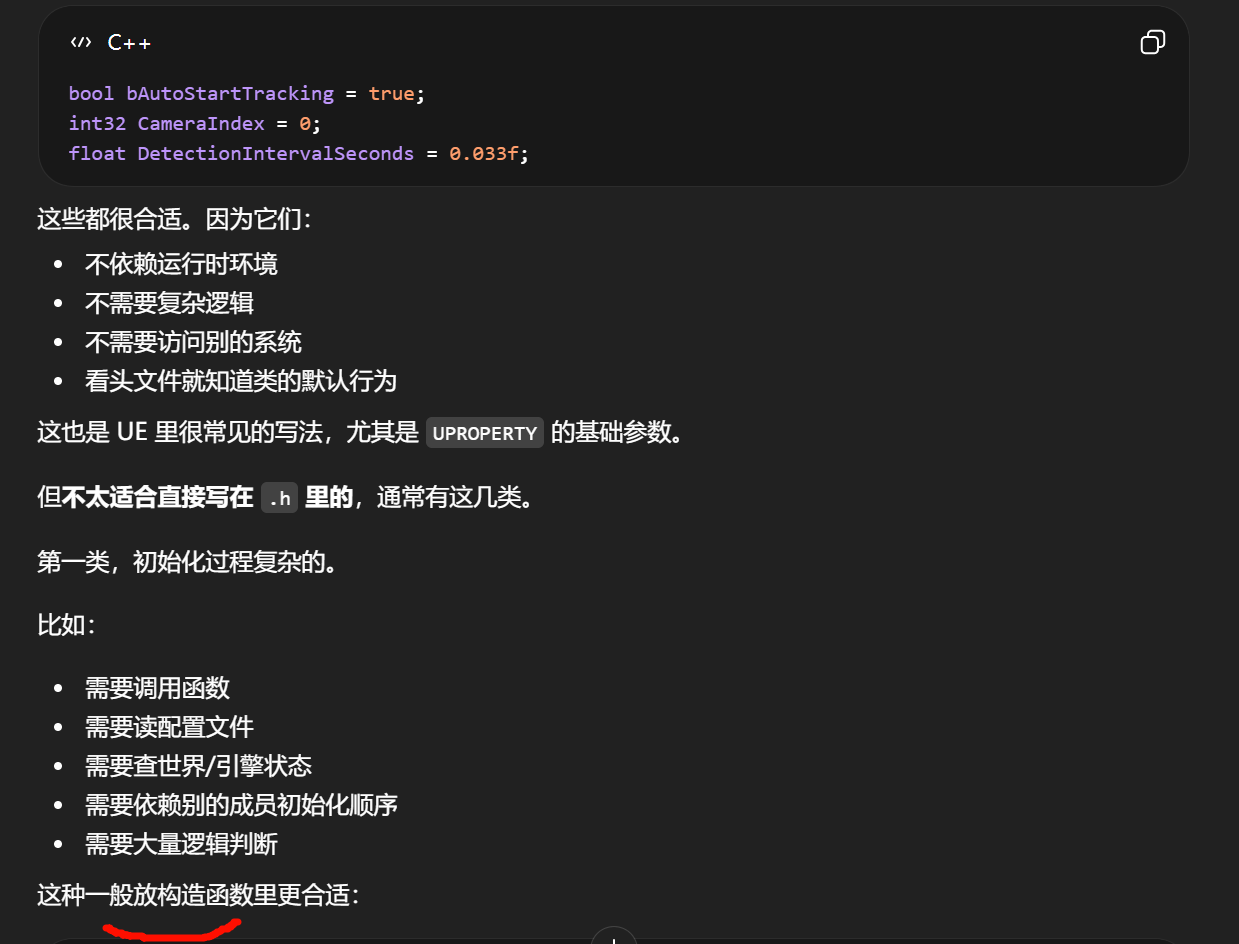
"复制为 PNG / JPG / WEBP / BMP"
表示除了普通图像格式外,PixPin 还会尽量提供一个"文件化"的图像版本,编码成你指定的格式。
于是某些程序会把它当成"你贴进来了一张图片文件",而不是单纯的内存图像。
无论如何,PixPin 大概率都会放基础图片格式
这些是为了保证通用粘贴兼容性。
比如常见的 CF_BITMAP、CF_DIB、CF_DIBV5 这一类。
在 CSDN 这种网页编辑器里粘贴时,网页侧最终能拿到什么,不是直接由你网页代码去读 CF_DIB / CF_BITMAP 这些 Win32 格式决定的,而是由浏览器先从 Windows 剪贴板里挑一份自己能消费的数据 ,再++转换成 Web 平台暴露的 ClipboardEvent/DataTransfer/ClipboardItem 形式给网页++。
PixPin → Windows 剪贴板里放多种格式
Chrome/Edge → 从这些格式里选自己要的
网页编辑器 → 只看到浏览器转交出来的 items/files
在网页里看到的不是"CF_xxx 本体",而是浏览器转译后的结果。
一般在 Chrome/Chromium 里,网页层最常见拿到的是这些 Web 格式,不是 Win32 的 CF_* 名字本身:
text/plain
text/html
image/png
这是 Clipboard API 规范里要求浏览器在 paste 场景必须能暴露的核心类型;如果系统剪贴板里存在对应的原生数据,浏览器应把它映射成这些 Web 类型。对图片来说,规范要求的必选图片类型就是 image/png。W3C
所以你问"谷歌浏览器里一般会转译成什么格式",对图片这件事,最实用的答案是:
在网页里通常按 image/png 来看待 。
也就是说,即便 Windows 底层可能是 CF_DIB、CF_BITMAP、注册的 "PNG",甚至别的图像表示,到了网页侧,Chrome 往往会把它包装成 ClipboardItem / DataTransferItem 里的 image/png,或者给你一个 type === "image/png" 的 File / Blob。这个结论和规范的"mandatory data types"一致。
第一,网页层不是直接看到底层 CF_DIB。
第二,不等于 Windows 里原本就一定是 PNG。
如果这张图的 File/Blob 大小是 3 MB,你执行:
const buffer = await file.arrayBuffer();
通常就会在 JS 可访问内存里拿到一块大约 3 MB 的 ArrayBuffer。
https://www.51cto.com/article/818899.html
对现代桌面浏览器来说,单次处理 3 MB 图片通常完全不算大负担。
3 MB 大概是:
3 * 1024 * 1024 = 3,145,728
也就是说,如果你把它看成一个按字节访问的数组,下标最大也就到三百多万。
而 JavaScript Number 能安全精确表示的整数上限是:
2^53 - 1 = 9007199254740991
三百多万和九千多万亿比,差太远了,所以根本不存在精度丢失。
要实现"读取剪贴板图片",你的扩展大概率还需要补相关能力,不是当前 manifest.json 里现成就能做的。 你现在权限只有 tabs、scripting、activeTab。 要读图片剪贴板,通常还要考虑:
