当传统风控遇上大模型,一家大型银行如何用AI重构信贷全生命周期与财富管理服务?
📌 项目概览:百亿参数模型驱动的银行核心业务数智化转型
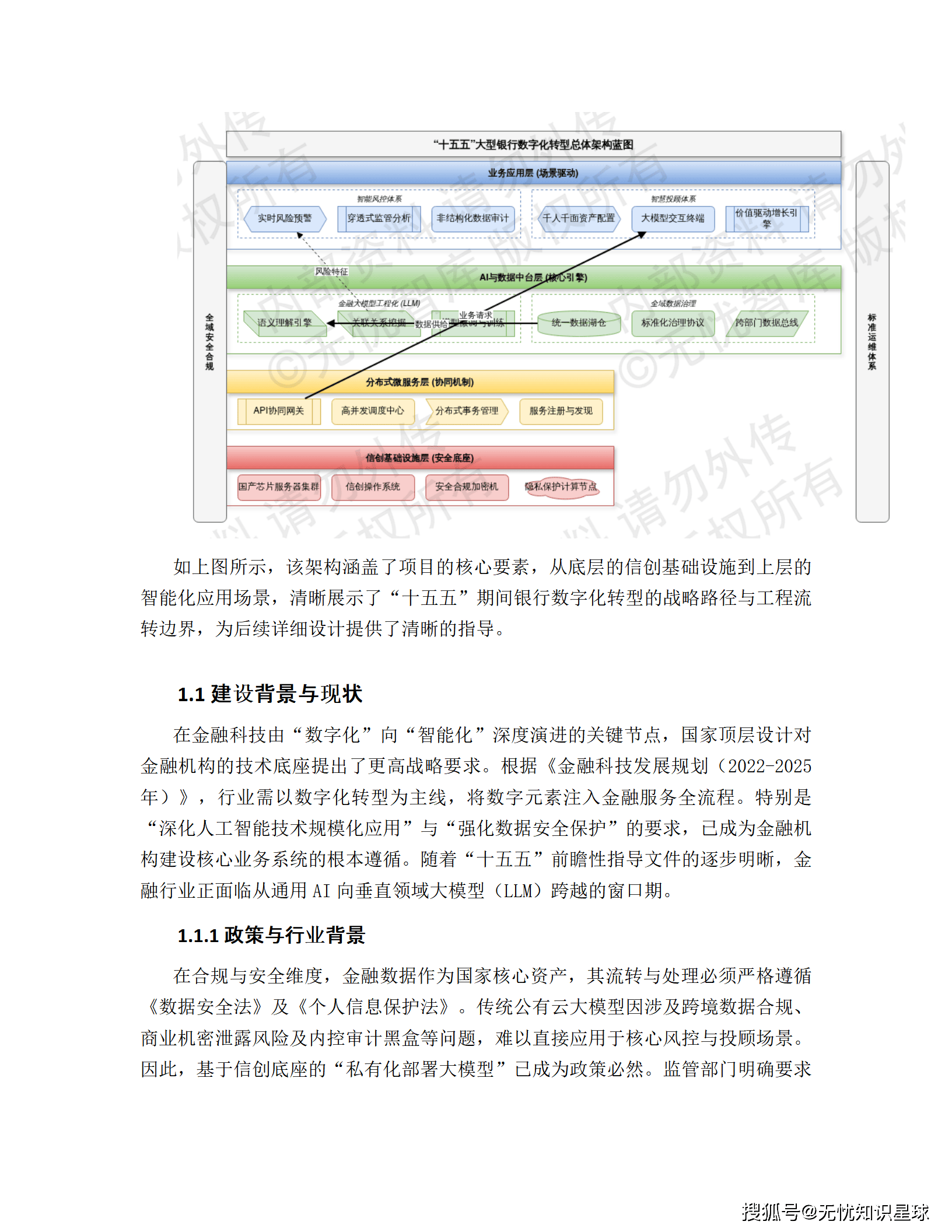
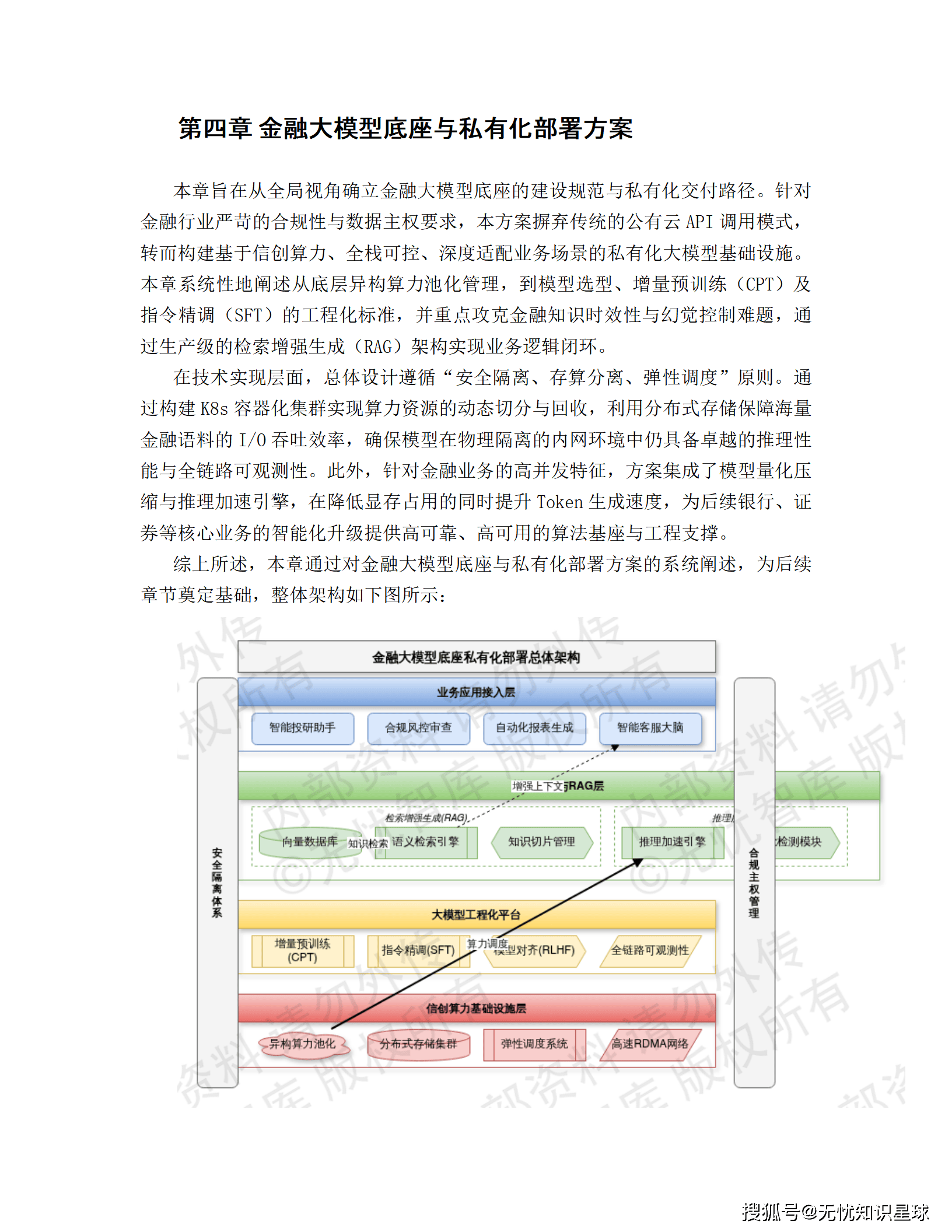
在"十五五"数字化转型深化的关键窗口期,某大型银行启动了一项以金融大模型(Financial LLM) 为核心引擎的战略级项目,旨在通过私有化部署、检索增强生成(RAG)技术,构建覆盖贷前、贷中、贷后全流程的智能风控系统 ,以及具备动态资产配置能力的智能投顾平台。
一、为什么必须上大模型?------ 传统系统的"三重天花板"
1.1 政策与合规驱动:私有化部署是唯一选项
金融数据作为国家核心资产,其流转必须严格遵循《数据安全法》及《个人信息保护法》。传统公有云大模型因涉及跨境数据合规、商业机密泄露风险、内控审计黑盒等问题,无法直接应用于核心场景。
关键结论:基于信创底座的"私有化部署大模型"已成为政策必然。
1.2 现有系统的三大致命痛点
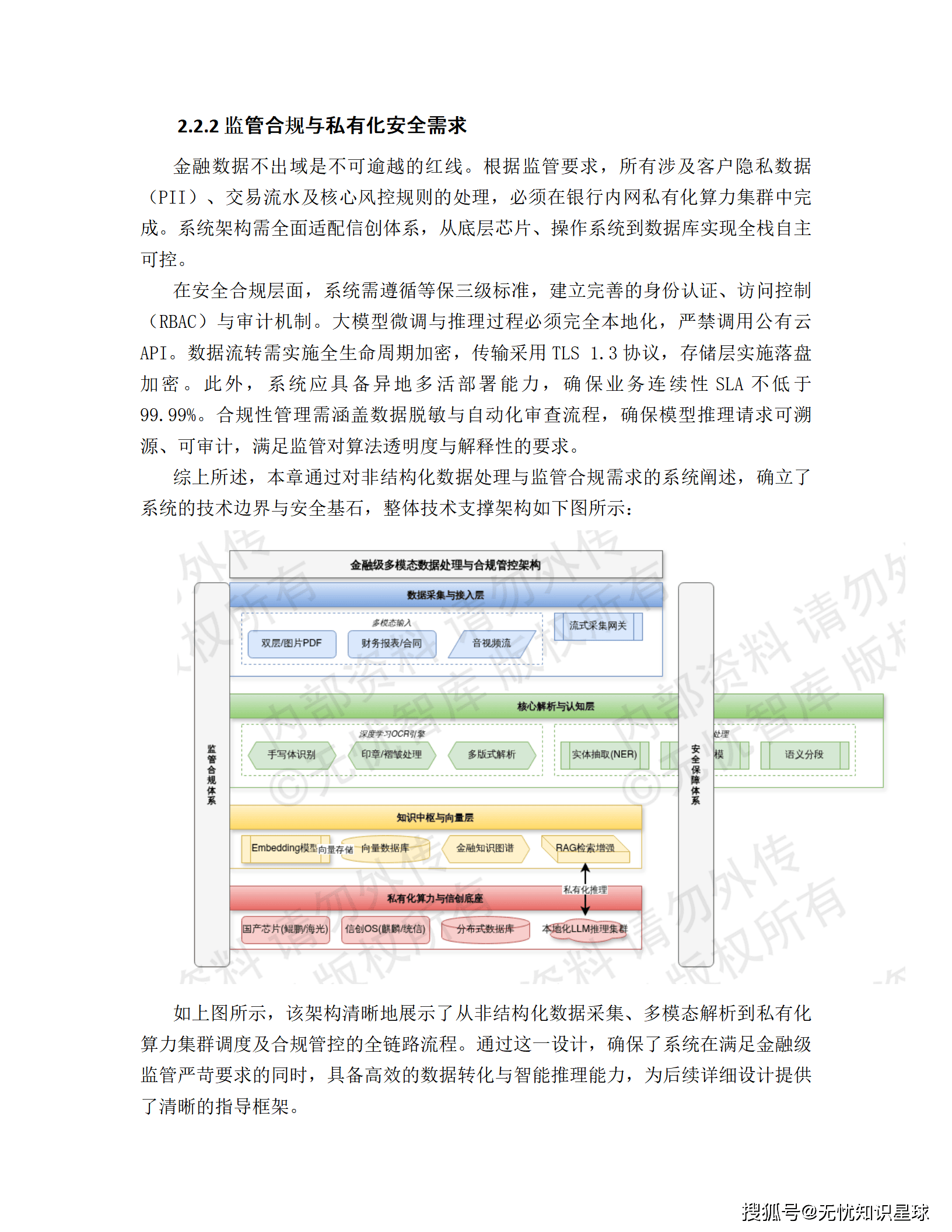
🔴 痛点一:非结构化数据处理瓶颈
在企业信贷及投后风控场景中,系统需处理大量年报、审计报告及法律文书。现有的OCR与关键词匹配技术难以理解复杂的上下文逻辑。
实测数据: 面对超过200页的非结构化财报,传统引擎解析单个主体平均耗时超 40分钟 ,关键财务指标提取准确率低于 85%。
🔴 痛点二:投顾策略生成的静态化困局
现行投顾系统高度依赖预设的静态规则与历史回测模型,缺乏对实时宏观研报、政策变动及舆情信息的语义理解能力。
残酷现实: 理财经理面临每日超过 5000篇的市场研报,传统人工筛选模式难以应对高频波动。
🔴 痛点三:风险预警的显著滞后
传统风控引擎无法实时消化海量非结构化信息,导致风险识别存在显著的时间差,无法满足实时风控要求。
二、业务场景深度拆解:大模型到底解决什么问题?
