一、人工智能AI、ML、DL之间的关系
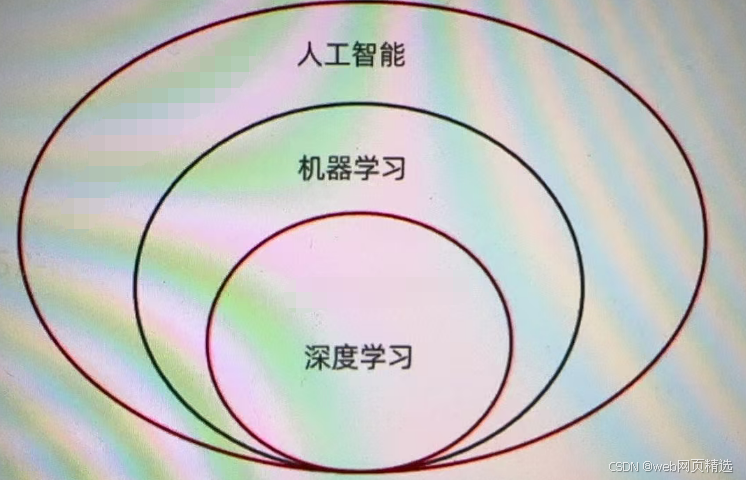
・人工智能三大概念:人工智能(AI)、机器学习(ML)、深度学习(DL)。
・人工智能:是一个研究领域,像人一样、机器智能的综合与分析。
・机器学习:从数据中获取规律;来了一个新数据,产生一个新的预测。
・深度学习:也叫深度神经网络,大脑仿生,设计一层一层的神经元模拟万事万物。
・三者关系:
|--------------------------------------|------------------------------------------------------------------------------------------------------------------|
| 1.人工智能 (AI, Artificial Intelligence) | 这是最广泛的概念,指的是使机器能够模拟人类智能行为的技术和研究领域。AI包括理解语言、识别图像、解决问题等各种能力。 |
| 2. 机器学习 (ML, Machine Learning) | 机器学习是实现人工智能的一种方法。它涉及到算法和统计模型的使用,使得计算机系统能够从数据中"学习"和改进任务的执行,而不是通过明确的编程来实现。机器学习包括多种技术,如KN、线性回归、逻辑回归、决策树、集成学习、聚类算法等。 |
| 3.深度学习 (DL, Deep Learning) | 深度学习是机器学习中的一种特殊方法,它使用称为神经网络的复杂结构,特别是"深层"的神经网络,来学习和做出预测。深度学习特别适合处理大规模和高维度的数据,如图像、声音和文本。 |机器学习是实现人工智能的一种途径。
深度学习是机器学习的一种方法。
・基于规则的学习:程序员根据经验利用手工的if-else方式进行预测
1.数据(多个样本)
2.发现规律(人工)
3.人工编程(规则)
4.新的样本
5.根据之前写好的程序预测
6.拿到结果
・基于模型的学习:从数据中自动学出规律
1.海量的数据(多个样本)
2.发现规律(算法模型)
3.通过重复学习,汇总规律
4.新的样本
5.根据模型学习的规律预测
6.结果 图中是大象
1.名词解释
① AI:人工智能
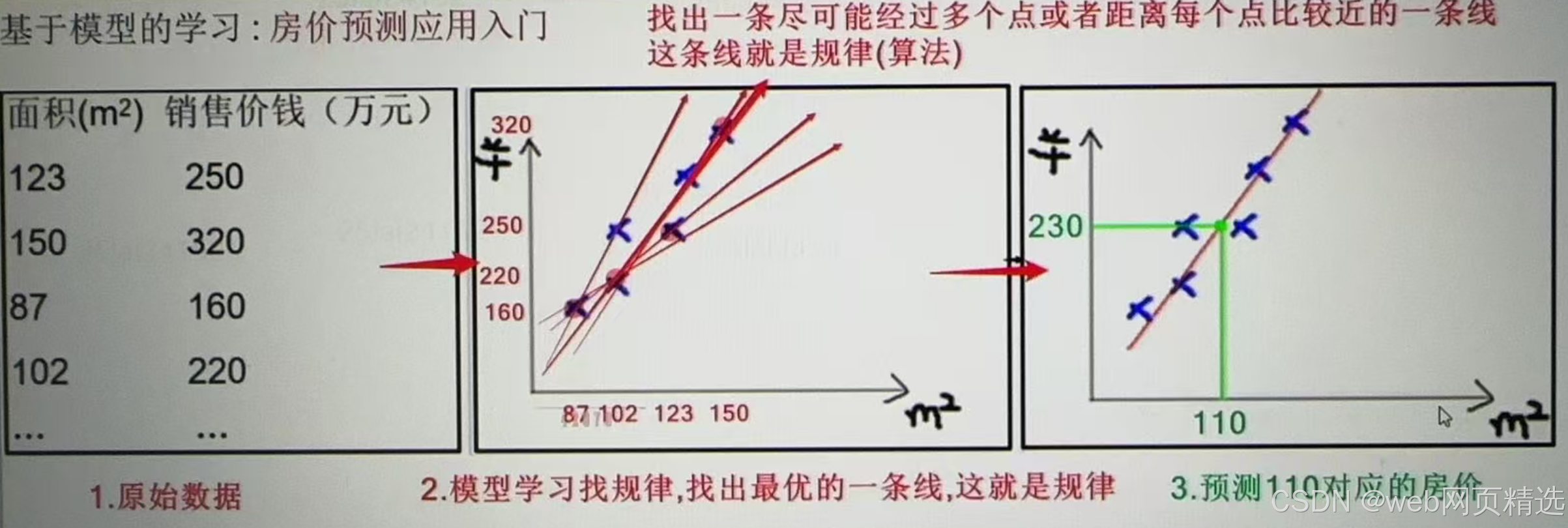
・基于模型的学习:房价预测应用入门
找出一条尽可能经过多个点或者距离每个点比较近的一条线,这条线就是规律(算法)
1 利用线性关系来模拟面积和房价之间的关系
eg:让直线尽可能多的经过这些点,不能经过的点分布直线两侧
2 机器学习模型
eg:直线记成 y = ax + b 就是模型,其中 a、b 就是我们要训练的模型参数!
房价 = a * 面积 + b
② ML:机器学习
1)机器学习的应用领域:
・计算机视觉CV:对人看到的东西进行理解
・自然语言处理:对人交流的东西进行理解
・数据挖掘和数据分析:也属于人工智能的范畴
2)机器学习发展史:
・1956年:人工智能元年
・...
