Real2Edit2Real
论文:Real2Edit2Real: Generating Robotic Demonstrations via a 3D Control Interface
网址: https://real2edit2real.github.io/
1. 介绍
-
仿真方法:MimicGen、SkillMimicGen
方法:已有少量专家轨迹(仿真) → 拆分成技能 → 在仿真中重组 → 生成新轨迹
可以直接生成轨迹,但是需要物体模型、场景建模,而且需要考虑sim-to-real gap,无法直接用真实数据做增强
-
3D Gaussian Splatting:RoboSplat、Real2Render2Real
方法:真实世界扫描 → 3D GS重建环境 → 在环境中生成新视角/轨迹 → 渲染成训练数据
不需要仿真,可以真实重建场景,但需要专门采集数据,需要多视角扫描实现高质量重建,但是不支持 RGB-only(不能只用"普通RGB视频/图像"作为输入来生成数据)
-
点云编辑方法:DemoGen、R2RGen、UMIGen
方法:真实/仿真数据 → 构建3D点云场景 → 编辑点云结构 → 生成新轨迹
可以生成新轨迹,但依赖depth / 点云,没有纹理信息,物理不完整
-
视频生成方法:RoboTransfer、MVAug
方法:原始视频 → 条件生成模型 → 新视频(外观变化)
可以直接处理 RGB,只改变视觉(颜色,纹理),不能改变:物体位置、轨迹、任务逻辑等

2. 方法
Real2Edit2Real 本质:
RGB
↓
3D重建
↓
3D编辑(改任务)
↓
生成"合理的depth"
↓
depth等条件信息 + 视频生成模型
↓
新视频 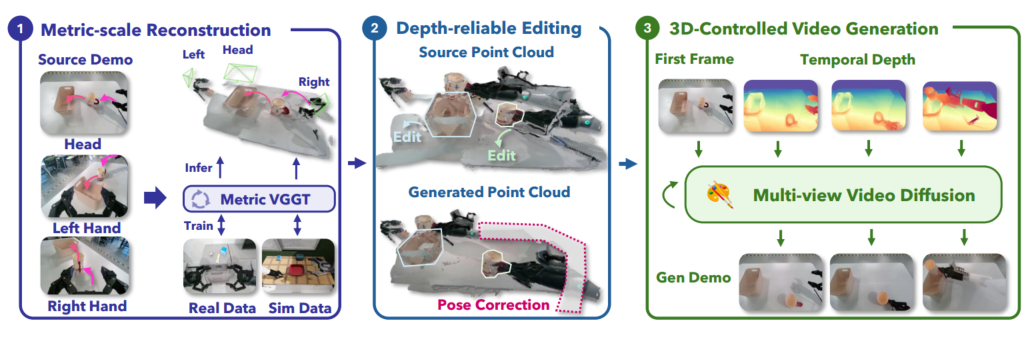
2.1 几何重建
早期的方法:
- NeuS、2D Gaussian Splatting:需要密集的图像捕获场景和后期优化,导致速度太慢而且成本高。
- "直接预测3D"的模型预测重建:
- 输入:少量RGB,输出:depth / point cloud / pose
- 模型预测的相机位置不准,物体常见尺度不对,导致训练数据 vs 实际机器人数据不一致:
只有3个相机(头 + 左腕 + 右腕)→ 视角非常稀疏,导致少视角 → 重建容易不准(pose错 / scale错)
所以采用 仿真 + 真实 数据联合训练 VGGT,然后进行几何重建
VGGT,一种前馈神经网络,可以直接从一张、少量或数百张视图中推断场景的所有关键三维属性,包括相机参数、点图、深度图和三维点轨迹。该网络在多项三维任务中达到了最先进的水平,包括相机参数估计、多视图深度估计、稠密点云重建 和三维点跟踪。
- Camera Pose
真实机器人采用手眼标定确定的,但是存在误差,仿真相机来自 URDF(机器人模型),完全精确。
核心:只用仿真数据监督 camera pose。
损失函数:L_camera = L1( T̂_sim , T_sim )- Depth Map
真实数据通过深度传感器捕获度量尺度的几何体,但由于传感器的限制、反射或无纹理的表面,所获取的深度图通常具有很高的噪声。
