前言
指令微调(Instruction Tuning)已经成为大语言模型落地前的"最后一公里"。在这一阶段,我们通常使用大量 (指令,回复) 样本对模型进行再训练,让模型更擅长对话、执行任务,并更符合人类偏好。
但一个越来越常见、也让算法团队颇为头疼的现象是:数据并不是越多越好。
在真实的指令数据池中,冗余样本、噪声数据、格式不一致以及任务类型混杂都非常普遍。更反直觉的是,越来越多的研究发现:只使用 10%--20% 的训练数据,模型效果就可以接近甚至超过使用全部数据训练的结果。 这意味着一件非常重要的事情:更大的微调数据规模,并不一定带来更好的模型效果。 相反,当数据规模不断扩大时,训练成本迅速上升,而样本之间的相互干扰反而可能拖慢模型学习。因此,一个非常自然的问题出现了:如果我们能从大数据池中挑选出一小部分"最有价值"的样本,是否可以用更少的数据训练出更好的模型?
近年来,学术界提出了一条非常优雅的思路:利用 Fisher 信息矩阵(Fisher Information Matrix, FIM) 来衡量每个样本能够为模型参数提供多少"信息量"。直观来说,如果一个样本的梯度能够为参数更新提供更多独立信息,那么它就更值得被选入训练集。
基于这一思想,可以通过最大化
logdet(I+αFS)
这样的信息体积指标来选择数据子集。这个目标函数具有一个非常漂亮的性质------次模性(submodularity) :意味着即使使用简单的贪心算法,也能获得接近最优解的理论保证。
然而,在实际工程中,我们经常会看到另一面。当仅依据 Fisher 信息进行贪心选择时,边际信息增益往往会非常快地衰减:随着选择过程继续进行,新加入样本带来的信息越来越少,最终导致数据子集的质量不稳定,下游模型效果也会出现波动。
进一步分析后,我们发现,一个被忽略的重要因素是:样本之间的梯度冲突(gradient conflict) 。简单来说,不同样本在训练时会产生不同方向的梯度更新,如果这些更新方向彼此不一致,甚至互相对抗,那么即使每个样本单独来看都"信息量很高",它们组合在一起时,也可能互相抵消,从而加速信息增益的衰减。
从更广义的角度看,数据选择其实包含两个层面的关系:
一是 样本与模型之间的关系------每个样本能为模型参数带来多少有效信息;
二是 样本与样本之间的关系------不同样本在训练过程中是相互协同,还是彼此冲突。
过去的大多数方法主要关注第一点,而我们的工作则尝试把这两个关键因素联系起来:在最大化样本信息量的同时,显式建模样本之间的梯度 冲突。
我们的论文 SPICE(Submodular Penalized Information-Conflict Selection) 正是为了解决这个问题。该论文已被 ICLR 2026 接收(arXiv:2601.23155)。

SPICE 的核心思想是:在保持 Fisher 信息最大化 这一理论框架的同时,把 样本之间的梯度冲突(gradient conflict) 也纳入数据选择目标。
这样一来,算法在选择样本时不仅考虑"信息量有多大",还会考虑"这些信息是否彼此一致"。
最终的效果是:在不牺牲 次模贪心算法效率 的前提下,我们能够选出 信息量更高、冲突更低 的数据子集,让 10% 的数据真正训练出接近甚至超过全量数据的效果。
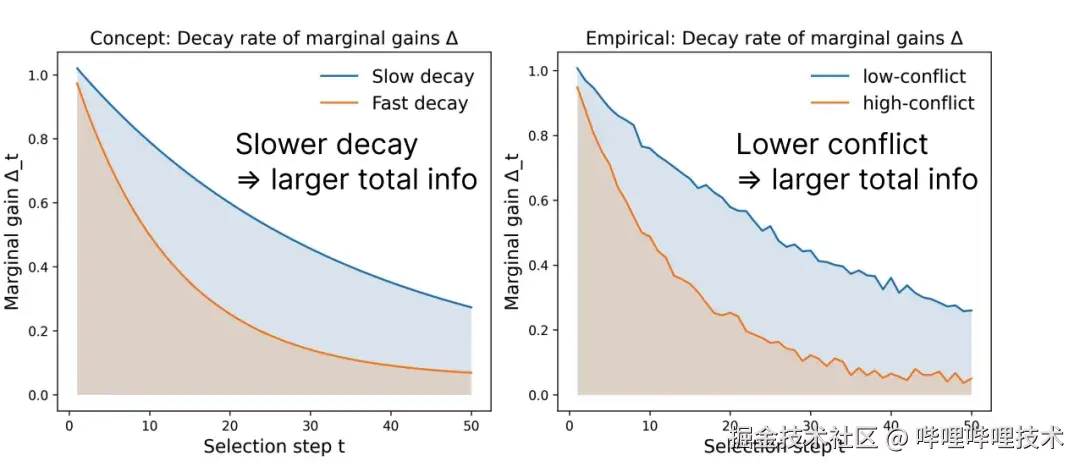
图1:边际信息增益 Δ 衰减越慢,同等预算下累计信息越大;实证上低冲突子集往往衰减更慢,信息更"耐用"。
动机:为什么 Fisher 贪心会越选越没用?
