目录
[1 文献阅读:《Coalbed methane concentration prediction and early-warning in fully mechanized mining face based on deep learning》](#1 文献阅读:《Coalbed methane concentration prediction and early-warning in fully mechanized mining face based on deep learning》)
[1.1 背景](#1.1 背景)
[1.2 方法论](#1.2 方法论)
[1.3 创新点](#1.3 创新点)
[1.4 实验结果及分析](#1.4 实验结果及分析)
[2 补充](#2 补充)
[2.1 GRU](#2.1 GRU)
[2.2 GA 遗传算法](#2.2 GA 遗传算法)
[2.3 PSO 粒子群优化算法](#2.3 PSO 粒子群优化算法)
[3 总结](#3 总结)
摘要
本周主要阅读了《Coalbed methane concentration prediction and early-warning in fully mechanized mining face based on deep learning》这篇论文,主要了解了从数据处理、模型构建与训练到实际应用落地的完整流程;其次,基于论文对 GRU 进行了回顾,梳理了其门控结构;最后,对遗传算法以及粒子群优化算法进行了学习,了解了其原理、算法流程与优缺点等。
Abstarct
This week, I mainly read the paper titled "Coalbed methane concentration prediction and early-warning in fully mechanized mining face based on deep learning," focusing on understanding the complete workflow from data processing and model construction/training to practical application and deployment. Second, based on the paper, I reviewed GRU and sorted out its gating structure. Finally, I studied genetic algorithms and particle swarm optimization, gaining an understanding of their principles, algorithmic procedures, advantages, and disadvantages.
1 文献阅读:《Coalbed methane concentration prediction and early-warning in fully mechanized mining face based on deep learning》
