1.从函数到神经网络

线性函数通过改变w,b就可能符合,但有时往往不够,要用到非线性函数;即可以用激活函数,它的目的就是把原本死气沉沉的线性关系给盘活了,变成了变化能力非常强的非线性关系
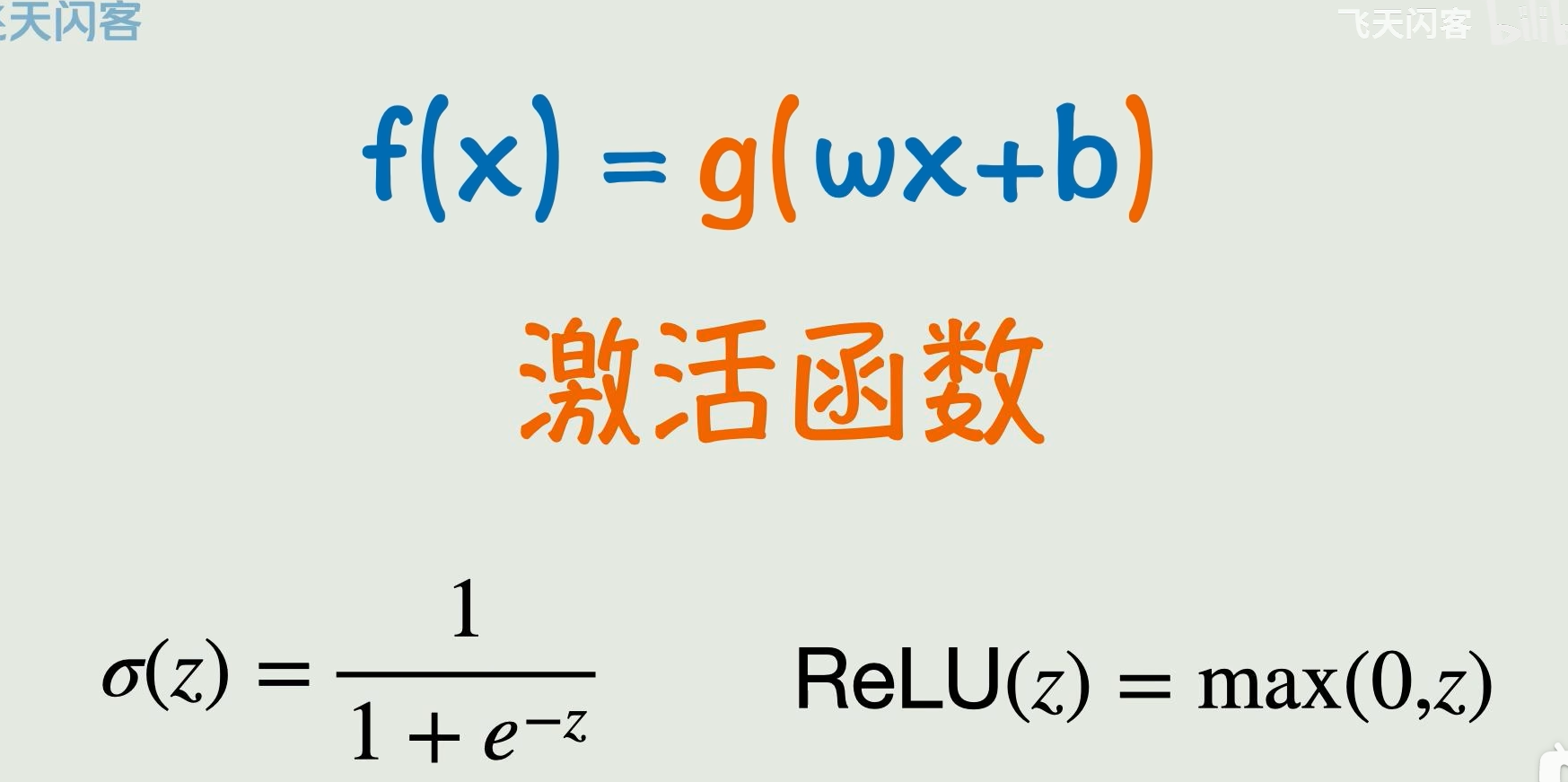
现实往往会有很多参数、会套很多层;可以一直进行套娃
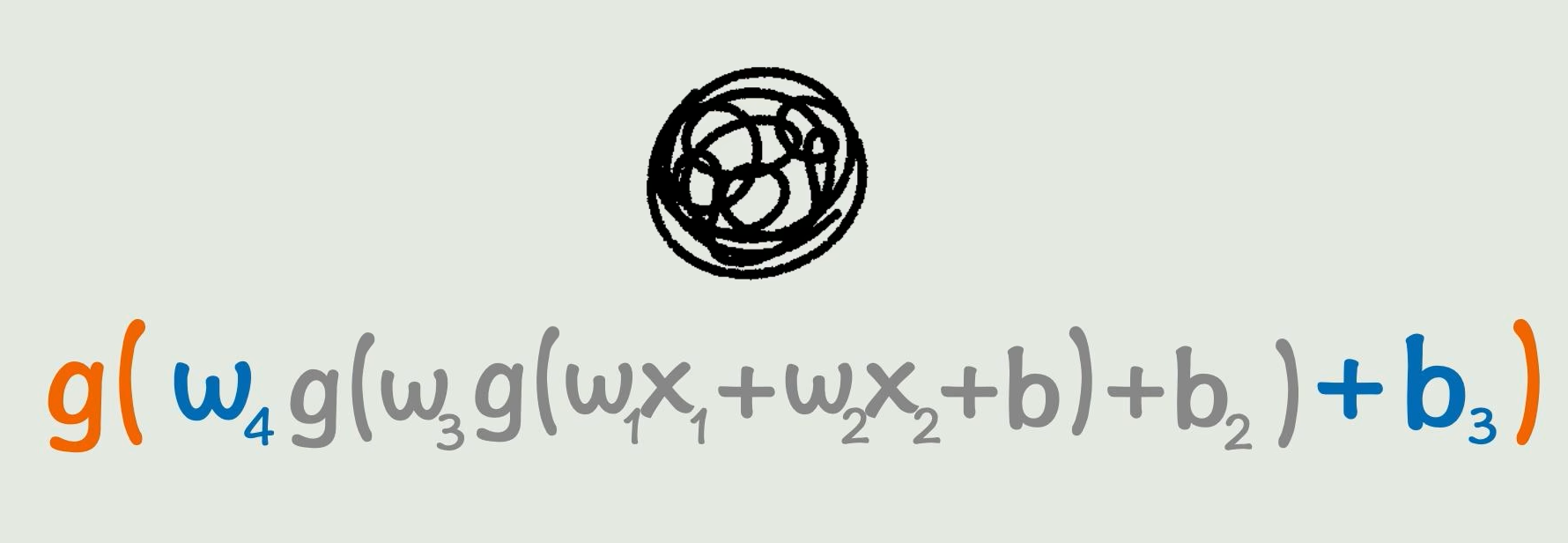
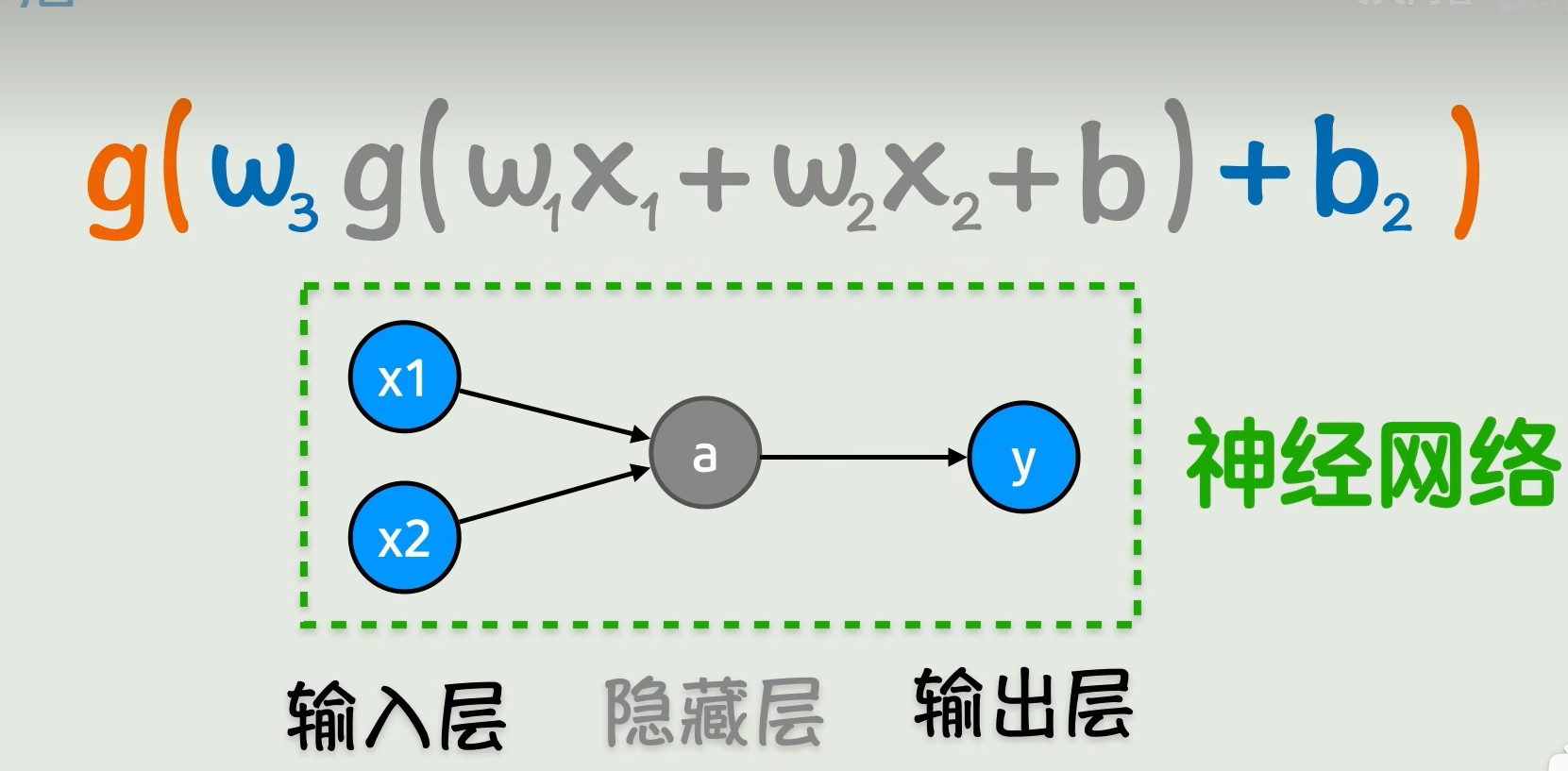
从神经网络这个图来看,就像信号从左向右传播了过去,那这个过程就叫做神经网络的前向传播
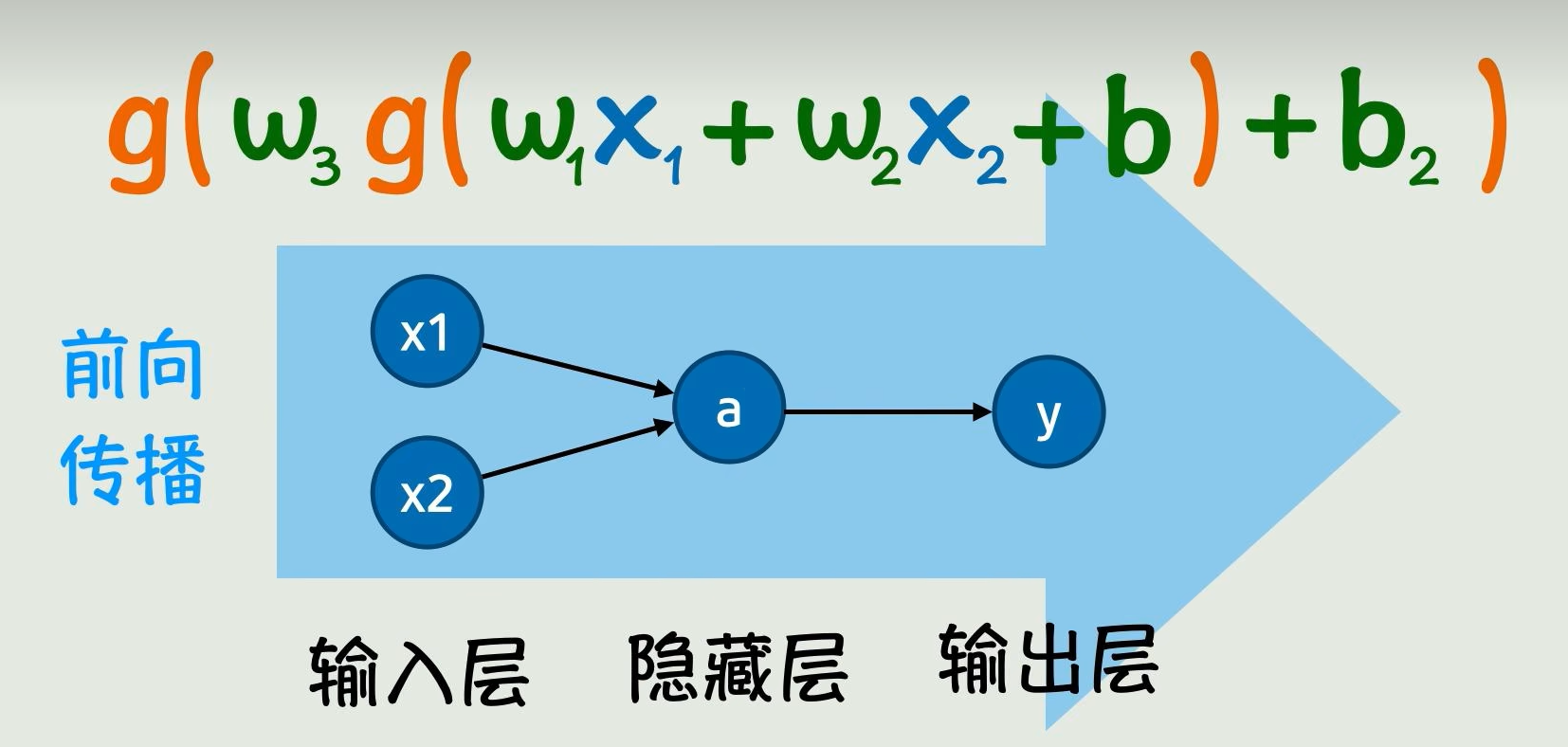
2.计算神经网络的参数
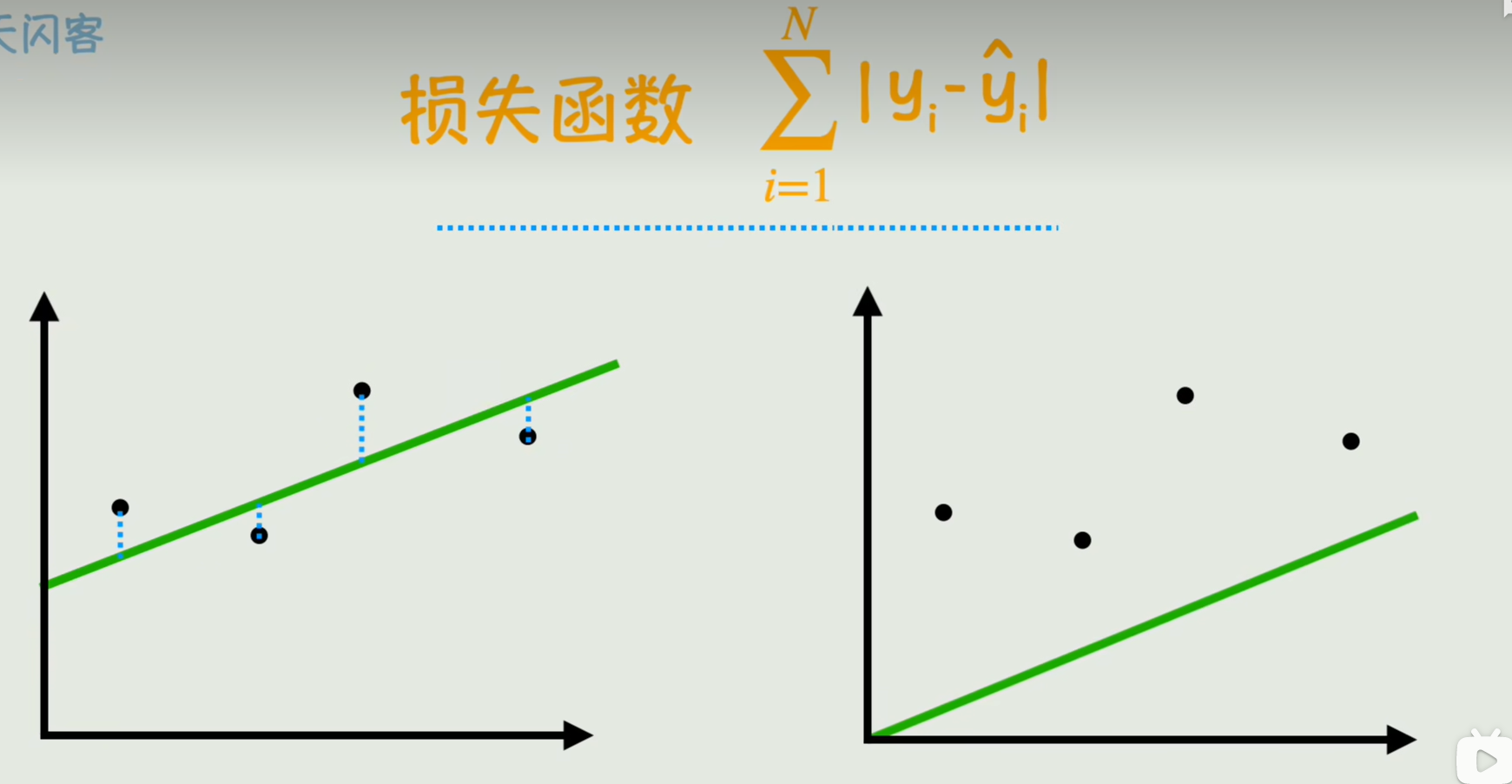
要构建一个线性函数,找到一个好的参数w,b就是越拟合真实数据越好,
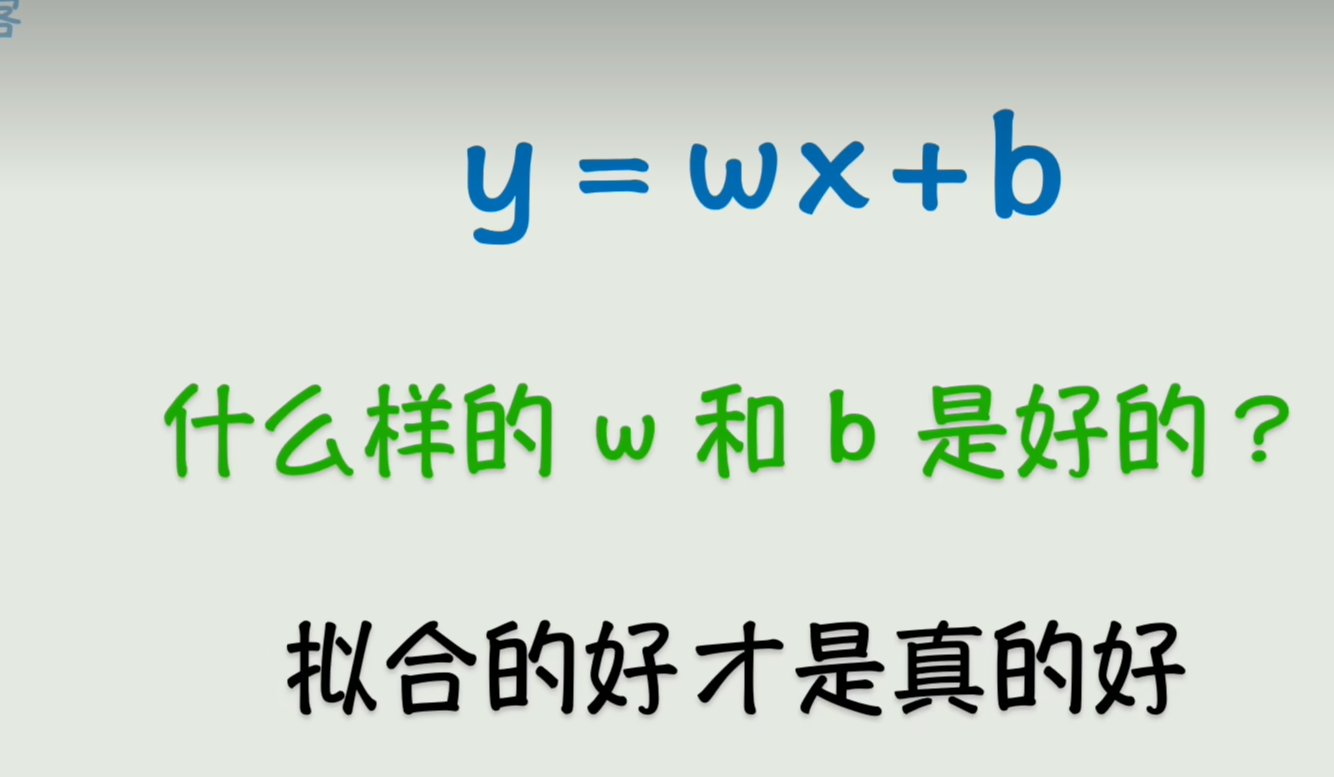
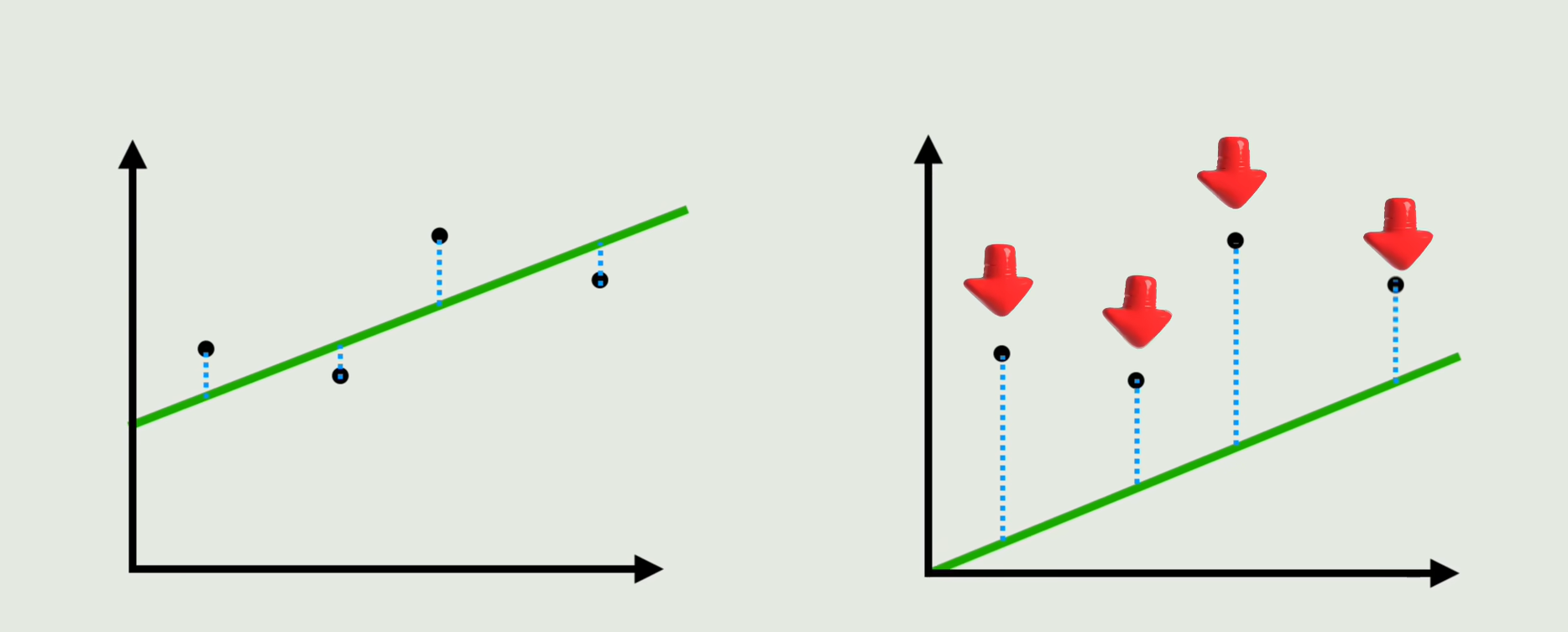
从数学的角度判断拟合的好坏,就是在每一个点上画一条竖直的线,使其与你的直线相交,由于这里的每个点的纵坐标表示的是真实数据,用y来表示,若在直线上的点表示预测值,用y^来表示,那么竖直方向的线段的长度就是真实值与预测值之间的误差,
将所有竖直方向的线段加起来,就叫做损失函数
再调整一下公式,就得到了均方误差公式:表示损失函数的一种
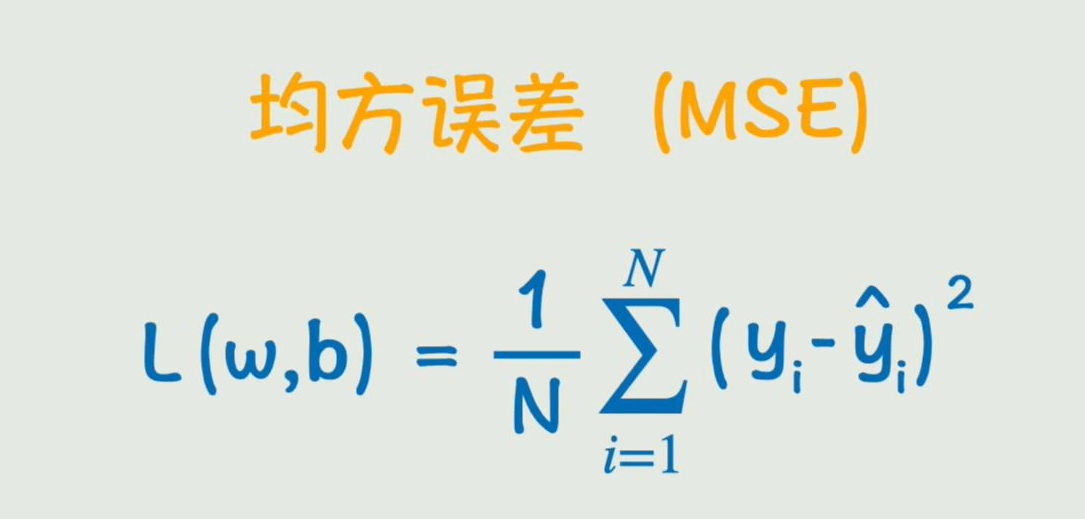