clipboardRead权限- 以及在合适上下文里调用 Clipboard API
这时候剪贴板里放的是图像数据格式,比如你前面聊到的位图/DIB/PNG 数据这类。
这种数据本质上是"内容",不是"文件实体",所以通常没有稳定的 文件名 这个字段。
File/Blob -> arrayBuffer() -> SHA-256
Blob / File 自带的方法:
const buffer = await file.arrayBuffer();
arrayBuffer() 属于标准 Web API。
在 Chrome 里当然能用,但它不是"Chrome 私有扩展 API",普通网页脚本、content script、扩展页面里只要拿到 Blob/File,通常都能这样调。
"这两张图看起来一样,不管是不是重新编码过,都别重复插"
那完整 hash 就不够了,要上感知哈希、像素级比较之类更高一层的方法。
PNG 文件里,IDAT 中看到的是压缩后的扫描线数据,不是裸像素。
如果你的目标平台基本就是 Chrome/Chromium 网页侧,type 的区分价值会比较低 ,因为图片粘贴到 Web 层时,浏览器通常暴露的是 image/png 这一类标准化后的 MIME,而不是 Windows 底层原始格式;Clipboard API 规范里图片的必选类型就是 image/png,MDN 现在也仍然把浏览器常见支持概括为文本、HTML 和 PNG 图片数据。
未来不只处理截图,还处理拖入/粘贴别的图片来源;
不同浏览器或不同输入链路可能给出别的 image/*;
某些页面逻辑可能同时接收到 file/item 的不同表示。
MDN 对剪贴板读写的描述也明确用了"commonly support",不是"永远只会是 PNG"。
因为 Chrome 的 MV3 service worker 虽然会被回收,但不是每几秒无脑回收。
对你这种短流程:
- 点击发布
- 很快 success
- 很快跳新 editor
++通常时间足够短,所以经常能成功。++
-
background Map:扩展级运行时缓存,快,但不可靠,worker 没了就丢。 Chrome for Developers -
content script 变量:页面实例级运行时状态,换页基本就没。 Chrome for Developers -
chrome.storage.session:扩展级会话态存储,适合临时状态兜底;可按tabId自己分桶。 Chrome for Developers -
chrome.storage.local:扩展级持久存储,适合长期数据。
第一种,页面表面加载完了,但目标按钮还没渲染出来。
CSDN 这种页面通常不是一次性静态 HTML,全是前端框架动态渲染。你 content script 在 document_idle 或 DOMContentLoaded 时跑了,但那一刻"发布按钮"节点可能还没真正插进 DOM。
于是你的代码像这样:
JavaScript
const btn = document.querySelector('xxx发布按钮选择器');
if (btn) {
btn.addEventListener('click', onPublishClick);
}
如果当时 btn 是 null,这次注入就什么都没挂上。