链接:基于深度学习的全机械化采矿面煤层甲烷浓度预测与预警------ScienceDirect
1.1 背景
煤层气(CBM)灾害占煤矿重大事故的90%,容易造成严重人员伤亡和财产损失,且随着开采深度和强度的增加,其浓度、压力和含量逐渐升高,事故风险也不断加大。
同时,现有的煤层气浓度预测方法存在着显著局限。比如,源预测法的许多参数难以实时量化,无法应用于实时预测;回归分析对专业知识的依赖性强,模型泛化能力差;浅层神经网络则需人工特征提取,且面对大数据时易过拟合,预测时间也较长。
因此在实际应用中,煤矿企业采集的大量时序数据通常难以得到有效利用,甚至出现丢失的状况。
1.2 方法论
本文从数据预处理、模型构建以及实际应用三个方面出发,尝试解决上述问题。
在数据与处理方面,对于缺失值,利用三次指数平滑法在平滑补充缺失值的同时保持原时间序列趋势;对于异常值,利用自回归模型(AR)对其进行识别与替换;对于数据中的噪声,则利用小波阈值去噪法平滑数据,过滤噪声。
在模型构建方面,首先,利用主成分分析法(PCA)降维数据以提取关键特征;其次,由于 GRU 相对 LSTM 参数更少,计算更快,故选择 GRU 作为基础模型,并利用粒子群优化算法(PSO)和遗传算法(GA)对 GRU 的超参数进行优化。
在实际应用上,结合 Kafka 和 Spark Streaming 流处理框架,构建分布式数据处理框架,并基于置信区间及瓦斯浓度持续增加时间设定预警阈值,划分正常、一级预警和二级预警。
1.3 创新点
在数据预处理上,针对瓦斯时序数据存在的异常值、缺失值和噪声问题,首次提出结合三次指数平滑、AR模型和小波去噪的预处理方案,且将误差控制在10%以内,有效提升了数据质量。
在模型构建上,提出混合模型架构,利用优化算法解决了循环神经网络学习能力弱和易过拟合的问题,显著提升了预测精度和训练效率。
在实际应用上,首次将优化的深度学习模型与 Spark Streaming 流计算框架结合,实现从数据采集到预警发布的全流程实时处理,填补了深度学习与大数据处理技术在煤矿安全领域应用的空白。
1.4 实验结果及分析
实验也主要分为三个方面,即数据预处理方法是否有效,混合模型与其他模型效果对比以及预警系统的效果。
数据预处理方面,处理缺失值的误差为 3.3%,处理异常值的误差在 10% 以内,小波去噪后曲线更平滑,能够在保留关键趋势信息的同时消除高频噪声,验证了预处理方法的有效性。
模型效果方面,主要是提出的两种混合模型架构与 GRU、RNN、LSTM、BPNN、SVR 几种模型架构效果进行对比,发现 PCA-PSO-GRU 模型表现最优,PCA-GA-GRU 模型其次,BPNN 最差。PSO 的优化效果优于GA,主要是因为参数少,调整过程简单方便。
预警系统方面,在工作面、上隅角、回风巷和进风巷四个区域的预警准确率均超过 90%,且预警速度快,使用3台虚拟机时预警时间达 7s 左右,能够满足高效预警需求。
