从0开始的机器学习之旅(一):什么是机器学习
零、前言
近十年来,毫无疑问最具潜力,颠覆最大的就是AI,在短短的几年时间从默默无闻到异军突起,再到一统江湖。毫无疑问,作为一个技术人员,去学习AI是非常有价值的且必须的。或许我们天天都在用各种Agent,各种LLM,但如果我们不知道它们的原理,仅仅只是把它们当成一个"黑盒",那相信如果技术发生变革那一刻,我们是很被动的。但作为一个RD ,从自身的角度来说,我们并不需要像算法岗了解得那么深,但我们需要知其然更知其所以然 。对自己天天在使用的工具有一个相对清晰的了解与认知,想必是对自身在AI浪潮的发展中大有裨益的,这也是我想写这篇博客的原因,一方面记录自己的学习路径,一方面希望可以为他人提供参考。
严格上来说,机器学习并不等同于AI,但机器学习是AI领域中最大也是最出色 的一个领域,无论是改变世界的LLM ,还是现在各类搜索推荐算法,都属于机器学习,所以这里才选择从机器学习开始对AI领域的学习
本文大致路径跟随 吴恩达的机器学习课 进行,很适合零基础人群学习
一、什么是机器学习
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
机器学习是对能通过经验自动改进的计算机算法的研究。
机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
-----维基百科对机器学习的定义
(一)、定义解释
如上述维基百科对其的解释,机器学习是设计与分析一些让计算可以自动"学习"的算法,并利用其规律对未知数据进行预测。这里的预测如果是预测语句的下一个词,那就是现在红极一时的Chat AI ,如果是预测你是不是对某个广告感兴趣,那就成了广告推荐系统 ,如果是预测你是属于哪一种人群,或者预测你身上有什么可以用来分类的标签,那就成了人群区分系统 ,总而言之,机器学习是一门"预测"的艺术,通过从海量数据进行挖掘,习得其中的各种隐藏信息,将其用来预测未知数据,便是机器学习的价值所在。
二、机器学习分类
机器学习是一个巨大的领域,但可以粗略地将其分为如下几类
(一)、监督学习
故名思意,监督学习的精髓在于"监督",在监督学习中,有一个个考官不断地告诉你:"这个不对!错得很离谱!"、"差不多,但还是差一点!"、"完美,正确!"。模型会根据这些反馈来不断地反思自己,改正自身,最后变成一个高正确率的"学霸"。
总而言之,监督学习可以总结为,给出 数据(X),和标签(Y),要求模型找出X--->Y的映射
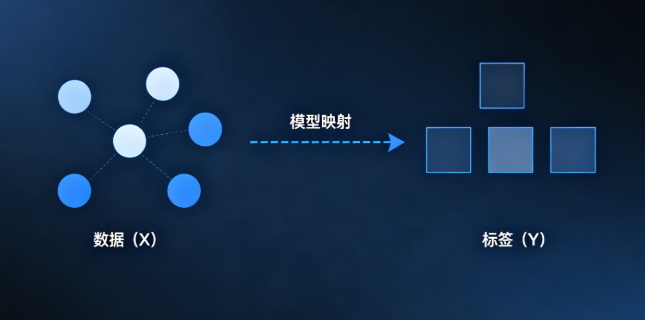
监督学习的用途大致可以分为两类:分类 和回归
1.分类
顾名思义,分类就是为了把一系列数据分成一个或多个类
举个例子,现在有很多邮件,要求你分成正常邮件和垃圾邮件,如何实现?
监督学习给出的答案是,给每一封邮件(X)打上标签:是否是垃圾邮件(Y),让模型不断尝试去判断,如果失败了就不断从中吸取经验改进自身,继续学习
这种类型的任务便被称为分类
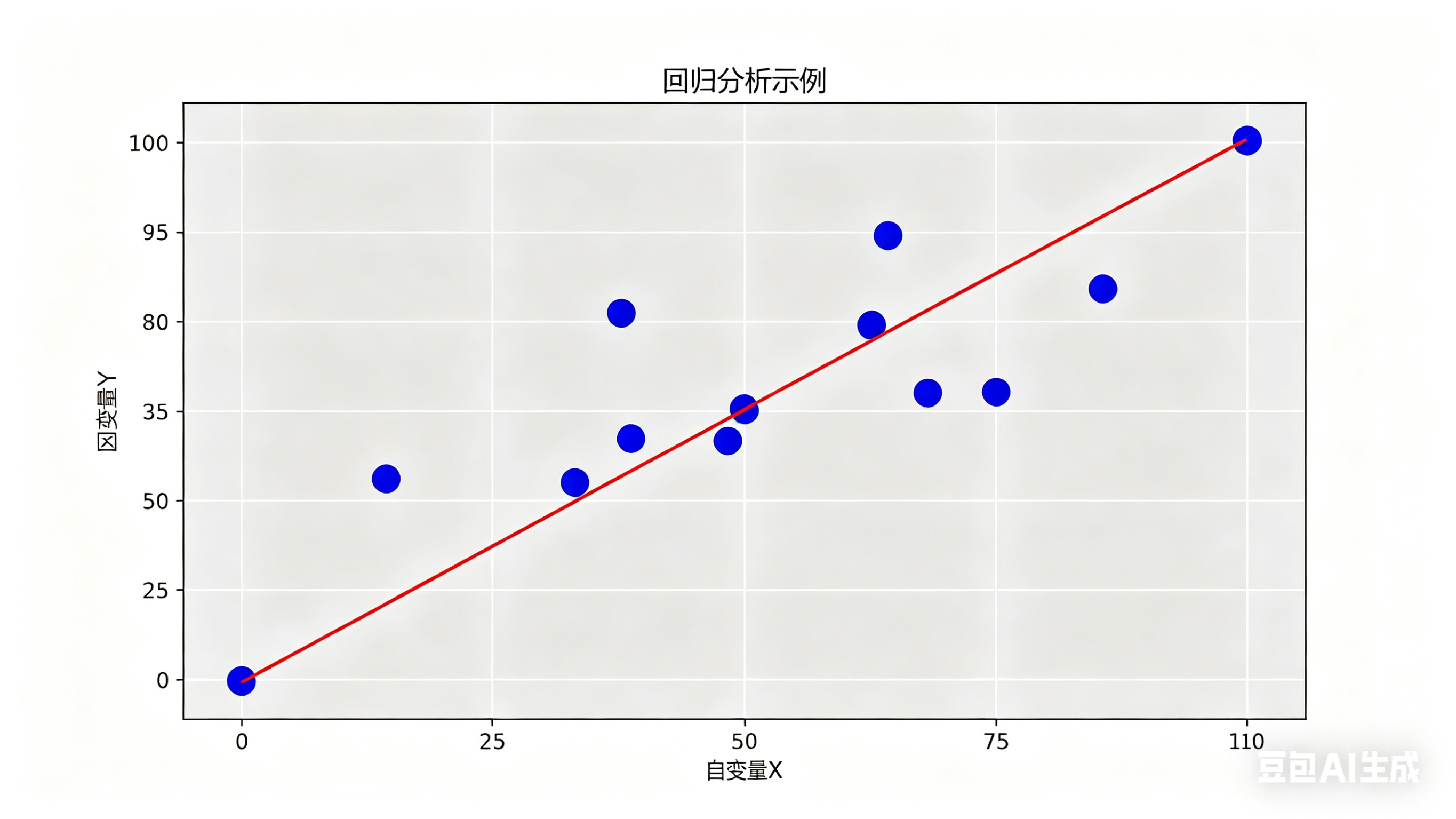
2.回归
回归,也可以理解为预测。当你想要一个模型告诉你确切的数字,文字时,这就是回归。
举个例子,你现在有一支股票五年的趋势图,你想预测一下接下来的趋势是怎么样的,于是你把趋势图数据喂给了AI(无穷多的 日期(X)和价格(Y)),然后AI会去尝试去找到其中的规律,并验证是否成立,这便是回归。回归的精髓在于,必定是连续的数字。
值得一提的是,只有预测明天的价格,才算是回归,如果是预测涨跌,就成了分类,回归做填空题,而分类做选择题
可能你觉得现在的LLM是属于回归?其实答案比较反直觉,其更多地属于分类:将下一个字(Token)分类到茫茫多的词表中,将其挑出来组成回答。
(二)、无监督学习
无监督学习和监督学习的最大区别在于,没有任何的答案提供给模型 ,模型必须自己摸索 ,找到数据中的潜在关系,这种没有答案的方式决定了无监督学习不适合用来找"答案",而是"结构",其经常用来把一堆看起来毫无关系的数据通过某种方式分为多簇,或是检测异常,降维数据
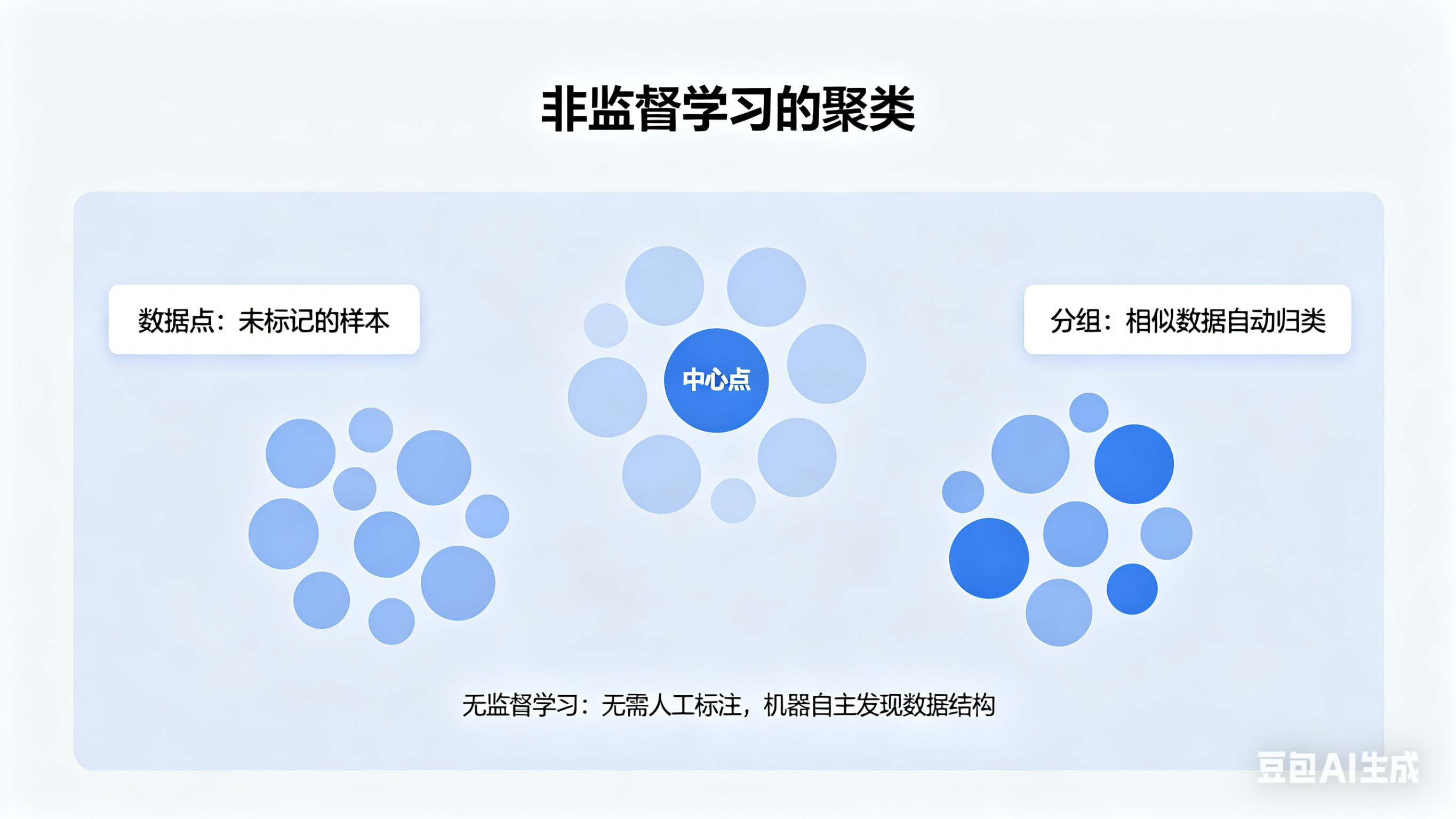
1.聚类
假如你是一个公司的经理,想知道和你们公司做生意的客户都有哪些特点,于是你收集了成千上万的详细的客户信息,但是茫茫多的信息你根本看不出任何规律,这时候便是无监督学习的主场。