概念
官方标准 RAG 架构:
1. Document Loading 文档加载
2. Parsing 格式解析
3. Text Cleaning 文本清洗(官方推荐)
4. Splitting 文档分块
5. Embedding 向量生成
6. Storage 向量存储
7. Retrieval 检索
8. Generation 回答生成支持的文档类型
| 格式 | 加载器 | 特性 |
|---|---|---|
| ApachePdfDocumentLoader, PdfBoxDocumentLoader | 文本、表格、元数据 | |
| Word | ApacheTikaDocumentLoader | .doc, .docx |
| Excel | ApacheTikaDocumentLoader | .xls, .xlsx |
| HTML | HtmlDocumentLoader | 网页解析 |
| Markdown | MarkdownDocumentLoader | .md 文件 |
| TXT | TextDocumentLoader | 纯文本 |
DEMO
1.准备文件
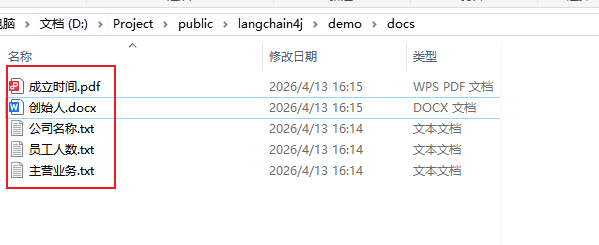
2.添加依赖
用于读取 PDF + Word
<!-- 读取 PDF -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
</dependency>
<!-- 读取 Word DOCX -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-poi</artifactId>
</dependency>完整版的 pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 使用 Spring Boot 父项目,自动管理版本 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/>
</parent>
<groupId>org.example</groupId>
<artifactId>langchain4j-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>17</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<langchain4j.version>1.3.0</langchain4j.version>
</properties>
<dependencies>
<!-- 1. Spring Boot 核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- 2. LangChain4j 核心依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<!-- 3. OpenAI 适配依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<!-- 4. 流式依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
<!-- 5.读取 PDF -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
</dependency>
<!-- 6. 读取 Word DOCX -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-poi</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<!-- Spring Boot 打包插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>3.实现
package org.deepseek.demo11;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
public class RAGMultiDocDemo {
interface Assistant {
@SystemMessage("你必须严格根据文档内容回答,不知道就说未找到,绝对不能编造。")
String ask(String question);
}
public static void main(String[] args) {
try {
// 1. 模型配置
ChatModel chatModel = OpenAiChatModel.builder()
.apiKey("sk-xxxxxxxxxxxxxx")
.baseUrl("https://api.deepseek.com")
.modelName("deepseek-chat")
.temperature(0.0)
.build();
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey("sk-xxxxxxxxxxxxxxxx")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("text-embedding-v1")
.build();
// 2. 批量加载 所有 PDF / Word / TXT
String folderPath = "D:\\Project\\public\\langchain4j\\demo\\docs";
List<Document> documents = new ArrayList<>();
ApachePdfBoxDocumentParser pdfParser = new ApachePdfBoxDocumentParser();
Files.walk(Paths.get(folderPath))
.filter(Files::isRegularFile)