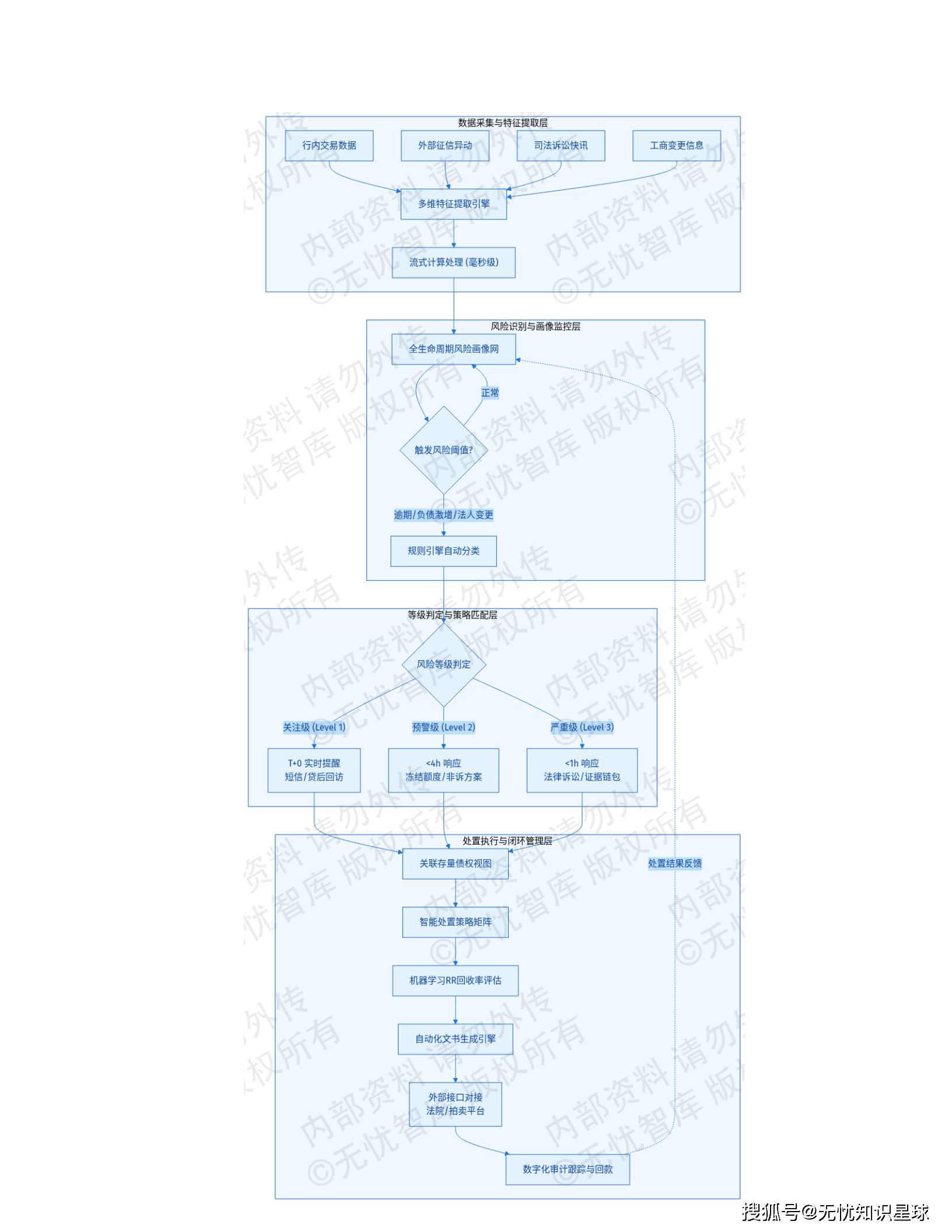
2.1 贷前中后全流程风控 ------ 从"指标化审查"到"穿透式风控"
📋 贷前阶段:自动化尽调与关联关系穿透
系统需具备长文本解析能力,自动抽取招股说明书、审计报告及财报中的关联方关系、重大合同履约及资金用途等关键要素,并实现跨文档的勾稽关系自动交叉验证。
场景案例: 当系统识别到财务报表科目不匹配或披露信息与工商登记冲突时,立即触发预警并生成风险偏离度分析报告。
⚙️ 贷中阶段:智能化流水与凭证审核
依托NLP技术解析法院判决书、执行公告等法律文本,实时监测借款主体及其关联方的诉讼风险与财产保全状态,严控资金违规挪用。
📢 贷后阶段:全网舆情监控与风险摘要生成
系统需每日处理万级公开信息,自动过滤冗余噪音,针对经营异常、环保处罚、股权质押等负面信号进行逻辑聚类,生成结构化的风险事件简报。
2.2 财富管理 ------ 从"千人一面"到"千人千面"
📚 研报自动摘要与观点提取
将深度研究报告压缩为包含投资评级、目标价及核心逻辑的结构化数据,并建立基于历史预测准确率的评价体系。
🎯 动态KYC与资产配置闭环
系统实时整合客户风险偏好、存量持仓结构及交易行为,将解析后的研报观点与客户画像进行自动化匹配。
场景案例: 当市场发生风格切换或行业黑天鹅事件时,系统须在 分钟级内完成全量客户池扫描,生成包含持仓诊断、建议调仓比例及预期收益测算的个性化投资建议书。
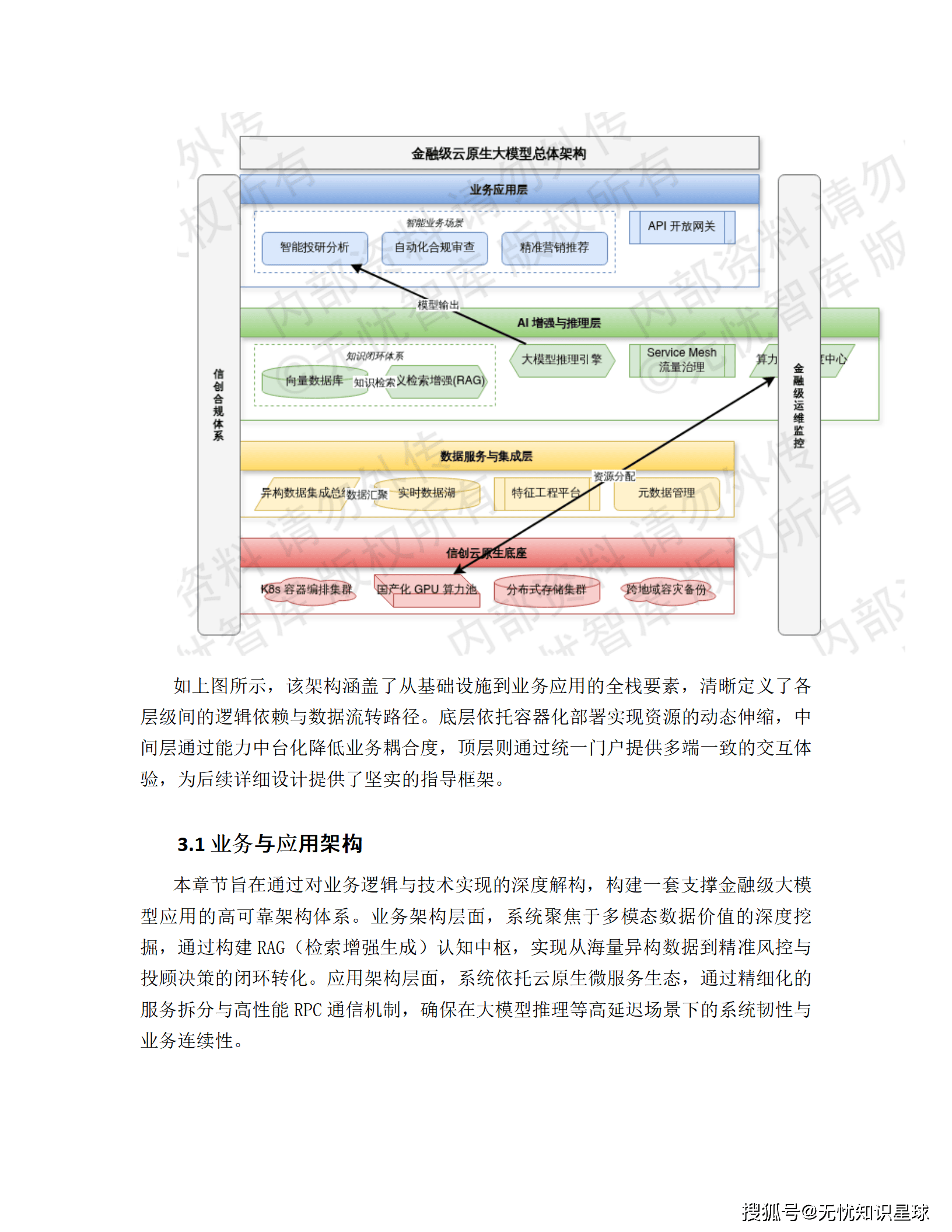
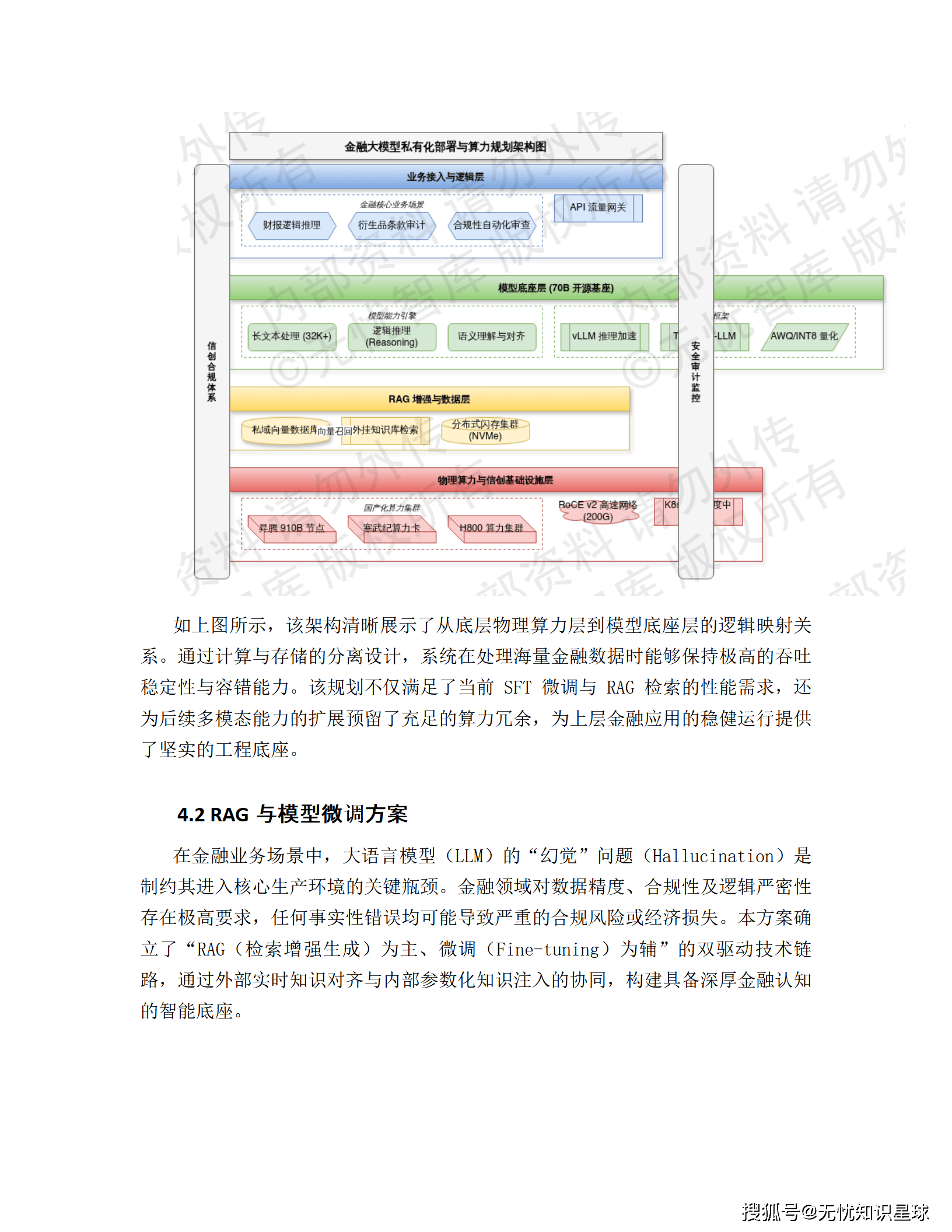
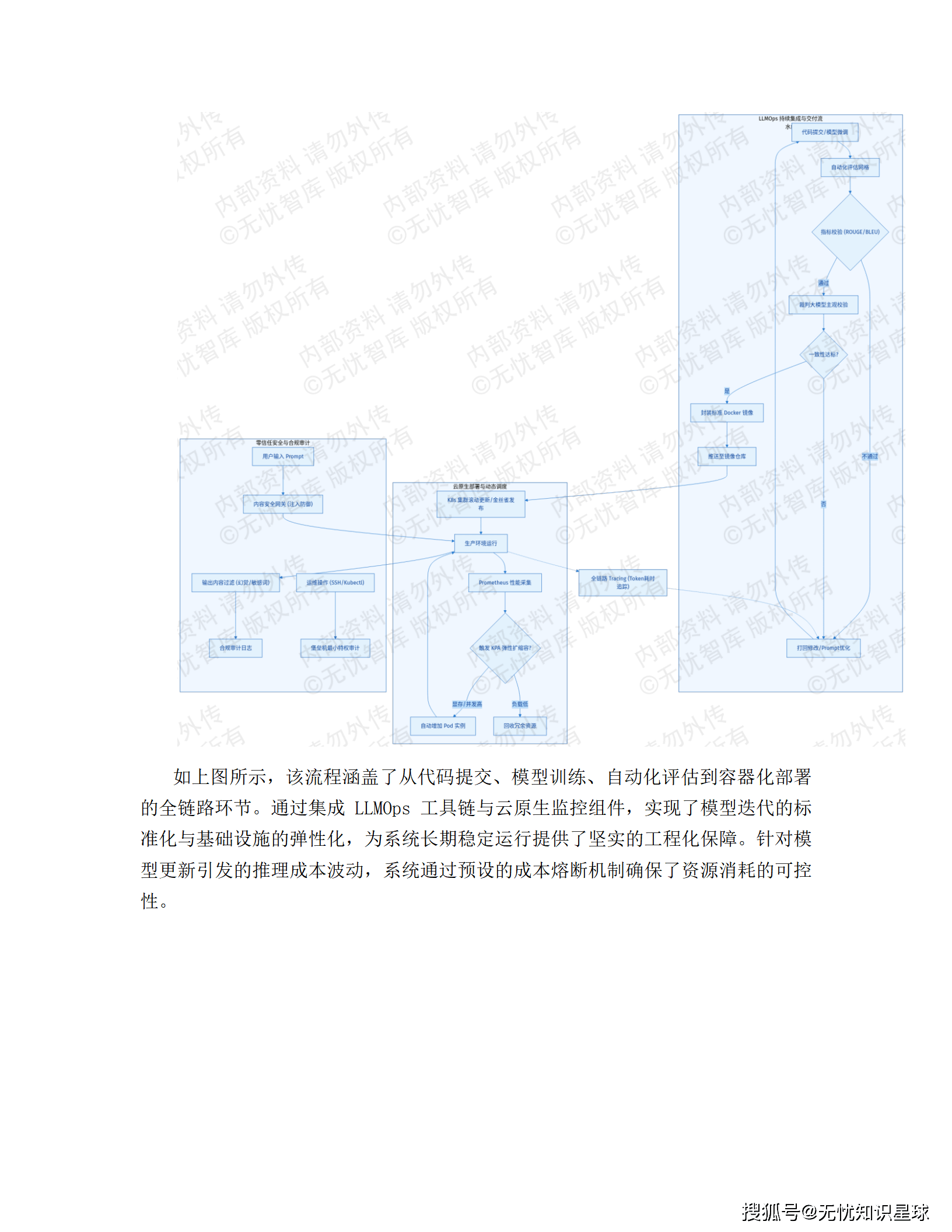
