从"猜"到"看":Agent 可观测性的挑战与新范式
在 Agent 应用迅速发展的今天,开发者们常常陷入一个熟悉的困境:面对一个看似简单的用户指令,AI Agent 背后可能经历了复杂的推理、多轮工具调用和动态任务规划。当结果不符合预期时------无论是答非所问、执行失败,还是长时间的静默------我们往往只能面对一个黑盒。
一个用户请求,可能经历:
vbscript
Message → Session → Queue → Agent → LLM → Tool → Memory → Response传统的监控手段,如分散的日志和基础的系统指标,在 Agent 这种非确定性、长链路的场景下显得力不从心。排查问题变成了一场"猜谜游戏":
- 是模型理解错了意图,还是 Prompt 的约束过于严苛?
- 是工具调用失败,还是它返回了非预期的结果?
- 是上下文窗口被截断,丢失了关键信息,还是任务在某个不为人知的角落悄然"卡住"?
这种低效的、依赖直觉的排障模式,不仅拖慢了迭代速度,更让服务的稳定性成为悬在头顶的达摩克利斯之剑。我们意识到,Agent 时代需要一套全新的可观测性范式------它必须能够将 Agent 的"思维链"清晰、完整地还原出来,让每一次交互都有迹可循。
ArkClaw 的答案:SLI 度量先行,数据驱动的全链路可观测
面对挑战,ArkClaw 团队没有选择在传统日志上修修补补,而是提出了一套更具前瞻性的解决方案:以服务等级指标(SLI)度量为牵引,构建一套从端点采集、链路追踪到数据治理的闭环可观测体系。 我们相信,只有先定义出衡量"好"与"坏"的标尺,后续的观测与优化才有意义。
这套体系的核心理念是将原本混乱、离散的 Agent 行为,转化为结构化、可分析的数据资产。其整体架构如下:
1. SLI 指标设计 (SLI Design): 基于统一的数据语义,我们需要定义出一组真正能够反映服务质量的核心 SLI 指标。例如,对话成功率、端到端响应延迟(P95)、Agent 执行成功率等。这些指标不再是模糊的"体感",而是可以量化、可以承诺、可以告警的业务语言。
