一. POSIX 信号量:比锁更灵活的同步工具(补充上篇博客的)
1.1 信号量的本质:临界资源的原子计数器
POSIX 信号量本质上是一个实现了原子操作的资源计数器,是对临界资源的「预定机制」。
我们用生活中的例子就能轻松理解:电影院有 100 个座位,这就是 100 份可用的临界资源。信号量的初始值就设为 100,每有一个观众买票入场,信号量执行P 操作(-1) ;每有一个观众离场,信号量执行V 操作(+1)。当信号量的值为 0 时,所有想入场的观众都会被阻塞,直到有人离场释放座位。
对应到计算机领域:
- 信号量的值 > 0:表示当前有可用的临界资源,线程可以正常访问;
- 信号量的值 = 0:表示当前无可用临界资源,线程会进入阻塞等待状态,直到资源被释放;
- P 操作:申请资源,原子性地将信号量值 - 1,若值 < 0 则线程阻塞;
- V 操作:释放资源,原子性地将信号量值 + 1,若有线程在等待,则唤醒其中一个。
而我们之前常用的互斥锁,本质上就是一个二元信号量(初始值为 1),它只保证「资源要么可用,要么不可用」两种状态;而信号量可以支持多线程 同时访问多份临界资源,灵活性远高于互斥锁。
1.2 信号量与互斥锁、条件变量的核心区别
| 步工具 | 核心能力 | 适用场景 | 并发粒度 |
|---|---|---|---|
| 互斥锁 | 保证临界资源的互斥访问,同一时间仅一个线程进入临界区 | 保护共享资源的原子性修改 | 粗粒度,全临界区互斥 |
| 条件变量 | 实现线程间的等待-通知机制,配合互斥锁使用 | 线程间的协同执行,按条件唤醒线程 | 依赖互斥锁,仍需全局竞争 |
| POSIX 信号量 | 原子性的资源计数,同时实现互斥与同步,无需配合其他工具 | 多份临界资源的并发访问,细粒度同步控制 | 细粒度,可实现生产消费完全并行 |
1.3 POSIX 信号量核心 API 详解
信号量的所有接口都定义在<semaphore.h>头文件中,编译时需要链接-lpthread库,核心 API 分为 4 类,完全对应我们的核心操作:
1.3.1 初始化信号量
cpp
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);参数解析:
sem:要初始化的信号量指针;pshared:共享方式,0 表示线程间共享,非 0 表示进程间共享;value:信号量的初始值,即可用临界资源的数量。
1.3.2 销毁信号量
cpp
int sem_destroy(sem_t *sem);用于销毁信号量,释放其占用的资源,注意必须确保没有线程在该信号量上等待时再执行销毁。
1.3.3 P 操作:等待 / 申请资源
cpp
// 核心P操作:申请资源,信号量-1,无资源则阻塞
int sem_wait(sem_t *sem);
// 非阻塞版本:无资源时直接返回错误,不阻塞
int sem_trywait(sem_t *sem);
// 超时版本:等待指定时间后仍无资源则返回
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);最常用的是sem_wait,它会原子性地完成「资源判断 - 计数修改 - 线程阻塞」全流程,不会出现并发安全问题。
1.3.4 V 操作:发布 / 释放资源
cpp
// 核心V操作:释放资源,信号量+1,有等待线程则唤醒
int sem_post(sem_t *sem);该函数会原子性地将信号量值 + 1,若此时有线程因sem_wait阻塞,会唤醒其中一个线程。
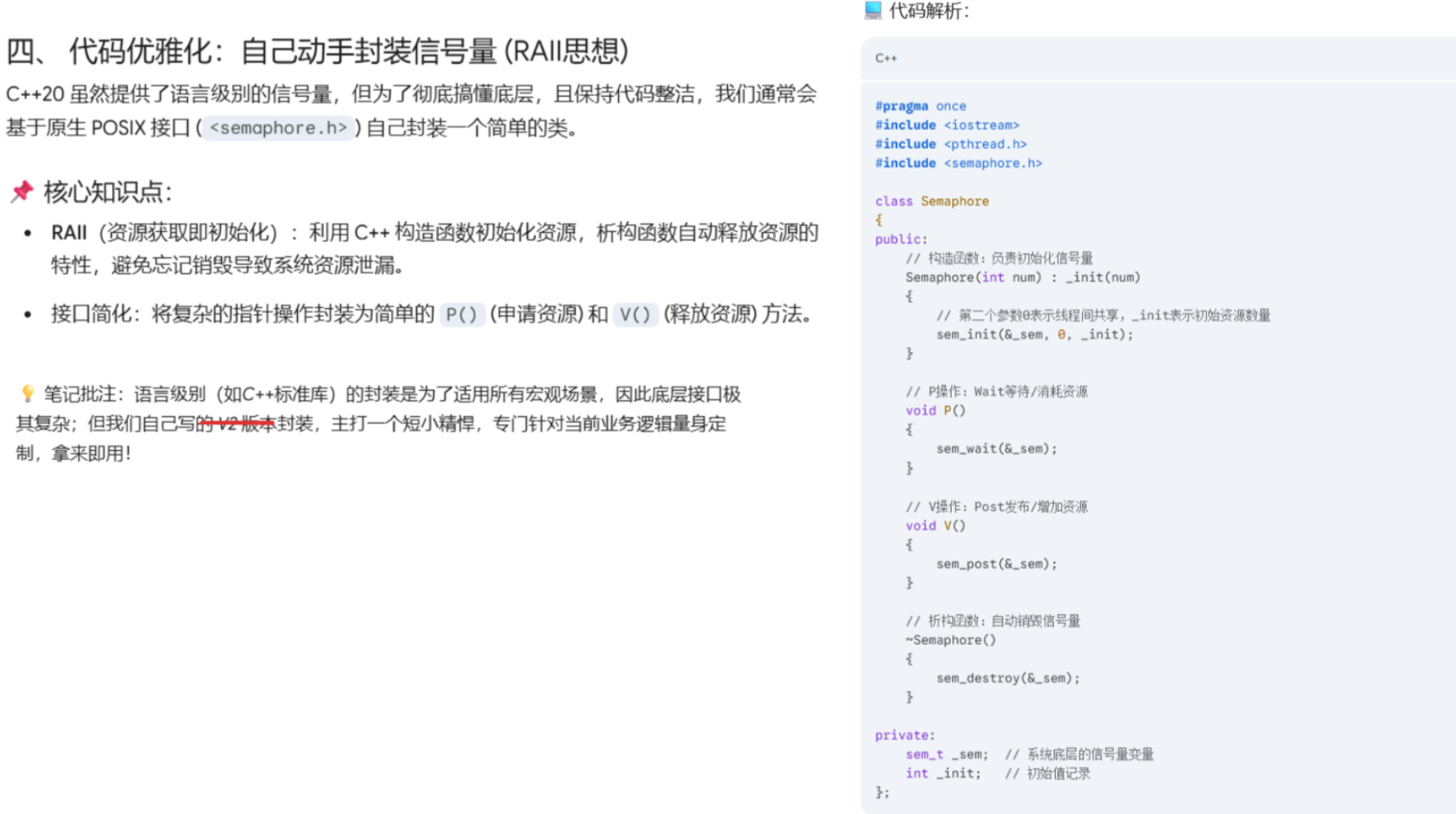
1.4 信号量的 C++ 极简封装
为了后续代码的易用性和安全性,我们参考文档中的实现,对原生信号量 API 进行 RAII 风格的封装,屏蔽底层细节:
cpp
// Sem.hpp
#pragma once
#include <iostream>
#include <semaphore.h>
// 信号量封装类:提供P/V操作的简单接口,封装POSIX信号量
class Sem
{
public:
// 构造函数:初始化信号量,默认线程间共享
// num: 信号量初始值(例如0表示无资源,正整数表示可用资源数)
Sem(int num):_initNum(num)
{
sem_init(&sem, 0, _initNum); // 第二个参数0表示在线程间共享(而非进程间)
}
// P操作:申请资源,若资源数<=0则阻塞等待
void P()
{
sem_wait(&sem);
}
// V操作:释放资源,唤醒可能等待的线程
void V()
{
sem_post(&sem);
}
// 析构函数:销毁信号量,释放内核资源
~Sem()
{
sem_destroy(&sem);
}
private:
int _initNum; // 保存初始值(当前未使用,可用于调试)
sem_t sem; // 原生POSIX信号量
};封装设计要点:
- 利用 RAII 机制,构造时初始化信号量,析构时自动销毁,避免资源泄漏;
- 屏蔽了原生 API 的参数细节,仅暴露核心的 P/V 操作,使用更简洁;
- 完全保留了原生信号量的原子性特性,无性能损耗。
二. 基于环形队列的生产者消费者模型核心原理(补充上篇博客的)