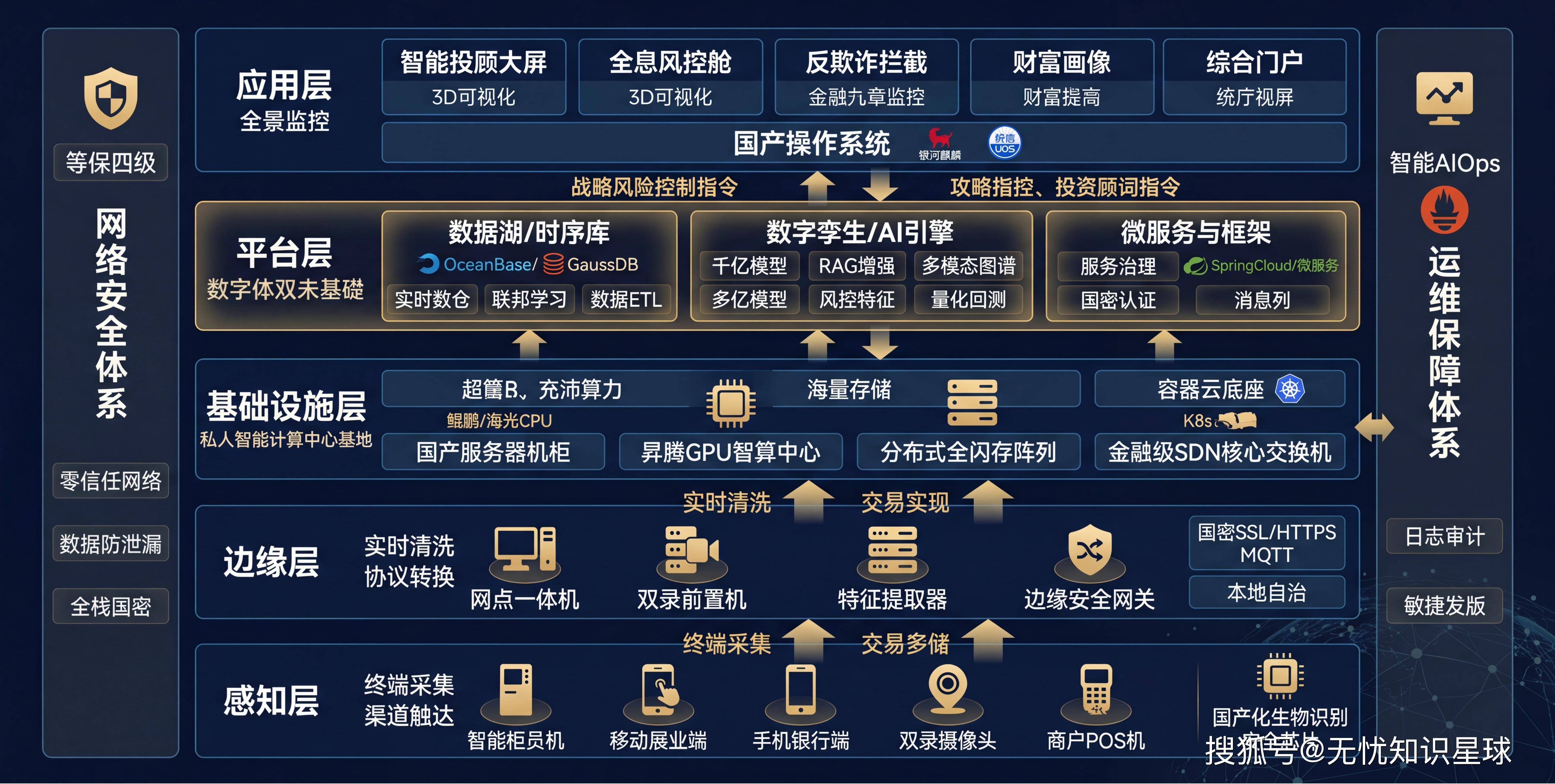
三、技术架构全景解析
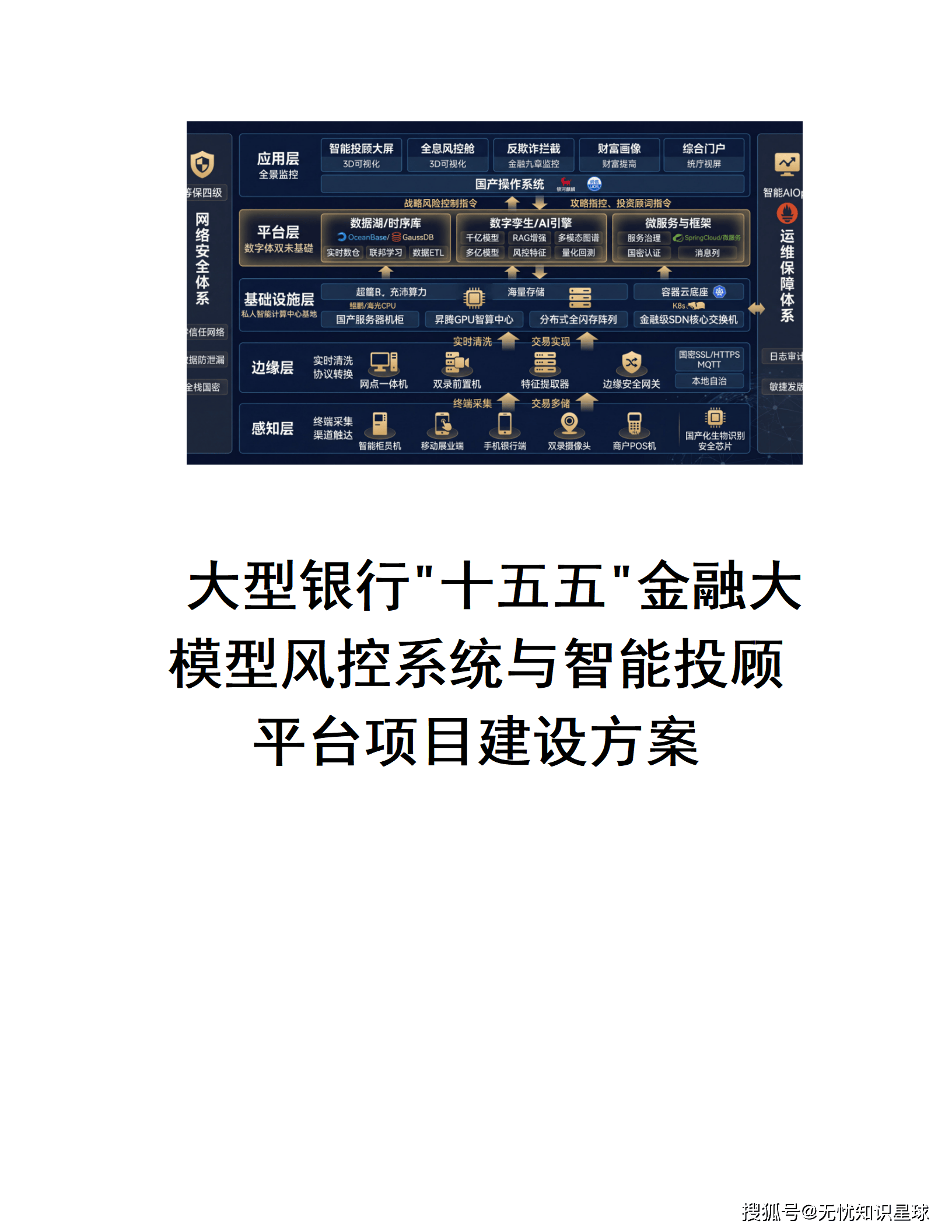
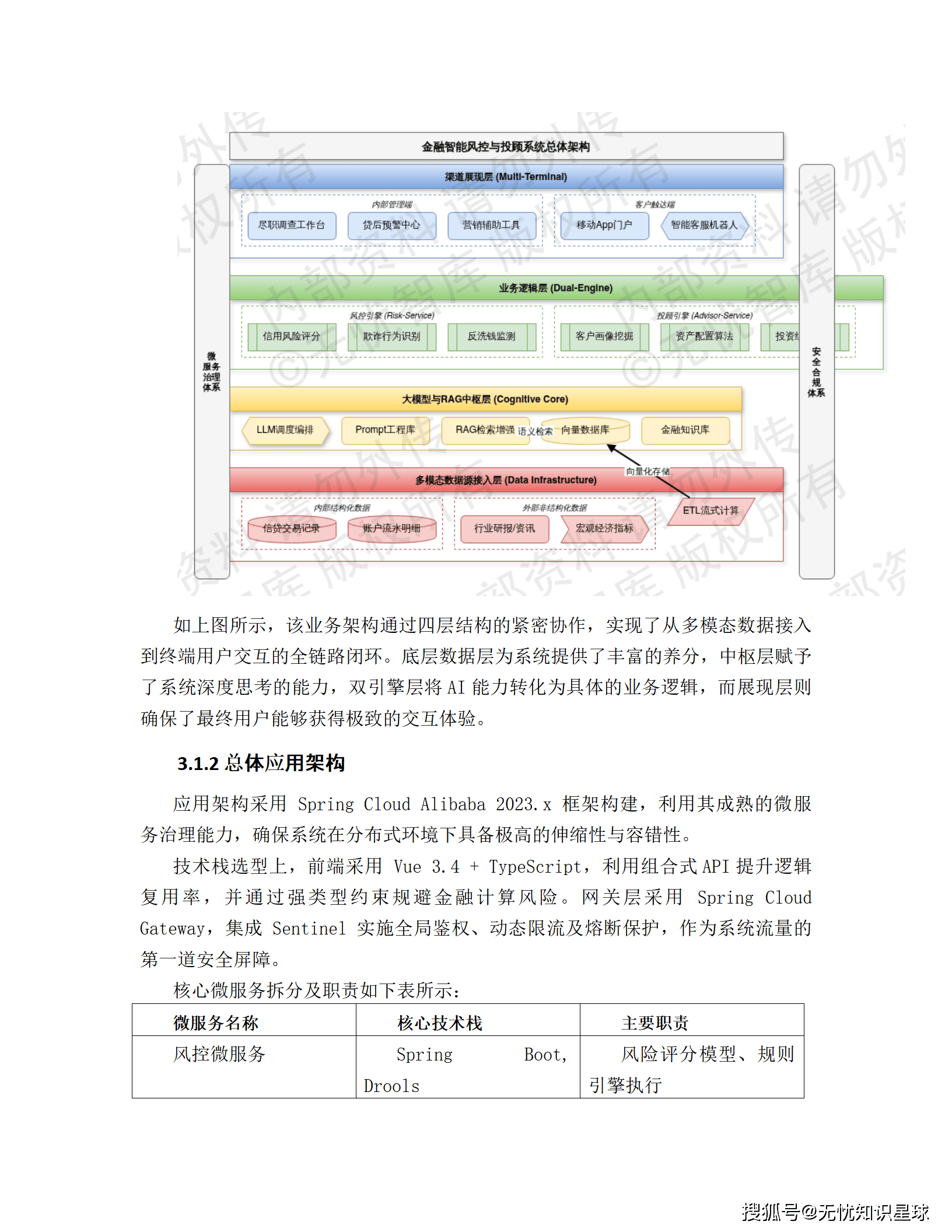
3.1 总体架构:四层协同的云原生体系
系统遵循 "数据驱动、模型中枢、双引擎协同" 的设计逻辑,自下而上划分为四个核心层级:
┌─────────────────────────────────────────────────────────┐
│ 渠道展现层 │
│ 信贷工作台 │ 理财经理辅助 │ 移动端智能客服 │
├─────────────────────────────────────────────────────────┤
│ 业务逻辑层 │
│ 风控引擎(信用评分/欺诈识别) │
│ 投顾引擎(资产配置/客户画像) │
├─────────────────────────────────────────────────────────┤
│ 大模型与RAG中枢层 │
│ LangChain Agent调度 │ Milvus向量数据库 │
│ Qwen-72B / Baichuan2-53B 双轨并行 │
├─────────────────────────────────────────────────────────┤
│ 多模态数据源接入层 │
│ 结构化数据(信贷记录/流水) │ 非结构化数据(研报/新闻) │
└─────────────────────────────────────────────────────────┘
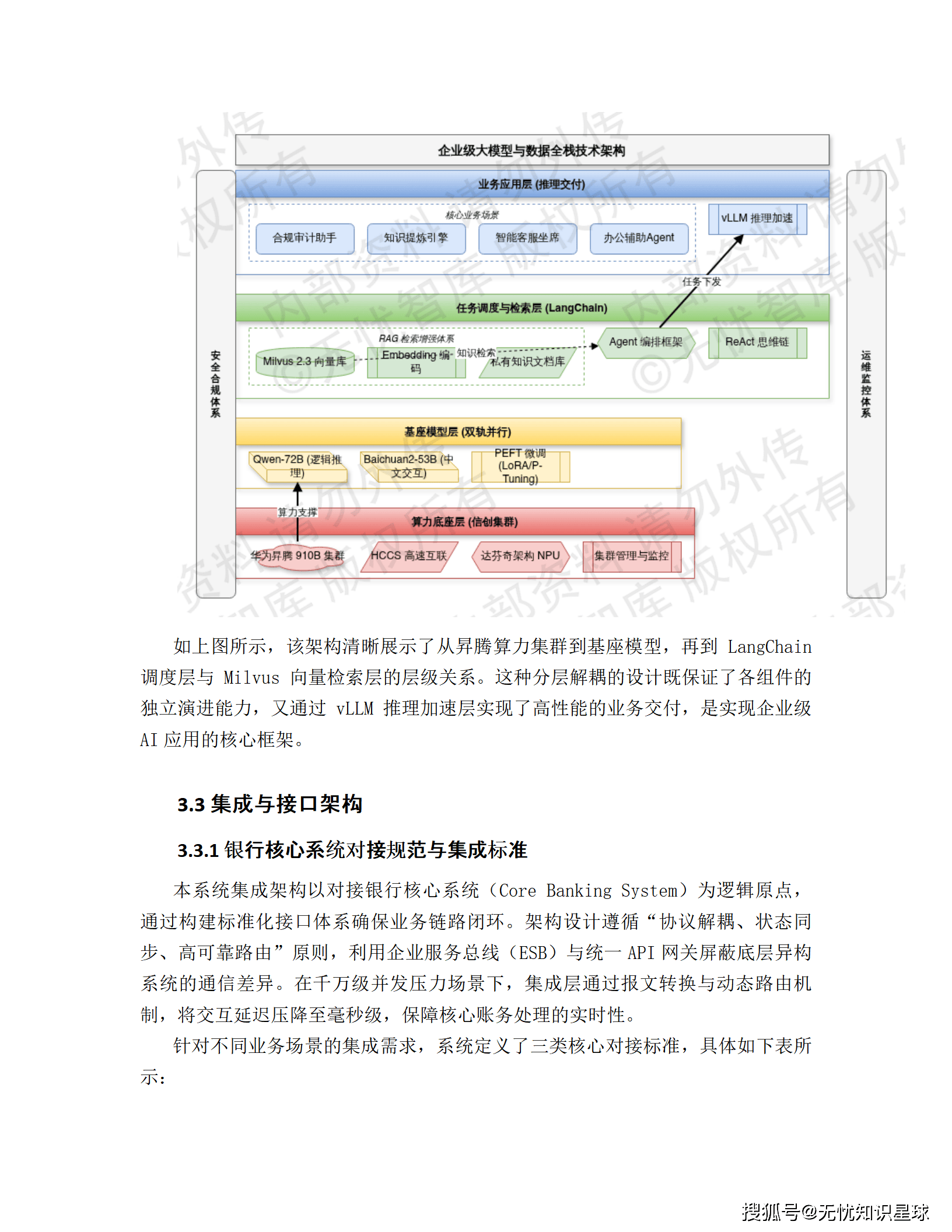
3.2 大模型技术架构:国产算力 + 双模型策略