・2024年:AI应用大规模落地,硬件与场景深度融合
・2025年:开启智能体时代,AI自主性提升

③ DL:深度学习
二、AI人工智能发展三要素
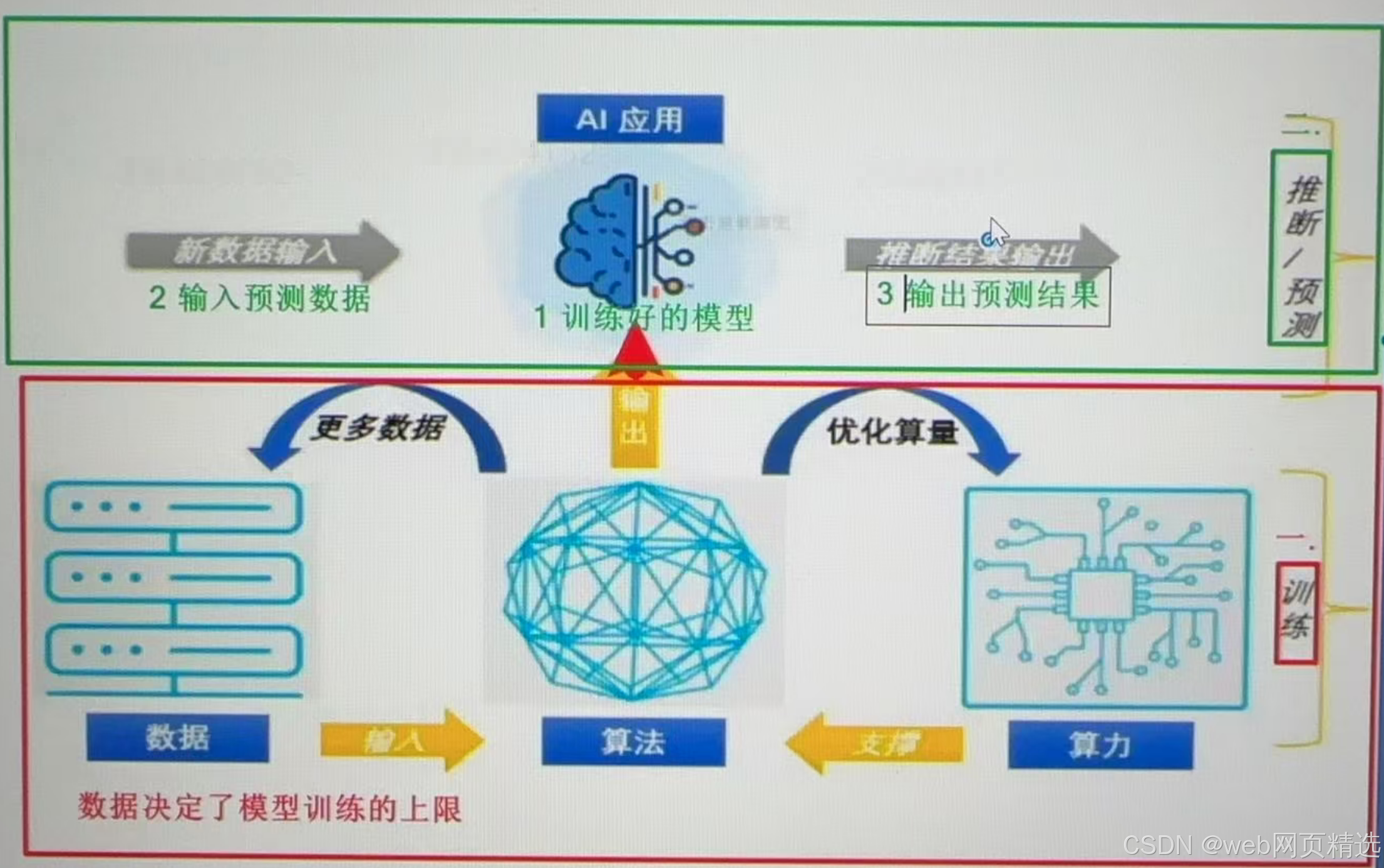
数据
数据决定了上限
算法
算力
・数据、算法、算力三要素相互作用,是AI发展的基石。
・数据决定了模型训练的上限
・数据,算法,算力
・CPU:主要适合I\0密集型的任务
・GPU:主要适合计算密集型任务
・TPU:专门针对大型网络训练而设计的一款处理器
三、算法的学习方式
1.基于规则的学习
2.基于模型的学习
四、数据集划分
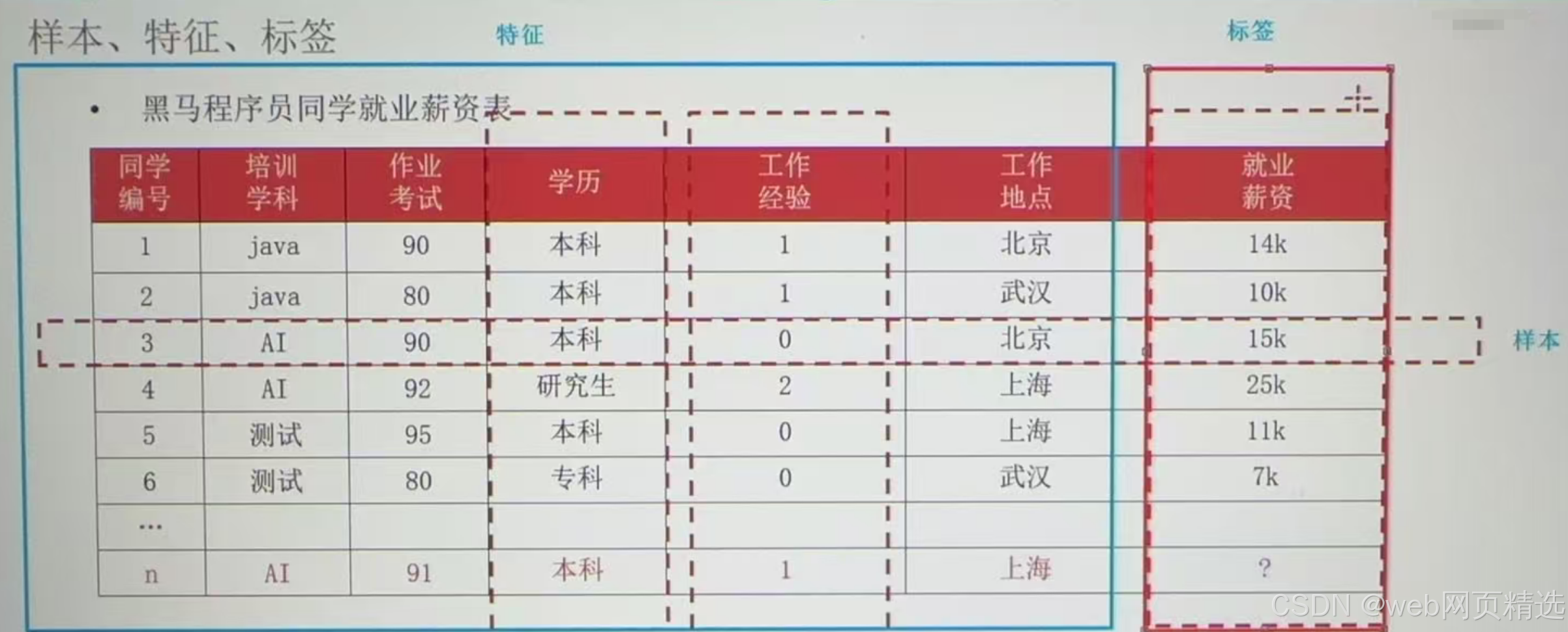
样本、特征、标签
样本(sample):一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录
特征(feature):一列数据一个特征,有时也被称为属性
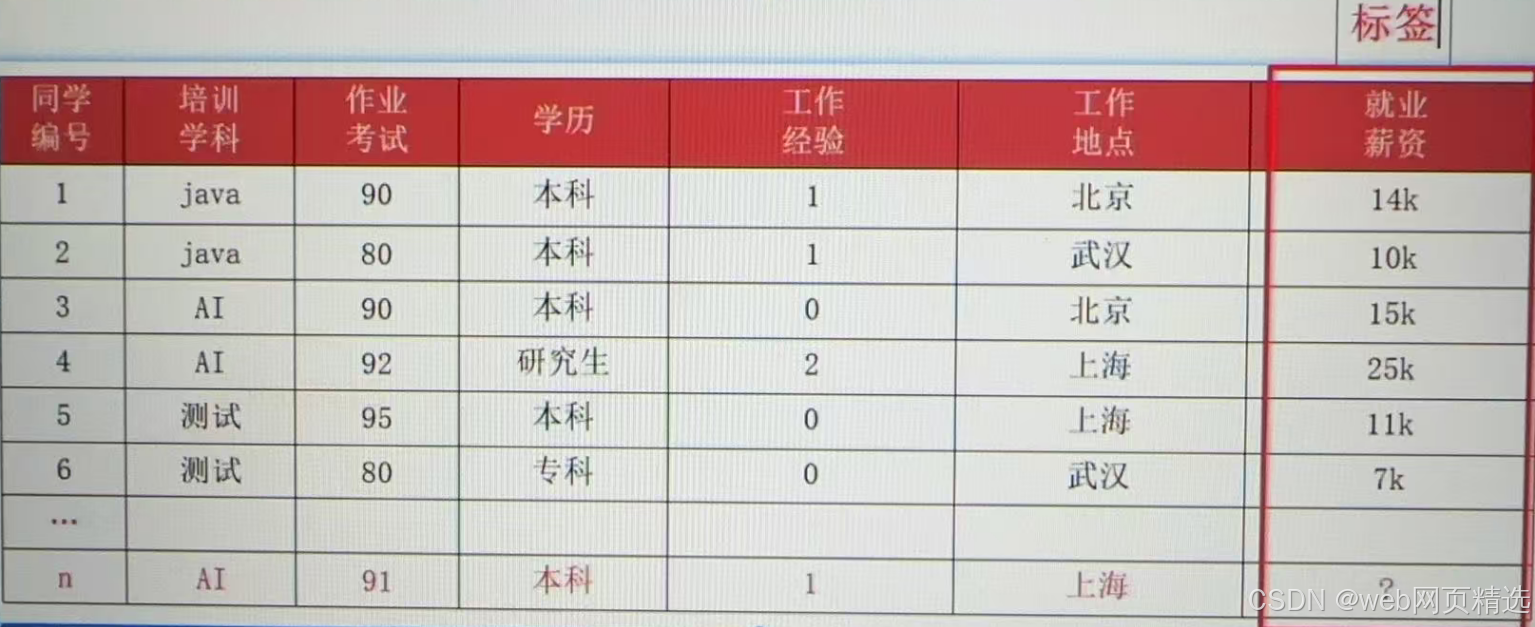
标签/目标(label/target):模型要预测的那一列数据。本场景是就业薪资