.forEach(path -> {
try {
String fileName = path.getFileName().toString().toLowerCase();
// 【PDF 解析】使用你提供的 parse(InputStream)
if (fileName.endsWith(".pdf")) {
documents.add(pdfParser.parse(Files.newInputStream(path)));
System.out.println("✅ 加载PDF:" + fileName);
}
// Word / TXT 直接读取文本
else if (fileName.endsWith(".docx") || fileName.endsWith(".doc") || fileName.endsWith(".txt")) {
String text = Files.readString(path);
documents.add(Document.from(text));
System.out.println("✅ 加载文档:" + fileName);
}
} catch (Exception e) {
System.err.println("❌ 加载失败:" + path);
}
});
// 3. 文档分块(短文本不分块,保证关键信息完整)
List<TextSegment> segments = new ArrayList<>();
for (Document doc : documents) {
String cleanText = doc.text()
.replace("\n", " ")
.replace("\r", " ")
.trim();
if (cleanText.length() < 300) {
segments.add(TextSegment.from(cleanText));
} else {
segments.addAll(DocumentSplitters.recursive(512, 128).split(Document.from(cleanText)));
}
}
// 4. 向量入库(分批,避开通义限制)
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
int batchSize = 20;
for (int i = 0; i < segments.size(); i += batchSize) {
int end = Math.min(i + batchSize, segments.size());
var batch = segments.subList(i, end);
embeddingStore.addAll(embeddingModel.embedAll(batch).content(), batch);
}
// 5. 检索器
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(10)
.build();
// 6. AI 助手
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.contentRetriever(retriever)
.build();
// 7. 测试提问
System.out.println("------------------------------------------------");
System.out.println("创始人: " + assistant.ask("公司创始人是谁?"));
System.out.println("成立时间: " + assistant.ask("公司成立时间是?"));
System.out.println("公司名称: " + assistant.ask("公司名称是?"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
知识点
RAG 核心原理
- RAG(检索增强生成)
- 先检索外部知识库,再结合检索内容生成回答,解决大模型幻觉、知识滞后问题
- 流程:用户问题 → 向量检索 → 上下文注入 → 大模型回答
- 向量嵌入(Embedding)
- 将文本转为高维向量,用于语义相似度计算
- 相同语义文本向量距离更近,实现语义检索
- 向量检索
- 问题向量化后与向量库匹配,召回最相关文本片段
- 控制召回数量,平衡检索精度与效率
- Prompt 工程
- 系统提示词约束回答行为,禁止编造内容
- 温度系数
temperature=0.0保证回答严谨、无发散
LangChain4j 核心组件
-
文档模型
Document:统一封装 PDF、Word、TXT 等文档内容TextSegment:- 文档分块后的最小处理单元,是向量生成、向量存储、检索的核心对象,包含文本内容、元数据等信息,与向量一一对应。
-
文档解析器
ApachePdfBoxDocumentParser:基于Apache PDFBox开源库实现,专门用于解析PDF文档,支持复杂PDF(如带图片、表格的PDF,但表格文本可能无法完全解析)通用文本处理:TXT、DOCX、DOC等文本文件无需专用解析器,可直接通过文件读取方法获取文本内容,再封装为Document对象。
-
文档分块器
-
核心类与方法:DocumentSplitters.recursive(maxSegmentSize, overlapSize),属于递归分块器,是项目中使用的核心分块工具。
-
官方职责:将长文档切分为多个小片段TextSegment,适配模型的上下文窗口,避免因文本过长超出模型输入限制。
-
参数详情:
-
512:每个片段的最大长度(单位:字符),需根据向量模型的输入限制调整。
-
128:相邻片段的重叠长度(单位:字符),核心作用是保证语义连续性,避免一句话被拆分导致语义断裂。
-
-
实践建议:长文本必须切分;短文本(<200字符)建议不切分;数字、时间、关键词等短关键信息需保持完整,避免切分后丢失核心信息。