求解方法:数学上让导数=0,求极值点;对于多元函数是求偏导,
这种通过寻找一个线性函数来拟合x,y的关系,就是机器学习中最基本的一种分析方法:线性回归,
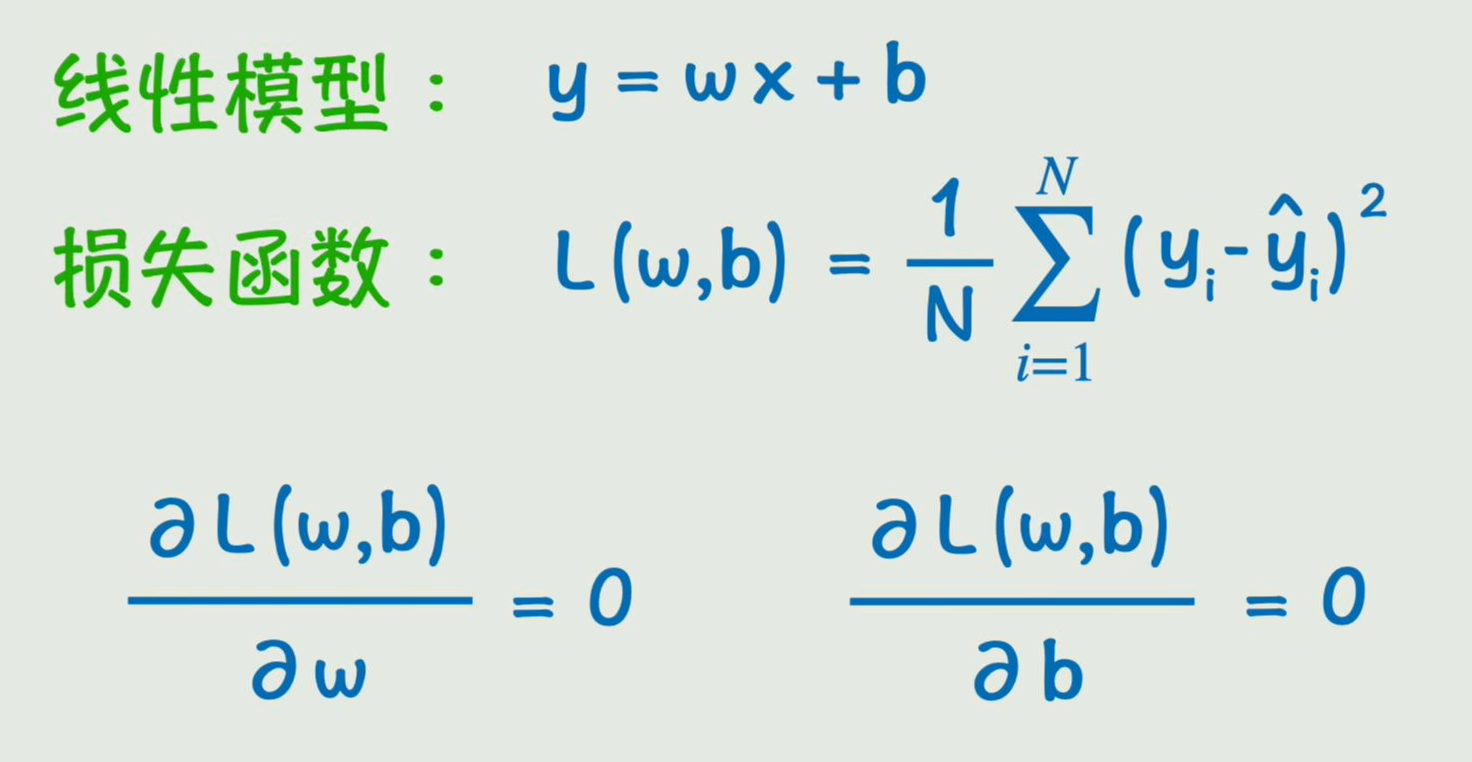
对于减小多元函数的损失函数值,就是一点点试;不断改变w,b观察损失函数的变化,每次都看下当前状况,调整w/b对损失函数的影响,然后每次把参数想着让损失函数变小的方向调整一点点,直到让损失函数足够小,
过程:
w变化一点点,使得损失函数会变化多少,这其实就是损失函数对w的偏导数;然后让w不断往偏导数的反方向去变化,具体变化的快慢,就再加一个系数【学习率】,这些偏导数所构成的向量就叫做梯度,而不断变化w,b让损失函数逐渐减小的过程,进而求出最终的w,b这个过程叫做梯度下降,
难点:偏导数不好求
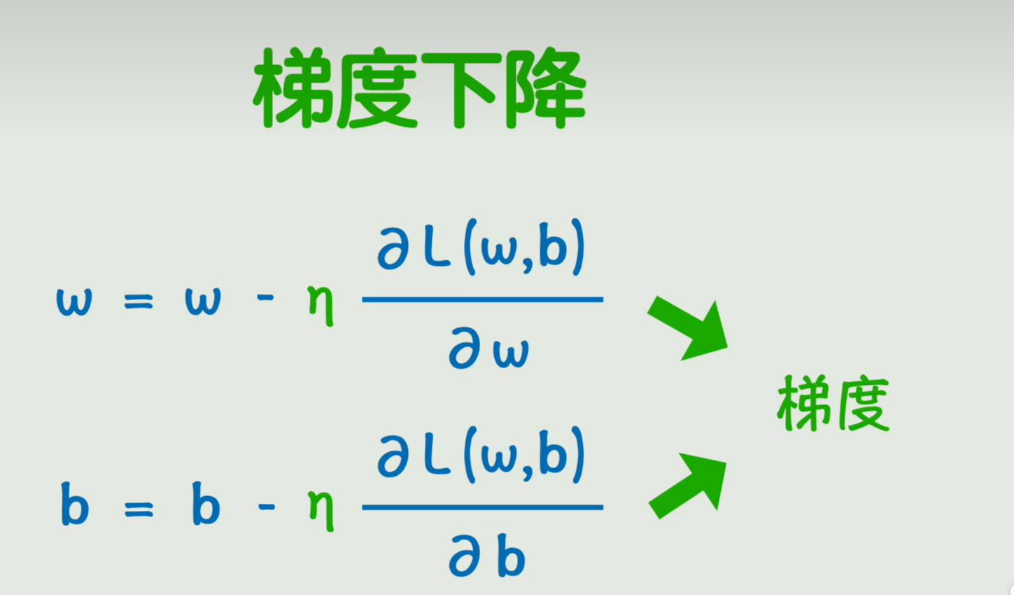
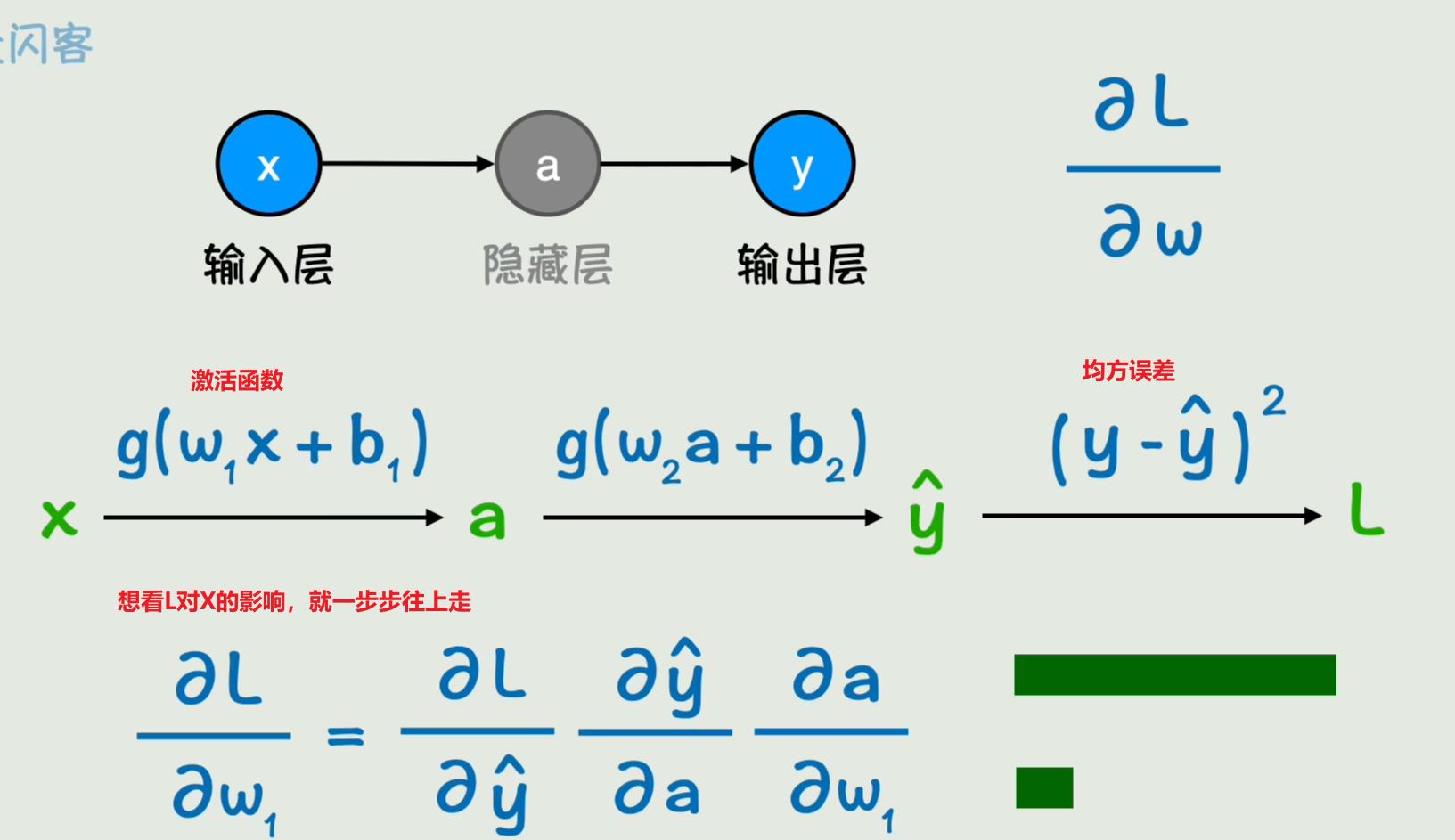
可以使用链式法则,也就是微积分中的复合函数求导,我们可以从右向左一次求导,然后逐步更新每一层的参数,直到把所有神经网络的参数都更新一遍,
前向传播:根据输入x计算输出y
反向传播:计算出损失函数关于每个参数的梯度,然后每个参数都向着梯度的反方向变化一点点,这就构成了神经网络的一次训练

