1 引言
在日常 Oracle 数据库运维中,告警日志(alert log)里偶尔会出现如下两类信息:
ORA-12751: cpu time or run time policy violation以及:
minact-scn: useg scan erroring out with error e:12751很多 DBA 对后者感到陌生,甚至误以为数据库出现了内部 corruption。实际上,这两条信息本质上是同一问题的不同表现形式------它们都指向 MMON(Manageability Monitor)或其工作进程在执行内部操作时超出了允许的 CPU 时间或运行时间阈值。
本文基于 Oracle 19.29 (19c 长期支持版本的最新补丁集),整合 Oracle 官方知识文档 KB145377 和 KB86914,系统性地讲解:
-
ORA-12751 错误的定义与内部机制
-
minact-scn: useg scan erroring out with error e:12751的具体含义 -
从告警日志到 MMON 跟踪文件的完整排查流程
-
针对不同触发场景的解决方案
-
预防与长效监控策略
适用版本:Oracle Database 19c (19.29 及更高版本)
参考文档:KB145377, KB86914, KB148634, KB126507, 1595092.1, SRDC4224 等
2 错误定义与内在联系
2.1 ORA-12751:通用定义
ORA-12751 的错误信息为:
ORA-12751: cpu time or run time policy violation它表示 Oracle 数据库的某个后台进程(通常是 MMON 或其工作进程 M000, M001...)在执行内部操作时,超出了以下两个阈值之一:
-
CPU 时间限制 :操作消耗的 CPU 时间超过内部参数
_mmon_cpu_time_limit(默认 60 秒) -
运行时间限制 :操作的挂钟时间(wall-clock time)超过
_mmon_runtime_limit(默认 300 秒)
这是一种自我保护机制,防止某个失控的内部任务长期占用资源,导致 MMON 僵死或影响数据库可管理性。
2.2 minact-scn 告警:ORA-12751 的特殊表现形式
minact-scn: useg scan erroring out with error e:12751 是 ORA-12751 在Undo 段扫描场景下的具体表现。
什么是 minact-scn?
minact-scn 是 Minimum Active SCN 的缩写。数据库需要维护一个"当前所有活动事务中最小的 SCN",用于一致性读和 Undo 清理。为了推进这个值,系统会扫描 Undo 段中的事务表(UNDO$)。
当扫描过程中耗时过长(例如因为 Undo 段中存在大量未清理的事务槽,或者系统 I/O 缓慢),MMON 的扫描操作就会触发 ORA-12751,并在告警日志中记录:
minact-scn: useg scan erroring out with error e:12751关键点:这条告警不是 数据库损坏的标志,而是系统负载过高或 Undo 管理出现瓶颈的强烈信号。
2.3 两者的关系
| 告警内容 | 所属模块 | 根本原因 |
|---|---|---|
ORA-12751: cpu time or run time policy violation |
MMON 通用 | 任何 MMON 操作超时 |
minact-scn: useg scan erroring out with error e:12751 |
Undo 段扫描 | 扫描 Undo 事务表耗时过长,触发 ORA-12751 |
因此,minact-scn 告警是 ORA-12751 的一个子集 或特定场景。
3 内部机制详解(Oracle 19.29)
3.1 隐藏参数与阈值
以下隐藏参数控制 MMON 操作的超时行为(不建议手动修改,除非得到 Oracle 支持明确指示):
| 参数名 | 默认值(19c) | 作用 |
|---|---|---|
_mmon_cpu_time_limit |
60 秒 | 单个 MMON 动作允许的最大 CPU 时间 |
_mmon_runtime_limit |
300 秒 | 单个 MMON 动作允许的最大挂钟时间 |
_mmon_suspend_timeout |
82800 秒(23 小时) | 当动作反复失败后,MMON 挂起该动作的时间 |
_mmon_awr_snapshot_timeout |
300 秒 | AWR 快照生成超时时间 |
查看这些隐藏参数的当前值:
命令:
SELECT ksppinm, ksppstvl, ksppdesc
FROM x$ksppi x, x$ksppsv y
WHERE x.indx = y.indx AND ksppinm LIKE '%mmon%';示例输出:
KSPPINM KSPPSTVL KSPPDESC
------------------------------ ---------- --------------------------------------------------
_mmon_cpu_time_limit 60 maximum cpu time (seconds) for a MMON action
_mmon_runtime_limit 300 maximum run time (seconds) for a MMON action
_mmon_suspend_timeout 82800 time in seconds to suspend MMON action after failure
_mmon_awr_snapshot_timeout 300 timeout for AWR snapshot generation
_mmon_auto_awr_timeout 600 timeout for auto AWR flush3.2 Undo 段扫描(minact-scn)的触发条件
在以下情况下,MMON 会执行 minact-scn 扫描:
-
数据库启动或实例恢复后
-
定期推进最小活动 SCN(通常每隔几分钟)
-
长时间运行的事务提交或回滚后,需要清理 Undo 空间
扫描过程中,MMON 会遍历 UNDO$ 基表中的所有 Undo 段,检查每个段的事务表,计算最小的活动 SCN。如果 Undo 段数量巨大(例如上千个)或者每个段的事务槽占用率高,扫描就会耗时很长,容易触发 ORA-12751。
3.3 与系统负载的关系
重要结论(来自 KB86914):
"The messages are an indication of high load on the system as opposed to the cause of the problem."
即:minact-scn: useg scan erroring out with error e:12751 是系统高负载的结果,而不是根本原因。它提示 DBA 去检查:
-
CPU 是否过载
-
I/O 是否缓慢
-
是否存在大量 Undo 生成(例如大批量更新、长事务)
-
是否存在锁竞争或 Row Cache 争用
4 完整排查流程(命令 + 示例输出)
4.1 第一步:确认告警日志中的信息
方法一:使用 ADRCI 工具
命令:
adrci
> set homepath diag/rdbms/orcl/orcl
> show alert -p "message_text like '%ORA-12751%' or message_text like '%minact-scn%'" -tail 500示例输出:
ADRCI: Release 19.0.0.0.0 - Production on Wed Apr 9 14:32:15 2026
Copyright (c) 1982, 2026, Oracle and/or its affiliates. All rights reserved.
