文章目录
https://ai-safety-book.github.io/index.html
https://ai-data-model-safety.github.io/
一、一个赌注
1965 年,Herbert Simon 说了一句后来被引用了将近六十年的话:
"二十年内,机器将能完成人类能做的任何工作。"
Simon 是诺贝尔经济学奖得主,是认知科学的奠基人之一,是一个极其聪明的人。他不是在胡说。他有论据。他看见了他那个时代最令人振奋的东西:一台机器,第一次,开始像人类一样推理。
不是计算。推理。
如果你能把世界的知识表示成符号,把推理规则表示成逻辑,那么机器就能推理。
二、If-Then 的美学
一个基于规则的推理系统,结构非常简单。你有两个部分:
知识库(Knowledge Base) :一组 If-Then 规则,描述世界的规律。
推理引擎(Inference Engine):给定一个问题,沿着规则链推导出答案。
举一个经典的例子------1972 年斯坦福大学开发的 MYCIN 系统。MYCIN 是用来诊断细菌性血液感染的。它的知识库里有大约 600 条规则,长这样:
IF 细菌的革兰氏染色 = 阳性
AND 细菌的形态 = 球状
AND 细菌的生长模式 = 成簇
THEN 细菌的种类 = 金黄色葡萄球菌(置信度 0.7)
推理引擎拿到一个具体病例,把已知的观测事实代入规则,一条条往前推,最终给出诊断和推荐用药。
MYCIN 的表现令人震惊。1979 年,斯坦福做了一个盲测------把 10 个真实病例交给 MYCIN 和 5 位医学专家分别诊断,然后请 8 位感染病学权威评估所有答案的质量,但不告诉他们哪个是机器的。结果:MYCIN 的表现排在所有参与者的前列,超过了其中几位人类医生。
你可以理解为什么 Simon 那一代人会如此乐观。如果你能把一个领域的专家知识写成规则,机器就能成为这个领域的专家。而且它不会疲劳,不会犯粗心错误,不会因为值完夜班而判断力下降。
这个想法有一种纯粹的美学。世界是复杂的,但复杂的背后是规律。规律可以被显式地表达。表达之后,机器可以操作它。
问题是,"写成规则"这件事本身,比看起来要难得多。
三、知识瓶颈
专家系统有一个让所有人都头痛的问题,他们给它起了个名字,叫知识获取瓶颈(Knowledge Acquisition Bottleneck) 。
"知识获取瓶颈"这个词说的是:把人类专家头脑里的知识转化为计算机能处理的规则,这件事本身极其困难。
原因有两层:
- **专家说不清楚自己在做什么:**很多经验性判断已经自动化到了潜意识层面,专家自己都无法把它显式地描述出来(见下方"内隐知识")。
- **知识是情境依赖的:**同一条信息在不同语境下含义不同,但规则系统无法优雅地处理这种依赖关系。
这是整个专家系统时代最核心的实践困难,最终导致了这一技术路线的衰落。
意思是:把专家的知识写进规则,这件事本身,就是一个几乎无法完成的任务。
你去找一个有三十年经验的外科医生,问他:"你是怎么判断病人需要手术的?"他会告诉你一些标准的答案:看影像结果,看血液指标,看症状持续时间。但你把这些都写进规则,发现系统的表现很糟糕。因为他没告诉你的,是他三十年积累的直觉 :病人说某句话时他皱眉的方式,两种指标同时出现时那个难以言说的"感觉",某类病人在某个季节的特殊模式。
这些东西是真实的知识,是让他成为顶级外科医生的东西。但他说不出来。不是因为他不想说,而是因为那些知识已经沉淀进了他的认知系统的底层 ,他自己都无法访问它们的显式形式。
认知科学把这种知识叫做内隐知识(tacit knowledge)------你知道怎么骑自行车,但你无法向一个不会骑车的人解释你在骑车时做了什么精确的力学调整。
内隐知识 这个概念来自哲学家迈克尔·波兰尼(Michael Polanyi),他在1958年提出:"我们知道的,比我们能说出来的要多。 "
典型例子:
- 骑自行车------你会骑,但你能精确描述每一帧你在做什么调整吗?
- 人脸识别------你一眼认出老朋友,但你能说出是哪些像素特征触发了这个识别吗?