就业薪资与培训学科、作业考试、学历、工作经验、工作地点5个特征有关系
特征如何理解(重点):特征是从数据中抽取出来的,对结果顶测有用的信息
eg:房价预测、车图片识别
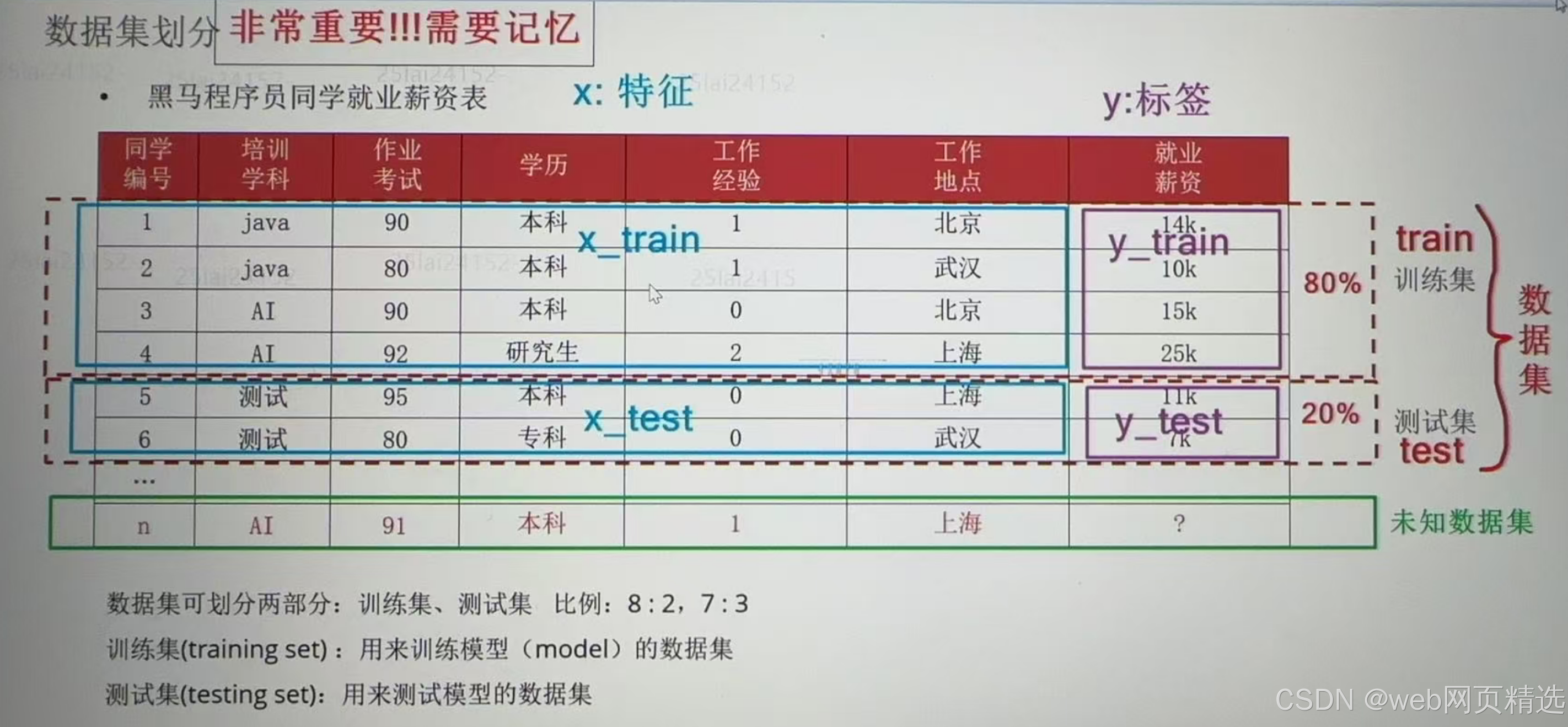
数据集划分
x_train训练集中的x
x_test 测试集中的x
y_train 训练集中的y
y_test 测试集中的y
总结
1 样本和数据集
・样本(sample):一行数据就是一个样本
・数据集dataset:多个样本组成数据集
2 特征
・特征(feature):一列数据一个特征,有时也被称为属性
3 标签
・标签/目标(label / target):模型要预测的那一列数据。
4 数据集划分
・训练集用来训练模型、测试集用来测试评估模型
・一般划分比例7:3 ~ 8:2
2.关系
1)ML是实现AI的一种途径
2)DL是ML的子集
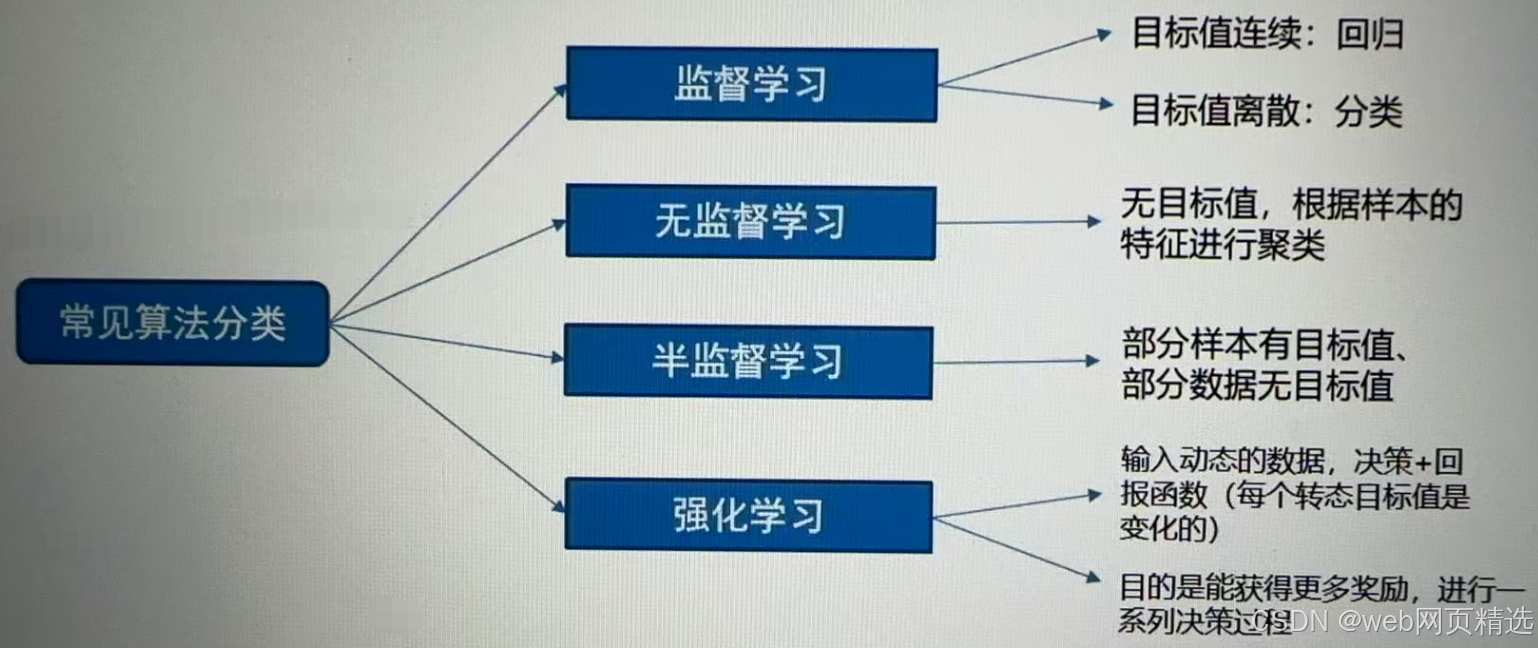
五、机器学习的算法分类
1.有监督学习
(有参考答案)