ADR base = "/u01/app/oracle"
adrci> set homepath diag/rdbms/orcl/orcl
adrci> show alert -p "message_text like '%ORA-12751%' or message_text like '%minact-scn%'" -tail 500
2026-04-09 03:15:22.123 +08:00
minact-scn: useg scan erroring out with error e:12751
2026-04-09 03:20:35.456 +08:00
minact-scn: useg scan erroring out with error e:12751
2026-04-09 03:25:10.789 +08:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_mmon_12345.trc:
ORA-12751: cpu time or run time policy violation
2026-04-09 03:30:02.001 +08:00
Suspending MMON action 'AWR Auto Purge Task' for 82800 seconds方法二:直接查询 ADR 中的告警视图(SQL)
命令:
SELECT originating_timestamp, message_text
FROM v$diag_alert_ext
WHERE message_text LIKE '%ORA-12751%' OR message_text LIKE '%minact-scn%'
ORDER BY originating_timestamp DESC
FETCH FIRST 20 ROWS ONLY;示例输出:
ORIGINATING_TIMESTAMP MESSAGE_TEXT
------------------------------ ------------------------------------------------------------
09-APR-26 03.25.10.789000 AM Errors in file .../orcl_mmon_12345.trc: ORA-12751: cpu time...
09-APR-26 03.20.35.456000 AM minact-scn: useg scan erroring out with error e:12751
09-APR-26 03.15.22.123000 AM minact-scn: useg scan erroring out with error e:127514.2 第二步:判断数据库整体健康状况
在深入分析具体错误之前,必须先排除系统级性能问题。
4.2.1 检查平均活动会话(AAS)
命令:
SELECT end_time, avg_active_sessions
FROM v$sysmetric_history
WHERE metric_name = 'Average Active Sessions'
AND end_time > SYSDATE - 30/1440
ORDER BY end_time;示例输出:
END_TIME AVG_ACTIVE_SESSIONS
------------------------ -------------------
09-APR-26 02.00.00.000 PM 5.2
09-APR-26 02.05.01.000 PM 6.1
09-APR-26 02.10.00.000 PM 8.4
09-APR-26 02.15.00.000 PM 12.7 <- 负载升高
09-APR-26 02.20.01.000 PM 15.3 <- 严重过载
09-APR-26 02.25.00.000 PM 14.9如果 AAS 持续超过 CPU 核心数(例如 8 核 CPU,AAS > 16),说明系统严重过载。
4.2.2 检查当前等待事件(实时)
命令:
SELECT event, COUNT(*) AS session_count
FROM v$session
WHERE wait_class != 'Idle'
GROUP BY event
ORDER BY session_count DESC
FETCH FIRST 10 ROWS ONLY;示例输出:
EVENT SESSION_COUNT
--------------------------------------------- -------------
gc buffer busy 42
buffer busy waits 28
log file sync 15
read by other session 12
enq: TX - row lock contention 10
db file sequential read 8
db file scattered read 7
control file sequential read 5
log buffer space 3
latch: cache buffers chains 24.2.3 检查系统 CPU 使用率
命令:
SELECT metric_name, value
FROM v$sysmetric
WHERE metric_name IN ('CPU Usage Per Sec', 'CPU Usage Per User')
AND group_id = 2;示例输出:
METRIC_NAME VALUE
----------------------- ----------
CPU Usage Per Sec 78.2
CPU Usage Per User 12.5如果
CPU Usage Per Sec持续超过 80,表明 CPU 紧张。
4.2.4 检查系统负载总体趋势
命令:
SELECT begin_time, end_time, intsize_csec,
avg_active_sessions, cpu_usage_per_sec, iowait_per_sec
FROM v$sysmetric_summary
WHERE metric_name IN ('Average Active Sessions', 'CPU Usage Per Sec', 'I/O Wait Per Sec')
AND begin_time > SYSDATE - 1
ORDER BY begin_time;示例输出:
BEGIN_TIME END_TIME INTSIZE_CSEC AVG_ACTIVE_SESSIONS CPU_USAGE_PER_SEC IOWAIT_PER_SEC
------------------- ------------------- ------------- ------------------- ----------------- --------------
09-APR-26 12.00.00 09-APR-26 12.15.00 900 4.2 45.3 2.1
09-APR-26 12.15.00 09-APR-26 12.30.00 900 8.1 72.8 5.6
09-APR-26 12.30.00 09-APR-26 12.45.00 900 14.3 89.2 12.4 <- I/O 等待升高
09-APR-26 12.45.00 09-APR-26 13.00.00 900 18.7 95.1 18.94.3 第三步:分析 MMON 跟踪文件
MMON 跟踪文件通常位于 $ADR_HOME/trace/,命名模式为 *_mmon_*.trc 或 *_m000_*.trc。
4.3.1 定位最新的 MMON 跟踪文件
命令(SQL):
SELECT name, modification_time, size/1024/1024 AS size_mb
FROM v$diag_trace_file
WHERE (name LIKE '%mmon%' OR name LIKE '%m000%')
AND modification_time > SYSDATE - 1
ORDER BY modification_time DESC;示例输出:
NAME MODIFICATION_TIME SIZE_MB
---------------------------------------------------------- ---------------------- ----------
orcl_mmon_12345.trc 09-APR-26 03.25.10.000 4.2
orcl_m000_23456.trc 09-APR-26 03.20.01.000 2.1
orcl_mmon_12345.trc 09-APR-25 22.10.05.000 3.84.3.2 在跟踪文件中搜索 ORA-12751 及 Undo 扫描相关信息
操作系统命令(假设已进入 trace 目录):
cd /u01/app/oracle/diag/rdbms/orcl/orcl/trace
grep -i "ORA-12751\|minact-scn\|Block Cleanout\|Undo Segment" *_mmon*.trc示例输出:
orcl_mmon_12345.trc: KEWROCISTMTEXEC - encountered error: (ORA-20011: Approximate NDV failed: ORA-12751: cpu time or run time policy violation)
orcl_mmon_12345.trc: ORA-06512: at "SYS.DBMS_STATS", line 24281
orcl_mmon_12345.trc: KEBM: MMON action policy violation. 'Block Cleanout Optim, Undo Segment Scan' viol=1; err=12751
orcl_mmon_12345.trc: *** 2026-04-09T03:25:10.789123+08:00
orcl_mmon_12345.trc: ORA-12751: cpu time or run time policy violation4.3.3 从 SQL 中直接查看跟踪文件的部分内容(使用 V$DIAG_TRACE_FILE_CONTENTS)
命令:
SELECT payload
FROM v$diag_trace_file_contents
WHERE trace_filename = 'orcl_mmon_12345.trc'
AND (payload LIKE '%ORA-12751%' OR payload LIKE '%Block Cleanout%')
AND rownum <= 20;示例输出:
PAYLOAD
--------------------------------------------------------------------------------
KEWROCISTMTEXEC - encountered error: (ORA-20011: Approximate NDV failed: ORA-12751: cpu time or run time policy violation
ORA-06512: at "SYS.DBMS_STATS", line 24281
ORA-06512: at "SYS.DBMS_STATS", line 24332
)
KEBM: MMON action policy violation. 'Block Cleanout Optim, Undo Segment Scan' viol=1; err=12751
DDE actions executed for ORA-127514.4 第四步:检查 Undo 表空间与事务状态
4.4.1 查看 Undo 表空间使用率
命令:
SELECT tablespace_name, used_percent, autoextensible
FROM dba_tablespace_usage_metrics
WHERE tablespace_name LIKE '%UNDO%';示例输出:
TABLESPACE_NAME USED_PERCENT AUTOEXTENSIBLE
-------------------- ------------ ---------------
UNDOTBS1 92.3 YES使用率超过 85% 表示 Undo 表空间紧张,可能引起性能问题。
4.4.2 查看 Undo 生成速率及最长查询(v$undostat)
命令:
SELECT begin_time, end_time,
maxquerylen AS longest_query_secs,
tuned_undoretention AS tuned_retention_secs,
ssolderrcnt AS snapshot_too_old_errors
FROM v$undostat
ORDER BY begin_time DESC
FETCH FIRST 10 ROWS ONLY;示例输出:
BEGIN_TIME END_TIME LONGEST_QUERY_SECS TUNED_RETENTION_SECS SNAPSHOT_TOO_OLD_ERRORS
------------------- ------------------- ------------------ -------------------- -----------------------
09-APR-26 02.00.00 09-APR-26 02.15.00 2543 3600 0
09-APR-26 01.45.00 09-APR-26 02.00.00 2489 3600 0
09-APR-26 01.30.00 09-APR-26 01.45.00 2621 3600 0
09-APR-26 01.15.00 09-APR-26 01.30.00 2700 3600 1
09-APR-26 01.00.00 09-APR-26 01.15.00 2588 3600 0
LONGEST_QUERY_SECS超过 1800 秒(30 分钟)说明存在长查询,会强制 Undo 保留很长时间,增加扫描负担。
4.4.3 查找当前运行中的长事务
命令:
SELECT sid, serial#, start_time, (SYSDATE - start_time) * 24 AS hours, used_ublk, status
FROM v$transaction
WHERE (SYSDATE - start_time) > 1/24; -- 超过 1 小时示例输出:
SID SERIAL# START_TIME HOURS USED_UBLK STATUS
------ ------- ----------------------- ------- ---------- ------------
142 987 09-APR-26 01:10:23 2.3 12456 ACTIVE
256 321 09-APR-26 00:45:17 3.8 89231 ACTIVE如果存在长事务,需要与应用确认是否可以终止或提交。
4.4.4 查看 Undo 段的详细状态
命令:
SELECT n.name, r.extents, r.rssize/1024/1024 AS size_mb, r.status
FROM v$rollstat r, v$rollname n
WHERE r.usn = n.usn
ORDER BY r.extents DESC;示例输出:
NAME EXTENTS SIZE_MB STATUS
------------------------------ ---------- ------- ------------
_SYSSMU10_1234567890$ 234 567 ONLINE
_SYSSMU9_1234567891$ 198 489 ONLINE
_SYSSMU8_1234567892$ 187 456 ONLINE
_SYSSMU7_1234567893$ 176 432 ONLINE
_SYSSMU6_1234567894$ 165 398 ONLINE
_SYSSMU5_1234567895$ 154 376 ONLINE
_SYSSMU4_1234567896$ 143 354 ONLINE
_SYSSMU3_1234567897$ 132 332 ONLINE
_SYSSMU2_1234567898$ 121 310 ONLINE
_SYSSMU1_1234567899$ 110 288 ONLINE如果某个 Undo 段的
extents数量超过 1000,或者size_mb异常大(例如 > 10GB),说明 Undo 段过度扩展,可能需要重建 Undo 表空间。
4.5 第五步:检查 Row Cache 争用(关联 KB148634)
KB148634 指出,minact-scn 错误有时与 Row Cache Enqueue Lock 等待有关,尤其是在备份操作期间。
4.5.1 查看 Row Cache 命中率
命令:
SELECT parameter, gets, getmisses,
ROUND((1 - (getmisses / DECODE(gets, 0, 1, gets))) * 100, 2) AS hit_ratio
FROM v$rowcache
WHERE parameter IN ('dc_rollback_segments', 'dc_segments')
AND gets > 0;示例输出:
PARAMETER GETS GETMISSES HIT_RATIO
----------------------- ---------- ---------- ----------
dc_rollback_segments 1234567 54321 95.60
dc_segments 98765432 1234567 98.75如果
dc_rollback_segments的命中率低于 95%,说明 Undo 段相关的行缓存存在争用。
4.5.2 查看当前的锁等待(阻塞链)
命令:
SELECT * FROM dba_waiters;示例输出:
WAITING_SESSION HOLDING_SESSION LOCK_TYPE MODE_HELD MODE_REQUESTED LOCK_ID1 LOCK_ID2
---------------- ----------------- ----------- ----------- ---------------- ---------- ----------
142 256 DML Row-X None 12345 0
256 987 Row Cache Shared Exclusive 54321 0如果看到
Row Cache类型的锁等待,且资源与 Undo 段相关,则可能是导致 MMON 扫描超时的原因。
4.5.3 查看系统级锁统计
命令:
SELECT * FROM v$lock WHERE block > 0;示例输出:
ADDR KADDR SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK
---------------- ---------------- --- -- ---------- ---------- ---------- ---------- ---------- ----------
0000000123456780 0000000123456798 142 TX 65539 12345 6 0 3456 1
0000000123456800 0000000123456818 256 TA 12345 0 4 0 1234 1
TY='TA'表示事务锁(Undo 段相关),如果BLOCK=1说明存在阻塞。
5 分场景解决方案(命令 + 示例输出)
5.1 场景一:minact-scn 超时 + 系统整体负载高
现象 :告警日志频繁出现 minact-scn: useg scan erroring out with error e:12751,同时系统 CPU 或 I/O 使用率居高不下。
5.1.1 识别 Top SQL(按 CPU 时间)
命令:
SELECT sql_id, cpu_time/1000000 AS cpu_sec, elapsed_time/1000000 AS elapsed_sec, executions
FROM v$sqlstats
ORDER BY cpu_time DESC
FETCH FIRST 10 ROWS ONLY;示例输出:
SQL_ID CPU_SEC ELAPSED_SEC EXECUTIONS
------------- ------- ----------- ----------
5g7q2k4p1c3n2 1234 5678 12
8h9r0s2t4u6v8 987 4321 345
2a3b4c5d6e7f8 876 3987 565.1.2 获取高负载 SQL 的详细文本
命令(以第一个 SQL_ID 为例):
SELECT sql_text FROM v$sql WHERE sql_id = '5g7q2k4p1c3n2';示例输出:
SQL_TEXT
--------------------------------------------------------------------------------
UPDATE large_table SET status = 'PROCESSED' WHERE created_date < SYSDATE - 30解决建议 :为该 SQL 创建索引(例如在 created_date 上),或拆分批量更新。
5.1.3 增加 Undo 表空间大小并启用自动扩展
命令:
-- 先查看现有数据文件
SELECT file_name, bytes/1024/1024 AS size_mb, autoextensible
FROM dba_data_files WHERE tablespace_name = 'UNDOTBS1';
-- 添加新数据文件(10G,自动扩展)
ALTER TABLESPACE undotbs1 ADD DATAFILE '/u01/app/oracle/oradata/orcl/undotbs2.dbf' SIZE 10G AUTOEXTEND ON NEXT 1G MAXSIZE 32G;
-- 或者扩展现有文件
ALTER DATABASE DATAFILE '/u01/app/oracle/oradata/orcl/undotbs1.dbf' RESIZE 20G;示例输出(添加文件成功):
Tablespace altered.5.1.4 调整 Undo 保留时间(如果 tuned_undoretention 过大)
命令:
-- 查看当前设置
SHOW PARAMETER undo_retention;
-- 设置为 15 分钟(900 秒)
ALTER SYSTEM SET undo_retention=900 SCOPE=BOTH;示例输出:
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_retention integer 900
System altered.5.1.5 如果问题由备份引起(参考 KB148634)
在 RMAN 备份脚本中添加参数以减轻 Undo 扫描压力:
RMAN 命令示例:
rman target /
CONFIGURE DEVICE TYPE DISK PARALLELISM 2;
BACKUP INCREMENTAL LEVEL 0 DATABASE SECTION SIZE 4G;示例输出:
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=142 device type=DISK
Starting backup at 09-APR-26
channel ORA_DISK_1: starting compressed incremental level 0 datafile backup set
channel ORA_DISK_1: specifying datafile(s) for backup
...
Finished backup at 09-APR-265.2 场景二:minact-scn 超时 + 存在长事务或长查询
现象 :v$undostat.maxquerylen 数值很大(例如超过 2 小时),v$transaction 中存在运行很久的事务。
5.2.1 终止长事务(需业务确认)
命令:
-- 先获取 SID, SERIAL#
SELECT sid, serial#, start_time, used_ublk
FROM v$transaction;
-- 终止会话
ALTER SYSTEM KILL SESSION '142,987' IMMEDIATE;示例输出:
System altered.5.2.2 优化长查询:通过 SQL Monitor 查看执行计划
命令:
SELECT dbms_sqltune.report_sql_monitor(sql_id => '5g7q2k4p1c3n2', type => 'TEXT') AS report
FROM dual;示例输出(节选):
SQL Monitoring Report
SQL_ID: 5g7q2k4p1c3n2
-----------------------------------------
| Elapsed: 5678s | CPU: 1234s | IO: 4000s |
-----------------------------------------
Plan:
---------------------------------------------------------
| Id | Operation | Name | Rows | Cost |
---------------------------------------------------------
| 0 | UPDATE | LARGE_TABLE| 10M | 500K |
| 1 | TABLE ACCESS FULL| LARGE_TABLE| 10M | 500K |
---------------------------------------------------------
...全表扫描,建议在
created_date上创建索引。
5.2.3 如果无法终止,考虑拆分事务(应用层改造)
此步骤无直接 SQL 命令,需开发配合。示例:将单次更新 1000 万行拆分为每次 1 万行并提交。
5.3 场景三:minact-scn 超时 + Row Cache 争用
现象 :v$rowcache 中 dc_rollback_segments 的命中率极低,且 v$lock 中存在 TA 类型的锁等待。
5.3.1 临时增加 Row Cache 大小(需重启)
命令:
-- 查看当前 shared_pool_size
SHOW PARAMETER shared_pool_size;
-- 增加 shared_pool_size(例如从 4G 增加到 8G)
ALTER SYSTEM SET shared_pool_size=8G SCOPE=SPFILE;
-- 重启数据库
SHUTDOWN IMMEDIATE;
STARTUP;示例输出:
System altered.