- 专家判断------老中医"一看气色",有经验的外科医生"感觉不对劲"
内隐知识的存在解释了为什么专家系统注定会遇到"知识写不完"的问题:最有价值的那部分专家经验,恰恰是专家自己也无法显式描述的部分。
所以知识工程师(知识库的建设者)的日子非常难过。他们花大量时间和专家访谈,得到一些规则,放进系统,测试,发现覆盖不到的边界情况,回去再问,再改,再测。这个过程慢、贵、而且没有终点。
你写了 1000 条规则,发现还需要 1000 条。你写了 10000 条,发现新的案例触发了之前 1000 条都没有预料到的情况。
世界不是封闭的。规则永远写不完。
四、逻辑门是因果的最简形式
在继续讲专家系统的失败之前,我想在这里插入一个物理学的注脚。
当我们谈论"规则推理"的时候,我们在谈论的实际上是一个非常具体的物理过程。
一个逻辑门------AND 门、OR 门、NOT 门------它的功能是什么?它在做的事情是:给定输入,产生确定性的输出。这是因果关系的最简单、最纯粹的物理实现。
一个 AND 门:如果 A=1 且 B=1,那么输出=1。否则输出=0。这就是一条 If-Then 规则,被蚀刻在硅片上,由电子的流动来执行。
所有的专家系统,所有的逻辑推理,最底层都是这样的物理实现。因果关系被具象化为电路:某个状态导致另一个状态,没有例外,没有概率,没有歧义。
这里有一个深刻的东西值得停下来想一想。
计算机不是在"思考"。它在做的事情是:执行一系列确定性的因果变换。每一步,输入决定输出,没有任何不确定性。麦卡锡和明斯基他们那一代人的直觉是:如果我们能把思维过程分解成足够多的确定性步骤 ,那么机器就能复现思维。
这个直觉在某种程度上是对的。数学证明可以被分解成符号操作的序列 ,而每一步符号操作都是确定性的 。MYCIN 的推理过程是确定性的------给定相同的事实,它总是给出相同的答案。国际象棋的棋步搜索是确定性的。一大类"精确定义的问题"都可以被这样处理。
【但"思维"不只是精确定义的问题的集合。】
五、封闭世界假设
这里我们需要正式引入一个概念,因为它是这一章所有问题的根源。
它叫做封闭世界假设 (Closed World Assumption,CWA)。
**封闭世界假设(CWA)**是规则型系统的默认工作方式:【凡是没有被明确记录在知识库中的事实,一律视为"不成立"或"不存在"。】
对比一下两种世界观:
- 封闭世界:没写进去的 = 不存在(数据库式查询的逻辑)
- 开放世界 :没写进去的 = 我不知道(更接近现实)
这个假设在封闭、有界 的领域(比如航班数据库)是合理的。但在【开放的现实世界中】,它非常危险:系统会把"我没见过这种情况"误认为"这种情况不存在",然后自信地给出错误答案。
今天的大语言模型也有类似的问题------训练数据的边界,在某种意义上就是一种新形式的"封闭世界"。这个问题贯穿本书始终。
在一个基于规则的系统里,你只能使用你已经放进去的知识。任何你没有明确说明的事情,系统都当做**"不存在"或"不成立"**来处理。
举个例子。你建了一个数据库,里面有你所知道的所有航班信息。有人查询"从北京到火星有没有直飞航班"。在封闭世界假设下,因为数据库里没有这条记录,系统的答案是:没有。这个答案是对的。
但是,有人查询"今天下午有没有北京到上海的航班"。数据库里没有,系统答:没有。但也许数据库只是不完整------也许有这个航班,只是你没录进去。
这两种情况,系统给出了完全一样的回答方式,但一个是正确的推断,另一个是错误的推断。【封闭世界假设无法区分"明确不存在"和"不知道是否存在"】。