① 数据中有标签的
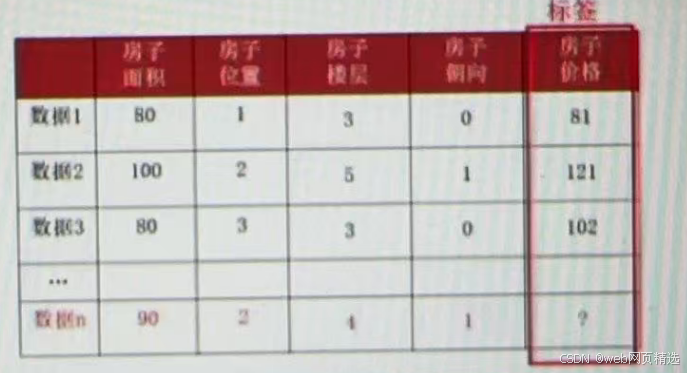
1)标签是连续的,就是回归任务
示例1:预测房价
示例2:预测就业薪资
2)标签是离散的,就是分类任务
示例1:预测电影类别
示例2:预测就业薪资等级
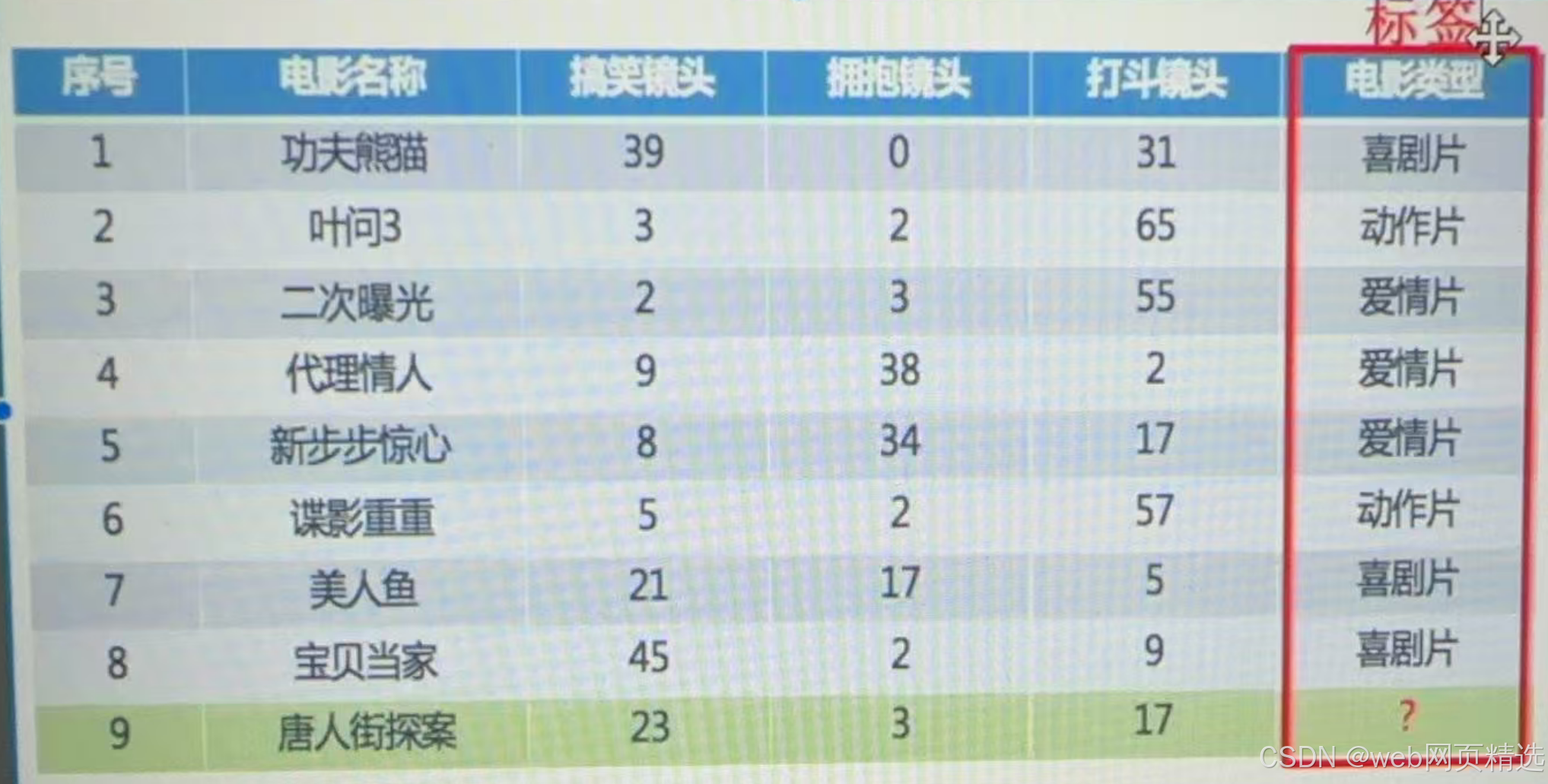
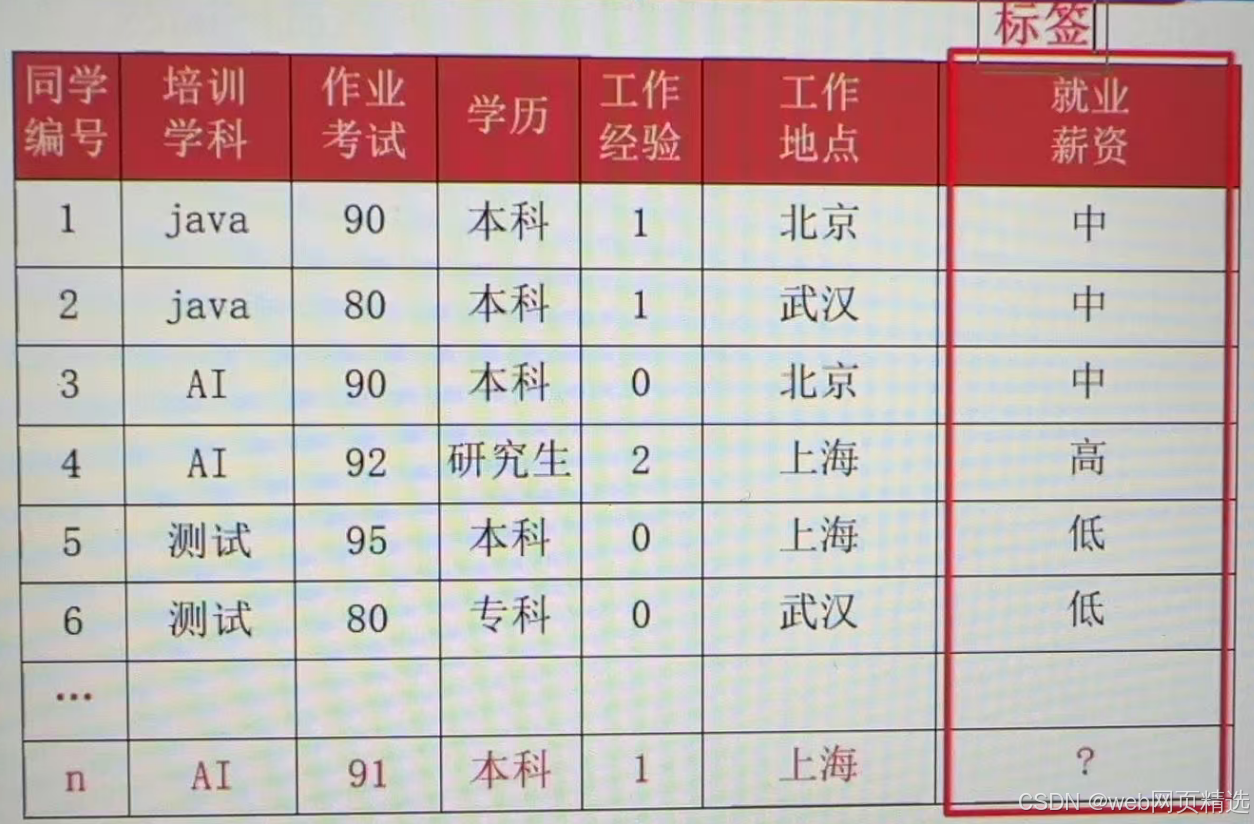
2. 无监督学习
(无参考答案)
① 数据中没有标签的
1)没有标签的,主要是聚类任务
举例1:
举例2:

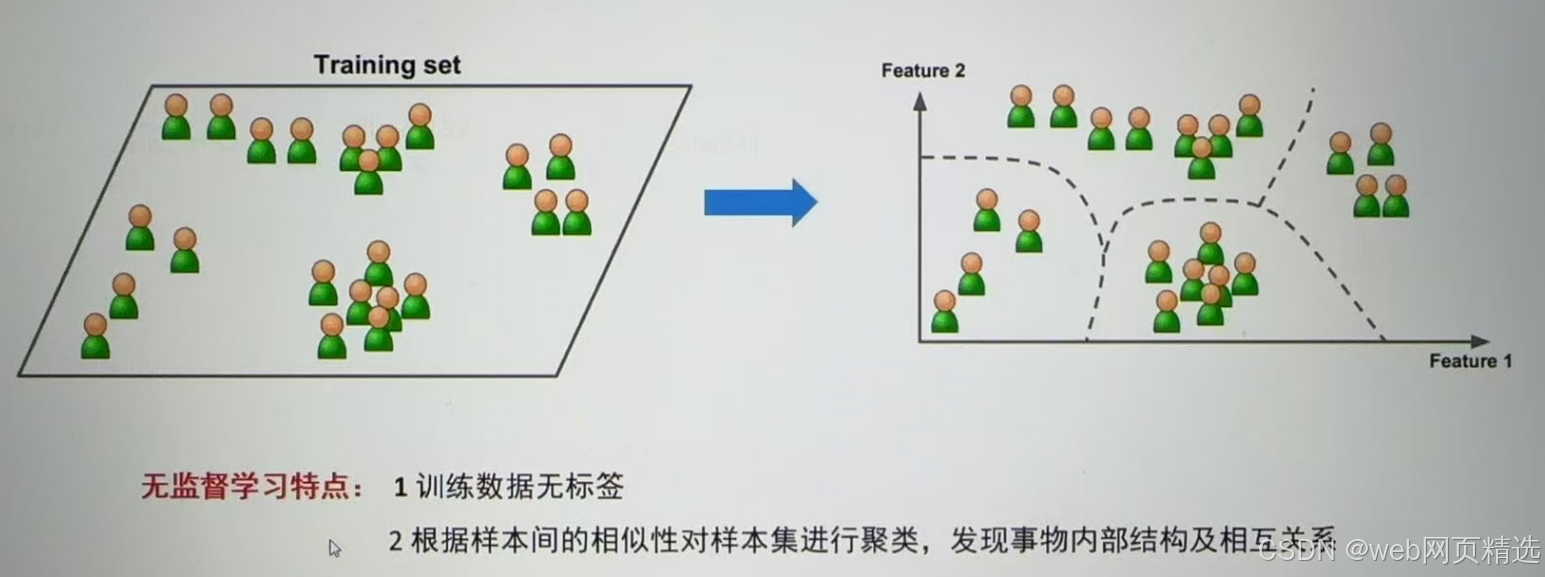
3.半监督学习
① 数据部分有标签,部分没有有标签
示例:
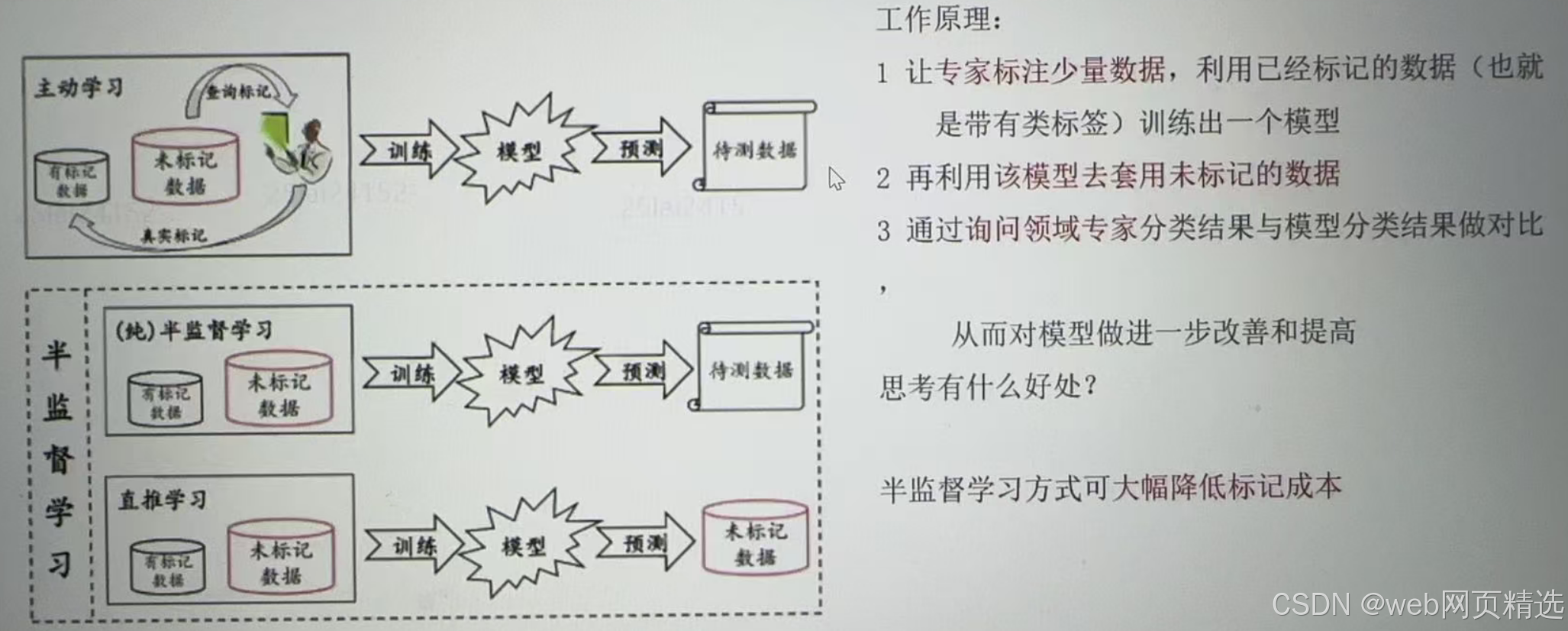
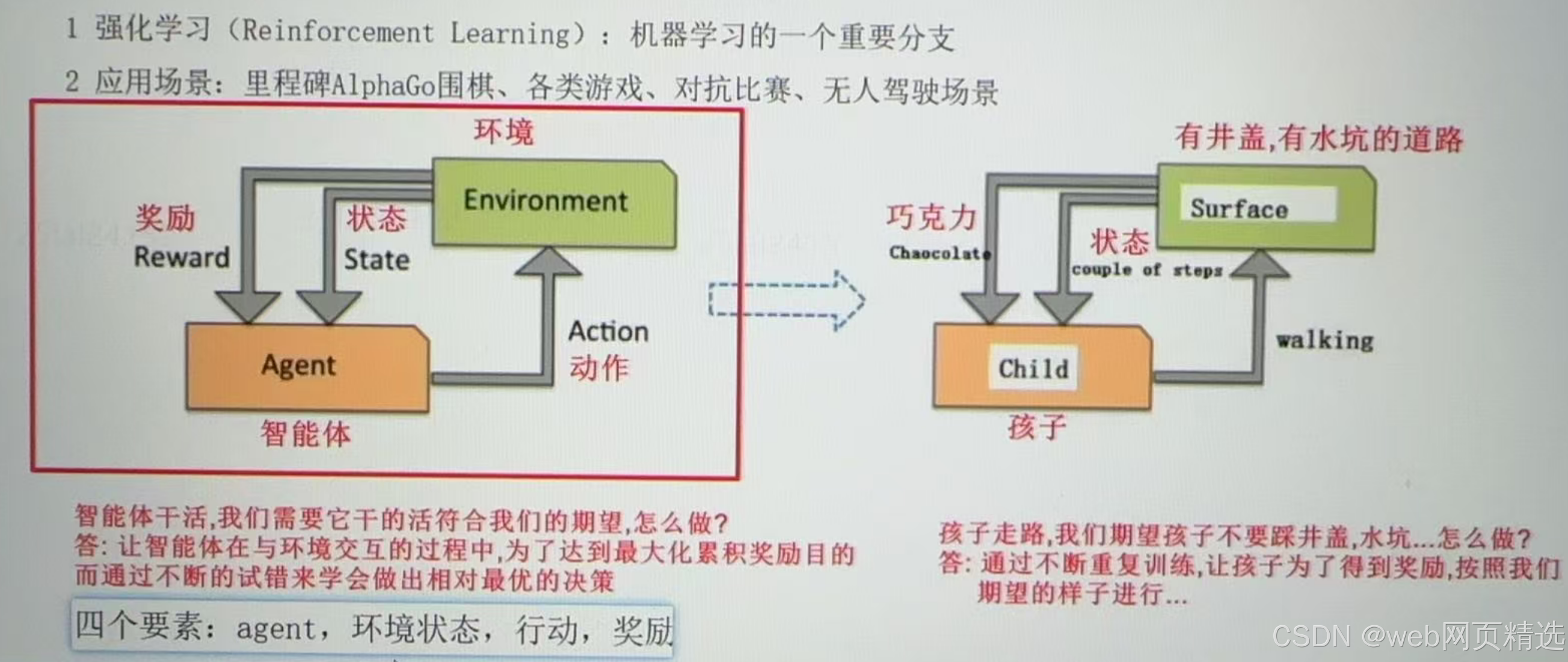
4.强化学习
① 核心思想
为了让智能体达到最大化累计奖励,通过不断地在环境中试错,学会做出最优的决策。
② 马尔科夫决策四要素
1)智能体
agent
