文章目录
- [1. 核心原理与运行机制](#1. 核心原理与运行机制)
-
- [1.1 长期记忆核心定义](#1.1 长期记忆核心定义)
- [1.2 长短记忆双向交互闭环](#1.2 长短记忆双向交互闭环)
- [1.3 记忆全生命周期闭环](#1.3 记忆全生命周期闭环)
-
- [1.3.1 记忆提取](#1.3.1 记忆提取)
- [1.3.2 记忆存储](#1.3.2 记忆存储)
- [1.3.3 记忆检索](#1.3.3 记忆检索)
- [1.3.4 记忆动态更新](#1.3.4 记忆动态更新)
- [1.3.5 冷热自动归档机制](#1.3.5 冷热自动归档机制)
- [2. 主流记忆实现范式与选型](#2. 主流记忆实现范式与选型)
-
- [2.1 各范式核心能力对比](#2.1 各范式核心能力对比)
- [2.2 各范式详细解析](#2.2 各范式详细解析)
-
- [2.2.1 向量检索范式](#2.2.1 向量检索范式)
- [2.2.2 知识图谱记忆范式](#2.2.2 知识图谱记忆范式)
- [2.2.3 分层记忆范式](#2.2.3 分层记忆范式)
- [2.2.4 专用记忆服务范式](#2.2.4 专用记忆服务范式)
- [2.2.5 原生长上下文范式](#2.2.5 原生长上下文范式)
- [2.2.6 混合融合范式](#2.2.6 混合融合范式)
- [2.3 业务落地应用场景](#2.3 业务落地应用场景)
- [3. 记忆存储设计](#3. 记忆存储设计)
-
- [3.1 核心设计原则](#3.1 核心设计原则)
- [3.2 三层存储架构](#3.2 三层存储架构)
-
- [3.2.1 基础元数据层](#3.2.1 基础元数据层)
- [3.2.2 业务属性层](#3.2.2 业务属性层)
- [3.2.3 辅助扩展层(可选)](#3.2.3 辅助扩展层(可选))
- [3.2.4 标准 JSON 存储模板](#3.2.4 标准 JSON 存储模板)
- [3.3 主流存储介质对比](#3.3 主流存储介质对比)
- [4. 主流开源/商用记忆框架与服务](#4. 主流开源/商用记忆框架与服务)
-
- [4.1 Mem0](#4.1 Mem0)
- [4.2 OpenViking](#4.2 OpenViking)
- [4.3 Supermemory](#4.3 Supermemory)
- [4.4 国内主流托管记忆服务](#4.4 国内主流托管记忆服务)
1. 核心原理与运行机制
1.1 长期记忆核心定义
Agent 长期记忆核心是结构化、可持久化、可迭代更新 的记忆体系,区别于临时聊天记录,以结构化事实、用户偏好、上下文摘要为核心,可跨会话留存,持续影响智能体的对话逻辑与应答风格,实现 AI 人格与服务的连贯性。
其落地核心依托三层关键设计:
-
Store存储层,支持JSON结构化存储,兼容文件系统、数据库、向量库、知识图谱等多类介质; -
Agent执行前,加载用户画像注入系统消息,初始化个性化应答基准; -
Agent执行后,通过LLM抽取对话核心信息,更新、沉淀用户偏好与事实记忆。
1.2 长短记忆双向交互闭环
AI 智能体的记忆体系由**短期记忆(当前会话)与 长期记忆(跨会话持久)**构成双向循环关系,是 AI 实现持续学习、个性化应答的核心。
核心流转逻辑:短期记忆负责实时交互,长期记忆负责沉淀复用,二者持续循环迭代。