2. 深入运行时的采集 (Collection): 通过深度集成 OpenClaw 的 apmplus-openclaw-plugin,我们不再满足于表面的日志抓取,而是深入 Agent 的运行时,通过 Hook 机制在会话开始、模型推理、工具调用、任务分派等关键生命周期节点进行精准的信号采集。这保证了数据的完整性与实时性,从源头抓住了最真实的执行现场。
3. 标准化与转换 (Processing): 采集到的原始信号通过 o11yagent 的处理流水线(Pipeline)进行标准化。在这里,非结构化的日志被智能解析,转化为结构化的 Metrics(指标) 、Traces(调用链) 和 Logs(日志) (MTL) 三位一体的数据。尤其是将离散事件关联成完整的 Trace,是化"黑盒"为"白盒"的关键一步。
4. 观测、诊断与治理 (Observability & Governance): 在 APMPlus 平台上,我们为开发者和业务团队提供了多维度的观测能力。从宏观的 SLI 稳定性大盘 ,到微观的 Trace 根因诊断 ,再到主动的智能告警 ,最终形成以数据驱动优化的治理闭环。开发者可以清晰地看到从业务指标到代码执行的每一处细节,让优化决策有据可依。
通过这套体系,ArkClaw 成功地将 Agent 的行为从不可捉摸的"艺术",转变为可以度量、可以分析、可以优化的"工程科学"。
全链路 SLI 体系:从指标设计到根因定位
1. 为什么传统 SLI 不适用于 Agent
传统系统:请求 → 返回
SLI:
- success rate
- latency
Agent 系统:
请求
→ 多步推理(LLM)
→ 多次 tool 调用
→ 状态更新
→ 最终响应挑战:
-
一次请求 ≠ 一次执行,而是一个"多步骤决策过程"。
-
"成功返回" ≠ "任务成功",例如:用户问"帮我订明天机票",用户问"帮我订明天机票",技术上是成功,用户体验是失败。
-
"LLM成功" ≠ "Agent成功",Agent 需要模型做正确决策,而不仅仅是返回了响应(无报错)
-
"Tool成功" ≠ "结果正确",例如:调用查询天气 API(成功),但城市参数错误 → 用户结果错误
