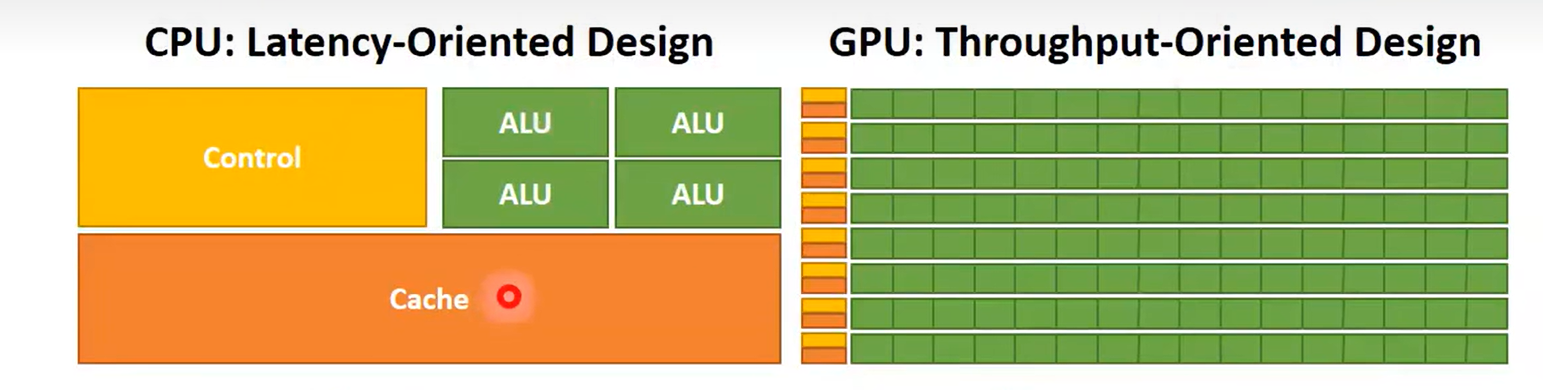
GPU是面向吞吐量设计的,它的算数逻辑单元(ALU)较小,因此单个算数运算耗时更长。然而,GPU拥有更多的ALU,从而实现了更高的吞吐量。同时,GPU也使用了更小的缓存和更简洁的控制单元,从而将更多芯片面积用于并行计算,通过并行来弥补运算延迟的问题。
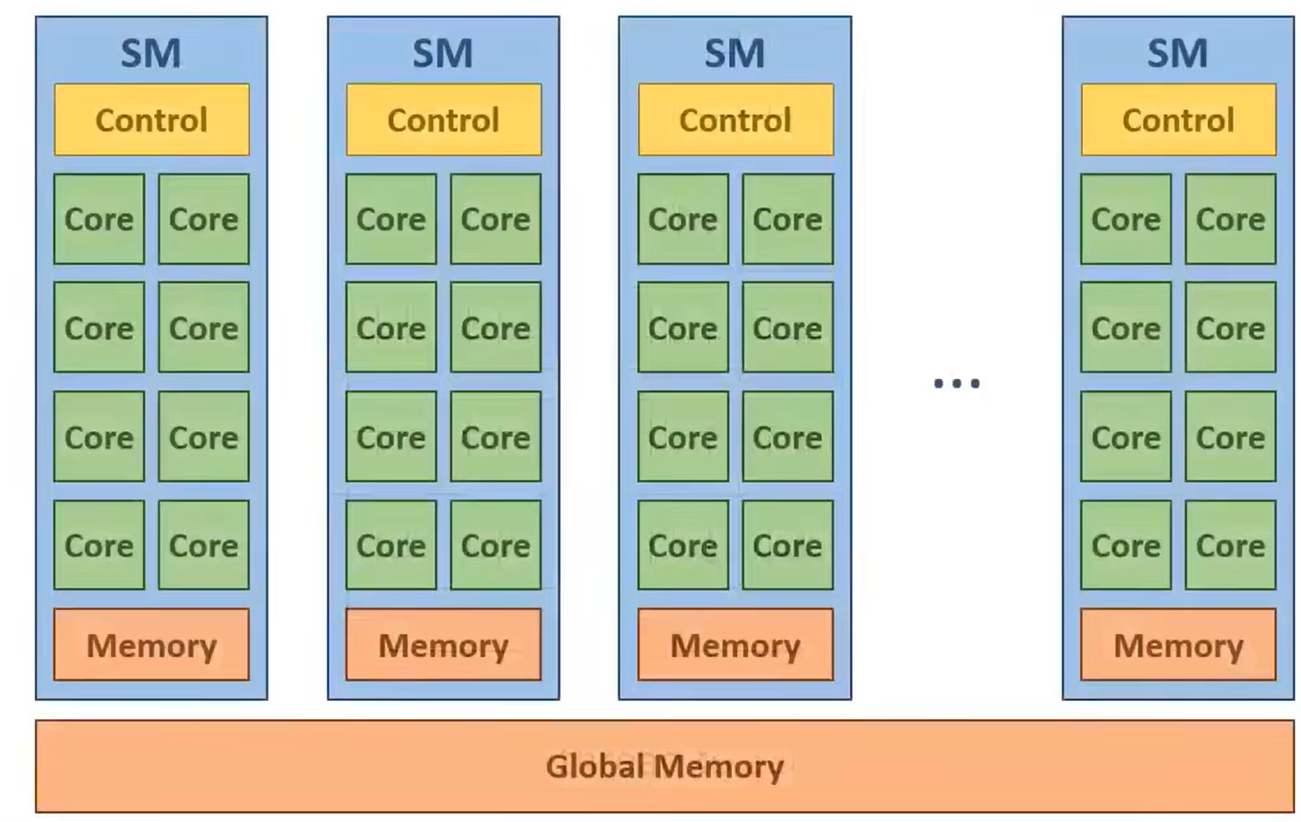
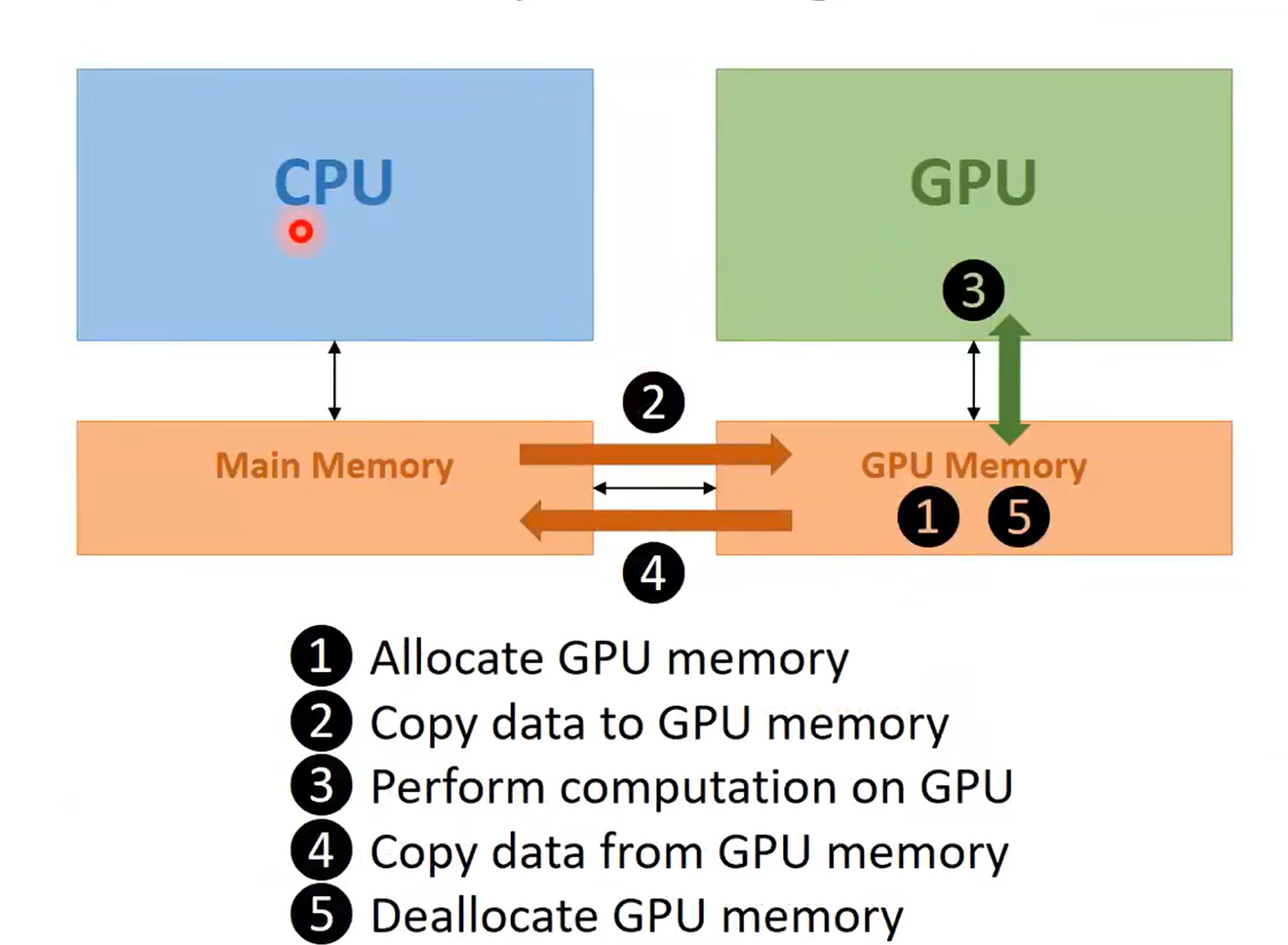