【在专家系统里,这个问题更加严重。你的规则库覆盖了医生知识的 70%。那剩下 30% 的情况怎么办?系统不会说"我不知道"------它会沿着已有的规则,推导出一个它"能"推导出来的答案,这个答案可能完全错误,而且系统对这个答案充满信心。】
这是一种非常危险的失效模式。
不会困惑,只会崩溃,而且崩溃得很自信。
#六、MYCIN 的后代们
MYCIN 之后,专家系统的思路被推广到几乎每一个能想到的领域。石油勘探(PROSPECTOR,1978 年,其中一个案例发现了价值约一亿美元的钼矿)。贷款审批(大量银行系统)。生产调度(Digital Equipment Corporation 的 XCON,每年为公司节省数千万美元)。
1980 年代,这是一个很火热的行业。有专门的公司在卖专家系统 的开发工具,有专门的工程师职位叫"知识工程师",有大学开了专门的课程。日本政府在 1982 年启动了一个宏大的"第五代计算机项目",目标是建造一台基于【逻辑推理】的超级计算机,预期十年后实现人工智能的突破。美国政府被吓到了,专门成立了 DARPA 的 Strategic Computing Initiative 来应对。
听起来是不是很熟悉?每隔几十年,这种故事就会发生一次。
然后,慢慢地,裂缝出现了。
维护成本。一个大型专家系统,规则之间的相互作用变得极其复杂。你修改一条规则,发现它破坏了另外三条规则的推理链。专家系统开始变得脆------不是在边界情况下脆,而是在它本来应该最强大的核心区域,因为内部的矛盾而崩溃。
扩展性 。从 600 条规则扩展到 6000 条规则,系统的行为变得不可预测。知识工程师无法在脑子里同时追踪所有规则之间的交互,更不用说理解它们合并之后的整体行为。
适应性。 MYCIN 是 1972 年写的。医学在进步。【新的病原体,新的检测方法,新的药物】。每一次更新都需要知识工程师重新进入系统,找到受影响的规则,手动修改------同时小心不要破坏其他东西。这不是一个能够自我学习 的系统;它是一个需要人类不断维护的静态快照 。
到 1980 年代末,日本的第五代计算机项目开始陷入麻烦。专家系统的局限性越来越清晰。1987 年,专家系统硬件市场崩溃,AI 行业进入了第二次"寒冬"。
七、一个简单的专家系统
为了让这些不只是抽象的历史,让我给你展示一个实际的微型专家系统是什么样的。
这是用来诊断"动物是什么"的小系统,最早由 Winston 和 Horn 在 1981 年的教科书里给出,是专家系统教学中的经典案例:
你输入的事实:["有毛发", "吃肉", "黄褐色", "有深色斑点", "有爪子", "眼睛向前"]
推理过程:
text
触发 R1: ['有毛发'] → 是哺乳动物
触发 R5: ['是哺乳动物', '吃肉'] → 是食肉动物
触发 R6: ['是哺乳动物', '有爪子', '眼睛向前'] → 是食肉动物 [已有]
触发 R8: ['是食肉动物', '黄褐色', '有深色斑点'] → 是猎豹
最终结论:是猎豹这个逻辑是清晰的、可追溯的、可解释的。每一步推理,你都能说出来它是从哪条规则来的。这正是专家系统的一大优势------透明度 。
但是现在,你提问:这只动物同时 有深色斑点和 黑色条纹。
系统不知道怎么处理这个情况。R8 和 R9 都部分满足 ,但两条规则结论不同------是猎豹还是老虎?系统的处理方式取决于实现:有时候它报告第一个匹配的结论,有时候它陷入冲突,有时候它产生两个互相矛盾的结论。
它不会困惑,它不会说"我不知道",它会给你一个答案。
而那个答案,可能是完全没有意义的。