在 Fisher 视角下,数据选择可以理解为一个非常直观的问题:每个样本都会产生一个梯度信号,告诉模型参数应该往哪个方向更新。
设第 i 个样本产生的梯度为:
gi=∇θℓi
如果我们选择一个数据子集 S,那么对应的经验 Fisher 信息矩阵可以写成:
FS=i∈S∑gigi⊤
直观来说,这个矩阵描述的是:这些样本一共为模型参数提供了多少"可学习的信息方向" 。
常见的数据选择目标是最大化以下信息量:
F(S)=logdet(I+αFS)
这个目标函数具有一个非常好的性质:次模性(submodularity) 。简单理解就是------越往后选择新样本,能够带来的新增信息通常会越来越少 。因此,使用简单的贪心算法逐步选择样本,理论上就能得到接近最优的结果。但在真实的指令微调数据上,我们却经常观察到一个现象:
边际信息增益并不是"平滑下降",而是会出现"断崖式掉速" 。换句话说,在选择到某个阶段之后,新加入的样本几乎不再提供新的有效信息,对模型训练的帮助也变得非常有限。
这显然超出了经典次模理论所描述的"渐进递减"行为。
针对这种实践问题:SPICE 的关键观察是:这种"边际信息断崖式衰减",往往会与 gradient conflict(梯度冲突) 同步出现。所谓梯度冲突,指的是不同样本在参数空间中产生方向不一致甚至相反的更新信号 。当这种情况发生时,就会出现一种现象:单个样本的信息量看起来很大,但它们提供的新方向却很少 。结果就是:Fisher 信息仍在增长,但真正可累积的有效信息却越来越少。于是,贪心算法的边际增益会被迅速"消耗",导致后续选择的样本对训练几乎没有帮助。
基于这一观察,我们重新审视了 Fisher 数据选择的机制,并提出了三个关键问题:
- Fisher 的边际信息增益到底由哪些项决定?
- 其中哪些项在实际数据中会被梯度冲突放大,从而导致增益快速衰减?
- 如果冲突确实是关键因素,能否把它做成一个可测量、可控制的惩罚项,并直接加入到贪心选择中?
