本文大部分内容从此处转载:
https://blog.csdn.net/2301_80017072/article/details/149673006![]() https://blog.csdn.net/2301_80017072/article/details/149673006https://blog.csdn.net/weixin_36531037/article/details/136644802
https://blog.csdn.net/2301_80017072/article/details/149673006https://blog.csdn.net/weixin_36531037/article/details/136644802![]() https://blog.csdn.net/weixin_36531037/article/details/136644802
https://blog.csdn.net/weixin_36531037/article/details/136644802
0. 前言

在大多数互联网应用中,缓存的使用方式如上图所示:
①发起一个查询请求时,首先判断缓存中是否有该数据;
② 如果缓存中存在,则直接返回数据
③如果缓存中不存在,则查询数据库,把数据写入到缓存中,最后返回数据
了解了上述过程后,下面说说缓存穿透
1. 什么是缓存穿透
**缓存穿透:**客户端请求的数据在缓存、数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
举例:假设有人传了一个不存在的商铺id 到服务器欲查询商铺信息,服务器会先查询缓存,发现没有,再去查询数据库,发现也没有该 id 对应的商铺信息,这就叫缓存穿透
危害: 如果恶意攻击者创建无数个线程,并发地请求这个不存在的数据,这会导致所有请求全部去查询数据库,数据库压力倍增,可能导致系统崩溃。这就是缓存穿透的危害
2. 缓存穿透是如何产生的?
**① 恶意攻击:**攻击者故意构造大量数据库里根本不存在的数据来发起请求(请求不存在的用户ID、商品ID、订单号等),由于缓存中并不存在这些数据,因此海量请求均落在数据库中
② 代码逻辑错误: 应用本身逻辑问题,错误地生成了无效的查询键(如输入校验不严,用户输入了无效ID等)
3. 缓存穿透的危害
① 数据库压力剧增: 缓存本应作为数据库的 "盾牌",穿透会让盾牌失效,数据库直接暴露在高并发请求下
② 数据库性能瓶颈: 数据库处理能力有限,面对大量无效查询,其CPU、内存、IO资源会被迅速耗尽
③ 服务响应延迟或不可用: 极端情况下,数据库可能因连接耗尽、CPU 占用过高而崩溃,进而导致依赖它的服务瘫痪,最终表现为整个应用卡顿或宕机
4. 缓存穿透的解决方案
解决的核心思路是:即使数据库中没有数据,也要在缓存层形成一种伪"存在"的标记或结果,阻止 请求穿透到数据库。 常用且有效的解决方案包括两种:缓存空数据、布隆过滤器
4.1 缓存空数据
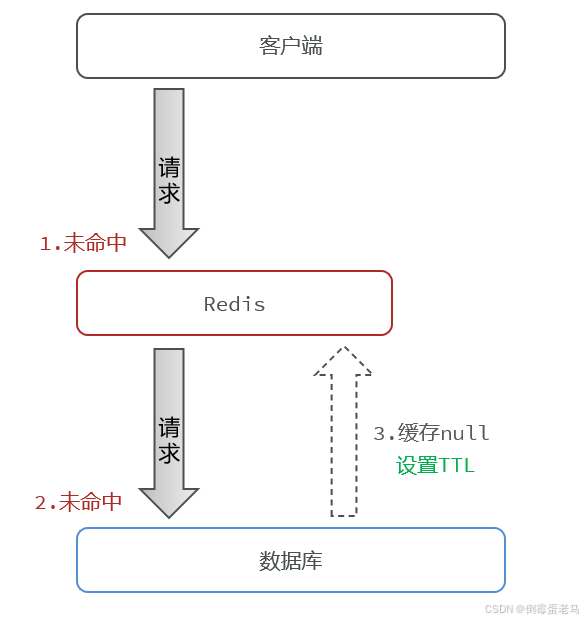
- 原理: 当查询数据库返回空结果(即数据不存在)时,将这个**"空结果"**也缓存起来。例如:用户查询 ID=12345 的用户,数据库无结果 → 缓存 Key = user:12345,Value = null ,设置有效时间 3 分钟 → 3 分钟内相同的 Key 请求则直接返回 null
- 过程:
- 请求查询 Key X
- 缓存未命中
- 查询数据库,发现数据不存在
- 将 Key = X 与一个表示 "空" 的值写入缓存,并设置一个相对较短的过期时间,如2分钟
- 后续请求查询 Key X 时,能有效拦截短时间内对同一个不存在 Key 的重复请求
- **优点:**实现简单,能有效拦截短时间内对同一个不存在 Key 的重复请求
- 缺点 :
- 内存浪费:如果攻击者大量构造不同的、随机的不存在Key,缓存中会存储大量无意义的空对象,内存资源浪费
- 数据短期不一致:如果某一个请求查询空数据 Key = 12345,此时在缓存中会生成该空数据对应的缓存,有效期假设为3分钟。如果在3分钟内,数据库中真的添加了这个Key对应的数据,那么在该Key过期之前,请求查询Key=12345的数据一直会返回空/错误结果,这导致数据不一致问题。所以可以通过设置一个较短的有效期或主动删除缓存来缓解
4.2 布隆过滤器(Bloom Filter)
(1)原理

