ConcurrentHashMap 线程安全实现原理全解析
在 Java 高并发编程的工具箱里,ConcurrentHashMap 无疑是"皇冠上的明珠"。它在保证线程安全的同时,提供了接近原生 HashMap 的高性能,这背后是 Java 并发大师们对锁粒度和数据结构的极致压榨。
今天,我们将通过对比 JDK 1.7 与 1.8 的演进,深度剖析它的核心原理与其背后的设计哲学。
1. 这篇文章要解决什么问题?
在多线程环境下,普通的 HashMap 就像是无序的交通现场,Put 操作随时可能导致数据丢失。 为了解决安全问题,早期的方案是:
- Hashtable :简单粗暴,给所有方法都加上
synchronized。这相当于整条马路只有一条车道,不管是读还是写,大家都得排队,性能极低。 - Collections.synchronizedMap :本质与
Hashtable一样,都是单对象锁。
ConcurrentHashMap 的诞生,就是为了解决 "高并发下的读写吞吐量" 问题。它要做到:读不加锁,写尽量不互斥。
2. 核心原理:从"分段锁"到"细粒度锁"
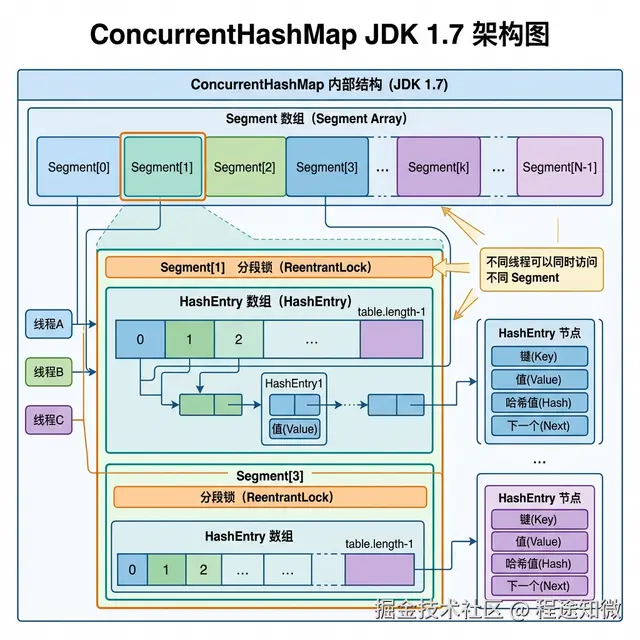
JDK 1.7:分段锁 (Segment)
在 1.7 版本中,ConcurrentHashMap 采用的是"分而治之"的思想。
- 结构 :它内部包含一个
Segment数组,每个Segment本身就是一个继承了ReentrantLock的锁。 - 锁粒度 :如果你修改下标为 1 的数据,只会锁住
Segment[1]。此时其它线程依然可以并发修改Segment[2]。 - 缺点 :锁的粒度还是偏大,且
Segment对象的存在增加了额外的内存开销。
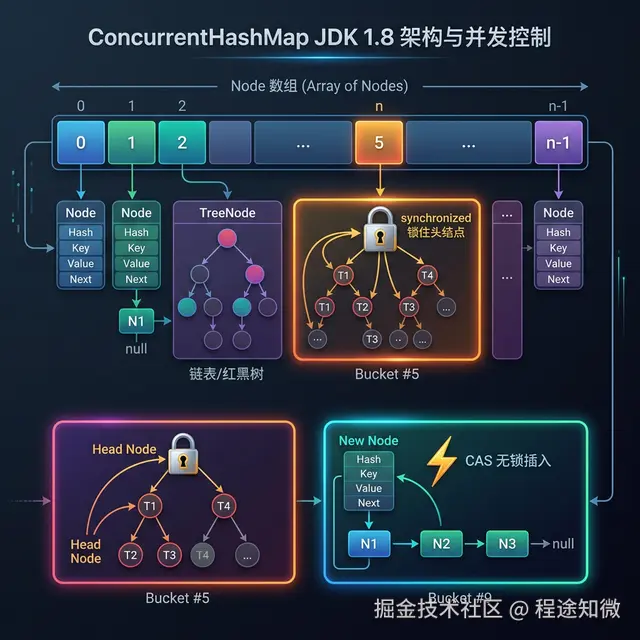
JDK 1.8:CAS + synchronized
在 1.8 中,官方抛弃了 Segment,直接回归到"数组+链表+红黑树"的结构。
- 锁粒度 :它不再锁住一个"段",而是锁住 数组的头结点 (Node)。这意味着只要 Hash 桶不同,线程之间完全互不干扰。
- 底层技术 :
- CAS :在插入首个节点时,使用
unsafe.compareAndSwapObject。如果是空位,直接放入,全程无锁。 - synchronized:如果首位已经有值(发生碰撞),则只针对头结点加锁,确保链表/红黑树操作的原子性。
- CAS :在插入首个节点时,使用
3. 流程/机制描述:高并发下的"骚操作"
Put 流程:精密的协作逻辑
- 无感初始化 :第一次 Put 时才通过
sizeCtl和 CAS 初始化数组。 - CAS 试探:如果桶位为空,直接 CAS 插入,失败则重试(自旋)。
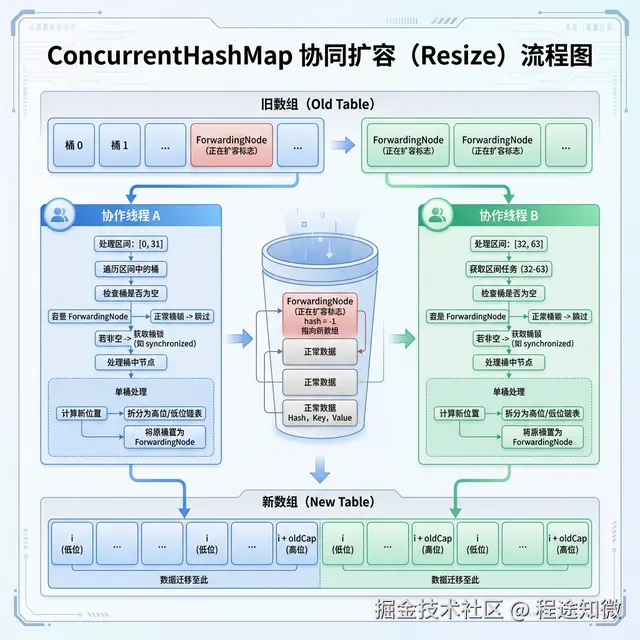
- 协助扩容 (Help Transfer):如果发现节点的 Hash 值为 -1 (ForwardingNode),说明此时其它线程正在扩容,当前线程会主动加入扩容大军,协助搬运数据。
- 定位锁头 :如果桶位不为空且未扩容,通过
synchronized(f)锁住头结点,进行链表或红黑树的插入。
get 操作:为什么读不需要加锁?
这是很多人的盲区。ConcurrentHashMap 的 get 操作全程无锁。
- volatile 保证 :数组引用
table和 Node 的next指针、val均使用了volatile修饰。 - 可见性 :根据 JMM 原理,写线程对
val的修改对比读线程是立即生效的。由于不涉及状态变更的竞争,直接读即可保证高性能。
协作扩容:多线程搬迁逻辑
