采无噪数据
考虑到很多去噪模型还是监督学习,如果没有噪声模型的话就需要采集noisy-clean成对数据。
ELD的制作方式相对简单,主要是通过调整ISO和长短曝以最高效的方式来制作数据集。
SIDD主要是通过多帧融合来制作数据集的,包括一套系统的去坏点、筛图、校正、对齐、融合流程。这几乎可以视作一种简明扼要的多帧raw图去噪流程了。

SIDD还有一个很关键的发现------即使把相机固定在防震的光学平台上,拍摄帧数多了仍然会存在错位,甚至在他们的实验中高达2~4 pixel!作者认为这种错位是由于手机的OIS(光学防抖)功能无法有效关闭导致的。我们在使用多台设备多种装置在多个位置复现这一现象后,发现这种错位本质上并不完全是OIS导致的。
经实验,关闭OIS在短时间内能观察到错位略有减小,而长时间下的错位则不是OIS开关的影响。范浩强做的另一个稳定性实验则隐隐戳到了这个现象的本质------这种空间错位是 不可测的环境扰动 与 手机夹的过阻尼摩擦力 共同导致的。
噪声模型
ELD提出了四个关键的噪声:shot noise, row noise, generalized read noise, and quantization noise。之前也写过噪声模型的总结。
最经典的就是泊松-高斯模型,还有它的简化版本,camera noise level functions (NLF)。Heteroscedastic (异方差的)是统计学和计量经济学中的一个术语,用于描述误差项或随机变量的方差不是常数,而是随着解释变量(自变量)的变化而变化的现象。NLF (异方差高斯模型Heteroscedastic),它认为图像中的噪声不是固定不变的(同方差),而是随着图像亮度的变化而变化的(异方差)。
NLF和泊松-高斯模型相比,假设噪声仅仅是高斯分布的,且方差只由亮度决定,并且忽略了泊松分布在低光下的非高斯特性(偏斜性),这里还是以泊松-高斯模型为主:
考虑到digital gain和anlog gain,最终得到的信号D可以写成:
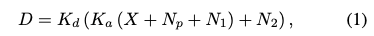
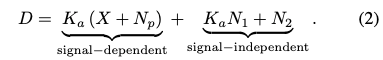
N_p就是泊松噪声,和信号紧紧相关。
N1和N2的区别就是N1经过了K_a的放大,是ADC之前就有的暗噪声和热噪声,dark-current noise and thermal noise
N2是ADC之后产生的读出噪声和量化噪声,read-out circuits, and quantization noise resulted from bit-depth adjustment
对于泊松噪声,需要通过K_a把图像像素值和光子数X联系到一起:
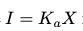
这样泊松分布就可以写成:
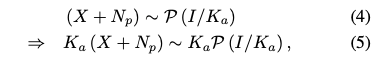