3.调教神经网络的方法
过拟合:在训练数据上表现的很好,但是在没见过的数据上表现的很糟糕的现象
泛化能力:在没见过的数据上的表现能力
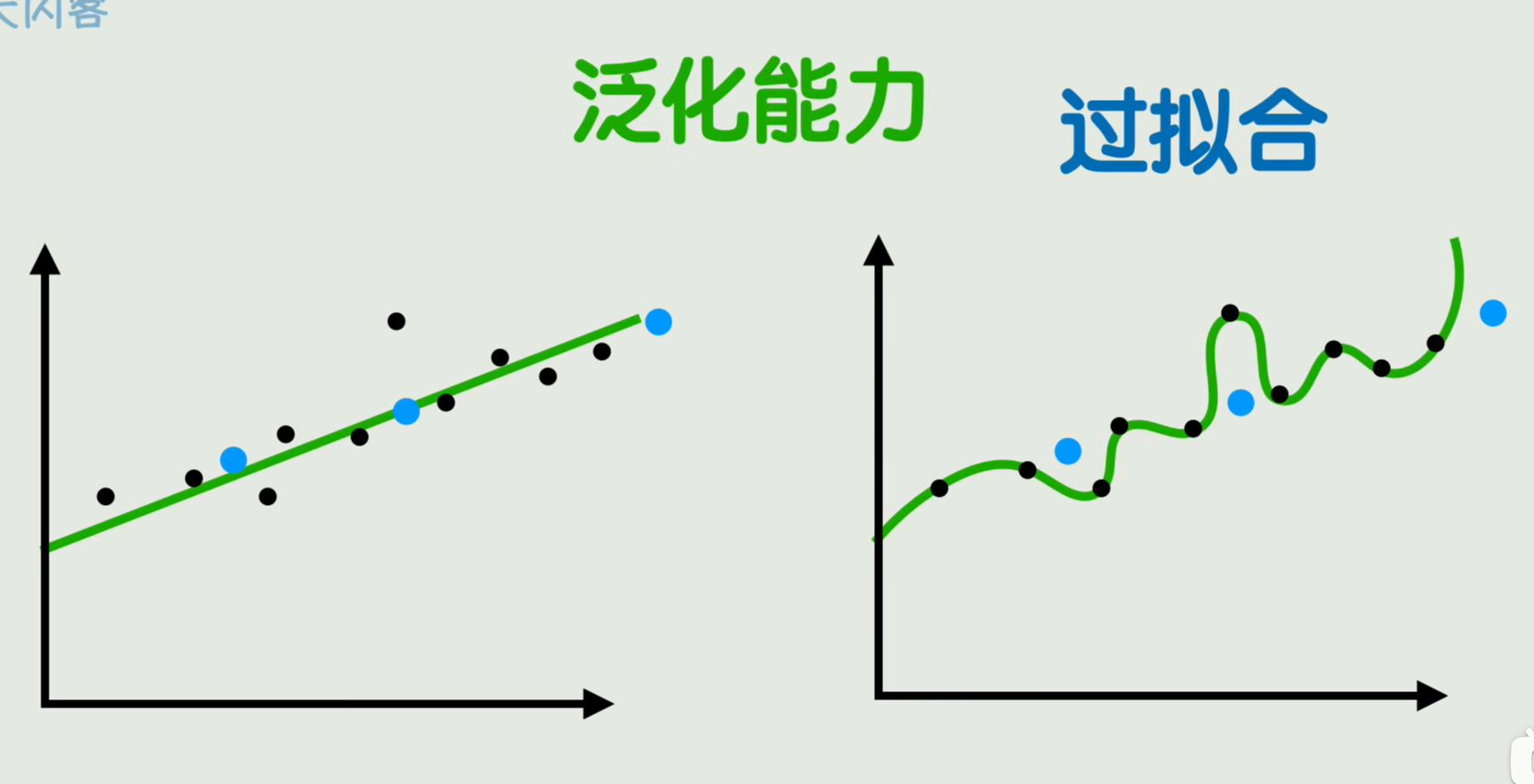
解决过拟合的方法:
1.简化模型复杂度
2.增加训练数据的量,如果没有较多的数据,就创造数据,比如对图像进行旋转、翻转、裁剪、加噪声、创造更多的新的训练样本,这也叫做数据增强。这样不仅增加了数据量,还让模型不因输入的一点点小的变化,而对结果产生很大的波动,这就是增强了数据的鲁棒性,
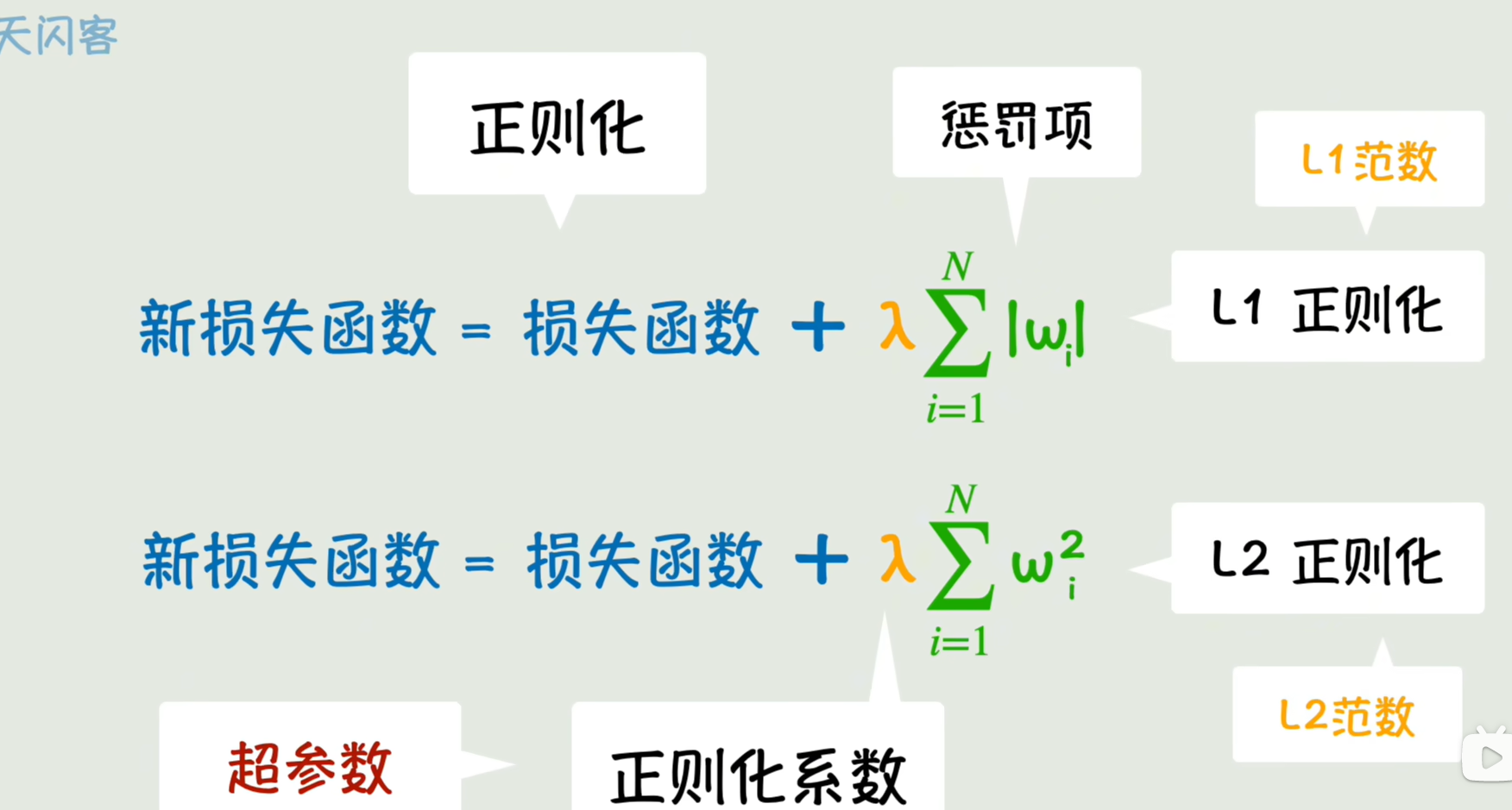
3.从训练过程中入手,即不断调整参数,也可以提前终止训练/抑制参数的野蛮增长,如下图,在损失函数中,把参数本身的值加上,这样在参数往大了的调整时,如果让损失函数减小的没有那么多,导致新的损失函数反而是变大的,那么此时的调整是不合适的,因此一定程度上就抑制了,参数的野蛮增长

绿色的这一项叫做惩罚项;
把通过 这种向损失函数中添加权重惩罚项,抑制其野蛮增长的方法叫做正则化,
和之前梯度下降时,增加学习率控制下降力一样,我们也增加一个参数来控制惩罚项的力度,即正则化系数。这种控制参数的参数叫做超参数
可以在训练中每次都随机丢弃一部分参数,这样模型就必须依赖更多的普通参数,从而避免了在某些关键参数上过度依赖的风险,这种方法叫Dropout



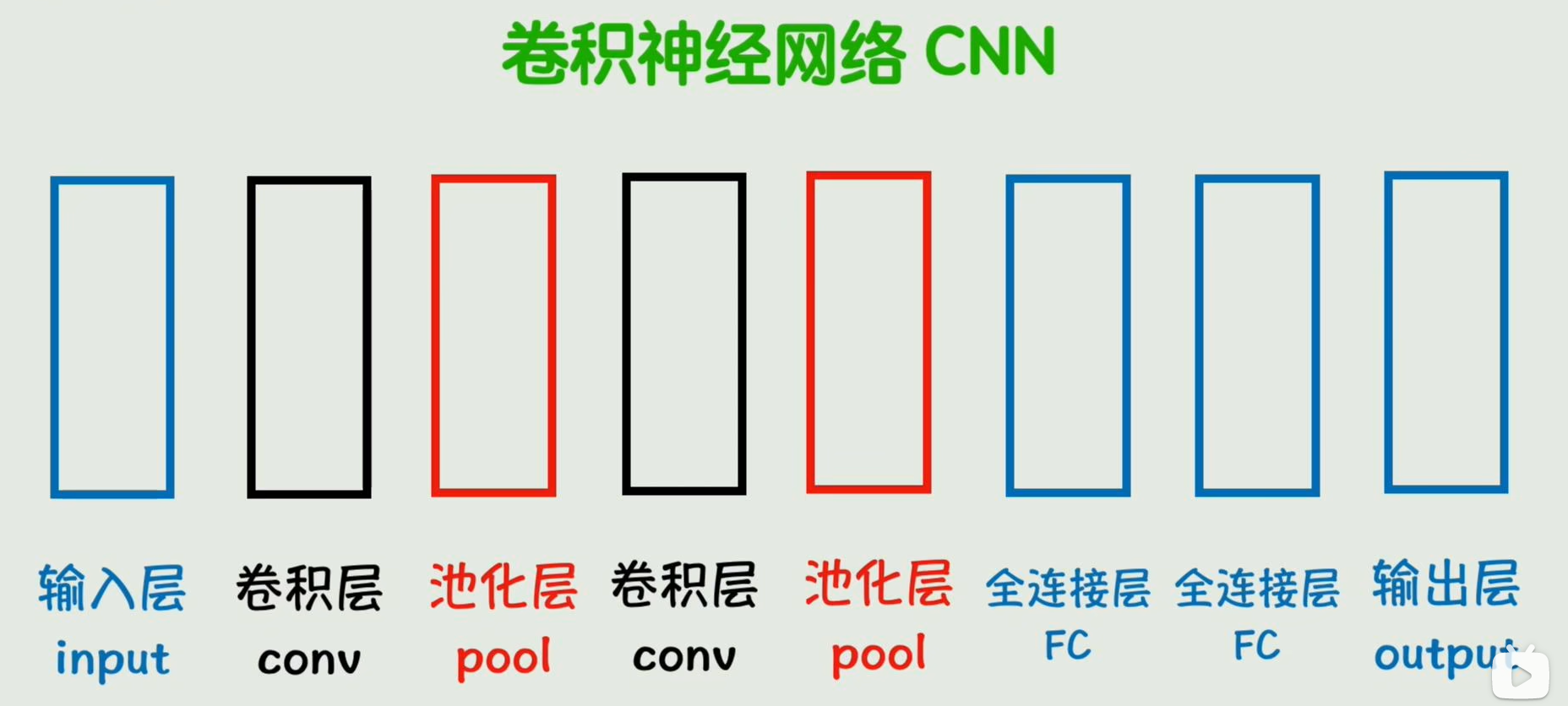
4.从矩阵到CNN
将这个长的式子换成矩阵
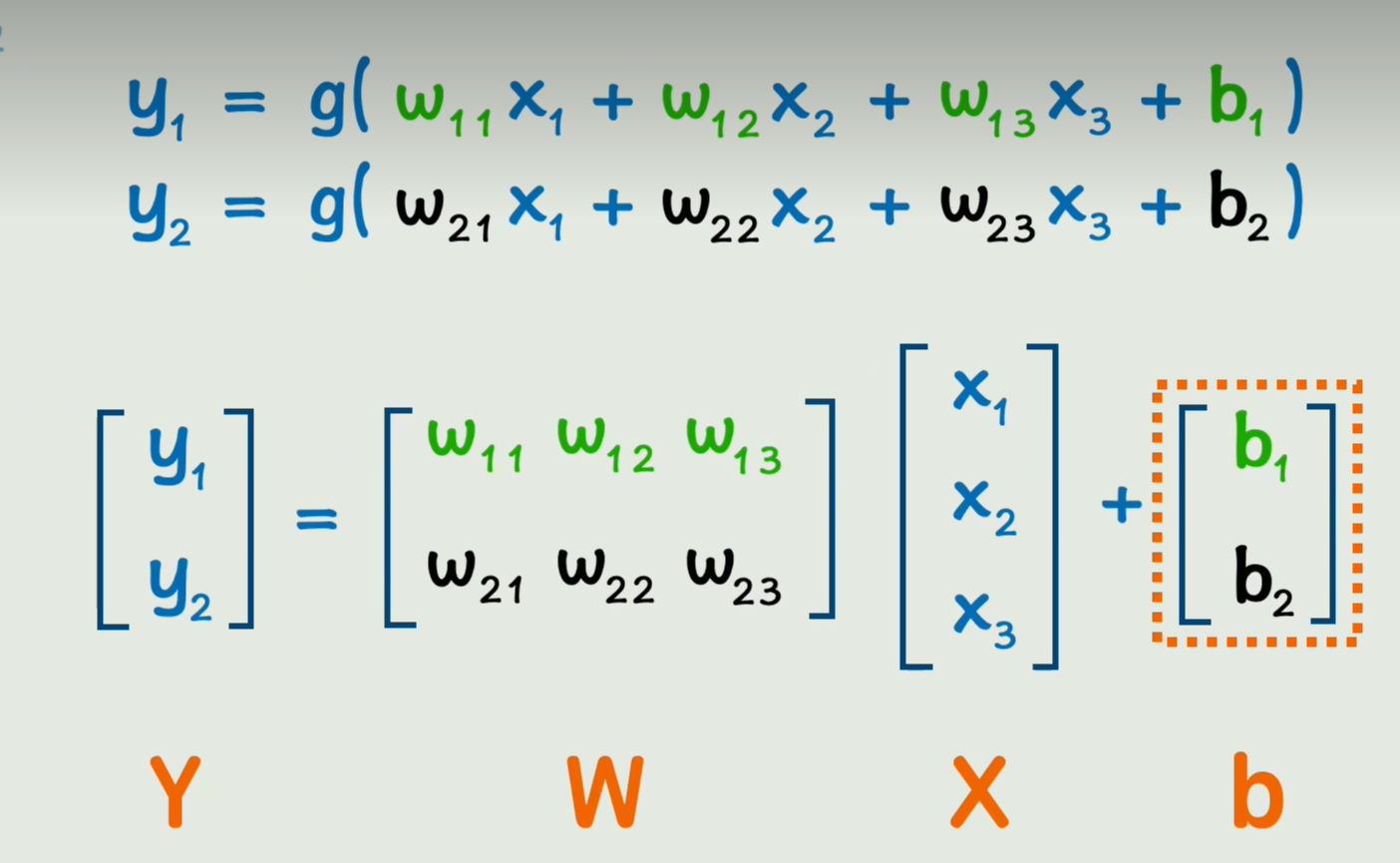
将矩阵用大写字母表示后,但是无法体现神经网络有很多层,所以可以上面标一个标号
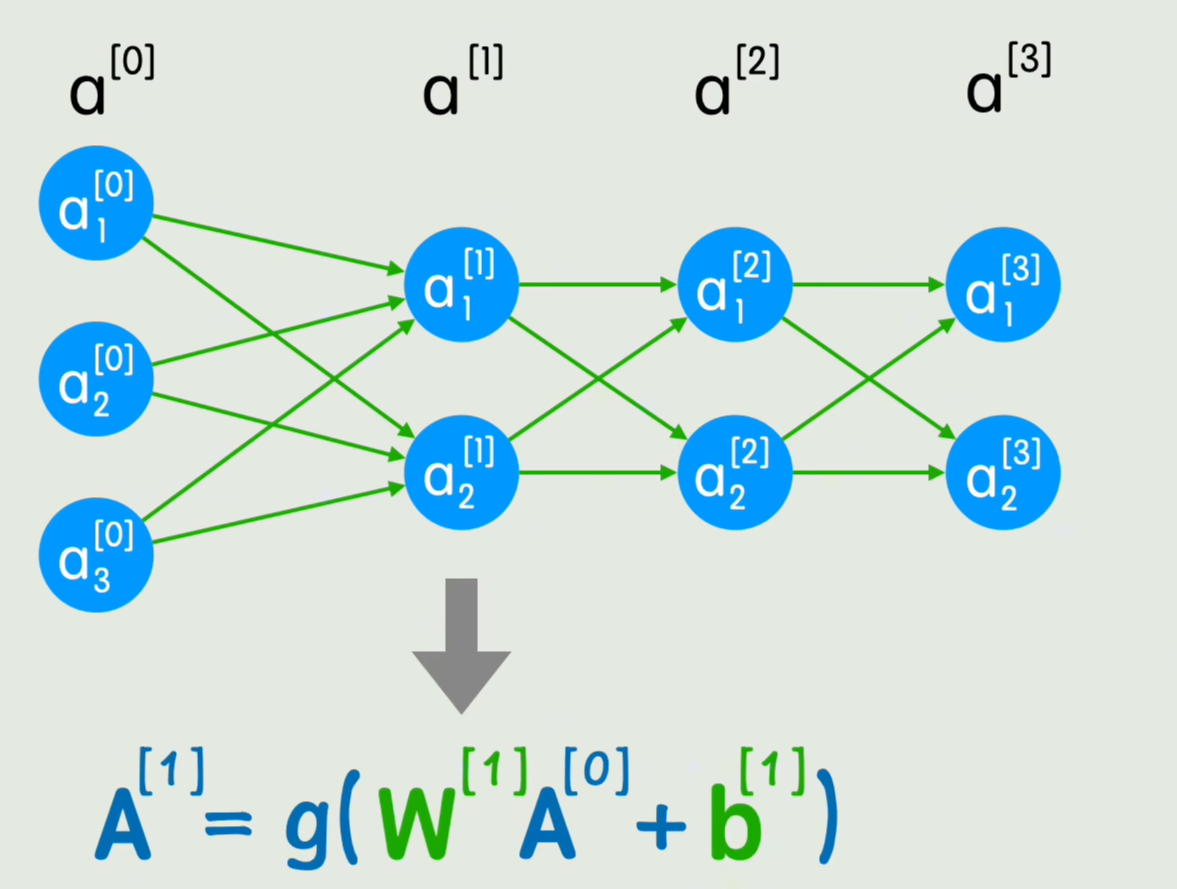
通式