因此,传统单一维度的 SLI(success / latency)在Agent系统中失效,无法描述真实系统状态。必须升级为,多层 + 可归因 + 面向任务的 SLI 体系。
2. ArkClaw 的 SLI 设计原则
我们总结出 4 条核心原则:
原则 1:SLI 必须分层(Control / Execution / AI)
控制面(接入 / 路由 / session)
执行面(agent / workflow)
AI面(LLM / tool / memory)原则 2:SLI 必须围绕"用户结果"
不是:请求成功
而是:任务完成原则 3:SLI 必须可计算(避免模糊定义)
所有 SLI 都必须有明确分子/分母原则 4:SLI 必须可归因
失败必须能回答:
是 LLM?Tool?Queue?Session?3. ArkClaw 全链路 SLI 设计
我们将 Agent SLI拆成 6 层,包含 2 个北极星指标,8 个核心指标:
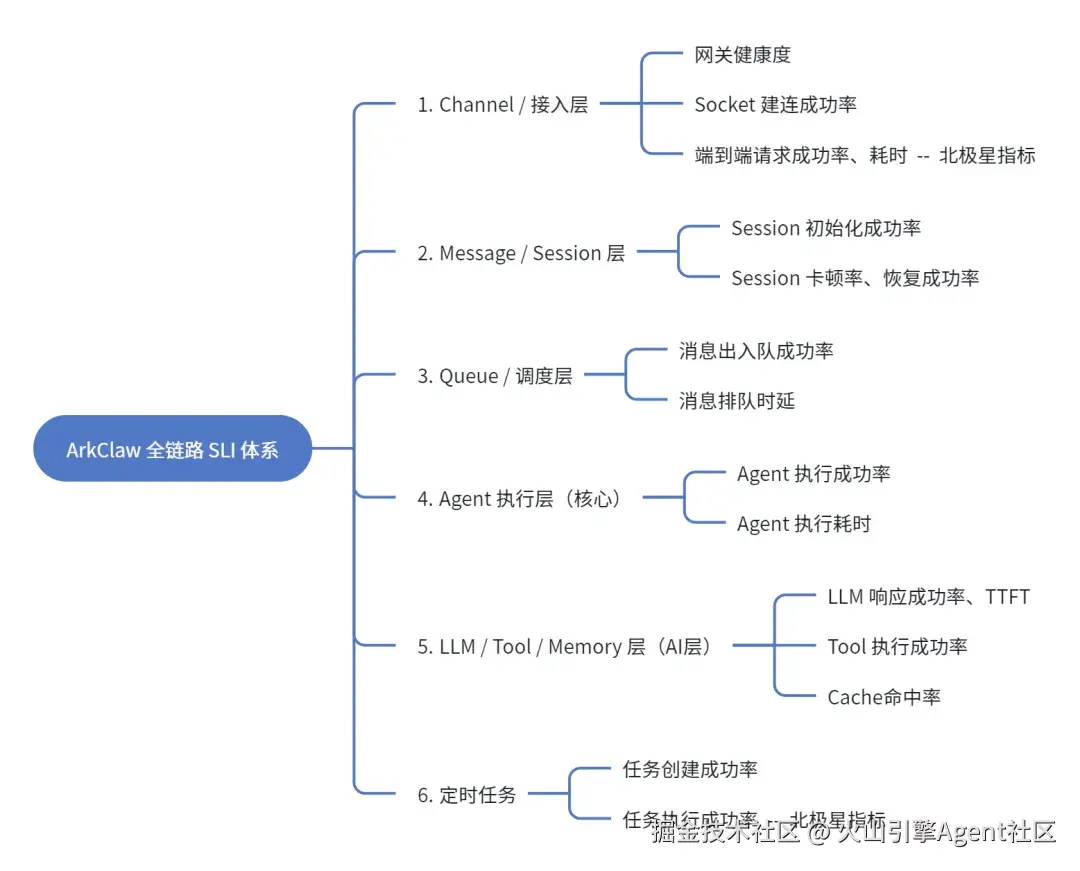
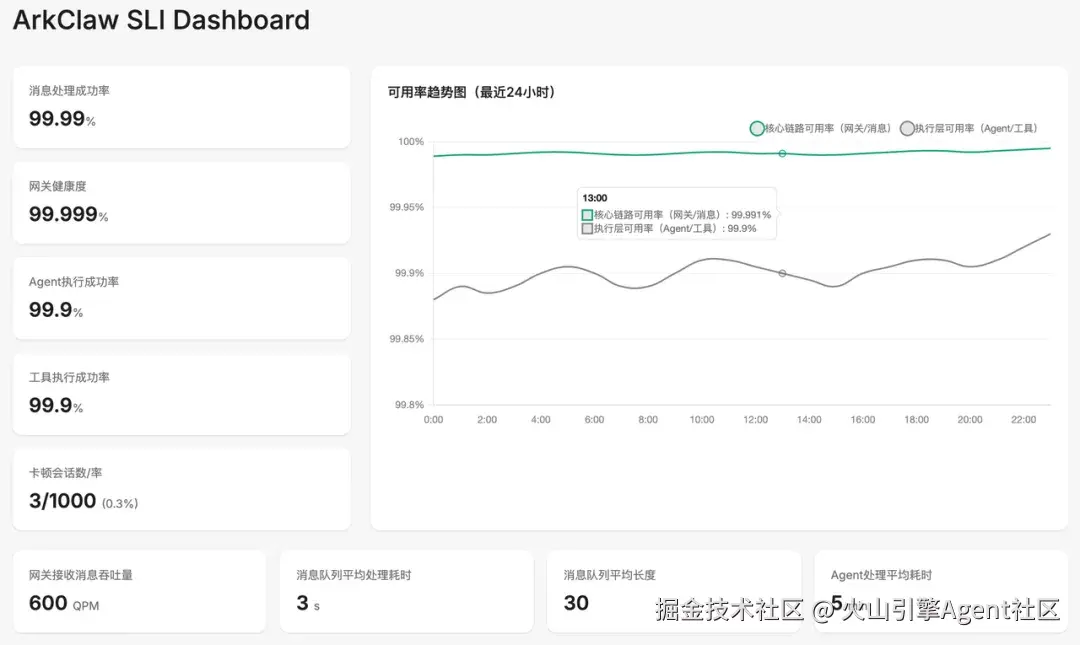
ArkClaw 进一步提供了开箱即用的 SLI 观测大盘(Dashboard) ,帮助开发者从"指标定义"走向"实时可视化与问题定位",详细请登录控制台查看,示例如下图:
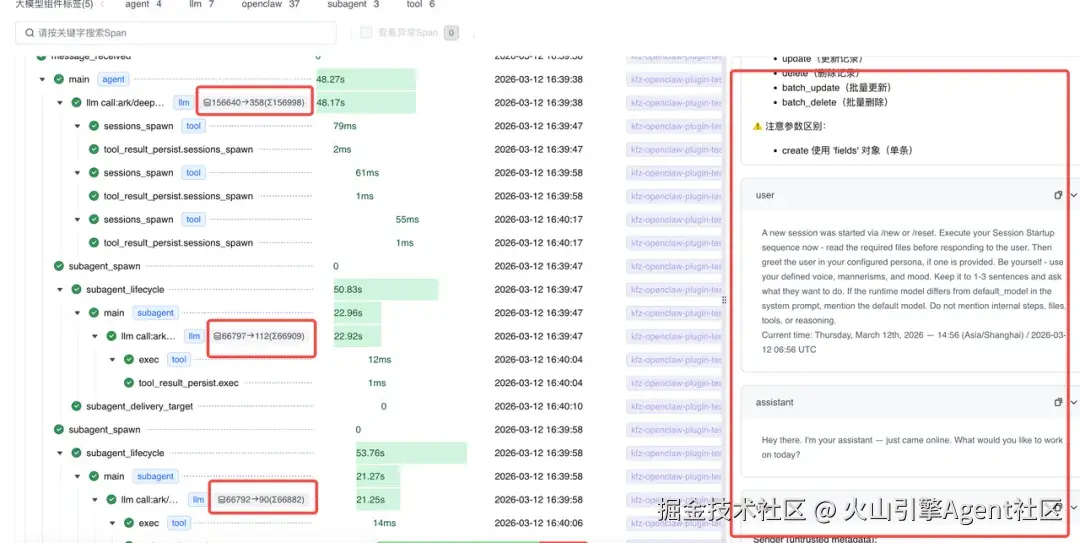
4. 从SLI 到 Tracing 根因定位
过去,分析排查SLI异动事件如同在迷雾中航行。现在,借助 apmplus-openclaw-plugin 带来的全链路追踪能力,每一次交互都被清晰地记录为一张"瀑布图",让问题无所遁形。提供如下能力:
-
支持多 Agent 协作追踪。能够清晰串联主、子 Agent 的协作链路,形成完整的调用拓扑,精准归因。
-
推理与工具调用细节还原。为推理过程和工具调用创建独立的 Span。对于推理过程:包含上下文窗口信息,和模型多步推理步骤的思考/响应/工具调用。对于工具:包含完整的入参、出参及异常信息。
-