所以关键问题就是如何得到K_a,它是一个增益系数,和iso有关,一般通过使用ISO-15739色卡,标定得到各个iso的K_a值。可不可以跳过标定的阶段呢?这就需要两点进一步的观察
信号相关
K怎么得到呢,不同的iso对应一个K。因为I=KX,通常的做法是在指定iso下,画出不同厚度值对应的raw值,斜率就是K。
如果是在原始raw上做的斜率标定,10bit的话,原始raw的范围最大值是1024,那么在对0~1浮点数加噪声时,对应的slope要除以1024,bias对应的是信号无关的方差,信号无关=K*N1+N2,所以bias要除以(1024*1024)。但其实最好的做法是把clean data转成1024的范围,这样更符合物理,而不是去缩放sclae和bias。
K实际上又两部分构成,quantum efficiency (QE) and the analog gain (AG) ,前者由材料学限制,后者是用户设置的。QE估计工艺的不同,波动在30%到70%之间,所以当AG固定后,K的范围就差不多固定了,上下限不会超过2倍。
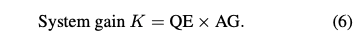
还有个重要的观察那就是K其实只影响信号相关部分的方差,而不影响均值:
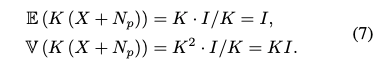
所以可以直接假设QE=0.5,来估计得到K,这样加噪声获得的图像虽然K不准确,但是仍然和clena raw的亮度是一致的,所以这样训练的网络不会学习到亮度改变,并且K的不准确可以看作是一种数据增广。
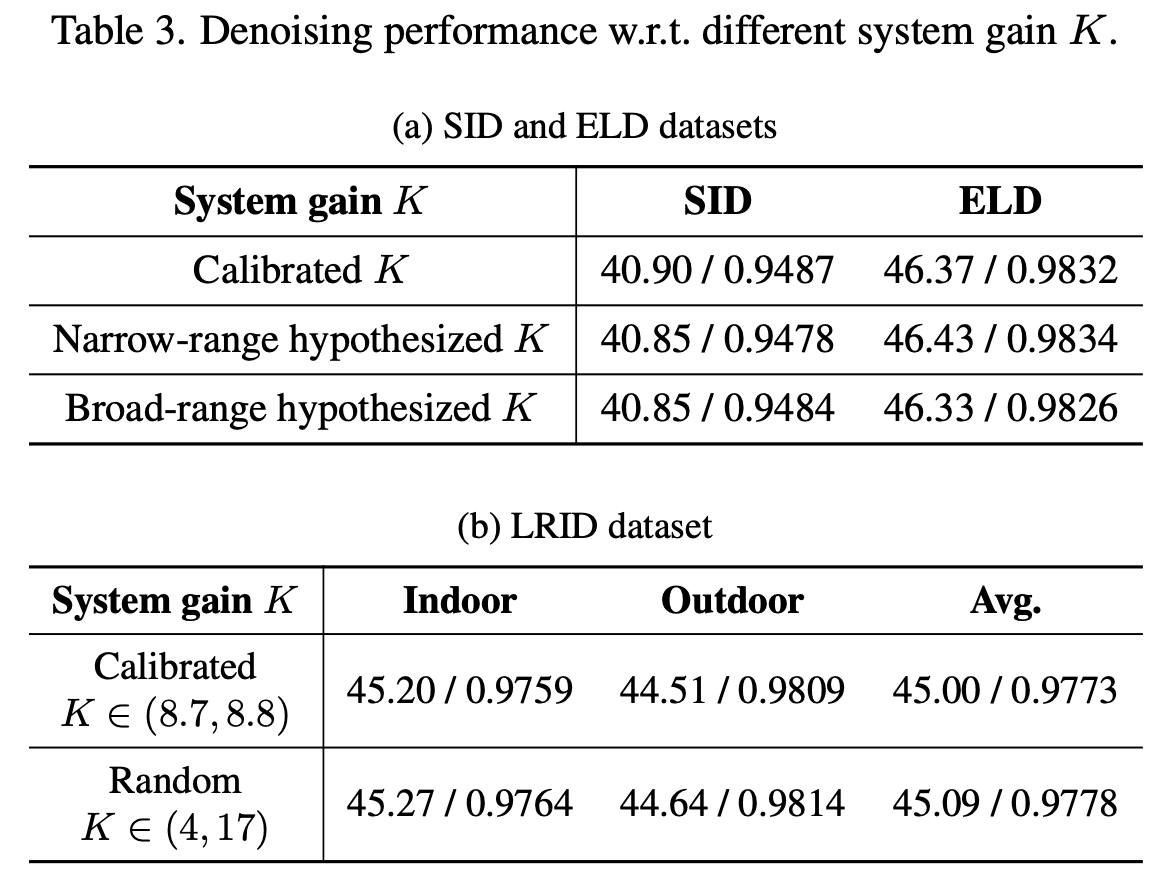
听起来有点离谱,看实验确实是这样,不管使用标定好的还是随机的K,结果相差不大:
在这里假设QE已知,所以只需要知道模拟增益 (Analog Gain, AG)
公式 :AG = ISO / BaseISO 计算的就是这个。
含义 :它表示传感器内部电路对信号的相对放大倍数。
基准点:在最低原生 ISO(即 BaseISO)时,模拟增益确实为 1(或 0dB),意味着信号没有被额外放大。
索尼文章在4.1章节提到,AG=1时iso=400,那么当QE=0.4时,iso/400*0.4就是K,换算一下,K=iso/100*0.1
we empirically investigate their characteristics and find that both cameras have their base
ISOs (i.e., AG = 1) around 400. To this end, we employ an empirical approximation equation for the system gain K: K = ISO/100 ∗0.1, representing a hypothesized QE of
40%.