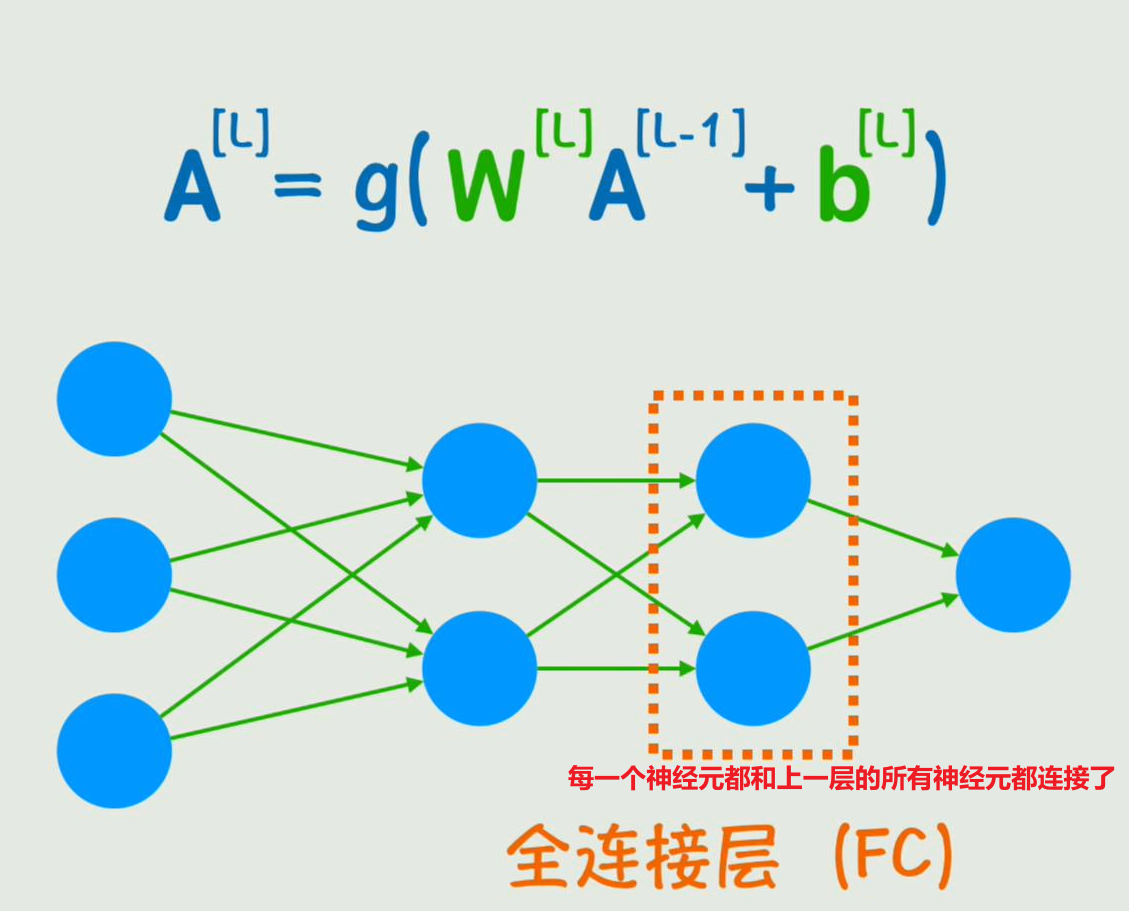
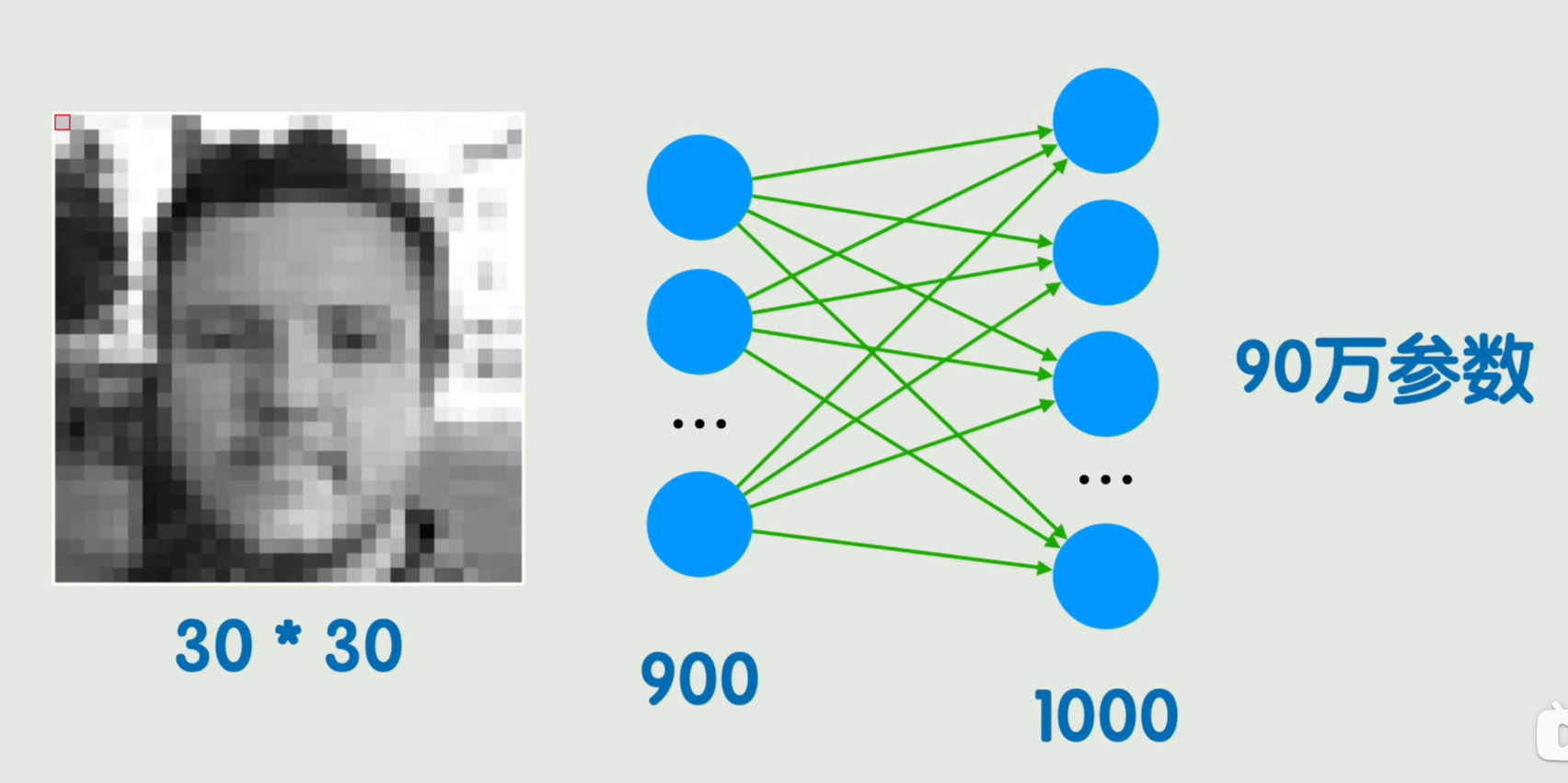
全连接层缺点:假如一个图片像素是:30*30,那么就是9000个参数,越往后面,隐藏层的神经元将很大,而且图像稍稍动一下,可能所有的神经元都和原来不同,那么就是不能很好的理解图像的局部模式
那么,假设随便取一个3*3的矩阵,里面像素表上数值即颜色的灰度值,然后再来一个固定的矩阵,再将两个矩阵对应位置处的值相乘并求和,之后再选取其他地方再次进行计算,这样得出的数值形成一个新的图像,这种方式叫做卷积运算,而刚刚那个固定的矩阵叫做卷积核,
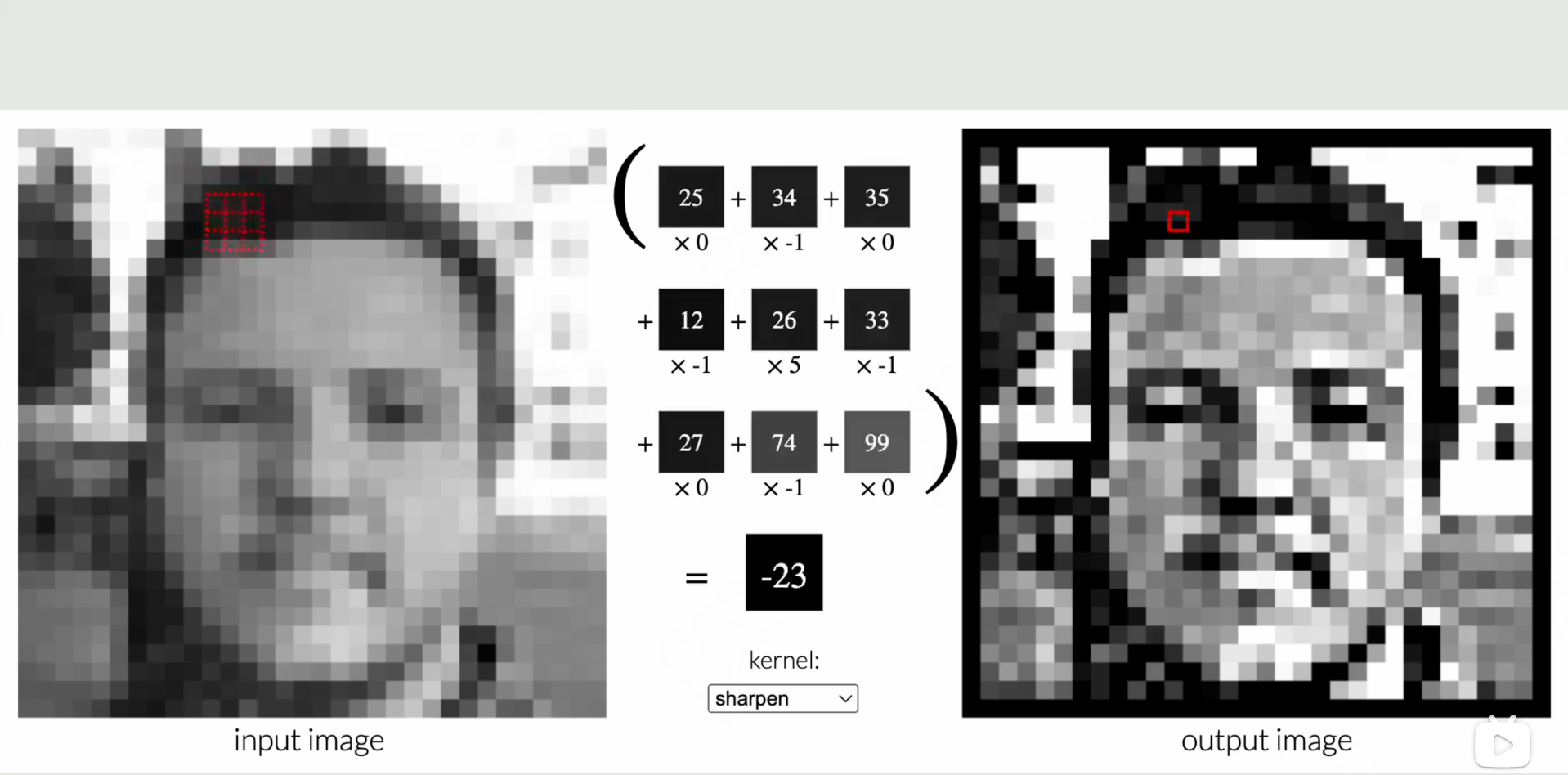
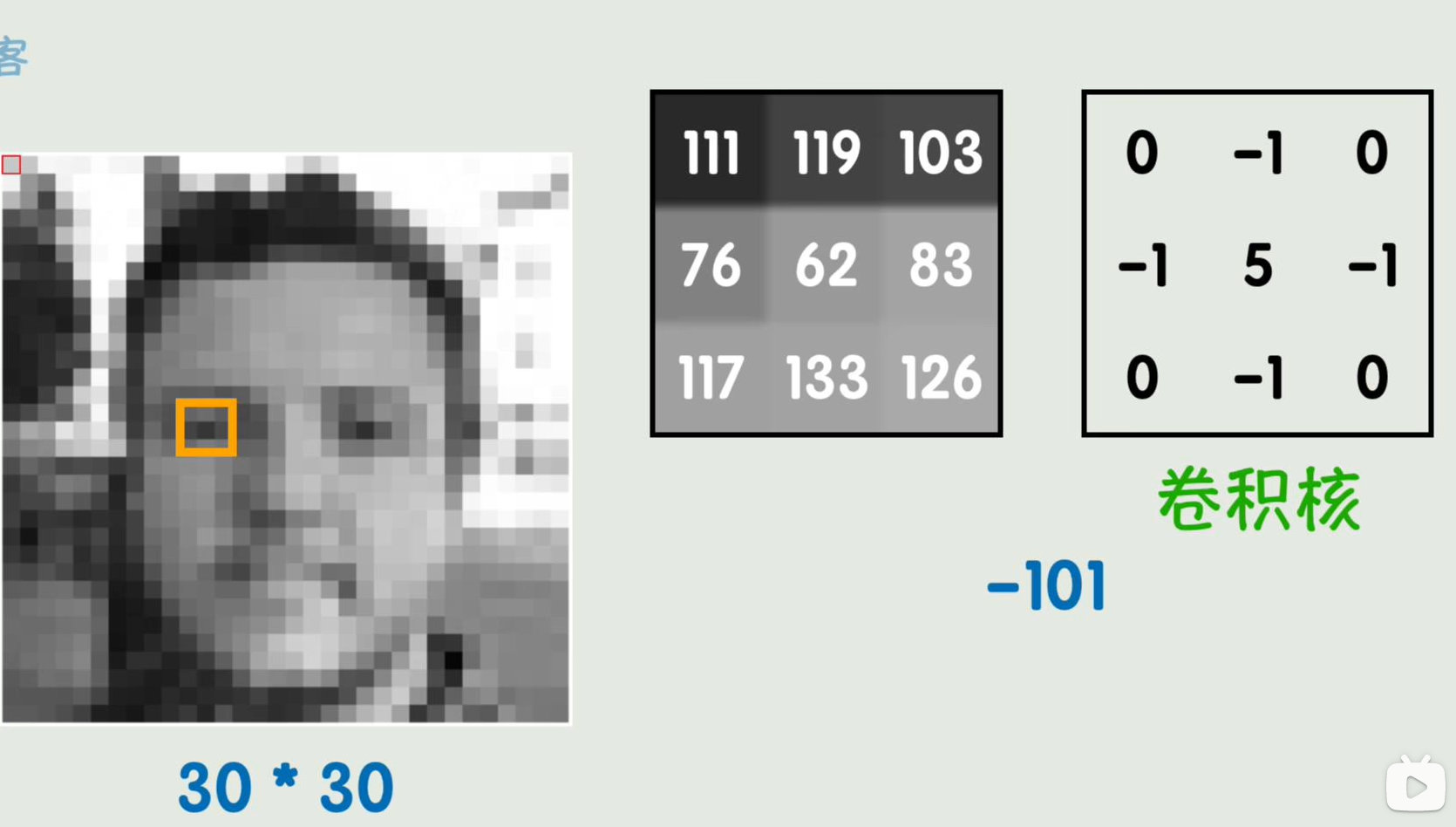
在深度学习中,卷积核的值是未知的,和神经网络的其他参数一样是被训练出来的,
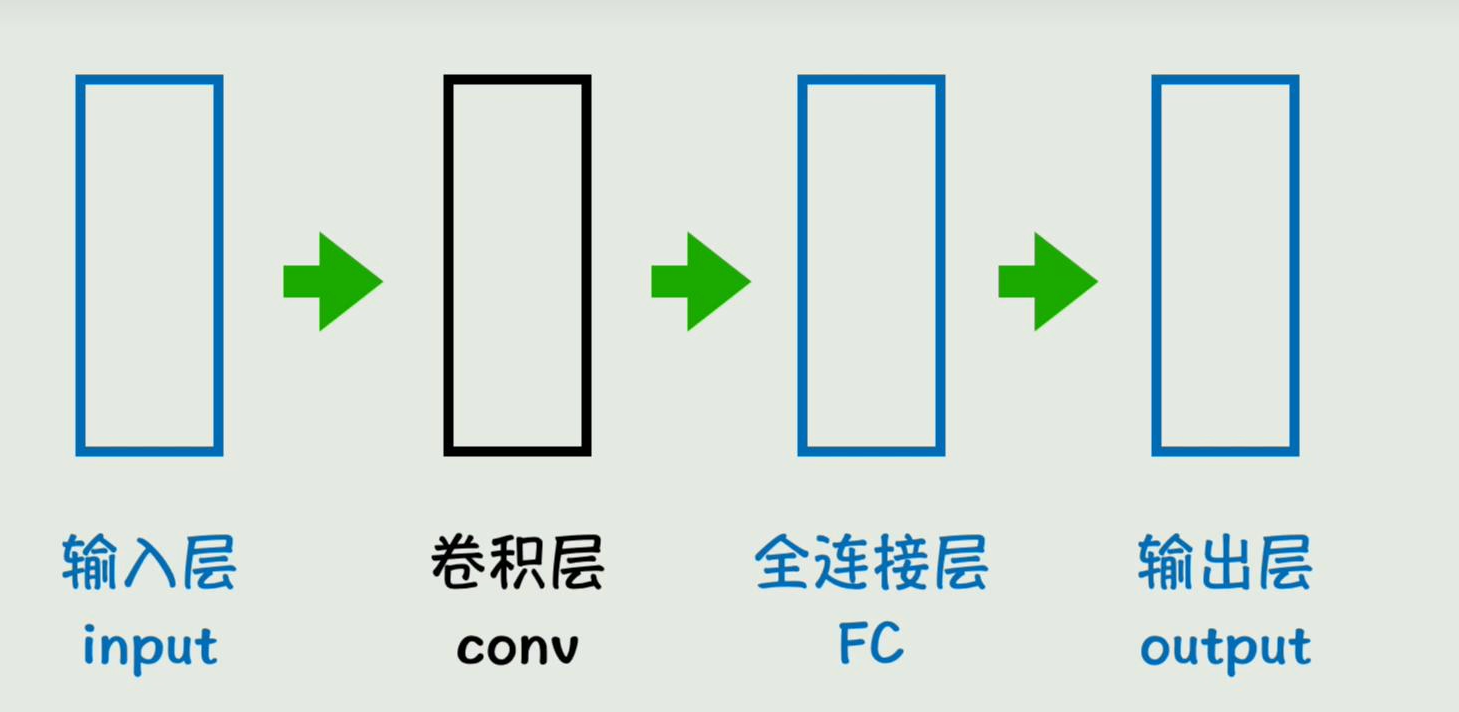
就是把其中一个全连接层替换为卷积层conv,这样就大大减少了权重参数的数量,同时还能更有效的捕捉到图片中的一些局部特征
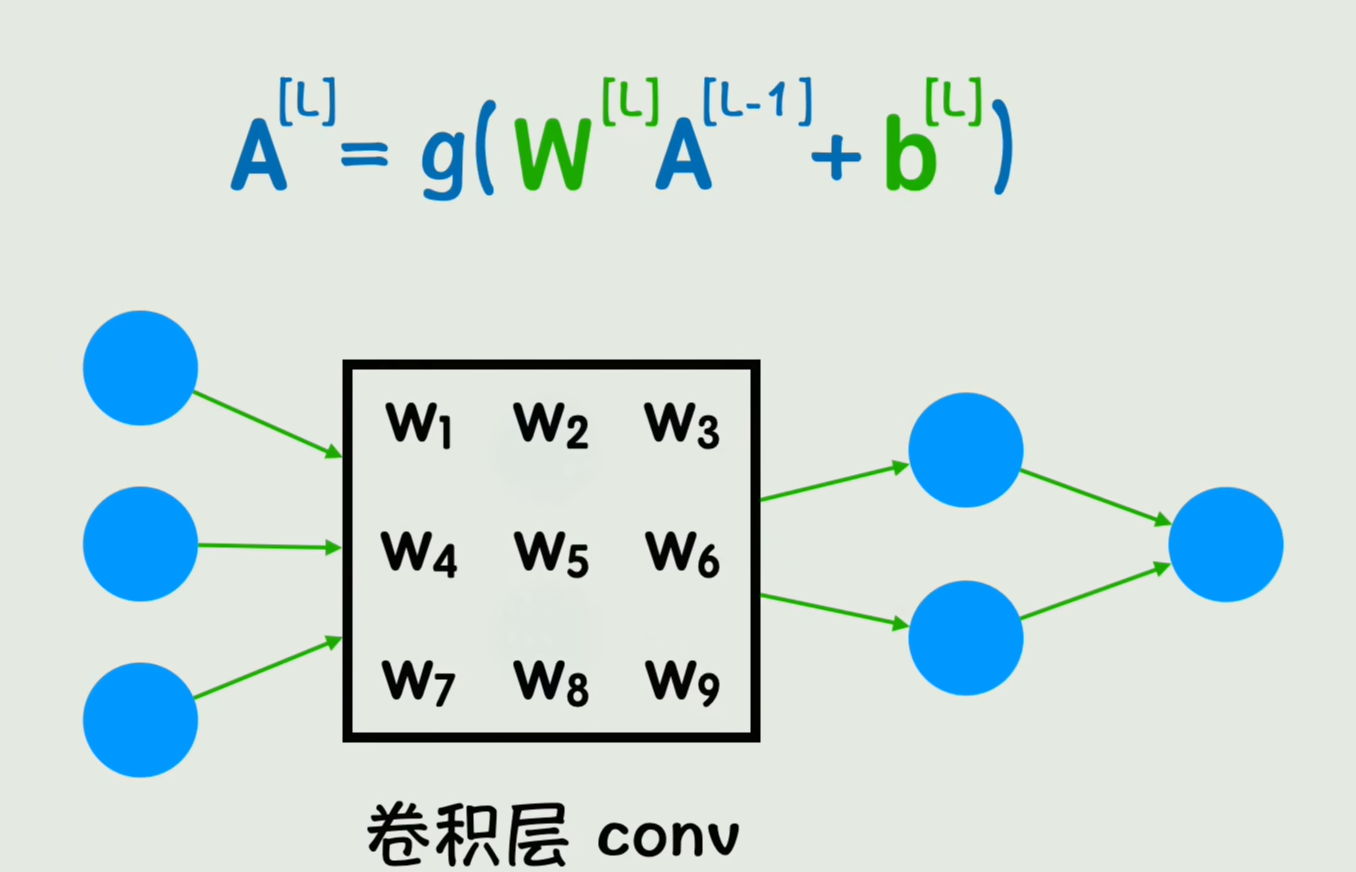
从公式上来看,将原来的叉乘变成了卷积运算

接着神经网络用这种方式进行简化
5.从RNN到transformer
想让机器识别这些文字,就要给文字进行编码
2种极端方式:
1.只用一个数字标识,来代表每个词,缺点:维度低,数字表示本身对语言理解没有任何意义,无法衡量词和词的相关性
2.独热编码ong-hot:使用一个超级大的向量,每个词只有向量中一个位置是1,剩下的都是0,缺点:维度太高了,而且非常稀疏,