2)环境状态
3)行动
4)奖励
reward就是打分
示例:
机器学习算法分类 - 总结
| In | Out | 目的 | 案例 | |
|---|---|---|---|---|
| 监督学习 (supervised learning) | 有标签 | 有反馈 | 预测结果 | 猫狗分类 房价预测 |
| 无监督学习 (unsupervised learning) | 无标签 | 无反馈 | 发现潜在结构 | "物以类聚,人以群分" |
| 半监督学习 (Semi- Supervised Learning) | 部分有标签,部分无标签 | 有反馈 | 降低数据标记的难度 | |
| 强化学习 (reinforcement learning) | 决策流程及激励系统 | 一系列行动 | 长期利益最大化 | 学下棋 |
记忆:

六、机器学习的流程
机器学习建模流程图解:
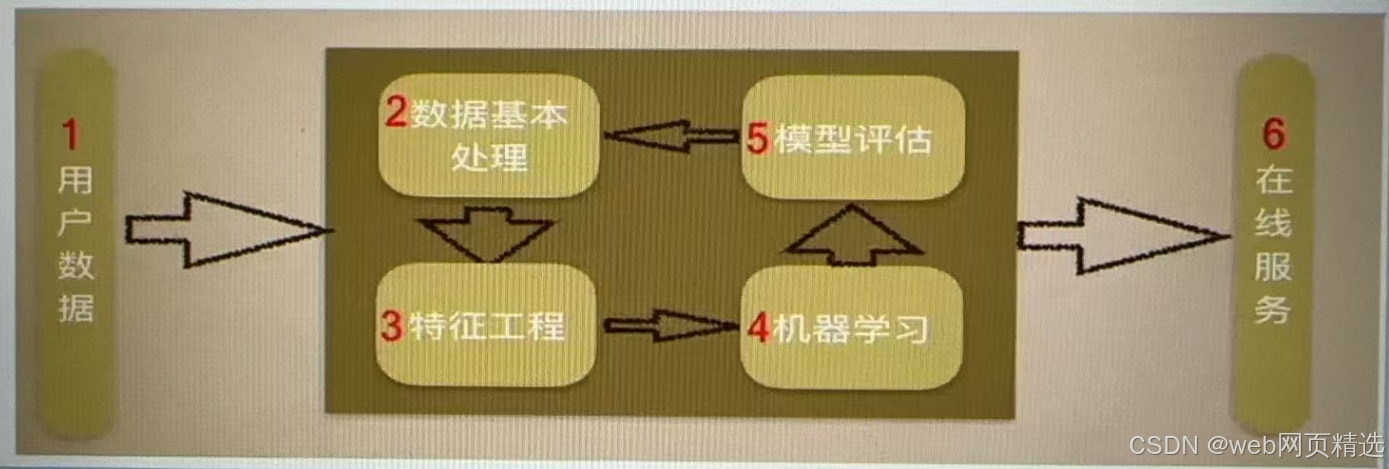
|--------------|----------------------|
| 1.获取数据 | 获取经验数据 图像数据 文本数据 ... |