后面按钮虽然出现了,但你没有重试,所以用户第一次点时当然抓不到。
Python和OpenCV是编程语言 与计算机视觉库 的关系 。Python作为一种易用、高效的脚本语言,通过封装底层的C++ OpenCV代码(主要是opencv-python ),让开发者能用简洁的语法进行图像处理、视频分析和机器学习,特别依赖Numpy进行数组运算。
OpenCV的核心代码是用C/C++编写的,速度极快。opencv-python 是OpenCV提供的一个Python封装库,它将这些底层的C++函数映射到Python中,使得Python程序员可以轻松调用。
tabs.onUpdated 绝对不是每帧调用。
它是 tab 发生更新时才触发的事件,
-
URL 变化
-
加载状态变化(
loading→complete) -
标题变化
-
favicon 变化
-
pinned / audible / muted 等 tab 属性变化
Chrome 官方对扩展 service worker 事件的说明里直接举过这个例子:tabs.onUpdated 会在每次导航、每个 tab 上被调用,但这说的是"导航/更新事件",不是渲染帧。
complete 只在 tab 的加载状态发生更新 时才可能出现在 changeInfo 里。Tabs API 里 status 本身就是 tab 的 loading status,枚举值是 "unloaded" | "loading" | "complete";但 onUpdated 不是每次都带 status,它只是"tab 某些属性更新了"时触发,changeInfo 里只包含这次变化的字段。
Chrome 启动后恢复了上次标签页,但这个 tab 在你扩展这次 service worker 生命周期里,没有再经历一轮你能观察到的 "loading" -> "complete" 更新,于是你的条件根本没命中。chrome.runtime.onStartup 只是启动事件,不等于所有已恢复 tab 都会重新给你一遍理想的更新序列。
URL 变了,但不是一次"完整导航完成",而是 History API 改地址。
官方 webNavigation 明确区分了 onHistoryStateUpdated:如果页面用 history.pushState() 之类修改 URL,会触发这个事件。也就是说,有些"看起来像换页面/换地址"的情况,并不是一次普通加载完成,自然不保证给你一个新的 status === "complete"。
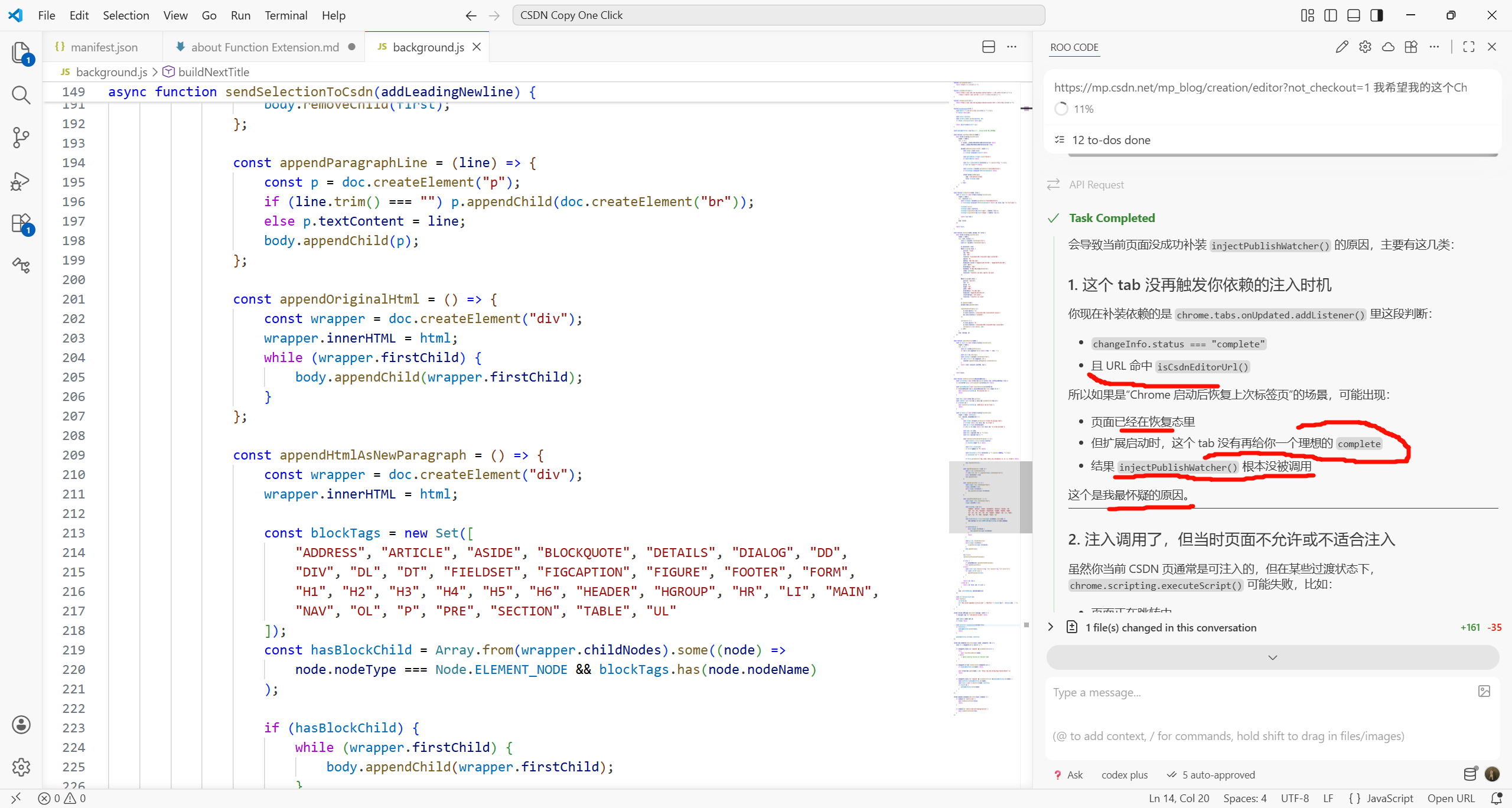
ensurePublishWatcherForExistingEditorTabs().catch((error) => {
console.warn("CSDN Quick Paste Failed to scan existing editor tabs", error);
});
是在 background.js 里执行的。
而你这个 background.js 在 MV3 下本质上就是 extension service worker。
background.js 作为 MV3 的 service worker,是 浏览器按需自动启动 的。只要有相关事件触发,比如:
-
tabs.onUpdated -
runtime.onMessage -
commands.onCommand
