使用强化学习GRPO微调大模型DeepSeek-R1-Distill-Qwen-1.5B
🐬 目录:
一、强化学习算法
| 🎥 01 开篇:职场生存与年终奖 |
|---|
在强化学习(RL)的世界里,目标非常简单粗暴:拿高分 。
但在大模型的训练中,如果只追求"分数"(即原始奖励 Reward),模型往往会学坏。它会发现一些"作弊"的手段:比如为了得到"回答正确"的奖励,它可能会无限重复同一句话;或者为了迎合评分标准,它可能会生成一些看似华丽实则空洞的废话。这就好比学生为了拿高分去背答案,而不是真正学会解题。
为了解决这些"高分低能"的问题,研究者们设计了一系列精妙的调控机制。为了把这套复杂的数学逻辑讲明白,我们不妨把训练一个大模型,比作 一个职场新人(模型)在公司里争取年终奖(奖励)
的全过程。
| 🎥 02 只有 Reward 时的朴素做法:为什么会有问题? |
|---|
假设你刚入职,公司规定:"年底给公司赚了多少钱,就按比例发年终奖。"
听起来多劳多得,非常公平,对吧?但实际操作中会出现两个严重问题:
1️⃣ 不公平(方差大):
你被分到了核心业务线(简单任务),躺着都能赚100万;你的同事被分到了新开拓的荒地(困难任务),拼死拼活才赚20万。
结果:你拿巨额奖金,同事拿低保。同事觉得"努力没用",直接躺平。
(对应模型:在简单样本上得分虚高,在困难样本上得不到正反馈,导致训练不稳定。)
2️⃣动作变形(走捷径):
为了冲业绩拿奖金,你开始"杀鸡取卵"------比如向客户过度承诺、甚至卖劣质产品。虽然今年钱赚到了,但把客户得罪光了,明年没法干了。
(对应模型:为了刷高奖励分数,模型开始生成重复、无意义或有害的内容,破坏了语言逻辑。)
数学对应: J naive ( θ ) = E ( q , o ) ∼ ( d ata , π θ ) r ( o ) J_{\text{naive}}(\theta) = \mathbb{E}{(q,o)\sim(d{\text{ata}},\pi_\theta)}r(o) Jnaive(θ)=E(q,o)∼(data,πθ)r(o)
也就是"把最终 Reward 直接拿来做优化目标",就会导致训练极其不稳定,模型容易"钻空子"。换言之,Actor得不到一个和自身水平相称的参考线(baseline),进而影响学习效率。
| 🎥 03 引入 Critic:用"预期绩效"来修正奖励 |
|---|
老板发现了问题,引入了一个**👮Critic(部门主管/预估师)** 。
现在的规则变了:奖金不再只看你赚了多少钱,而是看你"超没超出主管的预期"(Advantage)。
主管的评估逻辑:
📌对你(核心业务):主管预期你能赚100万。结果你真的赚了100万。
结论 :表现平平,没惊喜,奖金一般。
📌对同事(新业务):主管预期他只能赚5万。结果他赚了20万。
结论 :超额完成,惊喜巨大,奖金丰厚。
这样一来,即使你赚的钱多,但因为没有超出预期,奖励反而不如那个"超额完成"的同事。这迫使你去挑战更难的任务,而不是躺在舒适区。
数学对应:引入价值函数 : A t = r t − V ϕ ( s t ) A_t = r_t - V_\phi(s_t) At=rt−Vϕ(st)
如果实际奖励 r t r_t rt 超过了 Critic 的预期 V ϕ ( s t ) V_\phi(s_t) Vϕ(st) ,说明这个动作比预期好,模型会受到正向激励;反之则受到惩罚。
| 🎥 04 加入 Clip:防止"步子迈太大"的过山车效应 |
|---|
虽然有了主管的预期,但新的问题又来了:"策略崩塌" 。
假设你今年运气爆棚,用一种很激进的方式签了一个大单(Reward 很高)。
如果没有 Clip ,公司可能会想:"哇,这招太灵了,明年你的工作方式彻底 改成这样!"
结果呢?这种激进的方式风险极大,明年你可能直接搞砸所有项目,心态崩了,直接离职(模型训练崩溃)。
🚩引入 Clip(风控红线)后:
公司在调整你的"工作方式"(策略参数)时,加了一个"封顶限制":"不管你这次表现多好,你的工作方式调整幅度,不能超过去年的 20%。"
为什么要这样做?