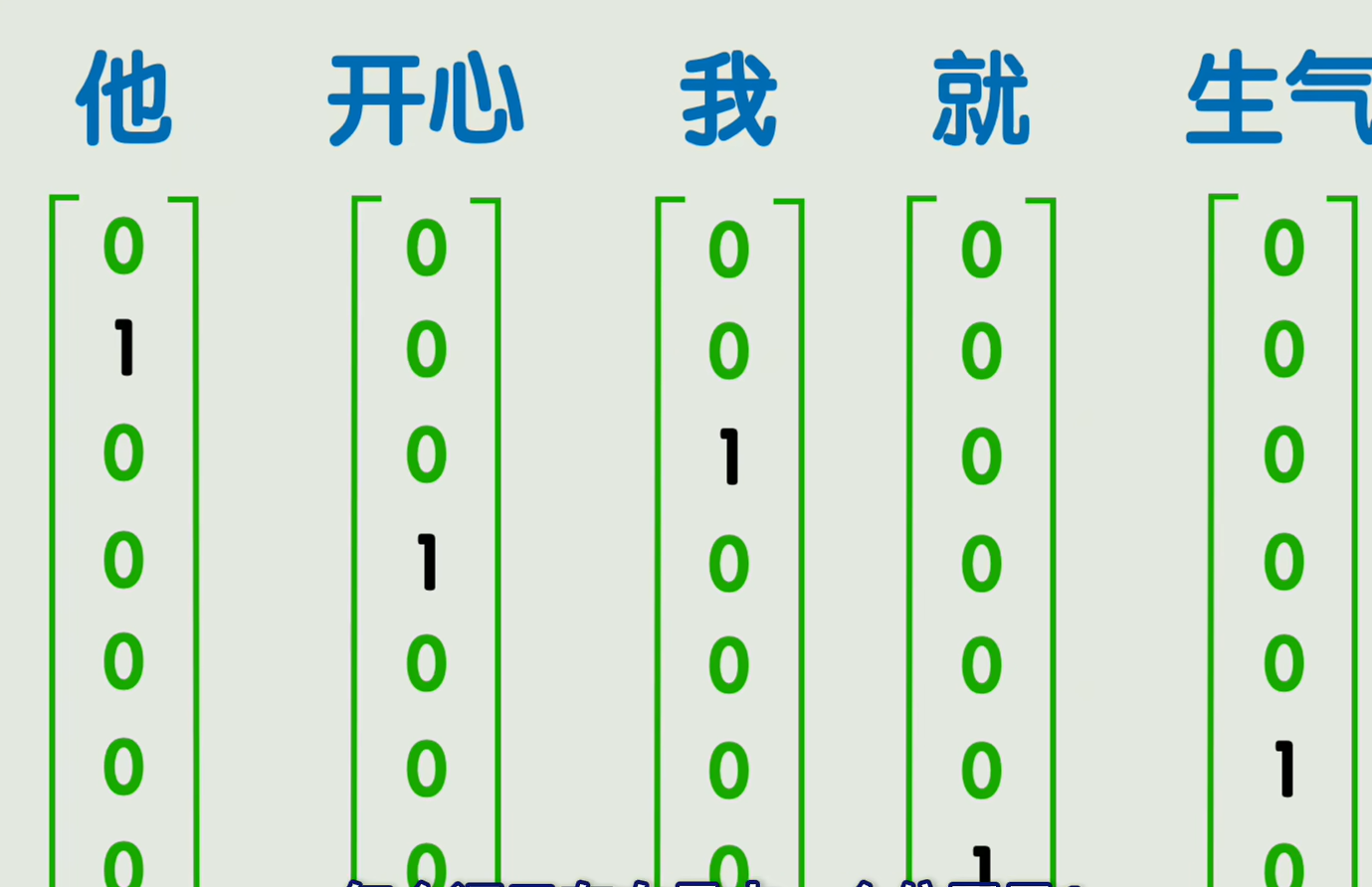

维度太高太低都不太好,但是通过词嵌入的方式所得到的词向量,维度不高也不低,每个位置处,依然可以理解为某一特征

用点积和余弦相似度来表示两个向量之间的相关性,从而表示词语之间的相关性,

通过数学计算也可以得到很有趣的发现
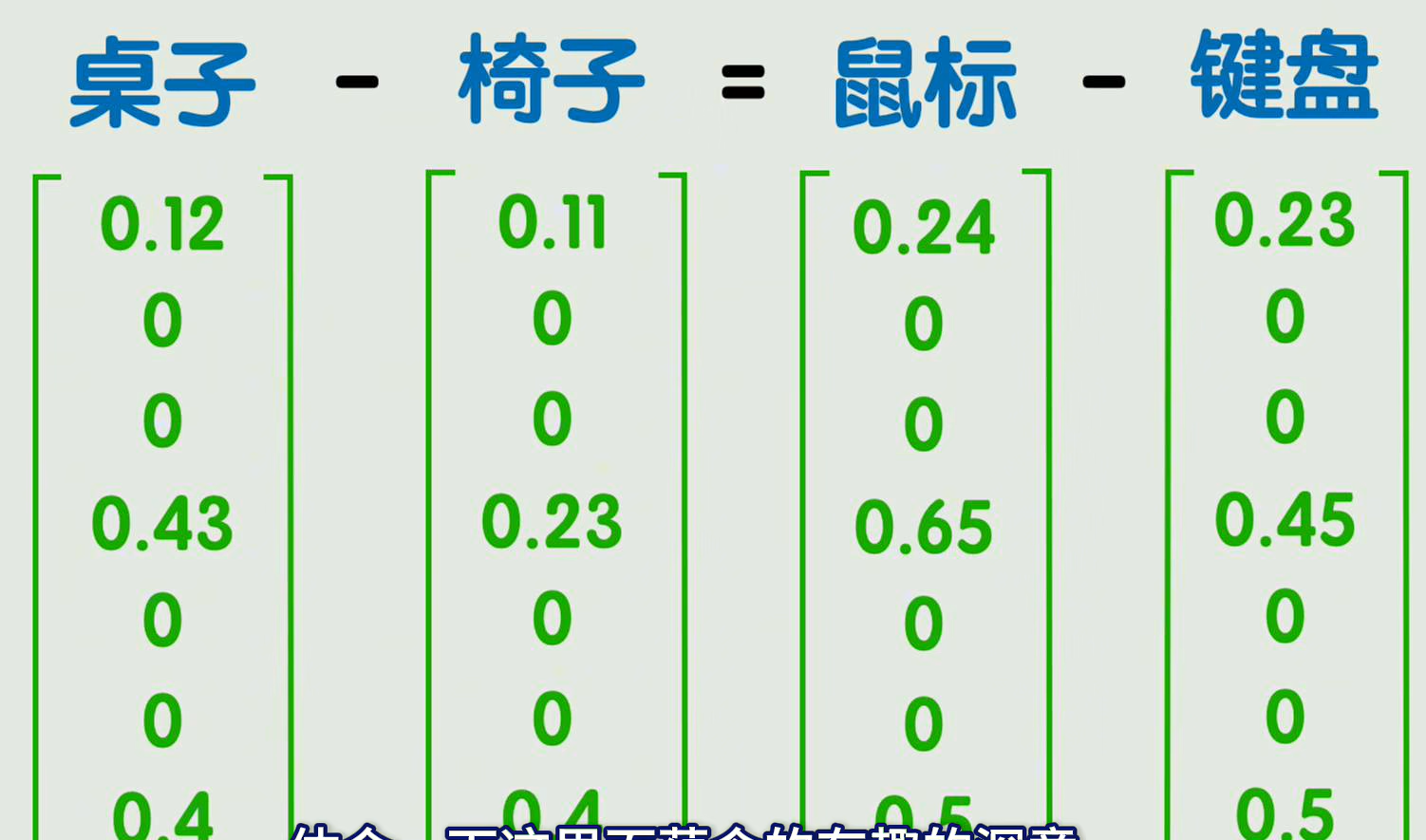
把所有词向量组成一个矩阵就是嵌入矩阵;每一列就表示一个词向量,这是通过深度学习训练出来的;这些词向量的维度很高,他们构成的空间的维度也很高;这个空间叫做潜空间


我们最初的需求是输入一句话,出入每个单词的褒贬性

把每个词通过词嵌入把他们变成300维的词向量 ,那么输入层要有1500个神经元;
2个问题:
1.输入层太大了,而且会随着一句话中词语数量多少而变化,是变长的,不确定的
2.无法体现词语的先后顺序仅仅是把他们生硬的铺开。
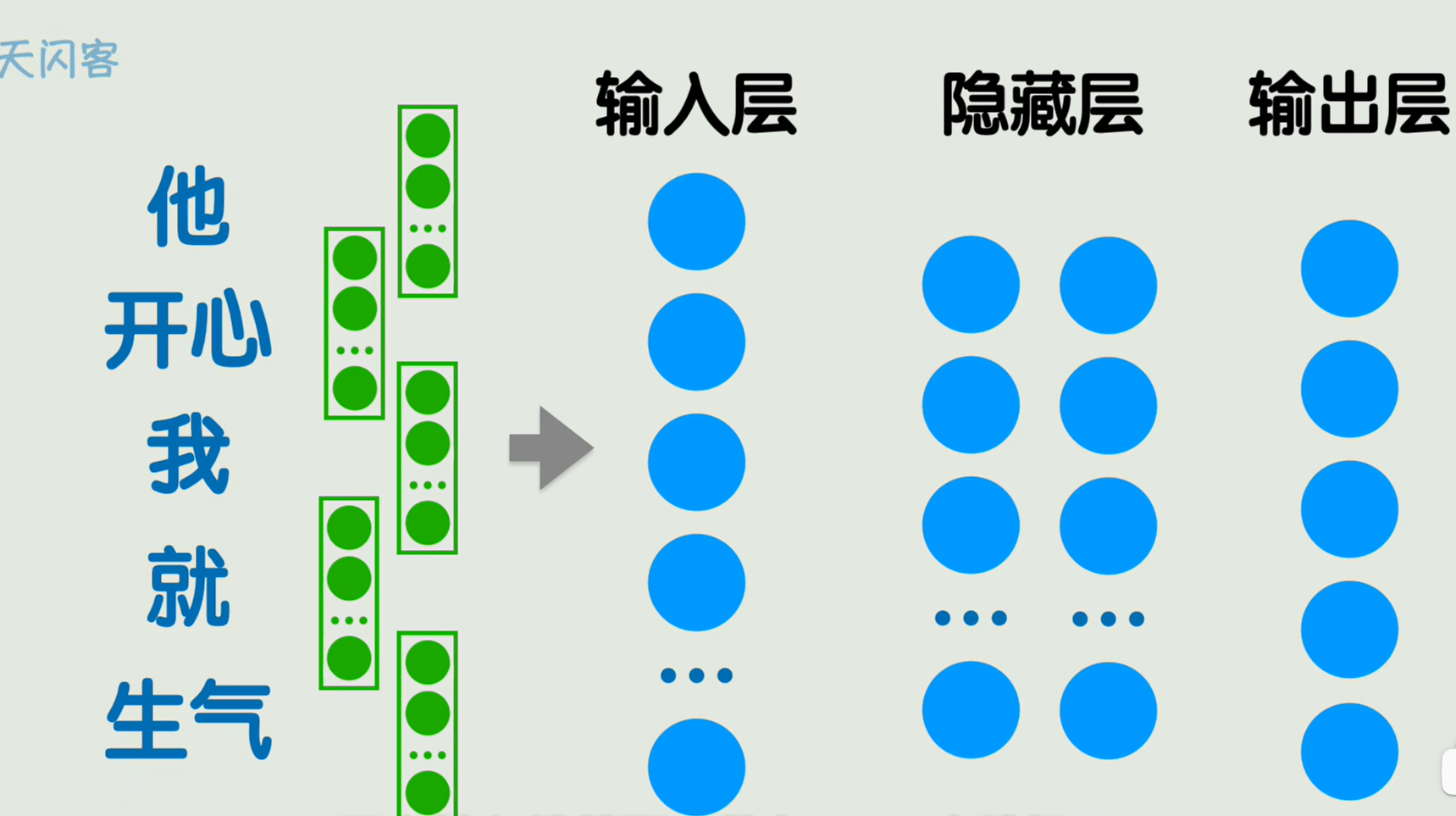
这就是RNN
缺点:
1.无法捕捉长期依赖
2.无法并行计算 ,它必须按顺序处理,每个时间部依赖上一个时间部的隐藏状态的计算结果
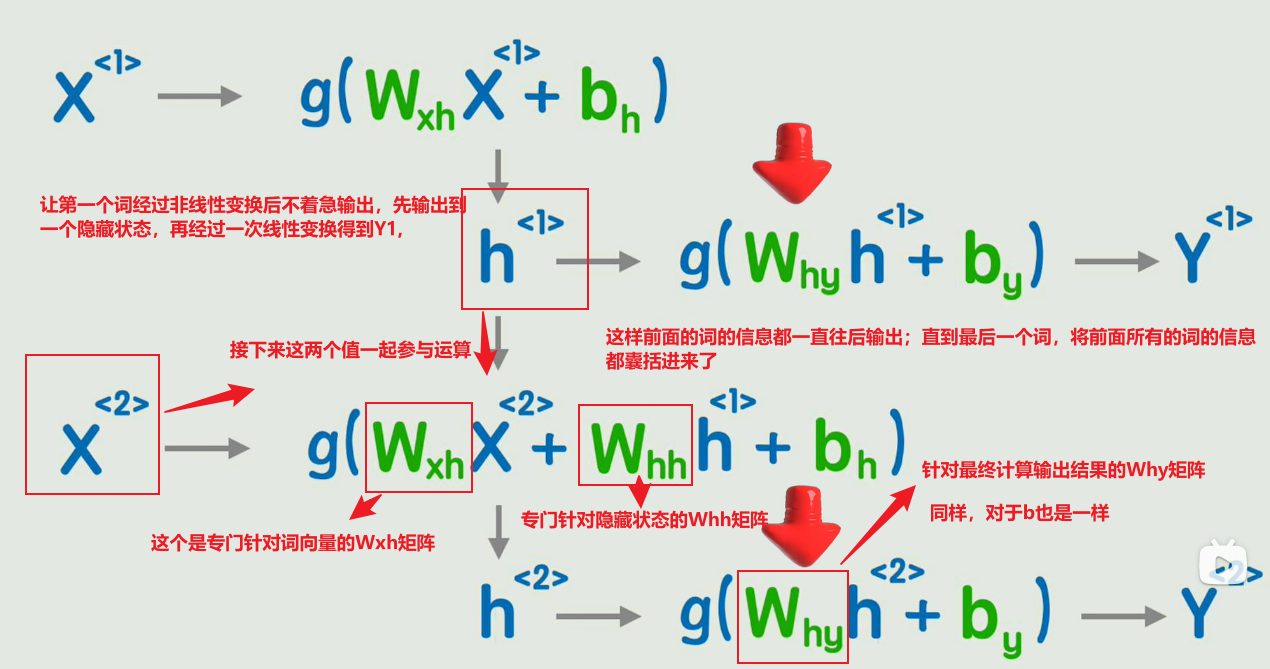
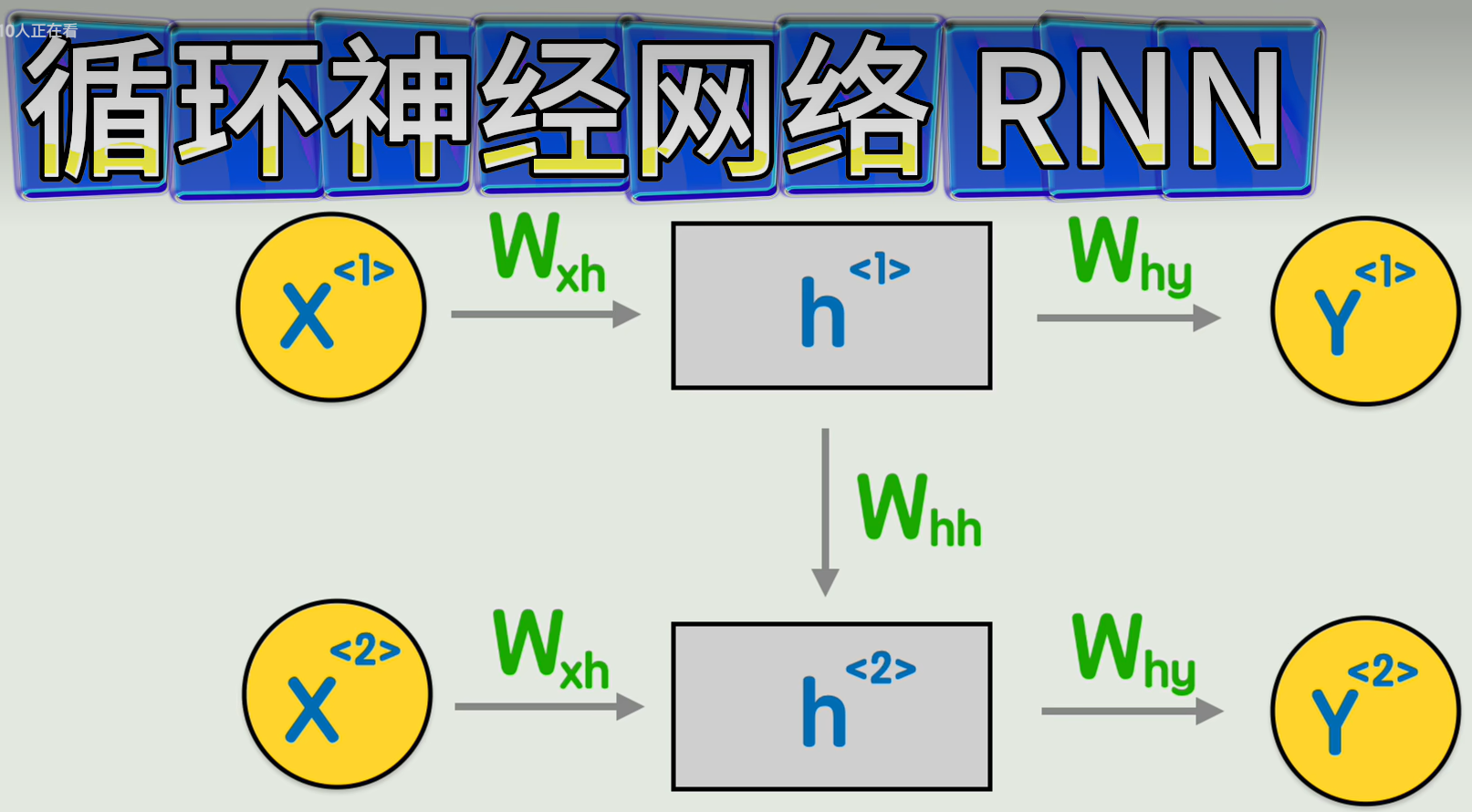
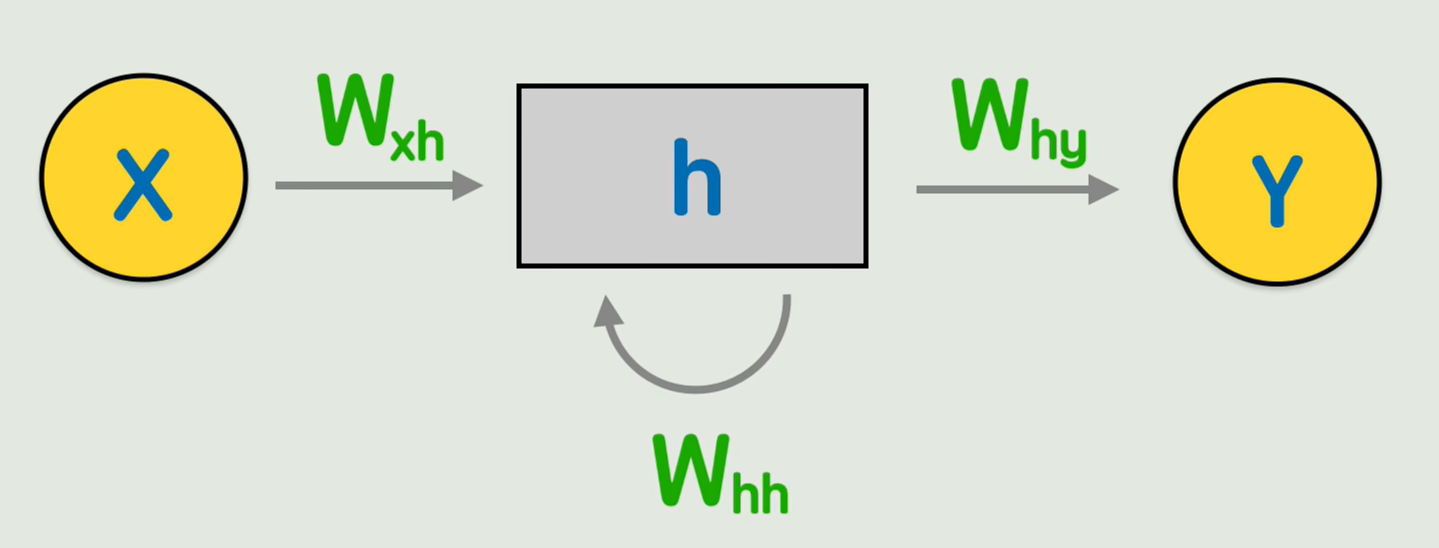
不同的画法
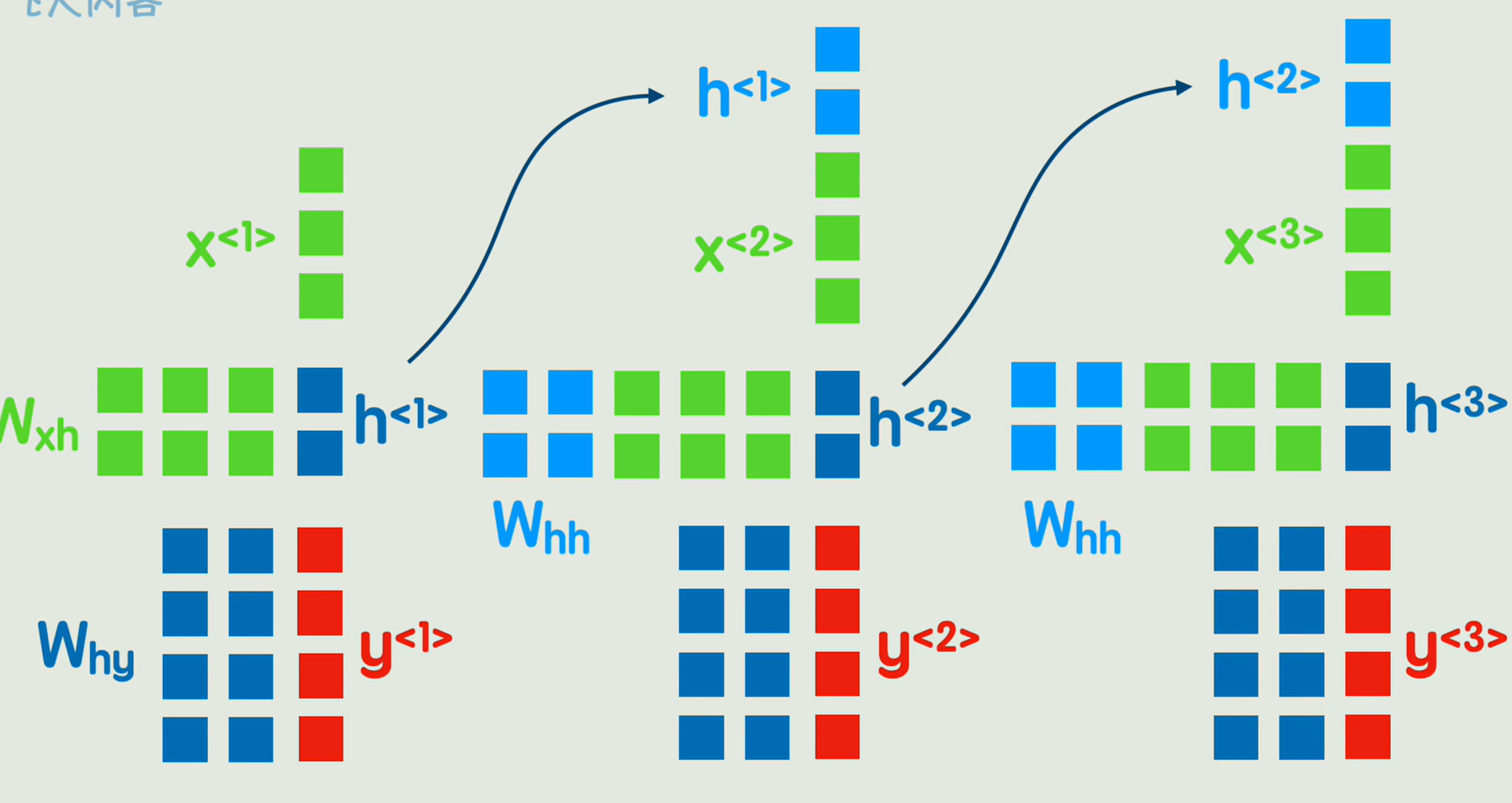
详细解释的过程
公式,和经典的神经网络相比,多了一个前一时刻的隐藏状态
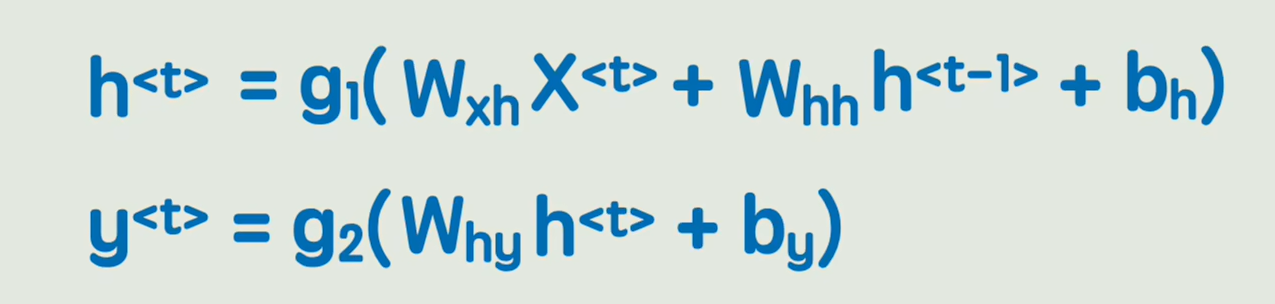
针对RNN的缺点,人类的改善方法:使用GRU和LSTM改进了传统的RNN ,只能缓解不能根治 ,那有什么方法,可以彻底抛弃顺序,而将一眼把全部信息尽收眼底,那就是transformer