AG=1时的iso就是BaseISO ,绘制 ISO 值 vs. 饱和曝光量 的曲线。
转折点即为 Base ISO: 你会发现,在低 ISO 段,饱和曝光量可能保持不变(这通常是数字增益区域);当 ISO 增加到某一点后,饱和曝光量开始随 ISO 增加而线性下降(这是模拟增益区域)。这个转折点通常就是模拟增益 AG=1AG=1 的位置。
文章中说的QE应该指的是归一化之前的raw的转换效率,但是我看到有的sensor其实只有10%的转换效率。
安卓手机的raw,可以通过exiftool 查看 DNG 文件:
exiftool image.dng | grep -i gain查找字段如 AnalogGain 或 BaselineExposure。注意:有些厂商只记录 ISO,AG 需要查表
信号无关
对于信号无关的噪声,需要先计算多个黑帧的平均值,作为Calibrated dark shading。这是完全和信号无关的底噪,包括
- 热噪声 (Thermal Noise):电子的热运动。
- 暗电流 (Dark Current):像素在无光情况下自发产生的电荷积累。
- 固定图案噪声 (FPN, Fixed Pattern Noise):由于制造工艺不完美,每个像素对"无光"状态的响应不一致(有的像素天生就比别的亮一点或暗一点)。
这些噪声通常是时间上一致的 (Temporally Consistent):即在相同的曝光时间、温度和增益(ISO/AG)设置下,传感器上同一个位置的噪声值是基本固定的。
黑帧采样
在商汤ICCV2021的文章中,直接对黑帧采样得到信号无关的噪声:
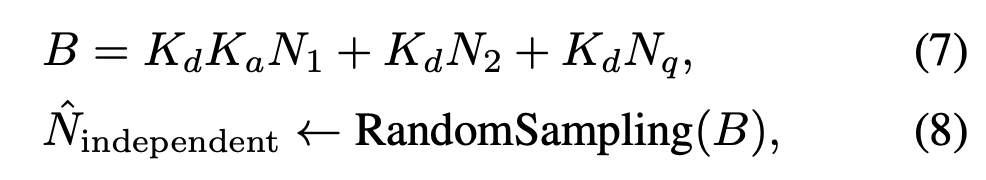
黑帧指定了iso,但是曝光参数是自动的。和泊松噪声一起合成噪声:
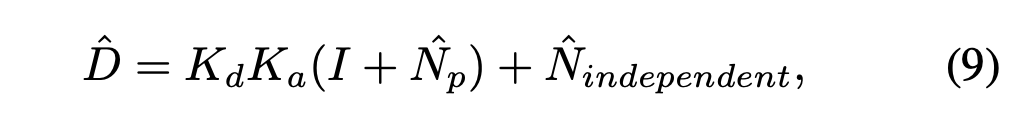
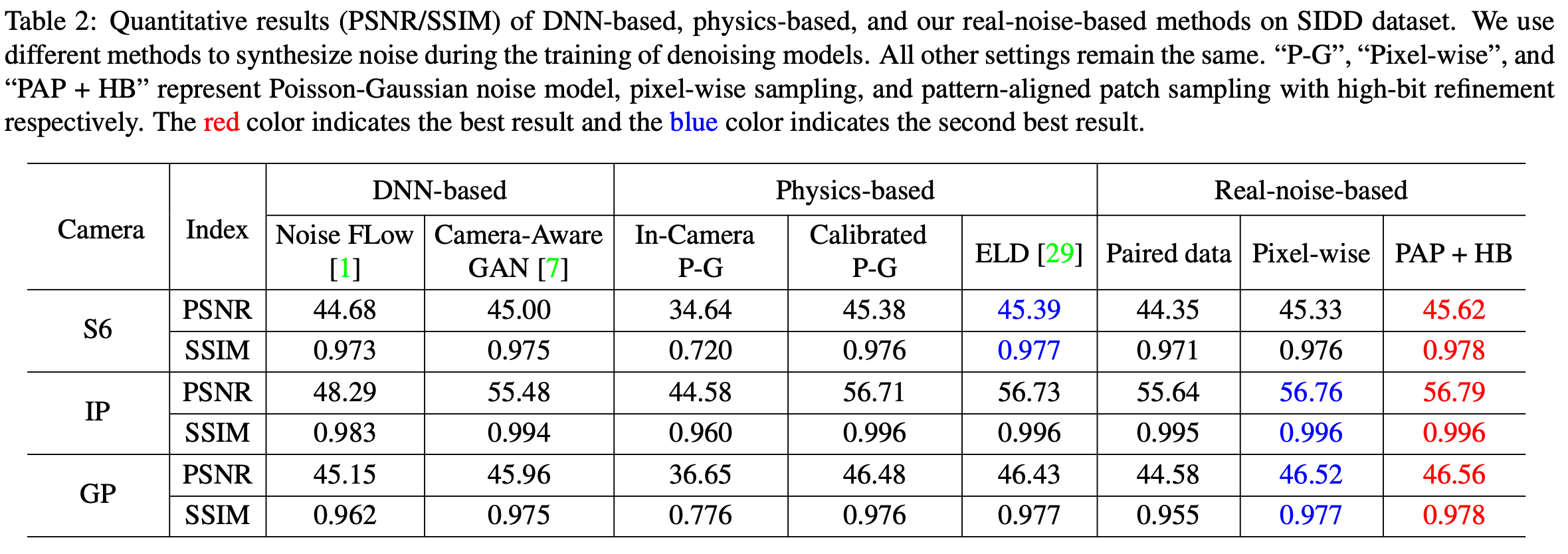
虽然在普通场景下好于ELD noise model,但是在极暗场景下还是比较差,原因可能是暗噪声被采样破坏掉了,直接采样也破坏了噪声的spatially-correlated特性。
应对这两个问题,所以提出了High-bit reconstruction和pattern-aligned patch sampling (PAP)
不是对每个ISO都采样,而是对log2(iso)等间隔采样,
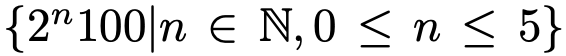
物理规律:ISO 每增加一倍(例如从 100 到 200),模拟增益(Analog Gain)通常也增加一倍。
- 线性采样(100, 200, 300...)的问题:在低 ISO 区间(100-200),增益变化剧烈,噪声特性变化快,需要采点;但在高 ISO 区间(比如 25600 到 25700),虽然数值增加了 100,但相对于基数来说增益几乎没变,噪声特性也没变,采这个点是浪费存储和计算资源。