因为一次的成功可能是运气。如果因为一次运气好,就彻底改变你的性格(策略剧烈变动),一旦下次运气不好,你就会彻底废掉。Clip 强制要求:"你可以拿奖金,但你的'人设'(策略分布)只能微调,不能突变。"
数学对应:PPO 的核心目标函数:
m i n ( r t ( θ ) A t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) min(r_t(\theta)A_t, clip(r_t(\theta), 1-ϵ, 1+ϵ)A_t) min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At),
其中: r t ( θ ) = π θ ( o t ∣ s t ) π θ old ( o t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(o_t \mid s_t)}{\pi_{\theta_{\text{old}}}(o_t \mid s_t)} rt(θ)=πθold(ot∣st)πθ(ot∣st)
,表示新策略与旧策略在这个动作上的概率比值。如果这个比值离1太远,就会被Clip在[1-
ϵ,,1+ϵ,]区间内,从而限制一次更新幅度别过大。
| 🎥 05 Reference Model:防止"为了业绩不择手段" |
|---|
即便有了风控,你还是可能变坏。为了拿到那个"超额奖金",你开始疯狂走极端 。
比如,为了讨好客户,你承诺"明年业绩翻倍",或者"给客户送车"。这种激进的做法虽然短期内能拿高分,但风险极大,一旦做不到,公司就破产了。
为了防止这种情况,公司引入了Reference Model(入职时的你) 。
💥规则:现在的你(模型)和入职时的你(Reference Model)不能差太远。
💥惩罚:如果你现在的行为模式(比如装哑巴、说胡话)和入职时判若两人,哪怕业绩再好,也要扣除一部分奖金(KL 散度惩罚)。
在PPO里,这体现为对Reference Model(初始策略)的KL惩罚,具体可加到Loss中,比如: − β D K L ( π θ ∥ π r e f ) -\beta \, D_{\mathrm{KL}}(\pi_\theta \,\|\, \pi_{\mathrm{ref}}) −βDKL(πθ∥πref).这样,Actor 不会为了短期Reward而脱离原本合理的策略范畴,不至于"作弊"或偏得太离谱。
| 🎥 06 GRPO:不需要主管的"组内大比武" |
|---|
在之前的 PPO 故事里,你有一个Critic(部门主管)。每次你做完一个动作(比如写了一段代码),主管都要立刻给你一个评价:"我觉得你做得比预期好(Advantage)。"
但是,请主管有两个大麻烦:
🎈很贵(显存占用大):主管本身也是个高智商模型,养着他需要消耗巨大的算力和显存。
🎈主观(评估不准):主管也是人,他也有心情不好的时候,或者他对某些新业务的判断根本不准。
于是,老板(算法研究者)决定:"我们要优化掉'主管'这个岗位,用更聪明的办法发奖金!"
第一步:批量试错(Group Sampling)
面对同一个任务,老板不再让你只交一份方案,而是让你一次性拿出 G G G个不同版本。
第二步:以均值为尺(Mean as Baseline)
直接计算这 G G G 个版本的平均分,这个平均分就自动成为了衡量优劣的基准线。它代表了你当下的真实平均水平。
第三步:组内PK(Relative Advantage)
如果你的某个版本分数高于平均分,说明你这次"超常发挥",获得正向奖励。如果分数低于平均分,说明这次"表现拉胯",获得负向奖励。
数学对应:
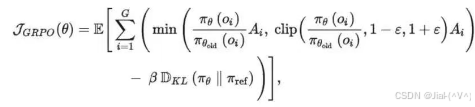 其中 A i = r i − mean ( { r 1 , r 2 , ⋯ , r G } ) std ( { r 1 , r 2 , ⋯ , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \cdots, r_G\})}{\text{std}(\{r_1, r_2, \cdots, r_G\})} Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG})就是用同一问题 的多条输出做平均,得到一个"相对评分"。这便实现了无需单独价值函数也能得到一个动态的"分数线"
其中 A i = r i − mean ( { r 1 , r 2 , ⋯ , r G } ) std ( { r 1 , r 2 , ⋯ , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \cdots, r_G\})}{\text{std}(\{r_1, r_2, \cdots, r_G\})} Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG})就是用同一问题 的多条输出做平均,得到一个"相对评分"。这便实现了无需单独价值函数也能得到一个动态的"分数线"
二、任务说明
该任务旨在利用群体相对策略优化(GRPO)算法,对DeepSeek-R1-distill-qwen-1.5B模型进行深度强化学习训练,以显著提升其在复杂数学推理任务中的表现。DeepSeek-R1-distill-qwen-1.5B作为基于Qwen架构蒸馏而来的轻量级模型,虽然具备基础的语言理解能力,但在处理需要多步逻辑推导的数学问题时,往往缺乏稳定的思维链生成能力。因此,本任务的核心目标是摒弃传统的监督微调模式,转而通过强化学习引导模型在推理过程中"自我觉醒"。
🔑目标:
利用GRPO算法去中心化且无需独立评论家模型的优势,我们将针对同一数学问题生成的多个候选回答进行组内博弈,通过计算群体内部的相对优势来更新策略。
🔑输入特征

数据集math_problems.parquet有100,000条数学数据,包含索引,问题描述和题解三个字段
🔑奖励设置
为了引导模型学习,代码设计了三个不同的奖励函数:
🍬格式化奖励 (format_reward_func) :这是一个基础奖励,用于检查模型的输出是否遵循了预设的 ...... 和 \boxed{...} 格式。如果格式正确,则给予正向奖励。