6.transformer简单而又强大
用神经网络做一个翻译的任务,
先用词嵌入的方式,把每个词转换成一个词向量;
如果把每个词直接丢入到全连接神经网络中,那每个词都没有上下文信息,且长度只能一一对应,
如果用RNN,又面临串行计算、长期依赖问题
那么就做一个全新的方案
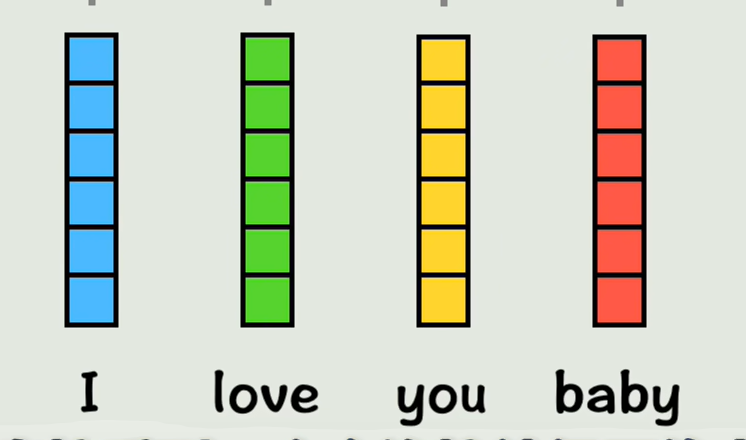
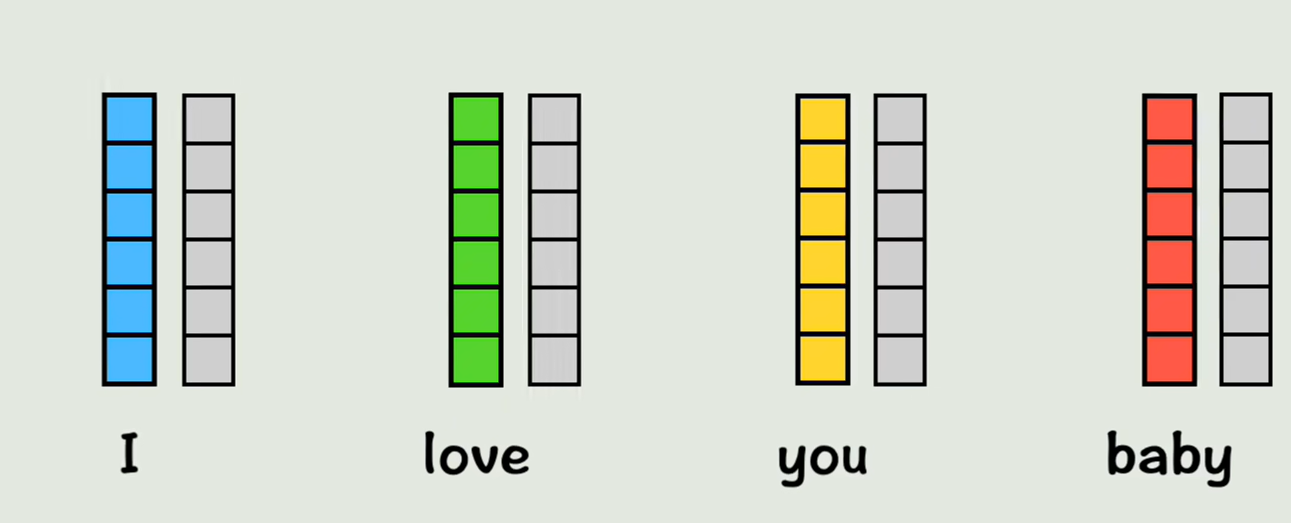
首先给每个词一个位置编码,表示这个词出现在整个句子中的位置,把位置编码加到原来的词向量中,现在这个词就有了位置信息,但此时每个词还没有其他词的上下文信息 ,也就是注意不到其他词的存在
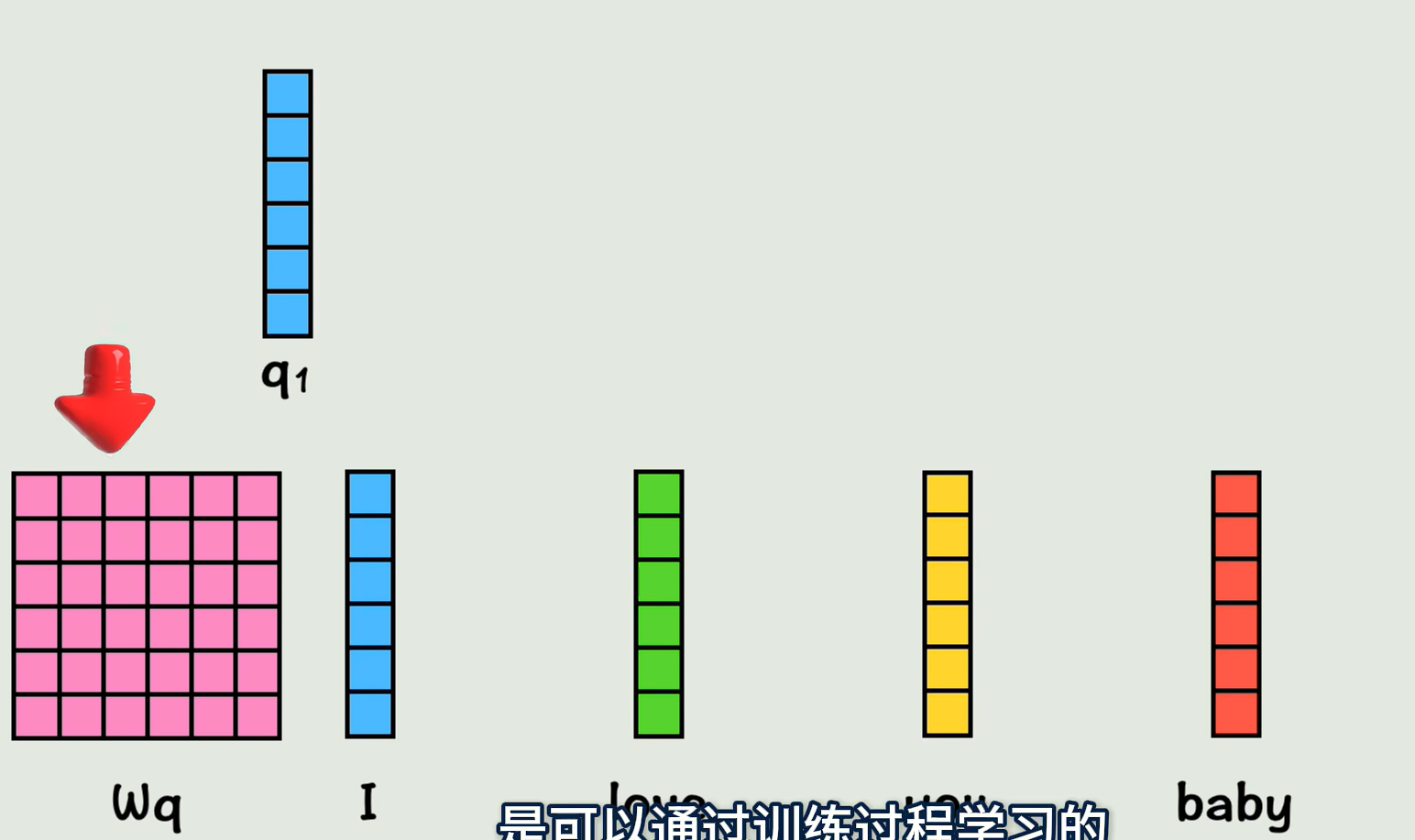
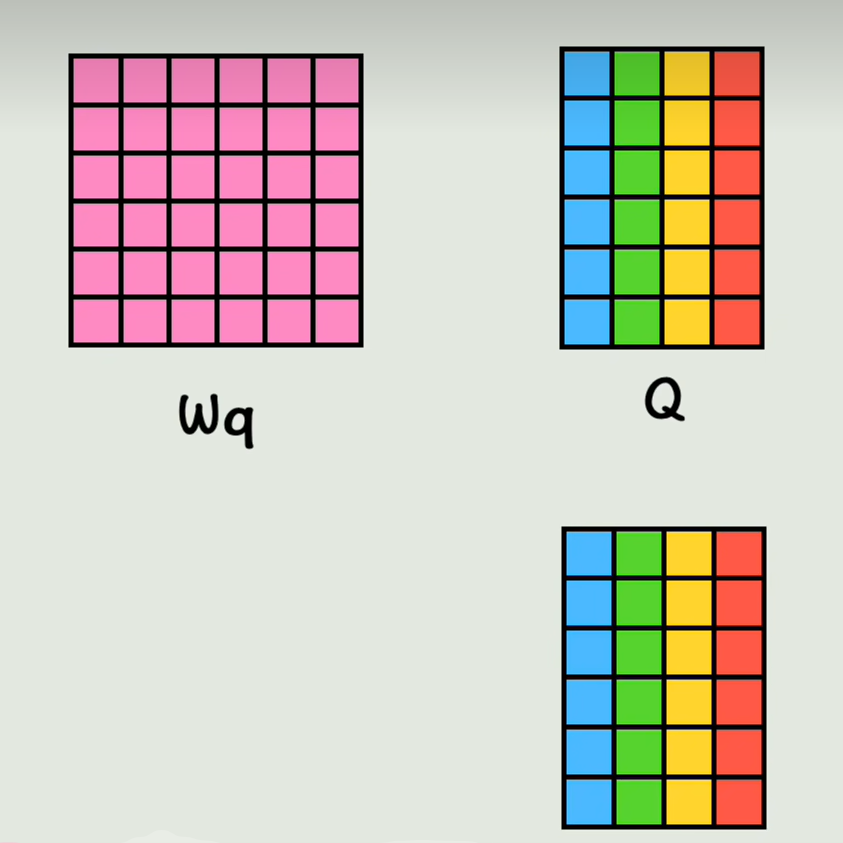
那么我们用一个Wq矩阵和第一个词向量相乘,得到维度不变的q1向量,PS:Wq矩阵是可以通过训练过程学习的一组权重值,再用Wk矩阵和第一个词向量相乘得到K1;Wv矩阵和第一个词向量相乘得到V1;其他词向量同理,分别得到自己对应的QKV,
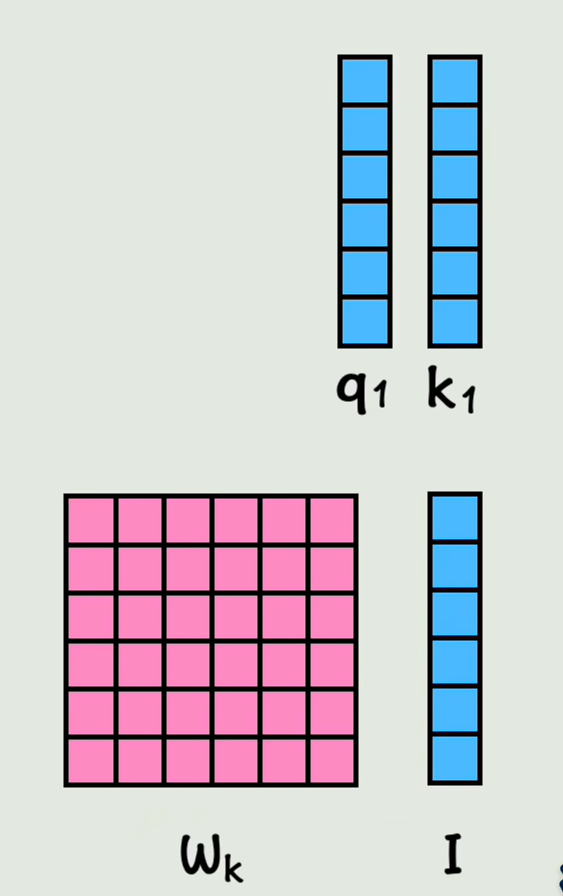
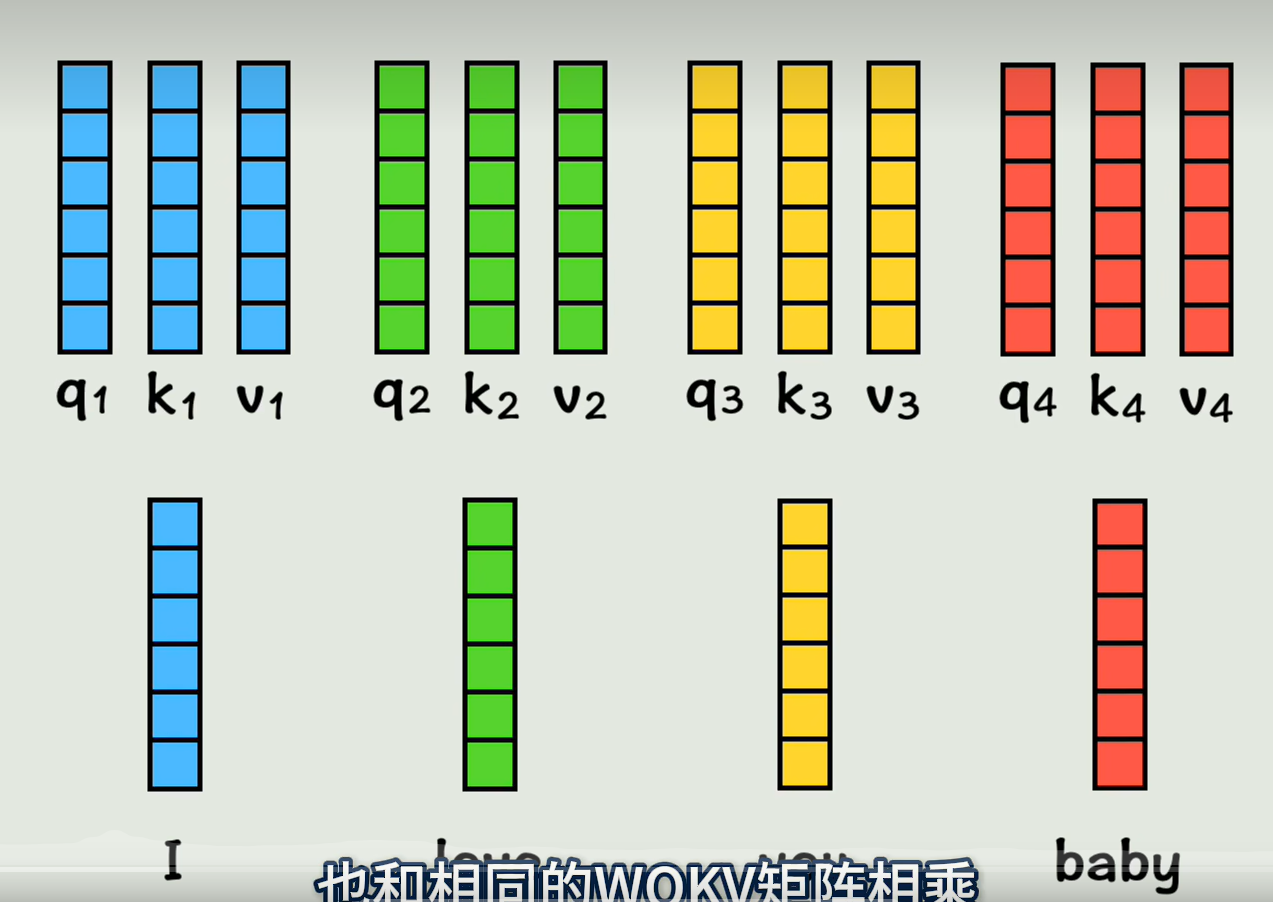
实际上是通过拼接而成的大矩阵做乘法,而不是一步步计算的,得到的直接就是包含所有词向量的qk,v矩阵
接着,让q1*k2,表示在第一个词的视角里,第一个词和第二个词的相似度是多少,q1和k1做点积,表示和自己的相似度
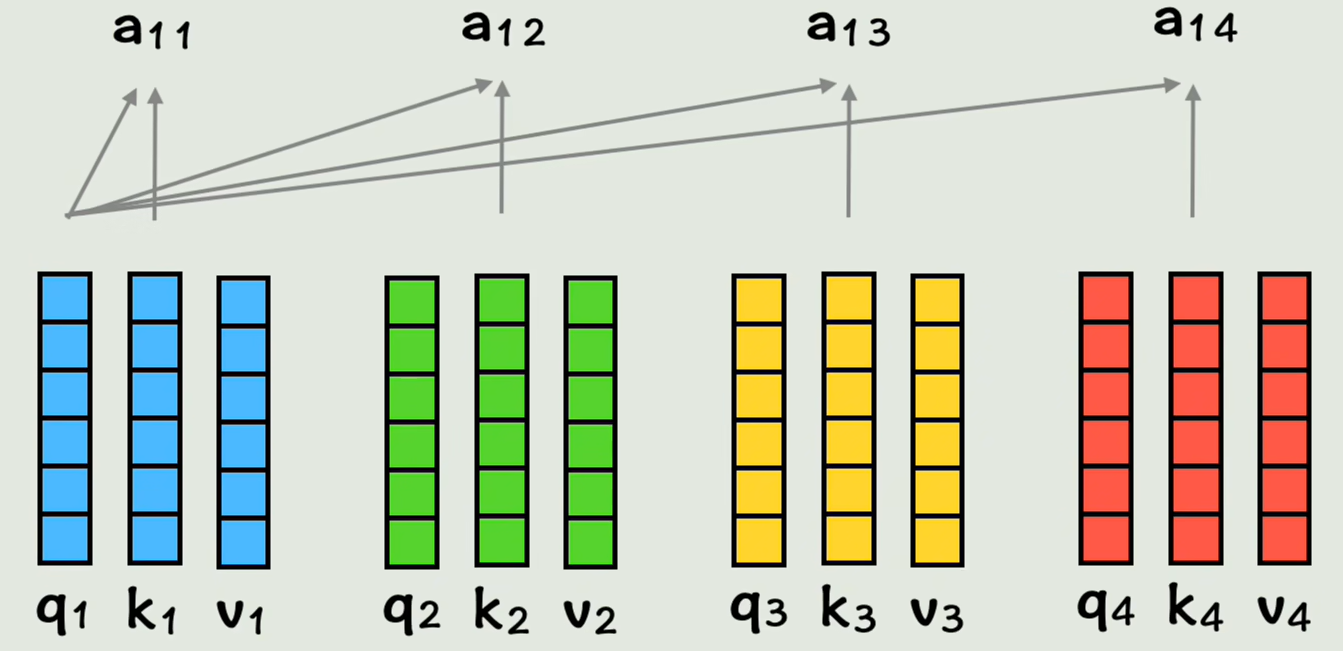
拿到这些相似度的系数后,分别和v向量相乘,再相加得到a1;此时a1表示在第一个词的视角下,按照和它相似度大小,按权重把每个词的词向量都加到一块,这就把全部上下文的信息都包含在第一个词当中了
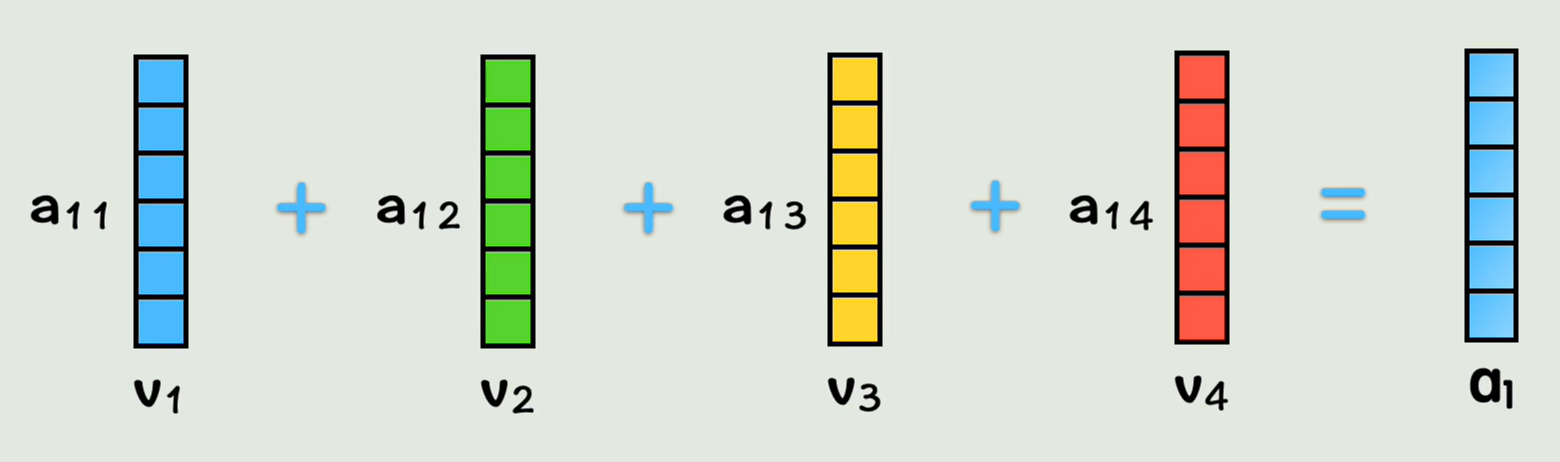
同理其他几个词也这样算,此时每个词都把其他词的词向量,按照和自己的相似度权重,加到了自己的词向量中,
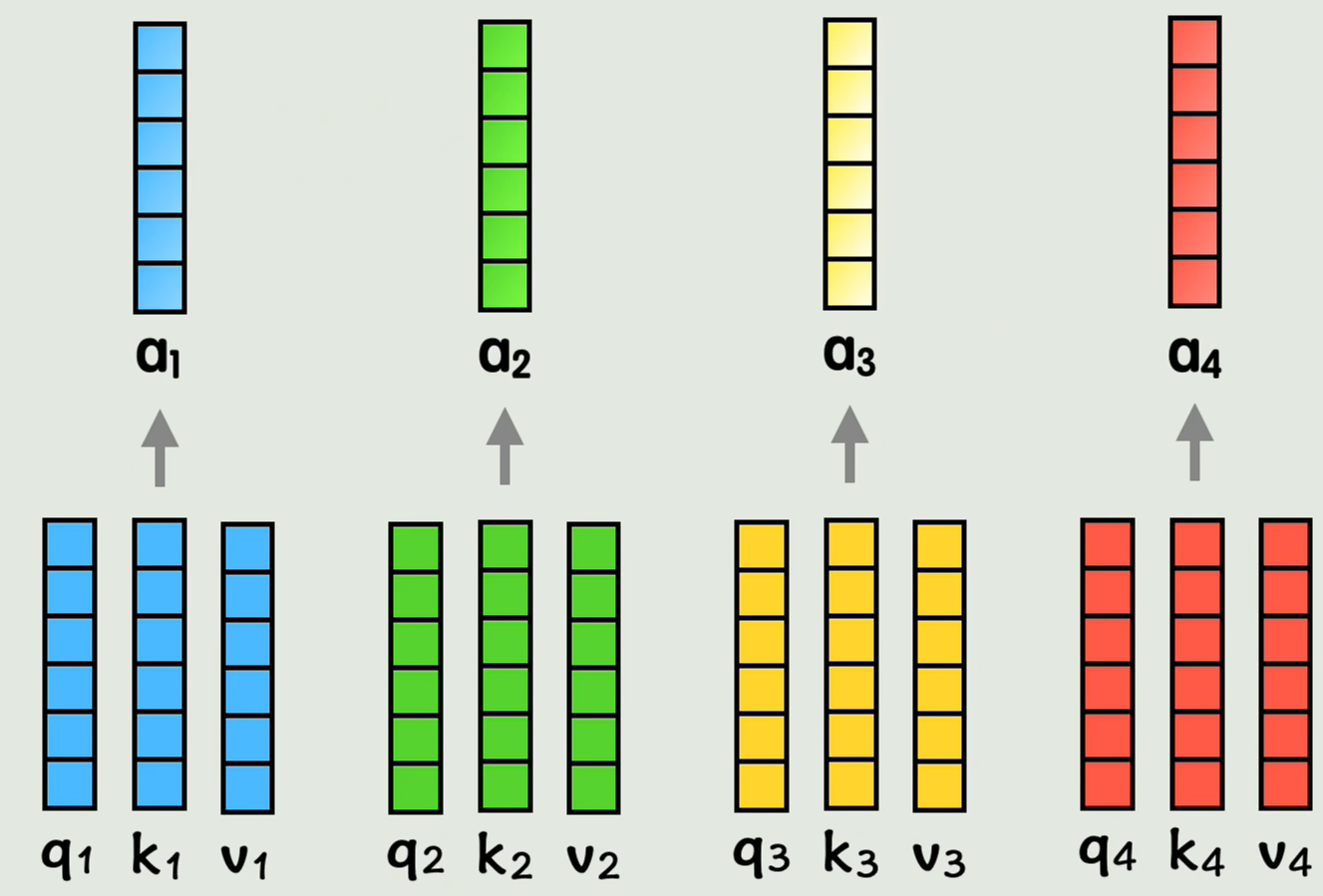
从全局来看,这些新的词向量中都包含了位置信息,和其他词上下文信息的一组新的词向量,这就是注意力机制attention做的事情
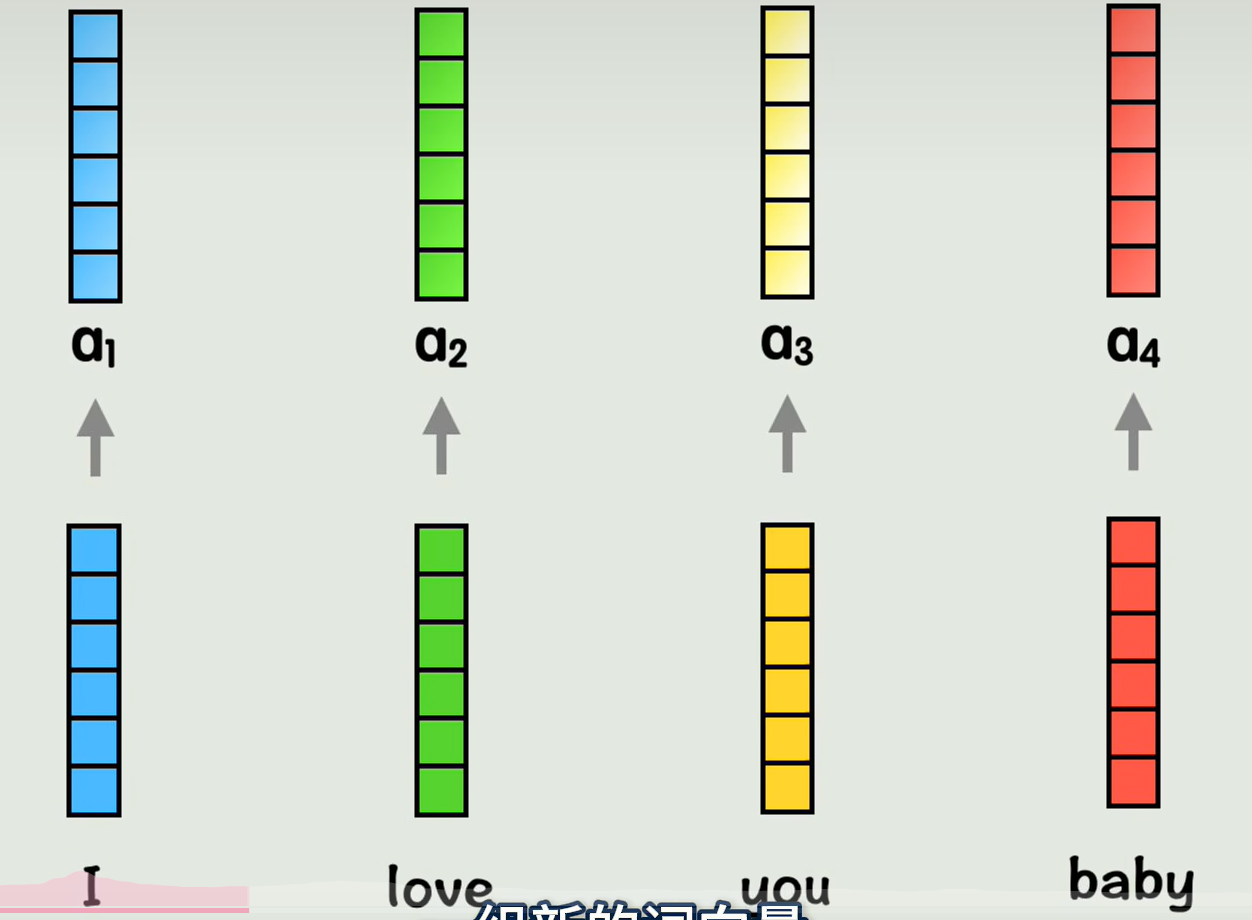
再进一步优化,有时一个词和另一个词的关系可能从不同视角看是不同的,对于注意力机制来说,如果只通过一种方式计算一次相关性,灵活性会大大降低
因此改进:之前是每个词计算一组QKV,现在我们在QKV的基础上,再经过两个权重矩阵变成两组QKV,给每个词两个学习机会,学习到不同的要计算相似度的QKV,来增加语言的灵活性
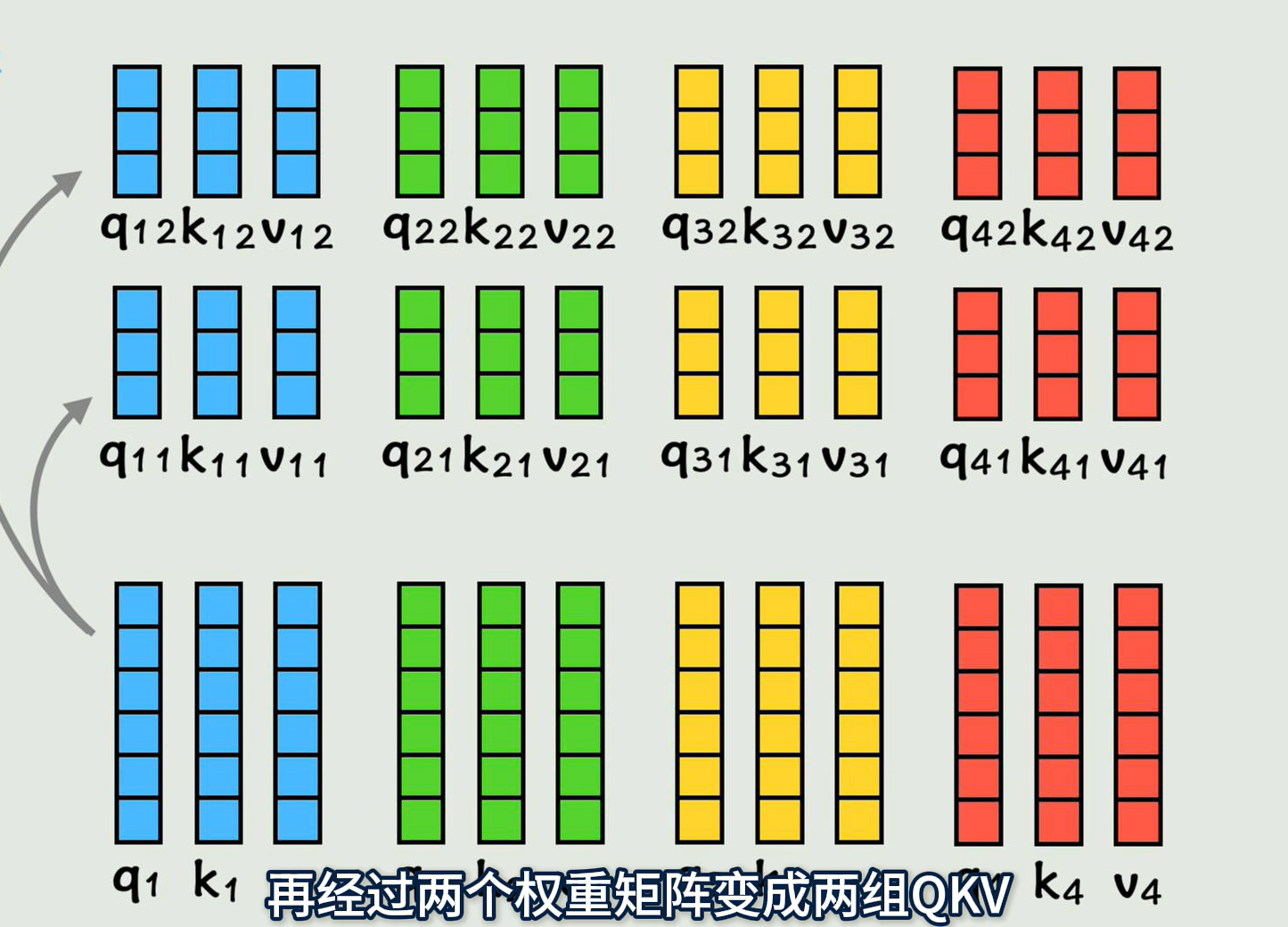
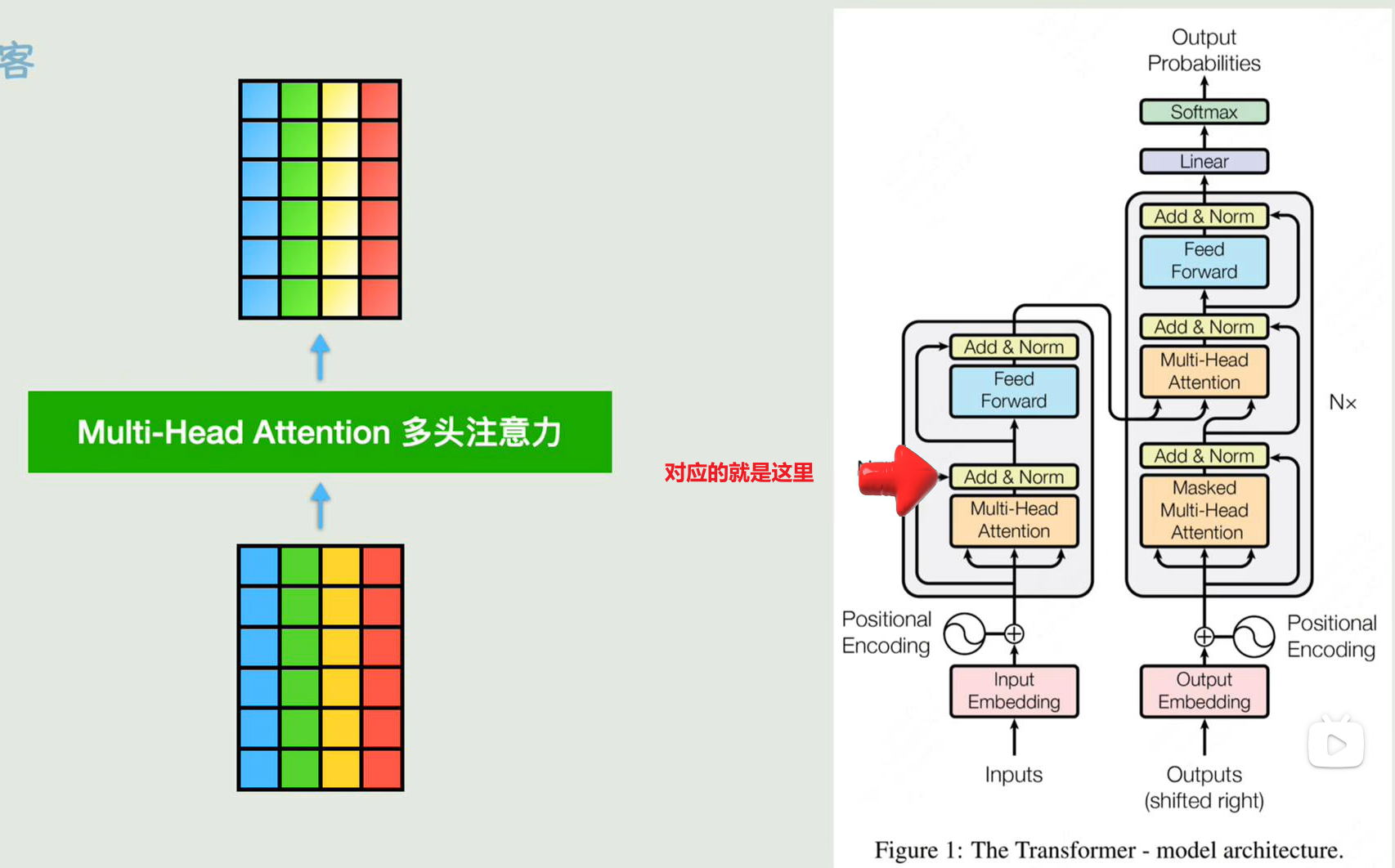
下面深入到多头注意力机制的细节部分
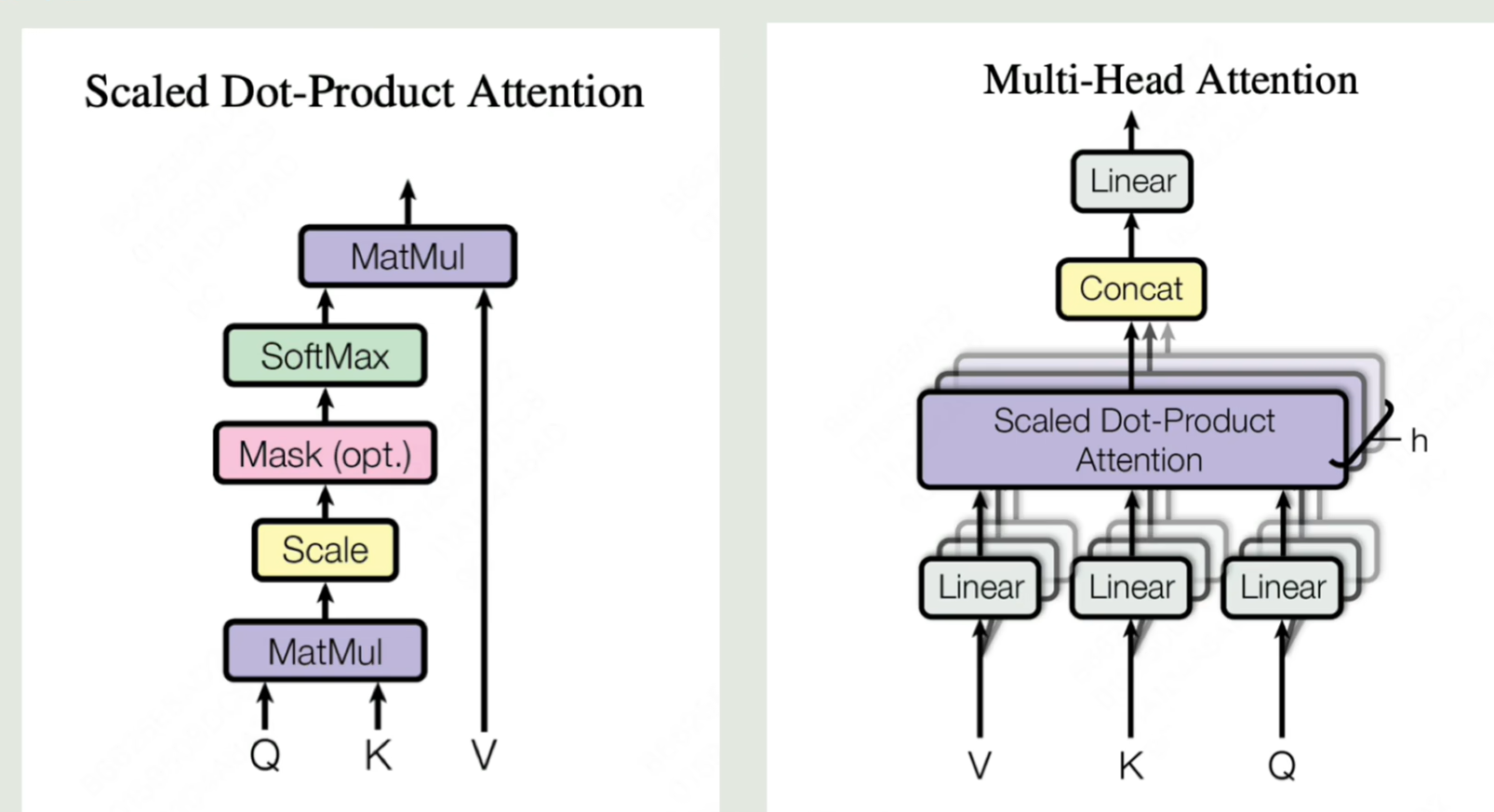
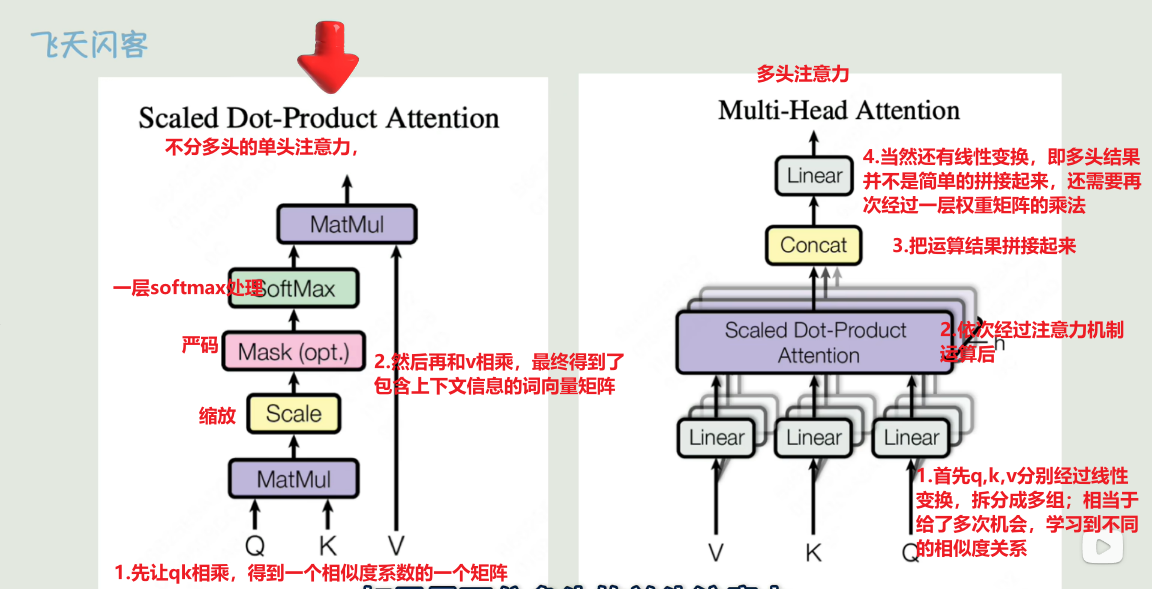
再看一下核心公式就可以理解了


