AI 圈有非常多的名词,token,LLM,context,prompt,mcp,skills,Agent.....
可能很多词你都听说过,但说实话你真的都懂它们到底是什么?底层逻辑是什么?作用是什么?
如果让你去面试 AI 的岗位,你是真的能讲清楚是什么?还是阿巴阿巴说不清?
就拿 Token 来说,很多人只知道 Token 消耗多 = 烧钱 但不知道它的原理,不信你就往下看。
本文我将从小白的角度,从最底层的东西,一层一层的往上讲,把这些概念全部串起来一文全部讲清楚。
看完本期内容,你将对 AI 底层逻辑的理解将有一个质的飞跃。
全文目录
LLM
LLM 的全称是 Large Language Model 翻译成中文就是大语言模型,简称:大模型。
目前市面上的大模型基本上都是基于 Transformer 这套架构设计出来的。
看起来很复杂,但实际上也不简单,看不懂是正常的,只需要知道大模型的底层引擎就是它就好了。
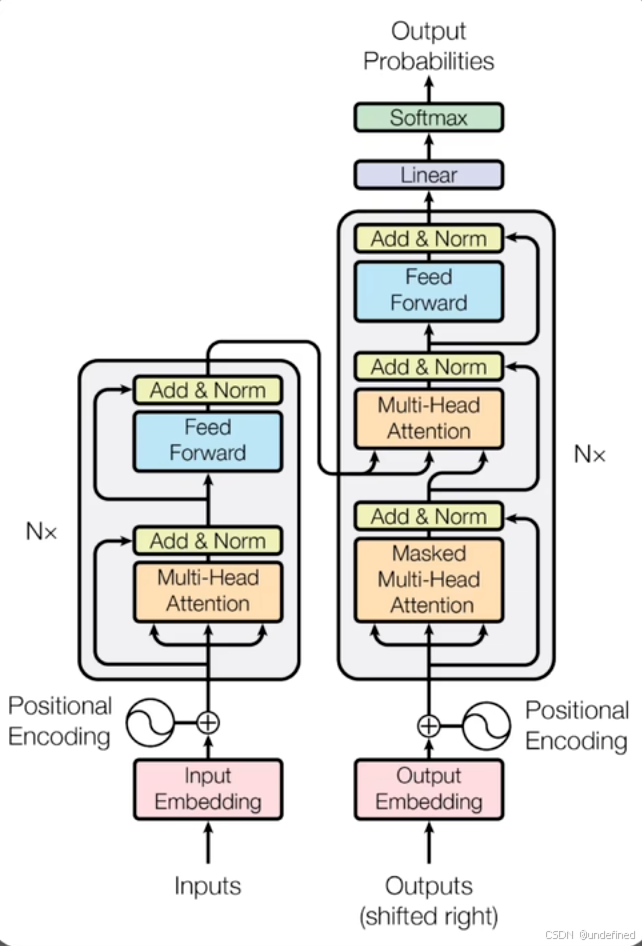
它最早是由 Google 在 2017 年提出来的,但把它带火的却是 OpenAI 。
OpenAI 可以说的上是目前大模型的鼻祖了,毕竟是它开创了大模型的热度先河,到今天 GPT 模型依旧是业界的标杆。
大模型的工作原理:
简单来说的话,它本质上就是一个文字接龙游戏,根据你前面说的话,一个字一个字猜下一个最可能出现的字。
比如:你输入:我今天去公园,看到了一只___
大模型要做的,就是猜下一个字****。
它在脑子里飞快算概率:
-
小 → 很高
-
猫 → 很高
-
狗 → 很高
-
山 → 很低
-
飞机 → 极低
-
桌子 → 几乎不可能
它选概率最高的,比如:小
现在句子变成:我今天去公园,看到了一只小___
它继续猜下一个字:
-
猫 → 最高
-
狗 → 次之
-
鸟 → 也还行
-
象 → 不太对
输出:猫
句子变成:我今天去公园,看到了一只小猫___
再继续:
-
。 → 概率最高
-
在 → 也有可能
-
跑 → 也有可能
它选句号,结束。
最终你看到:我今天去公园,看到了一只小猫。
但我们要知道的是,它是不会思考的,只会预测,你问它问题的时候,它不是在理解你、然后查资料、再进行推理回答。
而是在做一件事:在当前这句话后面,推测哪个字概率最高,就输出哪个**。**
那你可能会问了,我看现在好多 AI 模型都带有深度思考啊,你怎么说没有呢?