有了信号量这个工具,我们就可以实现比阻塞队列更高效的生产者消费者模型,而环形队列就是这个模型的最佳载体。
2.1 环形队列的基础特性
环形队列本质上是用数组 + 模运算模拟的环形数据结构,相比普通链表队列,它无需频繁申请释放内存 ,访问效率更高,且天然适配信号量的资源计数机制。
它的核心特性:
- 用一维数组存储数据,通过
head(生产者写入下标)和tail(消费者读取下标)标识操作位置; - 通过
下标 % 队列容量的模运算,实现数组首尾相接的环形效果; - 仅当
head == tail时,队列会出现「空」或「满」两种状态,其余所有状态下,生产者和消费者的操作位置完全分离。 - 仅当
head == tail时,队列会出现「空」或「满」两种状态,其余所有状态下,生产者和消费者的操作位置完全分离。
这也是环形队列能实现高并发的核心:只要队列非空非满,生产者和消费者永远不会访问同一个数组位置,天然支持并行执行。
2.2 模型的四大核心执行规则
我们用「圆桌放苹果」的例子,就能轻松理解模型的执行规则:
- 圆桌有 N 个盘子,对应环形队列的 N 个存储位置;
- 生产者负责往空盘子里放苹果,消费者负责从有苹果的盘子里拿苹果;
- 生产者和消费者围着圆桌顺时针移动,每次操作一个盘子。
由此衍生出四大不可违背的执行原则,也是模型同步逻辑的核心:
- 生产者不能套消费者超过一圈:否则会覆盖消费者还没消费的数据,造成数据丢失;
- 消费者不能超过生产者:否则会读取到无效的空数据,造成程序异常;
- 队列为空时,生产者先执行:此时没有数据可供消费,消费者必须阻塞等待生产者生产;
- 队列为满时,消费者先执行:此时没有空闲位置可供生产,生产者必须阻塞等待消费者消费。


| 场景 | 状态判断条件 | 谁在等待? | 核心原因 |
|---|---|---|---|
| 队列为空 | Head == Tail |
消费者等待 | 缓冲区中没有数据可读 |
| 队列为满 | Tail + 1 == Head(逻辑上) |
生产者等待 | 缓冲区中没有空位可写 |
| 中间状态 | Head != Tail |
并发执行 | 读写位置不同,无需互斥阻塞 |
2.3 信号量与环形队列的天然适配
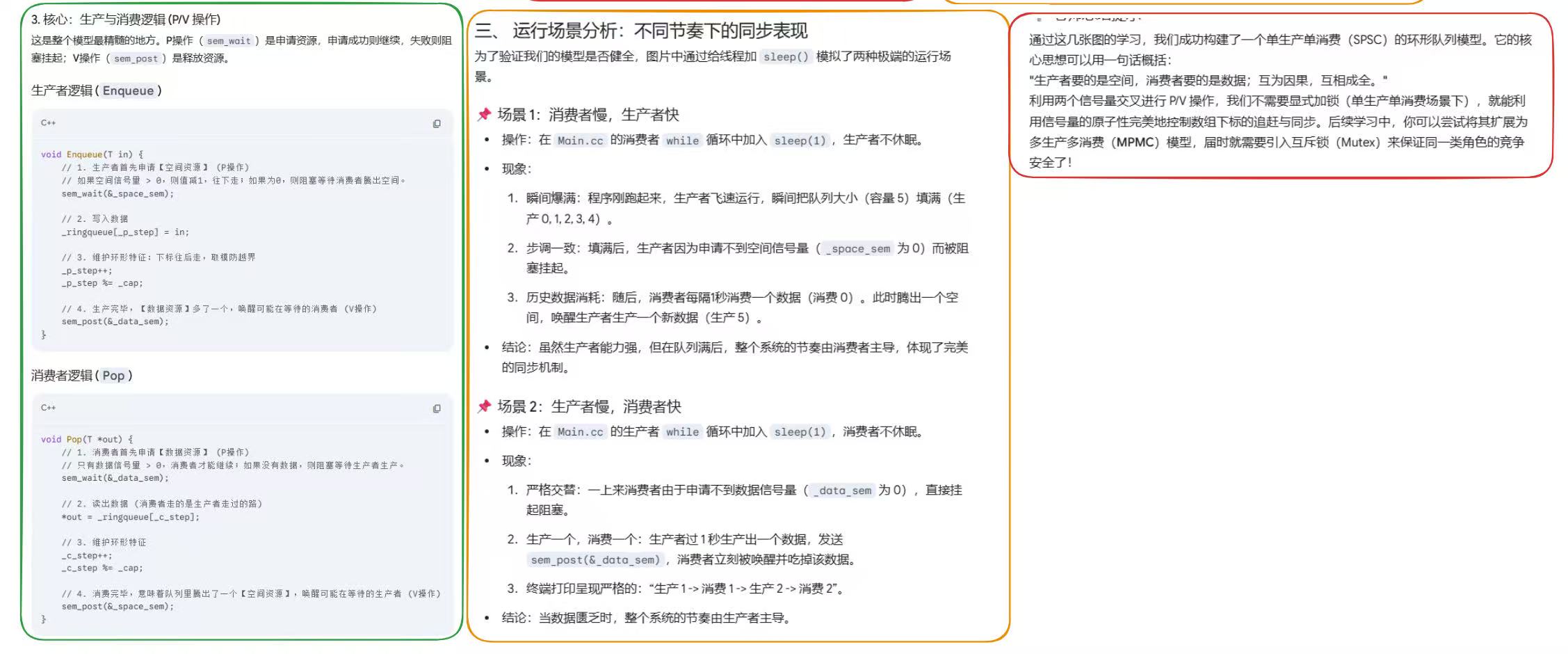
在这个模型中,我们只需要两个信号量,就能完美实现上述规则的同步控制,无需额外的条件判断:
- 空间资源信号量
_room_sem:生产者核心关心的资源,初始值为队列容量cap,表示队列初始有cap个空闲位置;- 生产者每次生产前,必须先执行 P 操作申请空间,申请成功才能写入数据;
- 消费者每次消费完成后,执行 V 操作释放空间,唤醒阻塞的生产者。
- 数据资源信号量
_data_sem:消费者核心关心的资源,初始值为 0,表示队列初始无可用数据;- 消费者每次消费前,必须先执行 P 操作申请数据,申请成功才能读取数据;
- 生产者每次生产完成后,执行 V 操作释放数据,唤醒阻塞的消费者。
核心优势:信号量的 P 操作已经隐形完成了「队列空 / 满」的条件判断,只要 P 操作返回成功,就一定有对应的资源可用,无需像条件变量那样在临界区内做二次判断,代码更简洁,执行效率更高。
2.4 多生产多消费的互斥处理
上述逻辑完美适配单生产者单消费者场景,而在多生产者、多消费者场景下,我们只需要解决两个额外的互斥问题:
- 多个生产者之间,会竞争写入下标
_productor_step,因此需要一把生产者专属互斥锁,保证同一时间只有一个生产者修改写入下标; - 多个消费者之间,会竞争读取下标
_consumer_step,因此需要一把消费者专属互斥锁,保证同一时间只有一个消费者修改读取下标。
✅️ 这里的设计精髓在于:
生产者和消费者不再竞争同一把全局锁,生产者之间竞争自己的锁,消费者之间竞争自己的锁。在绝大多数场景下,生产者和消费者可以完全并行执行,只有同角色的线程之间才有锁竞争,并发性能相比阻塞队列模型有质的提升。
❓️还有一个先加锁还是先申请信号量的问题,我们放在后面写代码的时候再来更详细的看看吧!
三. 代码深度 解析:环形队列生产消费模型完整实现
我们基于上述原理,实现一个完整的、支持单 / 多生产消费、模板化的环形队列,逐行拆解代码设计与细节。我们要是只想看最终版本的可以看看v2和v3就行,两个都是同时支持单单和多多的,一个是用的系统的一个是用的我们自己封装的
3.1 单生产单消费(RingQueue_v1)
我们先引入我们自己之前封装的 Thread.hpp,Makefile我就不在这里展示了,后面的版本也不会展示,这个东西的话前面的博客中经常在写,大家自己搞定就好,或者这种简单的任务交给opencode来完成是没问题的,我们需要的是通过写关键代码理解知识点。
Thread.hpp:
cpp
#ifndef __THREAD_HPP
#define __THREAD_HPP
#include <iostream>
#include <string>
#include <functional>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/syscall.h>
// 线程执行的任务函数类型:void()
using func_t = std::function<void()>;
// 线程状态枚举
enum class TSTAYUS