-
-
模型相关
ChatModel:对话大模型接口,负责最终的问答生成,项目中使用OpenAiChatModel实现类(兼容DeepSeek接口),调用DeepSeek Chat模型。EmbeddingModel:向量模型接口,负责将文本片段转为高维向量,项目中使用OpenAiEmbeddingModel实现类(兼容阿里云接口),调用阿里云text-embedding-v1模型。
-
向量存储与检索
EmbeddingStore:向量存储抽象接口,用于存储"向量-文本片段"的映射关系,本例使用InMemoryEmbeddingStore内存向量库,轻量、无需部署,适合演示和小规模测试;生产环境可替换为ElasticSearch、PGVector等。EmbeddingStoreContentRetriever:内容检索器,RAG检索端核心组件,负责将用户问题向量化、在向量库中检索相关片段,无需手动实现检索逻辑,简化开发。- 向量检索官方行为:根据用户问题生成向量,在向量库中进行相似度检索,返回最相关的Top-K片段(项目中K=10)。
-
AI 服务封装
AiServices:简化 AI 服务构建,绑定模型与检索器@SystemMessage:注解式定义系统提示词
工程实践与优化
- 批处理优化
- 向量生成分批调用(项目中batchSize=20),避免单次请求超出向量模型的接口频率/数量限制,提升接口调用的稳定性。
- 文本分块策略
- 差异化分块:短文本直接保留,长文本自动切块,既保证短文本的语义完整性,又避免长文本超出模型输入限制。
- 关键注意:短文本(<15字)语义向量表达较弱,检索相似度偏低,建议不切分,并适当提高maxResults,结合关键词检索提升精度。
- 低耦合设计
- 组件可替换:模型(对话模型、向量模型)、向量库、文档解析器均可灵活替换,无需修改整体代码结构,便于后续扩展和迭代。
- 模块化设计:将RAG流程拆分为模型初始化、文档加载、分块、向量生成、检索、问答等独立模块,职责清晰,便于维护和调试。
- 鲁棒性处理
- 文件遍历容错:通过try-catch捕获单个文件的加载、解析异常,确保单个文件处理失败不影响整体流程的执行。
- 格式兼容:针对不同格式的文档(PDF、Word、TXT)采用差异化的解析方案,提升项目的兼容性。
加载文件:
遍历文件夹 → 判断后缀 → 选择解析器 → 解析 → 加入列表
Files.walk(文件夹)
.filter(是文件)
.forEach(文件 -> {
if (pdf) 用 PDF 解析器
if (docx) 用 Word 解析器
if (txt) 用 纯文本解析器
})FileSystemDocumentLoader
FileSystemDocumentLoader 支持自动加载 PDF / Word / TXT
PDF 自动加载必须满足两个条件:
- 引入 langchain4j-document-parser-apache-pdfbox 依赖
- 解析器通过 SPI 自动注册
手动加载 PDF 是兼容写法,适用于所有版本
批量加载标准实现
1. 遍历目标目录,获取所有文件;
2. 根据文件后缀判断文件类型;
3. 获取系统中注册的对应DocumentParser;
4. 调用parser.parse(inputStream)解析单个文件,生成Document对象;
5. 收集所有Document对象到列表,完成批量加载。核心总结:批量加载 = 文件遍历 + 循环调用单个解析器,DocumentParser仅负责单个文件解析,不具备批量处理能力。
PDF 解析与文本清洗
PPDF 格式内部按行 / 块存储,解析后天然包含大量换行、空格、分段
这些符号会降低向量相似度,导致检索匹配失败
属于PDF 格式特性,非解析器错误,
必须进行文本清洗
- 去除换行符 \n
- 去除回车符 \r
- 多个空格合并为单个空格
- 去除首尾空白
DocumentParser
DocumentParser 是单个文件解析器
不提供批量能力、不提供遍历能力
职责:将 InputStream → 解析为 1 个 Document
文档分块(Document Splitting)
- DocumentSplitter 官方职责
官方定义:
将长文档切分为多个小片段 TextSegment,适配模型上下文窗口。 - recursive(512, 128) 官方行为
512:最大片段长度
128:片段重叠长度(保证语义连续性)
实践:
长文本必须切分
短文本(<200)建议不切分
数字、时间、关键词等短关键信息应保持完整
Embedding & Retrieval 规则
-
向量检索官方行为
根据用户问题生成向量
在向量库中做相似度检索
返回最相关的 Top-K 片段
-
对短文本的检索说明
短文本(<15 字)语义向量表达较弱
检索相似度偏低
建议:
不切分
适当提高 maxResults
结合关键词检索
流程图
开始
↓
【初始化模型】
├─ 对话模型:DeepSeek Chat
└─ 向量模型:阿里云 text-embedding-v1
↓
【遍历指定文件夹】
↓
判断文件类型
├─ .pdf → Apache PdfBox 解析 → 生成 Document
├─ .doc/.docx/.txt → 直接读取文本 → 生成 Document
└─ 其他文件 → 跳过
↓
【文档清洗】
去换行、去空格、统一格式
↓
【智能分块】
├─ 文本长度 < 300 → 直接作为片段
└─ 文本长度 ≥ 300 → 按 512 字符分块,重叠 128
↓
【批量生成向量】
调用向量模型 → 得到文本片段向量
↓
【存入内存向量库】
InMemoryEmbeddingStore
↓
【构建检索器】
EmbeddingStoreContentRetriever
↓
【创建 AI 助手】
绑定对话模型 + 检索器
↓
【用户提问】
例:创始人、成立时间、公司名称
↓
【RAG 检索】
问题向量化 → 向量库匹配 → 返回最相关10条片段
↓
【AI 生成回答】
仅依据检索内容作答,不编造
↓
输出答案
↓
结束