现在的模型看起来会深度思考,但其实不是它真的会思考,而是它学会了【模仿人类思考的步骤】。
Token
很多人只知道大模型干活烧 Token ,烧钱,但是不知道原理是什么。
如果你了解 Token 的在大模型中的运行逻辑原理,那你在使用大模型的时候,就能够极大的帮你省下不少的 Token (钱)
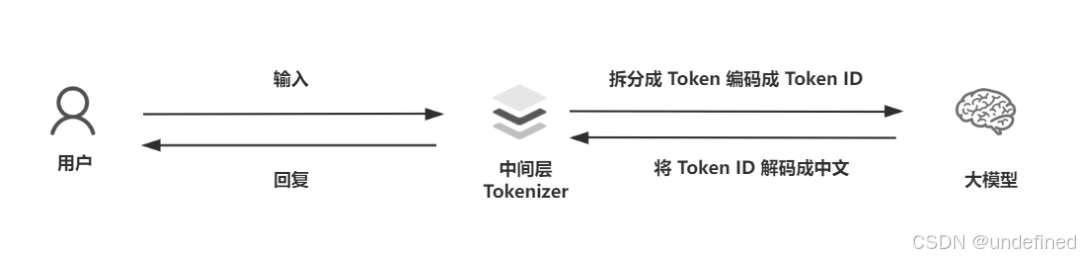
当我们提问题给大模型之后,大模型就会源源不断回复你一些词,但其实这是为了方便你理解,而简化的一种方式。
实际情况是:大模型本质上是一个庞大的数学函数,里面是以矩阵运算来进行的,它接收的是数字,输出的也是数字,它并不认识人类写的文字/英文,只认识数字(Token ID)。
因此在用户与大模型之间需要存在一个中间层作为翻译,这个中间层就叫做 Tokenizer 。
Tokenizer 它负责的是编码和解码两件事情。编码就是把文字变成数字,解码反过来就是把数字还原成文字。
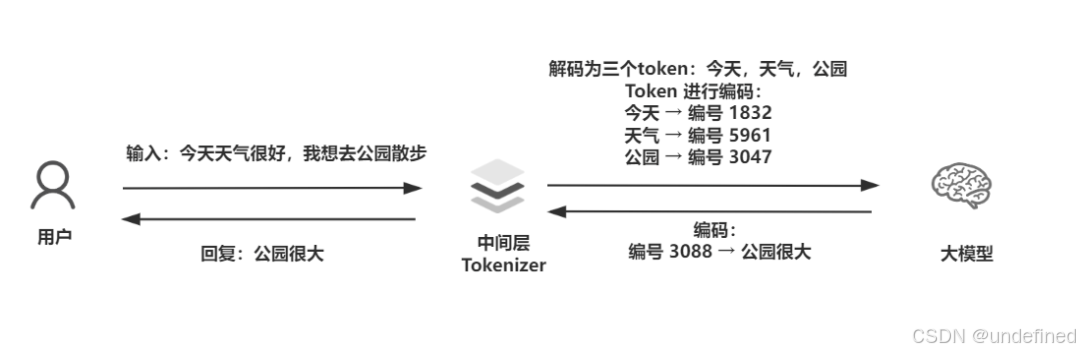
比如当我向大模型输入:今天天气很好,我想去公园散步。
文字就会【经过】Tokenizer 把内容进行【切分】变成 Token,然后再把 Token【转化成】Token ID。
例子中这段内容就会经过 Tokenizer 先切出三个 Token 分别是今天,天气,公园,然后再把这三个 Token 进行编码 今天 → 编号 1832,天气 → 编号 5961,公园 → 编号 3047。
然后模型看到的就是【1832,5961,3047】,这就是编码的过程。
Token 在这里是文字,是大模型切出来的碎片,Token ID 是数字,这两者本质上是一个意思,只不过是换了种表达的方式。
刚才我们了解了我们向大模型【提问】时的编码过程,我们继续了解,大模型向我们【回答】时的解码过程。
大模型接收到 Token ID 之后,会根据概率较大情况进行匹配 Token ID ,也就是上一节说的 LLM 原理,返回一些 Token ID 给到中间层 Tokenizer 再翻译成中文给我们。
比如刚才的公园【编号 3047】大模型收到后,返还一个【编号3088】,然后 Tokenizer 收到编号后,将编号翻译成公园很大给我们。
一句话总结来说:Token 就是大模型眼里的 "文字最小单位",不是字,也不是词,是模型切出来的碎片。我们提问的时候它会根据我们的问题切成碎片 Token ,然后回答的时候也会根据 Token 一个个返回。
平均来说 1 个 Token = 0.75 个单词 = 1.5 - 2 个汉字。
Context
Context 翻译成中文的意思是:上下文,语境,背景,环境,它代表的是大模型每次处理任务时所接收到的信息总和。
大模型的本质就只是一个数学函数,你输入问题提问,它就输出答案,它并不像人一样,真的有记忆。
那它究竟是怎么记住之前的聊天内容的呢?