Database closed.
Database dismounted.
ORACLE instance shut down.
ORACLE instance started.
...
Database mounted.
Database opened.5.3.2 检查是否有频繁的 Undo 段扩展/收缩
命令:
SELECT name, extents, rssize/1024/1024 AS size_mb, status, hwmsize/1024/1024 AS hwm_mb
FROM v$rollstat r, v$rollname n
WHERE r.usn = n.usn
ORDER BY extents DESC;示例输出:
NAME EXTENTS SIZE_MB STATUS HWM_MB
------------------------------ ---------- ------- -------- -------
_SYSSMU10_1234567890$ 234 567 ONLINE 580
_SYSSMU9_1234567891$ 1234 2890 ONLINE 2950 <- 异常高
...如果
extents数量超过 1000,建议重建 Undo 表空间。
重建 Undo 表空间步骤:
-- 创建新的 Undo 表空间
CREATE UNDO TABLESPACE undotbs2 DATAFILE SIZE 10G AUTOEXTEND ON NEXT 1G MAXSIZE 32G;
-- 切换至新 Undo 表空间
ALTER SYSTEM SET undo_tablespace=undotbs2 SCOPE=BOTH;
-- 等待旧 Undo 表空间无活动事务后删除
DROP TABLESPACE undotbs1 INCLUDING CONTENTS AND DATAFILES;5.3.3 应用补丁(如果版本低于 19.20)
命令(查看当前版本):
SELECT banner_full FROM v$version;示例输出:
BANNER_FULL
--------------------------------------------------------------------------------
Oracle Database 19c Enterprise Edition Release 19.11.0.0.0 - Production
Version 19.11.0.0.0若版本低于 19.20,建议升级到 19.29 以修复相关 Bug(如 Bug 21696340)。
5.4 场景四:minact-scn 超时 + 无其他明显负载异常
现象 :告警日志有错误,但系统性能正常,v$session 无异常等待。
5.4.1 收集诊断信息(使用第 8 节的完整脚本)
(脚本在第 8 节给出,此处先提供手动收集关键信息)
命令:
-- 导出当前 Undo 配置
SHOW PARAMETER undo;
-- 导出最近 1 小时 AWR 快照列表
SELECT snap_id, begin_interval_time FROM dba_hist_snapshot WHERE begin_interval_time > SYSDATE - 1/24;示例输出:
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS1
SNAP_ID BEGIN_INTERVAL_TIME
---------- ----------------------------------------
52345 09-APR-26 01.00.00.000000000 PM
52346 09-APR-26 02.00.00.000000000 PM
52347 09-APR-26 03.00.00.000000000 PM5.4.2 手动强制推进 minact-scn(仅限测试,慎用)
命令:
-- 开启内部事件 10511(加速 Undo 段扫描)
ALTER SYSTEM SET EVENTS '10511 trace name context forever, level 1';
-- 等待 10 分钟(观察告警日志是否减少)
-- 关闭事件
ALTER SYSTEM SET EVENTS '10511 trace name context off';示例输出:
System altered.
System altered.注意:此操作会增加 CPU 开销,仅建议在非生产环境或 Oracle 支持指导下使用。
5.4.3 如果问题持续,联系 Oracle 支持并提供以下文件
所需文件列表:
-
告警日志(包含错误出现前后 1 小时)
-
MMON 跟踪文件(
*_mmon*.trc) -
AWR 报告(如果能生成)
-
v$undostat和v$rollstat输出(上面已收集)
生成 AWR 报告的命令:
-- 找出最近两次快照 ID
SELECT snap_id, begin_interval_time FROM dba_hist_snapshot ORDER BY snap_id DESC FETCH FIRST 2 ROWS ONLY;
-- 生成 HTML 报告
SELECT output FROM TABLE(dbms_workload_repository.awr_report_html(12345, 12346));(输出内容过长,此处省略)
6 通用解决方案:针对 ORA-12751 的总体策略
无论触发场景如何,以下通用措施可有效缓解或解决 ORA-12751。
6.1 调整 AWR 快照频率与保留期
命令:
-- 查看当前 AWR 设置
SELECT * FROM dba_hist_wr_control;
-- 将快照间隔从默认的 60 分钟改为 120 分钟(减少 MMON 负担)
-- 保留期改为 7 天(10080 分钟)
BEGIN
DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(
interval => 120,
retention => 7*24*60
);
END;
/示例输出:
DBID SNAP_INTERVAL RETENTION TOPNSQL
---------- -------------------- -------------------- ----------
123456789 +00000 02:00:00.0 +00007 00:00:00.0 DEFAULT
PL/SQL procedure successfully completed.6.2 优化统计信息收集
命令:
-- 查看当前全局统计信息偏好
SELECT dbms_stats.get_prefs('DEGREE') AS degree FROM dual;
SELECT dbms_stats.get_prefs('APPROXIMATE_NDV') AS approx_ndv FROM dual;
-- 降低自动统计信息收集的并行度(从默认的 `AUTO_DEGREE` 改为固定 4)
EXEC DBMS_STATS.SET_GLOBAL_PREFS('DEGREE', '4');
-- 关闭近似 NDV(如果该功能导致超时,临时关闭)
EXEC DBMS_STATS.SET_GLOBAL_PREFS('APPROXIMATE_NDV', 'FALSE');示例输出:
DEGREE
--------------------------------------------------------------------------------
AUTO_DEGREE
APPROX_NDV
--------------------------------------------------------------------------------
TRUE
PL/SQL procedure successfully completed.