🖥️ 算力底座:华为昇腾910B集群
- 配置: 8节点/64卡,单卡320 TFLOPS (FP16)
- 互联: HCCS高速互联技术解决多节点通信瓶颈
- SLA: 99.9%的稳定运行保障
🤖 基座模型:双轨并行策略
技术亮点: 采用LoRA与P-Tuning v2等参数高效微调(PEFT)技术,在保留基座模型通用泛化能力的基础上注入行业私有知识。
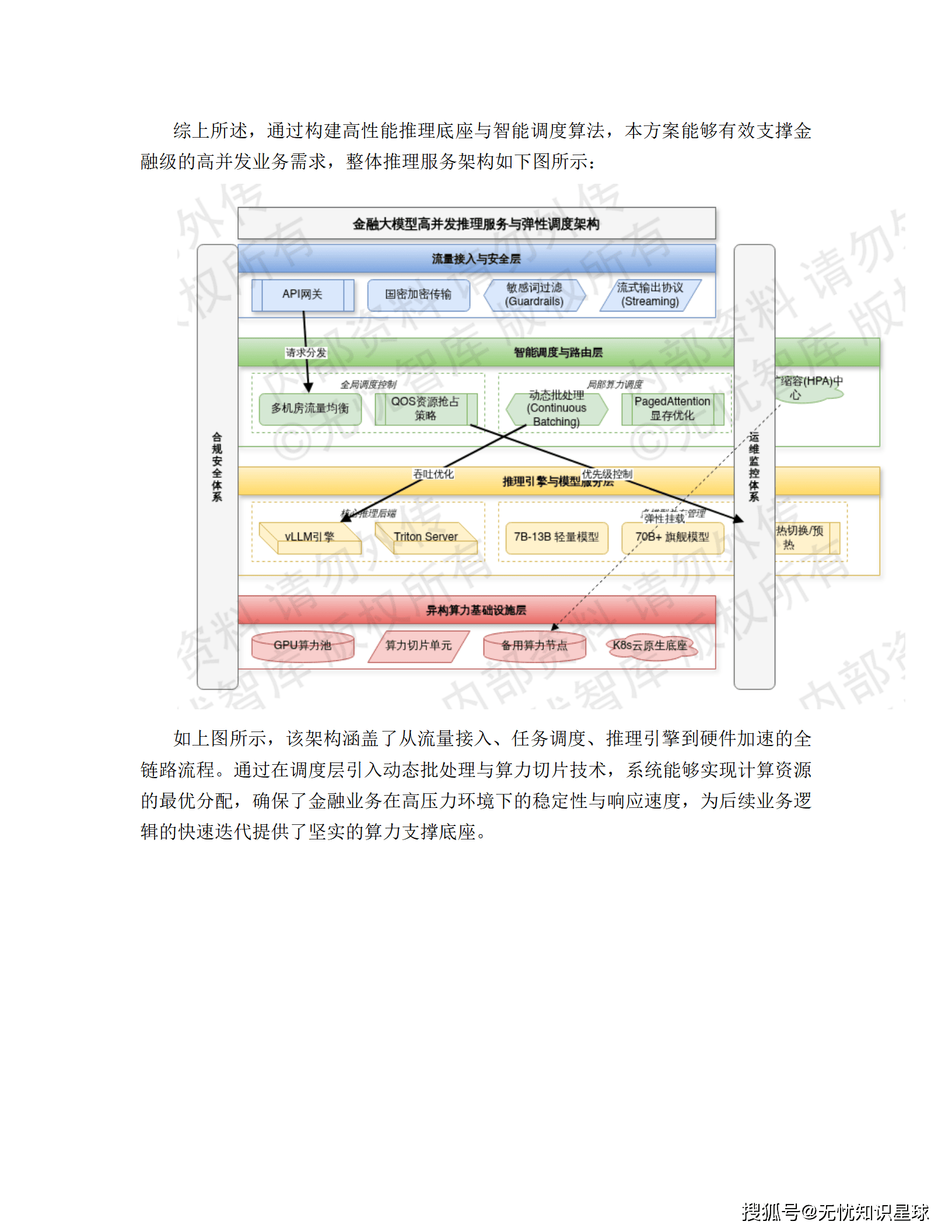
⚡ 推理加速:vLLM框架
- 利用PagedAttention技术优化KV Cache显存管理
- Continuous Batching动态批处理技术,单卡吞吐量提升2-4倍
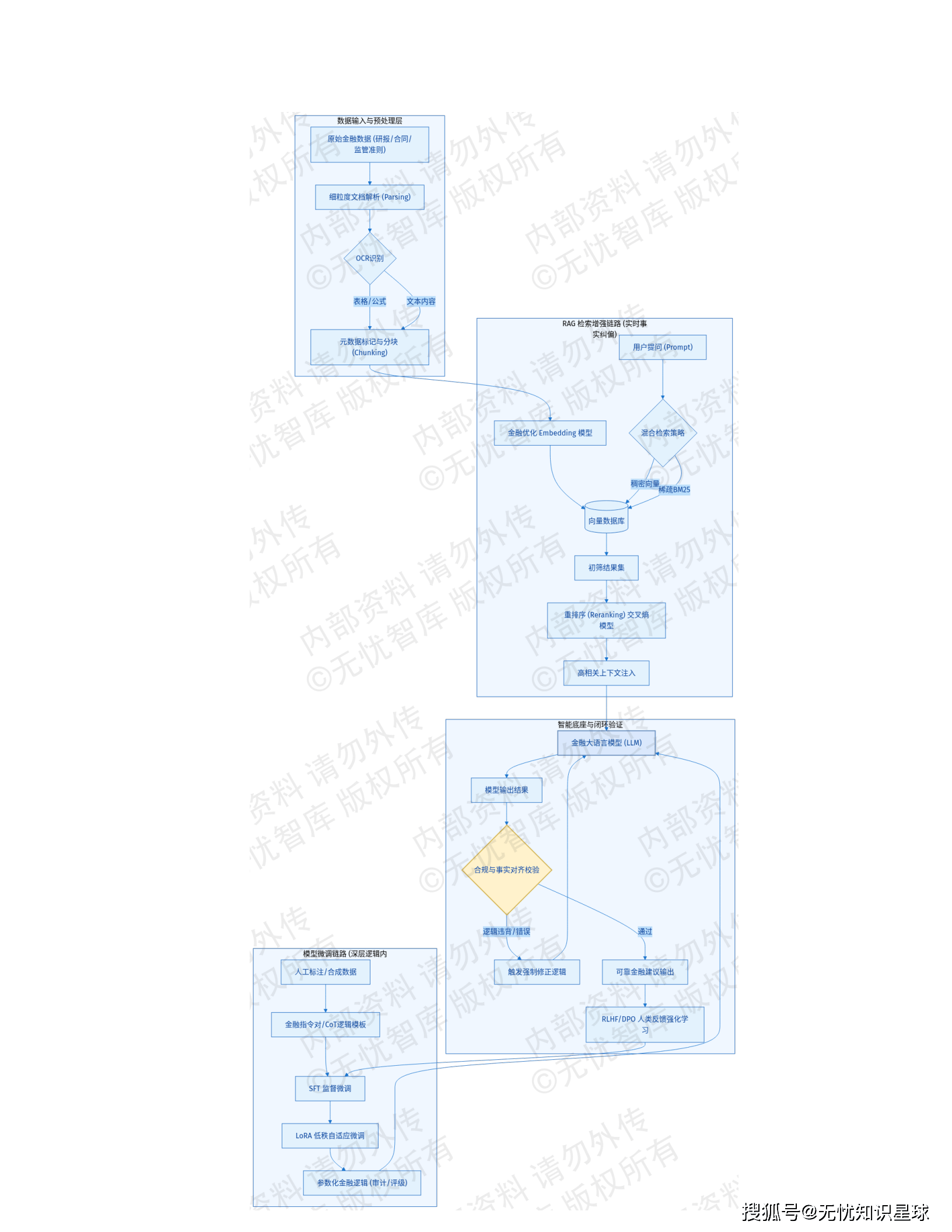
3.3 RAG架构:解决大模型"幻觉"问题的关键
系统外挂Milvus 2.3分布式向量数据库构建RAG体系:
金融文档 → 向量化 → Milvus存储 → 检索增强 → LLM生成
↑
混合检索策略
(稠密向量+BM25稀疏向量)
↓
重排序(Reranking)
核心指标: Milvus 2.3凭借HNSW索引实现百亿级向量数据的毫秒级检索。
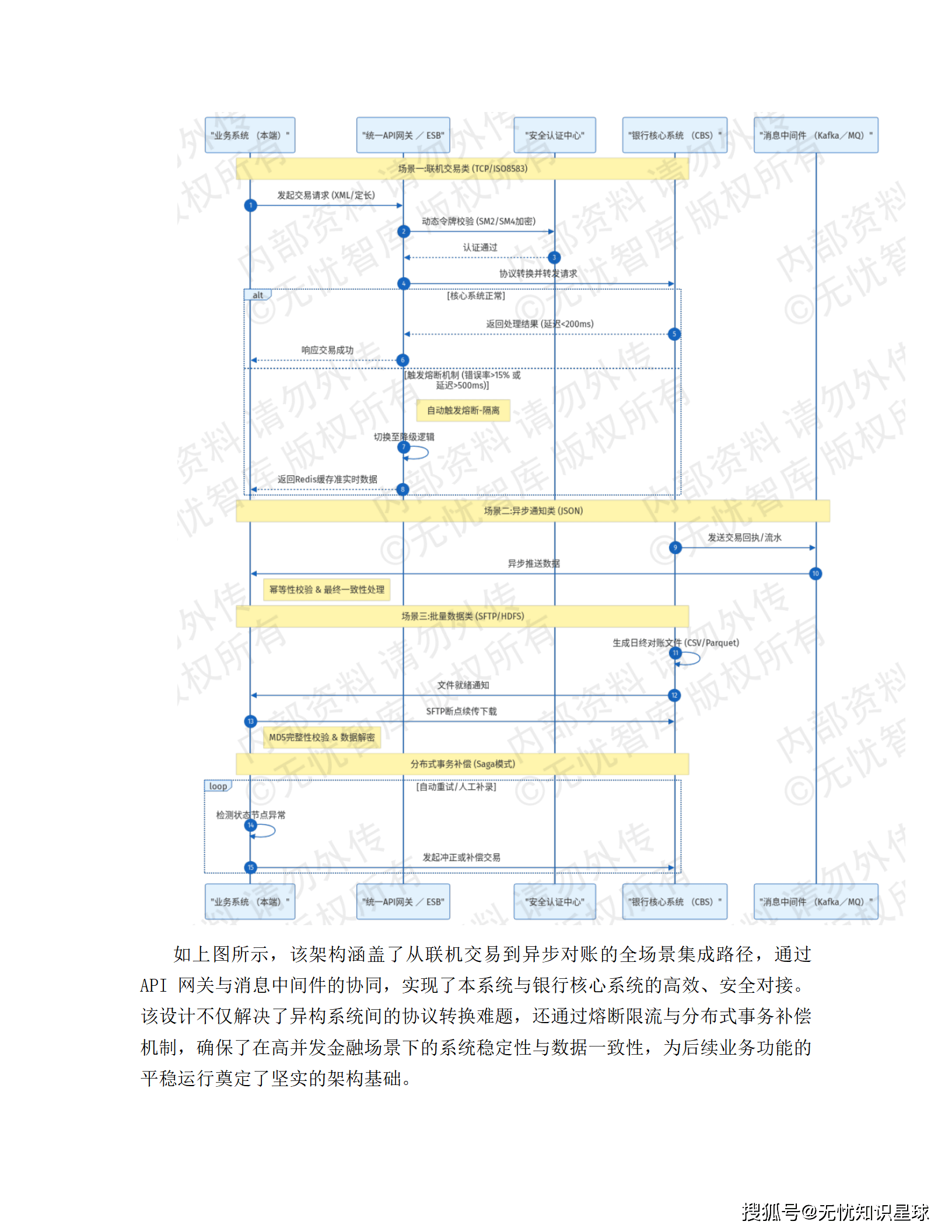
3.4 微服务应用架构
采用 Spring Cloud Alibaba 2023.x + Dubbo 3.x 框架:
高可用设计: 当调度服务响应超过3000ms或异常率达20%时,Sentinel自动触发熔断,业务降级至本地规则引擎。
四、智能风控系统功能深度解析
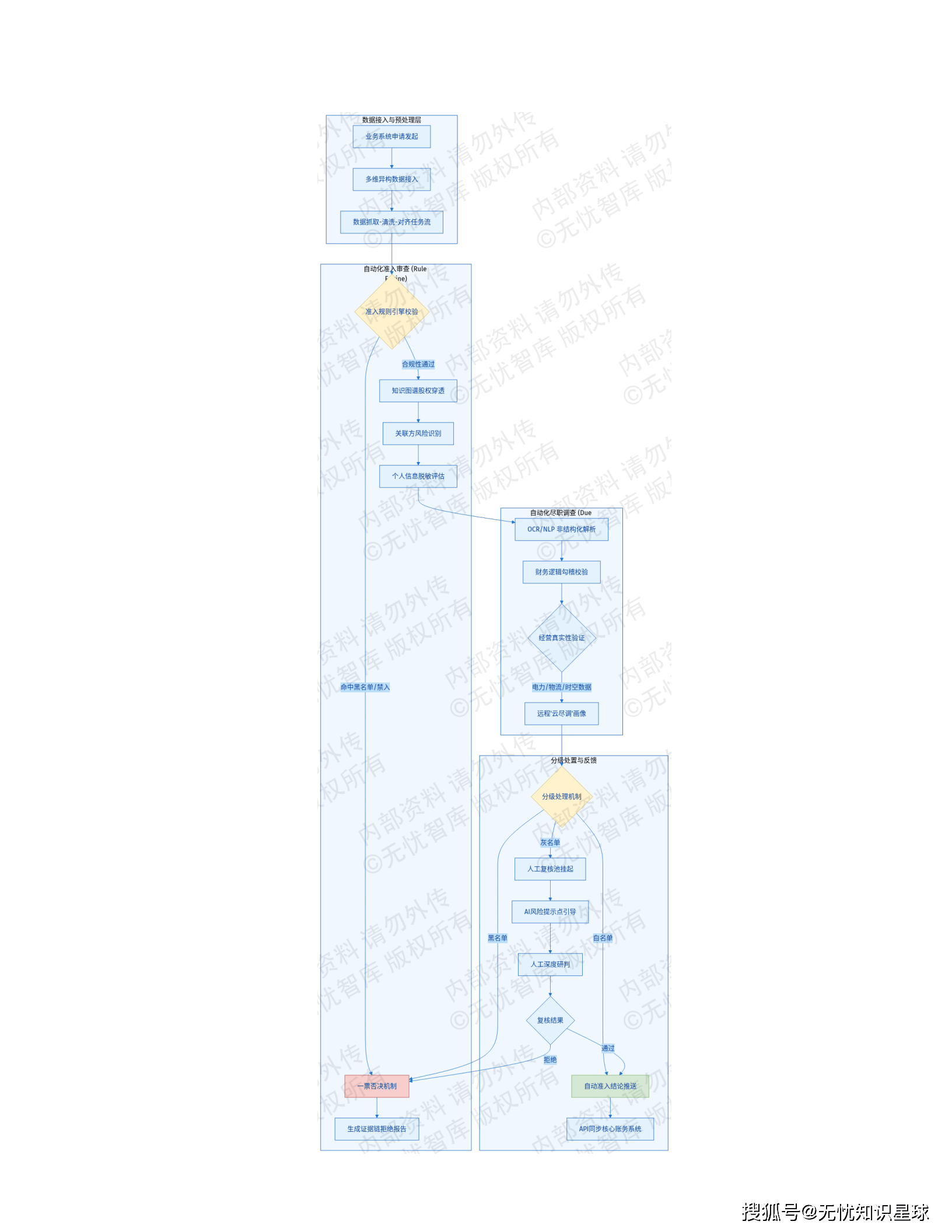
