langchain4j+rag+qdrant
一、前言
在当前 AI 应用开发中,单纯依赖大模型(LLM)已经难以满足实际业务需求,例如:
- 无法访问私有数据
- 容易产生"幻觉"(瞎说)
- 缺乏长期记忆能力
为了解决这些问题,逐渐形成了一种主流架构 ------ 检索增强生成(RAG, Retrieval-Augmented Generation )。
二、技术组件及作用
1 、LangChain4j :AI 应用开发框架
LangChain4j 是一个面向 Java 生态的 LLM 应用开发框架,主要负责:
- 封装大模型调用(如 OpenAI、本地模型等)
- 构建 AI 处理流程(Prompt、Chain、Agent)
- 管理对话上下文与记忆(Memory)
2 、RAG :核心架构思想
RAG (检索增强生成) 是本系统的核心机制,其流程为:
先从知识库检索相关内容 → 再交给大模型生成答案
主要作用:
- 让 AI 可以基于"数据"回答问题
- 显著降低模型幻觉
- 提高回答的准确性与可控性
3 、Qdrant :向量数据库
Qdrant 是一个专为 AI 场景设计的向量数据库,主要负责:
- 存储文本的向量表示(Embedding)
- 进行高效的相似度搜索(语义检索)
- 支持元数据过滤(如分类、标签等)
协作流程
整个系统的工作流程如下:
用户提问
↓
LangChain4j 接收请求
↓
向 Qdrant 查询相关向量(RAG 检索)
↓
返回最相关的文本片段
↓
拼接 Prompt
↓
调用大模型生成答案
↓
返回最终结果
注意RAG 检索 并不是简单的模糊查询(像mysql 的like那样),rag用的是向量检索(Embedding),即将数据和问题转成向量(数字),算他们的语义距离(相似度)(即语义是否相近)
三、环境与依赖
Langchain4j 最低支持java17
Pom依赖
<!-- LangChain4j 核心(AI调用、流程控制) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.3.0</version>
</dependency>
<!-- RAG 支持(文档切分 + 检索流程) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.3.0-beta9</version>
</dependency>
<!-- Qdrant 向量数据库(语义检索) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
<version>1.13.0-beta23</version>
</dependency>
<!-- 大模型(生成回答) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>**四、**qdrant的部署以及使用
这里推荐docker环境安装
首先你得有docker环境(安装教程可以看作者的其他文章Docker部署微服务-CSDN博客 的标题一)
1、下载/启动qdrant(Github地址 https://github.com/qdrant/qdrant)
docker pull qdrant/qdrant2、持久化 + 后台运行
docker run -d --name qdrant -p 6333:6333 -p 6334:6334 -v .\qdrant_data:/qdrant/storage qdrant/qdrant参数含义
-d
→ 后台运行(容器不会占用你的终端窗口)
--name qdrant
→ 给容器名叫 qdrant,方便管理
-p 6333:6333 -p 6334:6334
→ 开放端口,可访问 Web UI 和 API
-v .\qdrant_data:/qdrant/storage
→ 数据持久化
把容器里的数据映射到当前文件夹下的 qdrant_data
3、访问UI