通过K-Means等算法,能够将客户高效正确的划分为多个特征清晰的群体。
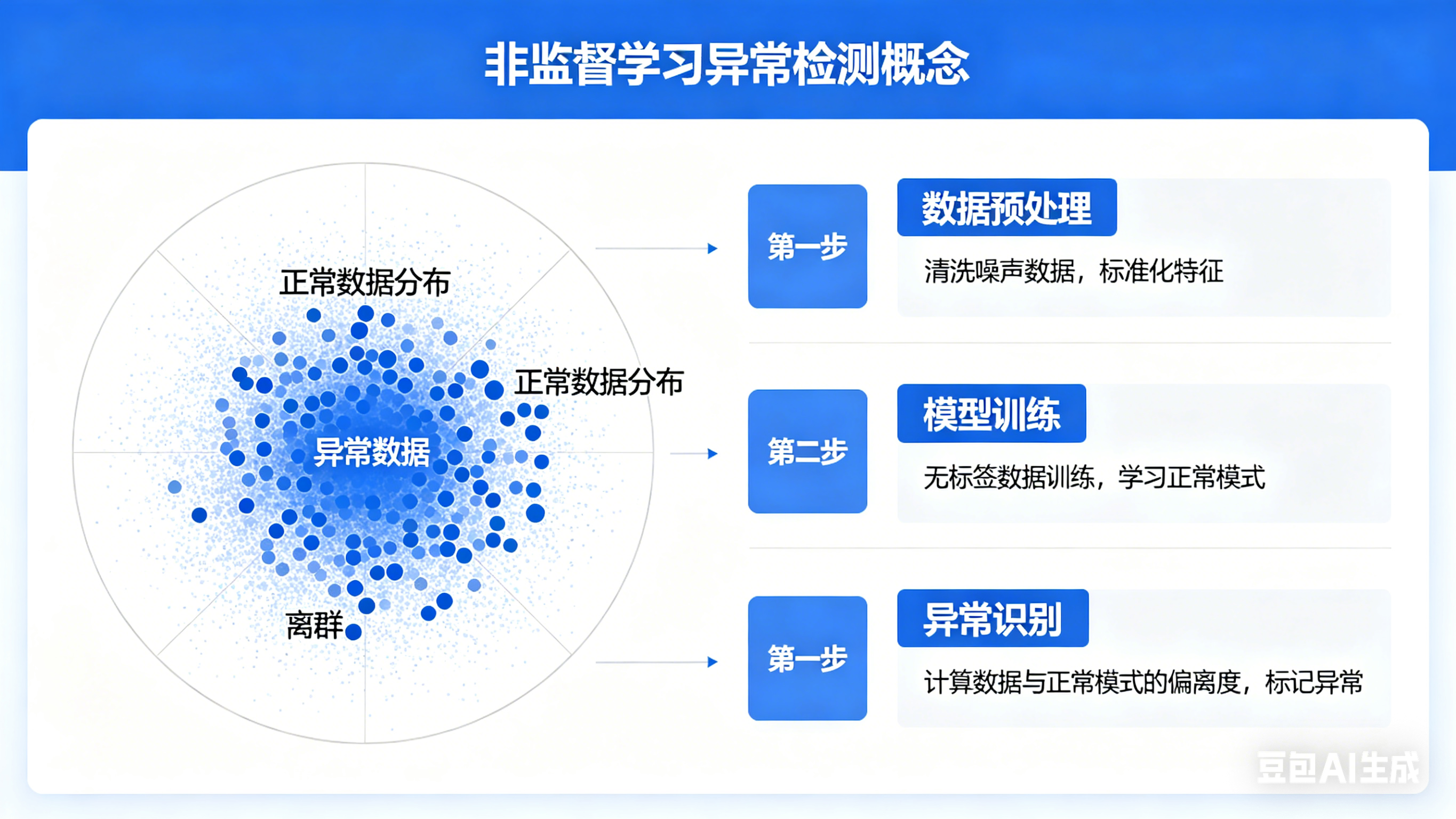
2.异常检测
在银行交易中,无监督学习不是为了把交易分类,而是为了看谁**"不合群"。如果大家的交易都在白天,在超市消费,突然有一个人在凌晨 3 点往境外汇了大额资金,模型会立刻报警。也就是找异类**。
可能你会觉得,判断"有异常"和"无异常" ,无疑是监督学习中的分类 ,但你要知道,可能十万笔交易中只有一笔 异常,如果是正常的分类算法,大概率会直接忽略掉这个"噪音",异常通常是不可预测的,无法提前给出其数据,这时候只能靠无监督学习的异常检测,来判断这个交易逻辑是否偏离正常交易来实现检测
