引言
学到后面会发现,很多性能问题并不是协议本身决定的,而是操作系统怎么搬数据、CPU 怎么访问内存、线程之间怎么共享缓存决定的。
这一篇把几个容易分散的知识点串起来:
- 文件发送到远程服务器时发生了什么
- 为什么零拷贝能提升性能
- 一次读 IO 的典型路径是什么
- CPU 三级缓存是什么
- 伪共享为什么会拖慢多线程程序
把磁盘中的文件发送到远程服务器,传统方式会经历什么
如果应用程序使用普通的 read + write/send 方式把文件发到网络上,数据大致会经历下面这条路径:
- 磁盘数据通过 DMA 进入内核空间的页缓存(Page Cache)。
- 应用调用
read,数据从内核缓冲区复制到用户态缓冲区。 - 应用调用
write或send,数据再从用户态缓冲区复制到内核的 Socket 发送缓冲区。 - 网卡通过 DMA 把数据从发送缓冲区搬到网卡缓冲区并发出。
这条路径里,典型问题有两个:
- 有多次数据复制
- 有多次用户态和内核态切换
这些成本在大文件传输或高并发场景下会比较明显。
零拷贝为什么更快
零拷贝的目标不是"完全没有任何复制",而是尽量减少不必要的 CPU 搬运和上下文切换。
在 Linux 中,sendfile() 就是典型方案。
它的核心思路是:
- 文件仍然先通过 DMA 读入内核页缓存。
- 应用程序不再把数据拷贝到用户空间。
- 内核直接把页缓存中的数据交给网络协议栈和网卡发送。
这样带来的好处是:
- 少了一次从内核到用户态的复制
- 少了一次从用户态回到内核态的复制
- 降低了 CPU 参与"搬运数据"的成本
所以零拷贝更像是在说:
"让 CPU 少当搬运工,多当调度员。"
一次读 IO 通常会经历什么过程
应用程序发起一次读操作时,典型过程如下:
先查 Page Cache
内核首先检查页缓存里是否已经有目标数据。
如果命中,读取速度会非常快,因为不需要真的去访问磁盘。
未命中则发起磁盘 IO
如果缓存没有命中,内核会把请求交给块设备层,再交给磁盘控制器执行实际读取。
磁盘把数据搬到内存
现代系统中,这一步通常通过 DMA 完成,把数据搬到内核空间相关缓冲区或页缓存。
内核再把数据交给用户进程
如果应用程序调用的是普通 read,最终还要把数据从内核空间复制到用户空间缓冲区。
所以一次看似简单的读操作,背后往往涉及缓存、调度、DMA、内核缓冲区和用户缓冲区等多个环节。
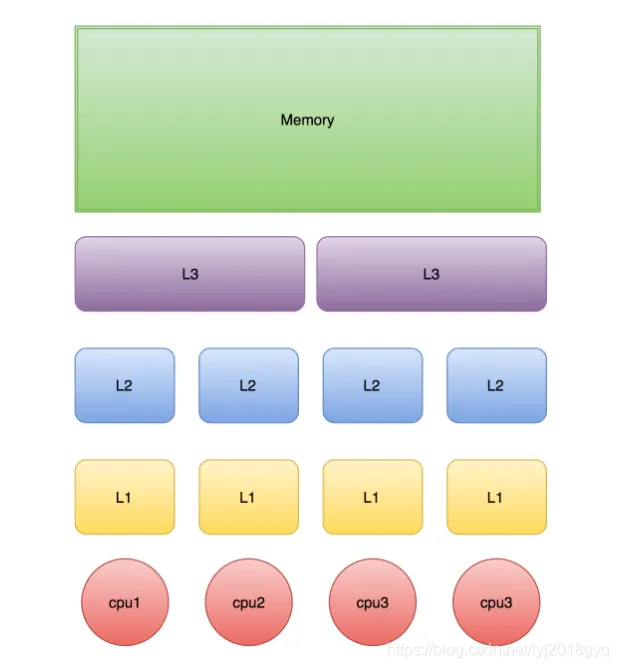
CPU 三级缓存是什么
CPU 的执行速度远快于内存访问速度,所以系统设计了多级缓存来缓解这个差距。
常见缓存层次是:
- L1 Cache
- L2 Cache
- L3 Cache
基本规律如下:
- 越靠近 CPU,速度越快
- 越靠近 CPU,容量越小
通常可以这样理解:
- L1:每个核心独享,容量最小,速度最快
- L2:通常也是核心级别,容量比 L1 大
- L3:多个核心共享,容量更大,但速度更慢
访问顺序通常是:
CPU -> L1 -> L2 -> L3 -> 内存
多级缓存的存在,本质上是为了减少 CPU 直接访问主内存的次数。
CPU 三级缓存结构示意图如下:
什么是缓存行
CPU 缓存不是按"一个变量"来管理的,而是按"缓存行"来管理的。
缓存行通常是 64 字节,它是缓存系统中最小的管理单位和失效单位。
这意味着:
- CPU 读取一个变量时,往往会把它周围相邻的一块数据一起读入缓存
所以连续内存访问通常更高效,因为它更容易命中缓存行。
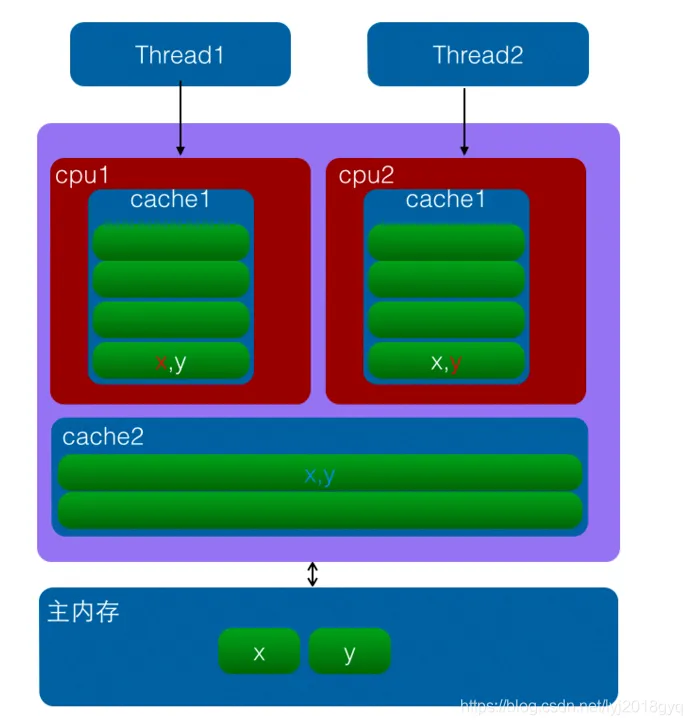
什么是伪共享
伪共享是并发编程里一个很常见但不容易一眼看出来的性能问题。
它的典型场景是:
- 线程 A 修改变量
x - 线程 B 修改变量
y x和y虽然是两个不同变量,但它们刚好落在同一个缓存行里
结果就是:
- 一个线程修改其中一个变量时,会导致另一个 CPU 核心上对应缓存行失效
- 另一个线程又不得不重新从更低层缓存甚至主内存加载
虽然两个线程逻辑上没有共享同一个变量,但硬件层面它们共享了同一个缓存行,因此产生了额外的缓存一致性开销。
这就是"伪共享"。
伪共享示意图如下:
如何减少伪共享
常见做法包括:
- 让高频写入的变量分散到不同缓存行
- 使用填充字段(padding)避免热点变量相邻
- 尽量减少多个线程同时写共享区域
所以很多高性能并发框架里,你会看到一些看起来"很浪费空间"的字段填充设计,本质上就是在避免伪共享。
Linux 服务器之间的时间差为什么通常不大
分布式系统里,时间同步也是基础问题。
Linux 服务器通常通过 NTP 来做时钟同步。
在实践中:
- 局域网环境下,服务器之间的时间差通常可以控制在毫秒级
- 广域网环境下,由于网络延迟和抖动,误差会更大一些
这也是为什么很多分布式系统不会完全依赖本地时间戳去做绝对顺序判断,而是会引入逻辑时钟、版本号、雪花算法等方案。
总结
很多高性能优化,最后都会落在三件事上:
- 少复制数据
- 少切换上下文
- 少让 CPU 缓存失效
零拷贝解决的是数据搬运成本,页缓存解决的是磁盘读取成本,CPU 多级缓存解决的是内存访问成本,伪共享解决的是多线程下缓存一致性带来的隐藏性能损耗。
如果你准备继续学习 Netty、Kafka、Redis 这类高性能组件,这些底层机制都是绕不过去的基础。
如果这篇文章对你有帮助,欢迎继续阅读本系列后续内容。若文中有不准确或需要补充的地方,也欢迎指出。