数据采集信息完备。能捕获运行时内存中的关键信息,如完整的 System Prompt 和模型输入。
-
端到端的归因分析。支持从 SLI 指标一键下钻到 Trace 细节,再关联到原始 Log,实现无缝的根因定位。
这套体系将 SLI 事件排查的效率从小时级 (反复试验、猜测求证)提升至分钟级甚至秒级(查看 Trace、定位问题),极大地解放了开发者的生产力。
可观测数据采集处理:多源采集、统一语义与 SLI 派生
可观测数据采集还依赖一个核心组件:observability-agent(o11yagent) ,O11yAgent 是可观测团队提供的新一代可观测性数据 M.T.L.E 采集和处理管道,具有丰富的开源协议对接,主动采集,数据清洗及加工能力。
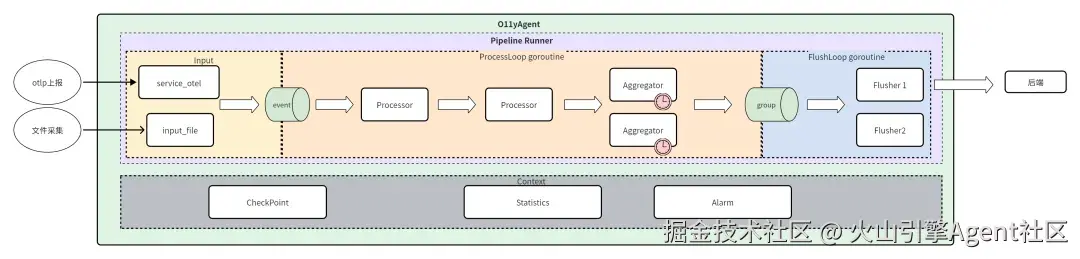
在 ArkClaw 场景,o11yagent 把来自 OpenClaw 运行时与宿主环境的信号,整理为可统一查询、可派生 SLI、可治理的数据资产。
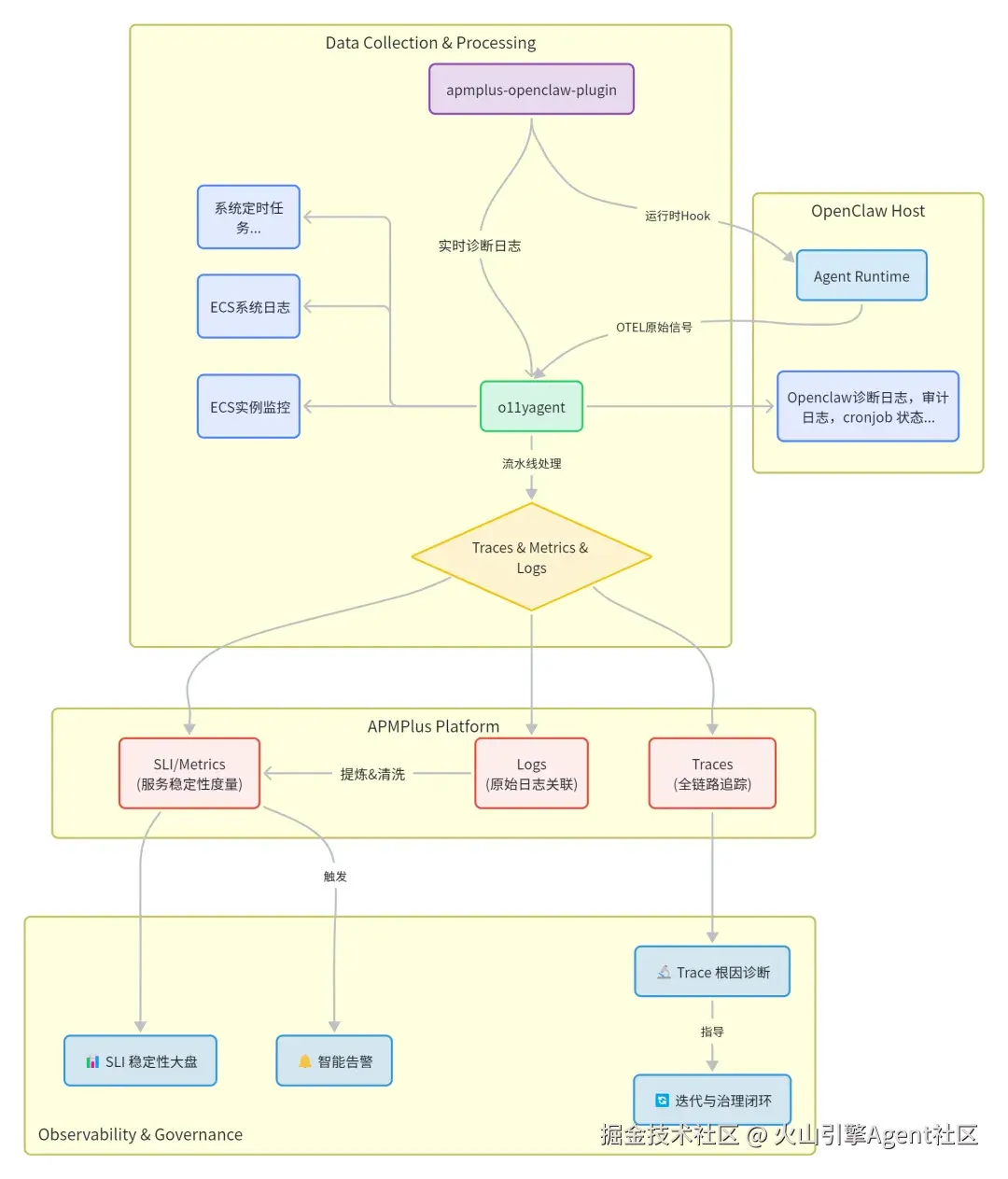
1. 采集数据入口
O11yAgent 在 ArkClaw 的常见数据入口可以归为 4 类:
- OTel 统一接入(Logs / Traces / Metrics): 通过 service_otel 在 4317与 4318 对外提供 OTLP 接入。
- 文件日志采集(结构化诊断日志为主): 典型是 /tmp/openclaw/**/*.log,通过 input_file 并做多层 JSON 解码后上报。
- 宿主机指标采集(主动采集): 将 CPU,Mem,Load,IO 等 ECS 带内监控上报,让用户更好地了解ECS 状态。
- 定时任务主动采集(主动采集): 将系统定时任务以及 Openclaw 定时任务数量和运行状态周期性采集上报。
2. 数据清洗与字段补充
在 ArkClaw 链路里,O11yAgent 的"清洗"不是单一环节,而是贯穿在 pipeline 各处的可配置治理动作:解析、补全、规范化、裁剪、校验,以及从 trace/log 派生指标。