Chrome 就会把这个 worker 拉起来执行对应代码。你不用先手动打开它的 DevTools,它也会正常工作。
看到它们,最好提前开;否则有些早期日志你可能错过
console.warn(...) 不是"打开 Console 才开始打印",而是代码一跑到那行就已经输出到浏览器日志系统里了。
两条逻辑的触发条件完全不同:
- 图片/文本追加:你按
Alt+V - 标题递增跳转:你点击"发布博客"并进入 success
它们共享的只是同一个 background.js,但事件源不同、状态不同、目标 DOM 也不同。
"permissions": "offscreen"
表示你的扩展可以用 chrome.offscreen 去创建和管理一个 隐藏的 offscreen document 。这个 document 本质上是一个不展示给用户的扩展页面,主要用途是:因为 service worker 没有 DOM,所以当你需要 DOM API、窗口相关能力、某些文档上下文能力时,可以在这个隐藏页面里做。Chrome 官方文档就是这么定义的。
不是"有了 offscreen 就能多读网页内容",
而是"扩展可以创建一个隐藏文档来做 service worker 做不了的 DOM/文档类事情"。Chrome 官方还说明了:offscreen document 里可用的扩展 API 很少,基本主要靠 chrome.runtime 来通信。Chrome for Developers
DOM 全称就是 Document Object Model ,中文常叫 文档对象模型。
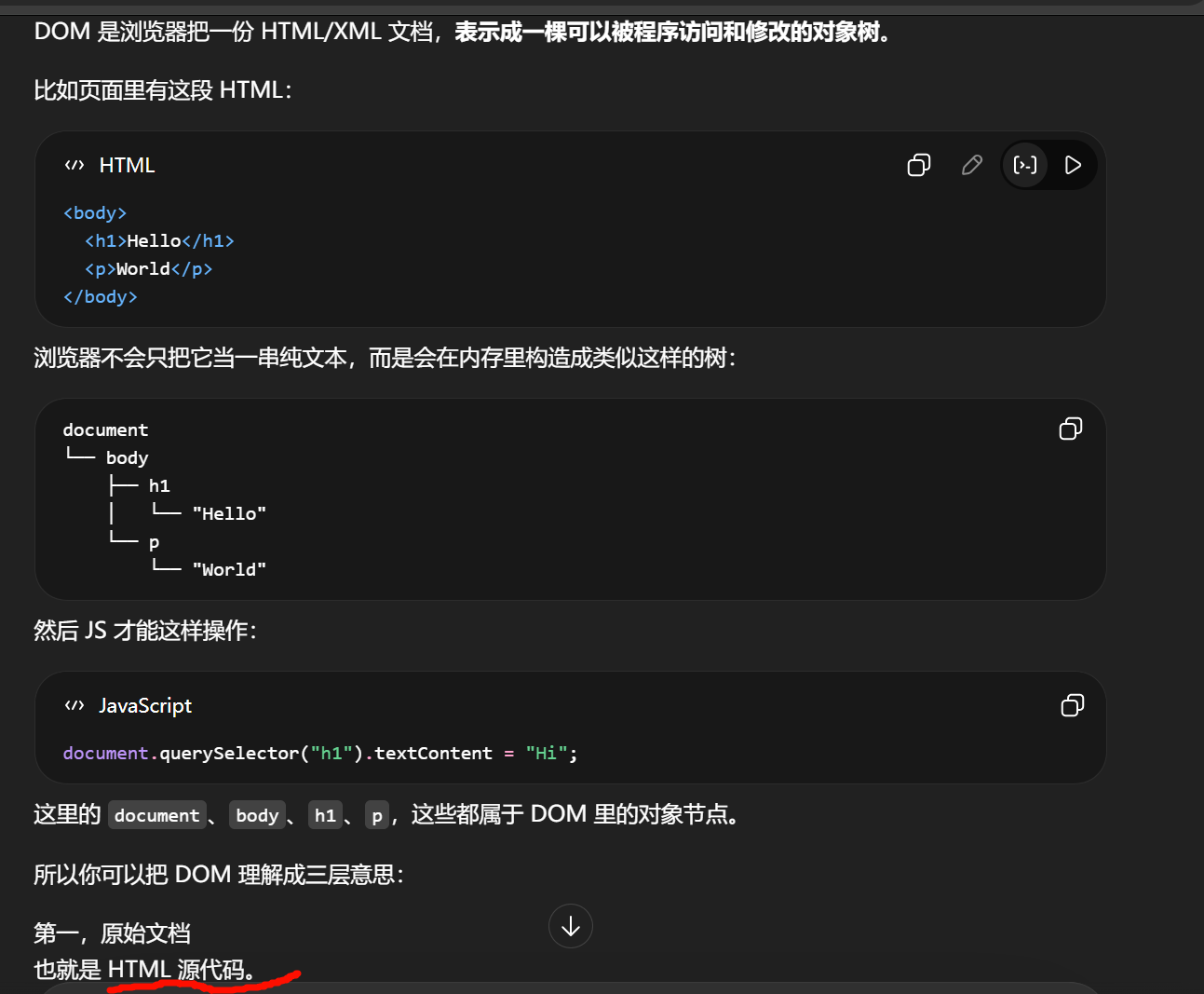
为什么"读取系统剪贴板图片"会把你往 offscreen 推。
官方 Offscreen 博客专门举过类似方向:一些原来在后台页能做、但在 service worker 里因为没有 DOM 或相关环境而做不了的事情,需要转给 offscreen document;文中还直接拿 Clipboard API 做过示意,甚至明确说"等将来 service worker 能直接用 Clipboard API,再替换掉 offscreen 方案"。这说明在官方视角里,剪贴板相关能力就是 offscreen 的典型使用场景之一。
申请 offscreen 是因为那版方案把"读剪贴板图片 + 处理图片数据"放在 MV3 后台协作流程里做,offscreen document 是最顺的官方文档上下文承载方式。
const img = new Image();
img.src = URL.createObjectURL(file);
img.onload = () => {
console.log(img.width, img.height);
};
这套思路天然就是"页面里读一个文件,造一个图片对象,等它加载后拿宽高"。
FileReader 也一样,虽然它不一定非得和 DOM 树绑定,但它就是典型 Web 文档环境里常见的文件读取对象。
URL.createObjectURL() 也是在这种浏览器对象环境里最自然。
图片读取、解码、中转、取尺寸、转 dataURL/Blob URL 这类操作,本来就更符合页面对象模型。
service worker 更适合
判断当前 tab,调度哪个页面/上下文去干活
background.js
确保 offscreen 页面存在,发消息让 offscreen 去读图,把结果发给目标 tab