答案就是当我们提问时,除了当前的问题以外,还会连带历史对话一起发送给大模型,这里的历史对话是包含了我们对大模型的提问,以及大模型给我们的回复。
比如对话历史:
我:你好,我叫偶然。
大模型:你好,偶然!
我再次向大模型提问:我叫什么?大模型就会知道我叫偶然。
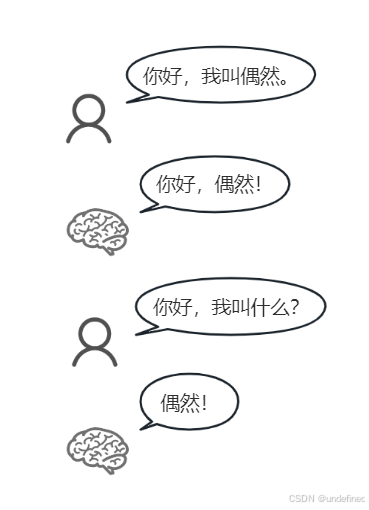
这种操作就会让我们误以为大模型是拥有记忆能力的,其实并不是,而是我们提问的时候连带历史对话一并发送给了大模型。
由于我们向大模型提问的时候会连带历史对话一并发送,所以我们在与大模型对话时,需要及时的总结内容。
这样会减少 Token 的消耗,同时也避免了上下文内容过多,导致大模型处理内容过多而造成的卡顿,回复时间长。
此外,Context 除了对话的内容以外,还会有一些工具,系统提示词也会被记录进来,在大模型执行我们给他的任务的时候一并使用,比如说一些天气工具啥的。
Context Window
了解了 Context 的底层逻辑之后,我们就要 Context Window 翻译过来就是上下文窗口,也就是 Context 能容纳的最大 Token 数量。
比如说 Context 为 1 万,那就代表这个模型最多能够处理 1 万个 Token 。
不过目前的大模型 Context Window 都是很大的,比如 GPT 5.4 的是 105 万,Gemini 3.1 pro 是 100 万,Claude Opus 4.6 是 100 万。
之前我们说过 Token 在 1.5 - 2 个汉字,那 100 万的话就是 150 万 - 200 万个汉字。
Prompt
Prompt 是中文提示词,是大模型接收的具体问题或者指令。
Prompt 的概念虽然简单,但我们需要注意的是它的质量,好的指令,它的回复才能符合你的预期。
一个好的 Prompt 应该是清晰的,具体的,明确的。
比如你向大模型提问:帮我写一首古诗,这样就不够具体,应该把故事的风格,字数,主题也加上。
其实说白了就是把话说清楚,让大模型更精准的理解你的意图是什么。
如果你不会写好的 prompt 那你就把你的大概意思描述出来,让 AI 帮你写 prompt 然后再根据个人情况进行微调就好了。
Tool
大模型有一个缺点,就是它无法感知外界环境。
比如你问它:今天广州的天气怎么样?
它会回答你:抱歉,我无法获取实时天气信息。我的知识库数据截止到 2025 年 10 月,无法提供当前的天气数据。
因为大模型本质就是一个文字接龙概率匹配的游戏,它的能力是根据训练的数据来预测下一个词。
它是真没有办法直接去查天气预报网站,拿到实时的天气数据。
这个时候我们就需要用到 Tool 了,Tool 翻译成中文就是工具的意思。
Tool 的本质是一个函数,你输入内容给它,它就会给你输出。
比如天气查询工具,它可能包含城市,日期这两个参数,当然还有其他的参数。
我们输入城市:广州,日期:2026年4月6日,这个工具就会去调用一些气象局的接口,然后输出天气:阴天,温度:24°~29°。
有了它,大模型就可以回答天气相关的问题了。
我们来看一下大模型调用工具完成任务的整个过程是怎么样的,我们先看一下这个过程中所涉及到的角色有那些。

这里有人可能会问,为什么需要平台这一角色,用户,大模型,天气查询工具这三个不就够了吗?