4.1 贷前智能审查模块 ------ 首道防御屏障
🔐 自动化准入与尽调
- 数据整合: 实时调用工商、征信、司法、舆情数据库
- 关联穿透: 知识图谱技术自动穿透股权结构,支持5层以上深度解析
- 一票否决: 命中黑名单、严重失信等硬性指标自动阻断
📄 自动化尽调(Due Diligence)
依托OCR与NLP技术对财报、税票、合同等非结构化文档进行深度解析:
- 提取关键财务指标
- 逻辑校验算法识别财务造假疑点(进销项税额不匹配、现金流异常波动)
- 时空轨迹分析与电力、物流数据交叉验证
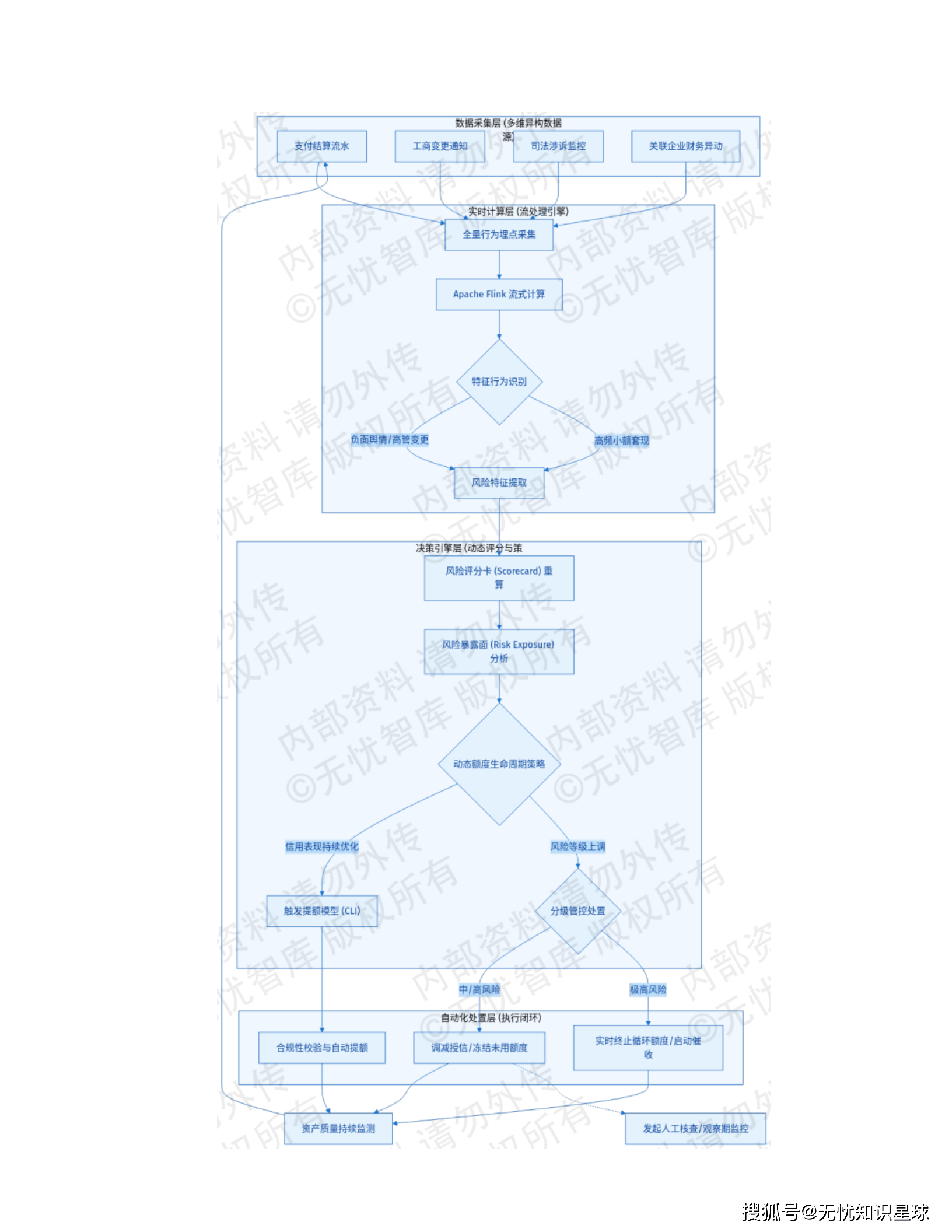
4.2 贷中动态监控模块 ------ 分钟级风险感知
📊 实时风险追踪体系
- 数据源: 支付结算流水、工商变更、司法涉诉、关联企业财务异动
- 计算引擎: Apache Flink流计算,对全量行为埋点实时聚合分析
- 触发机制: 识别重大负面舆情、法定代表人变更、高频小额跨行套现等特征行为
💰 动态额度生命周期管理
效果: 贷中管理平均响应时长(MTTR)从数日缩短至秒级。
4.3 贷后管理与处置模块 ------ 风险防御最后防线
🚨 风险事件捕捉机制
- 毫秒级异动探测:分布式任务调度框架
- 关联分析: 自动关联合同余额、担保方式、五级分类状态
📋 智能处置策略矩阵
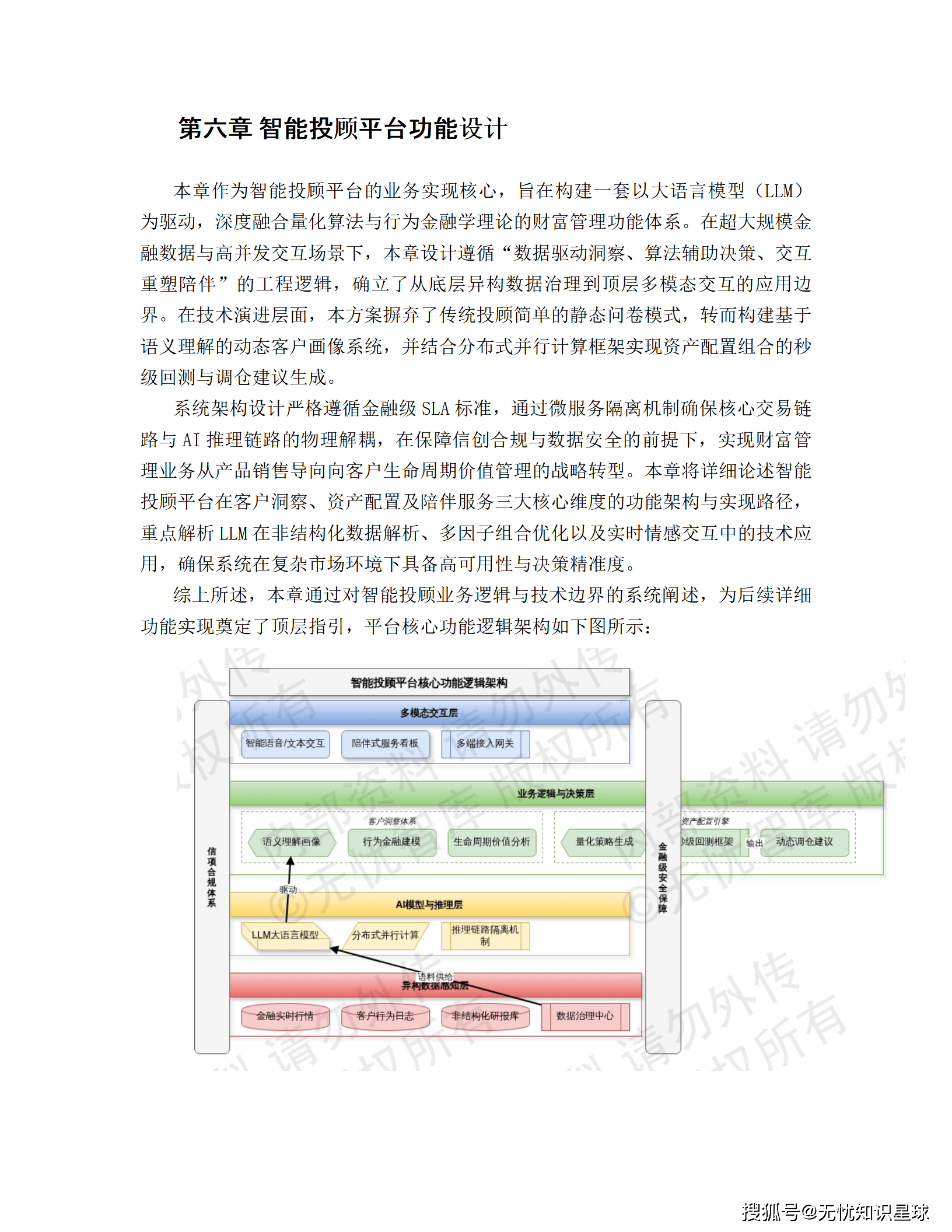
五、智能投顾平台功能深度解析
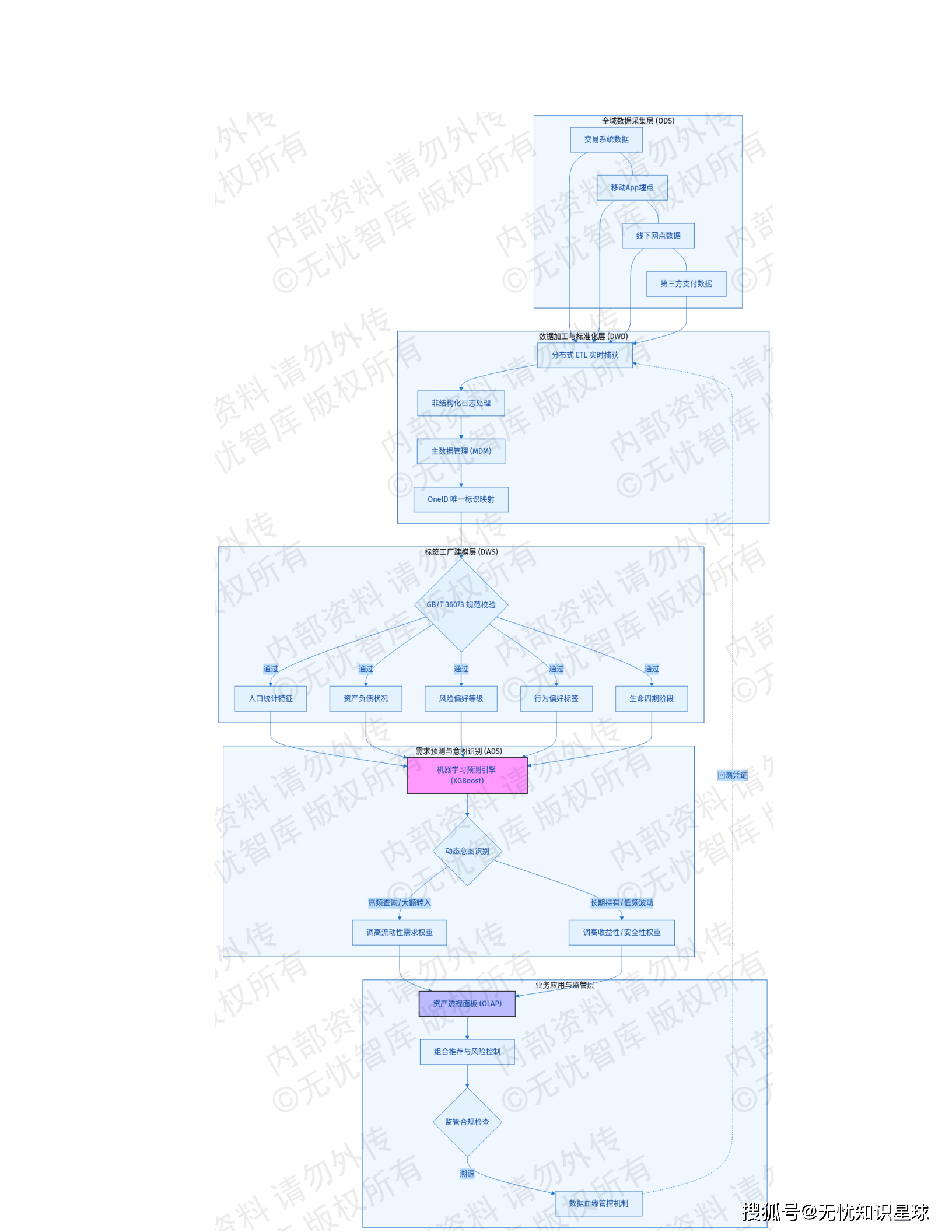
5.1 客户洞察与画像模块 ------ 数据驱动的客户理解
🏗️ 湖仓一体化架构
- ODS层: 原始数据采集(交易系统、移动终端、第三方支付埋点)
- DWD层: 结构化处理 + OneID映射
