【这一节的知识点在base spec的 2.2.6 transaction descriptor 小节】
这一节的内容如其名,主要描述的是TLP传输相关的特性,好了这篇博客主要以ARM系统为例要论的是no snoop这个概念。以及PCIe在集成接口层面No snoop(域段)的使用。
转载:(13 封私信 / 81 条消息) PCIe协议学习-PCIe的No Snoop Attr使用讨论 - 知乎
下图为ARM Neoverse N2 架构的LTI mode的I/O virtualization block:
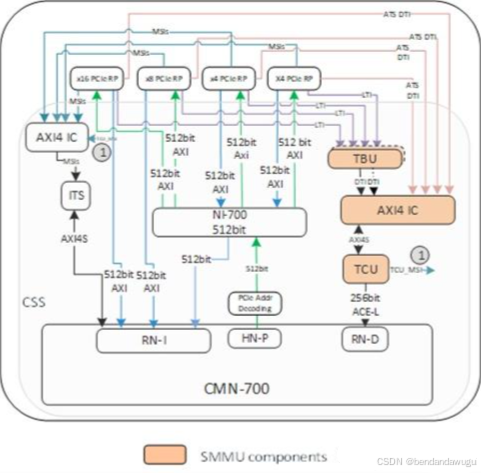
PCIe RP 通过AXI 接口与CMN总线的RN-I和HN-P节点相连,CMN总线内部各个节点通过CHI transcations进行亲求的接收和转发。
No snoop基本定义:
首先在TLP header中attr的layout如下所示:

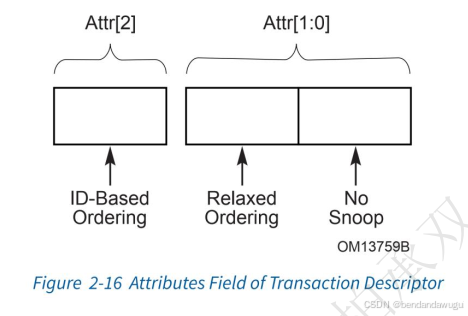
PCIe协议中对NS attribute的定义如下图中所示:
NS=0,说明硬件需要维护对应TLP操作(也可以理解为TLP请求对应的地址空间)的cache coherency;
NS=1,说明硬件不需要维护对应TLP操作的cache coherency;
axi的memory domain:
AXI5 协议协议中,将地址/内存空间的domain分为三种:system/Non-shareable/shareable,地址的domain属性通过Axdomain信号携带。
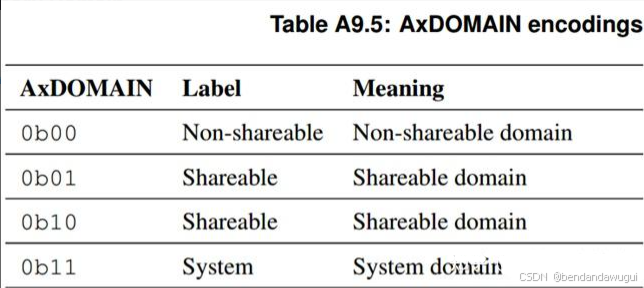
以前的版本中,2'b01表示Inner shareable domain,2'b10表示outer shareable domain,最新版本的AXI 已经不做这种区分了。
system domain:
system domain的地址空间对所有可以访问他们的managers可见,所有managers在访问对应地址空间时需要使用non-cacheable操作,并且本地不能保存对应地址的cache,这种方式可以比较简单的保证对应地址空间在所有managers中的coherency,但是访问性能较差(没有本地cache,路径长,终点访问也可能拥塞)。
device type memory必须使用system domain。
non-shareable domain:
non-shareable domain地址空间只对单个manager可见,对其他manager都不可见,non-shareable地址可以保存在本地cache中,对应的manager在访问non-shareable地址空间时也不需要触发hardware coherency mechanism 来保证coherency。
如果其他manager想要获取non-shareable data,则先需要使用cache maintenance operation(CMOs)将数据更新到内存中,并清除本地cache,这种方式也被称为software coherency,软件维护一致性的方式容易出错且难以定位,从具体应用上看,Non-shareable domain一般对应只有software(PE/processing elements)访问的地址空间。
shareable domain:
shareable domain地址空间对所有可以访问他们的manager可见,mannagers可以在本地cache中保存对应地址空间,在访问shareable domain时必须进行snoop操作,查找所有managers 中的cache。
AXI 的memory attribute:
AXI的memory attributes通过AxCACHE指示,系统中的组件基于请求的cache属性进行不同操作。
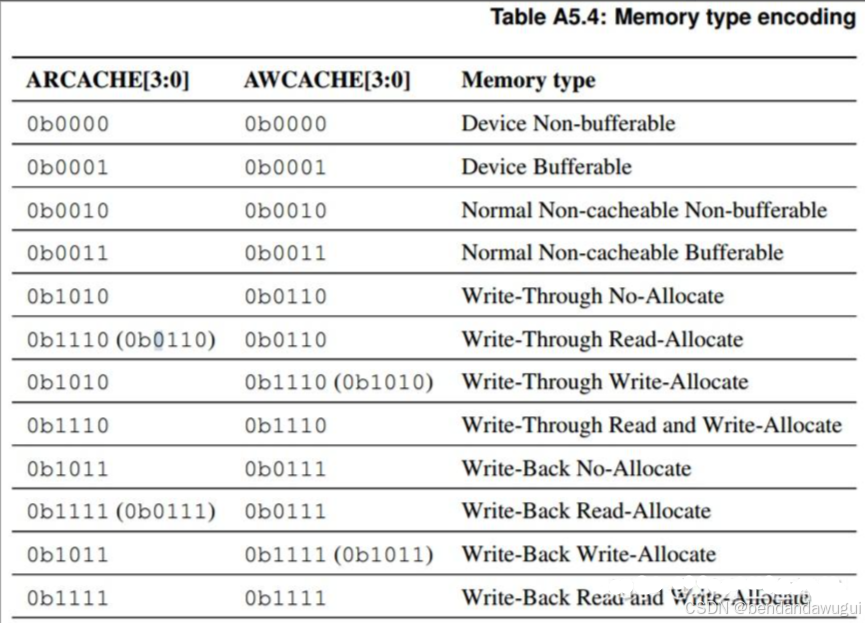
AWCACHE编码如下:
• 0 Bufferable
• 1 Modifiable
• 2 Other Allocate
• 3 Allocate
ARCACHE编码如下:
• 0 Bufferable
• 1 Modifiable
• 2 Allocate
• 3 Other Allocate
Bufferable, AxCACHE0
对于写操作:
如果bufferable=0,写response说明写数据已经到达final destination;
如果bufferable=1,写response可以由intermediate point生成并返回(只要能保证一致性)。
对于modifiable(ARCACHE1=1)和non-cacheable(ARCACHE3:2=0)的读操作:
如果bufferable=0,读数据必须从final destination返回;
如果bufferable=1,读数据可以从final destination或从正在往final destination发送的相同地址的写请求中获取。
对于ARCACHE3:1的组合,bufferable bit没有作用。
Modifiable, AxCACHE1
Modifiable表示transaction characteristics可以被修改(modified)。
对于non-modifiable transactions(AxCACHE1=0),transactions在system处理中不能被拆分(split)或合并(merged),以下参数也不能被修改:
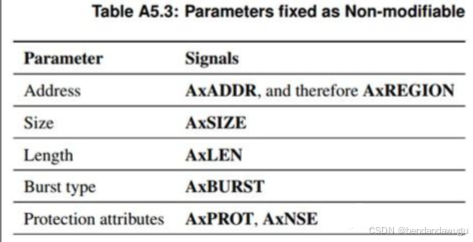
可以被修改的参数为AxCACHE0(bufferable),transaction ID和QoS。
AXI协议定义的最大transaction burst length为16,因此,在downsizing to a narrower data width时,可能存在必须将transaction进行拆分的情况。此时协议允许对请求进行相应modified,但建议通过一种implementation defined的机制指示请求已经被modified过。
Modified属性的transactions,可以基于需要进行拆分或者合并,以下参数也可以进行相应修改:

AxCACHE,transaction ID和QoS也可以修改,但是AxLOCK和安全相关属性(AxPROT和AxNSE)不能修改。
对transaction的修改必须保证不引起数据一致性问题,并且不跨4KB地址边界。
Allocate and Other Allocate, AxCACHE2, and AxCACHE3
如果Allocate=1,表示data(对应地址)可能被allocated过,可以先在cache中查找,同时建议将data也allocated到cache中(不是必须的),因为短期内可能会再访问这个data;
如果other allocate=1,表示data可能被allocated过,可以先在cache中查找,同时不建议将data allocated到cache中(不是必须的),因为短期内不会再使用这个data;
如果allocate和other allocate同时为0,表示不需要在cache中查找这个data(地址)。
Memory Types
不同AxCACHE组合对应的AXI memory types如下图所示:
CHI的Memory Attributes:
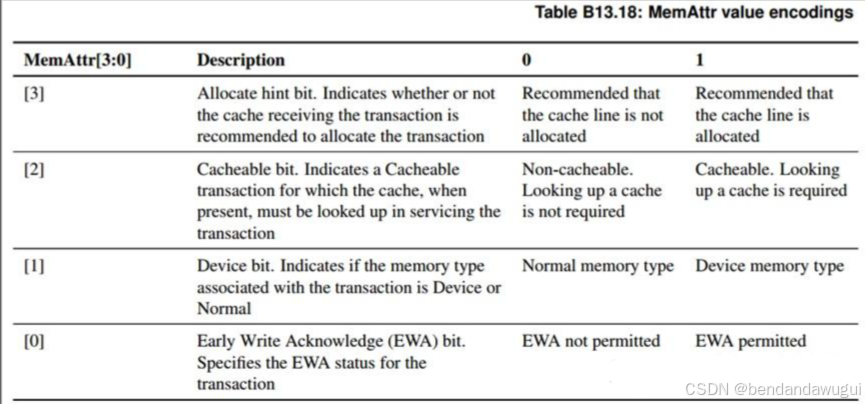