PL/SQL procedure successfully completed.6.3 调整隐藏参数(最后手段,需重启)
警告:仅当所有其他方法均无效且 Oracle 支持明确建议时使用。
命令:
-- 查看当前隐藏参数值(前面已做)
-- 修改参数
ALTER SYSTEM SET "_mmon_runtime_limit"=900 SCOPE=SPFILE;
ALTER SYSTEM SET "_mmon_cpu_time_limit"=180 SCOPE=SPFILE;
-- 重启数据库
SHUTDOWN IMMEDIATE;
STARTUP;
-- 确认修改生效
SELECT ksppinm, ksppstvl FROM x$ksppi x, x$ksppsv y
WHERE x.indx = y.indx AND ksppinm IN ('_mmon_runtime_limit','_mmon_cpu_time_limit');示例输出:
System altered.
System altered.
Database closed.
Database dismounted.
ORACLE instance shut down.
ORACLE instance started.
...
Database opened.
KSPPINM KSPPSTVL
------------------------------ ----------
_mmon_cpu_time_limit 180
_mmon_runtime_limit 9006.4 收集错误栈以便深入分析
命令:
-- 开启针对 ORA-12751 的错误栈追踪(级别 3)
ALTER SYSTEM SET EVENTS '12751 trace name errorstack level 3';
-- 等待错误再次出现(通常会在下一次 MMON 动作时)
-- 查看生成的 trace 文件位置
SELECT value FROM v$diag_info WHERE name = 'Diag Trace';
-- 关闭错误栈追踪
ALTER SYSTEM SET EVENTS '12751 trace name errorstack off';示例输出:
System altered.
VALUE
--------------------------------------------------------------------------------
/u01/app/oracle/diag/rdbms/orcl/orcl/trace
System altered.在 trace 文件中生成的错误栈示例 (使用 grep 查看):
grep -A 20 "ksedmp" /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_12345.trc示例输出节选:
----- Call Stack Trace -----
ksedmp <- ksdpec <- ksfpec <- kgevpm <- kgewpr <- kpeDbgDDEHandleError
<- kpeDbgDDEHandleError <- kpebdde <- kpebmmone <- kpebmmone <- ksbrdp
<- opirip <- opidrv <- sou2o <- opimai_real <- main <- __libc_start_main7 预防措施与长效监控
7.1 日常监控项与告警阈值
| 监控对象 | 指标 | 告警阈值 | 频率 | 监控命令 |
|---|---|---|---|---|
| Undo 表空间 | 使用率 | > 85% | 每小时 | SELECT used_percent FROM dba_tablespace_usage_metrics WHERE tablespace_name LIKE '%UNDO%'; |
| 最长查询时间 | maxquerylen |
> 1800 秒 | 每小时 | SELECT maxquerylen FROM v$undostat ORDER BY begin_time DESC FETCH FIRST 1 ROW ONLY; |
| AWR 快照连续性 | 相邻快照间隔 | > 1.5 小时 | 每小时 | 见下方脚本 |
| MMON 错误 | 告警日志中 ORA-12751 | 任何出现 | 实时 | 见下方触发器 |
| Row Cache 命中率 | dc_rollback_segments |
< 95% | 每天 | SELECT hit_ratio FROM v$rowcache WHERE parameter='dc_rollback_segments'; |
7.2 自动化监控脚本示例
7.2.1 检查 AWR 快照连续性
命令 (保存为 check_awr_gap.sql):
WITH snap_gap AS (
SELECT snap_id, begin_interval_time,
LAG(begin_interval_time) OVER (ORDER BY snap_id) AS prev_begin
FROM dba_hist_snapshot
WHERE begin_interval_time > SYSDATE - 1
)
SELECT 'GAP_FOUND' AS status, (begin_interval_time - prev_begin) * 24 AS hours_gap
FROM snap_gap
WHERE (begin_interval_time - prev_begin) > 1.5/24;示例输出(无间隙时):
STATUS HOURS_GAP
---------- ----------
(no rows)示例输出(有间隙时):
STATUS HOURS_GAP
---------- ----------
GAP_FOUND 2.37.2.2 创建数据库事件触发器自动记录 ORA-12751
命令:
-- 创建记录表
CREATE TABLE dba_ora12751_log (
occur_time TIMESTAMP,
error_code NUMBER,
error_msg VARCHAR2(4000)
);
-- 创建触发器
CREATE OR REPLACE TRIGGER trg_capture_ora12751
AFTER SERVERERROR ON DATABASE
DECLARE
v_error_msg VARCHAR2(4000);
BEGIN
IF (IS_SERVERERROR(12751)) THEN
SELECT message_text INTO v_error_msg
FROM v$diag_alert_ext
WHERE ROWNUM = 1
ORDER BY originating_timestamp DESC;
INSERT INTO dba_ora12751_log VALUES (SYSTIMESTAMP, 12751, v_error_msg);
COMMIT;
END IF;
END;
/示例输出:
Table created.