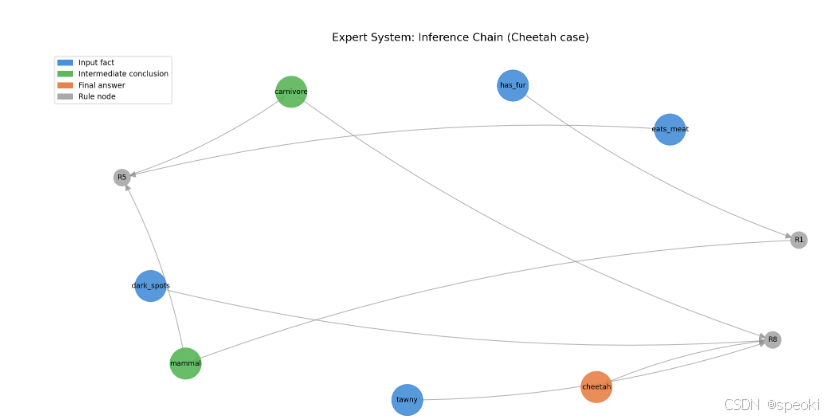
图1:MYCIN 式前向链接推理的 DAG 结构。每个节点是一个事实或结论,边是触发的规则。推理路径清晰可追溯------这是专家系统最大的优势,也是它的天花板。
八、为什么它失败------真正的原因
现在我要说一个比"知识写不完"更深的原因。
专家系统的核心假设是:推理可以被分解成独立的、可枚举的规则,规则之间的相互作用是有限的和可预测的。
这个假设在非常受限的领域里是成立的。MYCIN 面对的是细菌性感染的诊断------这是一个【有明确边界、有标准协议、有有限变量】的领域。在这里,【知识库接近于完整,推理接近于闭合】。
但在开放的、现实的世界里,这个假设根本性地错误。
人类的推理不是【规则系统】。当你走进一个没见过的房间,你不是在访问一个关于"房间"的规则库,然后逐条匹配。你的大脑在做的事情,是把这个新场景映射进一个内部的、高度压缩的世界模型------一个你花了几十年建立的、通过无数次经验不断更新的模型。这个模型是连续的,是生成式的,它可以做插值,可以做外推,可以在遇到新情况时产生合理的猜测 ,即便这个情况在它"见过"的样本里从未出现过。
规则系统没有这个能力。规则系统是离散的 ,是枚举式的 ,它只能在它显式覆盖的区域内推理。遇到规则库的边界,它不会猜,它会崩溃。
这里有一个更深的哲学问题,1971 年,哲学家 Hubert Dreyfus 在他的《计算机不能做什么》里就提出过:人类的智能,在很大程度上依赖于我们对"什么是重要的"的直觉------而这种直觉是情境性的(situated) ,是通过我们作为有身体的、活在世界里的生物所积累的体验来形成的。你无法把这种情境性知识抽提成脱离情境的规则,因为它本来就不存在于规则的形式里。
Dreyfus 当时被 AI 社区嘲笑了。后来被证明他大体上是对的。
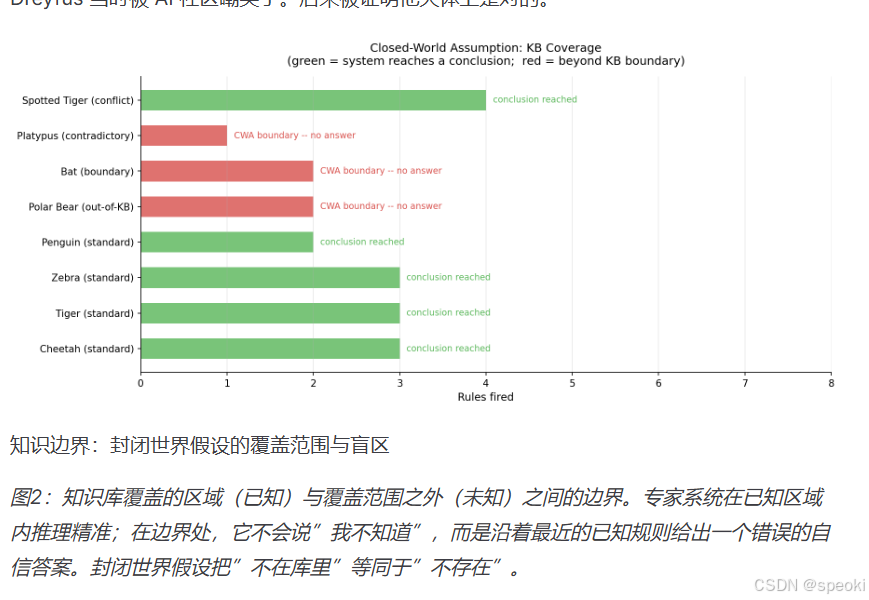
Dreyfus 的核心论点:人类的 "直觉" 和 "情境性知识",是无法被抽成脱离身体、脱离情境的规则的 ------ 因为它本来就不是规则,而是体验的沉淀。
举个更扎心的例子:
你教 AI "什么是椅子",可以写 100 条规则:"有四条腿、有靠背、能坐人"
但当你看到一个倒在地上的椅子,或者一个异形的艺术椅子,你立刻能认出它是椅子 ------ 因为你的判断基于 "身体使用椅子的体验",不是规则。
而 AI 呢?如果规则里没写 "倒着的椅子也是椅子",它会告诉你:"这不是椅子"。
九、然而它留下了什么
我不想让这章的结局听起来太像一个失败故事。因为那不是全貌。
专家系统在它擅长的地方,是真实有效的。那些规则数量有限、领域边界清晰、知识可以被完整枚举的问题------XCON 为 DEC 节省的真实的数千万美元,那是真的 。贷款审批系统里,如果规则写得好,偏见可以被显式地审计和修正------这件事比黑盒系统里的隐性偏见要透明得多。医疗决策支持系统至今仍在使用某种形式的规则引擎,在格式化的、规则明确的子任务上。
更重要的是,专家系统时代留下了一些真正重要的遗产:
更重要的是,专家系统时代留下了一些真正重要的遗产:
- **清晰的问题分解。**把一个复杂问题分解成可以独立处理的子问题,这是一种真正有价值的能力。现代软件工程仍然在做这件事。
- 推理的可解释性。你能追踪系统的每一步推理------这在今天的 AI 系统里反而是一种稀缺品。可解释性的问题,在深度学习时代重新变成了热点,而专家系统在这方面做得是最好的。