回答这些问题,正是 SPICE 方法设计的出发点。
方法:SPICE = 信息增益 − 冲突惩罚
SPICE 的核心思想其实非常简单:在 Fisher 信息最大化的基础上,引入一个"梯度冲突惩罚项" 。
这样,算法在选择样本时不仅会考虑 信息量有多大 ,还会考虑 这些信息是否彼此一致。
从方法设计的角度看,SPICE 的思路可以概括为三步:
- 把 Fisher 的边际信息增益拆解,找出真正导致增益衰减的因素;
- 用一个工程上可计算的指标度量梯度冲突;
- 在原有 Fisher 贪心算法上加入一个"软惩罚",并配合自适应早停和 proxy 选择机制。
下面我们依次来看。
1.边际增益的分解:衰减来自交互项
在 Fisher 贪心选择中,我们关心的是每个候选样本的边际信息增益:
Δx(S)=F(S∪{x})−F(S)
SPICE 的第一步,是把这个增益拆解为两部分:
Δx(S)=base: 单点强度 log(1+α∥gx∥22)+interaction: 交互扰动 εx(S)
单点强度交互扰动
直观理解:
第一项(base) 只反映这个样本本身的梯度强度,也就是它单独能提供多少信息。第二项(interaction) 描述这个样本与当前已选集合 S 的交互影响。
关键在于:真正导致信息增益快速衰减的,其实是这个交互项。
当当前集合已经覆盖了相似的梯度方向,或者不同样本之间存在方向冲突时,新样本能够提供的"新方向信息"就会迅速减少。
2.冲突度量:用平均梯度方向做代理
既然交互项与梯度方向有关,一个自然的问题是:如何高效度量样本之间的梯度冲突?
如果直接计算所有样本两两之间的关系,计算成本会非常高。
SPICE 采用了一种更工程友好的近似方法。我们维护当前集合的平均梯度方向:
gˉ=∣S∣1x∈S∑gx
然后用余弦相似度衡量新样本与当前更新方向的对齐程度:
Align(gi)=∥gi∥∥gˉ∥+ηgi⊤gˉ
冲突则定义为:
Conflict(gi)=max(0,−Align(gi))
这个度量非常直观:
- 同方向(对齐) :不惩罚
- 反方向(冲突) :产生惩罚
- 计算复杂度低:只需要对每个候选样本计算一次
因此在大规模数据池中也可以高效运行。
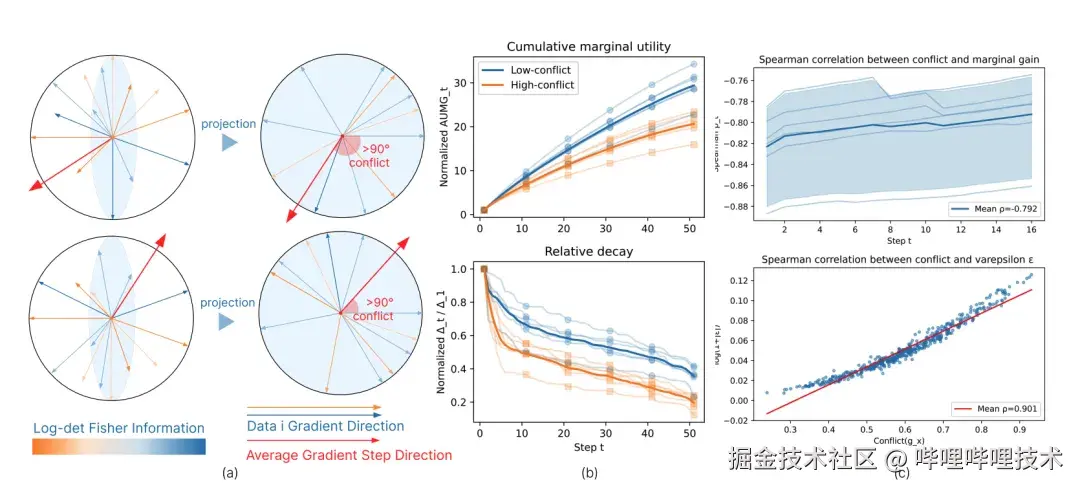
图2:论文展示冲突统计量与边际增益衰减/交互项之间存在系统相关性,为"用冲突解释掉速"提供证据。
3.冲突感知贪心:不丢信息,只降低冲突