因为用户,大模型,天气工具没办法直接进行对话,所以就需要一个平台来打通用户,大模型,天气工具三者之间的信息沟通。
平台的本质就是一段代码。
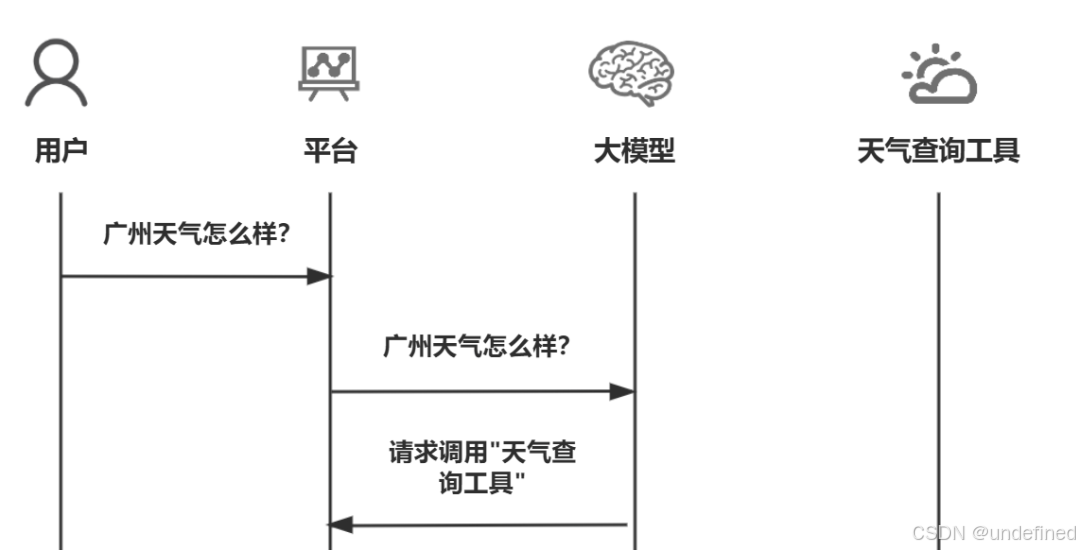
当我们向大模型发送内容时,并不是直接就能发给大模型,而是先通过平台这一媒介来进行传达的。
比如我问:今天广州的天气怎么样?内容会先发送给平台,然后平台再发送给大模型,大模型收到后,请求平台调用"天气查询"工具。
你要记得开始说的,大模型只会接龙游戏。
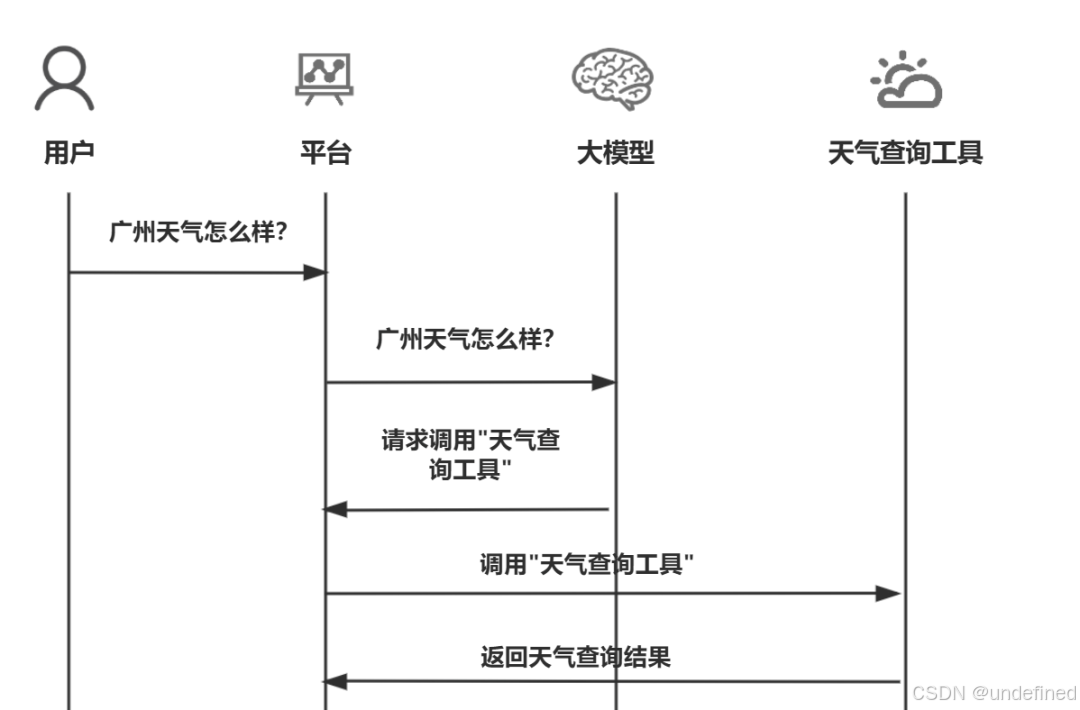
平台收到请求之后,会去调用"天气查询工具",然后天气查询工具查询了天气之后,就会返回天气查询的结果。
平台收到天气查询的结果之后,会给告诉大模型,大模型会调整相应的回答内容给到平台,然后平台再给到用户。