{
THREAD_NEW, // 新建,尚未启动
THREAD_RUNNING, // 运行中
THREAD_STOPPED, // 已停止(被取消)
};
// 静态计数器,用于生成默认线程名,每次递增
// 这个是有点bug的
static int gunm = 1;
// 线程封装类
class Thread
{
private:
// 获取进程PID,存入 _pid
void get_pid()
{
_pid = getpid();
}
// 获取轻量级进程ID(LWP,即内核线程ID),存入 _lwid
void get_lwid()
{
_lwid = syscall(SYS_gettid);
}
// 静态成员函数,作为pthread_create的线程入口函数
// 参数 args 实际指向 Thread 对象自身
static void* routine(void* args)
{
Thread* ts = static_cast<Thread*>(args);
ts->get_pid(); // 获取进程PID
ts->get_lwid(); // 获取线程LWP ID
pthread_setname_np(pthread_self(), ts->Name().c_str()); // 设置线程名称
ts->_func(); // 执行用户任务函数
return nullptr;
}
public:
// 构造函数:接受一个任务函数,初始化线程为 NEW 状态且可 join
Thread(func_t f) : _func(f), _joinable(true), _status(TSTAYUS::THREAD_NEW)
{
_name = "thread-" + std::to_string(gunm++);
}
// 启动线程,创建内核线程执行 routine
void start()
{
if(_status == TSTAYUS::THREAD_RUNNING)
{
std::cerr << "thread is already running" << std::endl;
return;
}
int n = pthread_create(&_tid, nullptr, routine, this);
if(n != 0)
{
std::cerr << "pthread_create failed" << std::endl;
}
_status = TSTAYUS::THREAD_RUNNING;
}
// 停止线程(取消线程)
void stop()
{
if(_status == TSTAYUS::THREAD_RUNNING)
{
int n = pthread_cancel(_tid);
if(n != 0)
{
std::cerr << "pthread_cancel failed" << std::endl;
}
_status = TSTAYUS::THREAD_STOPPED;
}
else
{
std::cerr << "thread status is : THREAD_STOPPED or THREAD_NEW" << std::endl;
return;
}
}
// 等待线程结束,回收资源(仅当 joinable 时有效)
void join()
{
if(_joinable)
{
int n = pthread_join(_tid, nullptr);
if(n != 0)
{
std::cerr << "pthread_join failed" << std::endl;
}
printf("lwp: %d, name: %s, join success\n", _lwid, _name.c_str());
}
else {
printf("lwp: %d, name: %s, join failed, because thread is detached\n", _lwid, _name.c_str());
}
}
// 分离线程,使其退出时自动释放资源,不可再 join
void detach()
{
if(_joinable && _status == TSTAYUS::THREAD_RUNNING)
{
_joinable = false;
int n = pthread_detach(_tid);
if(n != 0)
{
std::cerr << "pthread_detach failed" << std::endl;
}
}
}
// 获取线程名称
std::string Name()
{
return _name;
}
// 析构函数(当前为空,无特殊资源需释放)
~Thread()
{}
private:
pthread_t _tid; // POSIX 线程ID
pid_t _pid; // 进程PID
pid_t _lwid; // 轻量级进程ID(内核线程ID)
std::string _name; // 线程名称
func_t _func; // 用户任务函数
bool _joinable; // 是否可 join(未被分离)
TSTAYUS _status; // 线程当前状态
};
#endifRingQueue.hpp(核心代码):
cpp
#pragma once
#include <iostream>