- DWS层: 五大标签体系(人口统计、资产负债、风险偏好、行为偏好、生命周期)
🤖 需求预测引擎
- 算法: XGBoost对客户申赎行为进行意图预测
- 指标: 模型AUC值 > 0.85,支持日级重训
场景案例: 当系统识别到客户近期频繁查询货币基金且有大额资金转入记录时,意图识别模型自动调高其流动性需求标签权重。
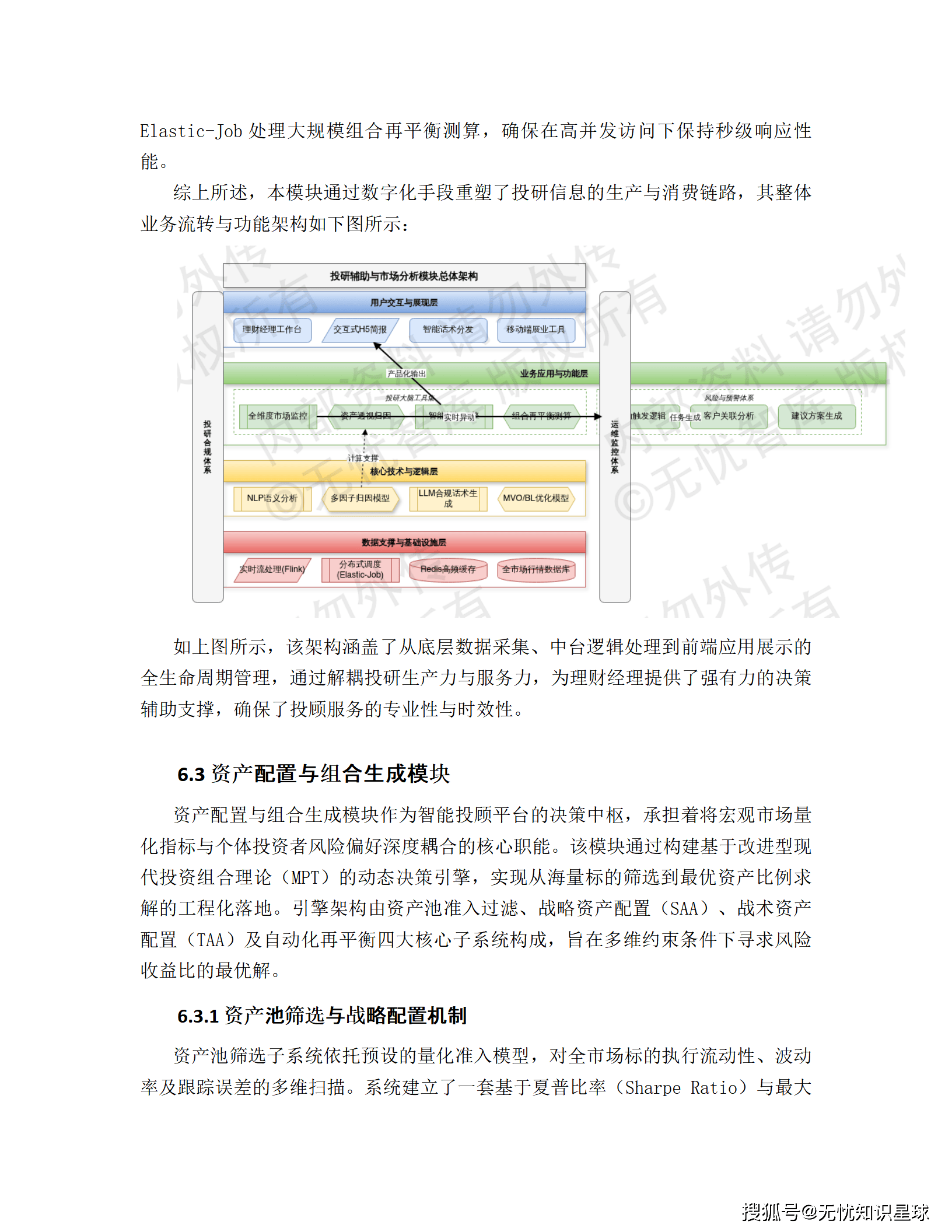
5.2 投研辅助与市场分析模块 ------ 理财经理的"AI副驾驶"
📈 全维度市场监控与预警
- 状态机模型: "异动触发-逻辑研判-任务生成"自动化链路
- 触发场景: 净值异常波动、基金经理变更、信用评级下调
🔬 深度资产透视与归因分析
一键生成包含以下指标的图形化报告:
- Brinson归因
- 风格箱偏移
- 最大回撤修复周期
技术支撑: Redis缓存高频查询结果,Elastic-Job处理大规模组合再平衡测算。
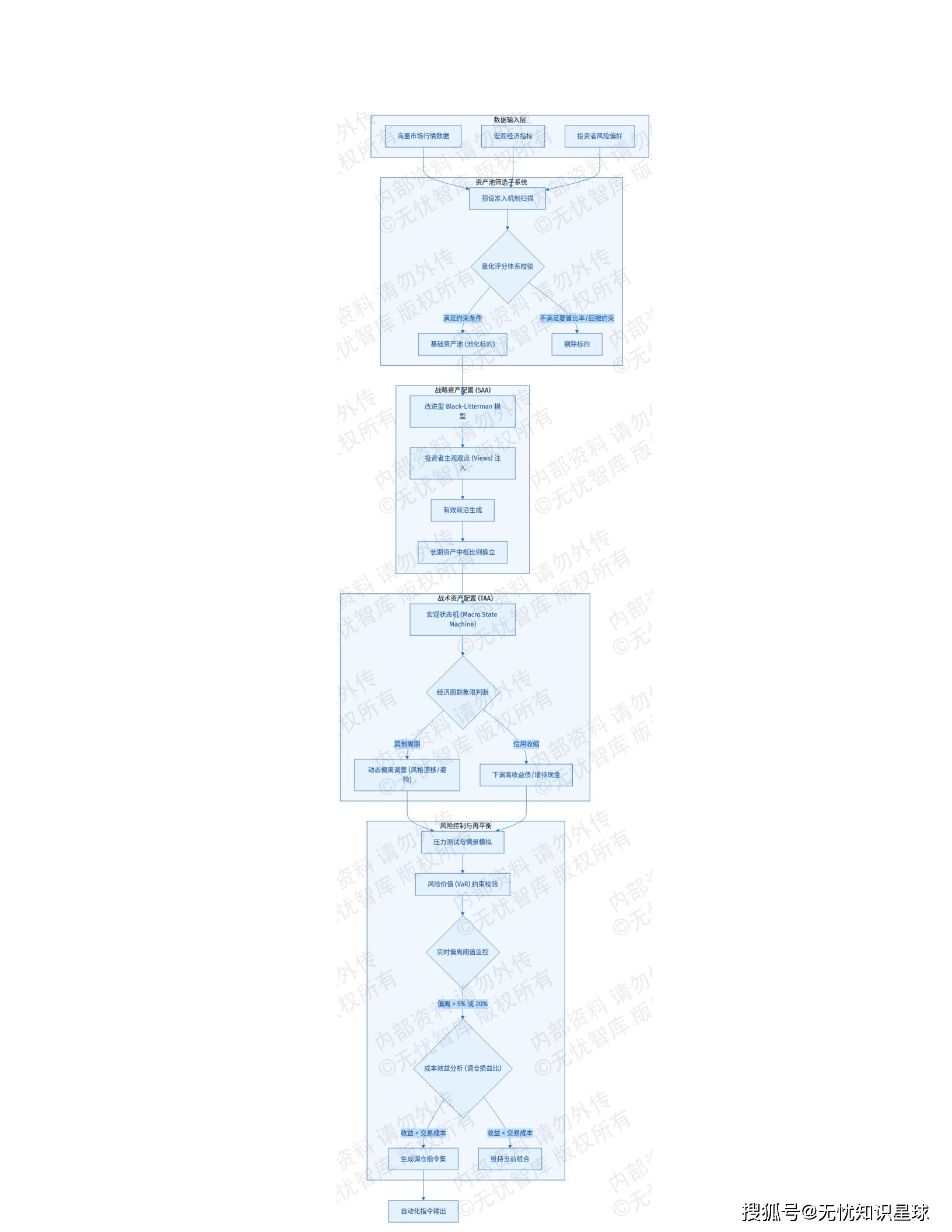
5.3 资产配置与组合生成模块 ------ 决策中枢
🎯 战略资产配置(SAA)
采用改进的Black-Litterman模型,通过引入投资者主观观点并配置置信度权重,修正传统均值-方差模型对输入参数过度敏感的缺陷。
⚡ 战术资产配置(TAA)
集成宏观状态机,根据通胀率、利率曲线及信用利差等前瞻指标判定经济周期象限:
场景案例: 在信用收缩周期,引擎自动下调高收益债配比,增持现金类资产。
🔄 再平衡触发机制
当实际资产比例偏离目标比例超过预设阈值(如绝对偏差5%)时,引擎自动计算调仓损益比,仅当预期超额收益覆盖交易成本时才下达指令。
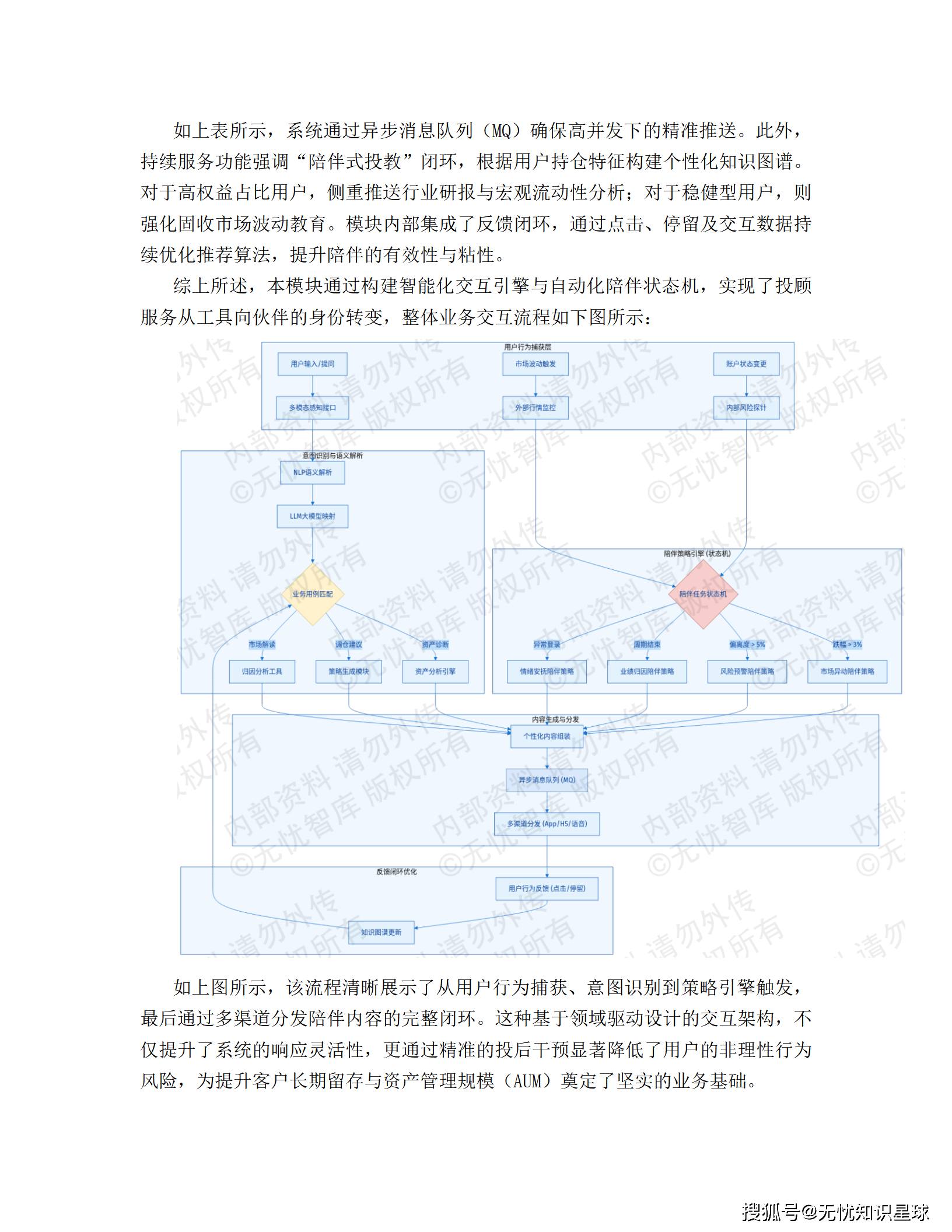