结构化与字段抽取(让日志/事件变成可聚合维度)
- /tmp/openclaw/**/*.log 的采集链路会对 content、_meta、path 等字段做多层 JSON 解码,并把 logLevelName/filePath/fileLine 映射到标准的 OTLP 字段名。
元信息补充与语义归一(让不同来源数据可关联)
- processor_otel_resource_detector 与 processor_ecs_openclaw 在多数 pipeline 中作为通用处理链,负责把 service、environment、宿主与 OpenClaw 相关标签写入 resources,从而保证 log/trace/metric 在平台侧可通过同一套资源维度聚合与下钻。
3. SLI 指标清洗与派生
SLI 这一类指标既有来自 Apmplus 插件的原生上报,也有来自诊断日志的规则化抽取与聚合的补充。O11yAgent 的 logtometrics 插件支持在配置中显式声明聚合逻辑。
在 OpenClaw 配置文件 ~/.openclaw/openclaw.json 中,添加或修改 diagnostics.flag 模块,并重启网关 openclaw gateway restart 即可。
开启后,详细的诊断日志会以 JSON 格式输出到 /tmp/openclaw/openclaw-*.log 文件中。获取日志后,o11yagent 。该过程主要分为三步:
1. 字段提取 (Field Extraction): 流水线根据预设规则,从原始 JSON 日志的 content 字段中提取关键信息,如 run_id、duration_ms、outcome 等,并将其作为独立的结构化字段。
2. 聚合计算 (Aggregation): 在固定的时间窗口内(例如 60 秒),流水线对提取的字段进行聚合计算。例如,对 ArkClaw_sli_request_total 进行 count 计数,对 ArkClaw_sli_message_processed_duration_ms 计算 P95 分位值。
