
【新智元导读】Vidu Q3 带着「全家桶」重磅回归,视觉、听觉、场景能力全面进化。AI 视频的生产级交付时代,真的来了。
这个月初,谷歌一纸公告,把 Veo 3.1 的视频生成能力,免费开放给了所有谷歌账号。
可以说,这是 AI 视频史上的一个分水岭------
曾经一条 10 秒视频要烧掉数美金的「奢侈品」,正在被巨头硬生生做成「水电煤」。
但越是免费、越是普及,一个尴尬的问题就越藏不住:
模型可以无限趋近「能用」,可它和「能交付」之间,依然隔着一整条生产线。
榜单上的分数、demo 里的炫技、社交媒体上的爆款片段,全都换不来一个剧组、一支广告团队、一条电商内容流水线的稳定输出。
热闹归热闹,能用归能用,从来就是两件事。
而当大多数玩家还在卷免费、卷分辨率、卷画面时长时,一个被低估的中国玩家,悄悄把答案摆上了桌。
今天,Vidu Q3 带着「参考生」重磅回归。
作为全球公认的「参考生鼻祖」,这一次,它直接把「参考生」揉进一整套全家桶------
以 Vidu Q3 参考生模型为「核心底座」,Vidu SaaS(Vidu Agent、Vidu Claw)与 Vidu MaaS(Vidu AI 开放平台)全面接入。
其中 Vidu AI 开放平台,可 0 门槛接入、价格仅为行业平均水平的 1/3、切镜自然合理、生成速度快。
同时,它还支持提示词调优、工作流适配及专项培训服务,即便在高峰时段也能确保稳健输出。
以上三层加在一起,构成了一套完整的、可直接接入真实生产流水线的内容生产系统。
至此,Vidu Q3 已全面覆盖文生、图生、参考生三大领域,完成由单一模型向全场景视频生成方案的跨越。
正如 Slogan 所言,「为剧而生,万物可参」,Vidu 正在做一件其他玩家还顾不上做的事:把模型能力,焊死在真正的生产流程中。