-
记忆写入 (短期→长期
Record):单轮/单会话交互结束后,LLM自动过滤冗余闲聊、重复话术,抽取高价值的用户偏好、事实结论、行为习惯,结构化后写入长期记忆,实现信息沉淀,避免会话结束后数据丢失。 -
记忆召回 (长期→短期
Retrieve):用户发起新查询时,系统基于语义检索匹配相关历史长期记忆,注入当前短期上下文,让模型关联过往信息,实现连贯、个性化推理。
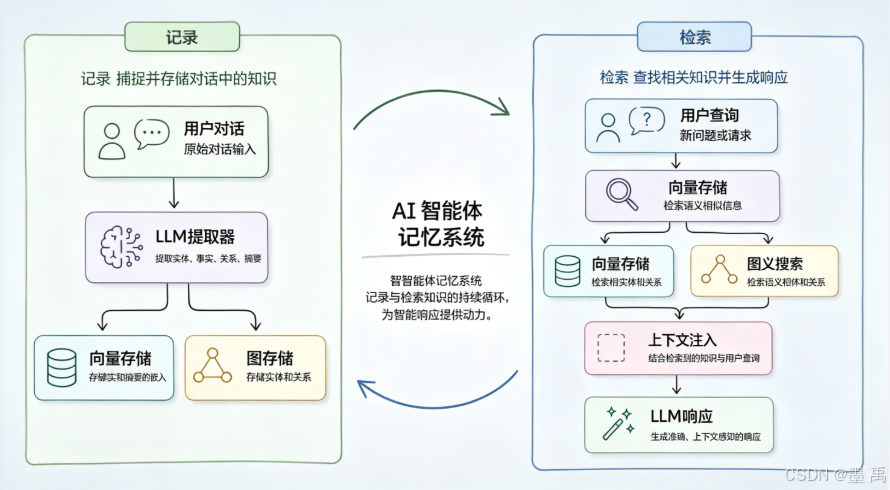
简单总结:
Record负责把当下变成历史,Retrieve负责让历史服务当下。
双向交互核心能力对比:
| 环节 | 流转方向 | 核心作用 | 依赖能力 |
|---|---|---|---|
Record 记忆写入 |
短期 → 长期 | 提炼有效信息,完成记忆积累,沉淀用户专属特征 | LLM 信息抽取、内容结构化、去重降噪 |
Retrieve 记忆召回 |
长期 → 短期 | 补充历史上下文,消除会话割裂,实现个性化应答 | 语义检索、相似度匹配、上下文智能拼接 |
1.3 记忆全生命周期闭环
长期记忆具备提取→存储→检索→更新 完整生命周期,通过标准化 CRUD 机制与冷热分层策略,保障记忆数据准确、低冗余、低成本、高时效。
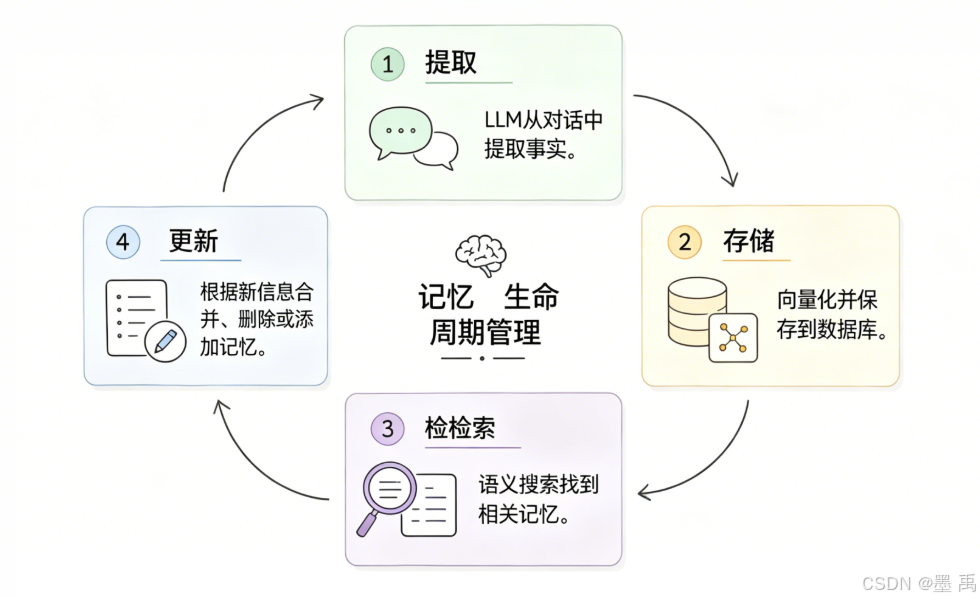
1.3.1 记忆提取
从原始对话中提纯有效知识,完成非结构化文本到结构化记忆的转换:
-
LLM结构化抽取 :解析多轮对话,输出标准JSON格式记忆,统一数据规范; -
语义前置去重 :通过
Embedding生成向量,匹配库内相似记忆,规避重复存储; -
类目限定匹配:仅在同业务类目下检索,杜绝跨领域误匹配。
1.3.2 记忆存储
承接提取后的结构化数据,存储核心包含记忆内容、向量、标签、时间、热度等元数据,并基于访问频率+时间衰减做冷热分层存储,区分活跃热记忆与低频冷记忆。
1.3.3 记忆检索
用户发起查询时,限定记忆分类+语义相似度匹配,优先检索主库热记忆,冷归档记忆按需调取,大幅降低 Token 开销与检索延迟。
1.3.4 记忆动态更新
新信息接入后,自动维护存量记忆,四种迭代策略保障数据新鲜度:
-
MERGE合并:融合新旧信息,更新原有记忆,保证内容连贯; -
DELETE删除:清理过时、冲突、无效记忆,减少数据冗余; -
CREATE新建:无匹配存量记忆时,新增独立记忆条目; -
SKIP跳过:识别为重复、无价值信息,直接舍弃不入库。
1.3.5 冷热自动归档机制
通过热度评分(访问频率+时间衰减)动态标记记忆状态,高频热记忆留存主库保障检索速度,长期低访问冷记忆自动归档,精简主库数据,降低长期运维成本。
2. 主流记忆实现范式与选型
当前 Agent 长期记忆共有六大主流实现范式,各有适配场景,可单独使用或混合组合,适配从轻量化应用到大型复杂企业智能体的全场景需求。
2.1 各范式核心能力对比
| 实现范式 | 核心能力 | 复杂度 | 成本 | 企业推荐度 |
|---|---|---|---|---|
| 向量检索 | 语义相似度召回,适配海量非结构化数据 | 低 | 低 | ⭐⭐⭐⭐⭐(基础必选) |
| 知识图谱 | 实体关系建模,支持逻辑推理、溯源、复杂关联分析 | 高 | 高 | ⭐⭐⭐⭐(复杂业务/高合规场景) |