GPU由流多处理器即SM组成。每个SM都有一堆核心,这些核心共享控制单元和内存。所有的SM共享全局内存(即Glocal Memory)。之前在GPU申请内存用于保存数据的就是全局内存。使用GPU时,内存管理模式如图所示:
线程是以一个线程块一个线程块分配给SM的,块内的所有线程在同一个SM上执行。如果网格中线程块数量超过SM容纳上限,多余的线程块就需要等待,直到某个线程块执行完毕。如果SM中剩余空间不足以执行整个线程块,此时线程块不会进入SM,直到SM剩余空间可以完整容纳整个线程块。
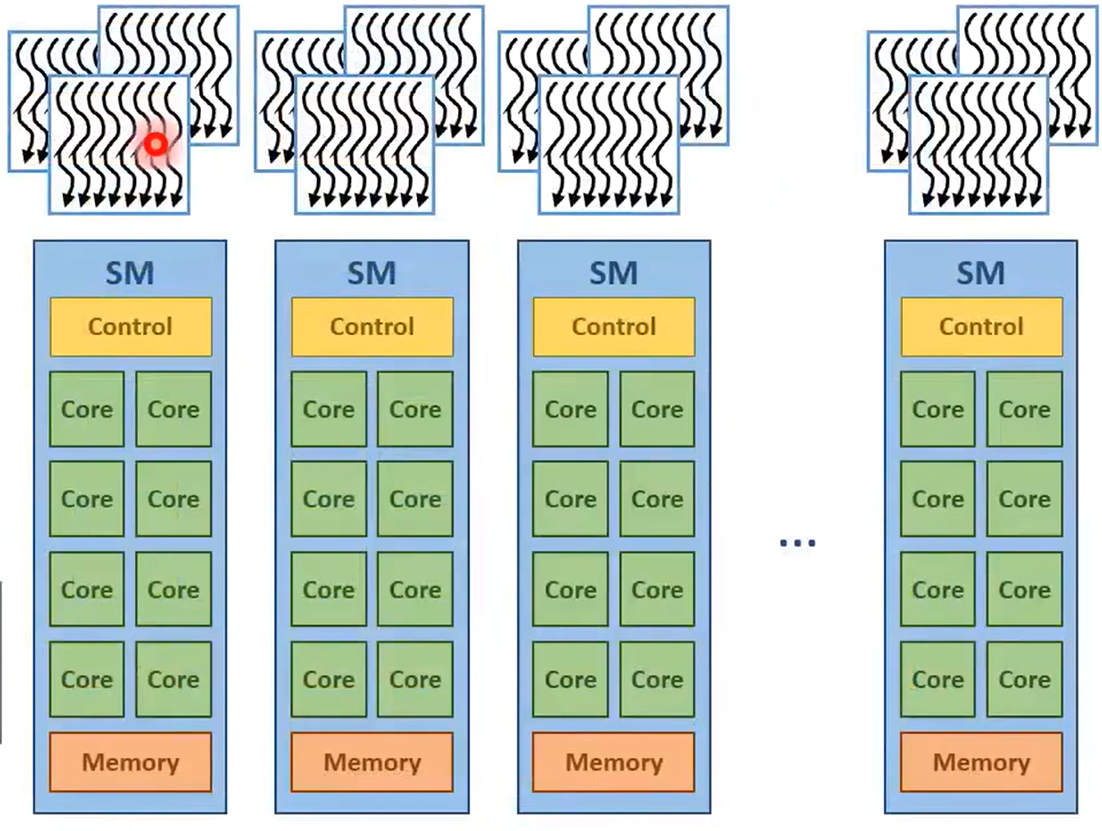
一个线程块中的线程可以相互协作(所以放在同一个SM上),而不同线程块中的线程相互独立,不能协作。
- 屏障同步:线程块中的线程可以通过屏障同步来实现同步,比如在某个位置设置屏障,那么线程块内的所有线程全部到达这个点之后才能往下执行,否则只能等。
- 共享内存:只有在同一个线程块中的线程才能访问共享内存
当线程块被分配到SM后,会被进一步划分为 线程束即warp 。线程束是SM的调度单位,每个线程束由32个线程组成。 