摘要
本文介绍了机器学习中常用的四种距离度量方法:欧氏距离、曼哈顿距离、切比雪夫距离以及闵可夫斯基距离,并解释了它们之间的数学关系与适用场景。此外,文章详细阐述了特征处理中的两种无量纲化技术------归一化与标准化,分析了各自的原理、计算公式、优缺点及适用条件,并通过代码展示了基于scikit-learn的具体实现。这些预处理方法对提升模型性能与稳定性具有重要意义。
Abstract
This article introduces four commonly used distance metrics in machine learning: Euclidean distance, Manhattan distance, Chebyshev distance, and Minkowski distance, explaining their mathematical relationships and applicable scenarios. Furthermore, it elaborates on two dimensionless techniques in feature processing---normalization and standardization, analyzing their principles, formulas, advantages, disadvantages, and applicable conditions, with code examples demonstrating implementations using scikit-learn. These preprocessing methods are crucial for improving model performance and stability.
一.距离度量
1.欧氏距离( Euclidean distance****)****
欧氏距离前面已经了解过,这个方法是直观的距离度量方法,也就是指两个点在空间中的距离,对应维度差值平方和,开平方根。
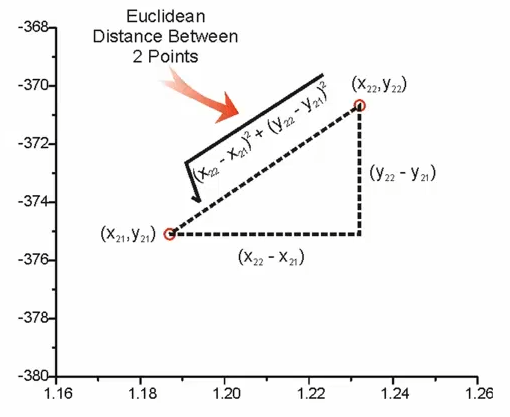
其在二维、三维以及n维空间下的计算方式如下:

2.曼哈顿距离( Manhattan distance )
曼哈顿距离,也称为L1距离或城市街区距离,是两点之间在标准坐标系上的绝对轴距总和。其名称来源于美国曼哈顿的网格状街道布局------从一个路口到另一个路口只能沿街道行走,无法斜穿街区(横平竖直)。
其计算方法就是对应维度差值的绝对值之和:

特点:
非负性、对称性、三角不等式(满足距离公理)。
旋转敏感:将坐标系旋转45度后,曼哈顿距离会变成缩放后的L∞距离(切比雪夫距离),但本身不具旋转不变性。
稀疏性:在高维数据分析中,曼哈顿距离往往比欧氏距离对异常值更鲁棒。
3.切比雪夫距离( Chebyshev distance****)****
这个方法也称为L∞距离或棋盘距离,定义在向量空间中两点在各坐标轴方向上的坐标差的最大绝对值。其名称源于国际象棋中"王"的移动方式------王可以横、竖、斜走一步,因此从一格走到另一格的最小步数恰好等于切比雪夫距离。
计算方式如下:

4.闵可夫斯基距离( Minkowski distance****)****
这个方法不是一种新的距离的度量方式。闵可夫斯基距离是Lp范数下两点间距离的统一定义,公式为:
其中参数p≥1。当p=1时退化为曼哈顿距离,p=2时退化为欧氏距离,p→∞时退化为切比雪夫距离,因此它通过调节p值能够灵活适应不同数据分布和度量需求。
二.特征处理
进行归一化与标准化的目的是因为特征单位或大小相差较大,或者某些特征的方差相比其他的特征要大出几个数量级,容易影响目标结果,使得一些模型无法学习到其他特征。
1.归一化
通过对原始数据进行变换把数据映射到mi,mx(默认0,1)之间。公式如下:
其中min与max对应该特征列中最小值与最大值,也是我们最终的计算结果。
计算过程如下图演示:
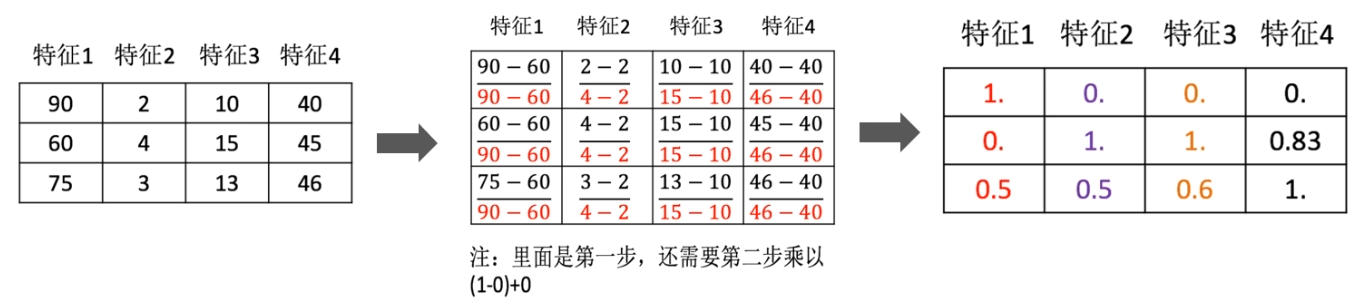
但是这个方法存在一个缺点,就是当某列特征中最大值或最小值发生了变化,则通过归一化方法计算得到的数据就是有问题的。所以这个方法更适用与小数据集的操作。
数据归一化API:
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1))
其中feature_range表示缩放区间
fit_transform(X) 将特征进行归一化缩放,这个方式适用于第一次处理的时候。之后就可以直接用transform(X)。
对数据归一化的代码实现如下:
python
# 导包
from sklearn.preprocessing import MinMaxScaler # 归一化对象
# 准备数据集
x_train = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
# 创建归一化对象
# 参数feature_range 表示生成范围,默认0------1,若就是在这个区间,则参数可以省略不写
# transfer = MinMaxScaler(feature_range=(3, 5))
transfer = MinMaxScaler()
# 对原数据集进行归一化
x_train_new = transfer.fit_transform(x_train)
# 打印处理后的数据
print('归一化后的数据集为:\n')
print(x_train_new)结果如下:
python
归一化后的数据集为:
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]2.数据标准化
通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据。其公式如下:
其中mean是特征的平均值,为特征的标准差。
数据标准化API:
sklearn.preprocessing.StandardScaler()
fit_transform(X) 将特征进行归一化缩放。
对数据归一化的代码实现如下:
python
# 导包
from sklearn.preprocessing import StandardScaler #标准化对象
# 准备数据集
x_train = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
# 创建标准化对象
transfer = StandardScaler()
# 对原数据集进行标准化
x_train_new = transfer.fit_transform(x_train)
# 打印处理后的数据
print('标准化后的数据集为:\n')
print(x_train_new)
# 打印数据集的均值和方差
print(f'数据集的均值为:{transfer.mean_}')
print(f'数据集的方差为:{transfer.var_}')
print(f'数据集的标准差为:{transfer.scale_}')结果如下:
python
标准化后的数据集为:
[[ 1.22474487 -1.22474487 -1.29777137 -1.3970014 ]
[-1.22474487 1.22474487 1.13554995 0.50800051]
[ 0. 0. 0.16222142 0.88900089]]
数据集的均值为:[75. 3. 12.66666667 43.66666667]
数据集的方差为:[150. 0.66666667 4.22222222 6.88888889]
数据集的标准差为:[12.24744871 0.81649658 2.05480467 2.62466929]所以总的说,数据归一化将数据映射到固定区间(如0,1),依赖于最大值和最小值,受异常值影响较大;数据标准化则减去均值后除以标准差,使数据服从均值为0、方差为1的分布,对异常值相对稳健。两者均为无量纲化处理,但归一化更适合需要严格边界(如图像像素)的场景,而标准化更适用于多数机器学习模型(如线性回归、SVM)对特征尺度一致的要求。
总结
本文系统讲解了距离度量与特征处理两类基础但关键的预处理技术。距离度量部分从欧氏距离延伸到曼哈顿距离、切比雪夫距离及闵可夫斯基距离,揭示了Lp范数框架下的内在联系。特征处理部分对比了归一化与标准化:归一化将数据映射到固定区间,但易受异常值影响;标准化使数据服从标准正态分布,对异常值更稳健。理解并正确应用这些方法,是构建可靠机器学习模型的重要前提。