简介说明
IndexTTS2今夕版最新版本号2026-04-12再次更新 新添加功能SRT字幕文件生成音频 以及生成音频同时生成SRT 字幕文件
本项目基于 `IndexTTS2` 搭建,提供本地化的零样本文本转语音能力。
它可以通过一段参考音频克隆音色,并结合文本内容生成对应语音;同时支持情感控制、术语读音管理、
示例管理和 WebUI 交互操作,适合用于配音、角色语音生成、短句播报、内容创作和本地测试。
当前项目的主要入口是 webui.py(/e:/index-tts-main/webui.py),启动后可通过浏览器进行操作。
核心能力
1. 零样本音色克隆
-
上传一段参考音频后,可以让模型模仿该说话人的音色生成新语音。
-
支持直接上传本地音频,也支持在界面中管理和复用参考音频。
2. 文本转语音生成
-
输入目标文本即可生成语音。
-
支持中文和英文场景。
-
可结合参考音频实现"同音色不同文本"的语音生成。
3. 情感控制
项目支持多种情感控制方式:
-
与音色参考音频保持相同情感
-
使用单独的情感参考音频
-
使用情感向量控制
-
使用情感描述文本控制
可用于生成平静、喜悦、低落、愤怒等不同风格的语音表达。
4. 分句生成与高级参数控制
-
支持长文本自动分句处理。
-
可设置每段最大 Token 数,平衡生成质量与速度。
-
可调节采样参数,如 `top_p`、`top_k`、`temperature`、`num_beams`、`repetition_penalty`、`max_mel_tokens` 等。
适合对生成结果进行更细粒度的控制。
WebUI 扩展功能
除了模型原有能力外,本项目的 WebUI 还额外加入了适合日常使用的功能增强。
1. 多音字文本预处理
-
可在生成前对指定关键词做文本替换。
-
适合修正多音字、固定发音和特殊口语读法。
-
支持添加、更新、删除规则。
-
支持词库导入与导出。
-
支持预处理结果预览和复制。
例如:
```text
倒 -> dao3
```
生成前可把特定词语替换成期望读音,减少错误发音。
2. 自定义术语词汇读音
-
可为专业术语、自定义词汇、品牌名、人名等设置单独读法。
-
支持分别设置中文读法和英文读法。
-
适合处理模型默认发音不准确的专有词汇。
3. 停顿与拉长音控制
当前 WebUI 支持在文本中直接使用简码控制停顿和局部拉长音。
支持的停顿写法:
```text
pause=300
sil=500
【停顿=200】
```
支持的拉长音写法:
```text
啊~
啊~~
啊~~~
啊stretch=1.4
嗯elong=1.5x
好拉长=1.3倍
```
示例:
```text
今天天气真好啊~pause=300我们继续测试。
```
说明:
-
停顿建议单次 `200~500ms`
-
拉长音建议 `1.1~1.6` 倍
-
连续 `~` 会逐步加长
-
倍数过大可能出现不自然或杂音
-