| 分层记忆 | 按生命周期分层管理,兼顾交互与长期留存 | 中 | 中 | ⭐⭐⭐⭐⭐(通用首选) |
| 专用记忆服务 | 开箱即用,企业级合规、多租户、标准化API |
低 | 中 | ⭐⭐⭐⭐(快速落地) |
| 原生长上下文 | 依托模型超大窗口,无额外存储组件 | 极低 | 极高 | ⭐⭐(轻量化短期场景) |
| 混合融合 | 多范式互补,覆盖语义、推理、分层全能力 | 极高 | 高 | ⭐⭐⭐⭐⭐(大型复杂Agent) |
2.2 各范式详细解析
2.2.1 向量检索范式
核心原理:将文本、对话、用户信息转为向量存入向量数据库,通过语义相似度检索召回相关历史内容,拼接至 Prompt 完成记忆复用。
优缺点:实现简单、检索速度快、生态成熟;但无逻辑推理能力,无法识别实体关联与时序关系。
适用场景 :通用客服、办公助手、轻量化 RAG+Agent 应用。
代表组件 :Milvus、FAISS、Pinecone、LangChain 原生向量记忆
2.2.2 知识图谱记忆范式
核心原理:将记忆拆解为实体+关系+属性,以图结构存储数据,支持关系查询、路径推理、事件溯源。
优缺点:可解释性强、支持复杂业务推理;但构建成本高、检索速度慢、维护难度大。
适用场景 :金融、医疗、政务、多实体复杂交互的企业级 Agent。
代表组件 :Zep、Graphiti、Neo4j、智谱 AgeMem
2.2.3 分层记忆范式
当前落地主流架构,模拟人类记忆机制,按生命周期与访问频率分层:
-
工作记忆(短期):当前会话上下文,内存临时存储;
-
情景记忆(中期):近期会话、任务记录,轻量化摘要存储;
-
长期记忆(永久):用户偏好、核心事实、历史行为,向量/图谱持久化存储。
配套记忆压缩、自动摘要、遗忘打分机制,兼顾交互体验与资源开销。
适用场景 :全品类企业 Agent、长任务助手、多轮持续交互智能体。
代表组件 :Letta(MemGPT)、Mem0、LangChain 分层记忆框架
2.2.4 专用记忆服务范式
将记忆能力封装为独立微服务,脱离向量库/图数据库的单一依赖,提供标准化记忆 CRUD、冲突消解、多租户、合规审计能力,底层存储对业务层透明。
优缺点:开箱即用、运维简单、企业能力完备;定制化深度受限。
适用场景 :中大型企业、多 Agent 集群、标准化业务系统快速落地。
代表服务 :Mem0、Zep 独立服务、腾讯云 Agent Memory
2.2.5 原生长上下文范式
依托大模型超大上下文窗口,直接拼接全量历史对话与长期记录,通过滑动窗口、摘要截断优化内容,无需外部存储组件。
优缺点 :架构极简、语义连贯;但 Token 成本极高、无法支撑海量长期记忆,受模型窗口限制。
适用场景:轻量内部工具、短周期任务、小体量历史数据场景。
代表模型 :GPT-4o、Claude 长上下文系列
2.2.6 混合融合范式
复杂企业 Agent 标配方案,整合多范式优势,取长补短,覆盖全场景能力。常见组合:分层记忆+向量检索(通用最优)、向量+知识图谱(语义+推理双能力)、全范式融合(大型复杂架构)。
优缺点:能力全面、适配复杂业务;架构复杂、开发运维成本高。
适用场景 :大型集团 Agent、多智能体协同、高复杂度业务流程。
2.3 业务落地应用场景
依托长期记忆能力,可实现用户信息沉淀与个性化服务落地,覆盖五大核心业务场景,适配全行业 Agent 落地:
-