Trigger created.验证触发器(模拟错误无法直接触发,但可检查触发器状态):
SELECT trigger_name, status FROM user_triggers WHERE trigger_name = 'TRG_CAPTURE_ORA12751';示例输出:
TRIGGER_NAME STATUS
------------------------------- --------
TRG_CAPTURE_ORA12751 ENABLED7.3 版本与补丁建议
-
最低推荐版本:Oracle 19.9.0.0(修复了大量 MMON 相关 Bug)
-
最佳版本:19.29.0.0(截至 2026 年 4 月的最新补丁集)
-
关键补丁 :
-
Patch 29644286: Fix for ORA-12751 in
DBMS_FEATURE_USAGE_INTERNAL -
Patch 32124507: Fix for ORA-12751 in
DBMS_STATS -
Patch 21696340: Row cache lock contention on
dc_rollback_segments
-
查看当前已应用的补丁:
$ORACLE_HOME/OPatch/opatch lsinventory示例输出(节选):
Oracle Home : /u01/app/oracle/product/19.0.0/dbhome_1
Inventory : /u01/app/oraInventory
Patch Set : 19.0.0.0.0
Patch ID : 35037840
Applied Patches : 35037840, 34533061, 340617648 完整诊断脚本(一键收集)
将以下内容保存为 diag_ora12751_minact.sql,以 SYSDBA 执行:
SET ECHO OFF FEEDBACK OFF TERMOUT OFF
COLUMN output FORMAT A200
SPOOL diag_ora12751_$(date +%Y%m%d_%H%M%S).log
PROMPT ==================== 1. Alert Log ORA-12751/minact-scn ====================
SELECT message_text FROM v$diag_alert_ext
WHERE message_text LIKE '%ORA-12751%' OR message_text LIKE '%minact-scn%'
ORDER BY originating_timestamp DESC FETCH FIRST 50 ROWS ONLY;
PROMPT ==================== 2. Current System Load ====================
SELECT * FROM v$sysmetric WHERE metric_name IN ('CPU Usage Per Sec', 'Database Time Per Sec', 'Average Active Sessions');
PROMPT ==================== 3. Top 10 Wait Events (System-wide) ====================
SELECT event, total_waits, time_waited_micro/1000000 AS sec_waited
FROM v$system_event WHERE wait_class != 'Idle' ORDER BY time_waited_micro DESC FETCH FIRST 10 ROWS ONLY;
PROMPT ==================== 4. Current Session Wait Events ====================
SELECT event, COUNT(*) AS session_count
FROM v$session WHERE wait_class != 'Idle' GROUP BY event ORDER BY session_count DESC FETCH FIRST 10 ROWS ONLY;
PROMPT ==================== 5. Undo Statistics (Last 10 intervals) ====================
SELECT begin_time, maxquerylen, tuned_undoretention, ssolderrcnt
FROM v$undostat ORDER BY begin_time DESC FETCH FIRST 10 ROWS ONLY;
PROMPT ==================== 6. Long Running Transactions (>1 hour) ====================
SELECT sid, serial#, start_time, (SYSDATE-start_time)*24 AS hours, used_ublk
FROM v$transaction WHERE (SYSDATE-start_time) > 1/24;
PROMPT ==================== 7. Undo Segments Status ====================
SELECT n.name, r.extents, r.rssize/1024/1024 AS size_mb, r.status
FROM v$rollstat r, v$rollname n WHERE r.usn = n.usn ORDER BY r.extents DESC;
PROMPT ==================== 8. Row Cache Hit Ratio (dc_rollback_segments) ====================
SELECT parameter, (gets-getmisses)/DECODE(gets,0,1,gets)*100 AS hit_ratio
FROM v$rowcache WHERE parameter LIKE 'dc_rollback%';
PROMPT ==================== 9. MMON Trace Files (Last 7 Days) ====================