http://localhost:6333/dashboard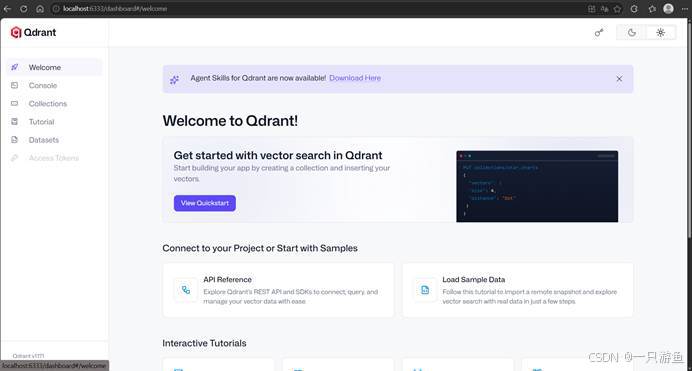
4、创建Collections
点击Collections右上角的create Collections按钮,仿照我的配置:
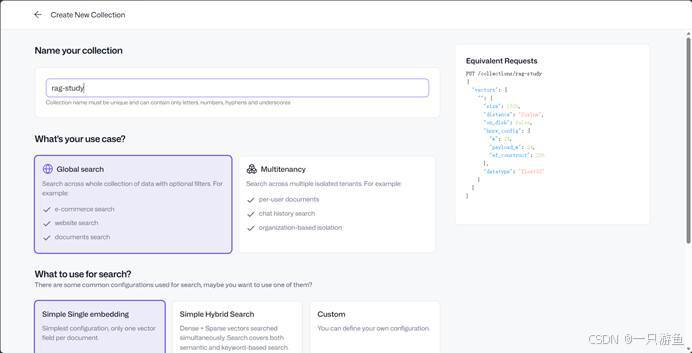
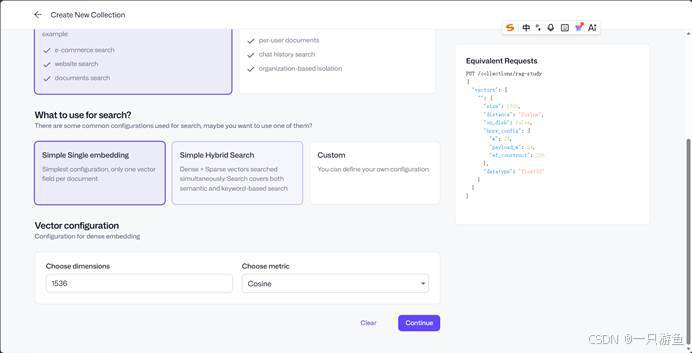
点击继续即创建成功
五、实战
配置文件:(需要去阿里百炼官网获取密钥)
spring:
application:
name: langchain4j
profiles:
active: local
langchain4j:
community:
dashscope:
chat-model:
model-name: qwen-max
api-key: <key>
#向量
embedding-model:
model-name: text-embedding-v2
api-key: <key>
streaming-chat-model:
model-name: qwen-max
api-key: <key>
server:
port: 8081AiCodeHelperServiceFactory工厂配置:
@Configuration
public class AiCodeHelperServiceFactory {
@Resource
private ChatModel qwenChatModel;
@Resource
private ContentRetriever contentRetriever;
@Resource
private McpToolProvider mcpToolProvider;
@Resource
private StreamingChatModel streamingChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService(){
// 会话记忆
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
// 构建
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.streamingChatModel(streamingChatModel)
.chatModel(qwenChatModel)
.chatMemory(chatMemory) // 会话记忆
.chatMemoryProvider(memoryId->MessageWindowChatMemory.withMaxMessages(10)) //每个会话独立存储
.contentRetriever(contentRetriever) // 内容检索 (启用 RAG)à主要是这里
.tools(new JavaInfoTool()) // 工具
.toolProvider(mcpToolProvider) // mcp
.build();
return aiCodeHelperService;
}
}AiCodeHelperService服务
public interface AiCodeHelperService {
@SystemMessage(fromResource = "system-prompt.txt") // 系统提示词
Flux<String> chatStream(
@MemoryId int memoryId,
@UserMessage String message
);
}RagQdrantConfig 向量数据库配置:
@Configuration
public class RagQdrantConfig {
@Resource
private EmbeddingModel embeddingModel;
// Qdrant
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("localhost")
