NL2SQL落地的隐形基石:为什么必须要有元数据库?
1. 先搞懂:NL2SQL到底难在哪里?
NL2SQL(自然语言转SQL)听起来很美好:业务人员不用学SQL,直接说"帮我查一下上个月计算机学院的借书总数",系统就能自动生成SQL并返回结果。
但90%的NL2SQL项目都卡在了Demo阶段,一到真实企业环境就彻底失灵。问题出在哪里?
我们先看一个最简单的对比:
- Demo环境:3张表,20个字段,大模型一眼就能看完所有表结构
- 真实企业环境:50+张表,3000+个字段,光把所有表结构打印出来就有几十页
这时候,把所有表结构全部塞给大模型会发生什么?
- 直接撑爆大模型的上下文窗口(即使是GPT-4o也处理不了这么多信息)
- 大量无关信息干扰大模型,生成错误的SQL
- 业务人员说"总借阅量",大模型根本不知道对应哪个表的哪个字段
- 业务库改个字段名,整个NL2SQL系统直接崩溃
这就是为什么纯大模型永远搞不定工业级NL2SQL,必须要有一个专门的基础设施:元数据库。
2. 什么是NL2SQL专用元数据库?
元数据库不是存业务数据的,而是存"关于数据的数据"------也就是数据库本身的结构、语义、业务含义。
它就像一个智能翻译官,一边懂大模型的语言,一边懂数据库的语言,专门解决"大模型看不懂你的数据库"这个核心问题。
2.1 元数据库标准ER图
下面是工业级NL2SQL元数据库的标准ER图,包含4张核心表,覆盖所有企业场景:
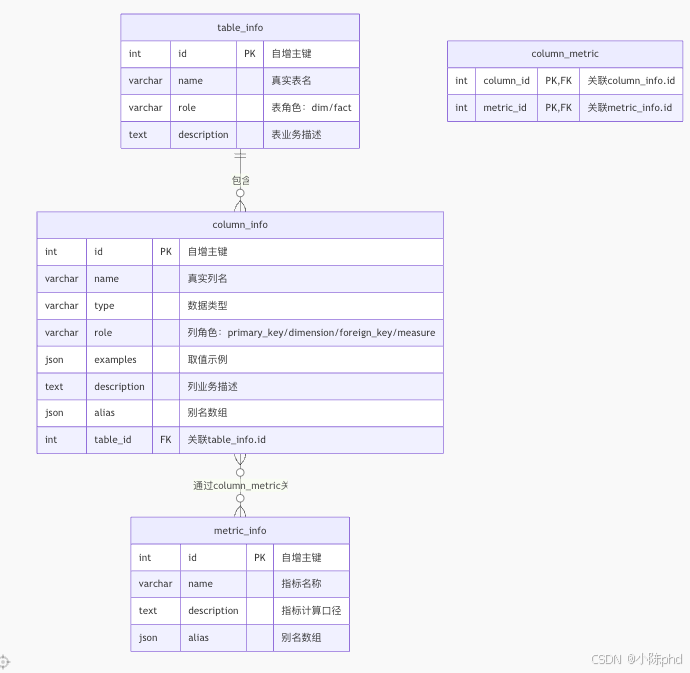
2.2 四张核心表的职责
| 表名 | 职责 | 一句话说明 |
|---|---|---|
| table_info | 存储所有业务表的基础信息 | 告诉大模型数据库里有哪些表,每张表是干什么的 |
| column_info | 存储所有字段的精细化语义信息 | 告诉大模型每个字段叫什么、是什么类型、用来干什么 |
| metric_info | 存储所有业务指标的定义和口径 | 告诉大模型业务人员说的"总借阅量"、"逾期数"到底是什么意思 |
| column_metric | 指标和字段的多对多关联中间表 | 建立业务指标和底层数据库字段之间的桥梁 |
3. 图书管理系统完整样例
我们用一个最常见的图书管理系统来演示元数据库如何工作。
3.1 原始业务库结构(附完整ER图)
首先明确:元数据库是原始业务库的"镜像说明书",不存任何真实借阅数据。我们的图书馆有4张核心业务表,专门存储真实的图书、读者、借阅数据。
图书管理系统业务库ER图
#mermaid-svg-xqgUMaygTGOHQ5T8{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-xqgUMaygTGOHQ5T8 .error-icon{fill:#552222;}#mermaid-svg-xqgUMaygTGOHQ5T8 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-xqgUMaygTGOHQ5T8 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-xqgUMaygTGOHQ5T8 .marker.cross{stroke:#333333;}#mermaid-svg-xqgUMaygTGOHQ5T8 svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-xqgUMaygTGOHQ5T8 p{margin:0;}#mermaid-svg-xqgUMaygTGOHQ5T8 .entityBox{fill:#ECECFF;stroke:#9370DB;}#mermaid-svg-xqgUMaygTGOHQ5T8 .relationshipLabelBox{fill:hsl(80, 100%, 96.2745098039%);opacity:0.7;background-color:hsl(80, 100%, 96.2745098039%);}#mermaid-svg-xqgUMaygTGOHQ5T8 .relationshipLabelBox rect{opacity:0.5;}#mermaid-svg-xqgUMaygTGOHQ5T8 .labelBkg{background-color:rgba(248.6666666666, 255, 235.9999999999, 0.5);}#mermaid-svg-xqgUMaygTGOHQ5T8 .edgeLabel .label{fill:#9370DB;font-size:14px;}#mermaid-svg-xqgUMaygTGOHQ5T8 .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edge-pattern-dashed{stroke-dasharray:8,8;}#mermaid-svg-xqgUMaygTGOHQ5T8 .node rect,#mermaid-svg-xqgUMaygTGOHQ5T8 .node circle,#mermaid-svg-xqgUMaygTGOHQ5T8 .node ellipse,#mermaid-svg-xqgUMaygTGOHQ5T8 .node polygon{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-xqgUMaygTGOHQ5T8 .relationshipLine{stroke:#333333;stroke-width:1;fill:none;}#mermaid-svg-xqgUMaygTGOHQ5T8 .marker{fill:none!important;stroke:#333333!important;stroke-width:1;}#mermaid-svg-xqgUMaygTGOHQ5T8 .edgeLabel{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-xqgUMaygTGOHQ5T8 .edgeLabel .label rect{fill:rgba(232,232,232, 0.8);}#mermaid-svg-xqgUMaygTGOHQ5T8 .edgeLabel .label text{fill:#333;}#mermaid-svg-xqgUMaygTGOHQ5T8 :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 包含