- 对数采样(100, 200, 400, 800...) :保证了每个采样点之间的增益倍数间隔是固定的,从而能最高效地描绘出噪声随增益变化的曲线。
- 误区,高iso时往往场景更暗,iso高的时候采样密集一点更好。低 ISO(Base ISO) :传感器的模拟增益(Analog Gain)非常低(比如 1x)。此时,电路底噪(Read Noise)、暗电流的非线性、ADC 的量化误差,相对于满阱容量来说非常微小且难以捕。高 ISO(比如 6400+) :传感器的模拟增益已经非常大(比如 32x)。此时,信号和噪声都被放大了几十倍。原本微小的电路噪声已经被"淹没"在巨大的信号波动中,或者已经被放大器"拉"到了线性区。高 ISO 密集采样 ,你会发现采集回来的 10 张黑帧,除了亮度(方差)不同,统计特征几乎是一模一样的直线。这就是数据冗余。
对ISO采样后,每个iso采集10个黑帧。因为iso没有覆盖到所有的iso,这意味着有的iso没有对应的黑帧,这时候可能需要插值,因为方差是一样的,只有亮度的区别。但是插值的时候注意不能安装iso去线性插值,iso3200和iso6400是2倍的关系,和3200,6400本身无关,所以要取log2转换到dB上去计算:
import numpy as np
# 1. 定义 ISO 值
iso_start = 3200
iso_end = 6400
iso_target = 4000
# 2. 计算对数域权重 (关键步骤)
# 将 ISO 比值转换为 dB
db_start = 20 * np.log10(iso_start / iso_start) # 0
db_end = 20 * np.log10(iso_end / iso_start) # ~6.02
db_target = 20 * np.log10(iso_target / iso_start) # ~1.94
# 计算插值系数 alpha
alpha = (db_target - db_start) / (db_end - db_start)
print(f"ISO 4000 的权重系数 alpha: {alpha:.3f}")
# 输出约为 0.322,说明它更靠近 3200
# 3. 估算黑电平 (均值)
# 假设 mean_3200 和 mean_6400 是黑帧的平均值或黑电平图
mean_4000 = (1 - alpha) * mean_3200 + alpha * mean_6400
# 4. 估算噪声强度 (标准差)
# 注意:要在方差域(功率)进行插值,而不是标准差域
var_3200 = np.var(noise_3200)
var_6400 = np.var(noise_6400)
var_4000 = (1 - alpha) * var_3200 + alpha * var_6400
std_4000 = np.sqrt(var_4000)
print(f"估算的 ISO 4000 噪声标准差: {std_4000}")clude code的方案感觉更靠谱:
# --- 准备:多帧黑帧均值 = FPN(空间固定结构)---
fpn_3200 = np.mean(dark_frames_3200, axis=0) # shape: (H, W)
fpn_6400 = np.mean(dark_frames_6400, axis=0)
# --- 单帧减去均值 = 随机 read noise ---
rand_3200 = single_dark_3200 - fpn_3200
rand_6400 = single_dark_6400 - fpn_6400
# --- FPN:线性插值(它是确定性的,直接插值合理)---
t = (5000 - 3200) / (6400 - 3200)
fpn_5000 = (1 - t) * fpn_3200 + t * fpn_6400
# --- 随机分量:插值方差后重新缩放 ---
# 计算方差
var_rand_3200 = rand_3200.var()
var_rand_6400 = rand_6400.var()
# 插值目标方差
var_rand_5000 = (1 - t) * var_rand_3200 + t * var_rand_6400
# 从 ISO 3200 随机分量缩放(保留空间相关性)
scale = np.sqrt(var_rand_5000 / var_rand_3200)
rand_5000 = rand_3200 * scale
# --- 合成 ISO 5000 黑帧 ---
dark_5000 = fpn_5000 + rand_5000但是看代码,不知道为什么合成噪声使用的还是泊松高斯噪声,而没有使用黑帧,具体代码见https://github.com/zhangyi-3/Noise-Synthesis/blob/main/synthesize.py
黑帧校准
在索尼的文章中,仍然使用叠加黑帧,但是考虑到高比特重建可能引入复杂性和额外的错误,并且低bit本来就是噪声低特性,所以放弃了高比特位重建high-bit-depth noise recovery (HBNR)。
因为ELD提到信号无关噪声是长尾分布long-tailed,可以使用Tukey-Lambda 或者Gaussian mixture model (GMM)来拟合。通过Q-Q图对比,GMM拟合更好,但是泛化性也不够:
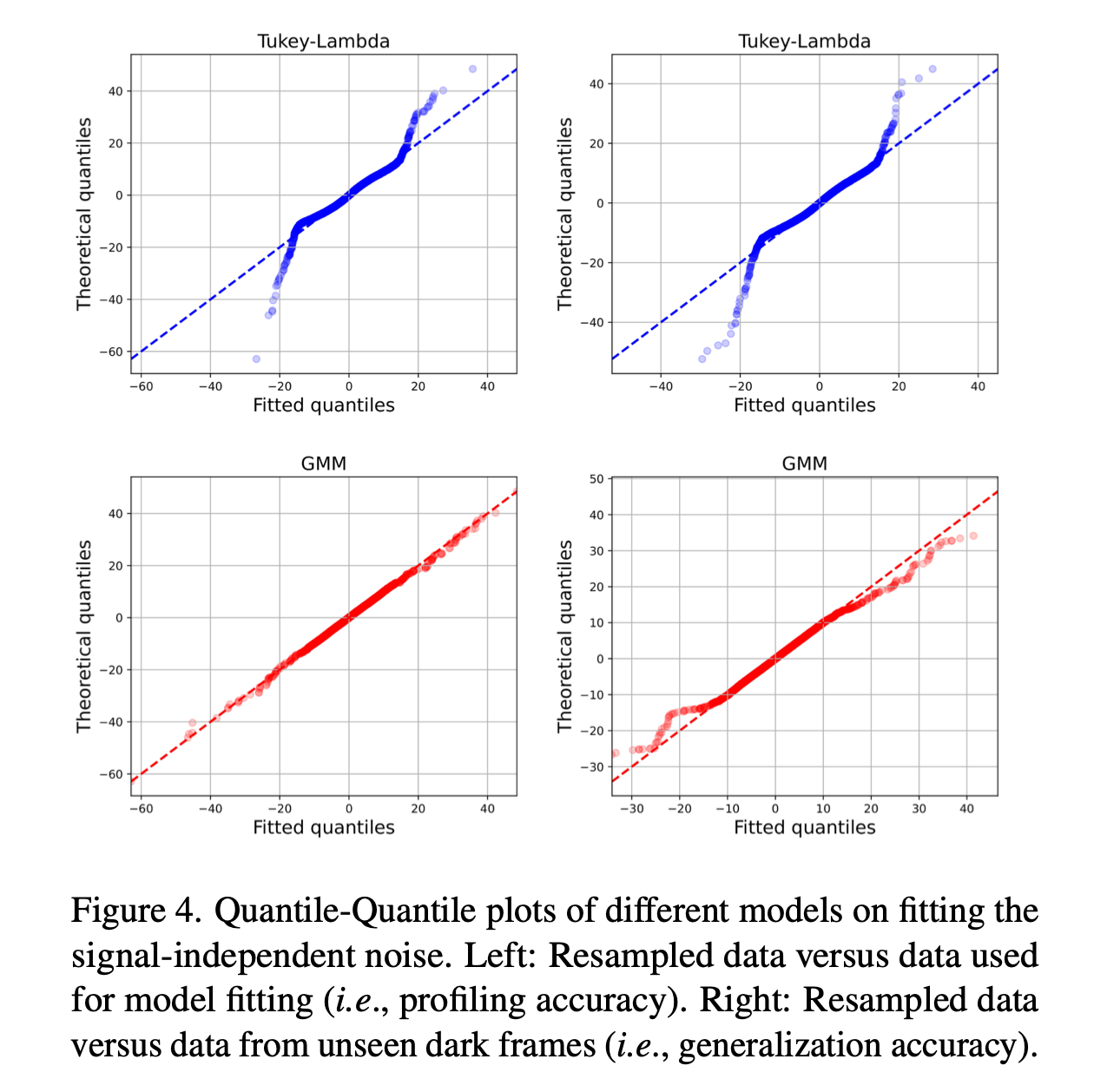
但是使用了校准dark shading的预处理。因为在专业摄影中,都需要把拍到的图减去这个底噪。所以网络的训练和加噪声的过程中,也要减去这个底噪:

darkshading的估计也是根据iso线性拟合,除了k和b还有根据均值计算出的ble:
def get_darkshading(self, iso):
if iso <= 1600:
return self.pmn_dsk_low * iso + self.pmn_dsb_low + self.pmn_ble[iso]