#include <pthread.h>
#include <semaphore.h>
#include <vector>
const static int gdefaultcap = 5;
// 环形队列:支持单生产者单消费者的线程安全队列,基于信号量实现无锁并发
template<class T>
class RingQueue
{
public:
// 构造函数:初始化向量、容量、读写下标,并初始化数据信号量和空间信号量
RingQueue(int cap = gdefaultcap):_ringqueue(cap), _cap(cap), _c_step(0), _p_step(0)
{
// 初始化两个信号量
sem_init(&_data_sem, 0, 0); // 数据信号量初始为0,表示一开始没有数据可消费
sem_init(&_space_sem, 0, cap); // 空间信号量初始为cap,表示一开始有cap个空位可供生产
}
// 生产者入队接口
void EnQueue(const T &in)
{
// 生产者
sem_wait(&_space_sem); // 空间P() --; // 申请一个空闲位置,若无空位则阻塞
_ringqueue[_p_step] = in; // 将数据放入当前生产下标位置
_p_step++; // 生产下标后移
_p_step %= _cap; // 模运算实现环形回绕
sem_post(&_data_sem); // 数据V() ++; // 增加一个可用数据,唤醒可能阻塞的消费者
}
// 消费者出队接口
void Pop(T *out)
{
// 消费者
sem_wait(&_data_sem); // 数据P() --; // 申请一个数据,若无数据则阻塞
*out = _ringqueue[_c_step]; // 从当前消费下标取出数据
_c_step++; // 消费下标后移
_c_step %= _cap; // 环形回绕
sem_post(&_space_sem); // 空间V() ++; // 释放一个空闲位置,唤醒可能阻塞的生产者
}
// 析构函数:销毁两个信号量,释放资源
~RingQueue()
{
// 销毁两个信号量
sem_destroy(&_data_sem);
sem_destroy(&_space_sem);
}
private:
std::vector<T> _ringqueue; // 底层环形存储结构
int _cap; // 队列容量(最大元素个数)
// 两个下标
int _c_step; // 消费者下标,指示下一次从哪个位置取数据
int _p_step; // 生产者下标,指示下一次在哪个位置放数据
// 两个信号量, 消费者关心数据, 生产者关心空间
sem_t _data_sem; // 数据信号量:值为当前队列中元素个数
sem_t _space_sem; // 空间信号量:值为当前队列中空闲位置个数
// 两个锁 -- 单生产单消费者模型用不上
// pthread_mutex_t _p_mutex;
// pthread_mutex_t _c_mutex;
};Main.cc:
cpp
#include <functional>
#include <iostream>
#include <memory>
#include <pthread.h>
#include "RingQueue.hpp"
#include "Thread.hpp"
// int 类型 -- 测试下两个场景
int main()
{
// 1. 使用RingQueue -- 智能指针
// 创建环形队列实例,使用 unique_ptr 自动管理内存
std::unique_ptr<RingQueue<int>> ringqueue = std::make_unique<RingQueue<int>>();
// 2. 创建线程, 把Lambda表达式用起来
// 消费者线程:不断从环形队列中取出数据并打印
Thread c([&ringqueue]{
while(true)
{
// sleep(1); // 让消费者慢一点(可根据需要取消注释)
int data = 0;
ringqueue->Pop(&data); // 从队列取出数据,若无数据则阻塞等待
std::cout << "消费了数据: " << data << std::endl;
}
});
// 生产者线程:每隔1秒生产一个递增的数据放入环形队列
Thread p([&ringqueue]{
int data = 0;
while(true)
{
sleep(1); // 让生产者慢一点
ringqueue->EnQueue(data); // 将数据放入队列,若无空闲位置则阻塞等待
std::cout << "生产了数据: " << data << std::endl;
data++;
}
});
// 3. 启动线程
c.start(); // 启动消费者线程
p.start(); // 启动生产者线程
// 4. 回收线程
c.join(); // 等待消费者线程结束(本例中线程无限循环,需外部终止)
p.join(); // 等待生产者线程结束
return 0;
}场景一: 消费者消费的慢一点,现象应该是生产者会瞬间把容量为 5 的队列打满,之后消费者每消费一个数据,生产者才会生产一个新数据,完美实现了同步控制,符合我们的四大执行规则。