- **知识表示理论。围绕专家系统建立起来的知识表示(Knowledge Representation)**理论,后来发展成了本体论(Ontology)、描述逻辑(Description Logic)、语义网(Semantic Web)------这些东西至今仍在很多工业系统里运行
"知识如何在计算机里被结构化表示"的不同层面:
- 本体论(Ontology):在计算机科学里,它指的是"用形式化语言定义某个领域的概念体系和概念间关系"。比如医学本体论 SNOMED 定义了"疾病""症状""药物"之间的层级关系。
- 描述逻辑(Description Logic):构建本体论用的那套逻辑语言,比自然语言更精确,比完整的一阶逻辑更可计算。OWL(Web 本体语言)就【基于描述逻辑。】
- 语义网(Semantic Web):Tim Berners-Lee 提出的愿景------让网页上的数据不只是给人读,也能被机器"理解"(即机器能理解数据的语义关系)。RDF、OWL 是它的核心技术。
本体论的核心要素(以 "动物领域" 为例):
概念(类):比如动物、鸟、麻雀、哺乳动物
关系:概念之间的关联,比如
- 继承关系:麻雀 ⊂ 鸟 ⊂ 动物(麻雀是鸟的子类)
- 属性关系:鸟 → 有翅膀(鸟的属性是有翅膀)
- 实例关系:"这只麻雀"是"麻雀"类的一个实例
公理 :强制约束的规则,比如"鸟和哺乳动物是互斥的,没有动物既是鸟又是哺乳动物"
描述逻辑是一套专门用于刻画 "概念 - 关系" 的逻辑系统,能让机器自动判断概念之间的包含、互斥关系,或验证知识的一致性。
语义网(Semantic Web) :让互联网的 "数据" 变成 "知识"
这是知识表示理论的终极应用场景,核心目标是:
让互联网上的信息从 "机器可读(比如文本、图片)" 升级为 "机器可理解(比如 "这篇文章讲的是'鸟',包含'麻雀会飞'的知识")"。
语义网就是要构建 "语义互联的知识网络 ",让数据带上 "意义标签",实现智能检索和推理 。
语义网的核心技术(和前面的概念强关联):
- RDF(资源描述框架):最基础的知识表示格式,用(主语,谓语,宾语)三元组描述知识,比如(麻雀,属于,鸟)。
- OWL(网络本体语言):基于描述逻辑的本体语言,能定义复杂的概念关系和公理 ------ 本质是把本体论 "搬到互联网上"。
- SPARQL:语义网的查询语言,类似 SQL,但能查询 "知识关系"------ 比如你可以问 "所有属于鸟且不会飞的动物",它会返回 "企鹅""鸵鸟"。
这三者是一条从概念到技术的链条:【本体论是目标,描述逻辑是工具,语义网是应用场景】。
一个关于推理边界的清晰反例。专家系统彻底地、实证地证明了:如果推理依赖于完整的显式知识库,那么推理能走多远,就完全取决于你的知识库写得多完整 。【世界是开放的,知识库是封闭的】。两者之间的张力,是任何基于规则的系统的根本性限制。
这个教训的对立面,是接下来几十年 AI 研究转向的方向:不要试图显式地写出所有规则,而是让机器从数据中学习这些规律,同时包括那些人类自己都说不清楚的内隐知识。
这不是一个容易的转变,也不是一个完全成功的转变。但那是下一章的故事。
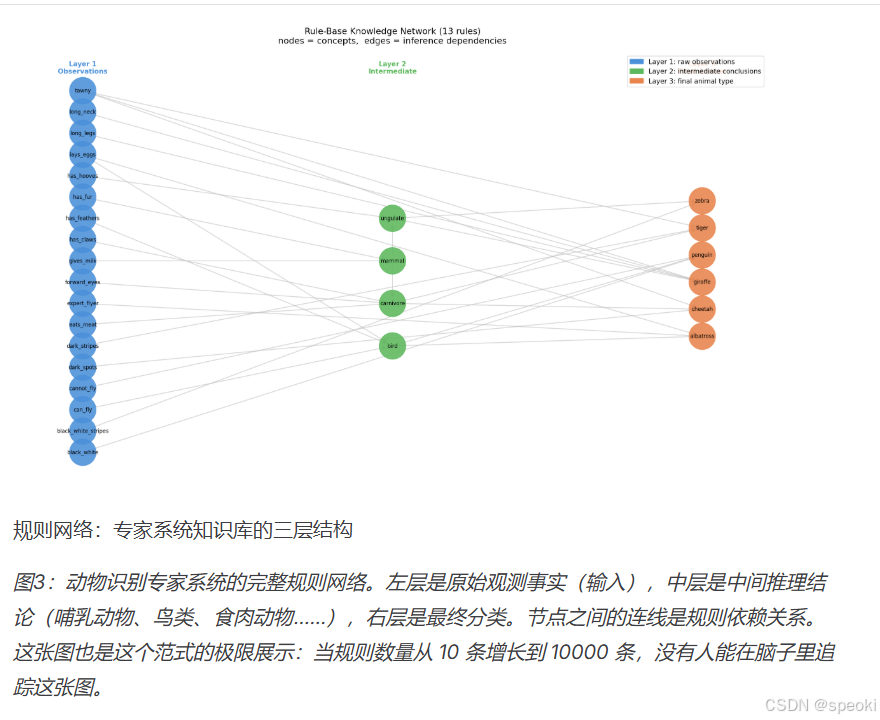
这张图也是这个范式的极限展示
符号 AI 和专家系统的时代给了我们一个非常干净的教训:把世界的知识显式地表达成规则,这件事从原则上就是不可能完成的任务。不是因为我们不够努力,而是因为知识的结构本身不是规则的形式------它是情境性的、内隐的、连续的、生成式的。