else:
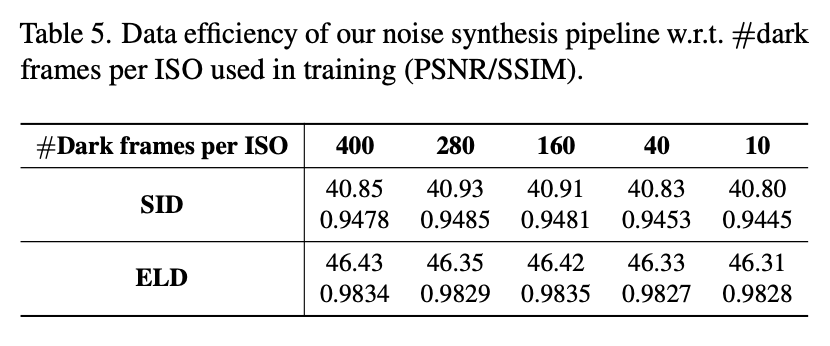
return self.pmn_dsk_high * iso + self.pmn_dsb_high + self.pmn_ble[iso]理论上要求dark shading比较准确,要使用大量的黑帧求平均。但实际上随着使用环境的变化,如高温环境连拍好久之后,就需要重新标定。文章中对比了不同黑帧数量下re-calibration的效果:

可以看到,使用10帧重新标定和180帧只差了0.1dB。事实上,在训练的阶段,利用了LLD每个iso400个黑帧的数据,但是实验证明训练时每个ISO也只需要10帧黑帧:
代码中可以看到生成噪声和高比特的实现。
def generate_noisy_obs(
y, camera_type=None, wp=16383, noise_code="p", param=None, MultiFrameMean=1, ori=False, clip=False
):
# # Burst denoising
# sig_read = 10. ** np.random.uniform(low=-3., high=-1.5)
# sig_shot = 10. ** np.random.uniform(low=-2., high=-1.)
# shot = np.random.randn(*y.shape).astype(np.float32) * np.sqrt(np.maximum(y, 1e-10)) * sig_shot
# read = np.random.randn(*y.shape).astype(np.float32) * sig_read
# z = y + shot + read
p = param
y = y * (p["wp"] - p["bl"])
# p['ratio'] = 1/p['ratio'] # 临时行为,为了快速实现MFM
y = y / p["ratio"]
MFM = MultiFrameMean**0.5
use_R = True if "r" in noise_code.lower() else False
use_Q = True if "q" in noise_code.lower() else False
use_TL = True if "g" in noise_code.lower() else False
use_P = True if "p" in noise_code.lower() else False
use_D = True if "d" in noise_code.lower() else False
use_black = True if "b" in noise_code.lower() else False
if use_P: # 使用泊松噪声作为shot noisy
