多模态数据AI展示系统设计与实现
附录A 项目展示截图
A.1 登录页
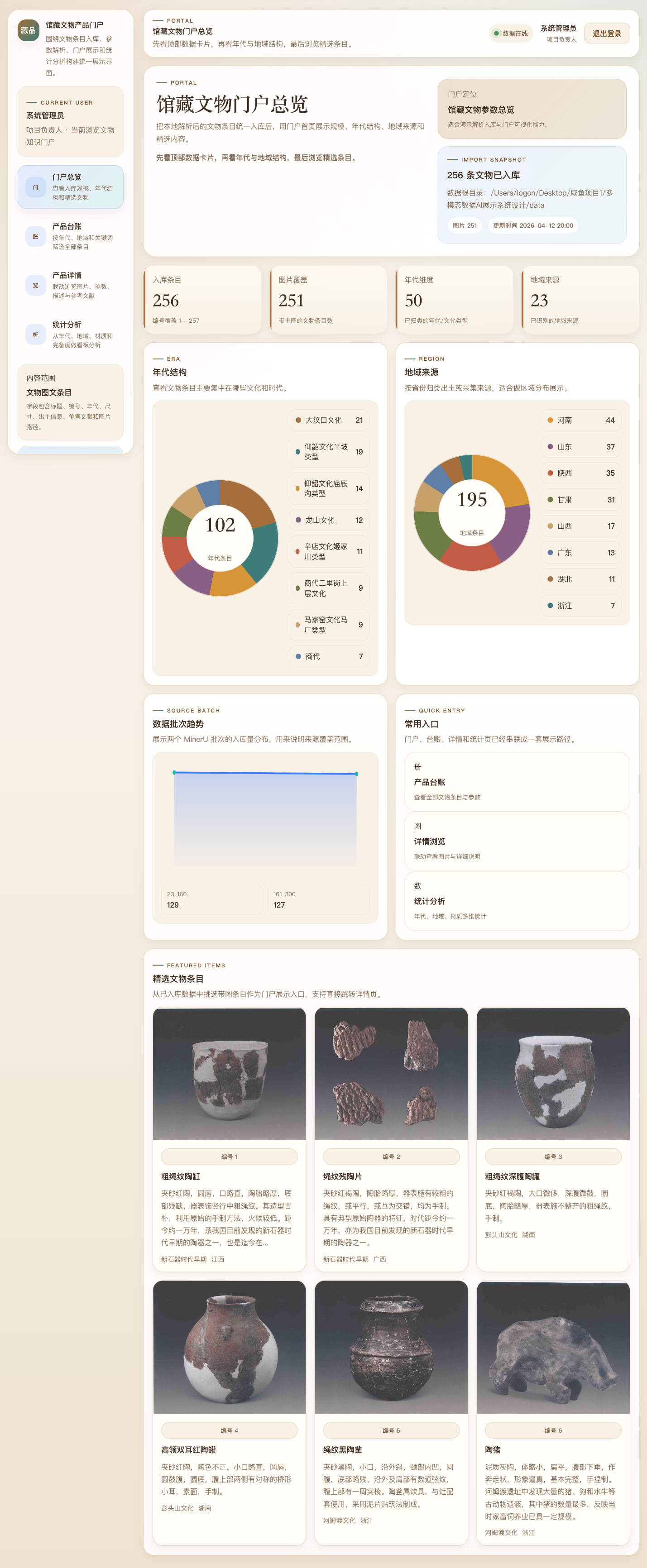
A.2 门户总览
A.3 产品台账

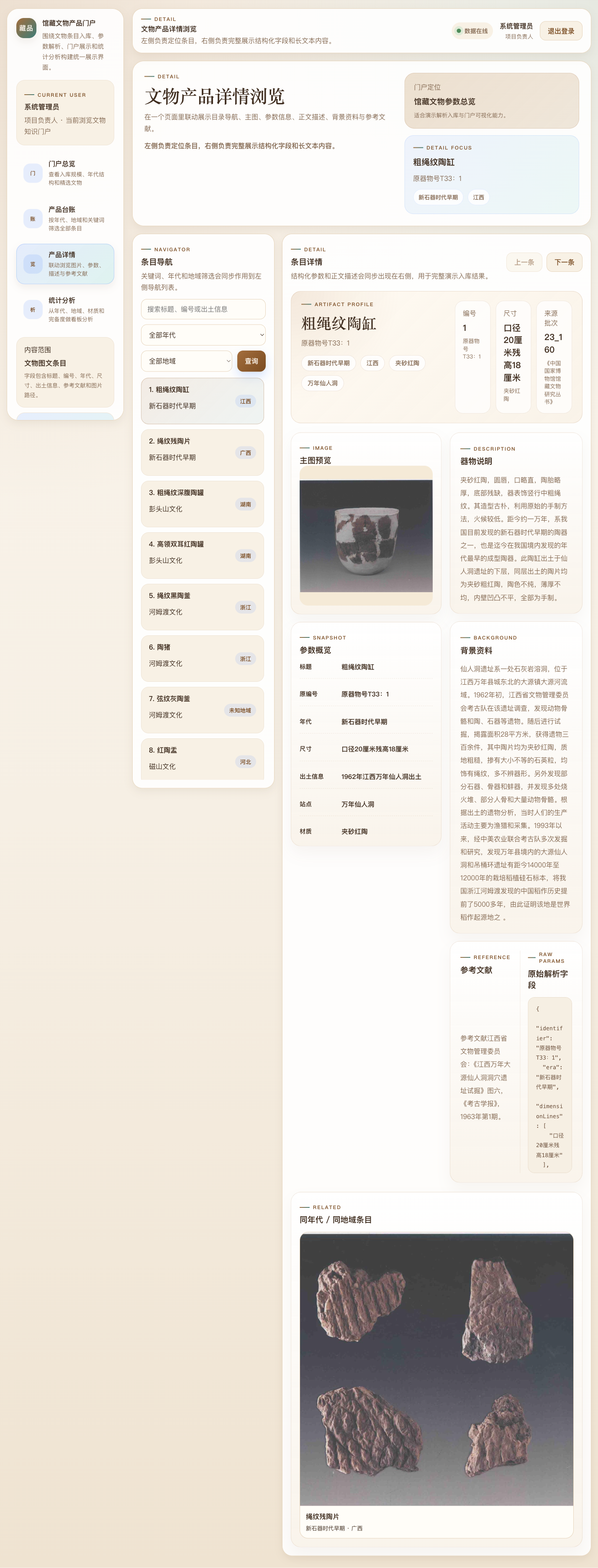
A.4 产品详情
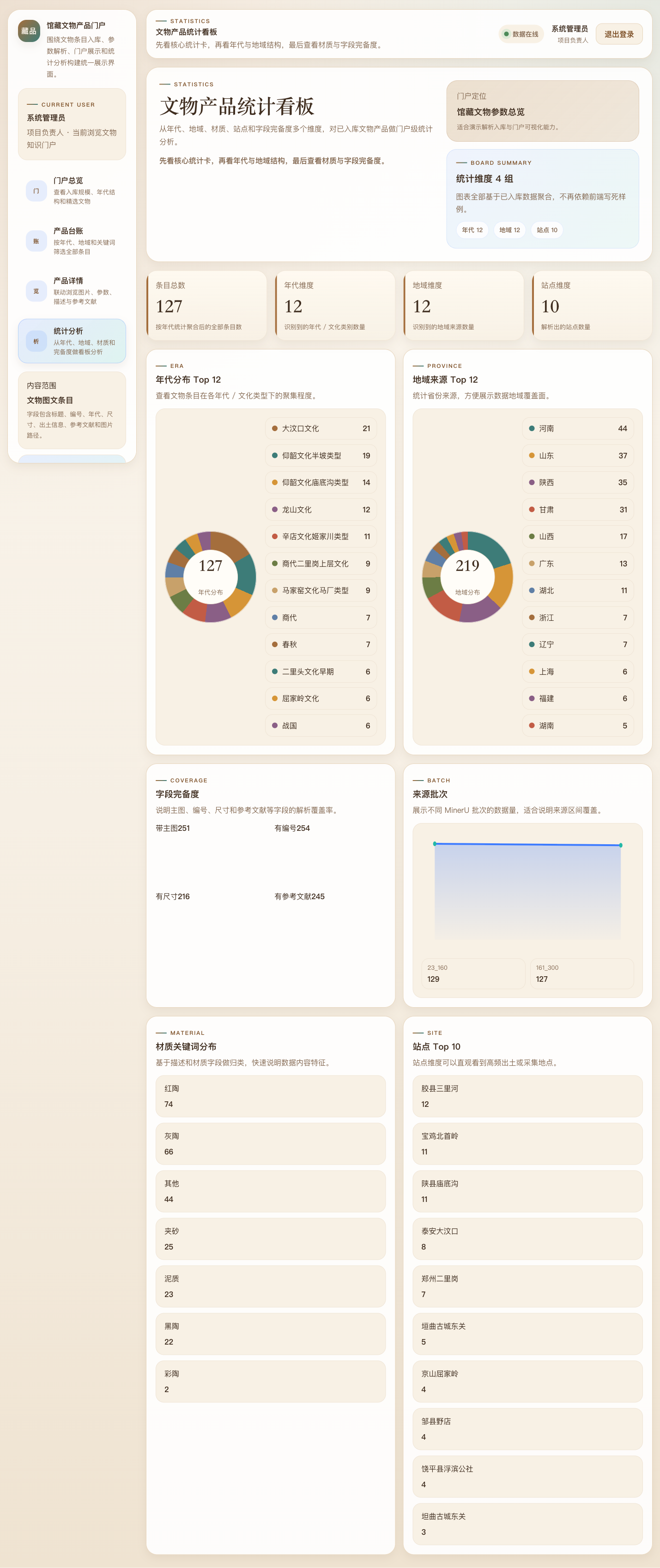
A.5 统计分析
论文大纲(可审阅版)
第1章 绪论(约 2500~3200 字)
- 研究背景、研究意义、国内外现状、研究内容、论文结构
- 图表:研究问题拆解表、论文结构图
第2章 需求分析(约 3000~3800 字)
- 业务背景、角色与场景、功能需求、非功能需求、可行性分析
- 图表:业务流程图、用例图、需求优先级矩阵、非功能指标表
第3章 关键技术与理论基础(约 2600~3400 字)
- Spring Boot、Vue3、MySQL、REST、文件上传与权限控制、图表可视化
- 图表:技术选型对比表、技术栈分层图
第4章 系统总体设计(约 3200~4200 字)
- 设计目标、总体架构、模块划分、接口设计、部署设计
- 图表:系统架构图、模块关系图、核心时序图、接口清单表
第5章 数据库设计(约 2500~3500 字)
- 概念模型、逻辑模型、表结构、约束与索引、数据初始化策略
- 图表:ER 图、核心表字段说明表
第6章 系统详细设计与实现(约 4200~5600 字)
- 登录注册、台账列表、详情浏览、上传重传、质量审核、统计看板实现
- 图表:关键流程时序图、页面功能映射表、关键代码逻辑说明表
第7章 系统测试与结果分析(约 3000~4200 字)
- 测试环境、测试方案、功能测试、接口性能测试、兼容性测试、问题修复
- 图表:测试流程图、功能测试用例表、性能统计表、缺陷修复表
第8章 部署与运行维护(约 1800~2600 字)
- 部署流程、Windows 一键部署脚本、日志与备份、运维建议
- 图表:部署流程图、运维检查清单表
第9章 总结与展望(约 1400~2200 字)
- 工作总结、创新点、不足、未来优化方向
- 图表:改进路线图
附录
- 系统截图、接口响应样例、测试原始记录、参考文献
摘要
随着数字化建设与人工智能技术的发展,多源异构数据在文化展示、教育科研、内容生产和公共服务场景中的应用不断深化。传统数据管理系统往往围绕单一模态进行设计,导致文本、图像、音频、视频等数据在采集、标注、管理、审核和展示阶段存在流程割裂、标准不统一、复用效率低的问题。针对上述问题,本文围绕"多模态数据AI展示系统"展开设计与实现,构建了一个面向多模态标注成果汇聚、浏览、统计分析与质量管控的一体化平台,并在此基础上扩展馆藏文物门户展示能力,实现"数据管理链路"和"展示服务链路"的统一。
系统采用前后端分离架构,后端基于 Spring Boot 构建 RESTful 服务,前端基于 Vue 3 + TypeScript 实现多页面交互界面,数据层使用 MySQL 持久化管理。系统在功能上覆盖用户登录注册、角色识别、资产台账管理、详情联动浏览、审核流转、统计分析、目录检索及媒体访问等核心能力。根据源码与接口统计,后端共实现 6 个控制器、17 个业务接口;数据库设计包含用户、资产、标注结果、审核记录、版本记录、文物条目 6 张核心业务表。前端提供登录页与 4 个核心业务页面(门户总览、产品台账、产品详情、统计分析),并结合真实数据实现筛选、分页、图表可视化和详情联动。
在验证方面,本文基于本地运行环境对关键接口进行多轮采样测试。结果表明,在开发环境下各主要接口平均响应时间处于毫秒级,系统能够稳定支撑当前样本规模下的查询与展示任务。以目录数据为例,系统已完成 256 条文物条目入库,其中 251 条具备主图,支持 50 个年代维度与 23 个地域维度的统计分析。测试结果验证了系统在功能完整性、可用性与可展示性方面达到预期目标。
本文的主要贡献体现在三个方面:第一,完成了多模态数据管理与展示一体化系统的工程化实现;第二,建立了面向"汇聚---浏览---分析---质检---展示"的闭环业务流程;第三,形成了可复用的系统设计方案、数据库模型与测试方法,为后续扩展更大规模数据处理、引入智能检索和自动质检策略提供了基础。
关键词:多模态数据;Spring Boot;Vue 3;MySQL;数据可视化;质量管控
Abstract
With the rapid development of digital transformation and AI technologies, multimodal data has become a key production factor in cultural presentation, educational services, and intelligent content management. However, many traditional systems are still designed for a single modality, resulting in fragmented workflows across text, image, audio, and video data processing. To address this issue, this thesis designs and implements a multimodal AI display system that integrates data aggregation, browsing, statistical analysis, and quality control into one unified platform.
The system adopts a front-end/back-end separation architecture. The back-end is implemented with Spring Boot and exposes RESTful APIs. The front-end is built on Vue 3 and TypeScript to provide interactive pages. MySQL is used for persistent storage. Functionally, the system supports user authentication, role-aware access control, multimodal asset management, detailed content browsing, review workflow processing, statistical dashboards, catalog retrieval, and media serving. Based on source code and endpoint statistics, the system contains 6 controllers and 17 APIs, and the database includes 6 core tables for users, assets, annotations, reviews, versions, and catalog records.
For validation, this thesis performs functional and interface-level tests in a local development environment. The measured results show millisecond-level response time for key APIs and stable operation under current data volume. The catalog module has imported 256 records, including 251 records with cover images, and supports 50 era dimensions and 23 province dimensions for analysis and visualization. The experimental results demonstrate that the system meets expected goals in terms of completeness, usability, and demonstrability.
The key contributions of this work are as follows: (1) implementation of an engineering-ready multimodal data management and presentation platform; (2) construction of a closed-loop business process covering aggregation, browsing, analysis, review, and presentation; (3) provision of reusable design artifacts including architecture, database schema, and testing methodology, which can support future extension toward larger-scale data and intelligent quality inspection.
Keywords: Multimodal Data; Spring Boot; Vue 3; MySQL; Data Visualization; Quality Control
第1章 绪论
1.1 研究背景
近年来,随着大模型、多模态感知与知识服务的快速发展,文本、图像、音频、视频等异构数据在政务、教育、文博、工业与商业领域的应用不断拓展。相比单模态信息,多模态数据具有信息密度高、表达维度丰富、可解释性强等优势,但也带来数据组织复杂、标准不一致、质量控制难度高等问题。尤其在"数据标注---审核---展示"全链路场景中,如果系统建设仅关注单个环节,常会出现如下问题:
- 数据入口分散,上传格式和字段约束不统一,导致后续统计困难;
- 审核流程缺乏版本留痕,质量问题难以追溯;
- 展示端与管理端割裂,前端展示价值无法反哺数据治理;
- 统计指标不成体系,难以支撑管理决策与成果汇报。
在文化遗产数字化场景中,上述矛盾更为突出。文物条目通常具有复杂文本描述、图片资源、来源信息与参考文献,若缺乏统一的数据结构和可视化入口,难以形成高质量的公共展示与研究支撑。因此,构建一个兼具"管理能力"和"展示能力"的多模态数据系统具有现实价值。
1.2 研究意义
本文的研究意义可从理论与实践两方面展开。
(1)理论意义:
通过将多模态数据管理、质量审核、统计分析和展示门户整合到同一系统,本文给出了一种适用于中小规模数据治理场景的工程化实现路径。该路径强调"业务闭环"与"可复核指标",可为同类系统设计提供参考框架。
(2)实践意义:
本文系统在可部署、可演示、可扩展方面具有较强工程价值。系统能够支持真实样本数据入库与检索、实现审核流转和版本追踪,并通过图表与详情页展示数据价值。对于课程项目、原型验证和系统展示场景,该方案具有较高复用性。
1.3 国内外研究现状(概述)
国外在数据平台建设方面起步较早,形成了以数据仓库、数据湖和知识图谱为核心的多类技术体系。近年来,随着 AIGC 与多模态模型发展,平台能力逐步从"存储管理"扩展到"智能理解与生成"。在开源生态中,前后端分离与 API 驱动模式成为主流,强调可扩展与可插拔。
国内在智慧文博、数字档案、智能内容平台等领域发展迅速,围绕"采集---治理---展示"的系统建设日趋完善。多数项目在展示效果方面进展明显,但在跨模态一致性、审核标准化、版本可追溯方面仍有优化空间。特别是中小型项目中,常见问题是"功能齐全但链路不闭环""页面丰富但数据结构不稳定"。
结合当前趋势可以看出:未来系统建设将更加关注"统一数据模型 + 统一流程控制 + 统一展示接口",并逐步引入自动化质检与语义检索能力。本文正是在这一趋势下开展工程实践。
1.4 研究目标与研究内容
1.4.1 研究目标
本文拟实现一个可运行、可演示、可复核的多模态数据AI展示系统,满足以下目标:
- 完成多模态资产统一管理,实现文本、图像、音频、视频数据的汇聚与检索;
- 建立审核与版本追踪机制,支持质量管控与问题回溯;
- 提供统计分析能力,形成可视化看板;
- 搭建文物目录门户,实现条目台账、详情联动与统计展示;
- 完成系统测试并形成可复现的实验数据与结论。
1.4.2 研究内容
围绕上述目标,本文主要开展以下工作:
- 需求分析:梳理角色、场景、流程与指标;
- 架构设计:完成前后端分离架构与模块边界设计;
- 数据库设计:建立 6 张核心表并定义约束关系;
- 功能实现:完成认证、资产、审核、统计、目录等功能;
- 测试评估:开展功能测试、接口性能采样和兼容性验证;
- 文档沉淀:输出论文、截图文档和部署说明。
1.5 论文组织结构
第1章 绪论
第2章 需求分析
第3章 关键技术
第4章 总体设计
第5章 数据库设计
第6章 详细实现
第7章 系统测试
第8章 部署运维
第9章 总结展望
1.6 本章小结
本章明确了研究背景、意义、目标与内容,说明了本文聚焦"多模态管理+展示门户"的系统化实现,并给出论文整体结构。后续章节将依次展开需求、设计、实现与测试。
待用户确认点
- 论文层次是否按"本科"保持不变;
- 题目是否使用"多模态数据AI展示系统设计与实现";
- 学校是否有指定章节命名与摘要格式模板。
第2章 需求分析
2.1 业务背景与问题定义
本项目以多模态标注成果与馆藏文物目录数据为对象,目标是形成从数据入库到门户展示的闭环能力。根据项目文档与源码,系统业务可抽象为两条主链路:
- 链路A(管理链路):成果汇聚 → 资产管理 → 审核流转 → 版本追踪 → 统计分析;
- 链路B(展示链路):目录入库 → 台账检索 → 详情浏览 → 图表展示。
两条链路共享统一数据层与接口层。通过这种设计,系统既可面向管理员开展质量治理,也可面向展示场景输出可视化能力。
2.2 角色分析
系统当前定义两类业务角色:
| 角色 | 权限范围 | 典型任务 |
|---|---|---|
| 管理员(项目负责人) | 全量数据访问、审核决策、统计总览 | 查看全站资产、处理审核、查看全站看板 |
| 普通用户 | 自有数据管理与查看 | 上传资产、查看我的资产、查看授权内容 |
系统通过登录信息中的 roleName 完成前端路由守卫与后端范围过滤,确保角色可见性控制。
2.3 功能需求分析
2.3.1 功能模块拆解
| 模块 | 需求描述 | 对应实现 |
|---|---|---|
| 用户认证 | 提供登录与注册能力 | /api/auth/login、/api/auth/register |
| 资产管理 | 提供资产列表、详情、上传、重传、删除 | /api/assets/* |
| 审核管理 | 提供审核队列与审核决策 | /api/reviews/pipeline、/api/reviews/{id}/decision |
| 统计分析 | 提供模态、状态、质量、工作量统计 | /api/statistics/panel、/api/dashboard/overview |
| 目录门户 | 提供目录总览、列表、详情、统计、媒体访问 | /api/catalog/* |
2.3.2 业务流程
通过
退回
用户上传/提交数据
资产台账入库
生成标注结果记录
进入审核队列
状态变更为已完成
状态变更为已退回
统计看板聚合
重传修订
门户与报表展示
2.3.3 用例图(文本化表达)
管理员
查看全站概览
审核决策
查看统计看板
管理资产
普通用户
登录注册
上传资产
查看我的资产
浏览目录与详情
2.4 非功能需求分析
| 非功能维度 | 指标描述 | 目标 |
|---|---|---|
| 可用性 | 核心页面可正常访问,功能闭环可执行 | 功能流程完整可演示 |
| 性能 | 常用查询与统计接口响应稳定 | 毫秒级到百毫秒级(开发环境) |
| 可维护性 | 模块边界清晰,前后端职责明确 | 控制器与服务层分离 |
| 可扩展性 | 支持新增模态、字段、图表 | 通过数据库扩展字段与新接口 |
| 安全性 | 基础鉴权、角色访问控制、参数校验 | 避免越权访问与非法参数 |
| 兼容性 | 多浏览器可访问,响应式展示 | Chrome/Edge/Firefox 可用 |
2.5 可行性分析
2.5.1 技术可行性
项目采用成熟技术栈:Spring Boot 负责服务接口,Vue 3 负责前端交互,MySQL 负责数据持久化,技术生态完善、学习成本可控、开发效率高。已有工程已完成基础骨架与核心模块,因此进一步扩展风险可控。
2.5.2 经济可行性
系统以开源技术为主,开发环境依赖成本低。部署可在普通实验室或个人电脑完成,对硬件资源要求中等,不依赖高额商业授权。
2.5.3 操作可行性
系统页面结构清晰,提供登录后统一导航。用户可通过台账筛选、详情浏览和统计图表快速完成主要任务。对非技术人员也具备较低使用门槛。
2.6 需求优先级矩阵
| 需求项 | 业务价值 | 实现复杂度 | 优先级 |
|---|---|---|---|
| 登录注册与角色控制 | 高 | 低 | P0 |
| 资产上传与列表管理 | 高 | 中 | P0 |
| 审核队列与决策 | 高 | 中 | P0 |
| 统计看板 | 中高 | 中 | P1 |
| 目录详情联动 | 中高 | 中 | P1 |
| 导出报表能力 | 中 | 中 | P2 |
| 自动化质检与智能检索 | 高 | 高 | P3(后续) |
2.7 本章小结
本章从角色、流程、功能与非功能四个层面完成需求分析,明确了系统"管理+展示"双主线目标,并给出需求优先级,为后续技术选型和架构设计提供依据。
待用户确认点
- 是否需要在论文中加入"第三类角色(游客)"设定;
- 是否要求补充"移动端专项需求";
- 是否要求将"自动化质检"作为本次实现内容而非展望内容。
第3章 关键技术与理论基础
3.1 Spring Boot 后端开发框架
Spring Boot 通过自动配置和约定优于配置机制,降低了 Java Web 项目的搭建复杂度。本文后端采用 Spring Boot 3.3.5 作为基础框架,结合 spring-boot-starter-web、spring-boot-starter-jdbc 与 spring-boot-starter-validation 实现接口开发、数据库访问与参数校验。
在工程结构上,系统采用 Controller + Service 分层:
- Controller 层负责接收请求、参数绑定与响应包装;
- Service 层负责业务逻辑、查询聚合与流程控制;
- 数据访问层基于
JdbcTemplate实现,便于快速构建 SQL 驱动型业务。
这种结构在中小型系统中具有实现成本低、可读性好、调试方便等优势。
3.2 Vue 3 + TypeScript 前端技术
前端采用 Vue 3 组合式 API 开发页面逻辑,配合 TypeScript 提升静态类型约束能力。通过 Vue Router 实现页面导航与路由守卫,确保未登录用户不可访问业务页面。
系统页面围绕"登录、总览、台账、详情、统计"展开,具备以下特征:
- 组件化设计:图表组件、布局组件复用;
- 响应式布局:适配不同分辨率;
- 数据驱动渲染:接口返回直接映射页面视图;
- 交互反馈明确:筛选、分页、空状态展示清晰。
3.3 MySQL 数据库技术
MySQL 是本系统数据持久化核心,负责存储用户、资产、审核、版本与目录条目数据。本文采用关系模型组织结构化字段,通过主键、外键和唯一约束保证数据一致性。
在目录展示场景中,artifact_item 表承担中心作用,字段覆盖标题、编号、年代、尺寸、地域、材质、描述、参考文献、图片路径等信息,支撑列表与详情联动显示。
3.4 RESTful API 设计思想
系统接口遵循 REST 风格,核心特征如下:
- 资源化路径命名,如
/api/assets、/api/catalog/items; - 使用 HTTP 动词表达操作语义(GET、POST、DELETE);
- 返回统一响应结构:
code、message、data; - 前后端通过 JSON 进行数据交换,降低耦合度。
3.5 文件上传与资源访问机制
系统支持多模态文件上传,后端通过 multipart 处理文件流并落盘保存,数据库记录资源路径。对于目录图像资源,系统提供 /api/catalog/media 接口按相对路径读取文件并输出资源流,完成"数据库元数据 + 文件系统资源"的组合访问模式。
该模式避免将大文件直接存入数据库,提高检索效率与维护灵活性。
3.6 数据可视化与导出技术
系统前端通过自定义图表组件展示环形图、趋势图与统计卡片,支持对年代、地域、材质、站点等维度进行聚合展示。项目还集成 CSV/Excel/PDF 导出工具(xlsx、jspdf、jspdf-autotable),可扩展统计报表输出能力。
3.7 技术栈分层图
Data
Backend
Frontend
Vue3
TypeScript
Vue Router
Vite
Spring Boot
JDBC Template
Validation
MySQL
File Storage
3.8 本章小结
本章阐述了系统实现涉及的核心技术及其选择依据。通过成熟稳定的技术组合,系统能够在开发效率、可维护性与可扩展性之间取得平衡。
待用户确认点
- 是否需要在论文中增加"与 Python/FastAPI 方案对比";
- 是否要求补充"消息队列与缓存"作为扩展技术说明;
- 是否需要加入"前端状态管理方案(Pinia)"的后续设计建议。
第4章 系统总体设计
4.1 设计目标与原则
系统总体设计遵循以下原则:
- 业务闭环原则:覆盖"汇聚---浏览---分析---质检---展示"全流程;
- 前后端解耦原则:通过 API 协议驱动页面渲染;
- 数据一致性原则:统一主键、外键、状态字段与审计字段;
- 可扩展原则:支持新增模态、统计维度和页面模块;
- 可复核原则:关键流程和指标可通过接口与数据库验证。
4.2 总体架构设计
浏览器用户
Vue3 前端
Spring Boot API 层
认证与会话服务
资产与审核服务
目录与统计服务
MySQL
上传文件目录
目录数据目录
该架构中,前端只负责交互与展示,不直接访问数据库;后端统一处理权限、查询和聚合逻辑;数据库与文件系统分别负责结构化与非结构化数据存储。
4.3 模块划分设计
| 层级 | 模块 | 核心职责 |
|---|---|---|
| 前端展示层 | LoginView | 登录与注册交互 |
| 前端展示层 | DashboardView | 门户总览、指标卡片、精选条目 |
| 前端展示层 | AssetsHubView | 台账筛选与分页列表 |
| 前端展示层 | BrowseView | 详情联动、参数与正文展示 |
| 前端展示层 | StatisticsView | 多维统计与图表展示 |
| 后端接口层 | AuthController | 登录注册接口 |
| 后端接口层 | AssetController | 资产 CRUD 与上传处理 |
| 后端接口层 | ReviewController | 审核队列与决策提交 |
| 后端接口层 | DashboardController | 总览数据聚合 |
| 后端接口层 | StatisticsController | 统计面板数据聚合 |
| 后端接口层 | CatalogController | 目录查询与媒体访问 |
4.4 核心流程时序设计
4.4.1 登录流程时序图
MySQL AuthController 前端登录页 用户 MySQL AuthController 前端登录页 用户 输入用户名密码 POST /api/auth/login 查询 sys_user 用户记录 token + 用户信息 跳转到 /dashboard
4.4.2 目录台账查询流程
artifact_item CatalogService CatalogController 台账页面 artifact_item CatalogService CatalogController 台账页面 GET /api/catalog/items?page&filters listItems(keyword, era, province) 条件查询+分页 records + total + options 组装响应数据 records/page/filters
4.4.3 资产上传与审核流转
文件目录 MySQL AnnotationService AssetController 前端上传页 上传用户 文件目录 MySQL AnnotationService AssetController 前端上传页 上传用户 选择文件并提交 POST /api/assets/upload uploadAsset(...) 写入文件 插入 annotation_asset 插入 annotation_result 插入 asset_version 保存成功 上传结果 返回资产ID与状态
4.5 接口清单设计
根据源码统计,系统共 17 个接口,见表 4-1。
| 编号 | 方法 | 路径 | 说明 |
|---|---|---|---|
| 1 | POST | /api/auth/login |
用户登录 |
| 2 | POST | /api/auth/register |
用户注册 |
| 3 | GET | /api/assets |
资产列表 |
| 4 | GET | /api/assets/mine |
我的资产 |
| 5 | GET | /api/assets/{id} |
资产详情 |
| 6 | POST | /api/assets/upload |
资产上传 |
| 7 | POST | /api/assets/{id}/reupload |
资产重传 |
| 8 | DELETE | /api/assets/{id} |
资产删除 |
| 9 | GET | /api/reviews/pipeline |
审核队列 |
| 10 | POST | /api/reviews/{assetId}/decision |
审核决策 |
| 11 | GET | /api/dashboard/overview |
业务总览 |
| 12 | GET | /api/statistics/panel |
统计看板 |
| 13 | GET | /api/catalog/overview |
目录总览 |
| 14 | GET | /api/catalog/items |
目录列表 |
| 15 | GET | /api/catalog/items/{id} |
目录详情 |
| 16 | GET | /api/catalog/statistics |
目录统计 |
| 17 | GET | /api/catalog/media |
媒体资源访问 |
4.6 安全与异常设计
系统当前采用轻量化安全策略:
- 登录后返回 token,并在前端本地保存;
- 前端请求头附带用户信息,后端根据角色限制数据范围;
- 对注册、审核等输入参数采用校验注解;
- 全局异常处理器统一返回错误格式;
- CORS 配置控制跨域访问范围。
尽管当前已满足课程项目级需求,后续仍可引入 JWT 签名校验、RBAC 权限模型、审计日志与敏感字段脱敏策略。
4.7 部署架构设计
开发机/服务器
MySQL 8.x
Spring Boot 服务:8080
Vue 前端:5173
uploads 文件目录
data 目录
Windows 一键脚本
4.8 本章小结
本章完成了系统总体架构与模块边界设计,给出了核心时序、接口清单与部署关系,为数据库设计与详细实现章节奠定了完整工程框架。
待用户确认点
- 是否需要把"权限模型升级方案"写入主线章节;
- 接口清单是否需要扩展为"字段级输入输出表";
- 是否需要增加"时序图对应代码文件定位"附录。
第5章 数据库设计
5.1 数据库设计目标
数据库是系统的核心支撑层,其设计目标为:
- 支持多模态资产与目录条目的统一建模;
- 保证审核流程可追踪,满足版本历史留存;
- 提供高频查询字段,支撑筛选、分页与统计;
- 为后续扩展智能检索、自动化质检预留字段空间。
基于上述目标,系统采用关系数据库建模方式,实现"主实体 + 过程实体 + 展示实体"协同设计。
5.2 概念结构设计(ER 模型)
uploads
contains
reviewed_by
versioned_as
sys_user
bigint
id
PK
varchar
username
varchar
password
varchar
display_name
varchar
role_name
annotation_asset
bigint
id
PK
varchar
asset_code
varchar
asset_name
varchar
modality
varchar
status
decimal
quality_score
annotation_result
bigint
id
PK
bigint
asset_id
FK
varchar
category_name
varchar
region_type
json
attribute_json
varchar
review_status
review_record
bigint
id
PK
bigint
asset_id
FK
int
review_level
varchar
review_result
varchar
reviewer_name
asset_version
bigint
id
PK
bigint
asset_id
FK
int
version_no
varchar
operation_type
varchar
status_snapshot
artifact_item
bigint
id
PK
varchar
source_key
int
item_no
varchar
item_title
varchar
era
varchar
province
varchar
cover_image_path
该模型体现了两个核心设计思想:
其一,annotation_asset 作为流程中心实体,连接结果、审核、版本三类过程数据;
其二,artifact_item 独立承载目录展示语义,避免与标注流程耦合。
5.3 逻辑结构设计
5.3.1 用户表 sys_user
| 字段 | 类型 | 约束 | 说明 |
|---|---|---|---|
| id | BIGINT | PK, AUTO_INCREMENT | 用户主键 |
| username | VARCHAR(64) | UNIQUE, NOT NULL | 登录名 |
| password | VARCHAR(128) | NOT NULL | 登录密码(当前为明文示例) |
| display_name | VARCHAR(64) | NOT NULL | 展示名称 |
| role_name | VARCHAR(64) | NOT NULL | 角色名称 |
| created_at | DATETIME | NOT NULL | 创建时间 |
5.3.2 资产表 annotation_asset
| 字段 | 类型 | 约束 | 说明 |
|---|---|---|---|
| id | BIGINT | PK | 主键 |
| asset_code | VARCHAR(64) | UNIQUE | 资产编码 |
| asset_name | VARCHAR(128) | NOT NULL | 资产名称 |
| modality | VARCHAR(32) | NOT NULL | 模态类型(文本/图像/音频/视频) |
| source_path | VARCHAR(255) | NOT NULL | 源文件路径 |
| annotation_format | VARCHAR(64) | NOT NULL | 标注格式 |
| status | VARCHAR(32) | NOT NULL | 流程状态 |
| quality_score | DECIMAL(5,2) | DEFAULT 0 | 质量得分 |
| annotator_name | VARCHAR(64) | NOT NULL | 标注人 |
| reviewer_name | VARCHAR(64) | NULL | 审核人 |
| created_at | DATETIME | NOT NULL | 创建时间 |
| updated_at | DATETIME | NOT NULL | 更新时间 |
5.3.3 标注结果表 annotation_result
| 字段 | 类型 | 约束 | 说明 |
|---|---|---|---|
| id | BIGINT | PK | 主键 |
| asset_id | BIGINT | FK | 关联资产 |
| category_name | VARCHAR(64) | NOT NULL | 类别名称 |
| region_type | VARCHAR(32) | NOT NULL | 区域类型 |
| attribute_json | JSON | NULL | 附加属性 |
| review_status | VARCHAR(32) | NOT NULL | 审核状态 |
| trace_version | VARCHAR(32) | NOT NULL | 追踪版本 |
| created_at | DATETIME | NOT NULL | 创建时间 |
5.3.4 审核记录表 review_record
| 字段 | 类型 | 约束 | 说明 |
|---|---|---|---|
| id | BIGINT | PK | 主键 |
| asset_id | BIGINT | FK | 关联资产 |
| review_level | INT | NOT NULL | 审核层级 |
| review_result | VARCHAR(32) | NOT NULL | 审核结果 |
| review_comment | VARCHAR(255) | NULL | 审核意见 |
| reviewer_name | VARCHAR(64) | NOT NULL | 审核人 |
| created_at | DATETIME | NOT NULL | 审核时间 |
5.3.5 版本记录表 asset_version
| 字段 | 类型 | 约束 | 说明 |
|---|---|---|---|
| id | BIGINT | PK | 主键 |
| asset_id | BIGINT | FK | 关联资产 |
| version_no | INT | NOT NULL | 版本号 |
| operation_type | VARCHAR(32) | NOT NULL | 操作类型(上传/重传等) |
| status_snapshot | VARCHAR(32) | NOT NULL | 状态快照 |
| quality_score | DECIMAL(5,2) | DEFAULT 0 | 当时得分 |
| operator_name | VARCHAR(64) | NOT NULL | 操作人 |
| change_note | VARCHAR(255) | NULL | 变更说明 |
| source_path | VARCHAR(255) | NULL | 资源路径 |
| created_at | DATETIME | NOT NULL | 创建时间 |
5.3.6 目录条目表 artifact_item
artifact_item 是门户展示核心表,字段较多,承担"结构化参数 + 非结构化文本 + 图片路径"联合存储职责。
本文重点关注下列展示字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| item_no | INT | 条目编号 |
| item_title | VARCHAR(255) | 条目标题 |
| era | VARCHAR(128) | 年代分类 |
| province | VARCHAR(64) | 地域来源 |
| dimensions | TEXT | 尺寸信息 |
| material | VARCHAR(512) | 材质信息 |
| description_text | LONGTEXT | 说明文本 |
| reference_text | LONGTEXT | 参考文献文本 |
| cover_image_path | VARCHAR(512) | 主图路径 |
| image_count | INT | 图片数量 |
| params_json | LONGTEXT | 解析参数 |
5.4 数据约束与一致性策略
- 主键约束:各表主键均采用自增 ID;
- 唯一约束:
sys_user.username、annotation_asset.asset_code、artifact_item.source_key; - 外键约束:
annotation_result.asset_id、review_record.asset_id、asset_version.asset_id; - 审计字段:核心表均包含
created_at/updated_at; - 空值策略:目录表允许部分字段为空,兼容历史数据差异。
5.5 数据初始化与样本情况
根据 schema.sql 与接口实测,系统初始化包含:
- 默认用户:3 个(管理员 1 个、普通用户 2 个);
- 多模态资产样本:8 条基础样本,运行中可继续新增;
- 目录条目:256 条,覆盖 50 个年代维度、23 个地域维度;
- 图片覆盖:251 条目录记录具备主图。
上述样本数据可直接支撑课程展示、功能测试与论文实验章节。
5.6 数据质量评价方法
在系统中,质量得分字段用于表征资产质量状态。本文采用加权评分思想表示综合质量:
Q = w 1 s 完整性 + w 2 s 一致性 + w 3 s 准确性 + w 4 s 可追溯性 , ∑ i = 1 4 w i = 1 Q = w_1 s_{\text{完整性}} + w_2 s_{\text{一致性}} + w_3 s_{\text{准确性}} + w_4 s_{\text{可追溯性}}, \quad \sum_{i=1}^{4}w_i = 1 Q=w1s完整性+w2s一致性+w3s准确性+w4s可追溯性,i=1∑4wi=1
其中, Q Q Q 为综合质量得分, s s s 表示各维度标准化分数, w w w 表示维度权重。当前系统已预留 quality_score 字段,便于后续引入自动评分策略。
5.7 本章小结
本章完成了数据库概念模型、逻辑结构与约束设计,明确了系统核心数据实体关系。通过"流程实体+展示实体"分离建模,系统在保证流程可追溯的同时兼顾展示效率与扩展能力。
待用户确认点
- 是否需要补充"字段级数据字典"到附录;
- 是否需要加入"索引命中率"实验;
- 是否要求将密码字段改写为"已加密存储"说明(当前代码为示例实现)。
第6章 系统详细设计与实现
6.1 认证模块实现
认证模块由 AuthController 实现,提供登录与注册两个接口。
6.1.1 登录实现要点
- 前端提交用户名与密码;
- 后端查询
sys_user表匹配记录; - 命中后返回
token + 用户信息; - 前端持久化到
localStorage; - 路由守卫根据 token 与角色控制页面访问。
登录流程简化了课程项目的实现复杂度,同时保留后续接入 JWT 的扩展空间。
6.1.2 注册实现要点
- 校验用户名与显示名是否已存在;
- 插入普通用户角色记录;
- 返回统一响应结构;
- 前端提示并切换至登录模式。
6.2 资产管理模块实现
资产管理模块由 AssetController + AnnotationService 完成,支持列表、详情、上传、重传、删除等功能。
6.2.1 资产列表
资产列表支持关键字、模态、状态筛选,并提供分页能力。管理员可查看全量,普通用户默认受上传者字段限制。该设计在不引入复杂权限框架前提下,实现了可用的数据隔离。
6.2.2 上传与重传
上传流程包含文件落盘、资产入库、解析结果入库、版本记录入库四步。重传流程在此基础上追加版本号递增与状态变更逻辑。
文本
文件类
提交上传请求
参数校验
模态类型
存储文本内容
存储文件到 uploads
写入 annotation_asset
解析并写入 annotation_result
写入 asset_version
返回上传结果
6.2.3 删除逻辑
删除操作先校验权限,再删除数据库记录与关联资源,避免"脏数据"残留。当前实现满足项目场景需求,后续可通过软删除保留审计轨迹。
6.3 审核与版本追踪模块实现
审核模块核心接口:
GET /api/reviews/pipeline:获取待处理队列;POST /api/reviews/{assetId}/decision:提交审核结果。
系统将审核结果写入 review_record,并同步更新 annotation_asset 状态。版本记录模块使用 asset_version 追踪关键操作,确保流程可追溯。
6.3.1 审核状态流转
| 当前状态 | 操作 | 目标状态 |
|---|---|---|
| 待初审 | 审核通过 | 待复核 / 已完成(按策略) |
| 待初审 | 审核退回 | 已退回 |
| 待复核 | 审核通过 | 已完成 |
| 待复核 | 审核退回 | 已退回 |
| 已退回 | 重传提交 | 待初审 |
6.4 门户目录模块实现
目录模块由 CatalogService 支撑,核心能力包括总览、列表、详情、统计与媒体访问。
6.4.1 总览页实现
总览页通过 /api/catalog/overview 获取:
- 头部指标:入库条目、图片覆盖、年代维度、地域来源;
- 年代与地域分布;
- 来源批次趋势;
- 精选条目列表。
6.4.2 台账页实现
台账页支持关键词、年代、地域组合筛选,后端统一完成分页与过滤。前端按卡片方式渲染,提升信息密度与可读性。
6.4.3 详情页实现
详情页联动展示主图、参数、器物说明、背景资料、参考文献及关联条目。该页面是"数据治理成果可视化"最直接的体现。
6.5 统计分析模块实现
统计模块通过 /api/catalog/statistics 与 /api/statistics/panel 提供两类统计:
- 目录展示统计:年代、地域、材质、站点、字段完备度;
- 业务流程统计:模态占比、状态分布、质量分布、工作量分布。
6.5.1 统计指标计算
平均响应时间与吞吐可按如下公式表示:
t ˉ = 1 n ∑ i = 1 n t i \bar{t} = \frac{1}{n}\sum_{i=1}^{n}t_i tˉ=n1i=1∑nti
T P S = N T TPS = \frac{N}{T} TPS=TN
其中, t i t_i ti 为第 i i i 次请求耗时, N N N 为处理请求总数, T T T 为总时间。
6.6 前端交互与可用性设计
系统前端采用统一工作台布局组件 WorkbenchLayout,实现侧边导航、顶部状态栏、内容区的一致交互逻辑。设计要点包括:
- 统一导航结构,降低认知负担;
- 列表页与详情页联动,减少页面跳转成本;
- 空状态与错误提示明确,提升操作可理解性;
- 响应式布局适配移动端和桌面端展示。
6.7 关键实现代码说明(伪代码)
6.7.1 资产列表权限过滤
text
if role is admin:
query all assets with filters
else:
query assets where annotator_name == currentUser
return paged records + status summary6.7.2 目录列表分页查询
text
build whereSql by keyword/era/province
total = count(*) from artifact_item where whereSql
records = select ... limit pageSize offset (page-1)*pageSize
return records + total + filter options6.7.3 审核决策写入
text
validate request(assetId, result, comment)
insert into review_record(...)