逻辑门 是因果关系的最简物理实现。规则系统 是因果推理的最直接建模。在它们擅长的地方,它们工作得非常好。但世界比这个宽广得多 。
【封闭世界假设】是这个范式的死穴:在你知道的范围内,它很强;【在你知道的边界处,它会优雅地崩溃;而你永远不知道那个边界在哪里,因为你不知道自己不知道什么】。
这是一个值得记住的模式。不只是关于专家系统的,而是关于任何推理系统 的。每一个推理系统都有它的【封闭世界边界】------【它在显式或隐含地假设某些东西不存在,或者某些情况不会发生。当现实触碰到这个边界,推理就会以某种方式失效】。
失效的方式不同,教训是一样的:推理需要世界模型,世界模型的边界,就是推理的边界。
第三章,我们要开始讲向量,讲连续表示空间,讲表示学习的革命。从离散的符号,走向连续的向量,是一次根本性的跨越。但这次跨越带来的新问题,比它解决的旧问题,不一定更少。
悬而未决
- 现代大型语言模型是否以某种隐含的方式,重新引入了封闭世界假设?训练数据的分布,是否就是一种新形式的"知识库边界"?
结论:是。大模型的 "封闭世界边界" 就是训练数据的分布,这是一种更隐蔽、更宽泛,但本质上没有突破的封闭性。

- 大模型的封闭性比专家系统更 "宽"------ 因为训练数据覆盖了人类语言的大部分场景,所以边界外的问题比例更低;
- 但大模型的封闭性比专家系统更 "隐蔽"------ 它不会像专家系统一样 "承认自己没规则",而是用 "看似流畅的语言" 掩盖自己 "没见过" 的事实(这就是幻觉的根源);
- 训练数据的分布就是新的 "知识库边界"------ 比如:
- 训练数据里没有 2025 年后的事件,大模型就无法准确预测 2025 年的技术趋势;
- 训练数据里对某个小众领域的描述是片面的,大模型就会输出片面的结论(甚至偏见)。
本质上,大模型只是把封闭世界的 "规则边界" 换成了 "数据边界"------ 它没有突破 "只能处理已知范围" 的桎梏,只是把范围扩大了。
- 专家系统的可解释性是一个真正的优势。但可解释性和正确性,是同一件事吗?能把推理过程说清楚,不等于推理过程是对的。
结论:不是同一件事。可解释性 ≠ 正确性,二者是相关但独立的两个维度。
- 可解释性: "能说清推理过程",但过程可能基于错误的前提
专家系统的可解释性是 "机械透明" 的 ------ 它的推理链是显式的 规则A→规则B→结论C,你能清晰看到每一步的逻辑。但这种透明性,不保证前提规则的正确性。举个例子:- 专家系统的规则库写了 "所有鸟都会飞"(规则A)、"企鹅是鸟"(规则B);
- 推理过程是 A+B→"企鹅会飞"(结论C)------ 这个推理过程完全可解释,但结论完全错误。
- 正确性:"结论符合现实",但过程可能无法解释
现代大模型的正确性(比如能正确回答 "企鹅不会飞"),来自训练数据中对 "企鹅" 的大量描述 ------ 它通过【高维模式匹配】,捕捉到了 "企鹅是鸟但不会飞" 的隐含关联。
但这个过程不可解释------ 你无法说清大模型是 "通过哪条规则" 得出的结论,只能说 "它在数据里见过类似的表述"。 - 可解释性与正确性的关系:一个二维坐标系

核心启示: - 可解释性的价值是 "便于纠错"------ 当专家系统输出错误结论时,你能直接修改对应的规则;而大模型输出错误时,你只能通过微调数据来间接修正。
- 但可解释性不是正确性的保证------ 错误的规则,再透明的推理过程,也会导出错误的结论。
- Dreyfus 的批评有一个核心:情境性知识无法被显式化。大型语言模型是否以某种方式捕获了情境性知识?还是它们只是在做一个非常高维度的模式匹配?
