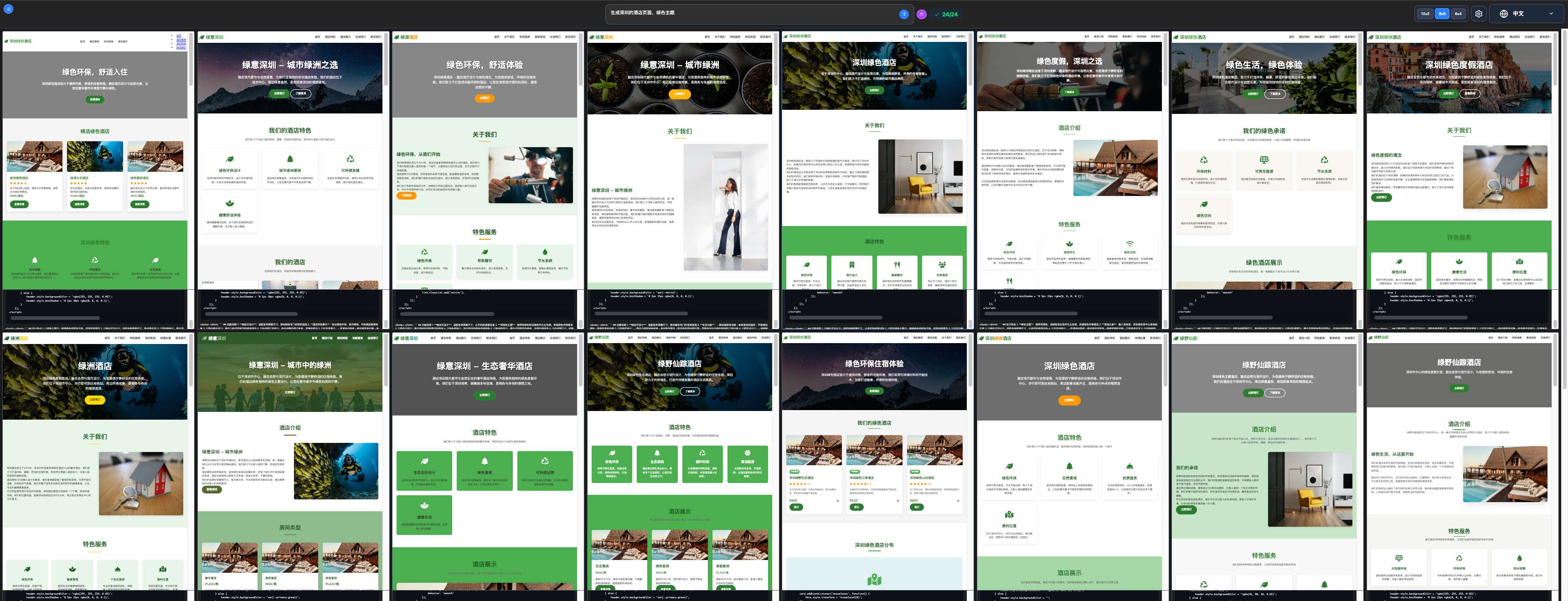
批量网页生成 rwkv-vibe-code,默认对输入的提示词快速并行生成 24 个网页,方便用户找到最佳风格:
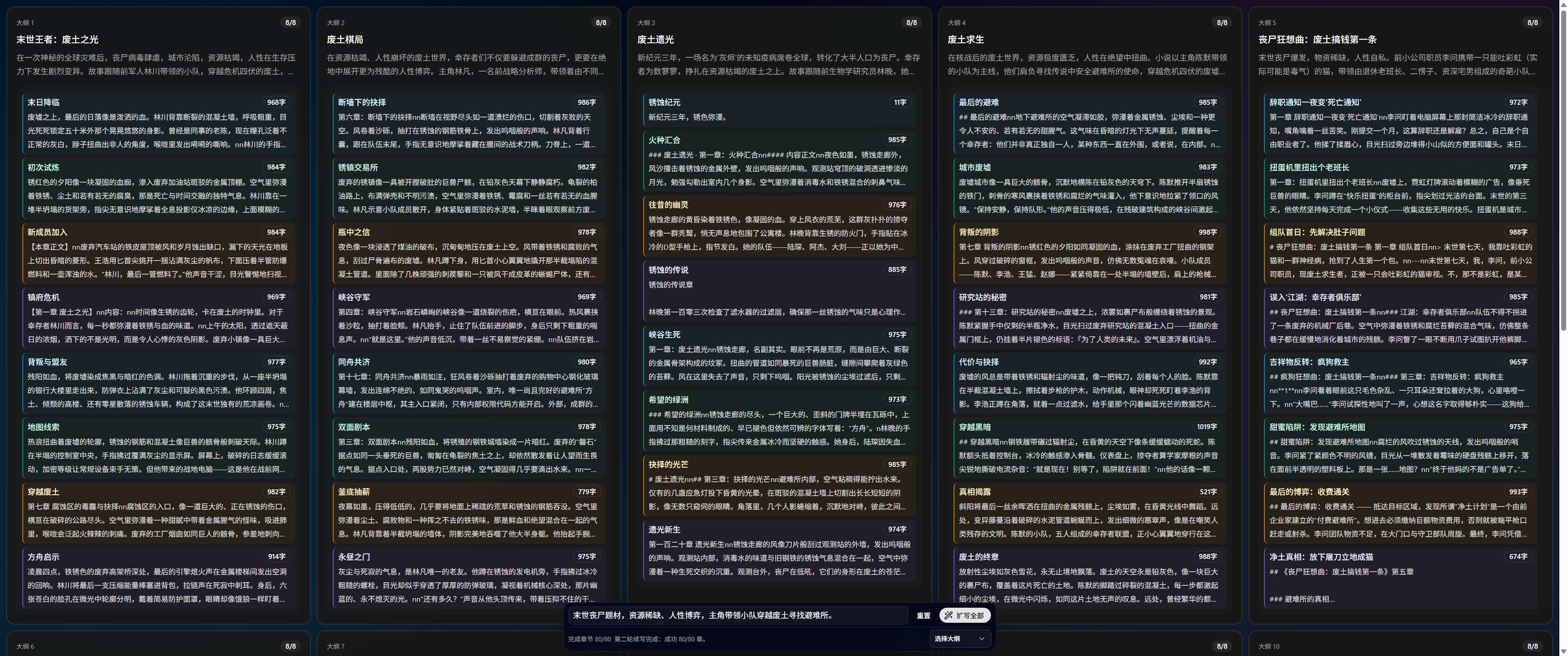
批量小说生成 RWKV-Parallel-Novel,会先生成总体大纲和章节大纲,然后再通过章节大纲快速并行生成具体章节内容,快速写出 10 个版本,每个版本 8 个章节:
RWKV-LM 的训练速度和显存优化
最近 Bo 对 RWKV-LM 进行了一轮优化,训练速度提升 40%(融合多个细碎算子),显存占用降低 40~80%(融合L2Wrap+CE+Head),且训练的精度更高,梯度更准确。
推荐各位都升级到最新版:https://github.com/BlinkDL/RWKV-LM
RWKV-LM 超并发大奖赛预告
最后,我们即将举办RWKV超并发大奖赛,下面是一些创意,欢迎大家参与,欢迎在RWKV技术群交流:
- 并行Agent(大模型拆出大量小任务,给RWKV模型并行做)
- 并行写代码(大模型将项目拆成多个模块,拆成多个函数,给RWKV模型并行写)
- 并行分析(大模型将目标拆成多个部分,给RWKV模型并行分析)
- 并行多风格问答/创作(让RWKV对于一个或多个内容,用不同风格并行回答/创作)
- 并行多角色NPC(让RWKV并行扮演几百个角色)
- 并行扩写/摘要(让RWKV并行处理大量数据)
- 并行改写(让RWKV并行处理多个文档,实现个人定制的信息流)
- 并行翻译(将文本拆成多段,让RWKV并行处理)
- 并行写小说(大模型将小说拆成多个章节,调用RWKV并行写)
- 并行做数学题(让RWKV用不同解码参数解题,然后自动投票得到更佳答案)