🍬准确性奖励 (accuracy_reward_func) :这是核心的奖励信号。它通过比较模型输出中 \boxed{} 的内容与数据集中的标准答案是否完全一致来给出奖励。答案正确得1.0分,错误得0.0分。
🍬解答质量奖励 (levenshtein_reward_func):这是一个更柔和的奖励函数,它计算模型在 之后生成的文本与标准答案之间的编辑距离相似度。即使答案不完全正确,只要与标准答案越相似,也能获得一定的奖励,这有助于在训练初期提供更平滑的梯度。
三、代码实现
1️⃣首先进行数据处理
从数据集中加载数据,为了进行后续的奖励计算,它定义了一个 extract_boxed_text 函数,用于从题目的标准答案(solution)中提取出 \boxed{} 标签内的最终答案。
def extract_boxed_text(text):
pattern = r'oxed{(.*?)}'
matches = re.findall(pattern, text)
if not matches:
return ""
for match in matches[::-1]:
if match != "":
return match
return ""
df = pd.read_parquet('../Datasets/math_problems.parquet')
df = df.reset_index().rename({'index': 'id'}, axis=1)
df['answer'] = df['solution'].map(extract_boxed_text)
df包含ID,Problem,Solution和answer三个字段
2️⃣Dataset构建
def is_valid_answer(s):
try:
if float(s) == int(s):
i = int(s)
return 0<=i<1000
else:
return False
except ValueError:
return False
mask = df['answer'].map(is_valid_answer)
df = df[mask].reset_index(drop=True)
# 在过滤后的数据中截取前 100 条
df = df.iloc[:100]
# 转换为 Dataset
dataset = Dataset.from_pandas(df)
dataset = dataset.train_test_split(test_size=0.1)3️⃣ 构造模型输入prompt
def create_prompt(sample):
question = sample['problem']
chat = [{"role": "system", "content": "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>"},
{"role": "user", "content": question + ' Return final answer within \\boxed{}, after taking modulo 1000.'},]
sample['prompt'] = tokenizer.apply_chat_template(
conversation=chat,
tokenize=False,
add_generation_prompt=True
)
return sample
dataset = dataset.map(create_prompt)4️⃣加载模型
model_name = '../../models/DeepSeek-R1-Distill-Qwen-1.5B'
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)
original_model = AutoModelForCausalLM.from_pretrained(model_name, device_map=device_map, quantization_config=bnb_config,
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True,padding_side="left")5️⃣ 构造奖励函数
def format_reward_func(completions, **kwargs):
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<think>.*?</think>.*?boxed{(.*?)}.*?$"
matches = [re.match(pattern, content, re.DOTALL) for content in completions]
return [1.0 if match else 0.0 for match in matches]🌸这个函数就像一个严格的 "格式检查员",专门用来验证模型生成的回答是否符合预设的"思考-作答"规范。它利用正则表达式
^.?boxed{(.?)}.*?$
对每一个生成的文本进行扫描,强制要求内容必须以 < / t h i n k > </think> </think> 标签开头,中间包含 < / t h i n k > </think> </think>,并且随后必须出现包裹答案的 boxed{} 结构。如果模型的输出完整包含了这套特定的标签序列,函数就判定格式正确并给出 1.0 的满分奖励,否则直接给 0 分,以此强迫模型学会"先思考、后作答"的标准化输出习惯。
def accuracy_reward_func(completions, answer, **kwargs):
# Regular expression to capture content inside \boxed{}
contents = [extract_boxed_text(completion) for completion in completions]
# Reward 1 if the content is the same as the ground truth, 0 otherwise
return [1.0 if c == str(gt) else 0.0 for c, gt in zip(contents, answer)]🌸这个函数扮演着 "判卷老师" 的角色,专门负责根据最终答案的对错来给出最核心的奖励信号。它会先调用 extract_boxed_text 工具从模型生成的文本中提取出 \boxed{} 里的内容,然后将其与数据集提供的标准答案(answer)进行严格比对。只有当提取出的答案与标准答案完全一致时,才会给予 1.0 的满分奖励,否则一律为 0。这种"非黑即白"的评分机制旨在强制模型不仅要学会说话,更要确保推理结果的绝对准确性。