结论:大模型通过 "高维模式匹配" , 近似捕获了一部分情境性知识 ,但并没有真正突破 "情境性知识无法显式化" 的本质 ------ 它只是把情境性知识变成了 "隐式的模式关联" ,而非 "显式的规则"。
要理解这个结论,我们需要先回到 Dreyfus 所说的 **"情境性知识" 的本质 **:
情境性知识是身体与环境互动的产物,是 "只可意会不可言传" 的直觉 ------ 比如你知道 "怎么坐椅子才舒服""怎么走路才不摔倒",这些知识无法写成规则,只能通过体验获得。
第一步:选一个你真的懂的领域
第二步:写出你的规则库
python
# 规则的数据结构:每条规则是一个字典
# 'conditions':前提条件列表(列表中所有条件都满足才能触发)
# 'conclusion':规则结论(一个字符串)
# 'name':规则名称,便于追踪推理轨迹
# 示例:以"判断菜系"为领域的规则库
rules = [
# ── 中间层规则:识别食材特征 ──────────────────────────────
{"name": "R1", "conditions": ["有鱼腥草"], "conclusion": "使用了四川特色食材"},
{"name": "R2", "conditions": ["有辣椒", "有花椒"], "conclusion": "麻辣风格"},
{"name": "R3", "conditions": ["有生鱼片"], "conclusion": "使用了日式食材"},
{"name": "R4", "conditions": ["有味噌"], "conclusion": "使用了日式食材"},
{"name": "R5", "conditions": ["有豆豉", "有蒸鱼豉油"],"conclusion": "粤式调味"},
{"name": "R6", "conditions": ["有姜葱"], "conclusion": "粤式底味"},
# ── 中间层规则:识别烹饪方式 ──────────────────────────────
{"name": "R7", "conditions": ["大火爆炒"], "conclusion": "高温快炒风格"},
{"name": "R8", "conditions": ["清蒸"], "conclusion": "清淡烹饪风格"},
{"name": "R9", "conditions": ["炭火烤制"], "conclusion": "烧烤风格"},
# ── 终结层规则:得出菜系结论 ──────────────────────────────
{"name": "R10", "conditions": ["使用了四川特色食材", "麻辣风格"], "conclusion": "是川菜"},
{"name": "R11", "conditions": ["使用了日式食材"], "conclusion": "是日料"},
{"name": "R12", "conditions": ["粤式调味", "清淡烹饪风格"], "conclusion": "是粤菜"},
{"name": "R13", "conditions": ["粤式底味", "粤式调味"],"conclusion": "是粤菜"},
{"name": "R14", "conditions": ["烧烤风格", "使用了四川特色食材"], "conclusion": "是川式烧烤"},
{"name": "R15", "conditions": ["高温快炒风格", "粤式调味"], "conclusion": "是粤式小炒"},
]a. 写中间层规则,不要只写直达结论的规则。
坏的写法:
IF 有鱼腥草 AND 有辣椒 THEN 是川菜
好的写法:
IF 有鱼腥草 THEN 使用了四川特色食材
IF 有辣椒 AND 有花椒 THEN 麻辣风格
IF 使用了四川特色食材 AND 麻辣风格 THEN 是川菜
中间层让推理链变得可解释,也让问题暴露得更清楚
b. 试着从结论反推,而不只是从条件正推。
问自己:"要得出'是川菜',最少需要什么前提?这些前提够吗?有没有例外?"