智能客服:存储用户设备信息、报修记录、沟通偏好,延续跨会话对话上下文,打造专属服务体验,提升交互温度与问题解决效率。
-
个性化教育:记录学生薄弱知识点、错题类型、答题正确率、学习习惯,按需定向推送错题与复习内容,实现精准动态复习,杜绝无效刷题。
-
医疗健康:留存患者病史、过敏史、诊疗方案、体检数据与用药记录,问诊时联动全周期历史信息,给出综合诊疗建议,同时预警药物冲突风险。
-
情感陪伴:记录用户情绪变化、触发事件、重要纪念日、人际关系与个人喜好忌讳,结合过往经历主动共情互动,提供持续情绪支持。
-
智能推荐:追踪用户长期兴趣、消费倾向、偏好变迁轨迹,搭建动态用户兴趣图谱,实现个性化、持续性商品与内容推荐。
3. 记忆存储设计
3.1 核心设计原则
以结构化、低冗余、可迭代、可追溯为核心,统一全场景记忆存储规范:
-
结构化优先:统一
JSON存储格式,适配提取、检索、更新全流程; -
最小冗余:过滤闲聊、重复、无效内容,仅留存高价值业务信息;
-
分类隔离:按业务域划分记忆类目,杜绝跨类误匹配;
-
可运维追溯:留存时间、热度、版本、来源信息,支持归档与合并;
-
冷热适配:区分冷热数据,适配分层存储策略。
3.2 三层存储架构
整体分为元数据层、业务属性层、辅助扩展层,兼顾通用性与场景定制性:
-
基础元数据层(通用) :存储记忆
ID、分类、向量、创建/更新时间、访问热度、状态、数据来源等运维字段,支撑生命周期调度; -
业务属性层(定制):包含通用用户标识、时间维度、关联对象,同时适配客服、教育、医疗、情感陪伴、智能推荐五大场景专属业务数据;
-
辅助扩展层(可选) :关联记忆
ID、合并日志、过期时间、热度分值,适配复杂迭代与版本管理、记忆溯源、自动过期清理,中大型企业系统推荐配置。
3.2.1 基础元数据层
用于记忆管理、生命周期调度、冷热判定,全局统一字段。
| 字段 | 说明 | 用途 |
|---|---|---|
| memory_id | 记忆唯一ID | 主键、增删改查标识 |
| category | 记忆分类 | 限定检索范围,防止跨类误匹配 |
| content | 结构化记忆主体内容 | 核心业务信息 |
| embedding | 语义向量 | 相似度检索、智能去重 |
| create_time | 创建时间 | 时间衰减、时效判断 |
| update_time | 最后更新时间 | 识别新旧内容、合并依据 |
| access_count | 访问次数 | 热度评分计算 |
| last_access_time | 最后访问时间 | 时间衰减、冷热划分、归档触发 |
| status | 状态 | 正常/已删除/已归档/临时 |
| source | 数据来源 | 对话、表单、外部系统等 |
3.2.2 业务属性层
根据业务领域,拆分通用属性+场景专属属性,是记忆的核心价值内容。
通用业务属性(全场景通用):
- 用户标识:
user_id/ 身份标签 - 时间维度:事件发生时间、有效周期(过期时间)
- 关联对象:关联人、设备、物品、订单等
智能客服景专属存储内容:
- 用户信息:姓名、联系方式、设备型号、所属产品
- 服务记录:历史报修问题、故障现象、处理方案、办结状态
- 交互偏好:沟通语气、咨询习惯、关注问题点
个性化教育:
- 学情数据:薄弱知识点、易错题型、答题正确率
- 学习轨迹:做题记录、复习时间、历史错题集