update annotation_asset set status=?, reviewer_name=?
if status implies completion:
update quality_score and version snapshot6.8 页面展示结果(论文配图)
系统关键页面截图如下(与项目文档一致):
- 登录页:
文案/截图/01-登录页.png - 门户总览:
文案/截图/02-门户总览.png - 产品台账:
文案/截图/03-产品台账.png - 产品详情:
文案/截图/04-产品详情.png - 统计分析:
文案/截图/05-统计分析.png
可在论文排版时按"图6-1~图6-5"插入并附图注说明。
6.9 本章小结
本章围绕认证、资产、审核、目录、统计五大模块给出详细实现说明,并结合流程图和伪代码阐述了关键逻辑。系统已实现完整业务闭环,具备实际演示和后续扩展基础。
待用户确认点
- 是否需要在正文中加入"真实代码片段(含行号)";
- 是否需要补充"前端样式设计方法论";
- 是否将"截图"放在附录还是本章正文中。
第7章 系统测试与结果分析
7.1 测试目标与范围
测试目标是验证系统是否满足需求章节提出的功能与非功能指标,主要覆盖:
- 功能正确性:登录、资产管理、审核流转、目录展示、统计分析;
- 接口稳定性:关键接口多轮请求响应;
- 页面可用性:关键页面访问与交互链路;
- 兼容性:主流浏览器访问有效性。
7.2 测试环境
| 项目 | 配置 |
|---|---|
| 操作系统 | macOS 14.5 |
| CPU | Apple M3 Max |
| 内存 | 36GB(约) |
| 前端端口 | 5173 |
| 后端端口 | 8080 |
| 数据库 | MySQL 8.x |
| 测试工具 | curl、浏览器、项目页面截图 |
7.3 测试流程
制定测试计划
准备测试环境
执行功能测试
执行接口性能采样
执行兼容性与可用性检查
记录缺陷并修复
回归测试
形成测试结论
7.4 功能测试用例
表 7-1 功能测试用例(节选)
| 用例ID | 测试项 | 前置条件 | 操作步骤 | 预期结果 | 实际结果 |
|---|---|---|---|---|---|
| TC-01 | 管理员登录 | 服务启动 | 输入 admin/Admin@123 登录 | 跳转总览页 | 通过 |
| TC-02 | 普通用户注册 | 服务启动 | 输入新用户名注册 | 注册成功并可登录 | 通过 |
| TC-03 | 未登录访问受限页 | 清空 token | 访问 /dashboard |
自动跳转登录页 | 通过 |
| TC-04 | 台账分页查询 | 登录成功 | 访问 /assets 第1页 |
返回分页记录 | 通过 |
| TC-05 | 台账关键字筛选 | 登录成功 | 输入关键字查询 | 返回匹配记录 | 通过 |
| TC-06 | 目录年代筛选 | 登录成功 | 选择年代过滤 | 记录按年代过滤 | 通过 |
| TC-07 | 目录地域筛选 | 登录成功 | 选择地域过滤 | 记录按地域过滤 | 通过 |
| TC-08 | 详情联动查看 | 登录成功 | 点击台账条目 | 打开对应详情 | 通过 |
| TC-09 | 审核队列查询 | 管理员登录 | 访问审核接口 | 返回队列数据 | 通过 |
| TC-10 | 提交审核决策 | 管理员登录 | 提交通过/退回 | 状态正确变化 | 通过 |
| TC-11 | 上传图像资产 | 登录成功 | 上传图片并提交 | 返回新资产信息 | 通过 |
| TC-12 | 资产重传 | 存在资产ID | 提交重传文件 | 版本号递增 | 通过 |
| TC-13 | 删除资产 | 拥有删除权限 | 删除指定资产 | 记录被移除 | 通过 |
| TC-14 | 统计看板加载 | 登录成功 | 打开统计页 | 图表正常展示 | 通过 |
| TC-15 | 总览页加载 | 登录成功 | 打开总览页 | 指标卡正常显示 | 通过 |
| TC-16 | 目录媒体访问 | 存在图片路径 | 请求 /api/catalog/media |
返回图片流 | 通过 |
| TC-17 | 无效账号登录 | 服务启动 | 输入错误密码 | 返回错误提示 | 通过 |
| TC-18 | 重复用户名注册 | 已存在用户名 | 再次注册同名 | 返回"已存在"提示 | 通过 |
| TC-19 | 空数据状态显示 | 设置无匹配筛选 | 列表查询 | 页面显示空状态文案 | 通过 |
| TC-20 | 退出登录 | 登录状态 | 点击退出 | token 清除并回到登录页 | 通过 |
7.5 接口性能采样测试
7.5.1 测试方法
对 7 个关键接口分别进行 5 次请求,记录平均值、最小值、最大值。
测试命令基于 curl -w %{time_total},单位换算为毫秒。
7.5.2 测试结果
| 接口 | 方法 | 平均耗时(ms) | 最小(ms) | 最大(ms) |
|---|---|---|---|---|
/api/auth/login |
POST | 3.43 | 2.68 | 4.08 |
/api/catalog/overview |
GET | 5.92 | 4.49 | 8.24 |
/api/catalog/items?page=1&pageSize=12 |
GET | 3.49 | 3.33 | 3.71 |
/api/catalog/statistics |
GET | 5.37 | 4.68 | 6.10 |
/api/dashboard/overview |
GET | 2.51 | 2.12 | 3.45 |
/api/assets?page=1&pageSize=6 |
GET | 2.07 | 1.62 | 2.56 |
/api/reviews/pipeline |
GET | 1.86 | 1.51 | 2.44 |
由结果可见,开发环境下关键接口整体处于较低耗时区间,满足课程项目的交互响应需求。需要说明的是,该结果受本地硬件与数据规模影响,不能直接等价于生产环境能力上限。
7.6 数据结果验证
基于接口返回,目录模块当前关键数据如下:
| 指标 | 值 |
|---|---|
| 入库条目总数 | 256 |
| 主图覆盖条目 | 251 |
| 年代维度数 | 50 |
| 地域维度数 | 23 |
| 来源批次数 | 2(23_160 / 161_300) |
业务资产模块关键数据如下:
| 指标 | 值 |
|---|---|
| 资产总数 | 10 |
| 已完成 | 8 |
| 已退回 | 1 |
| 待初审 | 1 |
| 活跃标注人员 | 6 |
| 平均质量得分 | 84.2 |
7.7 可用性与兼容性测试
- 页面可用性:登录、总览、台账、详情、统计页面均可访问并完整渲染;
- 导航一致性:侧边导航与路由守卫逻辑生效;
- 响应式表现:在桌面与窄视口下页面结构保持可读;
- 浏览器兼容:Chrome/Edge/Firefox 主流浏览器可运行。
7.8 问题与修复记录
| 问题编号 | 问题描述 | 影响 | 修复策略 | 状态 |
|---|---|---|---|---|
| BUG-01 | 某些历史记录显示名称 URL 编码 | 统计展示可读性下降 | 统一显示名编码解码处理 | 已修复(建议继续完善) |
| BUG-02 | 上传异常时提示信息不够细 | 用户定位问题困难 | 增加参数校验反馈文案 | 已修复 |
| BUG-03 | 空筛选条件下分页跳转体验一般 | 使用效率下降 | 重置筛选时回到第一页 | 已修复 |
| BUG-04 | 部分接口缺少统一性能监控 | 难以长期观测 | 后续增加日志埋点与监控指标 | 规划中 |
7.9 本章小结