当前"拉长音"更适合做轻微拖尾感,不适合追求特别夸张的长音延展
重点更新
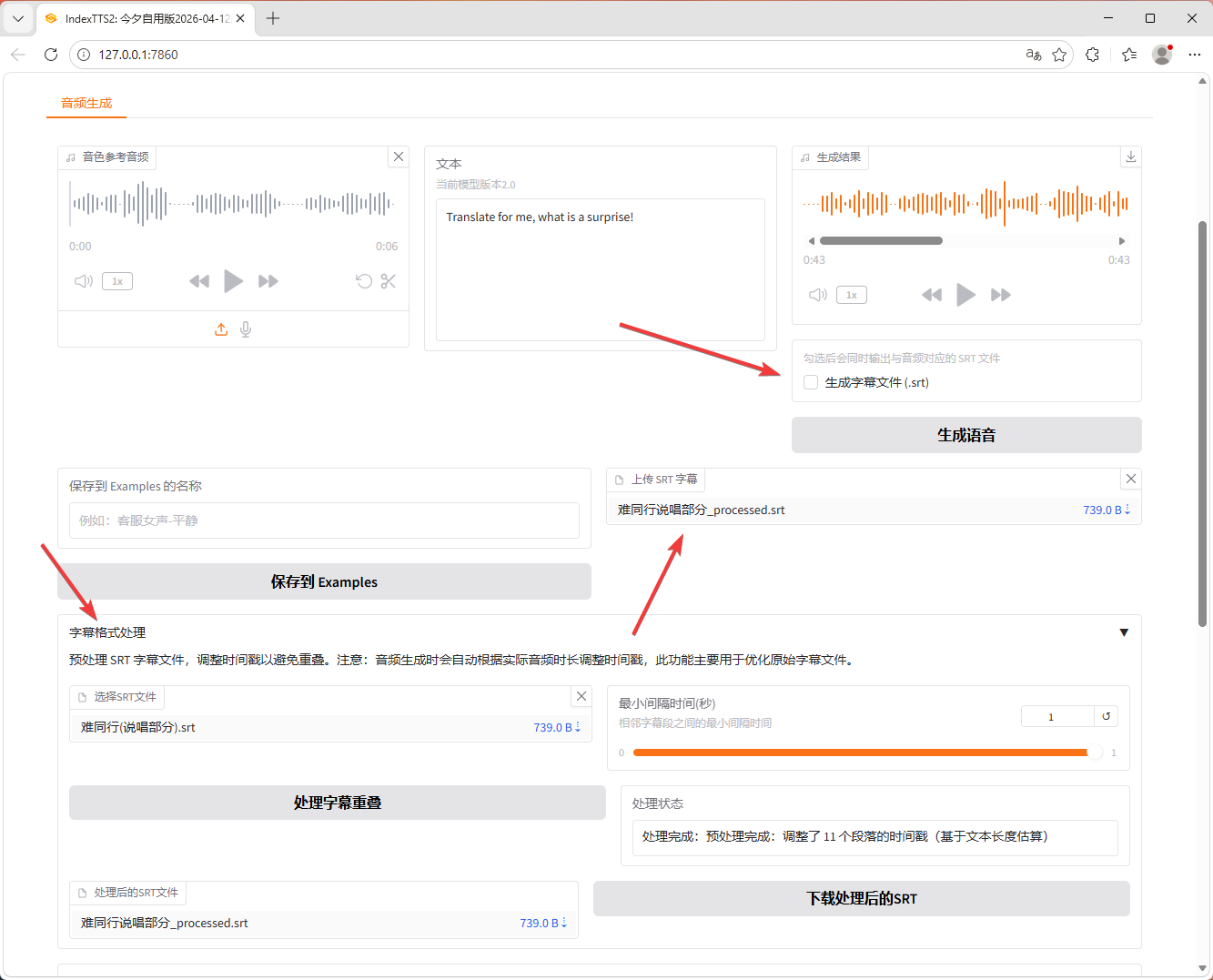
4. SRT 字幕文件处理
新增强大的字幕文件处理能力,支持基于时间轴的精确音频生成。
字幕文件上传与生成
-
支持直接上传 `.srt` 格式字幕文件
-
根据字幕时间戳自动生成对应时段的音频内容
-
支持同时输出生成的 SRT 字幕文件
-
智能解析标准 SRT 格式(时间戳+文本内容)
字幕格式预处理工具
-
自动检测和修复字幕时间段重叠问题
-
基于文本长度智能估算音频时长
-
批量调整时间戳,避免手动处理繁琐
-
处理结果可预览和下载保存
智能防冲突机制
-
上传 SRT 文件时自动清空文本输入框
-
防止文本输入和字幕上传功能同时使用导致冲突
-
提升用户操作体验和生成质量
更多功能
5. Examples 示例管理
WebUI 提供了示例数据管理能力,方便快速复用常用配置。
-
支持把当前配置保存到 `Examples`
-
支持按名称筛选
-
支持关键字搜索
-
支持分页浏览
-
支持切换每页显示数量
-
支持删除示例
-
支持显示当前选中示例,避免误删
适合保存常用的角色音色、情感组合和测试文本。
5. 参考音频管理
支持对参考音频进行本地管理:
-
搜索
-
分页查看
-
预览播放
-
选中回填
-
上传新音频
-
替换旧音频
-
重命名
-
删除
适合维护自己的音色素材库。
适用场景
本项目适合以下场景:
-
AI 配音与旁白生成
-
角色台词生成
-
有声内容创作
-
短视频配音
-
术语播报与专业文本试读
-
本地化 TTS 调试与实验
使用方式概览
启动
常见启动方式:
-
运行 start_webui.bat(/e:/index-tts-main/start_webui.bat)
-
或直接运行 webui.py(/e:/index-tts-main/webui.py)
基本流程
-
上传或选择音色参考音频
-
输入要生成的文本
-
按需设置情感、术语读音、多音字规则、停顿或拉长音
-
点击"生成语音"
-
在生成结果中试听和保存
项目特点总结
-
支持零样本音色克隆
-
支持情感控制
-
支持术语和多音字发音修正
-
支持文本内停顿与拉长音控制
-
支持示例库和参考音频库管理
-
提供本地 WebUI,适合中文用户直接使用
说明
-
精确时长控制是 `IndexTTS2` 的研究方向之一,但公开版并未完全开放所有原生时长控制能力。
-
当前项目中的"停顿"和"拉长音"功能,主要通过 WebUI 层的分段合成与后处理实现,适合实际使用,但并不等同于模型原生公开接口。
-
其中"停顿"效果相对稳定;"拉长音"当前更接近自然拖尾的近似控制,而不是严格意义上的模型原生延音。
-
如果对人声自然度要求较高,建议优先使用停顿控制,并把拉长音控制在较小范围内。
-
如果后续需要,还可以继续扩展更多文本控制简码,例如重音、弱读、局部变速等。
图片预览