一、串看起来像线性表,可它的思维重点不在线性表
从定义上说,串是由零个或多个字符组成的有限序列。空串、串长、子串、主串、模式串,这些概念本身并不难。真正要注意的是,串虽然形式上也是一个线性序列,但它和前面学过的线性表并不完全一样。在线性表里,我们更关心单个元素的插入、删除、查找,而在串里,真正有意义的操作往往不是针对某一个字符,而是针对整段字符序列。也就是说,串虽然长得像线性表,但它更强调整体性,而不是单点操作。
这也是为什么模式匹配会成为这一章的中心。因为在实际应用里,串最典型的任务并不是把某个字符删掉再加一个字符,而是在一段文本里判断某个模式是否出现过,出现在哪里。搜索引擎要做这件事,编辑器查找替换要做这件事,很多生物信息分析、日志检索和规则匹配也都在做这件事。串这一章真正有技术含量的部分,正是围绕这种需求展开。
存储结构当然仍然要学,因为算法总要落在实现上。定长顺序存储最直观,字符按连续空间摆开,访问方便,结构也简单,但长度受上界限制。堆分配存储让串长更灵活,适合动态变化的场景。块链存储则试图在链式组织和字符批量存放之间取得一个平衡。可如果从复习效率看,这部分不需要记得太散。你只要抓住一个共识就够了,也就是无论存储形式怎样变化,串最核心的应用仍然是匹配,而匹配算法的优劣,最终决定这一章的难度和价值。
二、暴力匹配并不低级,它是理解 KMP 的起点