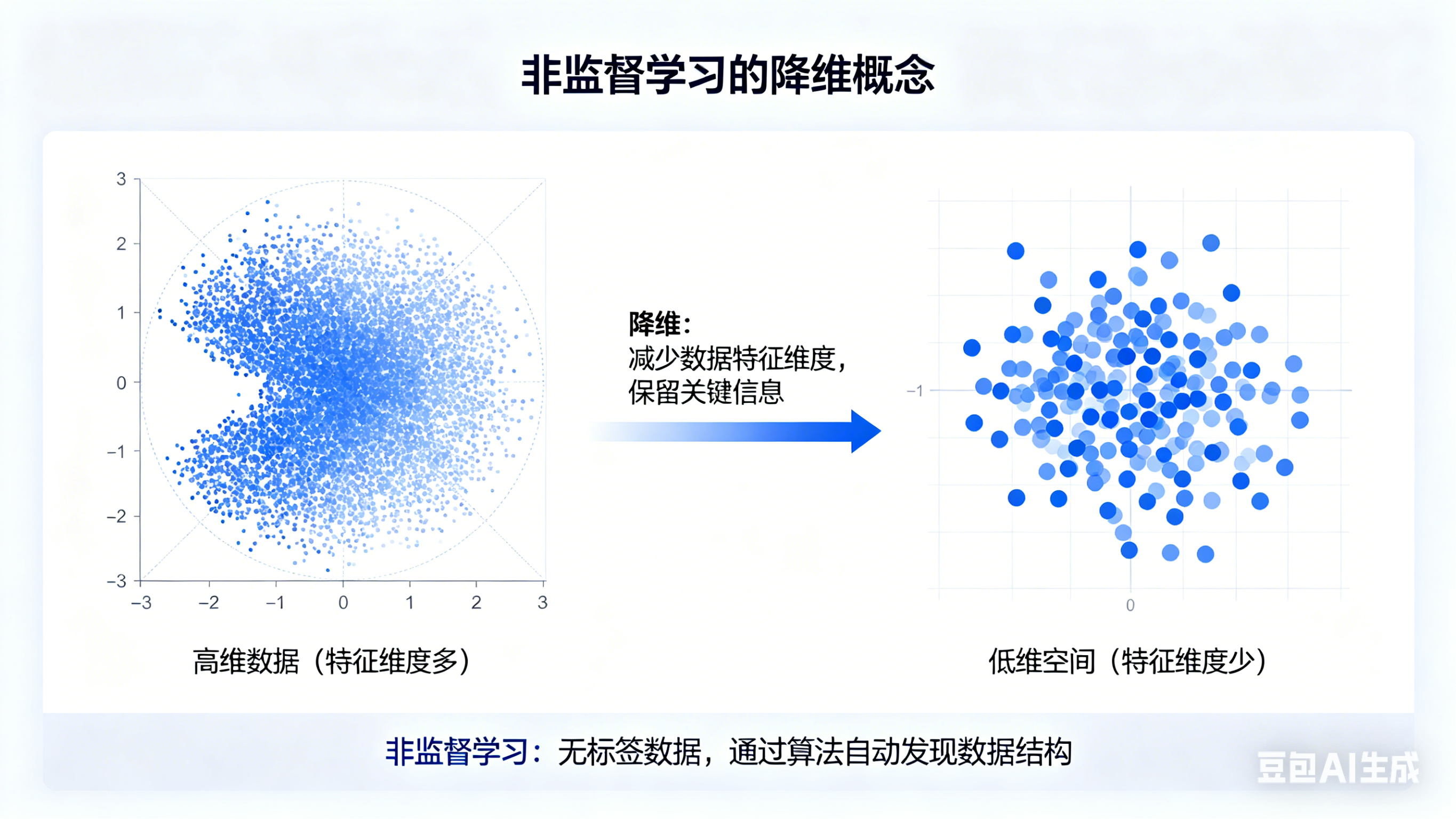
3.降维
如果你的客户信息有 100 个维度(年龄、收入、爱好、住址、鞋码......),数据太臃肿了。无监督学习可以帮你把 100 个维度压缩成 3 个"核心特征",也就是特征提取
同样的,这和监督学习的分类很像,但监督学习的分类是添加标签 :把数据分到指定的类中。而非监督学习的降维是减少列数:把不必要的特征隐去(也有可能把特征融合),对数据集进行精简
(三)、强化学习
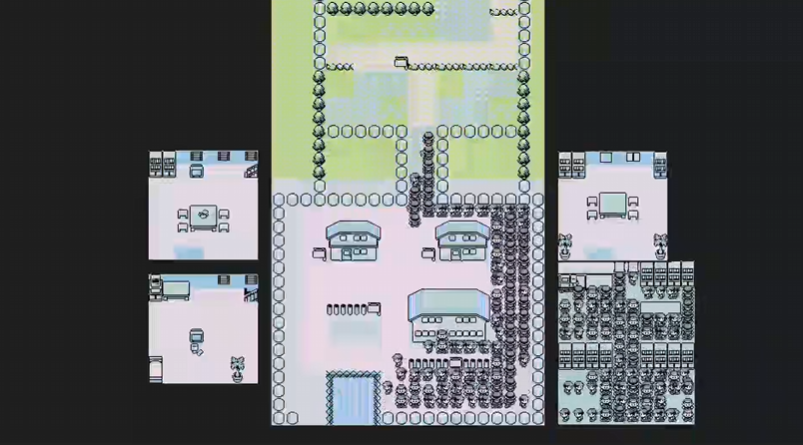
在强化学习里,没有考官告诉你 1+1 等于几,只有一套奖励机制。模型必须在环境里通过不断地试错,去寻找能让自己"分数最高"的动作。
举个例子,之前有一个 训练AI挑战通关 口袋妖怪:红,就是通过强化学习来实现的:到达新区域+5分,战斗胜利+1分,升级+1分,拿到道馆徽章+10分,战败-5分等等,模型一开始并不知道"拿道馆徽章"是什么意思,它只是为了得分,不断尝试各种动作,直到发现"战斗胜利就能升级,就能拿到徽章 "这个关联。
LLM虽然绝大多数由监督学习而形成,但在最后要让他更像人,就会通过强化学习(RLHF )来让他说话更迎合人类的价值观。
三、总结
以上便是对整个机器学习领域的简单的一个介绍,相信读到这里,你脑内已经有一个大致的机器学习的框架了,那么我们要做的就是往这个框架中填东西。接下来的一章,就让我们从监督学习开始,以回归方程来进一步加深对监督学习的学习和认知。