2 补充
本节主要对前面论文的模型构建方面进行补充学习,主要包括 GRU、PSO 以及 GA 算法。
2.1 GRU
前面学习 GRU 时,主要是将它看作 LSTM 的附属,在阅读论文时发现对它的模型架构不是特别熟悉,故在此进行补充学习。
GRU(Gated Recurrent Unit,门控循环单元)是 Kyunghyun Cho 等人在 2014 年提出的一种简化版的 LSTM。相比 LSTM,它主要通过减少门控机制和参数数量来简化模型结构、降低计算复杂度,并加速训练过程,核心思想即对 LSTM 的三个门(遗忘门、输入门、输出门)进行简化和合并。
首先,移除了独立的细胞状态,它的隐藏状态( )同时扮演了 LSTM 中隐藏状态和细胞状态的角色,是短期记忆与长期记忆的共同载体。
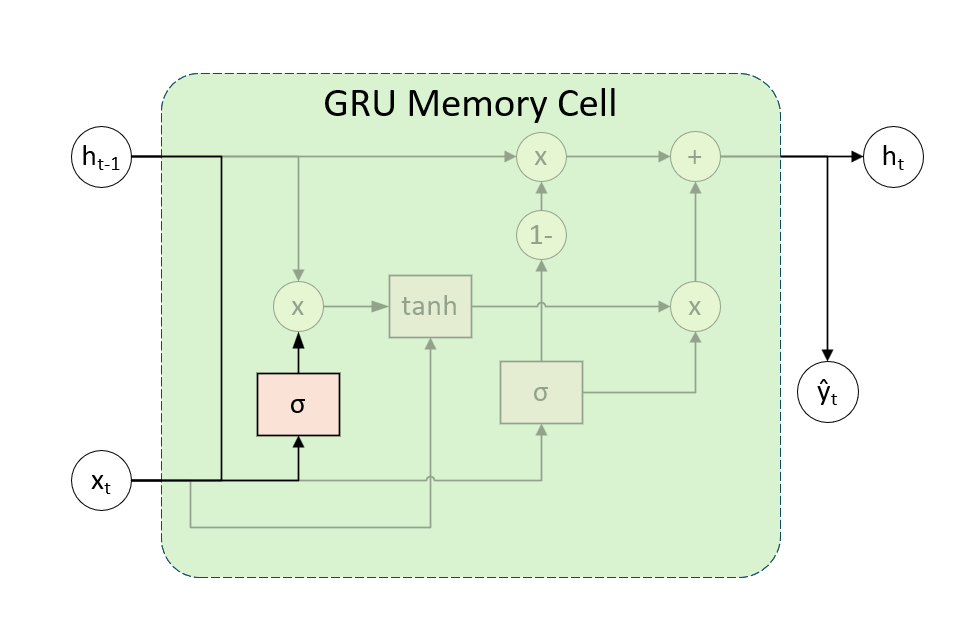
其次,引入重置门(Reset Gate )控制信息的写入,若 接近0 表示几乎完全忽略
,
接近 1 表示几乎完全保留
。门控公式与图像如下:
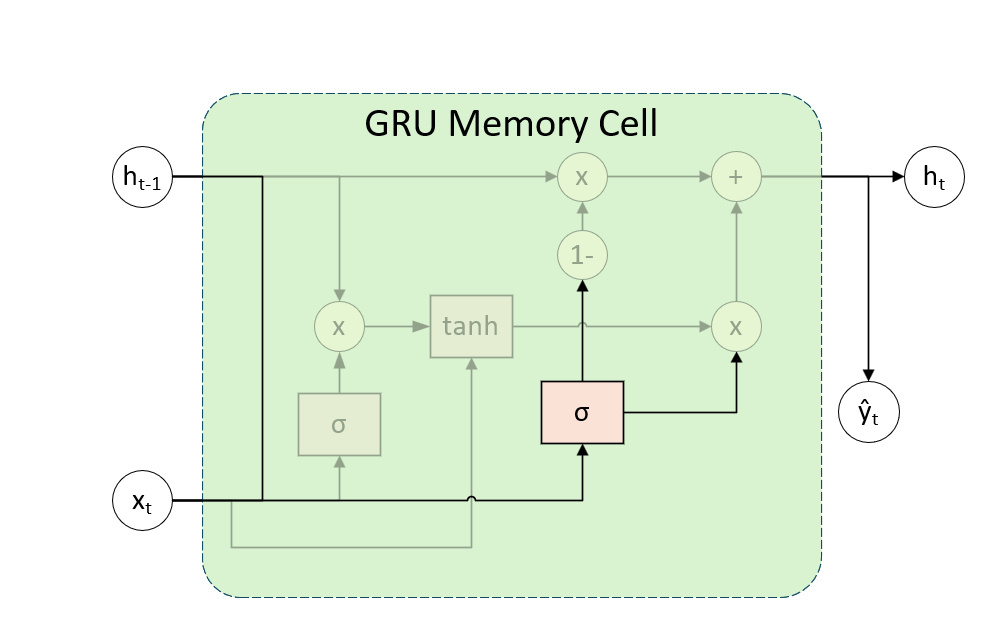
接着,将 LSTM 的遗忘门和输入门合并为更新门(Update Gate),同时控制遗忘和更新,即历史信息与当前输入的融合比例。门控公式与图像如下:
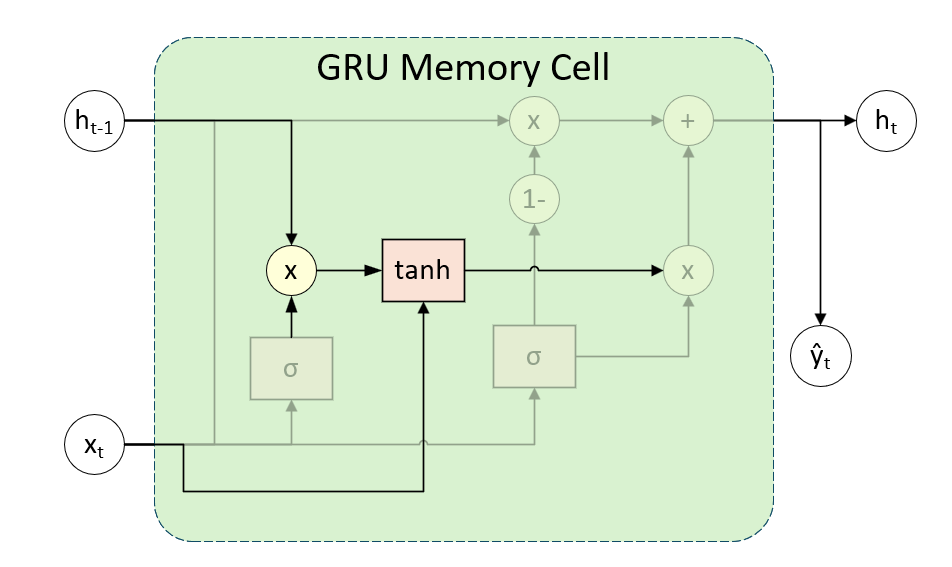
另外,它将重置门过滤后的历史信息与当前输入通过 Tanh 函数生成候选隐藏状态,这个设计允许网络在计算新信息时,有选择地忽略无关的历史信息。其公式与图像如下:
最终将旧状态与候选隐藏状态加权融合得到最终隐藏状态,公式如下:
由于 GRU 相较于 LSTM 结构更简单,计算高效,也更容易理解,但表达能力可能在一定程度上受限,故适应于大多数序列建模任务,如语音识别、时间序列预测等。
2.2 GA 遗传算法
遗传算法(Genetic Algorithm,GA)是进化计算的一个重要分支,是一种模拟自然界生物进化过程的随机自适应全局搜索与优化算法,最早由美国密歇根大学教授John H. Holland提出。
它基于自然选择和优胜劣汰的进化规律,通过模拟生物进化中的选择、交配和变异机制来寻找问题的全局最优解,主要通过维护一个代表问题潜在解的群体,通过不断迭代使种群中的个体越来越适应环境,末代种群中的最优个体经过解码即可作为问题的近似最优解。
为了实现种群的进化,遗传算法主要利用三个核心遗传算子,即选择、交叉(交配)以及变异。其中,选择 主要依据适者生存原则,从当前群体中选出优良个体作为父代繁衍子孙;交叉(交配) 将群体中的个体随机配对,以一定的概率交换它们之间的部分染色体,从而产生新个体,即具有父辈特征的新后代;变异则是对个体染色体上的某些基因以较低的变异概率进行随机改变,用以引入新的遗传信息,增加种群的多样性,能够帮助算法跳出局部最优解。
算法基本流程大致如下:
首先,设置进化代数计数器及最大进化代数,随机生成一定数量的个体组成初始种群,并计算种群中每个个体的适应度值,进行个体评价