CHI的Memory Attributes分别指示Early Write Acknowledgment (EWA), Device, Cacheable和Allocate,如下图所示:
EWA
EWA表示Early Write Acknowledgment (EWA):
EWA为1,表示write completion response可以来自一个intermediate point,比如Home Node;EWA为0,表示write completion response必须来自final destination。
可以看到EWA基本和AXI的bufferable(AxCACHE0)对应。
Device
Device指示memory type为device或memory,区别在于对device memory type的地址空间访问存在side-effects,因此只能使用某些特定的CHI transactions(不在本文讨论范围内),并且transaction处理存在以下约束:
1) read transaction不能读取超过请求范围的地址数据;
2) 不允许对请求地址空间做prefetching;
3) 读请求必须从final destination(endpoint)中获取数据;
4) 不能将多个请求进行合并;
5) 写请求如果从intermediate point返回completion,必须保证在一定时间内(implementation specific)将数据更新到endpoint中。
所谓side-effects,可以简单理解为第n次和第n+1次的访问结果会不同,比如,对应地址空间为read clear寄存器,或者为一个FIFO。
Cacheable
Cacheable=1,表示数据可能在cache中,应该进行cache lookup;
Cacheable=0,表示不需要进行cache lookup,transaction必须送到final destination中处理。
Allocate
Allocate=1,表示建议将请求地址的data allocate到cache中(但不是必须的)以提升后续访问性能;
Allocate=0,表示不建议将请求地址的data allocate到cache中(但也不是必须的)。
Memory Type
各memory attributes与ARM Memory type的对应关系如下:

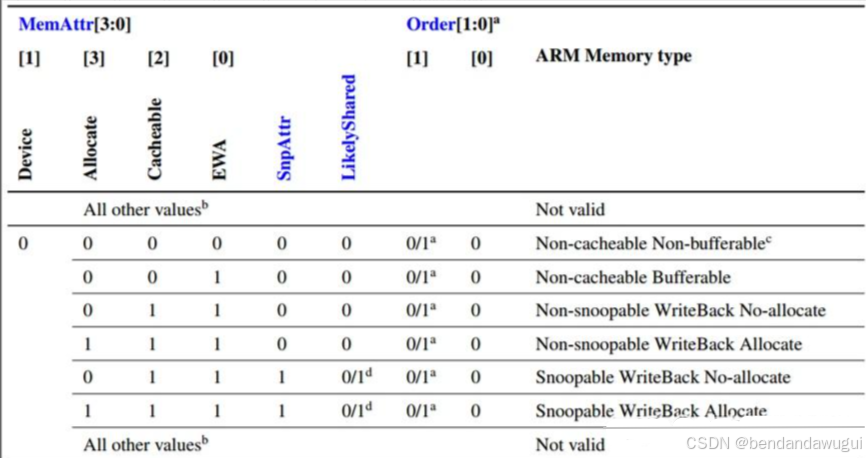

注意,在此之外的attributes组合都是不合法的。
所以,在ARM系统中,当PCIe请求的NS为1时,对应的AXI Domain应该为System,AXI Memory Attribute的allocate和other allocateAZ1 应该为0,CHI Memory Attribute的cacheable和allocate应该为0,表示对应data或地址空间不在cache中,也不需要进行snoop操作。
当PCIe请求的NS为0时,对应的AXI Domain应该为Shareable,AXI Memory Attribute可以Allocate或Other Allocate,CHI Memory Attributed Cacheable为1,表示data在cache中,需要进行snoop操作。AXI的Allocate或者Other Allocate和CHI的Allocate可以基于PCIe请求的TH域段。比如TH=1时,表示数据可能被频繁访问,应该allocated到cache中,此时可以用Allocate属性,反之则使用Other Allocate属性。
AZ1无论NS为多少,AXI的Memory Attribute的bufferable和modifiable都可以固定使能,这可以优化总线上的transaction处理,提升性能。