1、github路径
https://github.com/opendatalab/MinerU
2、docker 部署
https://opendatalab.github.io/MinerU/zh/quick_start/docker_deployment/
通过 Docker Compose 直接启动服务
提供了compose.yml文件,可以通过它来快速启动MinerU服务。
# 下载 compose.yaml 文件 wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/compose.yaml
compose.yaml文件中包含了MinerU的多个服务配置,可以根据需要选择启动特定的服务。- 不同的服务可能会有额外的参数配置,可以在
compose.yaml文件中查看并编辑。- 由于
vllm推理加速框架预分配显存的特性,可能无法在同一台机器上同时运行多个vllm服务,因此请确保在启动vlm-openai-server服务或使用vlm-vllm-engine后端时,其他可能使用显存的服务已停止。
启动 openai兼容接口 服务
并通过
vlm-http-client后端连接openai-server
docker compose -f compose.yaml --profile openai-server up -d在另一个终端中通过http client连接openai server(只需cpu与网络,不需要vllm环境)
mineru -p <input_path> -o <output_path> -b vlm-http-client -u http://<server_ip>:30000
启动 Web API 服务
docker compose -f compose.yaml --profile api up -d在浏览器中访问
http://<server_ip>:8000/docs查看API文档。
启动 MinerU Router 服务
docker compose -f compose.yaml --profile router up -d
- 默认配置会以
--local-gpus auto模式在容器内自动拉起本地 worker,并通过http://<server_ip>:8002/docs暴露统一入口。- 如果您希望聚合已有的
mineru-api服务而不是启动本地 worker,可直接参考compose.yaml中mineru-router服务下的注释示例,改为使用--upstream-url。
启动 Gradio WebUI 服务
docker compose -f compose.yaml --profile gradio up -d
- 在浏览器中访问
http://<server_ip>:7860使用 Gradio WebUI。
3、参数解释
在浏览器中访问 http://<server_ip>:8000/docs 查看API文档
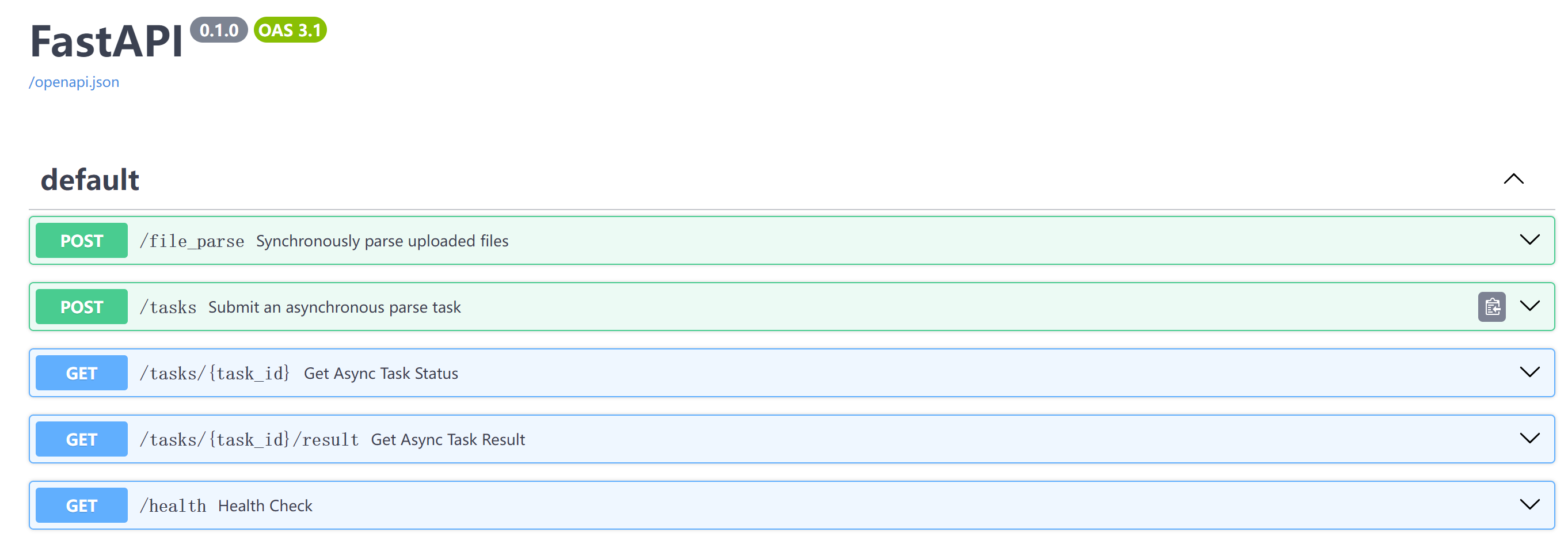
接口功能说明
| 接口 | 方法 | 功能 | 使用场景 |
|---|---|---|---|
/file_parse |
POST | 同步解析 | 小文件、实时返回结果 |
/tasks |
POST | 提交异步任务 | 大文件、批量处理 |
/tasks/{task_id} |
GET | 查询任务状态 | 轮询异步任务进度 |
/tasks/{task_id}/result |
GET | 获取任务结果 | 获取异步任务解析结果 |
/health |
GET | 健康检查 | 监控服务状态 |
什么时候用异步任务?
场景 推荐方式 原因 文件 < 10MB 同步 /file_parse快速返回,简单直接 文件 > 10MB 异步 /tasks避免超时,可轮询 批量处理多个文件 异步 /tasks后台处理,不阻塞 网页集成 异步 /tasks更好的用户体验 脚本/自动化 同步或异步均可 根据文件大小选择
核心参数详解
必填参数
参数 说明 示例 files要解析的文件(PDF/图片/DOCX) 支持多文件上传 语言设置 (
lang_list)根据文档类型选择:
# 中文文档(推荐) lang_list: ["ch"] # 中英繁混合 # 纯英文文档 lang_list: ["en"] # 英文 # 日文文档 lang_list: ["japan"] # 中日英繁 # 多语言混合(欧洲语言) lang_list: ["latin"] # 支持法语、德语、西班牙语等37种语言 # 俄语/乌克兰语 lang_list: ["east_slavic"] # 俄语、白俄语、乌克兰语 # 阿拉伯语 lang_list: ["arabic"] # 阿拉伯语、波斯语、乌尔都语等后端选择 (
backend)
后端 适用场景 硬件要求 特点 pipeline通用场景 CPU/GPU 均可 无幻觉、多语言、资源占用低 hybrid-auto-engine高精度需求 GPU 8GB+ 下一代方案,精度最高 vlm-auto-engine中英文高精度 GPU 8GB+ 基于VLM,精度高 vlm-http-client远程调用 仅需网络 连接 OpenAI 兼容服务器 解析方法 (
parse_method)仅对
pipeline/hybrid后端有效:
parse_method: "auto" # 自动选择(推荐) parse_method: "txt" # 强制文本提取(适合文本型PDF) parse_method: "ocr" # 强制OCR(适合扫描件)功能开关
formula_enable: true # 启用公式解析(转为LaTeX) table_enable: true # 启用表格解析(转为HTML)返回内容控制
return_md: true # Markdown格式(最常用) return_content_list: true # 结构化内容列表 return_middle_json: false # 中间结果(调试用) return_model_output: false # 模型输出(调试用) return_images: true # 提取的图片高级选项
start_page_id: 0 # 起始页(从0开始) end_page_id: 10 # 结束页(不包含10) response_format_zip: true # 返回ZIP包 return_original_file: true # 包含原文件(ZIP模式)
4、示例1
针对不确定是文字版还是扫描版 且含有表格 的PDF,auto + table_enable=true 是最佳组合。
parse_method: "auto" # 自动识别文档类型,智能选择txt/ocr
table_enable: true # 启用表格解析,转为HTML格式
formula_enable: true # 启用公式解析(如果文档有公式)
auto模式的工作原理
auto模式会智能判断:
文档类型 自动选择方法 说明 文字版PDF(可选中的文本) txt模式直接提取文本,速度快,无OCR误差 扫描版PDF(图片形式) ocr模式自动调用OCR识别文字 混合型PDF(部分页面扫描) 逐页判断 每页独立选择最优方法 推荐的完整配置
针对此场景,建议这样设置:
# 基础配置 files: 你的文档.pdf parse_method: auto # 自动识别文字版/扫描版 backend: pipeline # 通用后端,兼容性好 lang_list: ["ch"] # 中文文档(根据实际调整) # 功能开关 table_enable: true # 表格解析(推荐) formula_enable: true # 公式解析(如果有公式) return_md: true # 返回Markdown # 输出控制 return_content_list: true # 返回结构化内容(方便程序处理) response_format_zip: false # 先用JSON测试,需要图片再改ZIP
5、使用如下
方式1:cURL 命令
curl -X POST "http://服务器ip:port/file_parse" \
-F "files=@document.pdf" \
-F "parse_method=auto" \
-F "table_enable=true" \
-F "formula_enable=true" \
-F "lang_list=ch" \
-F "backend=pipeline" \
-F "return_md=true" \
-F "return_content_list=true"方式2:Python 调用
import requests
url = "http://服务器ip:port/file_parse"
files = {
'files': ('document.pdf', open('document.pdf', 'rb'))
}
data = {
'parse_method': 'auto', # 自动识别
'table_enable': True, # 解析表格
'formula_enable': True, # 解析公式
'lang_list': ['ch'], # 中文
'backend': 'pipeline', # 通用后端
'return_md': True,
'return_content_list': True
}
response = requests.post(url, files=files, data=data)
result = response.json()
# 保存 Markdown
with open('output.md', 'w', encoding='utf-8') as f:
f.write(result['md_content'])
# 如果包含表格,在Markdown中会呈现为HTML格式
print(result['md_content'])表格解析效果
启用 table_enable=true 后,表格会被解析为 HTML 格式嵌入在 Markdown 中:
# 解析结果示例
这是文档中的一段文字。
<table>
<tr>
<th>姓名</th>
<th>年龄</th>
<th>职位</th>
</tr>
<tr>
<td>张三</td>
<td>28</td>
<td>工程师</td>
</tr>
<tr>
<td>李四</td>
<td>32</td>
<td>经理</td>
</tr>
</table>
后续文字...如何确认解析效果
方法1:查看返回的 content_list
{
"content_list": [
{"type": "text", "content": "段落文字..."},
{"type": "table", "content": "<table>...</table>", "html": "..."},
{"type": "formula", "content": "$$E=mc^2$$", "latex": "..."}
]
}方法2:检查 parse_method 实际使用的方法
从日志或响应中可以看到系统选择了哪种方法:
-
如果是文字版:自动用
txt -
如果是扫描版:自动用
ocr
高级建议
如果表格解析不理想
# 可以尝试 hybrid 后端(如果GPU显存≥8GB)
backend: hybrid-auto-engine
table_enable: true如果文档包含多种语言
lang_list: ["ch", "en"] # 同时支持中文和英文如果需要提取表格中的公式
table_enable: true
formula_enable: true # 表格内的公式也会被解析注意事项
-
表格复杂度:简单表格(3-5列)解析效果好,复杂嵌套表格可能有偏差
-
OCR准确性:扫描版表格的识别精度取决于扫描质量
-
性能 :
auto模式会逐页判断,大文件处理时间稍长