noisy_shot = np.random.poisson(MFM * y / p["K"]).astype(np.float32) * p["K"] / MFM
else: # 不考虑shot noisy
noisy_shot = (
y + np.random.randn(*y.shape).astype(np.float32) * np.sqrt(np.maximum(y / p["K"], 1e-10)) * p["K"] / MFM
)
if not use_black:
if use_TL: # 使用TL噪声作为read noisy
noisy_read = stats.tukeylambda.rvs(p["lam"], scale=p["sigTL"] / MFM, size=y.shape).astype(np.float32)
else: # 使用高斯噪声作为read noisy
noisy_read = stats.norm.rvs(scale=p["sigGs"] / MFM, size=y.shape).astype(np.float32)
# 行噪声需要使用行的维度h,[1,c,h,w]所以-2是h
noisy_row = np.random.randn(y.shape[-3], y.shape[-2], 1).astype(np.float32) * p["sigR"] / MFM if use_R else 0
# [1, 1000, 2000] 的图像与 [1, 1000, 1]行噪声利用广播机制相加,行噪声的每一行都是同一个值
noisy_q = np.random.uniform(low=-0.5, high=0.5, size=y.shape) if use_Q else 0 # 模拟四舍五入的量化噪声
noisy_bias = p["bias"] if use_D else 0
else:
noisy_read = 0
noisy_row = 0
noisy_q = 0
noisy_bias = 0
# 归一化回[0, 1]
z = (noisy_shot + noisy_read + noisy_row + noisy_q + noisy_bias) / (p["wp"] - p["bl"]) # 加噪声是在10bit物理空间中,所以加完噪声再归一化
# 模拟实际情况
z = np.clip(z, -p["bl"] / p["wp"], 1) if clip is False else np.clip(z, 0, 1)
if ori is False:
z = z * p["ratio"]
return z.astype(np.float32)。这里https://github.com/SonyResearch/raw_image_denoising
深度学习
既然很难对信号无关,尤其是很暗的环境,还有一个方法就是使用深度学习的方法。这里介绍一篇ICCV 2023华中科大和大疆,构建了low-light raw denoising (LRD) 数据集