offscreen.html + offscreen.js
把图片变成 File/Blob,必要时创建 Image,生成轻量指纹或 dataURL,把结果回传给 background
针对网页必须打开 Chrome DevTools(开发者工具)才能正常加载或接受数据的情况,这通常是网站设置了防爬虫机制、调试检测(Anti-debugging)或特定的日志输出需求。开发者可能在代码中加入了检测DevTools打开状态的JavaScript,若检测到未打开,则会暂停功能或不返回数据。
-
chrome.commands仍然只注册一个普通的Alt+V -
在
background.js里自己做"双击时间窗判定"
现在这个 toast,本质上是在操纵:
-
DOM 节点
-
CSS 样式
-
浏览器提供的动画属性
-
浏览器排版和合成系统
也就是说,你不是在"自己画",而是在"命令浏览器替你画"。
比如图像是 8000×4000,但你的显示器只有 1920×1080。
如果 imshow 直接按原始大小开窗口,窗口内容就会超过屏幕边界,导致:
-
窗口标题栏或边框跑到屏幕外
-
你看不到整张图
-
某些系统下窗口初始位置不理想,看起来像"没弹出来"或"卡住"
-
你以为程序有问题,其实只是窗口太大了
这里的 cv.line(...) 不是"创建了一个叫 line 的新图像",而是:在已有的 blank 这张图上直接把线画上去
- 当你按
Alt作为快捷键前缀时 - 浏览器 UI 很可能先抢到焦点
- 比如菜单、地址栏、扩展栏、右上角按钮高亮
- 导致页面文档不再是 focused document
于是 navigator.clipboard.read() 就失败。
这不是偶发兼容问题,而是当前路线的结构性缺陷
只要你继续走:
- "命令触发后,在当前页面里读 clipboard"
那这个焦点问题就会反复出现,特别是带 Alt 的快捷键最容易触发。
也就是说:
- 你之前改成"不用
offscreen,改成当前活动页读取" - 虽然解决了 offscreen 的焦点文档问题
- 但它把问题转移成了"页面焦点被浏览器 UI 抢走"
所以这个方案对图片读取并不稳。
Contour(輪廓/修容)通常指透過霧面陰影產品來塑造臉部立體感、製造陰影的化妝技術,能讓顴骨、下顎線看起來更緊緻、精緻。其重點在於使用接近真實陰影的冷色調,而非暖色調的 bronzer(古銅粉)。正確的修容需從髮際線開始、向上暈染,避免拖低臉部重心。
findContours() 在干什么
它会扫描图像里的白色前景区域或边缘区域,把相连的边界点"串起来",形成一条条轮廓。
Python 的多返回值解包。
C/C++/Java 里,return 后面通常就是"返回一个对象/一个值"。
很多语言都支持"复合返回值",不需要靠引用或指针。
例如 C++:
C++
#include <tuple>
using namespace std;
tuple<int, int> f() {
return {1, 2};
}
auto a, b = f();
这里不是引用参数改值,而是正经返回一个 tuple。
C++ 还可以返回 pair 或自定义 struct:
C++
struct Result {
int x;
int y;
};
Result f() {
return {1, 2};
}
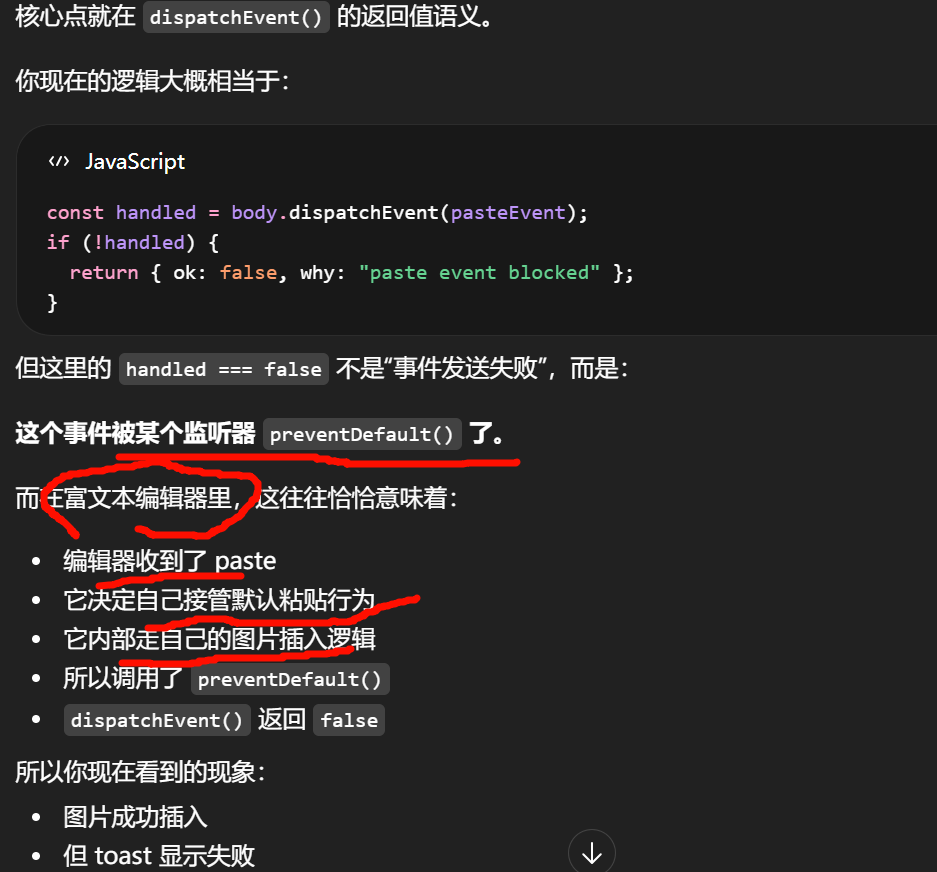