被借阅
借阅
dim_category
varchar
category_id
PK
分类唯一ID
varchar
category_name
分类名称
varchar
parent_id
父分类ID
dim_book
varchar
book_id
PK
图书唯一ID
varchar
book_name
图书名称
varchar
author
作者
varchar
publisher
出版社
date
publish_date
出版日期
varchar
category_id
FK
关联分类表
int
stock
在馆库存
dim_reader
varchar
reader_id
PK
读者唯一ID
varchar
reader_name
读者姓名
varchar
department
所属院系
date
register_date
注册日期
fact_borrow
varchar
borrow_id
PK
借阅记录ID
varchar
book_id
FK
关联图书表
varchar
reader_id
FK
关联读者表
date
borrow_date
借出日期
date
due_date
应还日期
date
return_date
实际归还日期
tinyint
is_overdue
是否逾期(0/1)
int
borrow_count
本次借阅数量
业务表关系说明
- 维度表(dim开头) :存储静态基础信息,不随时间频繁变化
dim_category:图书分类,如计算机、文学、历史dim_book:图书详情,每本书一条记录dim_reader:读者信息,每个读者一条记录
- 事实表(fact开头) :存储动态交易记录,随时间不断新增
fact_borrow:每一笔借阅操作生成一条记录,是所有统计分析的核心
3.2 元数据库样例数据
元数据库就是把上面这4张业务表的"说明书"结构化存储起来,供大模型检索使用。
3.2.1 table_info:业务表基础信息
| id | name | role | description |
|---|---|---|---|
| 1 | dim_book | dim | 图书维度表,存储所有图书的基础属性,包括书名、作者、出版社等 |
| 2 | dim_reader | dim | 读者维度表,存储借阅人的个人信息,包括姓名、学号、院系等 |
| 3 | dim_category | dim | 图书分类维度表,存储图书的分类信息,如计算机、文学、历史等 |
| 4 | fact_borrow | fact | 借阅事实表,记录每一笔图书借阅的完整记录,包括借阅时间、归还时间、是否逾期等 |
3.2.2 column_info:字段精细化语义信息
| id | name | type | role | examples | description | alias | table_id |
|---|---|---|---|---|---|---|---|
| 1 | book_id | varchar(20) | primary_key | "B001", "B002" | 图书唯一标识ID | "图书编号", "书号" | 1 |
| 2 | book_name | varchar(100) | dimension | "《三体》", "《Python编程》" | 图书完整书名 | "书名", "图书名称" | 1 |
| 7 | stock | int | measure | "5", "10", "0" | 图书当前在馆库存数量 | "库存", "在馆数量" | 1 |
| 8 | reader_id | varchar(20) | primary_key | "R001", "R002" | 读者唯一标识ID | "读者编号", "学号" | 2 |
| 10 | department | varchar(50) | dimension | "计算机学院", "文学院" | 读者所属院系 | "院系", "学院" | 2 |
| 14 | borrow_id | varchar(20) | primary_key | "BR001", "BR002" | 借阅记录唯一标识ID | "借阅编号" | 4 |
| 17 | borrow_date | date | dimension | "2026-05-01", "2026-06-05" | 图书借出日期 | "借阅日期", "借出时间" | 4 |
3.2.3 metric_info:业务指标信息
| id | name | description | alias |
|---|---|---|---|
| 1 | 总借阅量 | 统计所有借阅记录的总数量,按借阅记录条数计算 | "借阅总量", "借书总数" |
| 2 | 在借图书数 | 当前未归还的图书总数量 | "在借数量", "未还图书数" |
| 3 | 逾期图书数 | 当前已到期但未归还的图书数量 | "逾期数量", "超期图书数" |
3.2.4 column_metric:指标-字段关联
| column_id | metric_id | 计算逻辑 |
|---|---|---|
| 14 | 1 | COUNT(borrow_id) |
| 15 | 2 | COUNT(book_id) WHERE return_date IS NULL |
| 15 | 3 | COUNT(book_id) WHERE is_overdue = 1 |
3.3 完整工作流程演示
用户提问:"计算机学院2026年5月的总借阅量是多少?"