在得到冲突度量之后,SPICE 对原有 Fisher 贪心做了一个非常克制的修改:
其中:
● Δx(S):信息增益
● Conflict(x∣S):梯度冲突
● λ:冲突惩罚强度
我们特别强调,这是一种软惩罚(soft penalty) 。
这意味着:
- 如果一个样本信息量很大,即使存在冲突,仍然可能被选中
- 算法只是降低冲突样本的优先级,而不会直接删除
这是因为在真实数据中,确实存在一些信息量很高但梯度方向不稳定的困难样本。如果简单过滤掉它们,反而会损失数据覆盖度。
4.自适应早停:边际增益不值得时就停止
传统数据选择通常会预先设定一个固定预算 k,比如选 10% 数据。
SPICE 则采用一种更灵活的策略:根据边际增益的衰减情况自动停止选择。
具体来说,当第 t 步的最优边际增益满足:
Δxt(St−1)≤ω⋅Δx1(S0)
算法就会停止。
直觉上,这相当于在: "新增样本的性价比已经明显下降"时及时刹车。
这样可以避免把预算浪费在信息增益很低的尾部样本上。
5.Proxy 选择:让选择成本可控
最后一个工程问题是:在大模型上计算所有样本的梯度本身就很昂贵。
SPICE 的解决办法是:
- 使用同架构的小模型作为 proxy 来计算梯度
- 用合理的更新间隔来减少重复计算
这种方法利用了一个经验观察:数据选择模式在不同规模模型之间往往具有可迁移性。
因此,我们可以在小模型上完成数据选择,再把选出的子集用于大模型训练,从而实现:
选择成本可控,同时保持效果。
实验结果:只用约 10% 数据,也能匹配甚至超过全量微调
为了验证 SPICE 的效果,我们在约 97.5K 条指令数据上进行了系统实验。数据覆盖多个典型场景,包括:
- 数学推理任务
- 代码生成任务
- 通用指令跟随任务
在模型设置上,我们使用 LLaMA2-7B 和 Qwen2-7B 作为基座模型,并与多种主流数据选择方法进行了对比实验。
实验结果可以总结为两个核心发现。
1. 梯度冲突确实解释了信息增益"掉速"
实验分析发现,当数据选择序列中的 梯度冲突更低 时,会出现两个明显变化:
- 边际信息增益衰减更慢
- 累计 Fisher 信息更大
换句话说,如果样本之间的梯度方向更加一致,新的样本就更容易提供"真正的新信息"。
而当冲突较高时,不同样本会在参数空间中产生相互抵消的更新,导致信息增益被快速消耗,从而出现我们在实践中常见的 "越选越没用" 的现象。这一观察与 SPICE 的理论分析高度一致。