4. 关键代码/示例:别掉进"原子性"陷阱
哪怕 ConcurrentHashMap 的方法都是线程安全的,如果你组合使用它们,依然可能产生逻辑漏洞。
java
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
/**
* 演示:ConcurrentHashMap 复合操作的原子性陷阱
*/
public class AtomicTrapDemo {
private static final ConcurrentMap<String, Integer> scoreMap = new ConcurrentHashMap<>();
public static void main(String[] args) {
scoreMap.put("Alice", 10);
// --- 错误示范:复合操作破坏了原子性 ---
Integer oldScore = scoreMap.get("Alice");
Integer newScore = oldScore + 1; // 两个线程可能在这里拿到相同的 oldScore
scoreMap.put("Alice", newScore);
// --- 正确写法 1:使用 replace (基于 CAS) ---
scoreMap.replace("Alice", oldScore, newScore);
// --- 正确写法 2:使用 compute (推荐,更简洁原子化) ---
// compute 方法内部会锁住该桶的头结点,确保加 1 操作是绝对安全的
scoreMap.compute("Alice", (key, value) -> (value == null) ? 1 : value + 1);
System.out.println("Alice 的最新分数为: " + scoreMap.get("Alice"));
}
}5. 常见误区
误区 1:synchronized 性能很差,所以 1.8 的设计退步了
纠正 :在 Java 6 优化锁升级(偏向、轻量级、重量级)后,synchronized 的性能并不弱于 ReentrantLock。且 synchronized 不需要手动释放锁,减少了异常导致死锁的风险。而在 AQS 实现的 ReentrantLock 中,大量对象创建也会带来 GC 压力。
误区 2:Size 方法需要遍历全表
纠正 :AQS 的设计思想被借鉴到了 mappingCount() 中。它内部维持了一个类似 LongAdder 的结构(CounterCell 数组),将冲突分散。获取 size 时只需把 BaseValue 和所有 Cell 的值累加,不需要锁表。
6. 实际工作中怎么用?
- 组合操作必用 compute/putIfAbsent:涉及"如果不存在则放入"、"根据原值计算新值"的情况,严禁先 Get 再 Put。
- 弱一致性遍历 :
ConcurrentHashMap的迭代器是 弱一致性 的。如果在遍历过程中有其它线程修改了数据,迭代器不一定会抛出ConcurrentModificationException,但也不保证能读到最新的修改。 - 合理配置并发级别 :虽然 1.8 已经不再需要像 1.7 那样手动配置
concurrencyLevel,但在初始化时给出一个合理的初始容量依然能有效减少昂贵的扩容频次。
总结
ConcurrentHashMap 是并发编程中的集大成者。它不仅利用了 volatile 的内存可见性,还通过 CAS 和 synchronized 巧妙地控制了锁的粒度。理解它,你会明白为什么"并发不是简单的加锁",而是对系统资源的精妙调度与利用。