| 2.数据基本处理 | 数据缺失值处理 异常值处理 ... |
| 3.特征工程 | 特征提取 特征预处理 特征降维 ... |
| 4.机器学习(模型训练) | 线性回归 逻辑回归 决策树 GBDT |
| 5.模型评估 | 回归评测指标 分类评测指标 聚类评测指标 |
注:在整个建模流程中,数据基本处理、特征工程一般是耗时、耗精力最多的。
总结:
1.机器学习建模的一般步骤
・获取数据:搜集与完成机器学习任务相关的数据集
・数据基本处理:数据集中异常值,缺失值的处理等
・特征工程:对数据特征进行提取、转成向量,让模型达到最好的效果
・机器学习(模型训练):选择合适的算法对模型进行训练
・根据不同的任务来选中不同的算法;有监督学习,无监督学习,半监督学习,强化学习
・模型评估:评估效果好上线服务,评估效果不好则重复上述步骤
注意:数据决定了模型训练效果的上限,所以未来工作后最耗时的就是特征数据处理。
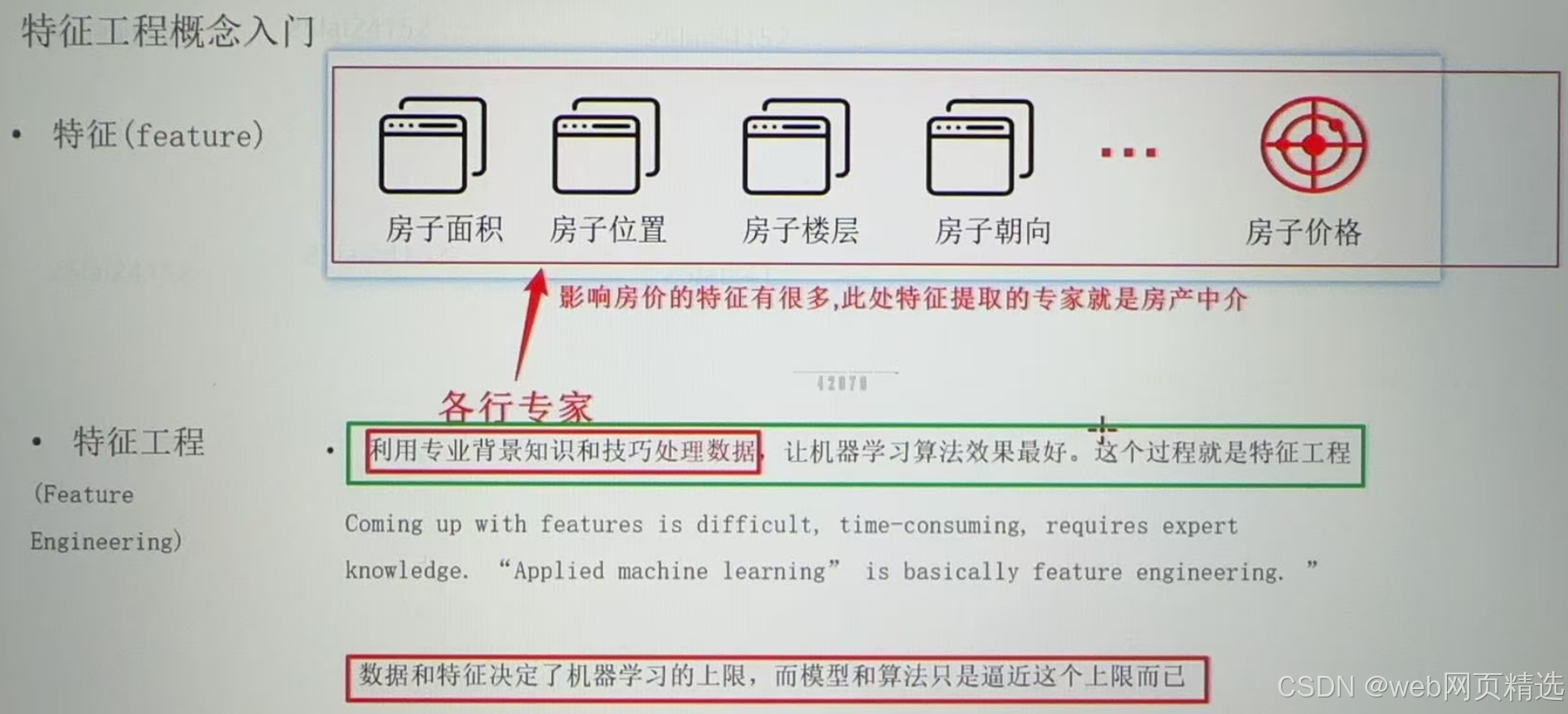
特征工程概念入门
特征工程概念 - 涉及内容
1.特征提取