3. 指标上报 (Metrics Reporting): 最后,将计算好的 SLI 指标连同其维度(如 provider、model、outcome)一同上报至 APMPlus 等监控后端,用于仪表盘展示与告警。
以下是一个简化的流水线配置(YAML)片段,展示了其工作原理:
ruby
# ... processors 用于提取字段 ...
processors:
-Type:processor_log_field_extractor
SourceKey:"%{contents.content}"
Rules:
# 提取消息处理结果与耗时
-DestKey:processed_outcome
Left:" outcome="
Right:" duration="
flushers:
-Type:logtometrics
MetricsFlushIntervalInSec:60# 每 60 秒上报一次
MetricsAggregationCardinalityLimit:2000# 控制维度基数,防止指标爆炸
MetricsDefinitions:
# 定义"消息处理总耗时"P95 指标
-MetricName:ArkClaw_sli_message_processed_duration_ms_p95
Aggregation:pct95
ValueFrom:"%{contents.processed_duration_ms}"# 从提取的字段中获取值
Dimensions:
-Key:outcome# 按成功或失败等维度拆分
From:"%{contents.processed_outcome}"这套流水线不仅提供了宏观的 SLI 监控,更赋予了我们快速归因的能力。当监控大盘出现异常时,我们可以迅速定位问题环节:
场景一:队列堆积导致响应延迟
- 现象: ArkClaw_sli_message_processed_duration_ms_p95 指标持续升高,用户反馈响应变慢。
- 归因: 通过下钻发现,ArkClaw_sli_lane_wait_ms_p95(队列等待延迟)指标同步飙升,而 ArkClaw_sli_agent_run_duration_ms_p95(Agent 执行延迟)保持平稳。