- 学习偏好:擅长科目、练习习惯、接受节奏
医疗健康:
- 基础档案:病史、过敏史、既往诊断、家族病史
- 诊疗数据:用药记录、治疗方案、体检报告、复查时间
- 风险标签:药物禁忌、症状关联记录
情感陪伴:
- 情绪数据:历史情绪状态、情绪触发事件、情绪变化时间线
- 人物关系:亲友、同事、重要人际关系
- 特殊节点:纪念日、重要日程、个人喜好与忌讳
智能推荐:
- 兴趣标签:长期偏好、兴趣演变轨迹、风格倾向
- 消费行为:历史浏览、购买记录、购买动机、决策倾向
- 偏好趋势:兴趣变化节点、接受的推荐类型
3.2.3 辅助扩展层(可选)
按需添加用于复杂逻辑、版本管理、记忆合并溯源,中大型系统建议配置:
related_memory_ids:关联记忆ID(多条相关记忆联动)merge_record:合并日志(记录新旧内容合并历史)expire_time:记忆过期时间(自动清理时效信息)hot_score:热度分值(冷热分离直接取值)
3.2.4 标准 JSON 存储模板
json
{
"memory_id": "mem_001",
"user_id": "user_123",
"category": "智能客服-报修记录",
"content": {
"device_model": "投影仪A款",
"fault_desc": "画面异常",
"handle_status": "已解决"
},
"embedding": "[向量数组]",
"create_time": "2026-05-20 10:20:00",
"update_time": "2026-05-20 10:25:00",
"access_count": 8,
"last_access_time": "2026-05-28 09:10:00",
"hot_score": 78,
"status": "normal",
"expire_time": "",
"source": "对话交互"
}3.3 主流存储介质对比
主流的长期记忆存储方案:
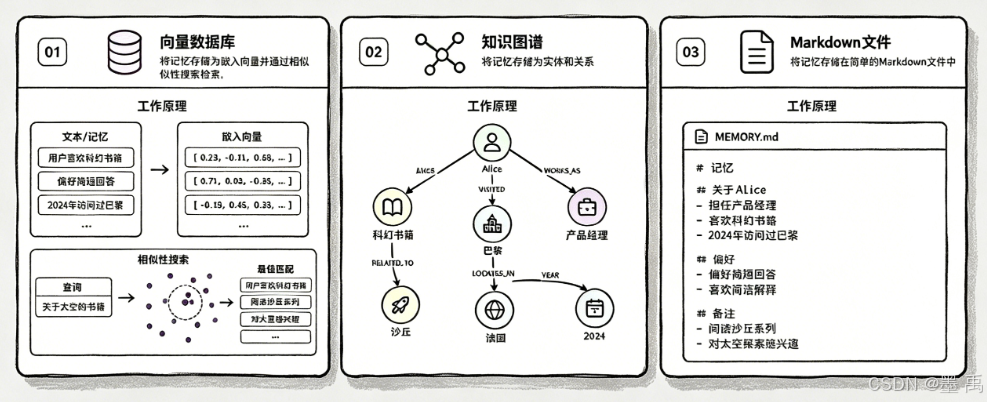
| 存储方案 | 核心优点 | 核心缺点 |
|---|---|---|
| 向量数据库 | 支持语义检索、适配非结构化数据、海量存储、语义解析能力强 | 可解释性弱、存在匹配幻觉、向量修改成本高、依赖嵌入模型 |
| 知识图谱 | 可解释性极强、实体关系清晰、支持逻辑推理与溯源 | 构建复杂、扩容困难、实体维护成本高、开发门槛高 |
| Markdown 文件 | 格式简洁、可读性强、支持Git版本控制、零学习成本 | 无语义检索、仅支持文本匹配、不适合大规模数据、依赖人工维护 |
4. 主流开源/商用记忆框架与服务
4.1 Mem0
Mem0 是 LLM 应用主流开源长期记忆中间件,解决模型上下文有限、会话记忆清零、个性化不足的核心痛点,支持自托管与托管双模式。
核心能力:
-
多粒度记忆隔离 :支持用户级、智能体级、会话级三级记忆隔离,适配多用户、多
Agent场景; -
智能动态更新 :依托
RAG+LLM实现记忆ADD/UPDATE/DELETE/NOOP动态迭代,2026年升级单趟提取,延迟更低、记忆更精准; -
三库混合存储 :向量库(语义检索)+
KV库(快速存取)+ 图数据库(关联推理),能力全覆盖。
快速接入示例(Python):
python