「参考生之王」回归
直接拍戏了
要理解这件事的重要性,先把背景拎清楚。
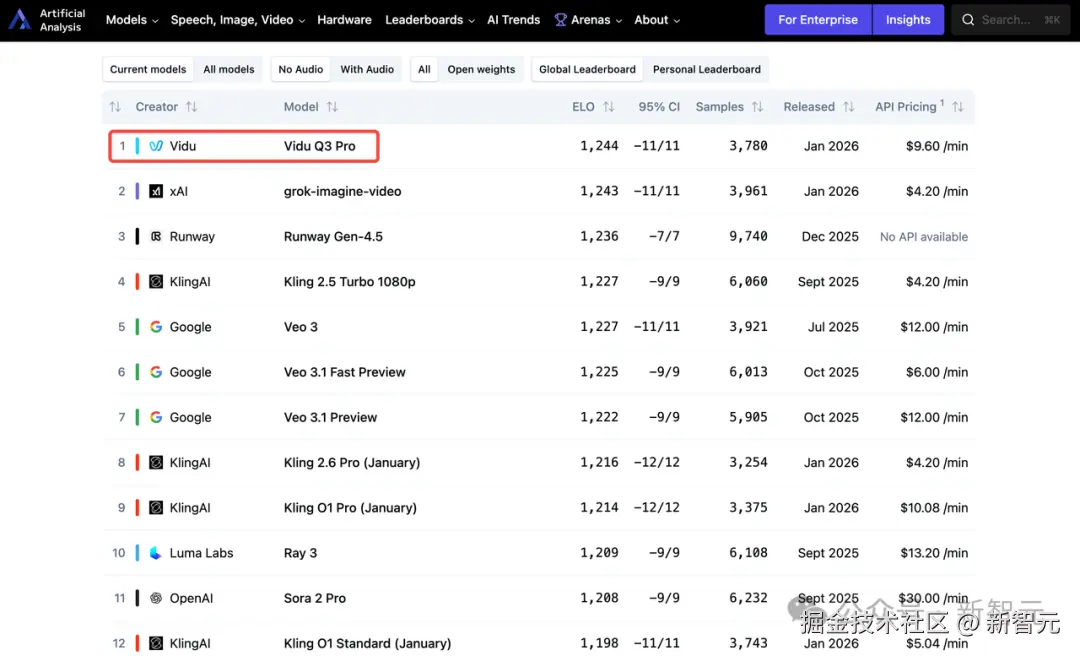
1 月 30 日,Vidu Q3 全球首发,在权威评测榜单 AA 上一骑绝尘,拿下了全球第一的成绩。
它一举超越了 Grok Imagine、Gen-4.5、谷歌 Veo3.1 等一众领先模型。
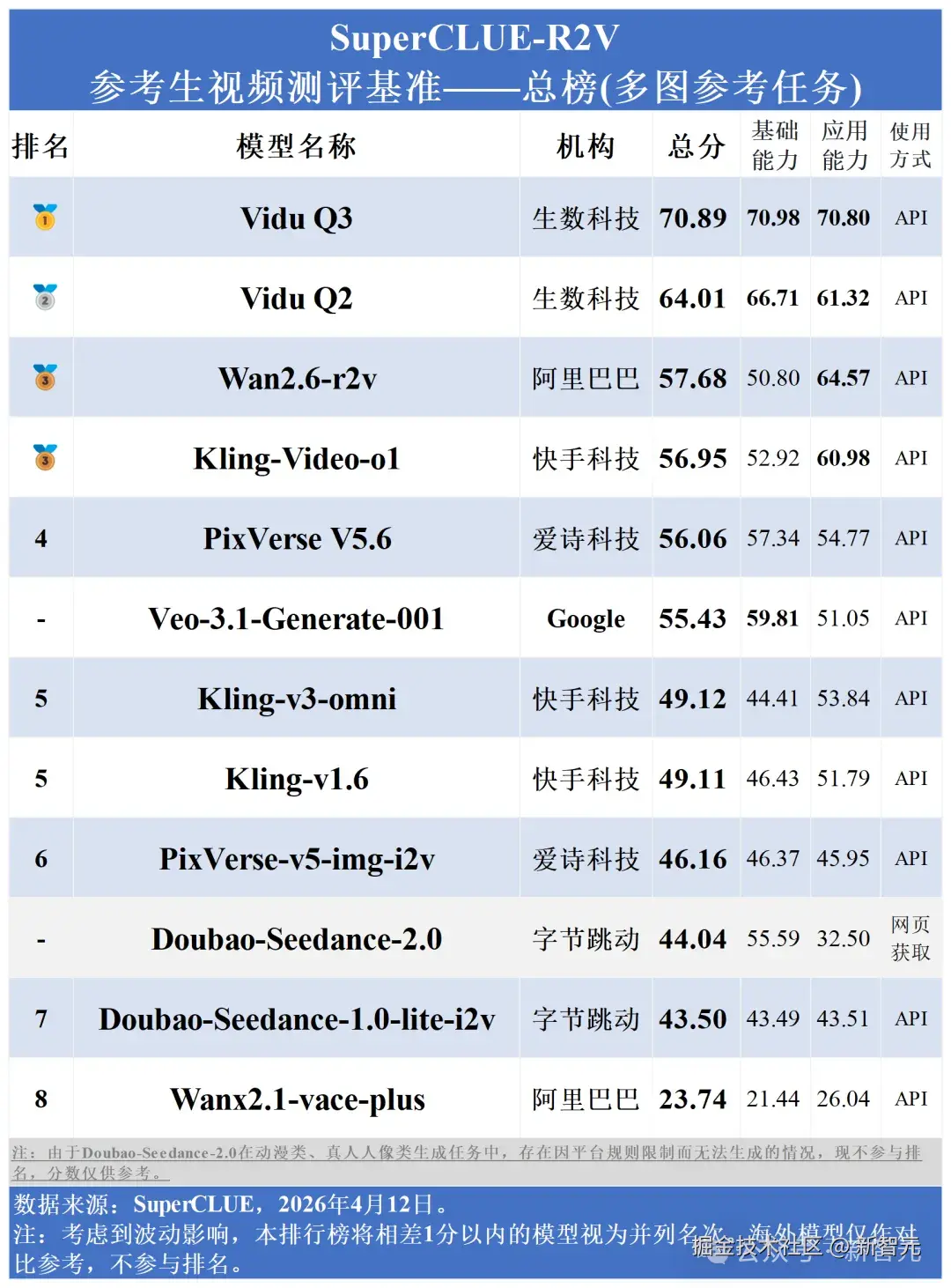
在全球首个参考生榜单,SuperClue 榜单上,Vidu Q3 断层登顶,在多图 / 单图参考任务蝉联双榜第一。
首次亮相,Vidu Q3 便主打「为剧而生」,成为全球首个声画直出 16 秒的 AI 视频模型。
事实上,整个 AI 视频行业的竞争焦点,正在悄悄发生一次根本性的位移。
视频大模型,正在从「生成画面」迈向「生成内容」。比拼的重点也从单点能力,转向两件更本质的事------
是否具备完整的叙事能力,以及,是否能进入真实场景的生产级交付。
这两件事,才是把 AI 视频从「技术 demo」推向「内容生产力」的真正分水岭。
Vidu Q3 的出世,恰恰被视为整个行业转变的阶段性节点------
从最早的「视频生成」,到 Q2 的「演技生成」,再到 Q3 真正具备「剧集生产能力」的叙事单元级跃迁。
每一步,Vidu 都踩在了行业演化的关节上。
而支撑这次跃迁的关键变量,正是 Vidu 一直握在手里的那张王牌------参考生。
在 AI 视频走向生产级交付的这条路上,「参考生」的角色正被彻底改写。
它不再只是一个提升画面一致性的工具能力,而正逐渐演变为一种可复用、可组合的内容生产范式。