其次,应用三个算子,选出优良个体,生成新个体并对部分基因进行随机变动得到下一代种群
最后,若进化代数达到最大值或满足其他终止条件,则以进化过程中具有最大适应度的个体作为最优解输出,终止计算;否则,返回步骤2继续迭代。
遗传算法本质上是一种并行、高效的全局搜索方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最优解。由于其强大的鲁棒性和全局搜索能力,GA已被广泛应用于组合优化、机器学习、信号处理、自适应控制、人工生命以及各类工程领域的复杂优化问题中。
2.3 PSO 粒子群优化算法
粒子群优化算法(Particle Swarm Optimization,PSO)是一种基于群体智能的启发式优化算法,拟鸟群觅食或鱼群游动的社会行为,认为群体智慧往往超越个体智慧,故选择利用粒子间的协作与信息共享来寻找最优解,由 James Kennedy 和 Russell Eberhart 于 1995 年提出,相对遗传算法更加简单高效。
以鸟群搜寻食物为例。刚开始,所有的鸟都不知道食物的具体位置,但能感知自己离食物有多远,那么寻找食物最简单有效的策略就是寻找当前离食物最近的鸟的附近区域。 在算法中,将鸟看作粒子,食物看作最优解,每个优化问题的潜在解都被抽象为搜索空间中的一个粒子(即离食物最近的鸟),它只有位置和速度两个属性。所有粒子在搜索空间中以一定速度飞行,其飞行方向和距离回根据自身的飞行经验(个体极值)和整个群体的飞行经验(全局极值)进行动态调整,从而逐步收敛于最优解。
假设在一个 D 维搜索空间中,有 n 个粒子,那么第 i 个粒子的位置可表示为 ,速度与其类似。在每一次迭代中,粒子通过跟踪 pbest(个体极值)和 gbest(全局极值)来更新自己的速度和位置,公式如下:
速度:
位置:
其中,w 为惯性权重,控制先前速度对当前速度的影响;、
为加速常数(或学习因子),前者调节粒子向自身历史最优位置移动的步长,后者则调节粒子向全局最优位置移动的步长,通常均设为 2;
、
为随机数,增加算法的随机性以扩大搜索空间。
算法流程大概包括两步,即初始化与迭代。首先,随机初始化粒子群中每个粒子的位置和速度,计算初始适应度,并设定初始的个体极值和全局极值。其次,每次迭代,先对比个体与群体分别的当前适应度与历史极值,选择是否更新极值,再根据速度和位置更新公式,计算每个粒子下一代的速度和位置,若达到最大迭代次数或适应度值满足收敛条件,则停止迭代并输出 gbest 作为最优解,否则继续迭代。
PSO 原理简单,容易实现,收敛速度快,同时全局搜索能力强,但它缺乏理论保障,容易陷入局部最优,在后期粒子速度逐渐减小,位置更新幅度变窄,收敛速度也会相应变慢。
3 总结
本周主要阅读了一篇关于煤层甲烷浓度预测方面的论文,新学习了遗传算法与粒子群优化算法。感觉随着论文阅读量的积累,逐渐开始掌握阅读技巧,能够更快地提取关键信息。另外,感觉这篇论文模型效果不算很好,但从训练到部署的流程比较完整,涉及到的未知或者说不太清楚的方法也较多,下周可以就几种数据预处理方法进行了解学习。