很多人一看到暴力匹配,就会下意识地把它归类成基础算法,觉得只是一个过渡内容,真正重要的是后面的 KMP。实际上,暴力匹配不只是铺垫,它还是理解 KMP 必不可少的参照物。因为只有先看清暴力匹配到底把时间浪费在了哪里,后面你才能真正看懂 KMP 在节省什么。
暴力匹配的过程其实非常朴素。主串从某个位置开始,模式串从第一个字符开始,逐个比较。如果一路都相等,就继续向后推进;一旦某个位置失配,就把模式串整体右移一位,再从它的第一个字符重新和主串当前的新对齐位置开始比较。这个过程之所以叫暴力,并不是因为它写起来粗糙,而是因为它在失配之后没有保存足够多的历史信息。前面明明已经比对过的内容,很可能在下一轮又要再比一次。
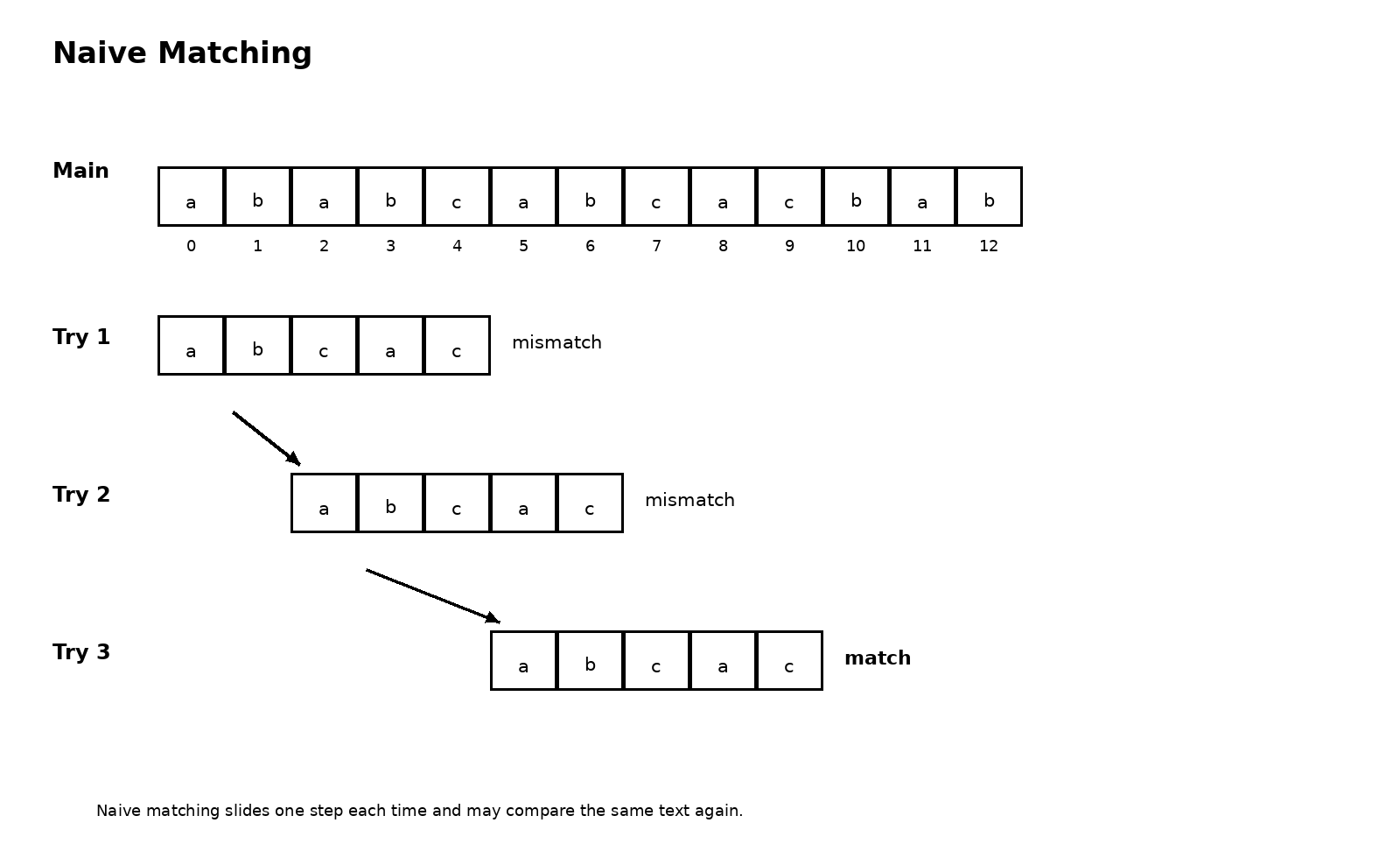
这一点在主串和模式串含有较多重复字符时尤其明显。比如主串中有大量相似前缀,模式串自己也有明显重复结构,那么一次失配之后,暴力匹配虽然把模式串向右移动了,但它并不知道前面那段已匹配信息其实部分仍然有用,于是只能老老实实回到模式串开头重新比。于是主串里的某些字符会被来回访问,模式串里的某些前缀也会被一遍遍试探。这就是它最核心的低效之处。
所以,复习暴力匹配时最值得记住的不是代码本身,而是一种问题意识。它为什么慢,不是因为比较操作本身慢,而是因为它在失配时没有聪明地利用过去。你一旦从这个角度去看,KMP 的出场就会显得非常自然。因为 KMP 所做的事,说到底就是一件事,尽量不让已经得到的信息白白浪费。
三、KMP 的难点不在跳得快,而在它凭什么敢跳