.port(6334)
.collectionName("rag-study") //要和刚刚创建的Collections
的名字一样
.build();
}
// 内容检索器
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> embeddingStore) {
return EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.maxResults(5)
.minScore(0.75)
.build();
}
}这里我们需要准备两个文档来作为私有数据:
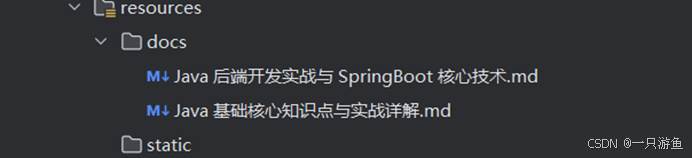
然后创建初始化类(将文档数据转化为数据存入向量数据库):
这里是做了一个演示要注意要检验不要将空向量存进去,否则检索时会报错
RagDataInitializer类
@Component
public class RagDataInitializer implements CommandLineRunner {
@Resource
private EmbeddingModel embeddingModel;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
@Override
public void run(String... args) {
System.out.println("开始初始化 RAG 数据...");
try {
// 强制清空 Qdrant(避免历史脏数据)
if (embeddingStore instanceof QdrantEmbeddingStore qdrant) {
try {
qdrant.clearStore();
System.out.println("已清空 Qdrant 集合");
} catch (Exception e) {
System.out.println("集合不存在,将自动创建");
}
}
// 加载文档
List<Document> documents =
FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
if (documents == null || documents.isEmpty()) {
System.out.println("没有找到文档,跳过初始化");
return;
}
System.out.println("文档数量: " + documents.size());
// 文档切割
DocumentByParagraphSplitter splitter =
new DocumentByParagraphSplitter(500, 100);
int success = 0;
int skipped = 0;
// 手动 ingest
for (Document doc : documents) {
List<TextSegment> segments = splitter.split(doc);
for (TextSegment segment : segments) {
String text = segment.text();
// 过滤空文本
if (text == null || text.trim().isEmpty()) {
skipped++;
continue;
}
String fileName = segment.metadata().getString("file_name");
if (fileName == null) {
fileName = "unknown";
}
String finalText = fileName + "\n" + text;
try {
// 调 embedding
var response = embeddingModel.embed(finalText);
if (response == null || response.content() == null) {