2. SPICE 让"小数据"真正变强
在仅使用 约 10% 的训练数据 时,SPICE 选出的数据子集在多个 benchmark 上:
- 能够匹配甚至超过全量数据微调的效果
- 同时 显著降低训练成本
这意味着,通过合理的数据选择,小规模高质量数据集可以替代大规模原始数据,从而实现 更高的数据效率和更低的训练成本。
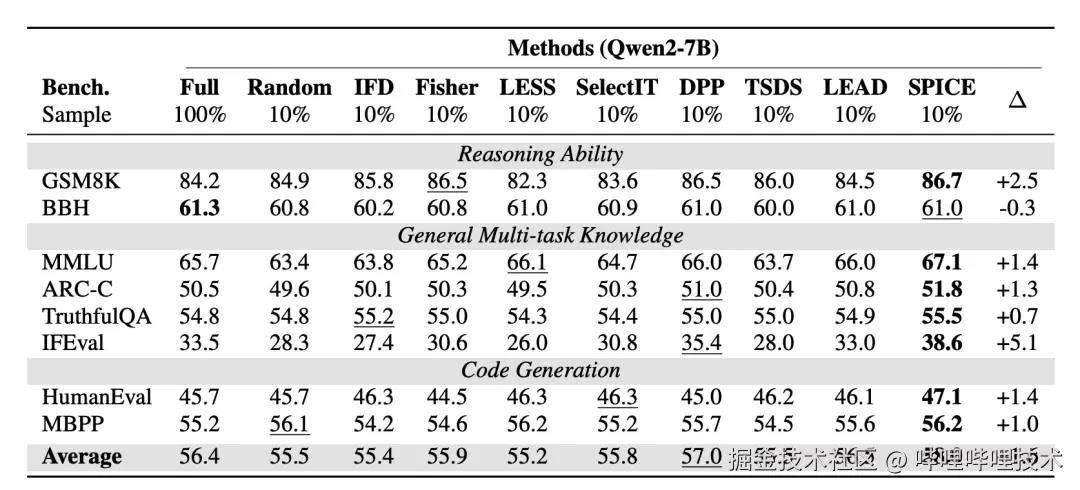
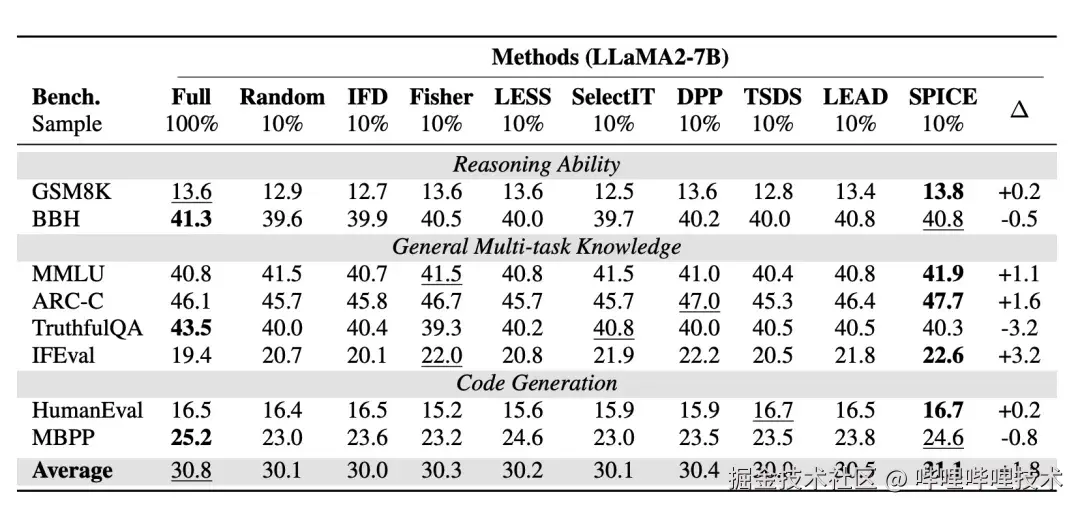
表1(Qwen2-7B/LLaMA2-7B):在仅用 10% 指令数据时,SPICE 在 GSM8K/MMLU/IFEval/HumanEval 等多类基准上整体优于多数选择基线,平均分也超过 Full/Random 等对照
一个有意思的现象出现在训练动态中:
SPICE 选出的数据子集往往"起点更难"(初始 loss 更高),但训练下降得更快、也更稳定。
这与 SPICE 的选择机制非常一致------它更倾向于选择 信息量更高、同时彼此不发生梯度冲突的样本序列。这些样本虽然更具挑战性,但能够为模型提供更加一致和有效的学习信号。
总结
SPICE 的核心贡献,并不是再提出一个复杂的数据选择算法,而是把一个长期存在却常被忽视的问题讲清楚,并给出一个简单而可落地的解决方案。
具体来说,这项工作做了三件事情:
- 从理论上,我们指出 Fisher 次模目标中常见的"边际信息增益快速衰减",实际上来自样本之间的交互项,而不仅仅是经典次模理论中的"递减收益"。
- 从经验上 ,我们进一步发现,这个交互项与 梯度冲突(gradient conflict) 之间存在稳定的统计关联------当样本之间的梯度方向冲突更少时,信息增益的衰减也会明显变慢。
- 从算法上 ,SPICE 用一个非常克制的方式改造了传统的 Fisher 贪心选择:通过在目标函数中加入 "信息增益 − 冲突惩罚" 的简单结构,并配合 自适应早停 和 proxy 选择机制,使这一方法能够在真实的大规模指令微调场景中高效运行。
对于正在进行 指令微调加速 或 数据治理 的团队,这项工作带来的启发是:数据选择不仅要挑"信息量大的样本",还要避免选择那些彼此"互相拆台"的样本。当我们把样本之间的冲突关系也纳入选择目标时,小规模的数据子集也能够更加稳定地把信息转化为真正的训练收益。
-End-
作者丨争气尾流、zbw