Harness Engineering 是什么:从提示词工程、上下文工程到驾驭工程的技术解读
本文章转自v.douyin.com/BGTi7gOUIRo... ,推荐大家都去看原视频!
引言
过去两年,AI 圈里最火的几个词,几乎离不开这几个:提示词工程(Prompt Engineering) 、上下文工程(Context Engineering) 、AI Agent ,以及这篇文章要重点讲清楚的 Harness Engineering。
很多人刚接触 AI 开发时,会把注意力放在"提示词怎么写"上;再进一步,会开始接触检索、记忆、规则文件、代码代理、工具调用和自动修复;再往后就会发现:真正决定 AI 应用落地效果的,往往不是模型本身,而是围绕模型外面那层工程外壳。
这层外壳,不只是 Prompt,也不只是 RAG,更不只是 Agent 框架。它是一个更完整的工程体系:负责约束模型、组织上下文、驱动执行、接收反馈、沉淀记忆、编排流程,最终把一个"只会预测下一个 token 的模型"变成一个"能够稳定完成真实任务的系统"。
这篇文章的主题,就是把这个外壳讲清楚:
Harness Engineering,本质上就是围绕大模型构建可约束、可执行、可反馈、可编排、可持续交付的工程系统。
文章会按下面这条主线展开:
- 大模型本质上在做什么
- 提示词工程解决什么问题
- 上下文工程解决什么问题
- Agent 为什么仍然不够
- Harness Engineering 到底是什么
- Harness Engineering 的核心分层与系统架构
- 如何在真实项目里落地
一、大模型本质上在做什么
如果把 ChatGPT、Claude、AI IDE、AI Agent 这些产品外壳都剥掉,最里面的大模型,本质上做的事情其实很简单:
基于当前输入的上下文,预测下一个最可能出现的 token。
也就是说,大模型本质上不是"真的懂了所有事情",而是在已有上下文基础上,持续进行概率预测。
这带来一个非常直接的结论:
- 输入越模糊,输出越泛泛
- 约束越明确,输出越稳定
- 给的信息越相关,回答通常越准确
- 给的信息越杂乱,模型越容易跑偏
所以,AI 开发从来不是"模型自己会搞定一切",而是一个持续给模型"提供合适信息、控制信息结构、约束输出行为"的过程。
二、提示词工程是什么
2.1 定义
提示词工程(Prompt Engineering) ,就是通过设计输入提示,让模型更稳定地朝预期方向输出内容和格式的技术方法。
它的核心目标不是"把话说得花哨",而是:
让模型明确知道你要它做什么、不要它做什么、输出成什么样。
2.2 提示词通常包含什么
一个完整的 Prompt 往往会包含这些要素:
- 角色设定
- 任务目标
- 业务背景
- 输入数据说明
- 约束条件
- 禁止事项
- 输出格式
- 示例
- 评分标准或验收标准
例如,同样是让模型改一段代码:
模糊写法可能只是:
帮我给这段代码加个排序。
而更工程化的写法会是:
- 仅修改必要代码
- 不要改动现有业务逻辑
- 使用 Java 8 语法
- 按 createTime 倒序排序
- 返回完整函数代码
- 最后说明修改点
两者效果往往差很多。
2.3 Prompt Engineering 解决什么问题
它解决的核心问题是:
模型在缺乏明确引导时,容易泛化回答、自由发挥、偏离预期。
提示词工程的价值,就是减少这种"无引导乱说话"的现象。
但注意,Prompt Engineering 并不是 AI 应用开发的全部。它只是第一层。