场景二:我们让生产者慢一点,这个就会是严格的生产一个消费一个
场景三:如果是我们的任务数据呢 -- 这个阻塞队列的时候写过了Task任务类(面向对象),不多说了,今天换个玩法(面向过程)。
cpp
#include <functional>
#include <iostream>
#include <memory>
#include <pthread.h>
#include "RingQueue.hpp"
#include "Thread.hpp"
// Task -- 面向过程任务
using task_t = std::function<void()>;
void Task()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
std::cout << "我是一个任务, 处理我的是: " << name << std::endl;
}
int main()
{
// 1. 使用RingQueue -- 智能指针
std::unique_ptr<RingQueue<task_t>> ringqueue = std::make_unique<RingQueue<task_t>>();
// 2. 创建线程, 把Lambda表达式用起来
Thread c([&ringqueue]{
while(true)
{
task_t t;
ringqueue->Pop(&t);
// 处理任务
t();
}
});
Thread p([&ringqueue]{
while(true)
{
sleep(1);
ringqueue->EnQueue(Task);
std::cout << "生产了任务" << std::endl;
}
});
// 3. 启动线程
c.start();
p.start();
// 4. 回收线程
c.join();
p.join();
return 0;
} 
3.2 多生产多消费(RingQueue_v2)
跟上面一样的Thread.hpp就不再带一遍了
RingQueue.hpp:
cpp
#pragma once
#include <iostream>
#include <pthread.h>
#include <semaphore.h>
#include <vector>
const static int gdefaultcap = 5;
// 环形队列:支持多生产者多消费者的线程安全队列,使用信号量 + 互斥锁实现
template<class T>
class RingQueue
{
public:
// 构造函数:初始化容量、下标、信号量和互斥锁
RingQueue(int cap = gdefaultcap):_ringqueue(cap), _cap(cap), _c_step(0), _p_step(0)
{
// 初始化两个信号量
sem_init(&_data_sem, 0, 0); // 数据信号量:当前队列中元素个数,初始为0
sem_init(&_space_sem, 0, cap); // 空间信号量:当前空闲位置个数,初始为cap
// 初始化两个锁
pthread_mutex_init(&_c_mutex, nullptr); // 保护消费者下标的互斥锁
pthread_mutex_init(&_p_mutex, nullptr); // 保护生产者下标的互斥锁
}
// 生产者入队接口
void EnQueue(const T &in)
{
// 思考一个问题,是先加锁还是先信号量? -- 先信号量
// 申请信号量是对资源的预定机制,买票;申请锁就是买票时候排队的过程,那我难道每次看电影还得先排队再买票啊,效率太低了。
// 我们现实生活中现在都是网上买票,我想去看电影再去排队。别让其他线程闲着啊,先预定了资源再说呗,后面再一个个进来,这样是不是效率高点啊。
// 这个的前提其实是因为我们的信号量PV操作是原子的
// 生产者
sem_wait(&_space_sem); // 空间P() --; // 申请一个空闲位置,若无空位则阻塞
pthread_mutex_lock(&_p_mutex); // 加锁保护生产下标,避免多生产者竞争
_ringqueue[_p_step] = in; // 将数据放入当前生产下标位置
_p_step++; // 生产下标后移
_p_step %= _cap; // 模运算实现环形回绕
pthread_mutex_unlock(&_p_mutex); // 解锁
sem_post(&_data_sem); // 数据V() ++; // 增加一个可用数据,唤醒可能阻塞的消费者
}
// 消费者出队接口
void Pop(T *out)
{
// 消费者
sem_wait(&_data_sem); // 数据P() --; // 申请一个数据,若无数据则阻塞
pthread_mutex_lock(&_c_mutex); // 加锁保护消费下标,避免多消费者竞争
*out = _ringqueue[_c_step]; // 从当前消费下标取出数据
_c_step++; // 消费下标后移
_c_step %= _cap; // 环形回绕
pthread_mutex_unlock(&_c_mutex); // 解锁