仿真数据提供了无噪声和几何精确的深度图,但对象和场景的比例可能会偏离现实世界的分布
核心:真实 + 仿真混合监督 depth
L_depth =Lconf(M(D̂_real), M(D_real)) + Lconf( D̂_sim, D_sim )
M代表mask,需要过滤真实数据深度图的噪声- Point Map
point map = 每个像素对应的3D点,由于真实点云不准(来自 noisy depth)
只用仿真数据训练VGGT
总损失:
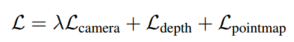
2.2 空间编辑
点云编辑(改任务)
↓
轨迹生成(让机器人能做这个新任务)
↓
生成"物理一致"的depth(给后面的视频生成模型用)-
轨迹合成
把轨迹分成两类:
-
Motion segment(运动段):机器人移动,不接触物体。
利用运动规划重新生成
-
Skill segment(技能段):机器人与物体交互(抓、放、推)。
如果物体:A → A'(平移/旋转),机器人(在该段)也做同样变换,保持"机器人-物体关系"不变
-
-
生成depth
由于物体位姿改变,则需要更新相机位姿。
编辑后的点云 + 相机新位姿 ---> 投影(projection) ---> depth map
由于物体移动、视角变化,深度图出现:深度图、稀疏、噪声,需要填补空洞和去噪
-
机器人pose修正
物体位置改变,只变换 end-effector,剩下的手臂姿态需要修正,保证运动学一致性,然后重新渲染机器人depth
整体Pipeline:
原始点云 + 轨迹
↓
分段(motion / skill)
↓
skill段 → 跟随物体变换
motion段 → 重新规划
↓
更新相机pose
↓
点云 → depth图
↓
深度图优化
↓
机器人姿态修正(IK + URDF)
↓
重新渲染机器人depth
2.3 3D控制视频生成
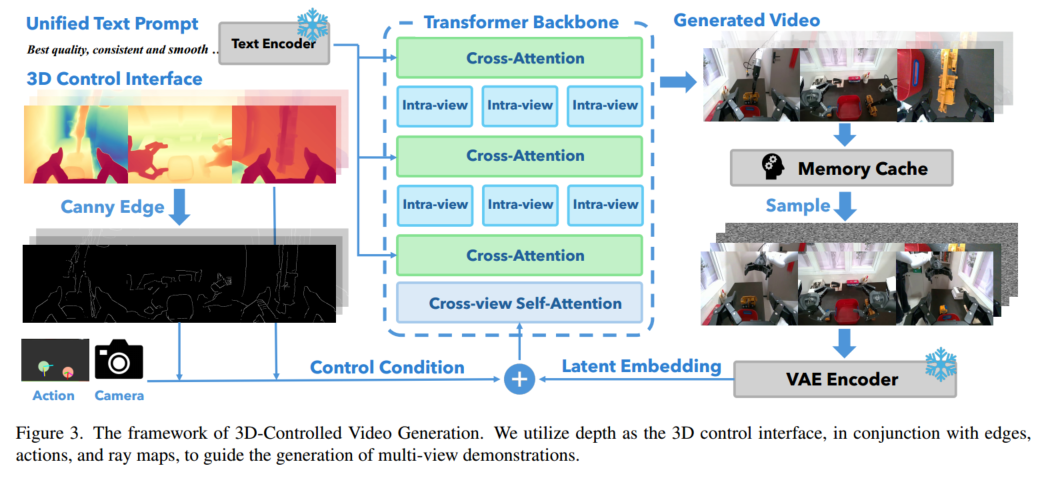
提出了一种3D条件视频生成模型,该模型从第一帧开始,合成具有逼真视觉外观、多视图一致性和物理上合理交互的新型机器人操作视频。该模型基于Transformer,采用三种关键设计:双注意力机制、深度控制界面和平滑的对象重定位。
-
深度控制界面:
使用度量VGGT来预测深度图,并根据深度计算Canny Edges,深度图和Canny Edges作为控制条件控制条件 + 图像 latent → Transformer,确保生成的视频必须符合3D几何结构
-
双重注意力机制:
-
intra-view attention:每个camera view单独做 self-attention,学习图像内部结构和局部空间关系
-
Cross-view self-attention:学习多视图对应关系,确保生成视频中的多视图一致性。
-
Cross-Attention:条件注入,融合文本信息
-
-
平滑对象重新定位:
模型从第一帧开始生成视频,但第一帧里,物体位置可能不对(因为编辑过3D),需要进行平滑重定位
在3D中插值:translation(平移)和rotation(旋转),生成一段"过渡轨迹"