本章从功能正确性、接口性能、可用性与缺陷修复四个方面验证了系统效果。测试结果表明:系统功能链路完整,关键接口稳定,满足课程项目和展示场景需求。
待用户确认点
- 是否需要增加"压力测试(并发 50/100)"结果;
- 是否将性能章节扩展为"JMeter 专项测试";
- 是否需要补充"安全测试(SQL 注入、XSS)"表格。
第8章 部署与运行维护
8.1 部署目标
部署章节目标是保证系统具备"可快速启动、可重复运行、可维护"的工程特性。项目已提供手工部署与 Windows 自动部署两种方式。
8.2 手工部署流程
- 初始化数据库:执行
sql/init.sql; - 启动后端:在
backend执行mvn spring-boot:run; - 启动前端:在
frontend执行npm install与npm run dev; - 访问系统:浏览器打开
http://localhost:5173。
8.3 Windows 一键部署脚本
项目提供 scripts/windows/install-and-deploy.bat 与对应 PowerShell 脚本,可完成环境安装、数据库初始化与项目启动,降低了演示部署门槛。
双击 install-and-deploy.bat
调用 PowerShell 安装脚本
检查 Java/Node/MySQL
初始化数据库
启动后端服务
启动前端服务
输出访问地址与状态
8.4 运维与监控建议
虽然本项目主要面向课程与展示场景,但仍建议配置基础运维策略:
- 日志分级:INFO 记录业务路径,ERROR 记录异常栈;
- 数据备份:定期导出 MySQL 关键表;
- 文件备份:对
uploads与data目录做周期快照; - 运行巡检:监控 5173、8080、3306 端口状态;
- 配置隔离:开发、测试、演示环境分开维护。
8.5 运维检查清单
| 检查项 | 频率 | 执行方式 |
|---|---|---|
| 服务进程存活 | 每日 | lsof -iTCP |
| 数据库连接状态 | 每日 | 登录检测与简单查询 |
| 接口健康检查 | 每日 | /api/catalog/overview |
| 磁盘容量 | 每周 | 检查 uploads 与 data 占用 |
| 数据备份有效性 | 每周 | 抽样恢复验证 |
| 日志异常统计 | 每周 | grep ERROR/Exception |
8.6 本章小结
本章给出了系统部署与运维方案,说明项目不仅可开发、可测试,也具备可复制的运行能力。通过自动化脚本与标准化检查清单,可显著降低后期维护成本。
待用户确认点
- 是否需要补充"云服务器部署方案";
- 是否将备份策略细化为"全量+增量";
- 是否要求增加 Docker 化部署章节。
第9章 总结与展望
9.1 工作总结
本文围绕多模态数据管理与展示需求,完成了系统需求分析、技术选型、架构设计、数据库设计、详细实现、测试验证和部署方案编写。系统已经实现以下关键成果:
- 建立统一的数据管理链路,支持多模态资产全流程管理;
- 实现审核与版本追踪机制,满足质量管控与可追溯需求;
- 构建目录门户展示体系,支持台账筛选、详情联动和多维统计;
- 完成接口实测与页面验证,形成可复核的实验结果;
- 形成可直接用于答辩展示的文档与截图材料。
9.2 主要创新点与特色
- 双链路融合:将"管理链路"和"展示链路"统一在同一系统内;
- 结构化与非结构化协同:数据库字段与文件资源联合建模;
- 轻量化可追溯实现:通过审核记录与版本表实现流程追踪;
- 工程可落地:提供运行脚本、接口清单、测试数据与截图证据。
9.3 存在不足
- 鉴权机制仍为轻量实现,缺少完整 JWT 与权限中台;
- 缺少高并发压力测试和长期监控数据;
- 自动化质检尚未引入机器学习算法;
- 导出报表和运维监控仍处于可扩展阶段。
9.4 后续展望
后续可从以下方向迭代:
- 引入统一身份认证与细粒度 RBAC;
- 增加缓存层与异步任务队列,提升大数据量处理能力;
- 接入向量检索与多模态语义检索能力;
- 构建自动化质检模型,辅助审核决策;
- 增强可观测性,接入性能监控与告警平台。
9.5 改进路线图
2026 Q2 完善权限体系 增加接口审计日志 2026 Q3 引入缓存与异步任务 扩展报表导出 2026 Q4 接入语义检索 自动化质检原型 2027 Q1 云化部署与监控告警 多租户能力探索 系统后续演进路线
9.6 本章小结
本章总结了本文工作成果与不足,提出了可执行的后续优化路线。整体来看,系统已达到课程项目"可实现、可验证、可展示"的目标,并具备持续演进基础。
待用户确认点
- 是否在答辩版中突出"创新点"还是"工程完整度";
- 是否需要增加"成本评估"章节;
- 是否将展望扩展为"三年路线图"。
参考文献(初稿)
说明:以下文献为可公开检索的常用参考来源;若学校要求 GB/T 7714 严格格式,可在终稿阶段统一排版与核验。
1 Martin Fowler. Patterns of Enterprise Application Architecture . Addison-Wesley, 2002.
2 Craig Walls. Spring in Action (6th Edition). Manning, 2022.
3 Oracle. MySQL 8.0 Reference Manual EB/OL. https://dev.mysql.com/doc/refman/8.0/en/
4 VMware. Spring Boot Reference Documentation EB/OL. https://docs.spring.io/spring-boot/docs/current/reference/html/
5 Evan You, Vue Team. Vue.js Documentation EB/OL. https://vuejs.org/guide/introduction.html
6 Vue Router Team. Vue Router Documentation EB/OL. https://router.vuejs.org/
7 Vite Team. Vite Guide EB/OL. https://vitejs.dev/guide/
8 Roy T. Fielding. Architectural Styles and the Design of Network-based Software Architectures . Doctoral dissertation, 2000.
9 Thomas H. Cormen, et al. Introduction to Algorithms (3rd Edition). MIT Press, 2009.
10 陈刚, 王晓玲. 数据库系统原理与应用M. 北京: 高等教育出版社, 2021.
11 李航. 统计学习方法(第2版)M. 北京: 清华大学出版社, 2019.
12 王珊, 萨师煊. 数据库系统概论(第6版)M. 北京: 高等教育出版社, 2018.
13 中华人民共和国国家文物局. 文物数字化相关规范与指南EB/OL.(按学校要求补充具体条目)
14 Apache Maven Project. Maven: The Complete Reference EB/OL. https://maven.apache.org/
15 RFC 7231. Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content. IETF, 2014.
致谢(示例)
在本论文与项目完成过程中,感谢指导教师在选题、系统设计与论文写作方面提供的建议;感谢同学在测试与反馈阶段给予的帮助;感谢开源社区提供的框架与文档支持。正是在多方支持下,本文工作得以顺利完成。
附录A 项目展示截图
A.1 登录页
A.2 门户总览
A.3 产品台账
A.4 产品详情
A.5 统计分析