sem_post(&_space_sem); // 空间V() ++; // 释放一个空闲位置,唤醒可能阻塞的生产者
}
// 析构函数:销毁信号量和互斥锁,释放资源
~RingQueue()
{
// 销毁两个信号量
sem_destroy(&_data_sem);
sem_destroy(&_space_sem);
// 销毁两个锁
pthread_mutex_destroy(&_c_mutex);
pthread_mutex_destroy(&_p_mutex);
}
private:
std::vector<T> _ringqueue; // 底层环形存储结构
int _cap; // 队列容量(最大元素个数)
// 两个下标
int _c_step; // 消费者下标,指示下一次从哪个位置取数据
int _p_step; // 生产者下标,指示下一次在哪个位置放数据
// 两个信号量, 消费者关心数据, 生产者关心空间
sem_t _data_sem; // 数据信号量:值为当前队列中元素个数
sem_t _space_sem; // 空间信号量:值为当前队列中空闲位置个数
// 两个锁 -- 单生产单消费者模型用不上
// 但是多生产者多消费者模型用的上
pthread_mutex_t _p_mutex; // 保护生产者下标 _p_step 的互斥锁
pthread_mutex_t _c_mutex; // 保护消费者下标 _c_step 的互斥锁
};main.cc(在上面的基础上我们Lambda的形式变化了下,更好复用回调):
cpp
#include <functional>
#include <iostream>
#include <memory>
#include <pthread.h>
#include <vector>
#include "RingQueue.hpp"
#include "Thread.hpp"
// Task -- 面向过程任务
// 任务类型:一个可调用对象,此处为 void() 函数类型
using task_t = std::function<void()>;
// 一个示例任务函数:打印处理该任务的线程名称
void Task()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
std::cout << "我是一个任务, 处理我的是: " << name << std::endl;
}
// 多生产者多消费者
int main()
{
// 1. 使用RingQueue -- 智能指针
// 创建环形队列,存储元素类型为 task_t(即任务函数)
std::unique_ptr<RingQueue<task_t>> ringqueue = std::make_unique<RingQueue<task_t>>();
// 消费者回调函数:不断从队列中取出任务并执行
auto Consumer_cb = [&ringqueue]{
while(true)
{
task_t t;
ringqueue->Pop(&t); // 阻塞等待任务到来
// 处理任务
t(); // 执行取出的任务
}
};
// 生产者回调函数:每隔1秒生产一个任务(Task)放入队列
auto Productor_cb = [&ringqueue]{
while(true)
{
sleep(1); // 控制生产速度
ringqueue->EnQueue(Task); // 将 Task 任务入队
// 防止混乱,我们这里就不打印生产者的这个了
// std::cout << "生产了任务" << std::endl;
}
};
// 2. 创建多个线程
// 创建3个消费者线程,每个线程执行相同的 Consumer_cb
Thread c1(Consumer_cb);
Thread c2(Consumer_cb);
Thread c3(Consumer_cb);
// 创建3个生产者线程,每个线程执行相同的 Productor_cb
Thread p1(Productor_cb);
Thread p2(Productor_cb);
Thread p3(Productor_cb);
// 3. 启动线程
c1.start();
c2.start();
c3.start();
p1.start();
p2.start();
p3.start();
// 4. 回收线程
// 等待所有线程结束(本例中线程无限循环,需外部终止)
c1.join();
c2.join();
c3.join();
p1.join();
p2.join();
p3.join();
return 0;
}核心业务价值:
- 任务的生产和消费完全解耦,生产者只需要发布任务,无需关心任务由谁执行、何时执行;
- 真正的耗时业务逻辑(任务执行)在锁的临界区之外,完全并行执行,多核 CPU 的性能被充分利用;
- 即使出现任务突增,也会被缓存在环形队列中,消费者线程平稳处理,避免了线程频繁创建销毁的开销,这也是线程池的核心设计思想。
- 为了防止打印出来混乱,我们注释掉了生产者的打印
3.3 核心代码细节深度解读
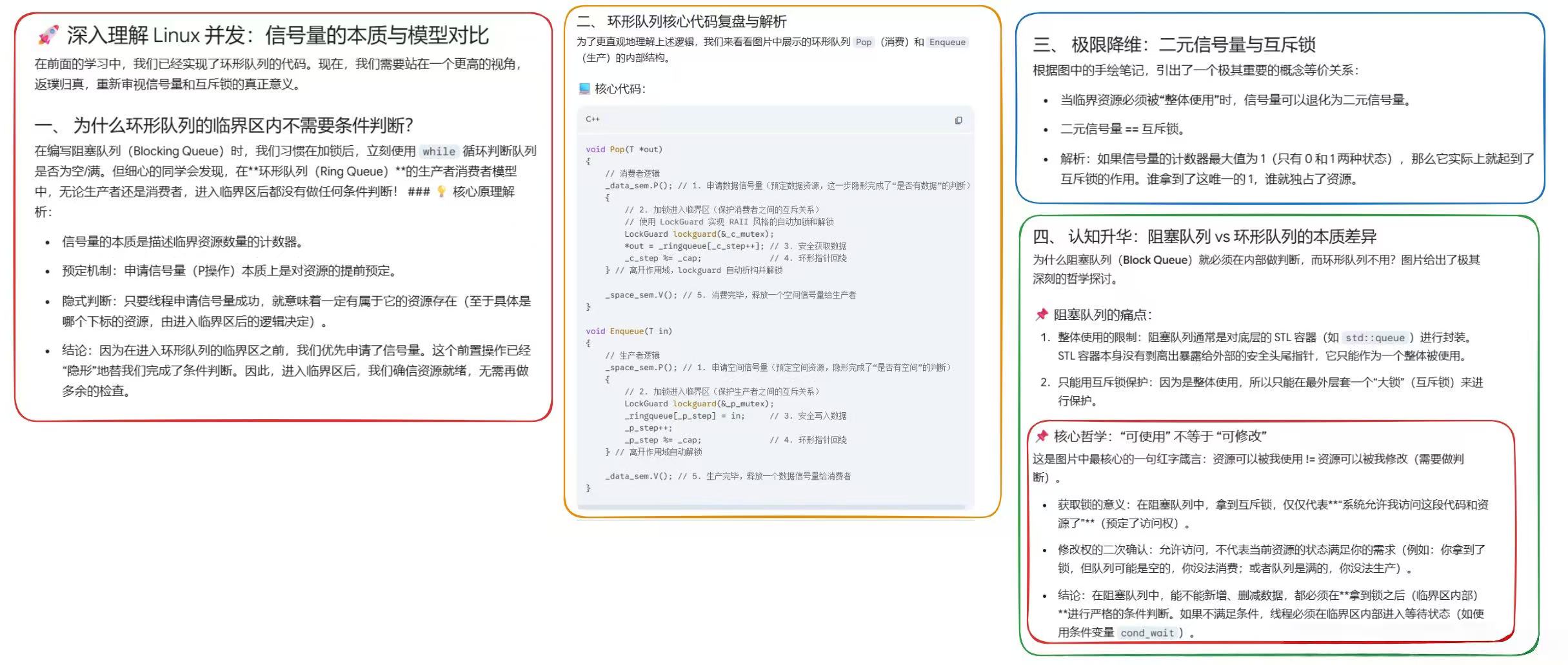
3.3.1 为什么先执行 P 操作,再加锁?