KMP 最让人困惑的地方通常不是结果,而是理由。很多人知道它在失配后不会让主串指针回退,也知道它的时间复杂度能做到 O(n + m),可一问为什么它可以这样做,就容易说得很虚。真正想明白 KMP,必须先想通一个问题。模式串在某个位置失配时,前面那一段已经匹配成功的字符,到底留下了什么有价值的信息。
答案就在前缀和后缀的关系里。假设模式串的前 j - 1 个字符已经和主串某一段成功匹配,这意味着这段模式前缀已经被主串确认过了。现在第 j 个字符失配,我们当然不能简单把模式串整个右移一位然后重头比较,因为前面那 j - 1 个字符内部本身可能含有重复结构。如果这段已匹配前缀的某个前缀,恰好也是它的后缀,那么模式串就没有必要回到开头,而是可以把这个相等的部分直接对齐过去,继续比较。
这就是部分匹配值真正想表达的意思。它衡量的不是某个字符有多特殊,而是当前前缀内部有多少可复用的自相似信息。一个前缀的最长相等前后缀越长,说明失配后越不需要从头再来,因为模式串自己已经告诉我们,前面有一段结构可以延续。
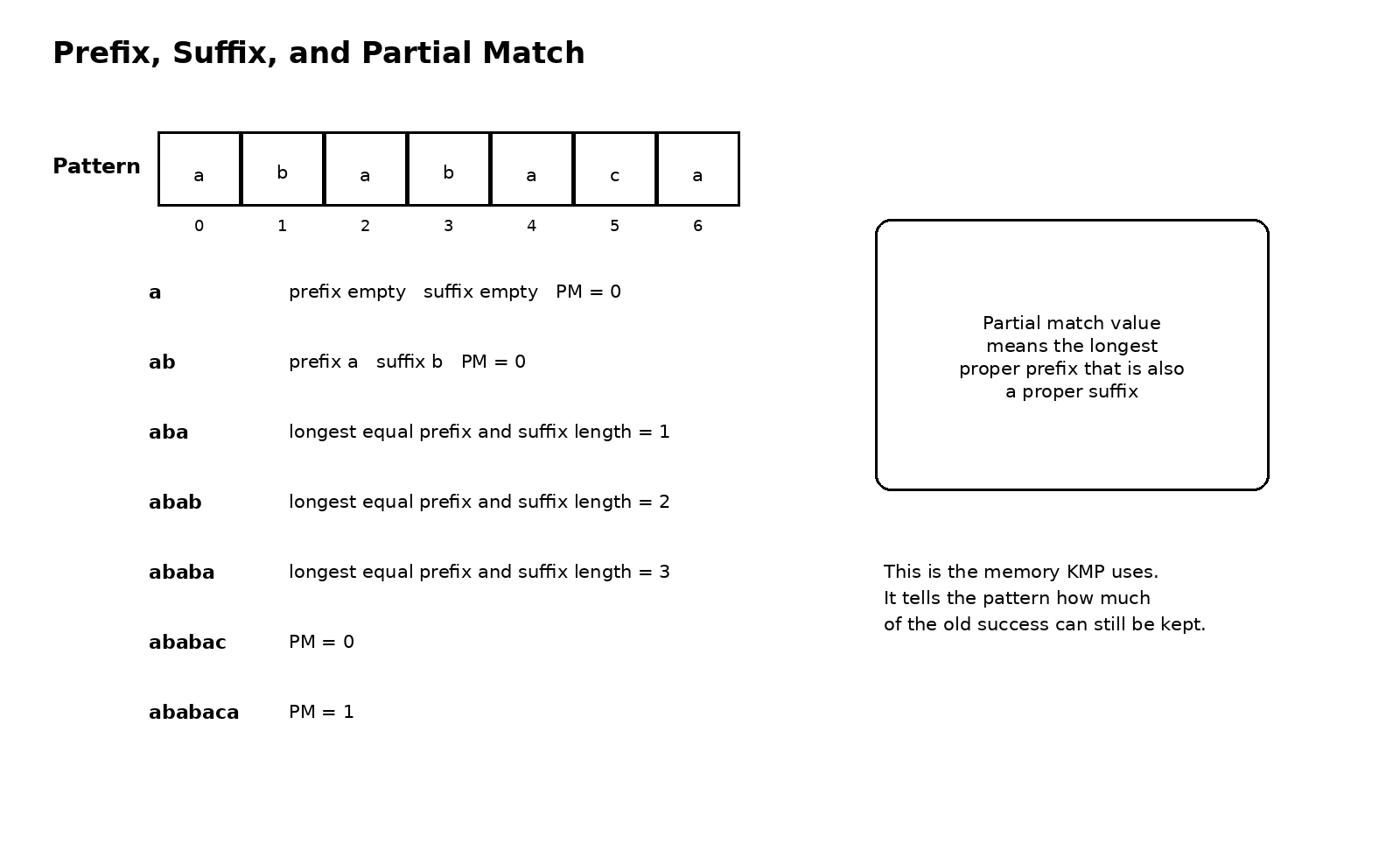
从这里再去看 KMP,就会顺很多。KMP 并不是神奇地预测了下一个字符,而是在失配发生后,根据模式串本身的结构,算出模式串应该退回到哪里继续比较。这个退回位置不是随便猜的,而是前面已经匹配成功的那段内容逼出来的逻辑结果。也正因为跳转只发生在模式串内部,主串指针才可以坚定地停在当前位置,不需要回头。因为主串之前扫过的那部分信息,已经被模式串的前后缀关系吸收进跳转决策里了。