从原始数据中提取与任务相关的特征
2.特征预处理
特征对模型产生影响;因量纲问题,有些特征对模型影响大、有些影响小。
3.特征降维
将原始数据的维度降低,叫做特征降维,一般会对原始数据产生影响。
4.特征选择
原始数据特征很多,与任务相关是其中一个特征集合子集,不会改变原数据。
5.特征组合
把多个的特征合并成一个特征。利用乘法或加法来完成。
A × B:将++两个特征的值相乘++形成的特征组合。
A × B × C × D × E:将++五个特征的值相乘++形成的特征组合。
A × A:对++单个特征的值求平方++形成的特征组合。
七、拟合和泛化等相关概念
拟合
|-------------------|--------------------------|
| 拟合 fitting | 用在机器学习领域,用来表示模型对样本点的拟合情况 |
| 欠拟合 under-fitting | 模型在训练集上表现很差、在测试集表现也很差 |
| 过拟合 over-fitting | 模型在训练集上表现很好、在测试集表现很差 |
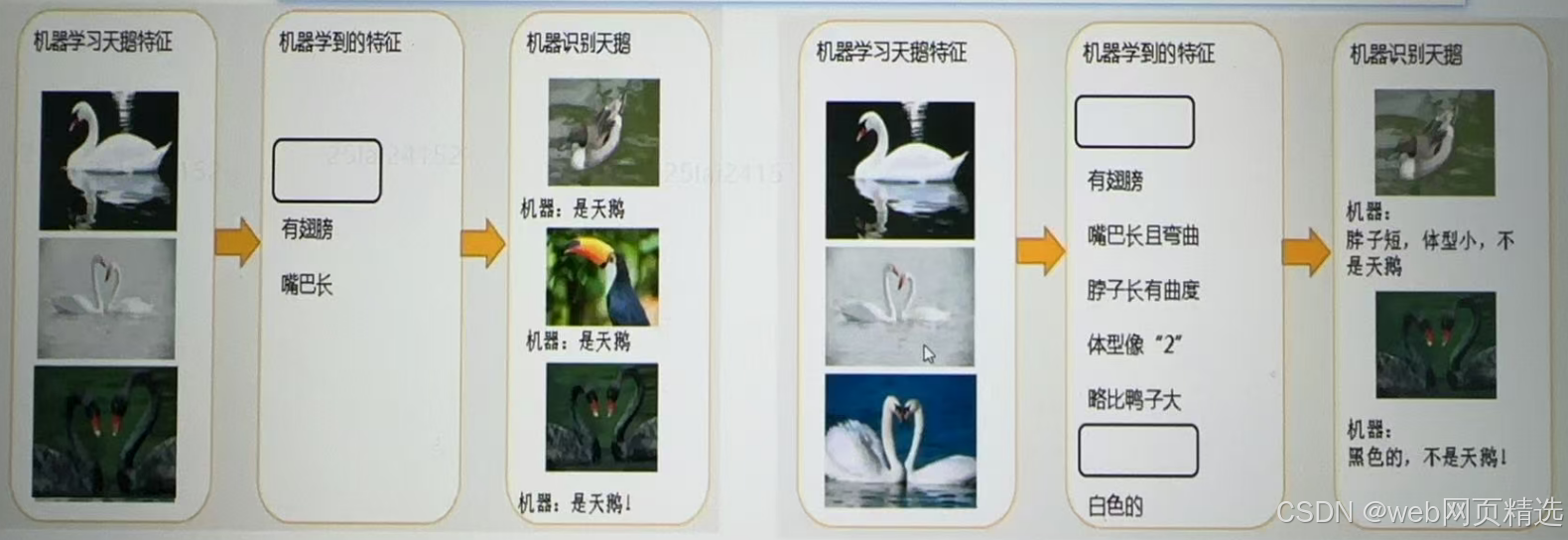