你往编辑器里粘贴图片时,大致发生的是:
-
目标元素收到一个
paste事件 -
事件对象里带着剪贴板数据,比如文本、HTML、图片文件
-
页面上的编辑器代码也在监听这个
paste -
编辑器读取
clipboardData -
编辑器调用
event.preventDefault() -
编辑器按自己的规则把内容插进去
关键点就在第 5 步。
preventDefault() 的意思不是"拒绝这次粘贴",而是:取消浏览器默认的粘贴实现,改由我这个编辑器自己处理。
不让自己上图,服务器要自己按自己的规则存图,文本可以是因为文本分散
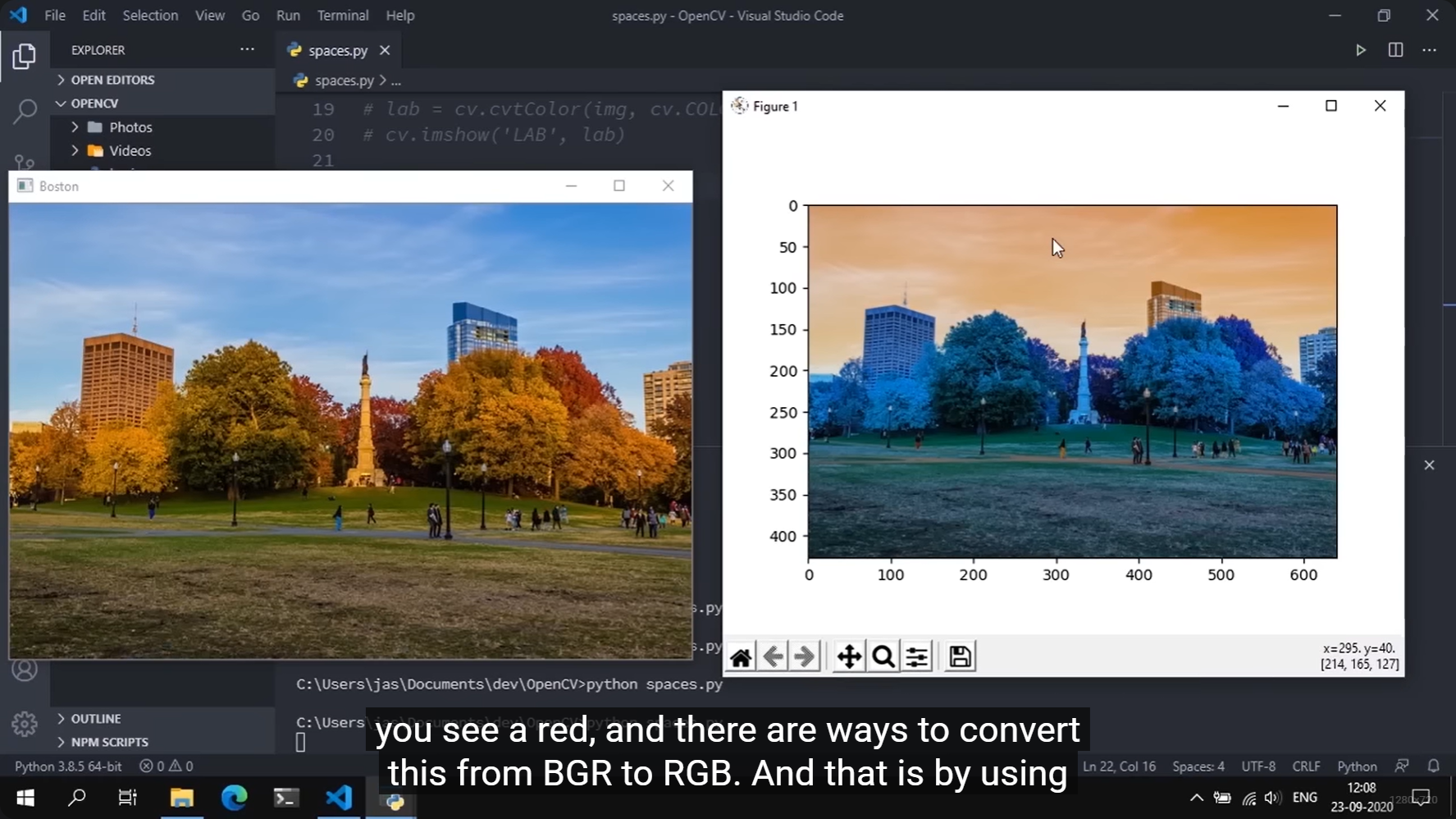
OpenCV 的历史和底层实现习惯决定了它长期默认用 BGR。
这不是视觉学上的"更标准",只是 OpenCV/老图像库传统。
- 但如果你把这个数组直接拿给别的默认认为是 RGB 的库,就会颜色错乱
最经典的例子就是 Matplotlib。
修 浏览器对样式初值与动画起点的采样时机。
浏览器没有稳定地看到"这个条先是满的,再变成 0"这个过程。
不显式写:
transform: "scaleX(1)"
依赖"默认状态",那浏览器拿到的可能只是:
-
当前 style 没有 transform
-
之后你又立刻改成
scaleX(0)
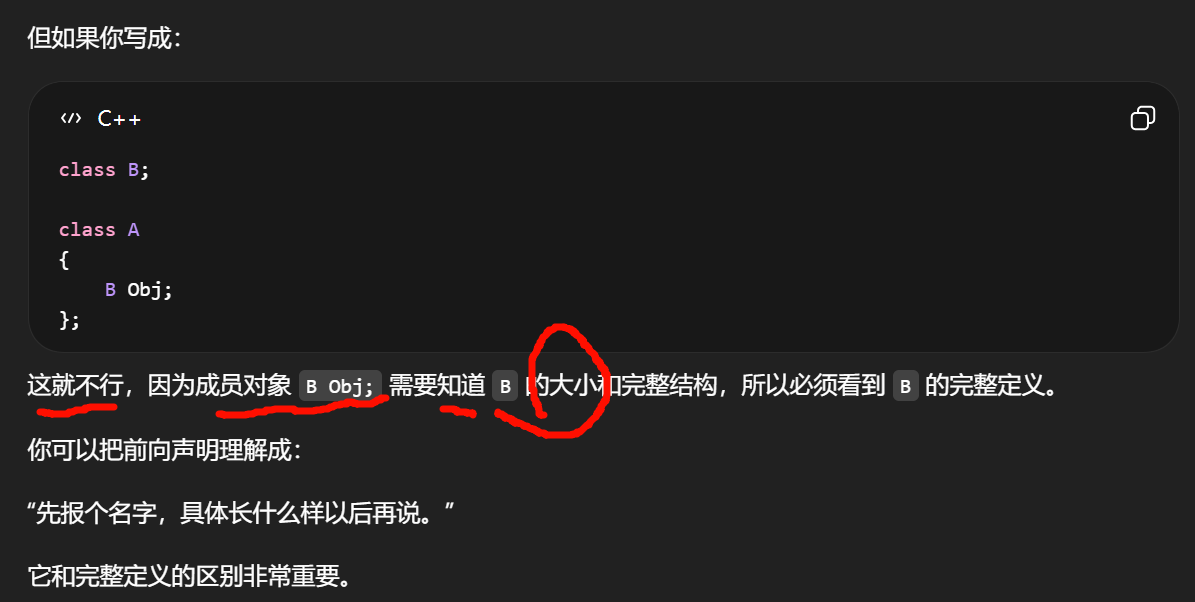
编译器在编译阶段 就要把"对象将来怎么析构"这件事确定下来,而 unique_ptr 的析构逻辑里,最终会走到 delete,而 delete 一个对象时,编译器必须知道这个类型的完整定义
编译器在生成析构相关代码时,就已经发现自己没法合法生成了。
不是编译器"主动调用析构函数"
-
局部对象离开作用域
-
类成员随着外部对象析构
-
程序结束时静态对象析构
-
unique_ptr自己析构时释放所管理对象 -
对象的成员也会依次析构
恰恰相反,在现代 C++ 里,通常优先直接写对象本身,而不是一上来就
new。栈(Stack)和堆(Heap)在硬件内存中的大小管理差异巨大。栈通常是连续的、大小固定的,在 Windows 下为 1-2MB,Linux 下为 10MB 左右;而堆是不连续的、通过链表管理,大小受限于虚拟内存,理论上可达 GB 级别,空间远大于栈。
日常编程中,你创建的变量要么在栈 上(局部变量),要么在堆上(动态生成的复杂数据),其他区域通常由编译器和系统在底层自动打理,开发者参与感较低。
此外,在不同的编程语言环境中,名称可能略有差异。例如 Java 会提到方法区 (Method Area)来存放类信息和常量;JavaScript 则会有常量池的概念。
-
全局/静态存储区 (Data Segment / BSS Segment) :
- 存什么 :全局变量和静态变量(
static)。 - 特点:程序启动时分配,程序结束时才释放。
- 存什么 :全局变量和静态变量(
-
常量区 (Text/ROData Segment) :
- 存什么:字符串常量、数字常量等不可更改的数据。
- 特点:通常是只读的,防止程序意外修改基础数据。
-
代码区 (Code/Text Segment) :
- 存什么:编译后的机器指令(二进制代码)。
- 特点:只读,确保你运行的指令不会被自己改掉。