所以,理解 KMP 最关键的一句话不是失配后把 j 变成 nextj,而是要知道为什么 nextj 合法。它之所以合法,是因为它对应着当前已匹配前缀中仍有可能继续成功的那一段最大候选边界。换句话说,KMP 并不是少比了必要的字符,而是删掉了那些逻辑上已经不可能带来新结果的重复比较。
四、next 数组本质上是一份失配时的行动指南
一旦前缀和后缀的逻辑想通了,next 数组就不再是死记硬背的神秘对象。它本质上就是一份行动指南,告诉模式串在某个位置失配时,下一步应该把模式指针跳到哪里。它记录的不是表面位置,而是每个前缀在失配后还能够保留多少已经匹配的信息。
很多教材在 next 的定义上会有细微差别,有的是传统写法,有的是更贴近代码实现的变体,所以不少同学常常在不同版本之间被绕晕。其实复习时不用把自己困在符号差异里。无论具体采用哪种下标体系,思想都没变。失配发生时,模式串不用回到第一个字符,而是跳到当前已匹配前缀所对应的最长可复用边界位置。你只要把这层意思抓住,具体写代码时再按老师或教材要求去统一下标细节就够了。
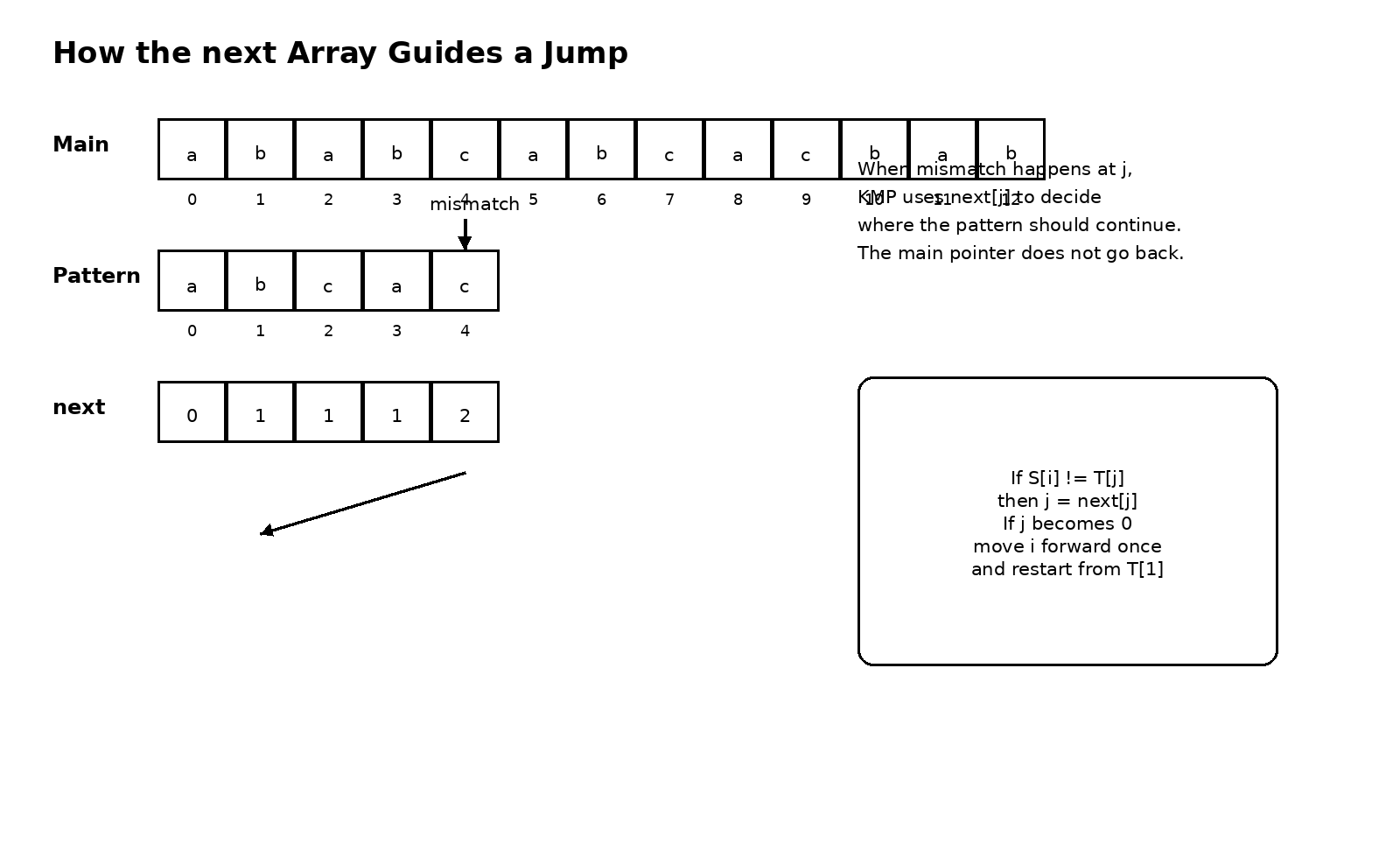
从算法角度看,next 数组的生成过程本身也很重要,因为它体现了 KMP 另一层巧妙之处。我们不只是用模式串去匹配主串,还先用模式串的结构来分析模式串自己。求 next 的过程,实际上也是在不断地问,当前前缀的最长相等前后缀是多少。这个过程和正式匹配有一种镜像关系。正式匹配是在主串里找模式串,求 next 则是在模式串内部找它自己的规律。也正因为这种自分析过程同样能通过边界回退高效完成,整个 KMP 才能保持线性复杂度。