再看这张全局的图
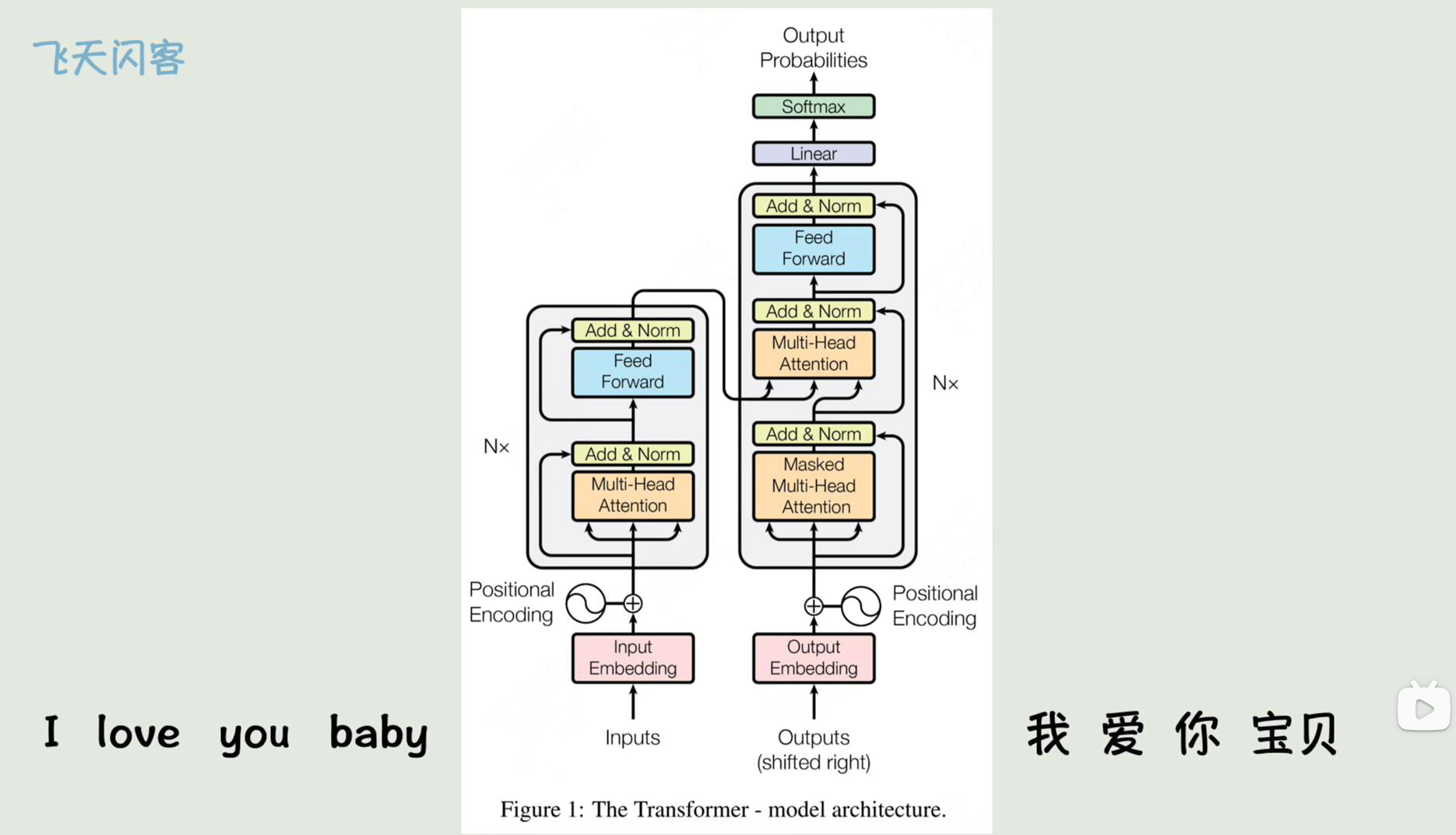
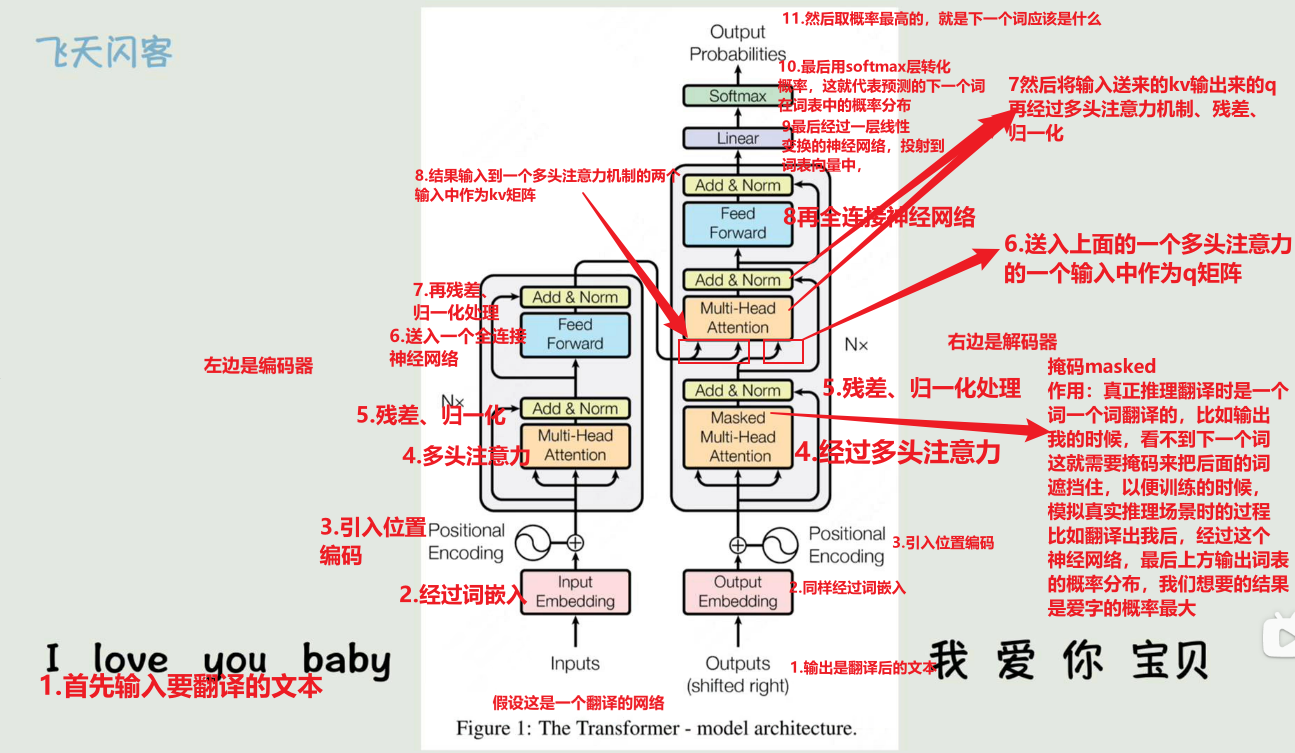
如果训练时有偏差,那就计算损失函数,再反向传播调整transformer结构中的各种权重矩阵,直到学习好为止,
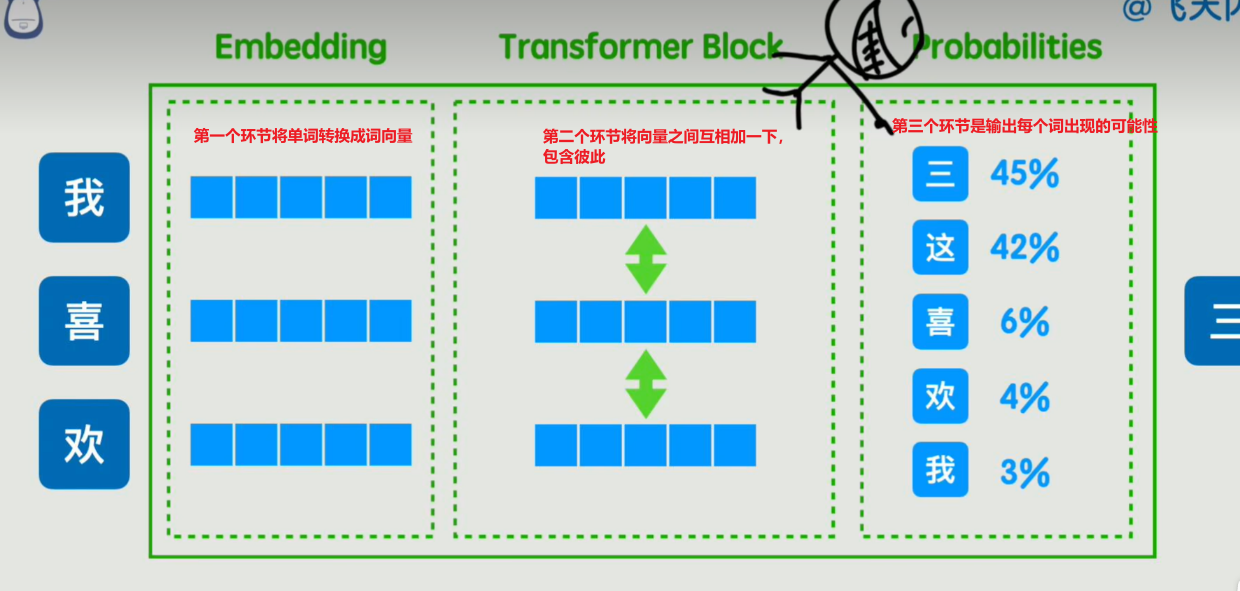
7.补充
嵌入矩阵的创建