- 结论: 问题出在消息队列环节,可能是因为瞬间请求量过大或消费能力不足导致消息积压。
场景二:LLM 端瓶颈导致 P95 升高
- 现象: ArkClaw_sli_agent_run_duration_ms_p95 指标升高,影响端到端延迟。
- 归因: 进一步查看 APMPlus 的 Trace 视图,发现 Agent 执行的 Span 内部,LLM 调用的子 Span 耗时显著增加。
- 结论:瓶颈位于下游的 LLM 服务。此时可直接联系模型服务团队,或检查模型推理配置(如并发限制、超时设置)是否合理。
通过这套从日志到指标、从宏观到微观的实践,ArkClaw 真正实现了对 Agent 服务"看得清、管得住、优得动"的闭环治理能力。
告别猜谜:全链路可观测性的三大核心价值
从理念到落地,ArkClaw 的全链路可观测体系为开发者和业务带来了实实在在的价值,彻底改变了过去"靠猜排障、靠感觉优化"的局面。
1. 建立用户视角的"黄金指标"
可观测性的第一步是定义什么是"好服务"。我们摒弃了海量的底层指标,聚焦于最贴近用户感受的"黄金 SLI 指标",为服务稳定性建立了统一的度量衡。

这些 SLI 指标不仅为日常监控和告警提供了基线,也成为了衡量架构演进、版本发布和优化效果的"北极星"。
2. 产品化集成,实现开箱即用的观测能力
我们深知,再强大的能力如果接入复杂,也难以发挥其价值。因此,我们将极致的易用性作为核心设计目标。我们将可观测能力预置植入到了 ArkClaw 中,创建 ArkClaw 实例时,自动就带上了可观测能力。开发者无需深入理解可观测性原理,也无需手动修改复杂的配置,所有数据自动采集,开发者可以立即在 APMPlus 平台查看 SLI 大盘与调用链数据,让可观测性真正成为一种开箱即用的基础能力。
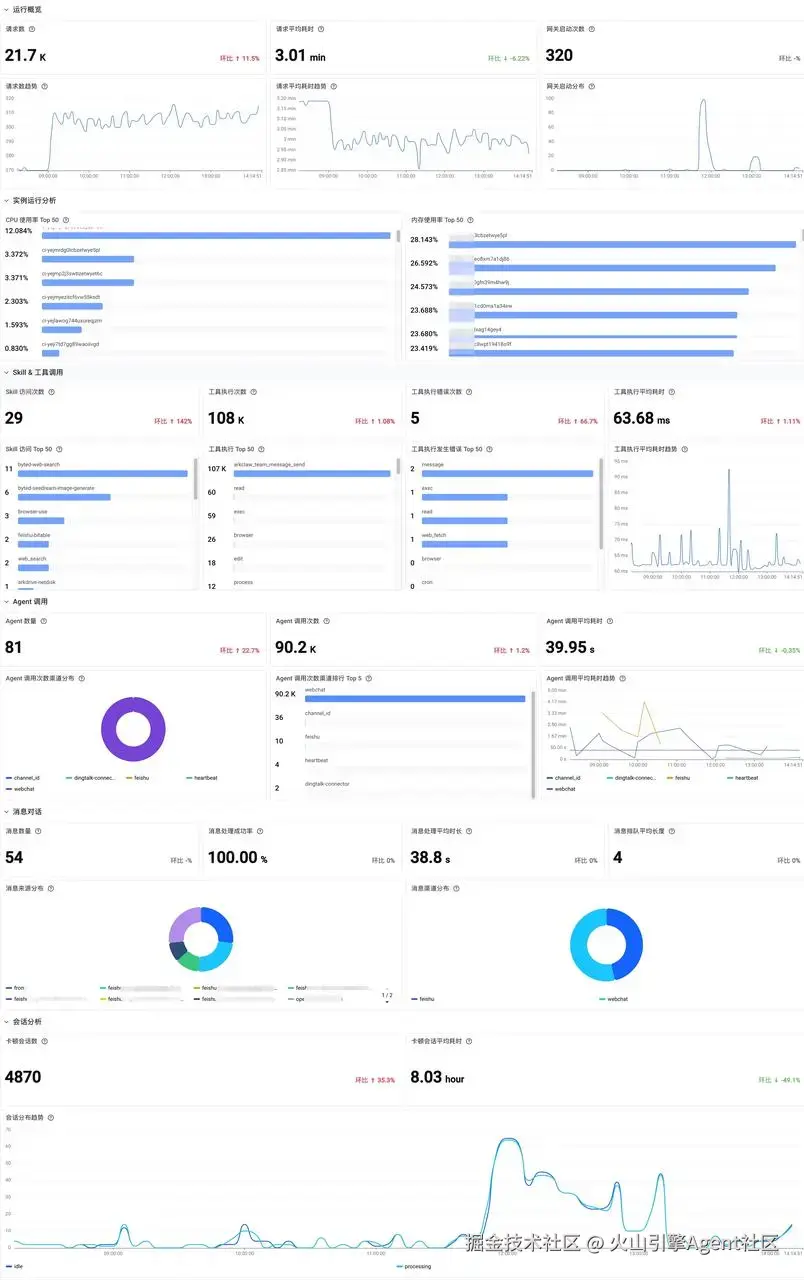
3. 监控与告警:分级触达,降噪闭环
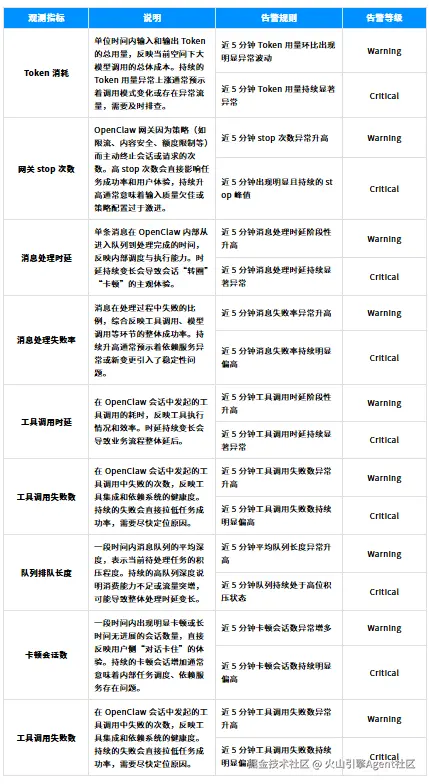