error C4150: deletion of pointer to incomplete type 'AFaceTrackerActor::FOpenCVState'; no destructor called
只看到了前向声明,看不到 FOpenCVState 的完整定义
Program Database
也就是 调试符号文件。
编译产物 = DLL
调试地图 = PDB
PDB 是"让编辑器/调试器知道这个 DLL 里面每段机器码对应哪段源码"
前向声明:
C++
struct T;
完整定义:
C++
struct T
{
int X;
void Foo();
};
只有第二种,编译器才真正知道 T 是什么。
.h 里改宏环境,相当于把这个影响扩散到更大范围。
.cpp 的好处是:
更符合"谁引入第三方库,谁处理兼容问题"的原则
自己范围内"的 .h,不是按"文件夹看起来像不像自己人"来算,也不是由编译器凭空猜。
判断标准本质上是:
当前 .cpp 所在模块,能不能通过 UBT 配置合法地看到这个 .h。
不是"build tool 选择哪个 .h",而是 "UBT 决定当前翻译单元的 include 搜索路径、模块依赖和可见性边界"。
编译器真正做的事只是:
在 UBT 给它准备好的 include path 里找文件,然后编译。
同一个 Module 里的头文件
这是最典型的"自己范围内"。
比如你的模块是 ZMDrender,那:
-
Source/ZMDrender/Public/... -
Source/ZMDrender/Private/...
这两个目录里的头,原则上都属于这个模块自己的头。
但还要再细分:
-
Private:只给本模块内部.cpp用 -
Public:给外部模块也能 include
第二层:依赖模块暴露给你的头文件
如果你在 ZMDrender.Build.cs 里写了:
C#
PublicDependencyModuleNames.AddRange(new string\[\] { "Core", "CoreUObject", "Engine" });
那就表示:
这些模块对你是依赖模块,它们的 Public 头文件会被暴露给你。
于是你当前模块就能 include 它们的公开头。
比如:
C++
#include "Engine/World.h"
#include "GameFramework/Actor.h"
能不能用,不是因为这些文件"在磁盘上存在",而是因为:
UBT 已经把 Engine 模块的 Public include 路径加进当前模块的编译环境了。
所以这里"自己范围内"的第二层可以理解成:
"当前模块依赖链上,对我公开可见的 Public 头文件集合"。
第三层:第三方库头文件
像 OpenCV 这种,通常不属于 UE Module 的普通源码头。
它们的可见范围不是靠 Public/Private 文件夹约定,而是靠 Build.cs 里显式加路径:
C#
PublicIncludePaths.Add(Path.Combine(OpenCVPath, "include"));
或者更现代一点,通过第三方 module 包装。
这时"自己范围内"其实就变成:
UBT 是否把这个第三方 include 目录加入了当前模块的编译命令。
如果加了,那当前模块编译时就"看得见";
没加,就不在范围内。
所以第三方 .h 的"范围",不是按文件物理位置,而是按 Build.cs 配置是否把它暴露进来。
第四层:预处理器根本不管"范围归属"