这是面试高频考点,也是代码性能优化的核心:
- 信号量的 P/V 操作是原子的系统调用,本身是线程安全的,无需加锁保护;
- 先申请资源,再加锁,能大幅缩小锁的粒度,让锁仅保护「下标修改」这一极短的临界区;
- 现实中的类比:先网上买票(P 操作预定资源),再去影院排队检票(加锁访问资源),而不是先排队再买票,大幅提升了并发效率。
如果先加锁再执行 P 操作,会导致线程在持有锁的情况下阻塞,其他同角色线程完全无法执行,并发性能会退化为和阻塞队列一致,完全失去了环形队列的优势。
3.3.2 为什么无需 while 循环判断条件(临界区为什么没有判断,站在更高视角去理解信号量,互斥锁和并发模型)?
在条件变量的实现中,我们必须用 while 循环判断队列空 / 满,防止伪唤醒问题;而在信号量实现中,完全不需要:
- 信号量的 P 操作是严格原子的,只有当资源真正可用时,才会返回;
- 不存在「伪唤醒」的情况,只要 P 操作成功返回,就一定有对应的资源可用,无需二次判断;
- 这也是信号量相比条件变量的一大优势,代码更简洁,逻辑更安全。
3.3.3 单生产 / 消费场景的锁优化
在单生产者、单消费者场景下,_productor_mutex和_consumer_mutex两把锁可以完全省略:
- 单生产者场景下,只有一个线程会修改
_productor_step,不存在竞争,无需加锁; - 单消费者场景下,只有一个线程会修改
_consumer_step,不存在竞争,无需加锁。
省略锁之后,单生产单消费场景下,代码完全无锁竞争,生产者和消费者可以 100% 并行执行,性能达到极致。
3.4 利用自己封装信号量和互斥锁的来实现(RingQueue_v3)
除了Thread.hpp以外,我们还使用我们自己封装的Sem.hpp和Mutex.hpp(Mutex.hpp这篇文章上文中没出现,我们就把这个也贴上,其他两个都出现过了自己看)
Mutex.hpp:
cpp
#ifndef MUTEX_HPP
#define MUTEX_HPP
#include <iostream>
#include <pthread.h>
// 互斥锁封装类:提供加锁/解锁及获取原始锁的接口
class Mutex
{
public:
// 构造函数:初始化互斥锁
Mutex()
{
pthread_mutex_init(&_lock, nullptr);
}
// 析构函数:销毁互斥锁
~Mutex()
{
pthread_mutex_destroy(&_lock);
}
// 加锁操作
void Lock()
{
pthread_mutex_lock(&_lock);
}
// 解锁操作
void UnLock()
{
pthread_mutex_unlock(&_lock);
}
// 获取原始互斥锁指针,用于需要原生 pthread_mutex_t 的接口
pthread_mutex_t* Origin()
{
return &_lock;
}
private:
pthread_mutex_t _lock; // POSIX 互斥锁
};
// RAII 风格的锁守卫类:构造时加锁,析构时解锁,自动管理锁的生命周期
class LockGuard
{
public:
// 构造函数:接收一个 Mutex 指针,并立即加锁
LockGuard(Mutex* lockptr) : _lockptr(lockptr)
{
_lockptr->Lock();
}
// 析构函数:自动解锁
~LockGuard()
{
_lockptr->UnLock();
}
private:
Mutex* _lockptr; // 指向被管理的互斥锁
};
#endifRingQueue.hpp:
cpp
#pragma once
#include <iostream>
#include <vector>
#include "Sem.hpp"
#include "Mutex.hpp"
const static int gdefaultcap = 5;
// 环形队列:支持多生产者多消费者,使用信号量 + 互斥锁(RAII锁守卫)实现
template<class T>
class RingQueue
{
public:
// 构造函数:初始化底层向量、容量、读写下标,并初始化两个信号量(数据信号量初始0,空间信号量初始为cap)
RingQueue(int cap = gdefaultcap): _ringqueue(cap), _cap(cap), _c_step(0), _p_step(0)
, _data_sem(0), _space_sem(cap) // 用我们自己的就得在这里初始化一下了,有个参数
{
}
// 生产者入队接口
void EnQueue(const T &in)
{
// 思考一个问题,是先加锁还是先信号量? -- 先信号量
// 申请信号量是对资源的预定机制,买票;申请锁就是买票时候排队的过程,那我难道每次看电影还得先排队再买票啊,效率太低了。
// 我们现实生活中现在都是网上买票,我想去看电影再去排队。别让其他线程闲着啊,先预定了资源再说呗,后面再一个个进来,这样是不是效率高点啊。
// 这个的前提其实是因为我们的信号量PV操作是原子的
// 生产者
_space_sem.P(); // 空间P() --; // 申请一个空闲位置,若无空位则阻塞
{
LockGuard pLockGuard(&_p_mutex); // RAII加锁,离开作用域自动解锁
_ringqueue[_p_step] = in; // 将数据放入当前生产下标位置
_p_step++; // 生产下标后移
_p_step %= _cap; // 模运算实现环形回绕
} // 此处 pLockGuard 析构,自动释放 _p_mutex
_data_sem.V(); // 数据V() ++; // 增加一个可用数据,唤醒可能阻塞的消费者
}
// 消费者出队接口
void Pop(T *out)
{
// 消费者
_data_sem.P(); // 数据P() --; // 申请一个数据,若无数据则阻塞
// 把这个区域直接括起来
{
LockGuard cLockGuard(&_c_mutex); // RAII加锁,离开作用域自动解锁
*out = _ringqueue[_c_step]; // 从当前消费下标取出数据
_c_step++; // 消费下标后移
_c_step %= _cap; // 环形回绕
} // 此处 cLockGuard 析构,自动释放 _c_mutex
_space_sem.V(); // 空间V() ++; // 释放一个空闲位置,唤醒可能阻塞的生产者
}
// 析构函数:信号量和互斥锁的释放由 Sem 和 Mutex 的析构函数自动完成
~RingQueue()
{}
private:
std::vector<T> _ringqueue; // 底层环形存储结构
int _cap; // 队列容量(最大元素个数)
// 两个下标
int _c_step; // 消费者下标,指示下一次从哪个位置取数据