元数据库会驱动整个NL2SQL流程,分5步生成正确的SQL:
步骤1:向量检索匹配业务指标
将用户问句向量化,在Qdrant向量库中检索最相似的业务指标:
- 匹配到
metric_info.id=1(总借阅量) - 别名"借书总数"也命中,进一步确认匹配
步骤2:找到指标依赖的字段和表
- 查询
column_metric表,找到metric_id=1关联的字段:column_id=14 - 查询
column_info表,找到id=14的字段是borrow_id,所属表table_id=4 - 查询
table_info表,找到id=4的表是fact_borrow(借阅事实表)
步骤3:检索筛选条件相关的字段
用户问句中的"计算机学院"和"2026年5月":
- "计算机学院"匹配到
column_info.id=10(department),所属表table_id=2(dim_reader) - "2026年5月"匹配到
column_info.id=17(borrow_date),所属表table_id=4(fact_borrow)
步骤4:自动推断表关联关系
根据字段角色:
fact_borrow.reader_id是外键dim_reader.reader_id是主键- 自动生成JOIN条件:
fact_borrow b JOIN dim_reader r ON b.reader_id = r.reader_id
步骤5:生成最终SQL语句
大模型只需要处理裁剪后的上下文:
- 表:fact_borrow、dim_reader
- 字段:borrow_id、department、borrow_date
- 指标口径:总借阅量=COUNT(borrow_id)
生成的SQL:
sql
SELECT COUNT(b.borrow_id) AS 总借阅量
FROM fact_borrow b
JOIN dim_reader r ON b.reader_id = r.reader_id
WHERE r.department = '计算机学院'
AND b.borrow_date BETWEEN '2026-05-01' AND '2026-05-31';4. 元数据库的4大核心价值
4.1 解决上下文窗口爆炸问题
这是元数据库最直接的价值。
没有元数据库:需要把4张表的21个字段全部塞给大模型,大约需要500个token
有了元数据库:只需要把2张表的3个相关字段塞给大模型,大约需要100个token
对于有上百张表的企业数据库,元数据库可以将上下文大小压缩90%以上,彻底解决窗口超限问题。
4.2 跨越业务口语与物理字段的语义鸿沟
业务人员永远不会说"统计fact_borrow表中borrow_id的数量",他们只会说"总借阅量"。
元数据库建立了完整的业务语义层:
- 用户说"借书总数"→匹配指标别名→找到总借阅量
- 用户说"学号"→匹配字段别名→找到reader_id
- 用户说"逾期"→匹配字段描述→找到is_overdue
让大模型真正听懂业务语言,而不是只懂数据库语言。
4.3 解耦业务层与物理数据库层
这是元数据库最被低估的价值。
假设业务库要改个字段名:stock → available_stock
- 没有元数据库:需要找到所有用到这个字段的NL2SQL代码,批量修改,漏一条就报错
- 有了元数据库:只需要修改
column_info表中id=7的name字段,所有业务指标和NL2SQL逻辑完全不用改
业务库的任何改动,都只需要同步元数据库的几条记录,上层NL2SQL系统完全不受影响。
4.4 标准化业务口径,消除歧义
同一个指标在不同部门可能有不同的定义:
- 运营部:总借阅量=所有借阅记录的数量
- 财务部:总借阅量=所有实际借阅图书的数量
没有元数据库:大模型会随机生成一种口径,导致结果错误
有了元数据库:所有指标的口径统一存储在 metric_info 表中,大模型生成的SQL永远符合业务定义
5. 元数据库是NL2SQL从Demo到生产的必经之路
很多人以为NL2SQL就是"把表结构塞给大模型,让它生成SQL",但这只是Demo级别的做法。
真实企业级NL2SQL的核心不是大模型有多聪明,而是你能不能把你的数据库"翻译"成大模型能看懂的语言。元数据库就是这个翻译官,它解决了纯大模型无法克服的所有根本性问题:
- 上下文窗口爆炸
- 业务语义与物理字段的鸿沟
- 业务库变动的影响
- 业务口径不统一
没有元数据库,NL2SQL永远只能处理3-5张表的小数据库;有了元数据库,NL2SQL才能支持上百张表的企业级数据库,真正落地到业务中。
这就是为什么所有工业级NL2SQL产品(Chat2DB、DB-GPT、Vanna)都内置了元数据库模块,它是NL2SQL落地的隐形基石。