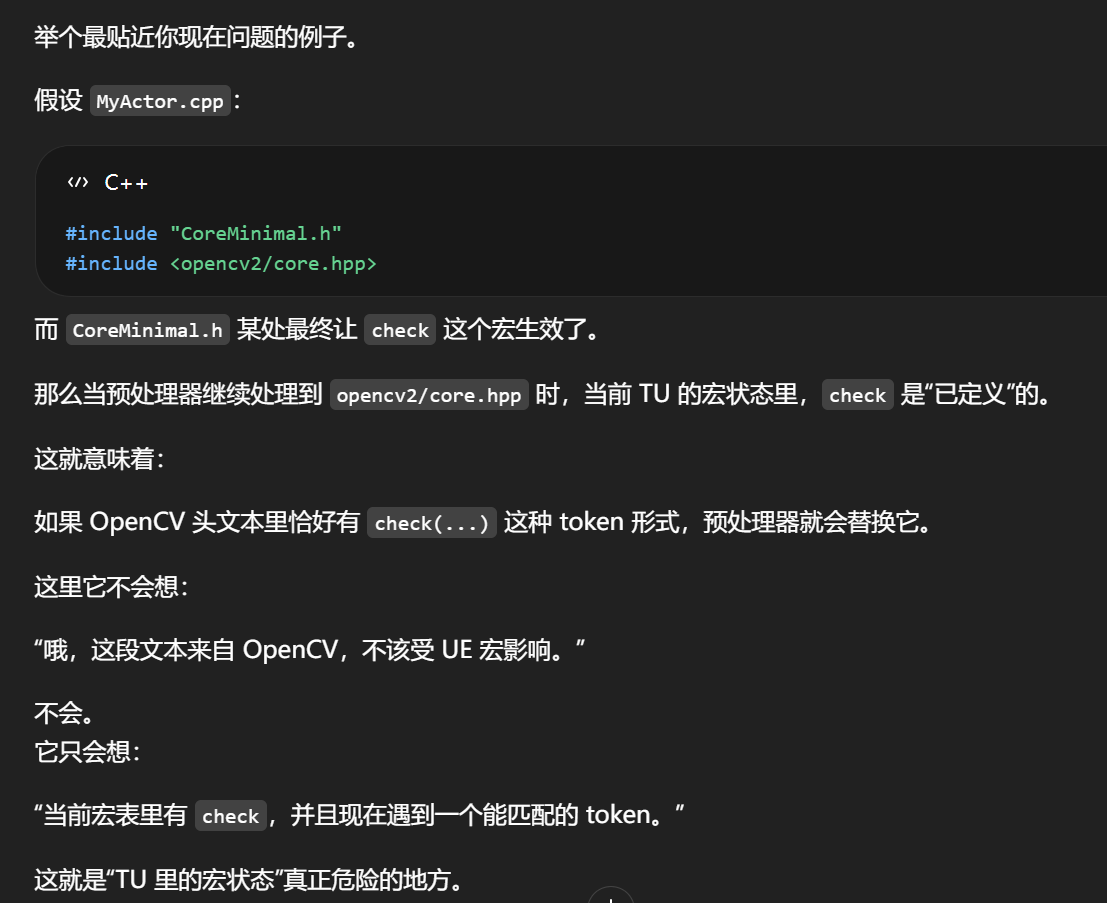
这点和你上一张图里的 check 宏冲突直接相关。
对于宏来说,它根本不关心某个 .h 是不是"自己范围内"。
它只看:
当前翻译单元在预处理展开后,这个宏定义是否已经生效。
例如:
C++
#define check(expr) ...
只要这个宏在某个先前 include 里已经进来了,那么后面哪怕你写的是 OpenCV 的头:
C++
some_header_from_opencv.h
只要里面出现匹配 token 形式的 check(...),预处理器就会替换。
对某个头文件 X.h,你可以问四个问题:
-
它属于当前模块吗?
如果是
Source/当前模块/Public|Private/...,通常算自己模块范围内。 -
它属于依赖模块的 Public 吗?
如果是,并且该模块在
Build.cs依赖里,算当前模块可见范围内。 -
它属于第三方 include 目录吗?
如果
Build.cs显式把这个目录加入 include path,那也算当前编译单元可见范围内。
前三个回答的是:
"这个头文件在构建系统/模块系统看来,是否对你可见、可引用?"
第四个回答的是:
"这个头文件的文本,是否已经真的被拼进当前这个翻译单元里,从而受到当前预处理状态影响?"
更严格地说:
前三个属于"可达性 / 合法性 / 可见性"
第四个属于"实际进入 TU 的事实状态"
这里的 TU 就是当前 .cpp 经过所有 #include 展开后的那个大文本。
第四个:预处理/当前 TU 层
第四个问的是:
无论它原来属于谁,它现在是否已经被 #include 进当前 .cpp 对应的翻译单元了?
只要答案是"是",它就会吃到当前 TU 里的宏状态。
.cpp 文件并不是直接单独送去编译器做 C++ 语法分析的。
Translation Unit (编译单元 / 翻译单元)。
宏的生命周期只存在于它所在的那个 TU 内部。你在 A 文件(TU-A)中定义的宏,在 B 文件(TU-B)中是不可见的,除非你通过头文件将它包含进 B 文件的 TU 里。
预处理器会扫描 TU 里的源代码,发现宏名就将其替换为对应的代码片段。最终交给编译器的是一个"平铺"好的、完全没有宏定义的巨大纯代码流,这个整体就是完成后的 TU。
多个头文件在同一个 TU 里面定义了同名的宏,就会导致编译警告或错误,这是开发者处理 TU 时最头疼的问题之一。
 1 个 TU=1 个.cpp文件+所有被 #include的头文件-所有被跳过的条件编译代码
1 个 TU=1 个.cpp文件+所有被 #include的头文件-所有被跳过的条件编译代码
编译器每次只吃掉这一个 TU,并把它转换成一个 .obj 或 .o 目标文件。
- 两个头文件里定义了同名的宏,且这两个头文件都被包含进了同一个 TU,编译器就会在处理这个 TU 时报错。
在 main.cpp 里 #define LIMIT 100 ,这个宏只在这个 TU 里有效。
另一个 tool.cpp 形成的 TU 完全不知道 LIMIT 是什么
有些大型项目为了加快速度,
会搞"Unity Build":新建一个 all.cpp ,里面写满 #include "a.cpp" , #include "b.cpp" 。
在这种情况下,多个 .cpp 文件被强行合并成了一个 TU。
一些试图"像语言扩展一样"改变代码写法的宏。