如果你复习时总觉得 next 难算,不妨换个角度,不要硬背公式,而是把每一位都看成一个问题。假如模式串在这里失配,前面已经匹配成功的那段里,还有多长的一部分值得保留。这样一位一位问下去,next 的含义就会逐渐变得具体,而不是一串抽象数字。
五、KMP 和暴力匹配的真正差别,在于对失配的态度不同
学完 next 之后,再回头看暴力匹配和 KMP 的差异,会觉得两者像是在面对同一件事时采取了两种完全不同的态度。暴力匹配一旦失配,就默认前面的努力基本作废,于是重新开始。KMP 则认为,失配并不等于前面的信息全部失效,其中仍然可能藏着可延续的结构,所以它会先在模式串内部做一次逻辑跳转,然后再继续向前。这其实是一种很有代表性的算法思想。高效算法往往不只是跑得快,而是更会记住过去。暴力匹配的问题不在于它每次移动得慢,而在于它太容易遗忘。KMP 的优势也不只是少做了几次比较,而是它通过 next 数组把模式串的自相似结构提前整理好了,于是正式匹配时能把这些结构当作经验直接调用。很多同学一开始学 KMP 时总想盯着指针怎么动,结果越看越乱。其实更好的抓法是盯着信息有没有被浪费。只要你看见 KMP 在不断挽救已匹配信息,就能明白它为什么快。