from mem0 import Memory
# 初始化记忆实例
m = Memory()
# 写入用户记忆
m.add("用户叫张三,后端工程师,擅长`Go`和`Python`", user_id="user123")
# 语义检索记忆
results = m.search("用户的技术栈", user_id="user123")
print(results[0]["memory"])4.2 OpenViking
2026年初字节开源的 Agent 专属上下文数据库,以文件系统范式 统一管理记忆、资源、技能,主打工程化、低Token开销,是OpenClaw官方推荐记忆层。
核心能力:
-
目录树结构化记忆 :分为用户记忆(档案、偏好、实体、事件)与
Agent记忆(案例、模式、工具、技能)八大体系; -
三级摘要按需加载 :
L0轻量摘要、L1核心概览、L2完整详情,Token消耗降低83%-96%; -
工程化适配:支持长会话、复杂任务、代码助手、企业知识库场景,可观测性强。
快速接入示例(Python):
python
from openviking import VikingContext
# 初始化上下文数据库
vc = VikingContext(user_id="user_001")
# 写入多维度记忆
vc.user.profile.set(name="张三", job="设计师")
vc.user.preferences.add("喜欢简约风格", "夜间工作")
vc.user.events.add("2025-05-29 完成PPT设计任务")
# 分层检索
summary = vc.retrieve(level=0) # 轻量摘要,省`Token`
detail = vc.retrieve(level=2) # 完整详情4.3 Supermemory
面向AI智能体的低延迟、可扩展记忆平台,主打无限记忆、毫秒级检索、全生态集成,解决记忆碎片化、跨会话不一致问题。
核心能力:
-
极致性能:边缘部署,检索延迟300ms以内,月处理100B+ tokens;
-
五层上下文架构:连接器、提取器、检索、知识图谱、用户画像全链路覆盖;
-
全生态适配 :支持
Claude、Cursor等主流模型,提供Python/TSSDK与浏览器插件; -
企业级合规 :支持私有化部署、
SOC2/HIPAA合规,数据自主可控。
快速接入示例(Python):
python
from supermemory import `Supermemory`
client=`Supermemory`(api_key="YOUR_`API`_KEY")
# 保存用户记忆
client.memories.create(content="我喜欢深色模式,编程用`Python`")
# 检索相关记忆
results=client.memories.search(query="我的编程偏好")
print(results)4.4 国内主流托管记忆服务
-
阿里云百炼记忆库 :国内官方托管服务,开箱即用、低延迟、适配
OpenClaw,个人免费、企业按量付费; -
腾讯云
Agent Memory:混元生态专属,适配多模态、企微生态打通,企业级合规,纯托管API服务; -
Zilliz MemSearch:向量数据库大厂出品,开源+托管双模式,文件与向量混合检索,适配多客户端记忆同步。