单单"看得清"还不够,更重要的是在问题发生前就收到预警。ArkClaw 的可观测性不仅用于事后复盘,也延伸到主动防御:提供一套开箱即用的监控与告警体系,让你的"虾"在异常行为刚出现时就能被及时发现。
我们为核心观测指标内置了丰富的预置告警规则,默认覆盖应用性能、资源消耗、依赖健康度等多个维度,你无需手动配置即可获得基础监控能力。
告警支持 Warning(警告)和 Critical(严重)分级,并可通过飞书、邮件等多渠道第一时间通知;同时内置告警合并、抑制策略与静默时段配置,减少偶发抖动或计划内维护带来的告警轰炸。指标恢复正常后也会发送恢复通知,形成完整的"发现-处理-恢复"闭环。
未来之路:迈向更智能、更自动化的 Agent 治理
度量与观测只是起点,我们的终极目标是构建一个能够自我诊断、自我优化的智能 Agent 体系。基于当前坚实的可观测性基础,ArkClaw 的下一步将聚焦于:
- 更智能的根因诊断: 结合 AIOps 能力,自动识别异常模式,从"看懂 Trace"进化到"自动推荐问题根因",进一步缩短故障排查时间。
- 与成本治理的联动: 将可观测性数据(如 Token 消耗、工具调用成本)与业务价值关联,构建精细化的成本度量与优化模型,让每一分投入都花在刀刃上。
- 更全面的场景覆盖: 持续深化对 CronJob、多模态交互等复杂场景的度量,确保在各种业务模式下都具备同样出色的可观测能力。
- 开放与生态: 将我们的实践与能力持续贡献给 OpenClaw 社区,与广大开发者共同推动 Agent 技术走向成熟与可靠。
我们相信,随着 Agent 应用从"可用"迈向"可靠",可观测性将不再是"锦上添花"的选项,而是保障业务连续性、驱动产品迭代的基础设施。ArkClaw 正在这条道路上坚定前行,我们邀请每一位开发者加入,共同定义 Agent 可观测性的未来。
虾友集结令,邀友享返券
ArkClaw 优惠上新,邀请好友首次订阅 ArkClaw 立得 10% 实付金额返券,多邀多得,>> 立即邀请 (szacq.cn/YWf7H/)
欢迎加入 ArkClaw 用户社群,和更多"养虾人"交流"玩虾"技巧