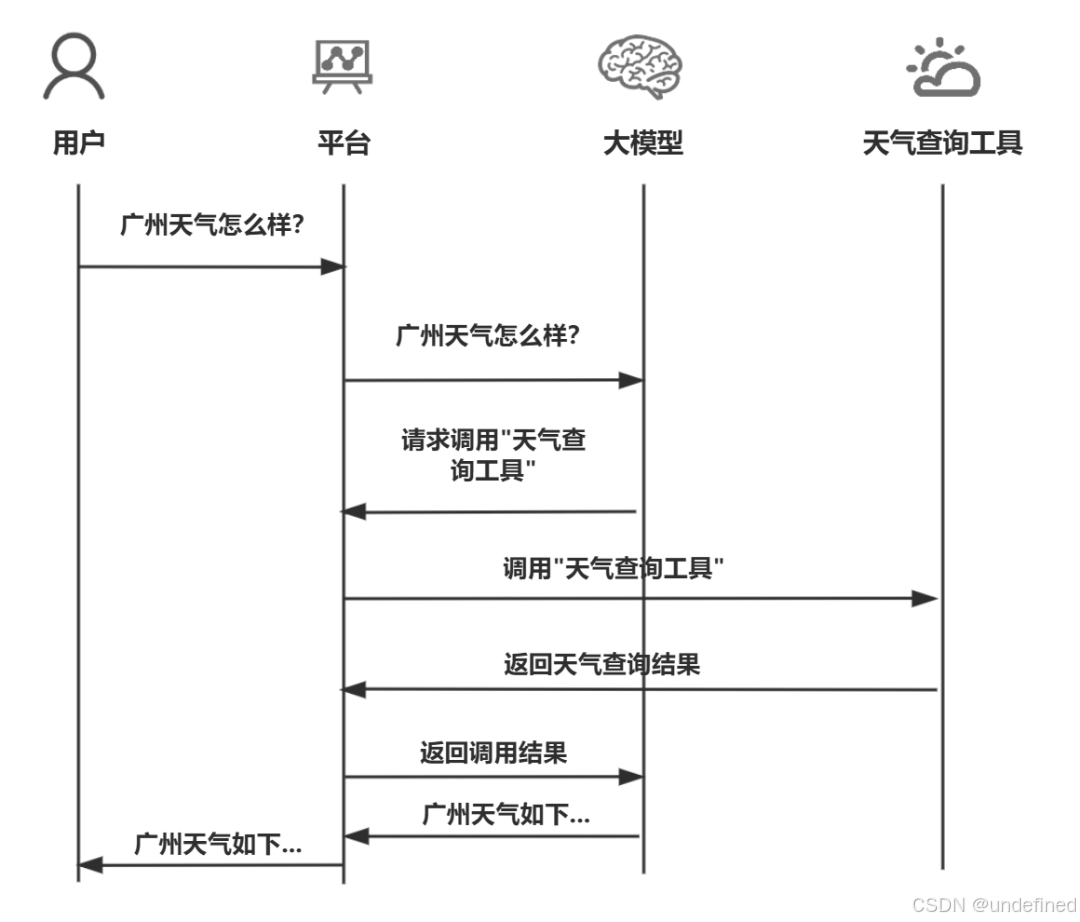
在整个过程中,每个角色都承担了不同的职责。
大模型:承担选择工具,归纳总结。
工具:实现查询天气。
平台:串联流程。
用户:给出指令。
到这里,我们更加了解了大模型完成任务的一个底层原理,接下来咱们继续。
MCP
刚才我们说了平台把工具列表传给模型,然后平台还要调用工具。
我们把工具接到平台里面,这样平台才知道那些工具可以使用,以及每个工具的用途,参数,调用方法。
但会有一个问题就是接入规范,每个平台都不一样。
比如你用的是 Chatgpt 你就要按照 OpenAI 的规范接入工具写一套接入代码。
比如你用的是 Claude 你就得按照 Anthropic 的规范接入规范,再写一套接入代码。
比如你用的是 Gemini ......