原理: 布隆过滤器是一种空间效率极高的概率型数据结构 。它使用一个很长的二进制向量(Bit Array)和一系列随机映射函数(Hash函数)来存储和检测某个元素是否可能存在于一个集合中

**添加元素:**将元素通过 K 个不同的hash函数映射,一个hash函数可以得到一个在bitmap中的索引值,因此可得到 K 个不同索引,将这些位置上的值置为1
**查询元素:**将元素通过 K 个 hash函数(跟添加时相同),得到 K 个索引
① K个索引上的值全为1,则认为该元素"可能存在"(布隆过滤器存在一定的误判率),因为这些索引上的值可能是其他元素导致这些位被置为 1 的,所以对于布隆过滤器判断可能存在的值,还需要进一步验证
② K个索引上的值存在任何一个位置是 0,则该元素一定不存在
总结:当布隆过滤器说某个元素存在时,这个值可能不存在;当它说某个元素不存在时,那就肯定不存在
(2)应用解决缓存穿透
应用解决缓存穿透:
① 将所有可能存在的、有效的查询Key(例如,所有有效的用户ID、商品ID)预先加载到布隆过滤器中
② 当请求到来时:
(1)先用布隆过滤器检查请求的key
(2)如果布隆过滤器说 Key不存在,则说明肯定不存在 ----> 直接返回空结果或错误响应给客户端,不再查询缓存、数据库(这是拦截穿透的关键)
(3)如果布隆过滤器说 Key 可能存在 ---> 继续走正常的缓存查询流程(查缓存 ---> 缓存命中则返回;缓存未命中则查询数据库 ----> 数据库查到则回填缓存;数据库查不到则缓存空对象)
(3)优缺点、适用场景
优点
① 间效率极高: 相比存储完整Key或空对象,布隆过滤器占用空间极小(存储 1 亿个 ID 仅需约 100MB)。
② 查询效率极高: 检查一个Key是否存在的时间复杂度是 O(K)(K是哈希函数个数)
③ 有效拦截: 能准确拦截数据库中肯定不存在的Key的请求
缺点
① 误判率(False Positive): 可能存在误判(即布隆过滤器认为Key存在,但实际上数据库不存在)。这是概率性的,但可以通过增加位数组大小和哈希函数数量来降低误判率(代价是空间和计算时间增加)
**② 删除困难:**标准的布隆过滤器不支持元素删除(因为多个元素可能共享同一个bit位)。可以使用变种如计数布隆过滤器(Counting Bloom Filter)支持删除,但空间开销更大
③ 初始化/维护: 需要预加载有效Key集合,并在数据库新增/删除有效Key时同步更新布隆过滤器(有一定延迟或复杂性)
适用场景
**适用场景:**非常适合解决大规模、随机Key的恶意攻击造成的穿透问题。是当前最主流和推荐的解决方案
4.3 接口层校验(Validation)
- 原理: 在请求到达缓存 / 数据库前,通过接口层(如网关、Controller)过滤明显无效的参数,直接拦截恶意请求。
- 方法:
- 格式校验: 检查ID是否符合规则(如必须是正整数、长度范围、符合特定格式如UUID)
- 范围校验: 检查ID是否在已知的有效范围内(如果业务允许定义范围)
- 业务规则校验: 根据业务逻辑判断请求是否合理(例如,查询一个状态为"已删除"的订单)
- 优点: 简单直接,能过滤掉一部分明显无效的请求。
- **缺点:**对于构造精良、看起来符合规则的无效Key(如随机生成但在有效范围内的ID)无法拦截。无法防御大规模、随机的无效Key攻击。
- 适用场景: 作为基础防护,必须与其他方案(布隆过滤器、缓存空数据)结合使用。是防御的第一道门槛
4.4 实时监控与风控
- **原理:**对系统的访问模式进行实时监控,识别异常流量(如大量请求命中空对象缓存、大量请求直接访问数据库且返回404)
- 方法:
- 设置告警阈值(如单位时间内访问不存在Key的频率)
- 对识别出的恶意IP或用户行为模式进行限流(Rate Limiting)、封禁(IP Blocking)或人机验证(CAPTCHA)
- **优点:**能主动发现并应对攻击行为,保护系统
- 缺点: 属于事后补救或动态防御,需要一定的监控和风控系统建设成本。不能完全替代前几种在数据访问层的防御措施
- 适用场景: 作为补充防护手段 ,用于发现和缓解正在进行的攻击