线程束 遵循单指令多数据模型即SIMD :线程束中的所有线程执行同一个指令,如果指令路径出现分歧(if、while),那么有的线程在执行即活跃,有的线程不会执行即空闲。当线程空闲时依然占用GPU核心资源,导致GPU利用率下降,所以在编写线程代码时需要尽量避免路径分歧问题。
当在SM上运行的线程束遇到延时操作时,我们会将这个线程束挂起,并调用另一个线程束来运行直到前一个线程束完成操作 ,从而减少停顿次数降低总体延迟。为了更好地实现这一点即隐藏延迟,我们最好在SM上分配尽可能多的线程束 。这就引入了占有率:SM上实际分配的线程数/SM最大可容纳线程数。占用率受多种因素影响,比如SM最多容纳的线程块数量、线程块最多容纳的线程数量、寄存器数量等
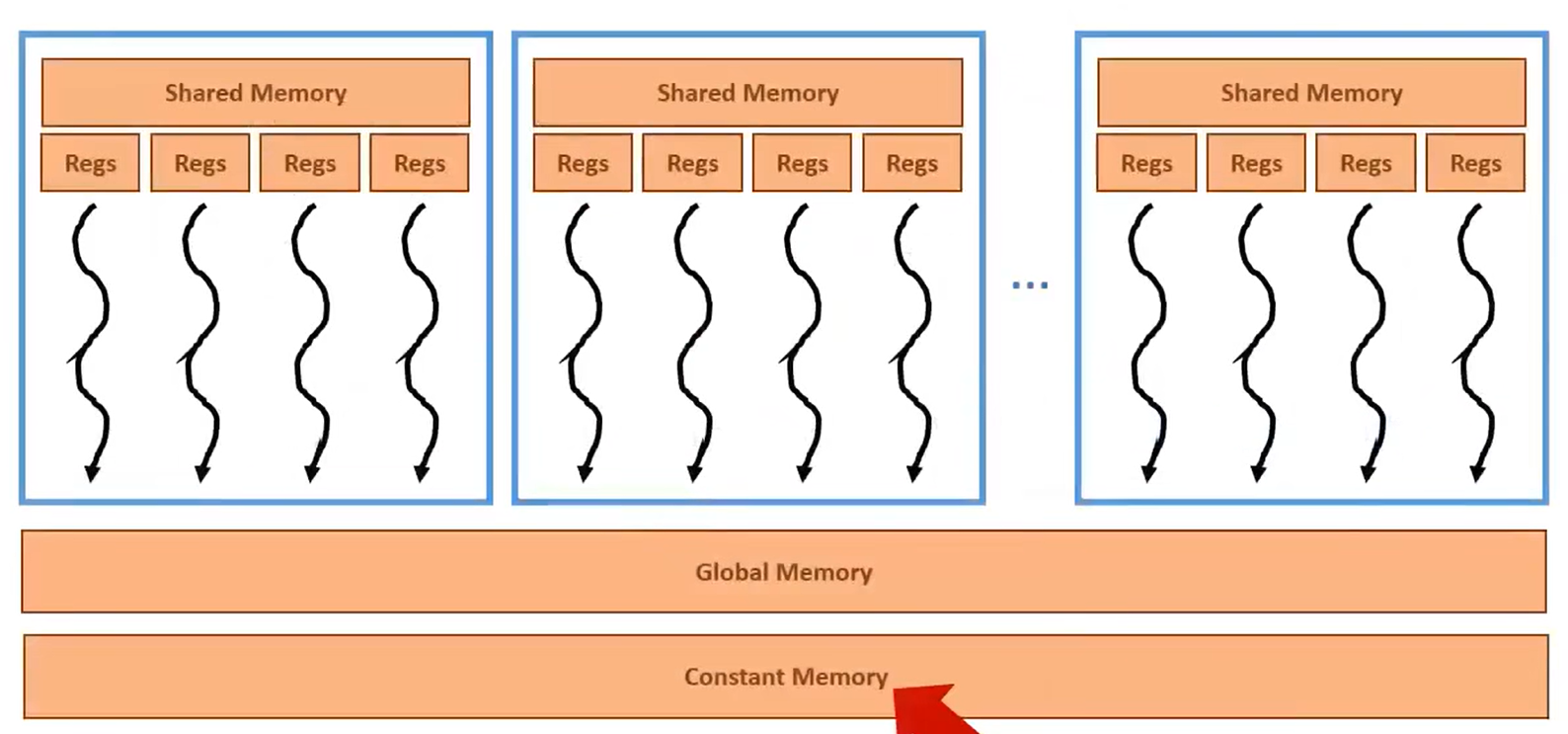
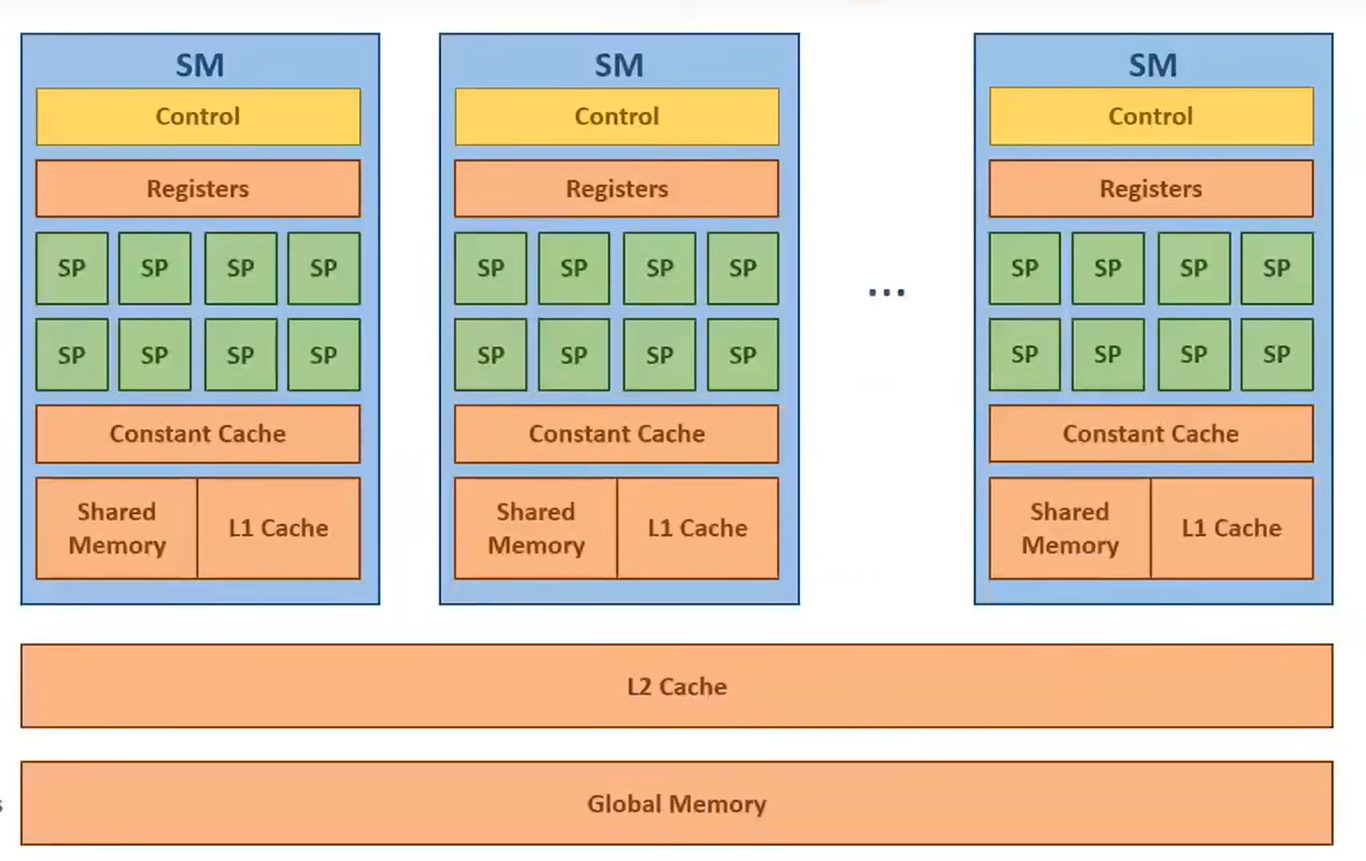
如图是GPU架构中的内存层次。同一SM上的核心可以访问共享内存,我们可以通过充分利用共享内存来减少全局内存的使用:
与GPU内存模型不同,cuda编程模型更为抽象简约。在实际编程时,我们都是依据cuda编程模型来编写代码: