论文标题:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
发布时间:2024 年 1 月
DeepSeek MoE最核心的就是 DeepSeek V1的前馈网络(FFN)替换成了 MoE 层。
具体:
- 在 2B 规模的验证实验中 :研究人员确实将 所有(all) 前馈网络(FFN)替换成了 MoE 层。
- 在更大规模的模型中(16B 和 145B) :DeepSeek 采取了不同的策略,即除了第一层(first layer)之外,将其余各层的 FFN 替换为 MoE 层。
为什么要保留第一层的前馈网络? 论文提到,这是因为观察到第一层的负载均衡(load balance)状态收敛速度显著慢于其他层。为了训练的稳定性和效率,16B 和 145B 模型在第一层保留了标准的稠密 FFN 结构。
1.为什么需要 MoE 代替 FFN?
- 计算效率与规模的平衡:研究表明,增加参数量和计算预算可以显著提升模型能力,但极大规模的模型会导致极其高昂的计算成本。
- 稀疏激活:MoE 架构允许模型拥有巨大的总参数量,但在处理每个 token 时只激活一小部分专家,从而在保持计算量(FLOPs)适中的同时,实现参数规模的扩展
2. 传统 MoE 架构存在的问题
DeepSeek 认为,像 GShard 这种传统的"Top-K"路由 MoE 架构虽然比稠密模型(Dense)高效,但仍然无法达到性能的理论上限,主要原因有两点:
- 知识杂合(Knowledge Hybridity) :
- 问题:传统架构通常只使用少量的专家(如 8 个或 16 个),导致每个专家需要处理涵盖多种不同领域的知识。
- 后果:由于分配给特定专家的 token 涵盖了过于广泛的知识,该专家被迫在其参数中汇集极不相同的知识类型,而这些知识很难被同时有效利用。
- 知识冗余(Knowledge Redundancy) :
- 问题:被分配到不同专家的多个 token 可能都需要一些通用的公共知识。
- 后果:这会导致多个专家在各自的参数中重复学习并存储相同的通用知识,从而造成专家参数的浪费和冗余,降低了参数效率.
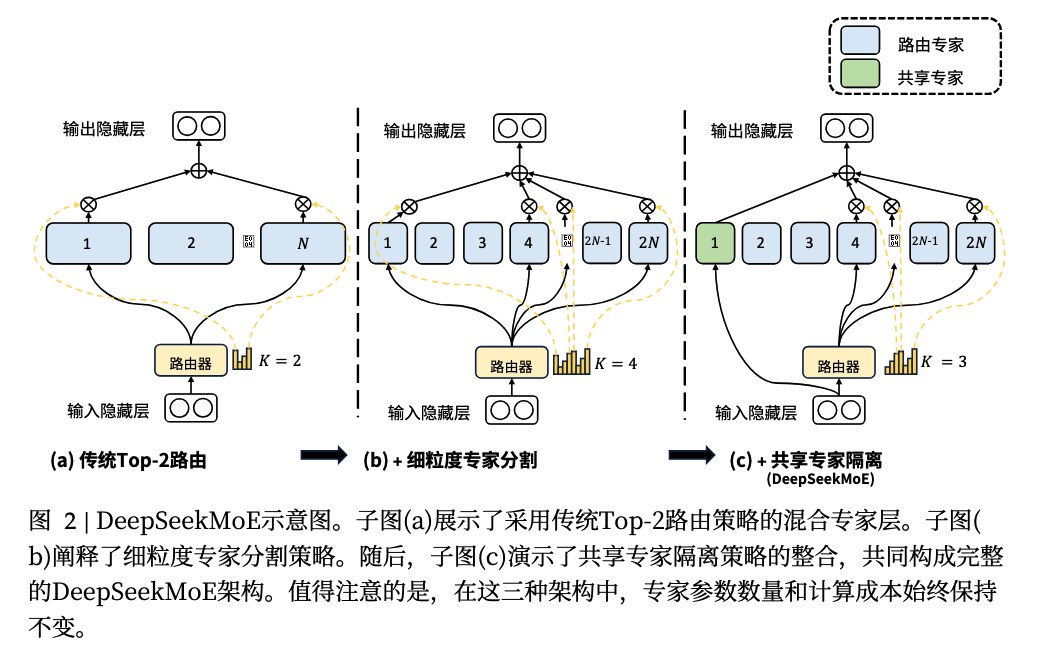
3.DeepSeek MoE 提出了两大核心策略:
- 细粒度专家切分(Fine-Grained Expert Segmentation):在保持总参数量不变的前提下,将专家切分成更小的单元(例如将一个标准 FFN 切分为 m 个小专家),并激活更多的小专家。这种做法极大地提升了激活专家的组合灵活性(例如从 120 种组合增加到超过 44 亿种),使模型能更精确地学习和调用特定知识。
- 共享专家隔离(Shared Expert Isolation) :将部分专家设置为"共享专家",这些专家对所有 token 始终保持激活状态,不参与路由选择。其目的是让这些共享专家集中捕捉公共知识,从而减少其他路由专家在学习这些通用知识时的冗余,提高参数效率。
下面是细粒度专家分割和共享专家隔离的公式,省略了层归一化。中心向量 被视为模型中的可学习参数(learnable parameters),
∈ RT×d 表示第 l个注意力模块后所有标记的隐藏状态 。在训练开始前,它们与其他模型参数一样,会被随机初始化 。例如,在 DeepSeekMoE 的不同规模配置中,这些参数通常以 0.006 的标准差进行随机初始化。
 细粒度专家分割
细粒度专家分割
 共享专家隔离
共享专家隔离
4. 训练与系统优化
为了确保模型在大规模训练中的效率和稳定性,论文进行了以下优化:
- 高效训练框架(HAI-LLM):采用轻量级训练框架,集成张量并行、ZeRO 数据并行和流水线并行。
- 双层负载均衡策略 :
- 专家级平衡损失(Expert-Level Balance Loss):防止路由崩塌,确保每个专家都能得到充分训练。
- 设备级平衡损失(Device-Level Balance Loss):在专家分布于不同设备时,优化计算平衡,减少计算瓶颈
4.1 专家级平衡损失


4.2 设备级平衡损失


5. 性能验证与扩展性
论文通过不同规模的模型展示了该架构的卓越性能:
- 2B 规模验证:DeepSeekMoE 2B 的性能可以匹配参数量和计算量是其 1.5 倍的 GShard 2.9B,并且接近同参数密集的 Dense 模型(MoE 性能的理论上限)。
- 16B 规模扩展 :DeepSeekMoE 16B 仅使用约 40% 的计算量,就达到了与 LLaMA2 7B 相当的性能。
- 145B 规模潜力 :初步实验表明,DeepSeekMoE 145B 仅需约 28.5%(甚至可能低至 18.2%)的计算量,即可达到与 DeepSeek 67B 稠密模型相当的水平。
总结: 这篇论文通过细粒度专家切分 和共享专家隔离,成功地在显著降低推理和训练计算开销的同时,保持了极强的模型能力,为大规模语言模型的高效扩展提供了一条新的技术路径。