三、什么是上下文
在理解上下文工程之前,先要明确"上下文(Context)"是什么。
一次模型调用时,模型能看到的全部信息总和,就是上下文。它通常包括:
- 系统提示词
- 用户提示词
- 历史对话
- 外部文档
- 检索召回结果
- 当前代码文件
- 工具调用结果
- 错误日志
- 测试输出
- 环境信息
所以必须强调一句:
Prompt 只是 Context 的一部分。
如果把 AI 理解成一个需要被喂信息的系统,那么 Prompt 只是其中最显眼的一块,但绝不是全部。
四、上下文工程是什么
4.1 定义
上下文工程(Context Engineering) ,就是在有限上下文窗口内,动态决定:
- 什么时候给模型什么信息
- 给哪些信息
- 不给哪些信息
- 信息先后顺序如何安排
- 信息以什么形式进入模型
它的目标不是单纯"写好一句 Prompt",而是:
让模型在每一轮都看到最相关、最关键、最有结构的信息。
4.2 它解决什么问题
上下文工程解决的是:
模型上下文如何组织的问题。
提示词工程关注的是"怎么说清楚";
上下文工程关注的是"该给它看什么、怎么给、给多少"。
这就是为什么:
- 同样一个模型
- 在不同 AI IDE 或 AI Agent 产品里
- 表现会明显不同
因为差异往往来自上下文工程,而不是模型本身。
五、为什么会有上下文腐化
5.1 上下文窗口不是无限的
大模型一次能处理的信息量是有上限的,这个上限通常叫做:
上下文窗口(Context Window) 。
当任务很长、对话很多轮、读取文件很多、工具调用很多时,进入模型的内容会越来越多。问题随之而来:
- 前面设定的目标会被冲淡
- 重要规则会被淹没
- 历史信息压缩后可能丢失关键点
- 新信息不断覆盖旧约束
5.2 什么是上下文腐化
这类随着任务推进导致的"记忆偏移、目标漂移、回答失真"问题,可以统称为:
上下文腐化(Context Corruption) 。
常见表现包括:
- 前后回答不一致
- 忘记之前的限制条件
- 忘记输出格式要求
- 越做越偏离原始任务
- 修改范围不断失控
在 Agent 场景里,这类问题尤其常见。
六、上下文工程的三个核心动作
从工程视角看,上下文工程可以概括为三个动作:
6.1 召回(Retrieve)
先解决:当前最该找什么信息。
信息来源可能包括:
- 知识库
- 历史聊天
- 项目代码
- 本地文件
- 运行日志
- 报错栈
- 外部网页或 API
- 测试结果
召回的本质是:
从大量候选信息里,找到当前任务最相关的内容。
6.2 压缩(Compress)
因为上下文窗口有限,不可能把所有内容原封不动都塞进去。
所以需要压缩,例如:
- 摘要总结
- 关键信息提炼
- 去重
- 结构化提取
- 长文切块后再总结
压缩的核心目标是:
保留关键信号,丢掉噪音。
6.3 组装(Assemble)
即使召回和压缩做对了,如果组装顺序错了,模型效果也可能不好。
因为模型对不同位置的信息关注程度并不完全一致。通常:
- 越靠近当前任务目标的信息越容易被关注
- 越明确的规则越应该放在高优先级位置
- 冲突信息如果并排放入,会导致模型不稳定
所以最终不是"把所有东西拼起来"那么简单,而是要进行结构化组装,例如:
- 系统规则
- 当前任务目标
- 当前限制条件
- 相关背景资料
- 代码片段 / 检索结果
- 最近执行反馈
- 当前待执行动作
七、Prompt Engineering 和 Context Engineering 的关系