def levenshtein_reward_func(completions, solution, **kwargs):
res = []
for completion, sol in zip(completions, solution):
if '</think>' in completion:
t = completion.split('</think>')[-1]
res.append(levenshtein_ratio(t, sol))
else:
res.append(0.0)
return res🌸这个函数充当了 "温和的引导者" ,它不再像准确性奖励那样只看最终结果,而是关注模型回答的文本相似度。它首先检查模型输出中是否包含 < / t h i n k > </think> </think> 标签,如果存在,就截取该标签之后的所有文本(即模型给出的最终回答部分),然后利用 Levenshtein 编辑距离算法计算这段文本与标准答案(solution)的相似比率。
与"非对即错"的准确性奖励不同,这个函数会给出一个 0.0 到 1.0 之间的连续分数:即使模型没有算出完全正确的答案,只要它的回答在文字上与标准答案越接近(例如步骤正确但计算小错),就能获得一定的奖励。这种机制避免了训练初期因模型完全答错而导致梯度消失的问题,帮助模型更平滑地学习解题思路。
6️⃣模型配置和训练
reward_functions = {'formatting': format_reward_func, 'accuracy': accuracy_reward_func, 'solution_quality': levenshtein_reward_func}
peft_config = LoraConfig(
r=32, #Rank
lora_alpha=32,
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense'
],
bias="none",
lora_dropout=0.05, # Conventional
task_type="CAUSAL_LM",
)
trainer = GRPOTrainer(
model=original_model,
reward_funcs=list(reward_functions.values()),
args=training_args,
train_dataset=dataset['train'],
peft_config=peft_config,
callbacks=[PrinterCallback()]
)
trainer.train()7️⃣测试与验证
让训练好的模型(new_model)去考一遍测试集(dataset'test'),每道题做4次,然后算出它在格式规范、答案准确度和解题思路相似度这三个方面的平均分,以此来判断训练到底有没有效果
def gen(model, text, max_tokens):
model_input = tokenizer(text, return_tensors='pt').to(model.device)
model.eval()
with torch.no_grad():
tok = model.generate(**model_input, max_new_tokens=max_tokens,pad_token_id=tokenizer.pad_token_type_id)
outputs = []
for i in range(len(tok)):
res = tokenizer.decode(tok[i], skip_special_tokens=True)
output = res.split(CFG.splitter)[-1]
outputs.append(output)
return outputs[0] if len(outputs) == 1 else outputs
def evaluate_rewards(model, dataset, reward_functions: dict[str, callable], max_tokens: int, num_generations: int):
completions = []
other_info = []
for example in tqdm(dataset):
txt = example['prompt']
kw = {k: v for k, v in example.items() if k not in {'prompt', 'completion'}}
for _ in range(num_generations):
other_info.append(kw)
completion = gen(model, [txt]*num_generations, max_tokens)
if isinstance(completion, str):
completions.append(completion)
else:
completions += completion
kwargs = {k: [d[k] for d in other_info] for k in other_info[0].keys()}
res = {}
for nm, reward_func in reward_functions.items():
v = reward_func(completions=completions, **kwargs)
print(nm, np.mean(v))
res[nm] = np.mean(v)
return res
#new_model为加载训练权重后的模型
rewards = evaluate_rewards(model=new_model, dataset=dataset['test'], reward_functions=reward_functions, max_tokens=2047, num_generations=4)