从上面的举例来看,一个工具,接入不同的平台,你需要写不同的规范,因为每个平台的标准不一样。
因此就出现了 MCP 这个统一的标准,让所有的平台都遵循这个标准。
这样工具的开发者,只需要写一次代码,就可以在所有的平台上使用了。
因此 MCP 就是统一接入规范。这就像手机的 Tpye c 接口一样,有统一的标准,大家就会很方便。
如果你想更了解 MCP 的内容,可以看我之前这篇:一文读懂什么是MCP,RAG,Agent,以及它们之间的关系(小白必备)
Agent
其实智能体去年的时候就非常的火了,从去年的 Coze ,N8N,Dify,再到今年爆火的通用智能体 Openclaw 小龙虾。
但其实到今天懂的人还是不多的,而且懂的人大概也只懂概念,不懂原理。
这里我给大家举一个例子吧。
比如我给大模型说:今天广州的天气怎么样?有没有下雨?如果下雨了的话,帮我看看附近有没有店铺可以买雨伞?
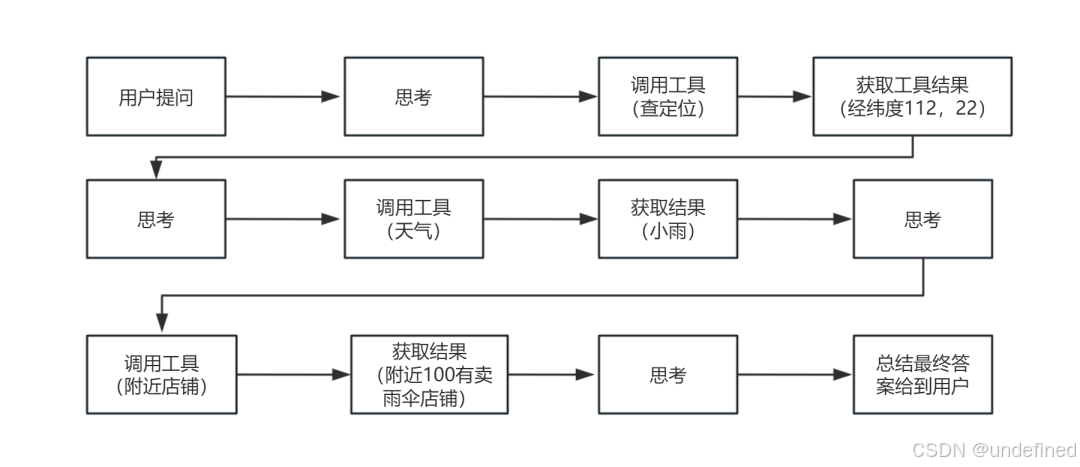
从过程来看,大模型并不是只调用一次工具,而是一步步思考当前的情况,然后决定下一步做什么。
这也是为什么过往我的 Agent 文章都是画流程图出来的,因为要梳理出 Agent 的一个执行情况,只有梳理了,才能更好的搭建出来。
我们称这种能够自主规划,自主调用,直到完成用户任务的系统为 Agent 。
目前市面上比较火的 Agent 产品,有 Claude Code,Codex,Gemini CLI 等等,比较经典的 Agent 构建模式有:ReAct,Plan And Execute。
Agent Skills
这个前几天刚写,直接看这篇吧:Agent Skills 从原理到实战一文彻底搞懂!
总结
我们一文讲清了 LLM,Token,Context,Context Window,Prompt,Tool,MCP,Agent 的底层运行方式逻辑。
LLM 词配对接龙游戏,Token 最小单元"词"单元,Context 模型上下文,Contxt Window 模型上下文窗口大小,Prompt 模型指令提示词,Tool 工具.....
希望看完本文,你能了解 AI 这些名词的所有底层运行逻辑,不懂可以在评论区留言。
本期的内容就到这里了,感谢你的耐心。
如果看完喜欢,请帮忙转发分享一下,你的点赞转发,就是我更新下去的动力