zhangfeng的文章:https://github.com/fengzhang427/LRD
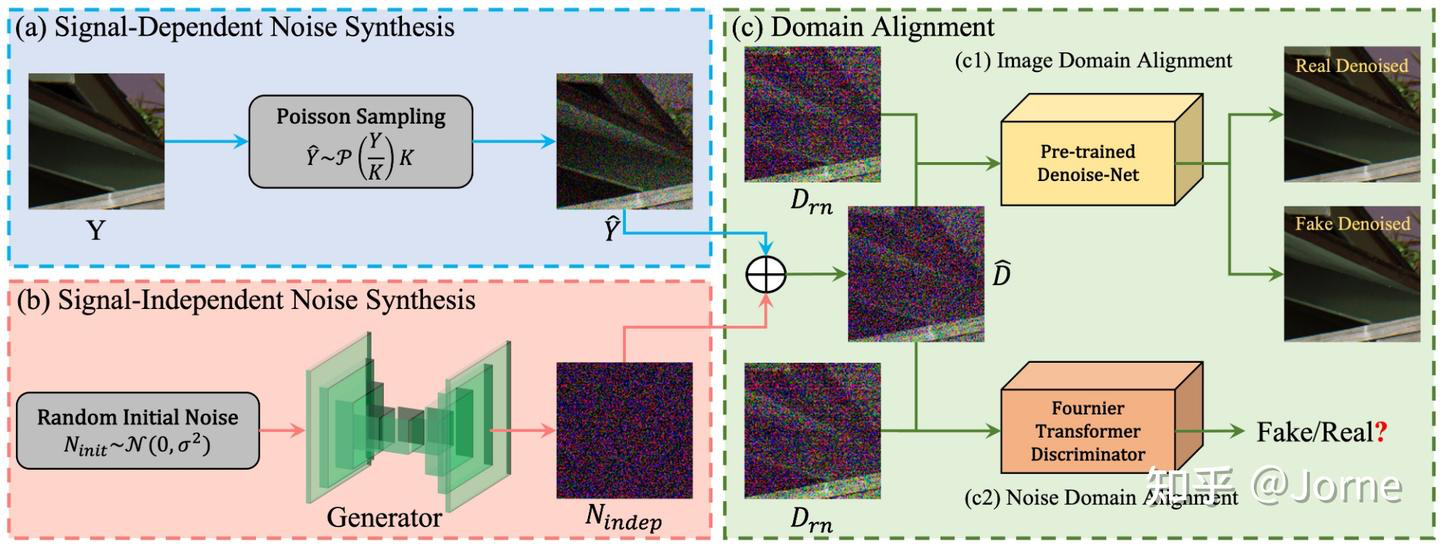
使用Fourier transformer discriminator (FTD)来区分噪声分布。Kullback-Leibler divergence (KLD)计算合成的噪声和真实噪声的分布。
这个生成模型可以生成不同iso的信号无关噪声。首先第一个问题就是怎么衡量合成噪声和真实噪声的差异,直接使用L1肯定不可以,因为不可能要求噪声一模一样,我们更关注的是统计学的分布。解决办法就是对真假带噪声图像分别经过预先训练的降噪模型之后,再去计算L1 loss和perceptual loss:
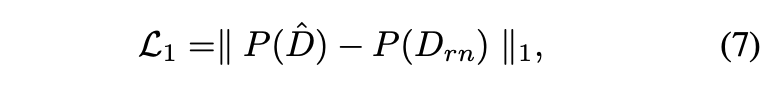
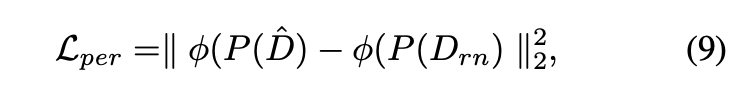
此外,还引入了对抗损失,但是对抗损失在噪声很多的场景下会失效。参考傅立叶变换,把图像内容和噪声根据频率区分开来。fast Fourier convolution (FFC) 就可以看作是傅立叶变换的CNN形式,在此基础上,把卷积部分替换成transformer就得到了Fourier transformer block。和FFC一样,数据的一半在频域上计算,一半在空域,这样就得到了互补的信息。又参考TransGAN,从多尺度进行判别,所以完整的Fourier transformer discriminator (FTD)是:
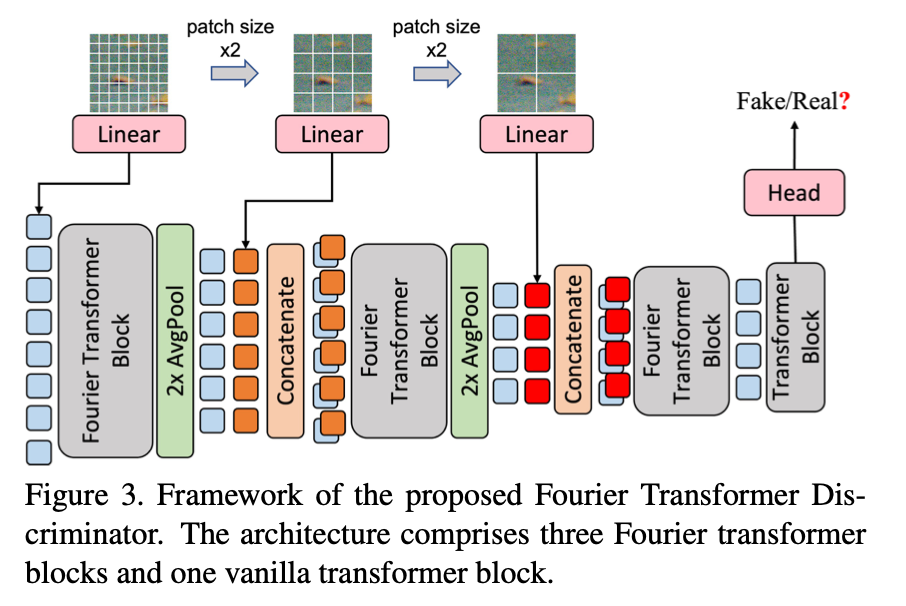
不同patchsize得到的patch被序列化,经过Fourier transformer block之后再转回2D,通过平均池化和另外一个尺度的序列做concate。
使用WGAN-GP,因为Wasserstein distance训练更稳定。
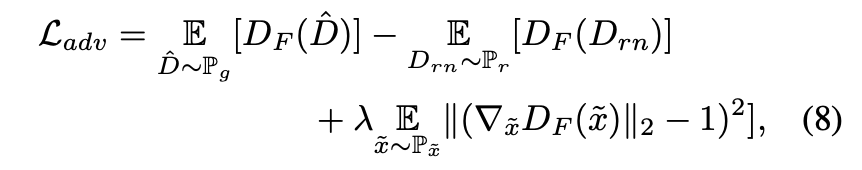
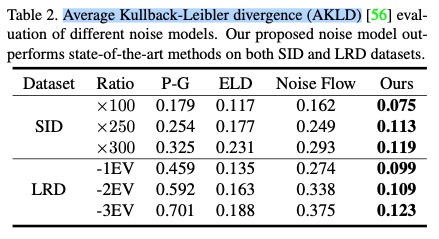
使用Average Kullback-Leibler divergence (AKLD)衡量不同噪声模型和真实分布的距离:
虽然提供了源码,但是只有训练降噪模型的部分,没有生成噪声的代码https://github.com/fengzhang427/LRD/tree/main
此外,还有对噪声分得更精细,分别涉及模块去对应的深度学习方法如caoyue的LLD,但只提供了数据,没有相关代码。当然还有经典的使用流模型生成的noiseflow。
reference:
-
rethinking https://arxiv.org/pdf/2110.04756
-
onehour https://arxiv.org/pdf/2505.00045
-
noiseflow https://arxiv.org/pdf/1908.08453