第一帧里:杯子在 A 位置 进行3D插值,进行过渡 视频第一帧:杯子在 B 位置开始被操作
3. 实验
3.1 实验设置
Metric VGGT:
从Agibot DigitalWorld数据集中采样40K帧作为模拟训练数据,并使用深度传感器收集100K真实机器人数据作为真实训练数据
视频生成模型GE-Sim:
GE-Sim(基于CosmosPredict-2B), 从AgiBot World数据集中的64个任务中抽取7K作为训练数据微调
对两种VLA策略进行了实验:Go-1和π0.5。
-
对于Go-1(AGIBOT),只对动作专家进行微调,同时保持主干冻结,因为我们使用的是与其预训练数据相同的实施例。该动作是6D末端执行器姿势。
-
对于π0.5,由于实施例不匹配,进行了完全微调。动作是7-DoF关节角度
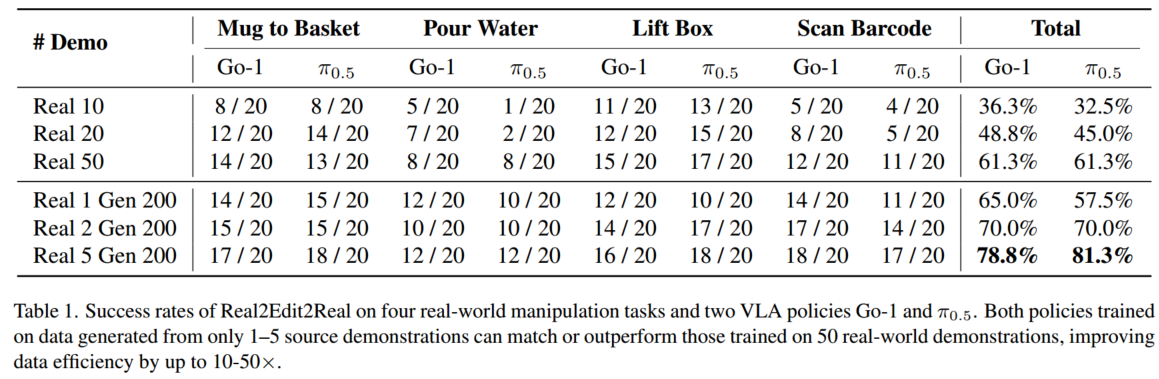
在四个任务上进行了真实的机器人实验,从单臂到双臂操作:
-
杯子到篮子:机器人用右臂抓住杯子并将其稳定地放在篮子里。
-
倒水:机器人用左臂拿起水壶,将壶嘴与杯子对齐,将水倒入纸杯。
-
升降箱:机器人用双臂抓住箱子的两侧并将其抬起。
-
扫描条形码:机器人左手拿着零食,右手拿着条形码扫描仪,通过将扫描仪与条形码对齐来扫描条形码。
3.2 实验结果
视频生成的定量结果
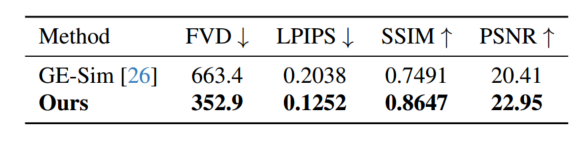
我们的视频生成模块能够生成具有显著增强视觉真实感的机器人演示。
删除深度控制或Canny边缘约束会导致对象模糊和不正确交互等问题,从而大大降低了生成演示的质量。
平滑对象重定位

-
编辑对象高度
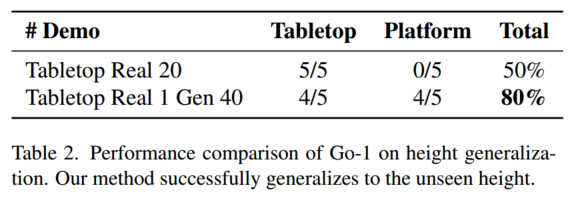
在桌面上通过20次真实演示训练的策略在平台高度上完全失败。如果我们通过我们的框架在桌面上生成20个演示,在平台上生成20次演示,可以实现80%的成功率
-
编辑纹理
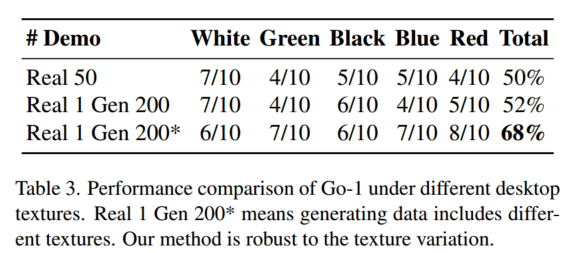
通过第一帧编辑编辑视频,比如更改背景纹理。表3显示了图4所示的不同桌面纹理下的性能,并表明我们的方法可以生成具有不同纹理的演示,以提高策略的鲁棒性。
消融实验
-
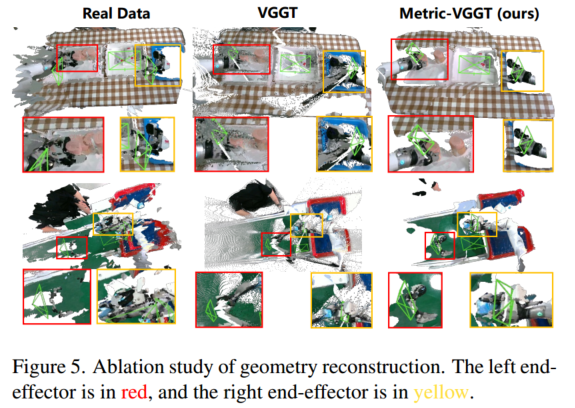
几何重建

我们的模型预测了机器人场景中最干净的点云和最准确的相机姿态,而现实世界的数据受到相机姿态不准确的影响,VGGT重建包含大量的杂波和噪声。
-
机器人姿势校正

如果没有机器人姿态校正,错误的深度图会导致模糊和不一致的生成结果。通过机器人姿态校正,深度图在运动学上变得一致,使模型能够在合成视频中生成逼真的机器人运动。
-
平滑对象重新定位
如果没有平滑的对象重定位,生成的对象放置通常会出现明显的错误,导致演示不可用。相比之下,平滑的对象重定位能够将对象精确地放置在目标位置
4. 总结
介绍了Real2Edit2Real框架,通过将3D可编辑性与2D视觉数据联系起来,实现了可扩展的演示生成。通过几何重建、深度可靠的空间编辑和3D控制视频生成,可以生成逼真和运动学一致的多视图操作演示