这两个概念容易混淆,但关系其实很清楚:
Prompt Engineering 是 Context Engineering 的一部分。
可以这样理解:
- Prompt Engineering:聚焦于"如何设计输入指令"
- Context Engineering:聚焦于"如何管理整轮输入环境"
换句话说:
- Prompt 是上下文的一部分
- 提示词工程是上下文工程中的一个局部能力
- 但上下文工程的范围更大,涉及检索、压缩、记忆、组装、注入、裁剪等整套机制
所以如果只会写 Prompt,而不会做上下文管理,那么 AI 应用能力很快就会遇到天花板。
八、Agent 是什么
8.1 Agent 的本质
Agent 不是一个"更会聊天"的模型,而是:
大模型 + 工具能力 + 循环执行机制
也就是说,Agent 不只是回答问题,而是可以:
- 读取文件
- 调用命令行
- 执行测试
- 操作代码
- 调用外部 API
- 使用 MCP 或其他工具系统
- 根据反馈继续下一步动作
8.2 Agent 的工作循环
一个典型 Agent 往往会进入这样的循环:
- 理解目标
- 规划下一步
- 调用工具执行
- 获取反馈结果
- 将反馈结果重新写入上下文
- 继续下一轮判断与执行
这就是典型的:
Think → Act → Observe → Reflect → Continue
也就是"思考---行动---观察---调整"的闭环。
九、为什么 Agent 一定依赖上下文工程
Agent 一旦进入循环,就会持续产生新信息:
- 读到的文件内容
- 修改后的代码
- 编译输出
- 测试结果
- 报错信息
- 环境状态
- 子任务进度
这些信息如果处理不好,就会迅速把上下文挤满。
于是 Agent 系统很快就会面临两个典型问题:
9.1 上下文持续膨胀
任务越长,读的内容越多,模型看到的信息越复杂。
9.2 任务目标持续漂移
如果没有稳定约束,模型会越来越容易:
- 忘记原始目标
- 忘记业务边界
- 忘记技术限制
- 忘记不要做什么
所以:
Agent 越强,越依赖高质量的上下文工程。
没有上下文工程,Agent 只是一个很快会失控的执行循环。
十、规则文件、记忆层与长期约束
为了解决长任务里的目标漂移问题,一个非常关键的做法是:
把长期有效、可复用的核心信息,独立沉淀为规则文件或记忆层。
这些规则通常包括:
- 项目目标
- 技术栈
- 架构约束
- 代码风格
- 测试要求
- 禁止事项
- 交付规范
- 安全边界
在很多 AI Coding 工具里,这类内容通常会以类似以下形式存在:
- rules 文件
- project memory
- instruction files
- system constraints
- repo-level guidance
它们的核心作用是:
无论任务怎么演进,都为模型持续提供一个稳定锚点。
10.1 为什么规则文件很重要
因为上下文腐化通常不是突然发生的,而是在多轮执行后慢慢累积的。
如果每一轮调用时,系统都能自动重新注入这些高优先级约束,那么模型就更不容易偏离主航道。
10.2 规则文件也不能无限变长
但规则文件本身如果过长,也会反过来挤占上下文预算。
所以更合理的工程做法通常是:
- 按主题拆分文件
- 使用索引或路由方式按需加载
- 让高频核心规则常驻
- 让低频细节规则延迟注入
例如可以拆成:
product.mdstack.mdcoding-style.mdconstraints.mddelivery.md
这本质上也是上下文工程的一部分。