・机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅
・机器已基本能区别天鹅和其他动物了很不巧已有的天鹅图片全是白天鹅的。黑色的天鹅不能识别
模型表现效果 - 欠拟合欠拟合 - 从样本分布角度看
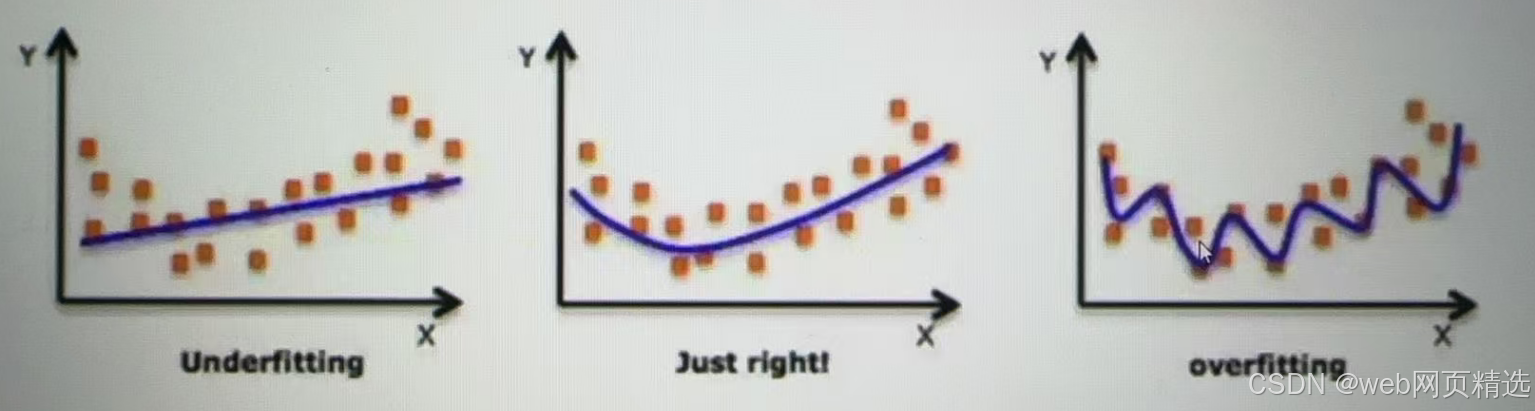
欠拟合产生的原因:模型过于简单
过拟合产的原因:模型太过于复杂、数据不纯、训练数据太少
泛化Generalization:模型在新数据集(非调练数据)上的表现好坏的能力。
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取
八、机器学习中核心算法
① 机器学习框架:sklearn
安装:pip install scikit-learn
导包:import sklearn
② 核心算法
1)经典算法
K近邻算法:分类和回归任务都支持
2)回归算法
核心代表:线性回归
3)分类算法
核心代表:逻辑回归
4)聚类算法
核心代表:K-Means
...