5.4 交互式服务与投后陪伴模块 ------ 从交易到陪伴
💬 智能交互意图识别
整合NLP与LLM,对用户输入进行深度语义解析,映射至具体业务用例(资产诊断、调仓建议、市场归因)。
📱 投后陪伴状态机
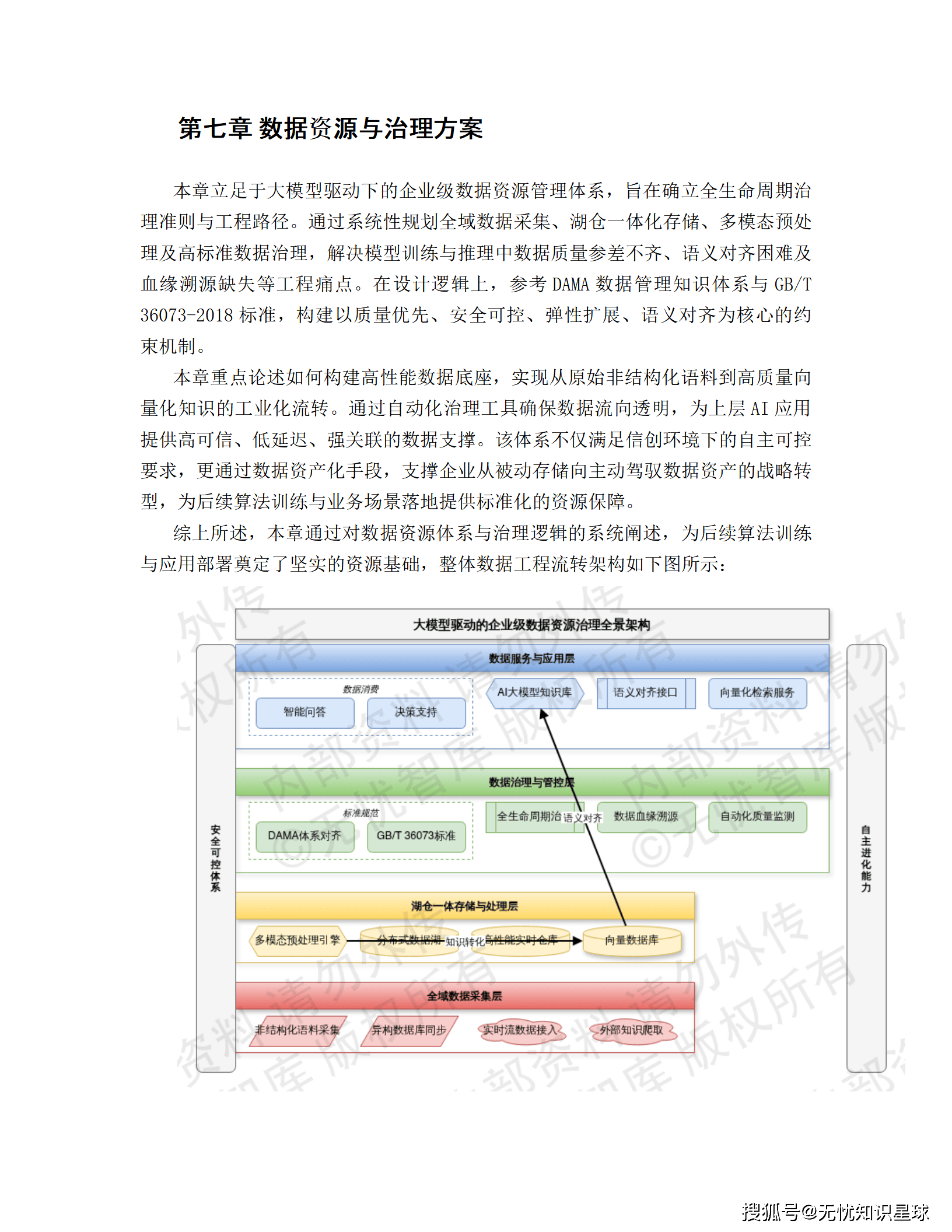
六、数据治理与向量化知识库
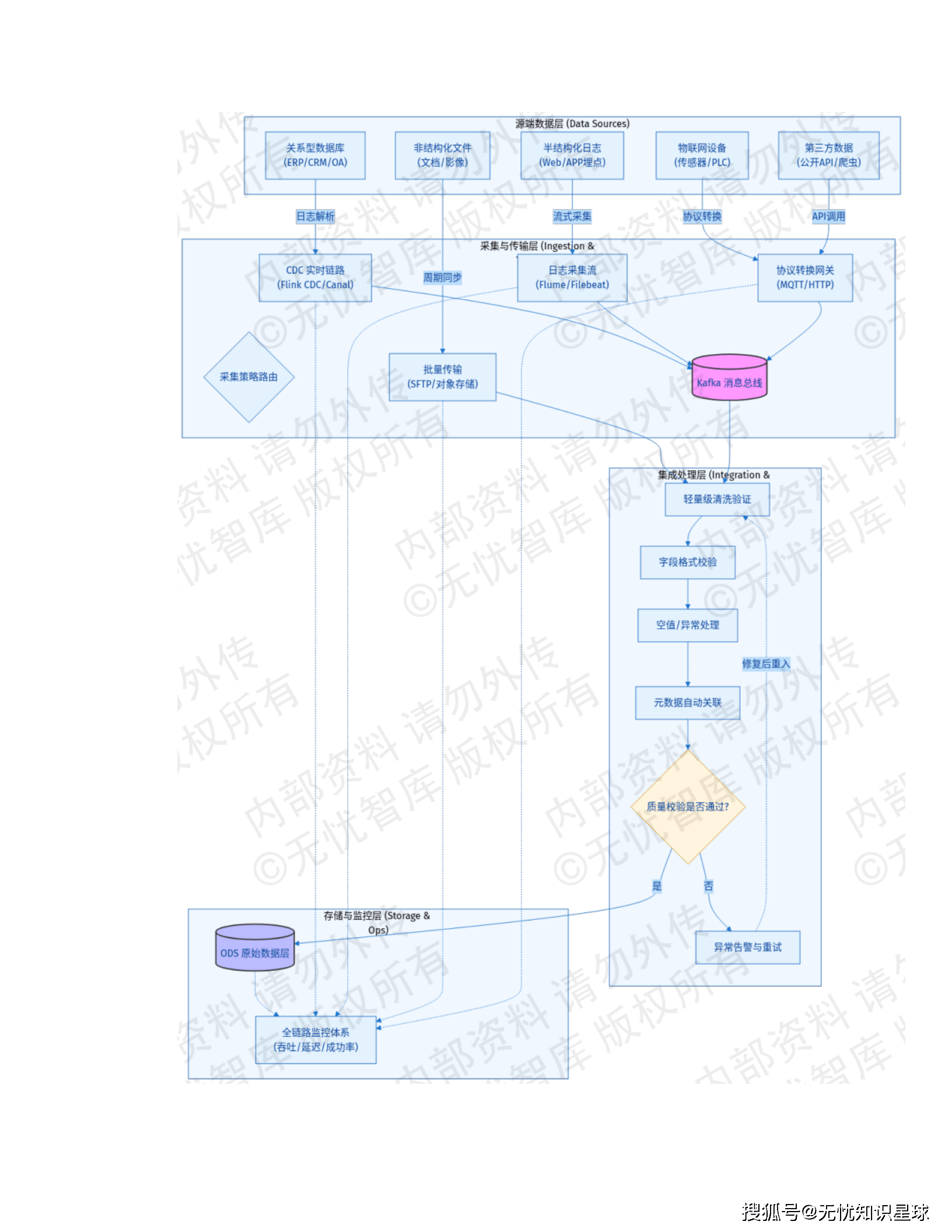
6.1 多源异构数据汇聚
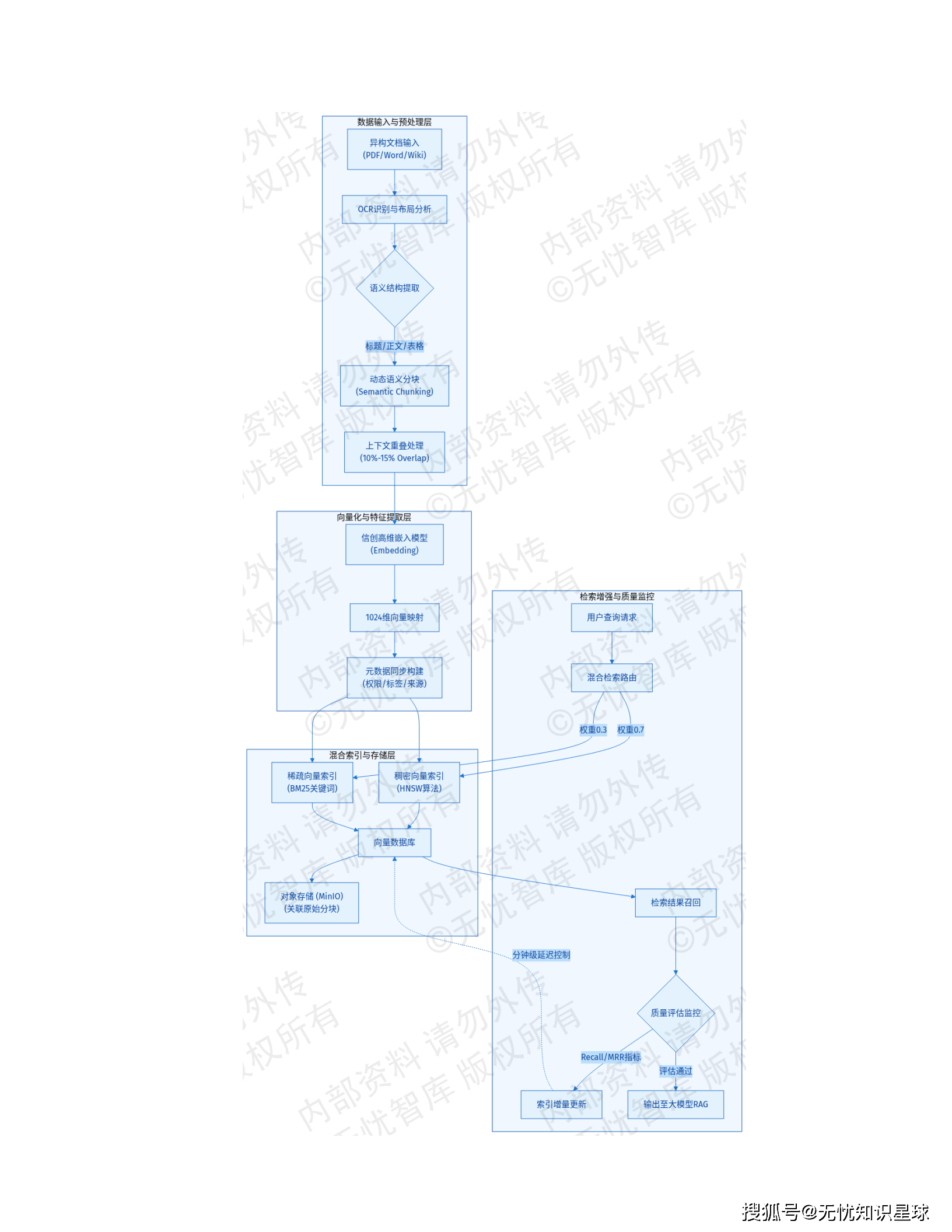
6.2 向量化与知识库构建
📝 语义分块策略
- 算法: 基于语义边界的动态分块(Semantic Chunking)
- 重叠机制: 10%-15%上下文重叠,解决跨块语义断层
🔍 混合检索架构
- 稠密向量: 捕捉深层语义相关性(1024维)
- 稀疏向量: BM25算法精确关键词匹配
- 索引算法: HNSW实现毫秒级大规模向量近邻搜索
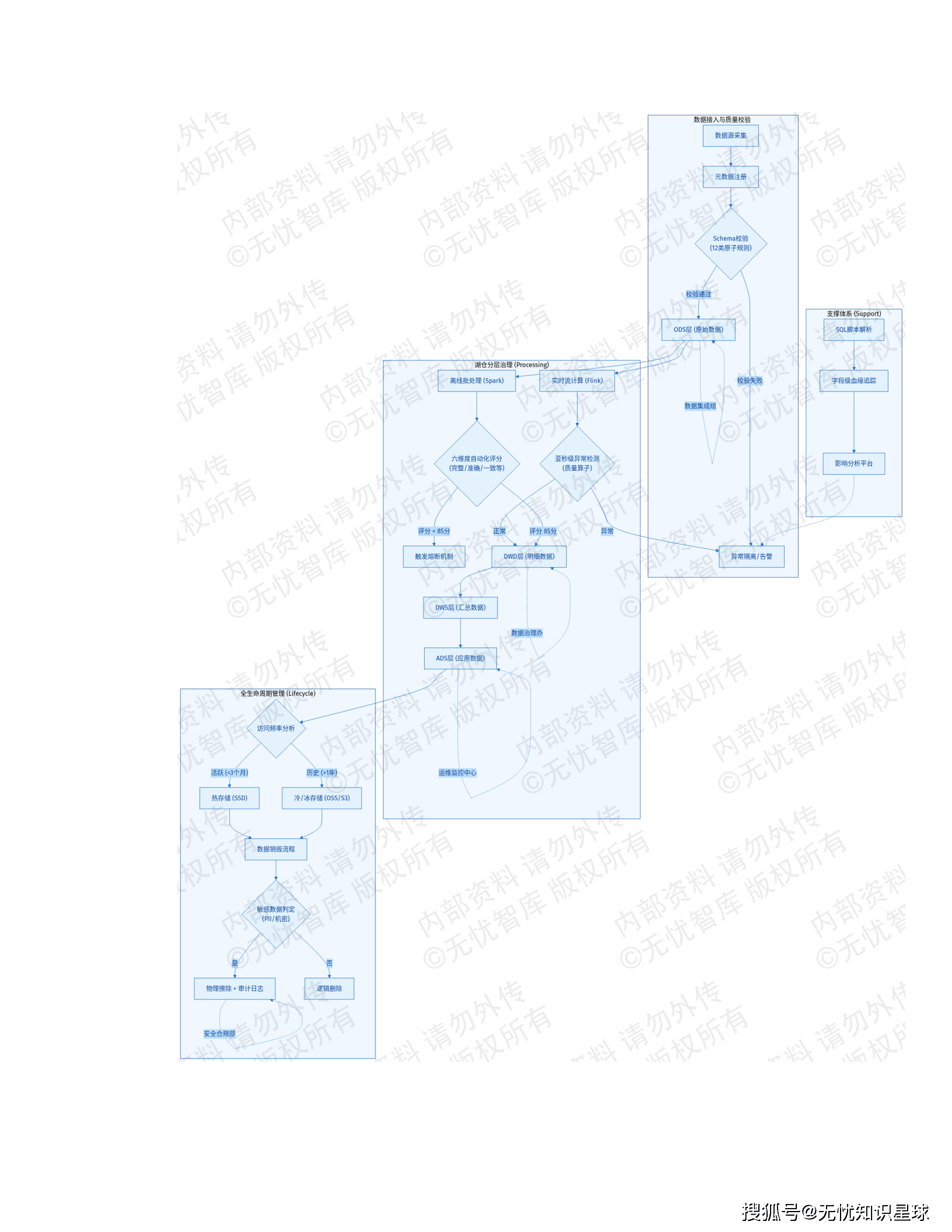
6.3 数据质量与生命周期管理
参照GB/T 36073-2018标准,建立"事前预防、事中监控、事后治理"闭环机制。
存储分级策略:
- 热存储(<3个月): SSD高性能存储
- 冷存储(>1年): 对象存储(OSS/S3)归档
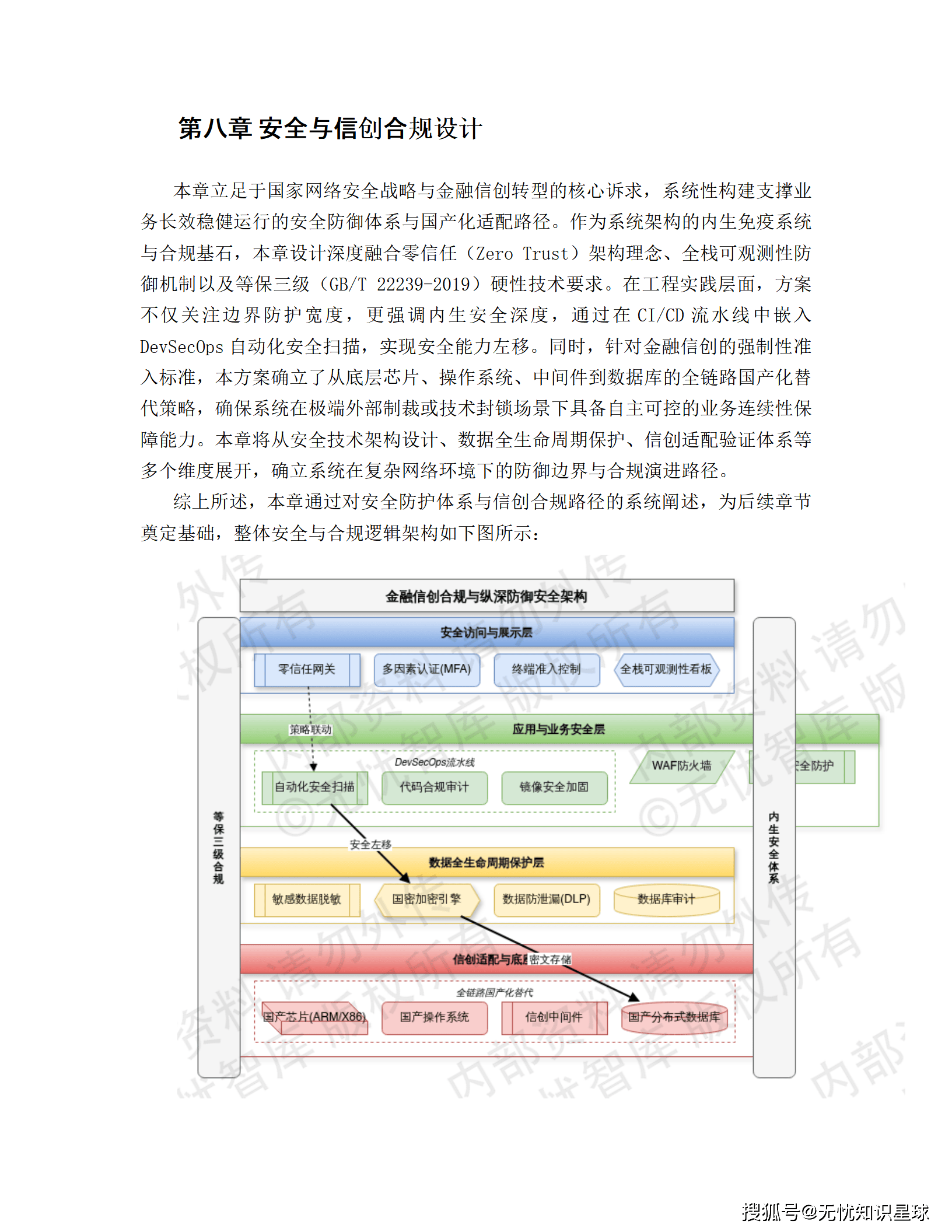
七、安全与信创合规设计
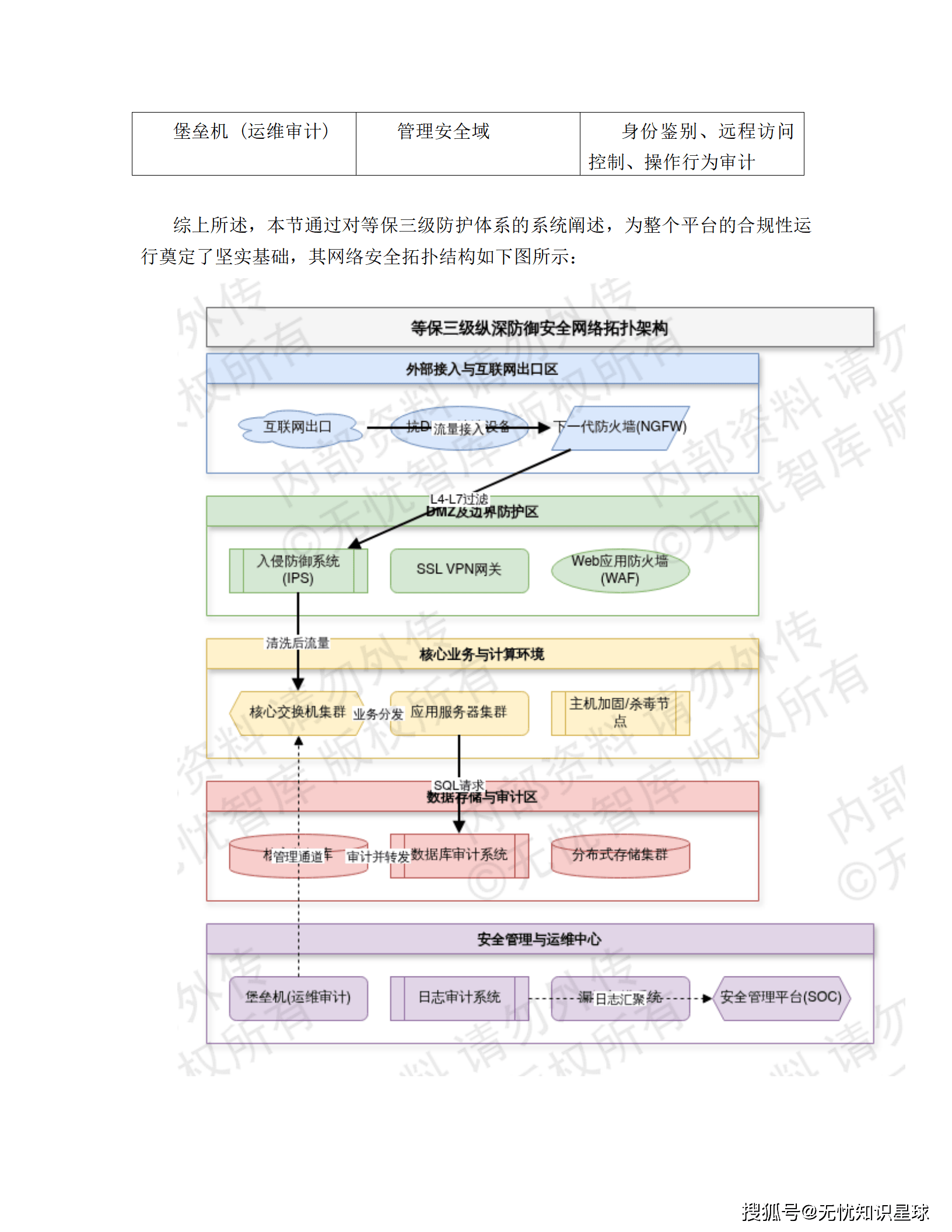
7.1 等保三级防护体系
遵循"一个中心、三重防护"架构:
- 安全管理中心: 日志审计、协议审计、数据库审计
- 通信网络: 国密IPsec/SSL VPN加密隧道