System.out.println("embedding 返回 null");
skipped++;
continue;
}
float[] vector = response.content().vector();
// 核心校验
if (vector == null || vector.length == 0) {
System.out.println("空向量,跳过: " + shortText(finalText));
skipped++;
continue;
}
if (vector.length != 1536) {
System.out.println("向量维度异常: " + vector.length);
skipped++;
continue;
}
// 写入向量库
embeddingStore.add(
response.content(),
TextSegment.from(finalText, segment.metadata())
);
success++;
} catch (Exception e) {
System.out.println("embedding失败: " + e.getMessage());
skipped++;
}
}
}
// 输出结果
System.out.println(" 成功写入: " + success);
System.out.println("跳过数据: " + skipped);
System.out.println("RAG 数据初始化完成!");
} catch (Exception e) {
System.err.println("RAG 初始化失败: " + e.getMessage());
e.printStackTrace();
}
}
/**
* 日志截断(防止日志爆炸)
*/
private String shortText(String text) {
if (text == null) return "";
return text.length() > 50 ? text.substring(0, 50) + "..." : text;
}
}控制器:
AiController
@GetMapping(value = "/chat", produces = "text/event-stream")
public Flux<ServerSentEvent<String>> chat(int memoryId, String message) {
if (message == null || message.isBlank()) {
// 返回空的 Flux,拦截请求
return Flux.empty();
}
// 正常流程
return aiCodeHelperService.chatStream(memoryId, message)
.bufferUntil(chunk ->
chunk.endsWith("。") ||
chunk.endsWith("!") ||
chunk.endsWith("?") ||
chunk.endsWith("\n")
)
.map(list -> String.join("", list))
.map(sentence -> ServerSentEvent.<String>builder()
.data(sentence)
.build());
}启动后
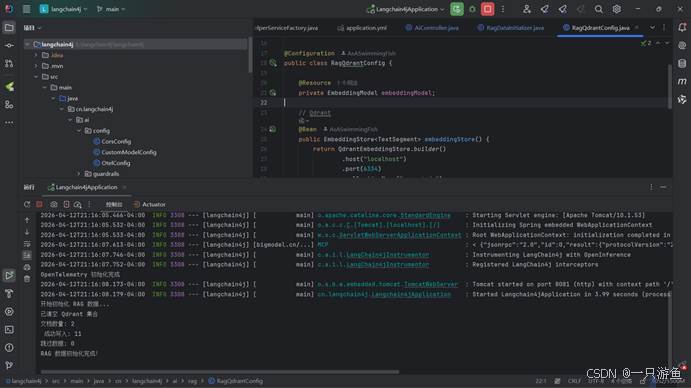
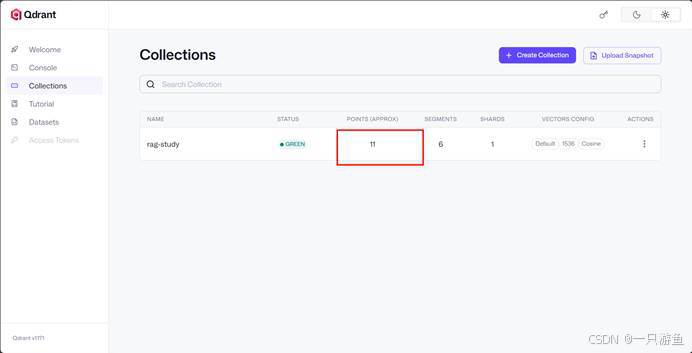
等到启动成功,可以看到向量数据库中刚创建的Collection有了内容:
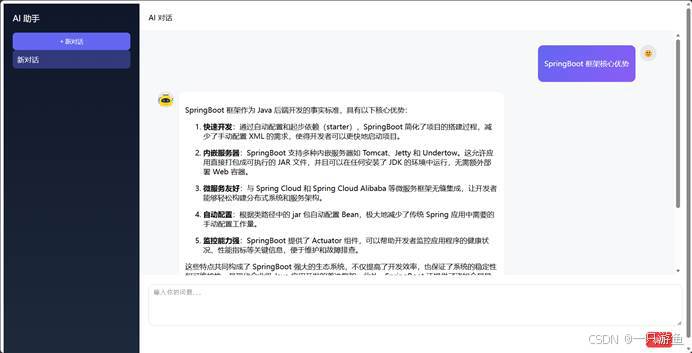
请求接口可以看到作者这里自己做了一个界面,大家可以通过api调用
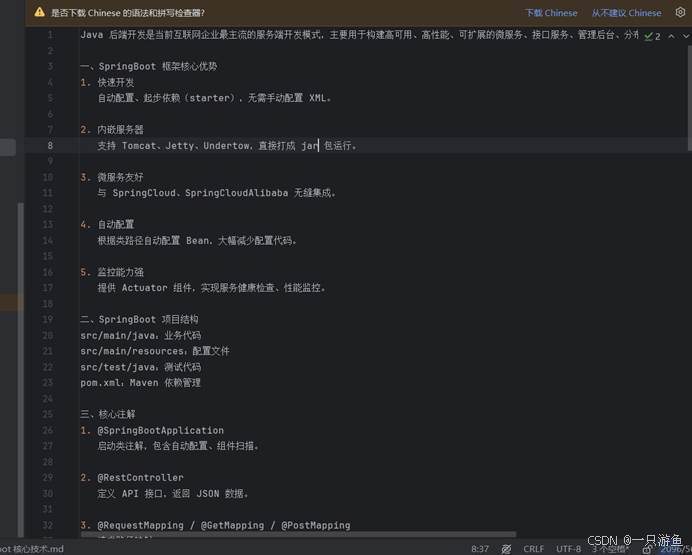
可以看到他用到了我们向量数据库的知识。