第三步:实现前向链接引擎
本章已经给了你完整的伪代码逻辑:
python
def forward_chain(rules, initial_facts):
"""
前向链接推理引擎。
rules: 规则列表,每条规则有 'conditions'、'conclusion'、'name' 三个字段。
initial_facts: 初始观测事实的集合(set)。
返回:(最终事实集合, 推理轨迹列表)
"""
# 已知事实集合 = 输入的观测集合
known_facts = set(initial_facts)
reasoning_trace = [] # 记录触发了哪条规则(推理轨迹)
# 重复推理,直到没有新事实被加入
while True:
new_fact_added = False # 标记本轮是否有新事实加入
for rule in rules:
# 检查规则的所有前提是否都在已知事实集合里
conditions_met = all(cond in known_facts for cond in rule["conditions"])
if conditions_met and rule["conclusion"] not in known_facts:
# 把规则的结论加入已知事实集合
known_facts.add(rule["conclusion"])
# 记录触发了哪条规则(这是你的推理轨迹)
reasoning_trace.append(
f"触发 {rule['name']}: {rule['conditions']} → {rule['conclusion']}"
)
new_fact_added = True
# 如果这一轮没有新事实被加入,停止
if not new_fact_added:
break
# 输出:已知事实集合 + 推理轨迹
return known_facts, reasoning_trace
# ── 示例运行 ────────────────────────────────────────────────────
# 初始观测:输入的菜品特征
initial_observations = {"有鱼腥草", "有辣椒", "有花椒", "大火爆炒"}
final_facts, trace = forward_chain(rules, initial_observations)
print("=== 推理轨迹 ===")
for step in trace:
print(" ", step)
print("\n=== 最终结论 ===")
conclusions = [f for f in final_facts if f.startswith("是")]
for c in conclusions:
print(" ", c)第四步:构造三个测试案例,让它一个通过,两个失败
案例 A:正常案例。 一个你的规则库能完整覆盖的典型案例。输入观测,得到正确结论,推理轨迹完整。这是"系统工作"的证明。
案例 B:边界案例。 构造一个处于两个类别之间的模糊案例 ------同时满足两个不同结论的前提条件 。观察系统的行为:它是报告两个结论?选择第一个匹配的?还是静默地给出一个错误答案?
你的第一个问题: 你的系统在案例 B 里的行为,是"可以接受的失败",还是"危险的沉默失败"?这两者有什么区别?
案例 C:分布外案例。 构造一个你的规则库完全没有预见到的案例------比如一道融合菜,同时有四川和日本的食材;或者一台电脑,故障现象跨越了所有已知类别。
观察:系统会给出什么?它会说"我不知道"吗?还是它会沿着某条最近的规则链,给出一个看似合理但实际错误的答案?
你的第二个问题: 案例 C 的输入,触发了哪些规则?这些规则本来是为什么情况设计的?系统误用规则的方式,说明了封闭世界假设的哪个具体缺陷?
第五步:算一笔账
你写了多少条规则?这些规则覆盖了这个领域的多少?
估算一下:你认为这个领域里,还有多少你没有写进去的知识?那些没写进去的知识,是因为你不知道,还是因为你"知道但说不出来"?
你的第三个问题(也是最难的一个): 如果要把你在这个领域的全部知识都转化成规则,需要多少条?这个数字,是有限的吗?
延伸阅读
Shortliffe, E. H. (1976). MYCIN: Computer-Based Medical Consultations --- 专家系统的奠基性案例研究
Dreyfus, H. L. (1972). What Computers Can't Do --- 对符号 AI 范式的哲学批判,在当时被嘲笑,后来被证明深刻
Reiter, R. (1978). "On Closed World Databases." Logic and Data Bases --- 封闭世界假设的形式化定义,理解本章核心概念的原始来源
Minsky, M. (1975). "A Framework for Representing Knowledge." The Psychology of Computer Vision --- Frame 系统,另一种尝试解决知识表示问题的路径
Winston, P. H. & Horn, B. K. P. (1981). LISP --- 包含动物识别专家系统经典案例,本章脚本的原始灵感
Bader et al., 2004, arXiv:cs/0408069 --- 神经-符号整合:连接主义与一阶逻辑知识表示的统一挑战,专家系统时代问题在现代的回响