- 区域边界: NGFW + IPS
- 计算环境: 主机加固 + 漏洞扫描
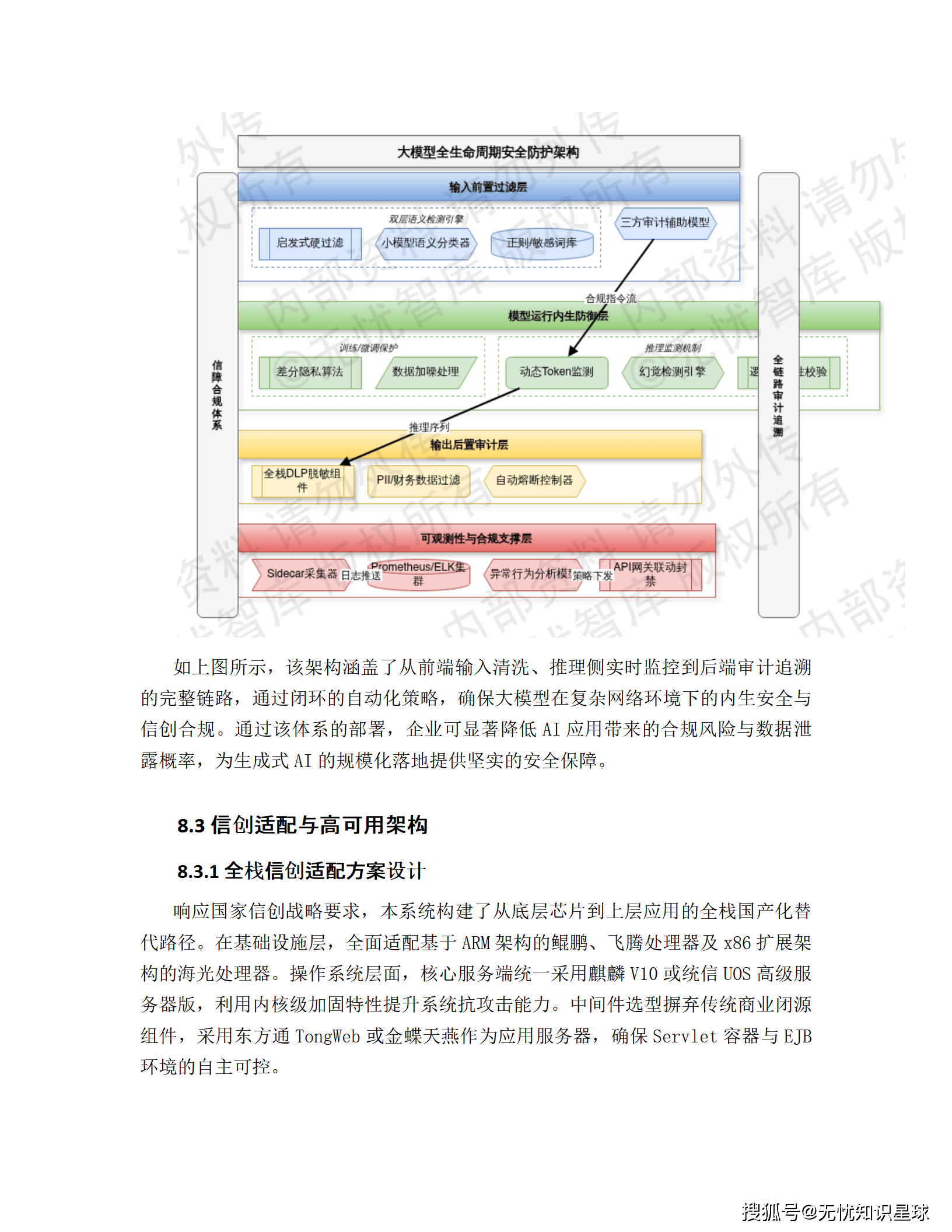
7.2 大模型专属安全设计
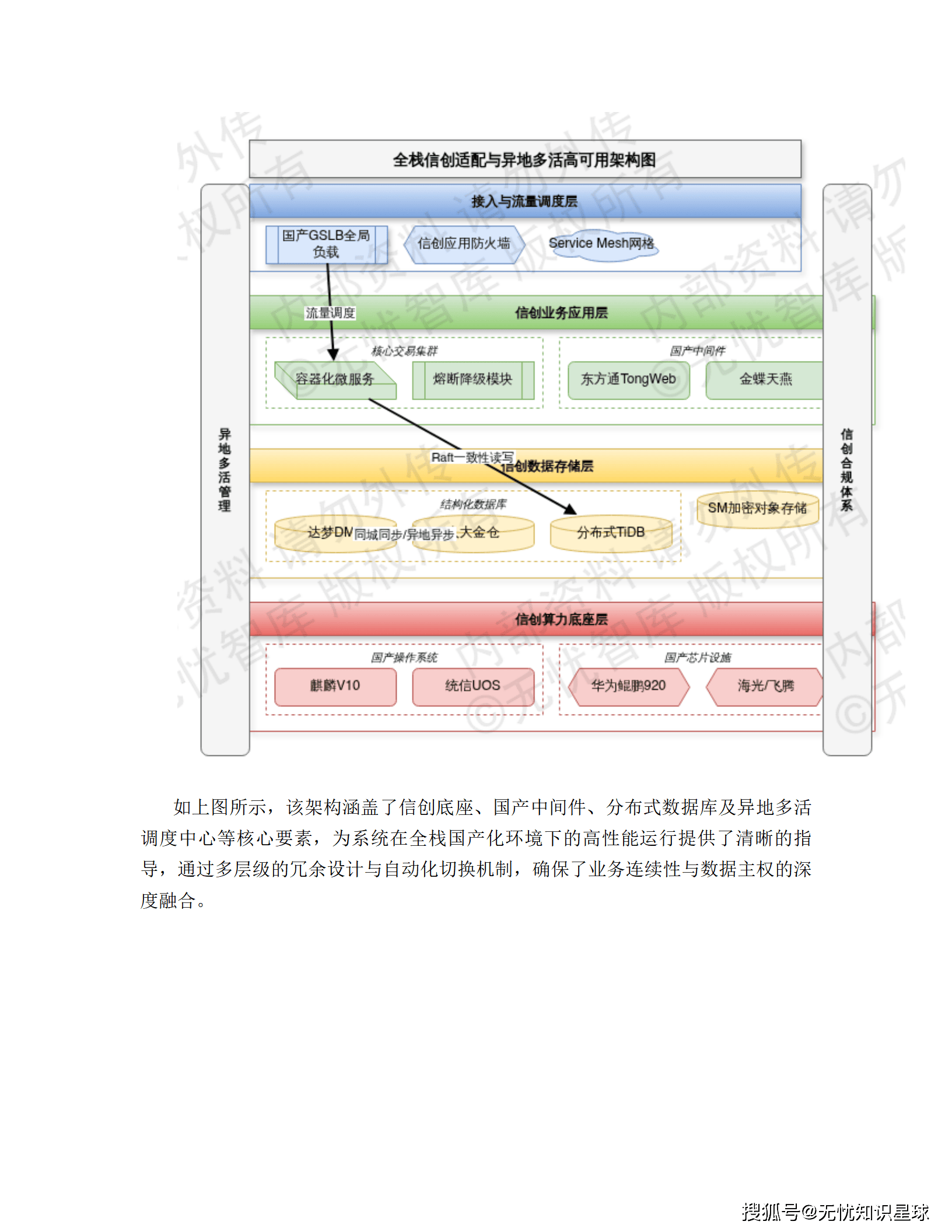
7.3 全栈信创适配
7.4 高可用架构:"两地三中心"
- RTO(恢复时间目标): <30秒
- RPO(恢复点目标): 同城0,异地异步补偿
八、实施路径与投资效益
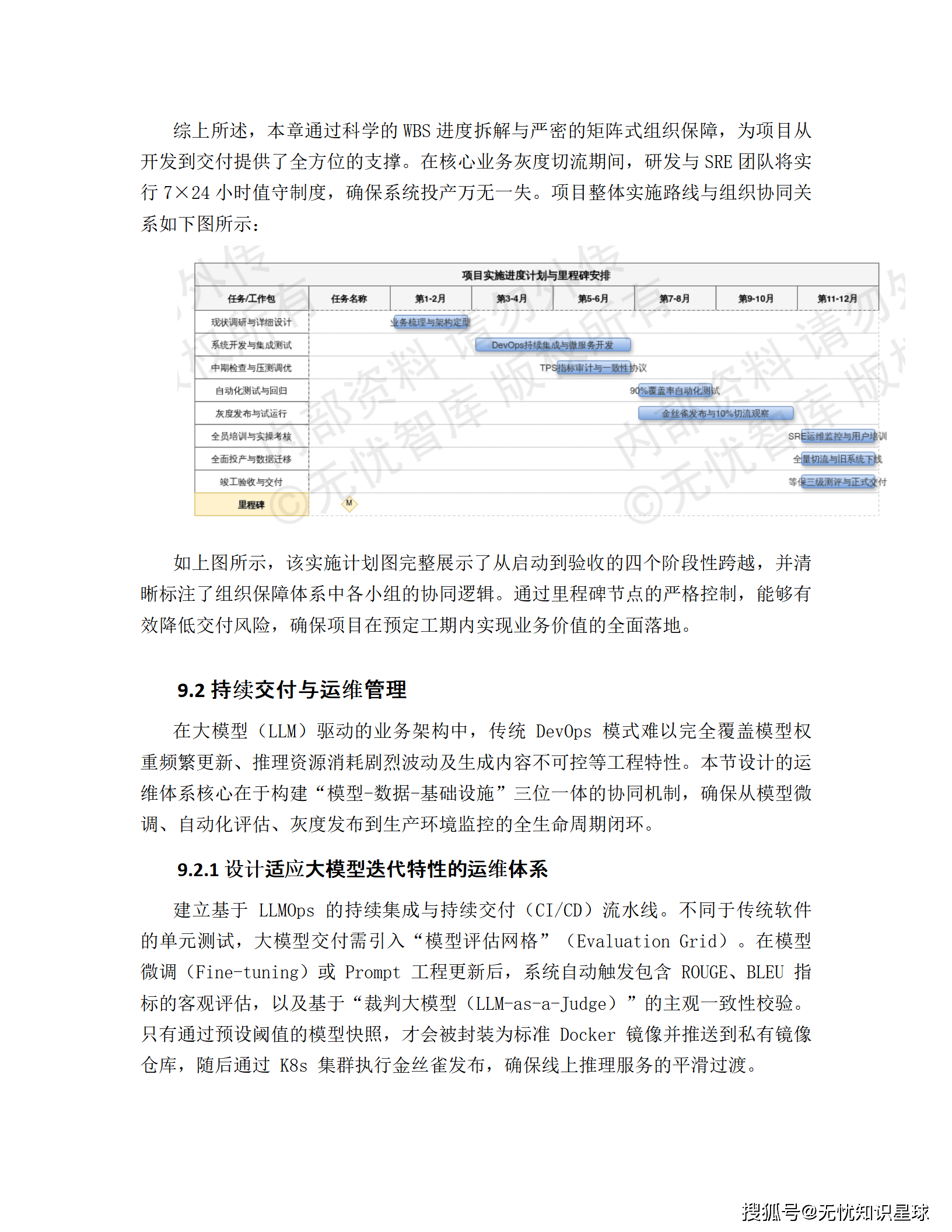
8.1 实施计划(12个月)
8.2 预期效益
直接经济效益:
- 基础架构运维人力成本下降约35%
- 计算资源综合利用率提升40%以上
- 业务峰值QPS提升5倍以上
- 平均修复时间(MTTR)缩短60%
业务效能提升:
- 非结构化数据处理效率提升300%
- 智能投顾方案生成时间 < 3秒
- 理财经理服务半径从百人到千人量级跨越
💡 总结与展望
本项目通过私有化部署的大模型底座 + RAG检索增强 + 双引擎业务协同的技术路线,系统性地解决了传统银行在风控与投顾领域的三大核心痛点:
- 非结构化数据处理效率低 → 大模型长文本理解 + 自动化解析
- 投顾策略滞后于市场 → 实时研报摘要 + 动态资产配置
- 风险预警存在时间差 → 流式计算 + 毫秒级异动探测
在"十五五"金融数字化转型的浪潮中,大模型不再是锦上添花的概念,而是决定银行核心竞争力的战略基础设施。本项目为大型金融机构提供了一个从架构设计到工程落地的完整参考范式。
核心启示: 金融大模型的工程化落地,关键在于"私有化部署保安全、RAG架构控幻觉、微服务治理保高并发"三位一体的系统性设计。