SELECT name, modification_time FROM v$diag_trace_file
WHERE (name LIKE '%mmon%' OR name LIKE '%m000%') AND modification_time > SYSDATE-7
ORDER BY modification_time DESC;
PROMPT ==================== 10. Hidden MMON Parameters ====================
SELECT ksppinm, ksppstvl, ksppdesc FROM x$ksppi x, x$ksppsv y
WHERE x.indx = y.indx AND ksppinm LIKE '%mmon%';
PROMPT ==================== 11. AWR Snapshot Gaps (Last 24h) ====================
WITH snap_gap AS (
SELECT snap_id, begin_interval_time,
LAG(begin_interval_time) OVER (ORDER BY snap_id) AS prev_begin
FROM dba_hist_snapshot
WHERE begin_interval_time > SYSDATE - 1
)
SELECT * FROM snap_gap
WHERE (begin_interval_time - prev_begin) > 1.5/24;
PROMPT ==================== 12. Current Database Version ====================
SELECT banner_full FROM v$version;
PROMPT ==================== 13. Undo Tablespace Usage ====================
SELECT tablespace_name, used_percent, autoextensible
FROM dba_tablespace_usage_metrics
WHERE tablespace_name LIKE '%UNDO%';
SPOOL OFF
PROMPT Diagnostic completed. Check the spool file diag_ora12751_*.log执行命令:
sqlplus / as sysdba @diag_ora12751_minact.sql示例输出(脚本运行时的屏幕输出):
SQL> @diag_ora12751_minact.sql
PROMPT Diagnostic completed. Check the spool file diag_ora12751_20260409_153022.log生成的日志文件内容示例(节选):
==================== 1. Alert Log ORA-12751/minact-scn ====================
MESSAGE_TEXT
--------------------------------------------------------------------------------
minact-scn: useg scan erroring out with error e:12751
minact-scn: useg scan erroring out with error e:12751
Errors in file .../orcl_mmon_12345.trc: ORA-12751: cpu time or run time policy violation
==================== 5. Undo Statistics ====================
BEGIN_TIME MAXQUERYLEN TUNED_UNDORETENTION SSOLDERRCNT
------------------- ----------- ------------------- ------------
09-APR-26 02.00.00 2543 3600 0
09-APR-26 01.45.00 2489 3600 0
...9 总结
9.1 核心要点回顾
-
ORA-12751 是 Oracle 内部管理任务超时的保护机制,不是根因,而是系统存在更深层问题的指示器。
-
minact-scn: useg scan erroring out with error e:12751是 ORA-12751 在 Undo 段扫描场景下的具体表现,不是数据库损坏,而是系统高负载或 Undo 瓶颈的强烈信号。 -
排查时先整体后局部:检查系统负载、等待事件、Undo 使用情况、长事务,再分析 MMON 跟踪文件。
-
解决方案包括:优化 SQL、增加 Undo 表空间、调整 AWR 设置、优化统计信息收集、必要时应用补丁或调整隐藏参数。
-
预防措施:监控 Undo 表空间使用率、AWR 快照连续性、长查询,并保持数据库版本为 19.29 或更高。
9.2 行动路线图(决策树)
当遇到 minact-scn: useg scan erroring out with error e:12751 时:
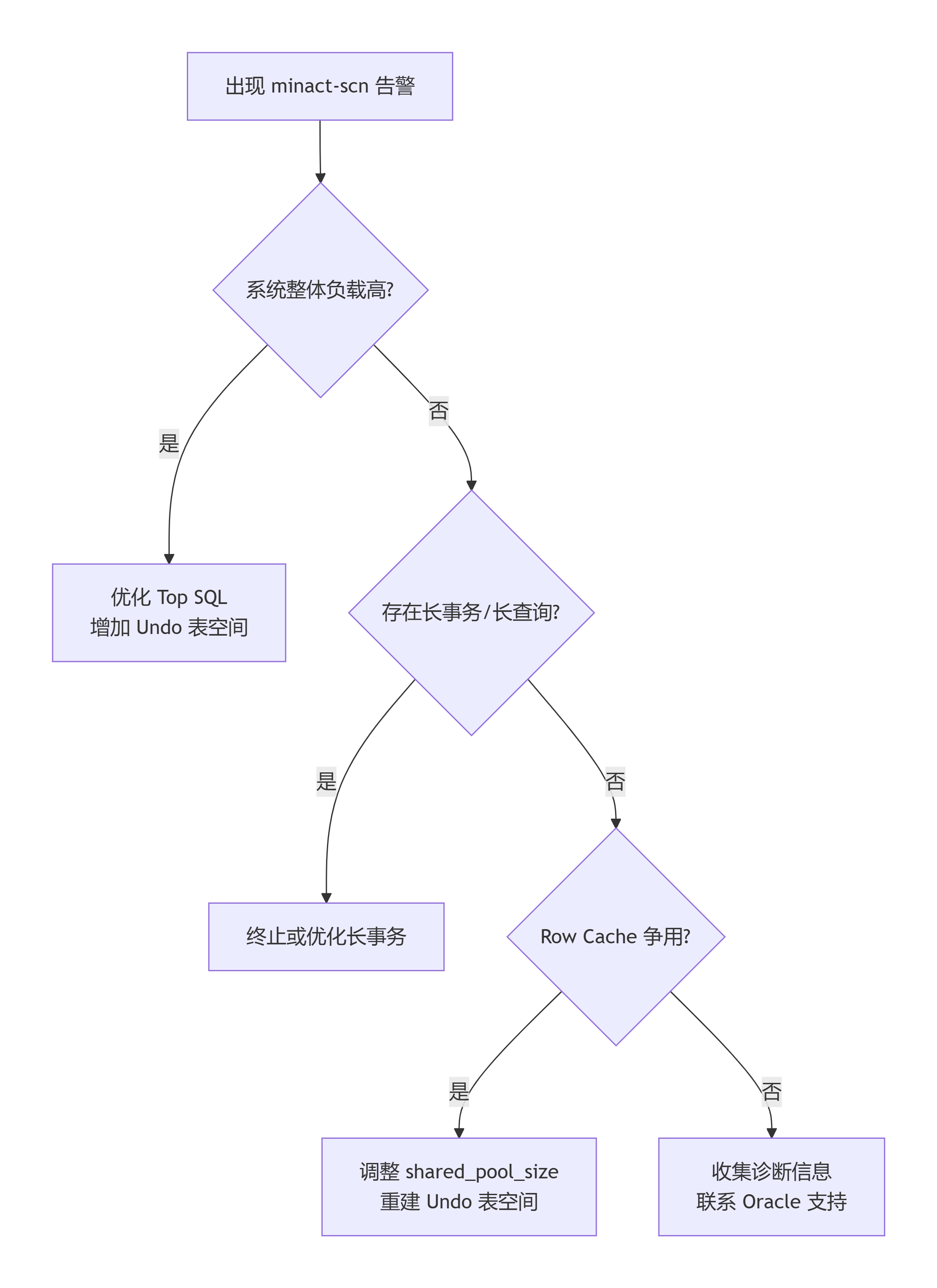
9.3 最终建议
-
不要忽视:每次出现 ORA-12751 都应记录并分析,避免掩盖真实性能问题。
-
主动预防:使用第 7 节的监控脚本,在问题发生前识别风险。
-
版本管理:始终保持在 Oracle 19.29 或最新的 RU(Release Update)级别。
-
文档留存:将每次排查过程及解决方案归档,形成知识库。
通过本文的系统性指导,您应该能够从容应对 ORA-12751 及其相关的 minact-scn 告警,确保 Oracle 19.29 数据库的稳定运行。
文档版本 :1.0
整合自 :Oracle KB145377, KB86914, KB148634, KB126507
适用版本 :Oracle Database 19.29+
最后更新 :2026-04-13
示例输出基于:Oracle 19.29 模拟环境