十一、为什么 Agent 还不够:必须上升到 Harness Engineering
很多文章会把 AI 应用开发直接等同于"做一个 Agent",但这其实还不够准确。
11.1 Agent 更像执行形态,不是完整工程体系
Agent 强调的是:
- 模型会规划
- 模型会调用工具
- 模型会循环执行
但如果只有 Agent,而没有长期记忆、上下文治理、规则注入、反馈控制和任务编排,那么系统很容易出现:
- 一直试错但不收敛
- 能执行但容易跑偏
- 会调工具但不知道什么时候停
- 改代码很快,但越改越乱
因此,Agent 更像是一种"执行模式",而不是完整的软件工程方法。
11.2 Harness Engineering 才是上层完整方法
Harness Engineering 比 Agent 多出来的关键点在于:
- 它强调长期规则和稳定记忆
- 它强调上下文不是自然出现,而是要动态治理
- 它强调执行之后必须有反馈回路
- 它强调整个系统需要编排、验收和终止条件
- 它强调交付质量,而不只是动作数量
所以更准确的关系是:
Agent 是 Harness Engineering 里的执行核心之一,但 Harness Engineering 的范围比 Agent 更大。
十二、Harness Engineering 到底是什么
讲到这里,就可以正式给出这篇文章最核心的定义。
12.1 定义
Harness Engineering,可以理解为:
围绕大模型构建一层工程化"驾驭外壳",把模型接入规则、上下文、工具、反馈、记忆和编排机制,最终让模型从"会回答"变成"能稳定完成任务并交付结果"。
这里的 Harness,可以把它理解成"束具、控制装置、工程外壳、驾驭系统"。
如果说大模型像一个能力很强但不稳定的"认知内核",那么 Harness Engineering 做的事情就是:
- 给它明确边界
- 给它持续输入正确信息
- 给它调用工具的能力
- 给它任务执行流程
- 给它反馈闭环
- 给它长期记忆锚点
- 给它结束条件和验收标准
也就是说,Harness Engineering 不是单点技术,而是一整套围绕模型构建"可控生产力"的工程方法。
12.2 它和 Prompt Engineering、Context Engineering、Agent 的关系
可以这样理解:
- Prompt Engineering:解决"怎么把要求说清楚"
- Context Engineering:解决"怎么把对的信息送进去"
- Agent:解决"怎么让模型调用工具持续行动"
- Harness Engineering:解决"怎么把这些能力整合成一个可控、可交付、可迭代的完整系统"
所以 Harness Engineering 的范围最大。它不是 Prompt 的同义词,也不是 Agent 的别名,而是:
把 Prompt、Context、Memory、Tools、Feedback、Orchestration 这些能力统一组织起来的上层工程方法。
12.3 为什么它才是 AI 应用开发真正的主战场
因为真实世界里的 AI 应用,几乎都不是"一问一答"这么简单。
只要任务涉及下面任意一项,就已经进入 Harness Engineering 范畴:
- 长上下文
- 多轮交互
- 文件读取
- 代码修改
- 命令执行
- 数据库操作
- 外部 API 调用
- 自动测试
- 错误修复
- 任务拆解
- 多阶段交付
所以 AI 应用开发的本质,并不是"调用一个模型",而是:
围绕模型,构建一套工程化 harness,让模型在真实约束下持续工作并交付结果。
十三、Harness Engineering 的核心架构
如果从系统视角看,Harness Engineering 可以抽象成下面这套分层结构。
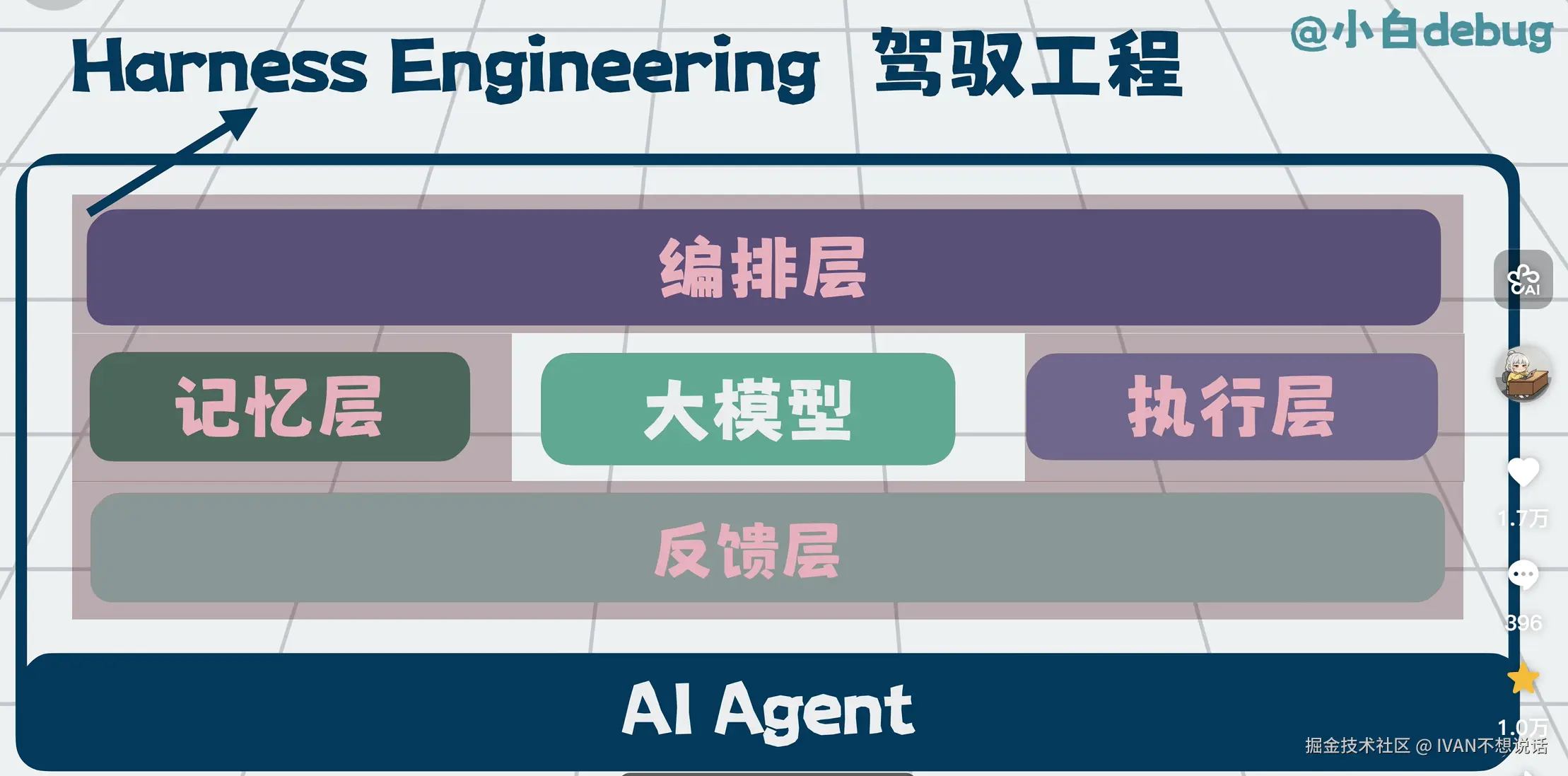
这张图表达的是:
- 编排层负责全局控制
- 记忆层提供长期稳定锚点
- 上下文构建层负责把最相关的信息送入模型
- 执行层负责真正干活
- 反馈层负责把执行结果回流给系统
- 模型是核心认知引擎,但不是整个系统本身
13.1 记忆层(Memory Layer)
负责长期稳定信息的沉淀与注入,例如:
- 项目背景
- 需求约束
- 技术栈
- 代码风格
- 安全规则
- 禁止事项
- 验收标准
它的核心作用是:
维持长期一致性,减少上下文腐化导致的任务偏移。
13.2 上下文构建层(Context Layer)
负责把模型当前最需要的信息组织出来。
它通常由三类动作组成:
- 召回:找相关信息
- 压缩:去掉噪音,保留关键点
- 组装:按优先级与结构送进模型
它的核心作用是:
让模型每一轮都尽量只看到"当前最相关、最关键、最可执行"的输入。
13.3 执行层(Execution Layer)
负责让模型具备"做事"的能力,而不是只会回答。
包括:
- 文件读写
- 命令行调用
- 测试执行
- API 请求
- MCP 工具调用
- 数据库 / SQL 操作
它的核心作用是:
把模型的推理结果转化为对外部世界的实际动作。
13.4 反馈层(Feedback Layer)
负责把真实执行结果重新送回系统,例如:
- 编译失败
- 测试失败
- 日志报错
- 接口返回异常
- 验收不通过
它的核心作用是:
形成"执行 - 观察 - 修复 - 再执行"的闭环。
13.5 编排层(Orchestration Layer)
负责统一调度其他各层,并决定:
- 当前目标是什么
- 子任务怎么拆
- 先做什么后做什么
- 哪一步算完成
- 什么情况下终止
- 什么情况下回退
它的核心作用是:
保证整个 Harness 不是盲目循环,而是目标明确、路径可控、结果可验收。
十四、为什么同样的模型,不同 AI 工具效果差异很大
这是实际使用中最常见的现象之一。
同样一个底层模型,放到不同工具里,效果往往差别很大。原因通常包括:
13.1 提示词体系不同
不同工具会有不同的系统提示词、默认规则、输出约束。
13.2 上下文召回机制不同
有的工具更擅长找相关文件,有的工具更容易召回噪音。
13.3 压缩策略不同
有的工具能保留关键约束,有的工具压缩后容易丢失核心信息。
13.4 组装逻辑不同
信息顺序、优先级、插入方式,都会影响模型理解。
13.5 工具能力不同
有的工具会跑测试、会读项目结构、会解析错误栈;有的不会。
13.6 编排层成熟度不同
有的系统知道怎么拆任务、怎么回退、怎么控制范围;有的系统只会线性试错。
因此,所谓"AI 工具体验差异",本质上往往是工程差异,而非纯模型差异。
十四、程序员以后是不是就不用写代码了
结论是否定的。
更准确地说,程序员的工作重心会发生迁移。
14.1 以前程序员更强调
- 手写实现
- 手工调试
- 手工查文档
- 手工写测试
- 手工定位问题
14.2 以后程序员会更强调
- 任务拆解能力
- 规则设计能力
- 上下文设计能力
- 验收标准定义能力
- 自动化反馈闭环设计能力
- 工程编排能力
- 风险识别与边界控制能力
也就是说:
代码不会消失,但"亲自写每一行代码"不再是唯一核心竞争力。
真正重要的,是你能不能把 AI 驾驭成一个可靠的工程执行系统。
十五、如何在项目里落地
如果要把这些理念落到真实研发流程中,可以从以下几个方向入手。
15.1 先写规则文件
先把以下内容沉淀下来:
- 项目目标
- 产品背景
- 技术栈
- 架构边界
- 禁止事项
- 代码风格
- 测试要求
- 发布要求
这些内容尽量结构化、可读、可维护。
15.2 做任务分阶段
不要直接把一个大需求整包丢给 Agent。
更好的方式是拆成阶段:
- 理解需求
- 明确边界与约束
- 生成开发计划
- 拆分子任务
- 修改代码
- 执行测试
- 修复问题
- 输出交付总结
15.3 把验证标准前置
提前告诉系统:
- 必须通过哪些单测
- 必须通过哪些 lint
- 哪些目录不能动
- 哪些 SQL 不能执行
- 哪些接口兼容性必须保持
让模型一开始就明确什么叫"做完了"。
15.4 建立反馈闭环
不要让 Agent 只会"生成内容",要让它能:
- 执行
- 观察
- 获取反馈
- 再修复
这样它才真正具备工程价值。
15.5 控制上下文预算
规则文件、历史记录、检索结果都要做分层管理。
不要什么都全量加载,而应该:
- 高频规则常驻
- 中频规则按需加载
- 低频材料检索后再注入
这会极大提升稳定性。
十六、几个常见误区
误区一:Prompt 越长越好
不对。
更准确地说:
Prompt 不是越长越好,而是越清晰、越相关、越结构化越好。
过长的 Prompt 可能会引入噪音和冲突信息。
误区二:上下文越多越好
也不对。
上下文不是越多越好,而是:
越相关越好。
无关内容、重复内容、低质量摘要,都会污染模型判断。
误区三:有了 Agent 就不用管过程
实际上正好相反。
Agent 越强,越需要:
- 明确边界
- 控制范围
- 设定终止条件
- 做反馈验证
- 防止死循环
误区四:模型强了,外壳就不重要了
模型越强,外壳可以更薄,但永远不会消失。
因为只要任务涉及:
- 多轮执行
- 外部工具
- 长上下文
- 真实交付
就一定需要工程外壳。
十七、一个最好记的总结框架
如果要把整篇文章压缩成最容易记忆的一版,可以记下面这组关系:
17.1 一句话版
- 提示词工程解决"怎么说清楚"
- 上下文工程解决"给模型看什么、怎么给"
- Agent解决"怎么让模型调用工具持续行动"
- Harness Engineering解决"怎么把这些能力整合成可控、可交付的完整工程系统"
17.2 包含关系版
Prompt Engineering ⊂ Context Engineering ⊂ Harness Engineering
而 Agent 更适合作为 Harness Engineering 中的执行形态来理解。
17.3 本质版
AI 应用开发的本质,不是调用模型,而是:
围绕模型构建一个可约束、可记忆、可执行、可反馈、可编排的 harness。
结语
今天再看 AI 开发,真正重要的已经不再只是"会不会写 Prompt",而是你能不能把模型放进一个靠谱的工程系统里,让它在真实约束下持续工作、持续修复、持续交付。
模型决定上限,工程决定落地效果。
未来的竞争,很大程度上不只是"谁有更强的模型",而是谁更懂得如何构建那层包裹模型的工程外壳。
而对程序员来说,这也意味着新的主战场已经很清晰了:
- 不是只做代码生成的旁观者
- 而是做 AI 工程系统的设计者、约束者、编排者和验收者
这,才是 AI 时代真正值得深入掌握的能力。