16÷4 陷阱:一行代码让 SharedArrayBuffer 数据全部错位
主线程写进去的采样数据,Worklet 线程读出来全是乱码。
不是数据损坏。不是跨线程竞争。不是字节序。
你把 16 字节偏移当成了 16 个元素索引。
这个 bug 我在写 stw-sentinel 时踩的。processor.js 里 HEADER_SIZE = 16,TypedArray 构造器第三个参数是元素个数不是字节数------16 个 Int32 元素 = 64 字节,header 直接膨胀 4 倍,后面的数据全偏了 48 字节。SAB 没坏,Atomics 没报错,数据就是永远对不上。
陷阱解剖
SharedArrayBuffer 是一块裸内存。你在上面建视图,同一个偏移量,不同类型的索引含义完全不同:
javascript
// ❌ 我的 bug
const HEADER_SIZE = 16; // 16 字节
const header = new Int32Array(sab, 0, HEADER_SIZE); // 16 个 Int32 元素 = 64 字节!
const data = new Float32Array(sab, HEADER_SIZE * 4); // 偏移 64 字节,完全错位
// ✅ 修完
const HEADER_BYTES = 16;
const headerElements = HEADER_BYTES / 4; // 4 个 Int32 元素
const header = new Int32Array(sab, 0, headerElements); // 4 元素 = 16 字节
const data = new Float32Array(sab, HEADER_BYTES); // 从第 16 字节开始错误版本里,Int32Array(sab, 0, 16) 创建了 16 个 Int32 元素,占 64 字节。你的 header 本该占 16 字节,实际占了 64 字节。后面的数据区跟着偏移了 48 字节------不多不少,刚好 4 倍。
数据不会报错。 Int32Array 和 Float32Array 都能正常读写,Atomics 操作也不报异常。你的监控面板上看到的只是"数据对不上",没有任何 red flag 告诉你偏移算错了。
为什么 AudioWorklet 里这个坑最致命
非实时场景下,写错偏移顶多是初始化失败,加个 try-catch 就能定位。但 AudioWorklet 的 process() 回调每 128 帧跑一次(约 2.67ms),数据是流式消费的------错位就是错位,没有重传机制,没有校验和,数据流永远对不齐。
更毒的是:console.log 打出来全是 Int32 值,值本身没坏,只是写到了错误的内存位置。你盯着输出看半天,看不出任何异常。
前端开发者对"字节对齐"几乎没直觉。JavaScript 层面你碰不到字节,new ArrayBuffer(16) 对你来说就是"16 个槽位",很少去想这 16 个槽位的单位是什么。直到你用 SharedArrayBuffer 搭实时管道,字节和元素的分界线才会咬你一口。
底层代码没有类型系统保护你。字节和元素搞混,编译器不报错,运行不崩溃,就是数据不对。这种 bug 最毒------你不一定发现得了。
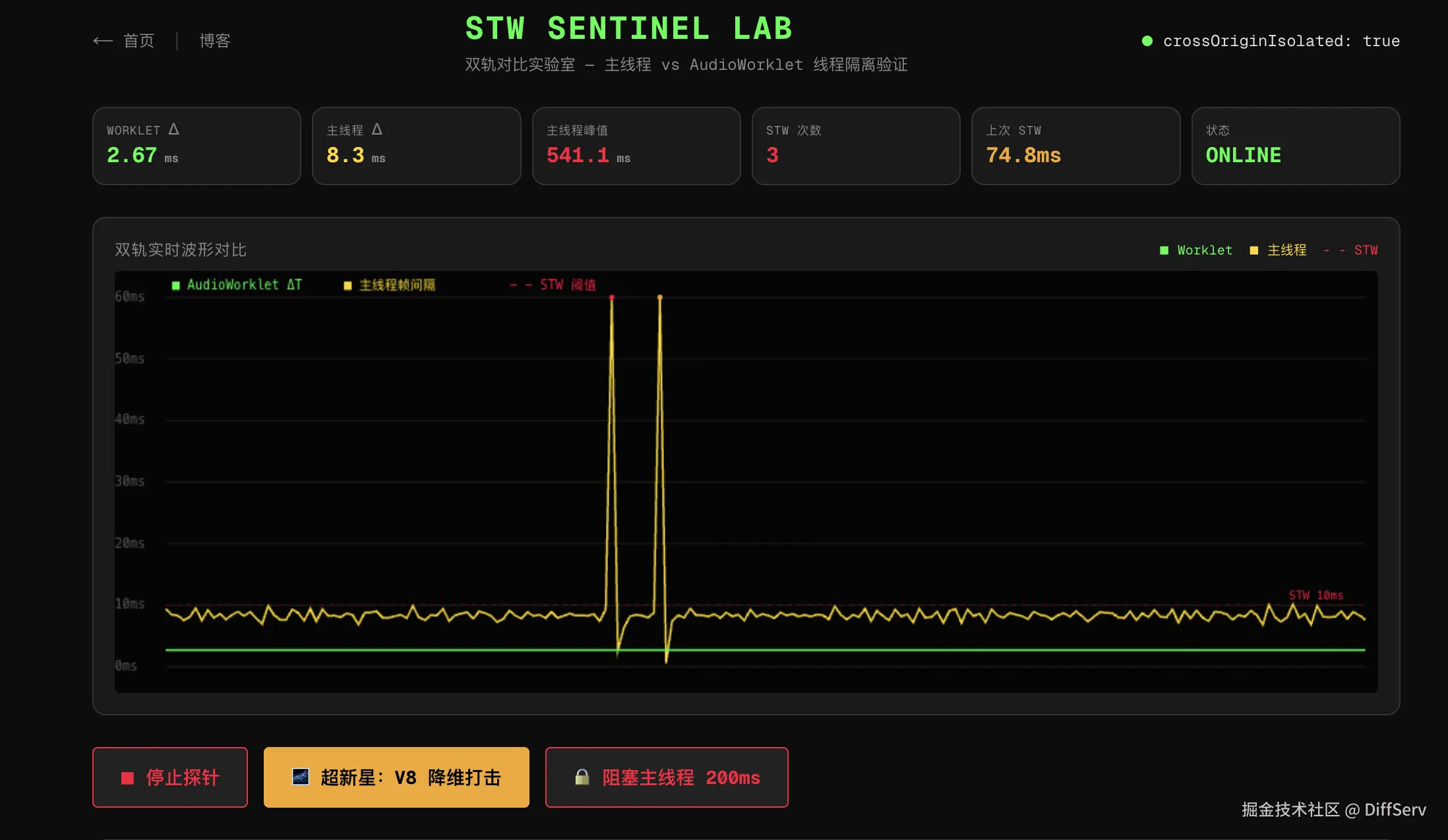
在线验证:diffserv.xyz/lab, Worklet 心跳(~2.67ms),黄线是主线程帧间隔。两条线各跑各的,SAB 是唯一的桥。数据对齐了,就没有坑。
npm install stw-sentinelGitHub: github.com/hlng2002/st...