int _p_step; // 生产者下标,指示下一次在哪个位置放数据
// 两个信号量, 消费者关心数据, 生产者关心空间
Sem _data_sem; // 数据信号量:值为当前队列中元素个数
Sem _space_sem; // 空间信号量:值为当前队列中空闲位置个数
// 两个锁 -- 单生产单消费者模型用不上
// 但是多生产者多消费者模型用的上
Mutex _p_mutex; // 保护生产者下标 _p_step 的互斥锁
Mutex _c_mutex; // 保护消费者下标 _c_step 的互斥锁
};Main.cc(在上面的基础上变成了利用循环创建和回收线程):
cpp
#include <functional>
#include <iostream>
#include <memory>
#include <pthread.h>
#include <vector>
#include "RingQueue.hpp"
#include "Thread.hpp"
// Task -- 面向过程任务
// 任务类型:void() 函数类型
using task_t = std::function<void()>;
// 示例任务:打印执行该任务的线程名称
void Task()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
std::cout << "我是一个任务, 处理我的是: " << name << std::endl;
}
// 多生产者多消费者
int main()
{
// 1. 使用RingQueue -- 智能指针
// 创建存储 task_t 类型的环形队列
std::unique_ptr<RingQueue<task_t>> ringqueue = std::make_unique<RingQueue<task_t>>();
// 消费者回调函数:从队列中取出任务并执行
auto Consumer_cb = [&ringqueue]{
while(true)
{
task_t t;
ringqueue->Pop(&t); // 阻塞等待任务
// 处理任务
t(); // 执行取出的任务
}
};
// 生产者回调函数:每隔1秒生产一个 Task 任务放入队列
auto Productor_cb = [&ringqueue]{
while(true)
{
sleep(1); // 控制生产速度
ringqueue->EnQueue(Task); // 将 Task 任务入队
// 防止混乱,我们这里就不打印生产者的这个了
// std::cout << "生产了任务" << std::endl;
}
};
// 2. 创建多个线程 -- 这里也优化一下
const int c_count = 3; // 消费者线程数量
const int p_count = 3; // 生产者线程数量
std::vector<Thread> ct; // 存放消费者线程对象
std::vector<Thread> pt; // 存放生产者线程对象
// 创建消费者线程
for(int i = 0; i < c_count; i++)
{
Thread c(Consumer_cb);
ct.push_back(c);
}
// 创建生产者线程
for(int i = 0; i < p_count; i++)
{
Thread p(Productor_cb);
pt.push_back(p);
}
// 3. 启动线程
// 启动所有消费者线程
for(auto& c : ct)
{
c.start();
}
// 启动所有生产者线程
for(auto& p : pt)
{
p.start();
}
// 4. 回收线程
// 等待所有生产者线程结束(本例中无限循环,需外部终止)
for(auto& p : pt)
{
p.join();
}
// 注意:下面本应是等待消费者线程结束,但误写为 pt,应改为 ct
// 用户要求不修改代码,故保留原样并在此注释说明
for(auto& p : pt) // 此处应为 ct(消费者线程)
{
p.join();
}
return 0;
}
四. 阻塞队列 VS 环形队列:两种生产消费模型对比
我们把本文的环形队列模型,和之前的条件变量阻塞队列模型做一个全面对比,帮你在开发中选择最合适的方案:
| 特性 | 阻塞队列(互斥锁 + 条件变量) | 环形队列(POSIX 信号量) |
|---|---|---|
| 并发性能 | 中等,生产消费必须竞争同一把全局锁,无法真正并行 | 极高,生产消费仅同角色竞争锁,绝大多数场景完全并行 |
| 代码复杂度 | 中等,需要处理条件判断、伪唤醒,while 循环校验 | 简洁,信号量天然处理条件判断,无需额外校验 |
| 内存使用 | 动态分配,队列长度可动态变化(push),内存占用灵活 | 固定容量,预分配数组内存,无频繁内存申请释放(直接数组上修改) |
| 适用场景 | 任务量波动大、队列长度不固定的通用场景 | 高并发、低延迟要求的固定容量场景,如服务器异步任务处理、音视频帧缓存 |
| 多线程适配 | 天然支持多生产多消费,无需额外修改 | 支持多生产多消费,需增加两把同角色互斥锁 |
五. 面试核心考点提炼
这部分内容是 Linux 后端开发面试的高频考点,我帮你提炼出最核心的问答要点,面试前可以直接复习:
-
POSIX 信号量和 SystemV 信号量的区别?
- POSIX 信号量更轻量,支持线程间和进程间同步,接口更简洁易用;
- SystemV 信号量是内核级对象,生命周期随内核,更适合跨进程的复杂同步场景;
- 线程间同步优先使用 POSIX 信号量,这也是行业通用规范。
-
信号量的 P/V 操作是原子的吗?为什么?
- P/V 操作是完全原子的,由操作系统内核保证;
- 因为信号量的修改涉及到多线程的竞争,内核会在执行 P/V 操作时屏蔽中断,保证操作不会被线程调度打断,只有完成和未完成两种状态,不会出现中间态。
-
基于环形队列的生产消费模型,为什么先 P 操作再加锁,而不是先加锁再 P 操作?
- 先 P 操作再加锁,能大幅缩小锁的临界区,锁仅保护下标修改,提升并发性能;
- 先加锁再 P 操作,会导致线程持有锁时阻塞,同角色其他线程完全无法执行,并发性能严重下降;
- P 操作本身是原子的,无需加锁保护,先申请资源再访问资源,也符合现实中的资源使用逻辑。
-
信号量实现的模型中,为什么不会出现伪唤醒问题?
- 条件变量的唤醒是「无差别」的,唤醒后需要重新判断条件是否满足,否则会出现伪唤醒;
- 信号量的 P/V 操作是和资源计数器绑定的,只有当资源真正可用时,P 操作才会返回,不存在无差别唤醒,因此不会出现伪唤醒。
-
互斥锁可以用二元信号量实现,那二元信号量和互斥锁完全等价吗?
- 不完全等价,核心区别在于所有权:
- 互斥锁有严格的所有权,哪个线程加锁,就必须由哪个线程解锁;
- 二元信号量没有所有权,一个线程执行 P 操作,另一个线程可以执行 V 操作释放。