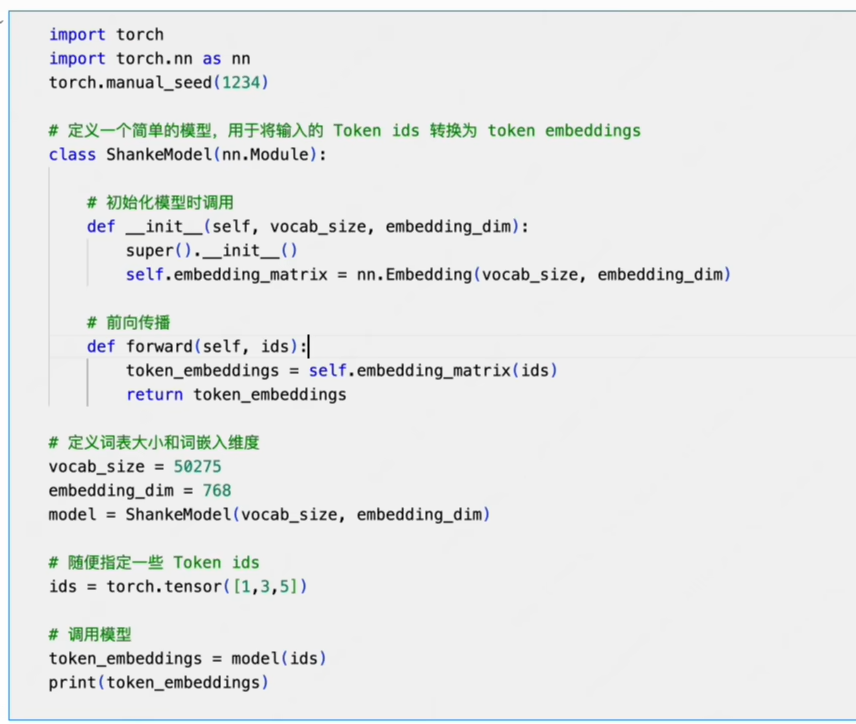
最终打印了3个词嵌入