这也是为什么 KMP 在最坏情况下仍然能保持线性复杂度。主串指针一路向前,模式串指针虽然会回退,但回退是有组织的,它不是反复回到起点,而是在已经计算好的边界之间跳转。于是整个过程里,每个字符参与比较的次数被严格压缩,总成本自然就从暴力匹配的 O(nm) 降到了 O(n + m)。
六、nextval 不是另一套新算法,而是对无效回退的再消减
很多人学到 nextval 的时候会再次迷糊,因为前面刚把 next 弄明白,后面又冒出一个 nextval,看上去像是又换了一套规则。其实 nextval 并没有改写 KMP 的核心思想,它只是对某一类特殊冗余做了进一步处理。
问题出在这样一种情况上。失配后,如果我们按照 next 数组跳到某个位置,而该位置对应的字符和刚才失配位置的字符恰好相同,那么下一次比较很可能仍然立即失败。也就是说,虽然这一步跳转在逻辑上没错,但它可能仍然保留了一次明显没必要发生的比较。nextval 想解决的,就是这种还能继续提前跳过去的冗余。
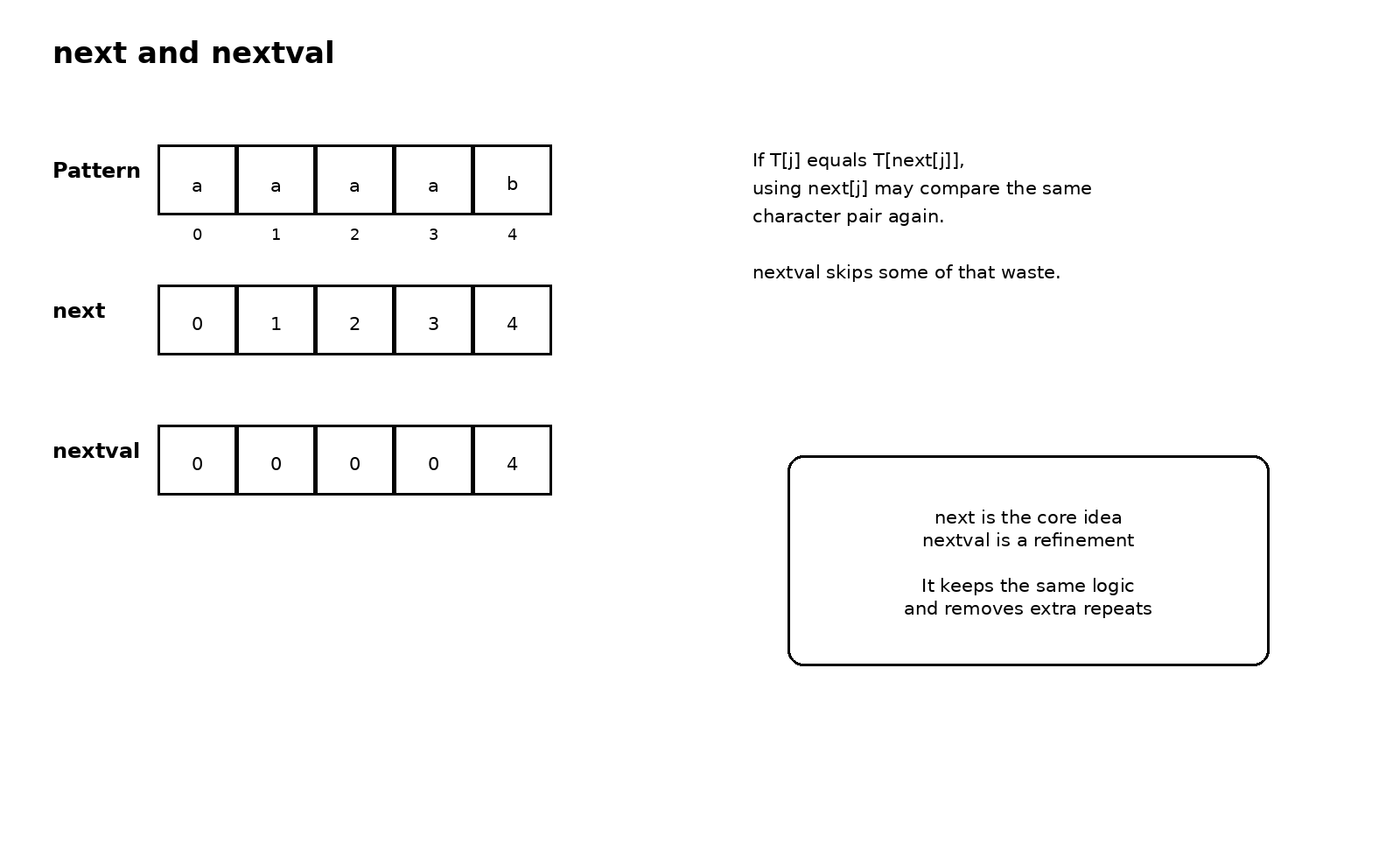
所以 nextval 可以理解成 next 的一个精细化版本。它并不是改变了失配后保留边界的基本原则,而是在某些特定情形下继续向前看一步,把那种显然会重复失败的跳转也合并掉。复习时如果时间有限,首先要确保 next 和 KMP 主体已经彻底想明白,然后再去理解 nextval。因为 nextval 的价值建立在你已经懂得 next 为什么成立的基础上。要是前一层还没稳,就很容易把 nextval 也学成另一堆孤立公式。