作为全球「参考生」首创者,名副其实的「参考生之王」,这一次,Q3 直接把其从模型层推到了应用层。
这种巨变,直接体现在了漫剧、短剧、广告、影视剧等应用场景中的可用性和交付性。
换句话说,Vidu 让 AI 视频,真正具备了「剧」的表达能力,为剧而生。
万物可参,为「剧」而生,声画同出
在视觉、听觉和场景上, Vidu Q3 系统性升级,招招致命。
相较于上一代,Q3 不再执着于枯燥的「生成质量指标」(FID/FVD)比拼,而是死磕一个核心目标:让 AI 生成内容,真正具备「剧」的表达能力。
要知道,所谓的「剧集感」,是由无数个符合直觉的微小细节堆砌而成的。
Vidu Q3 在视觉、听觉与场景三个关键维度上,交出了一份令人「恐怖」的答卷。
在视觉方面,Vidu Q3 新增六大特效:粒子、流体、动力学、运镜、转场、光影,将其深度融入叙事语言,让生成内容更接近「成片级表达」。
五大沉浸式音效:环境、动态、氛围、拟音、情绪,让 Q3 赋予了 AI 视频「听觉上的叙事连续性」。
至此,声音不再是画面的附属,而是情绪的载体。
最重要的是,Q3 场景能力已进化为直接对齐工业流程的「内容单元」,大幅缩减从创意到成片的距离,覆盖了短剧、漫剧、影视剧、广告四大场景。
在这些领域,Vidu 不仅实现了极速生成与高频迭代,更通过极高的视觉稳定性,率先解决了 AI 创作中「角色一致性」的行业难题。
这种从点到面的全场景渗透,标志着 Vidu 已从技术验证期跨入深度产业应用期,建立了不可逾越的落地领先优势。
为了验证其真实战力,我们抛弃了传统的「跑分逻辑」,直接把 Vidu Q3 扔进更接近真实生产的内容场景里------
漫剧的高燃瞬间、短剧的情绪爆点、影视级的灾难与悬疑调度,以及广告的多元创意。
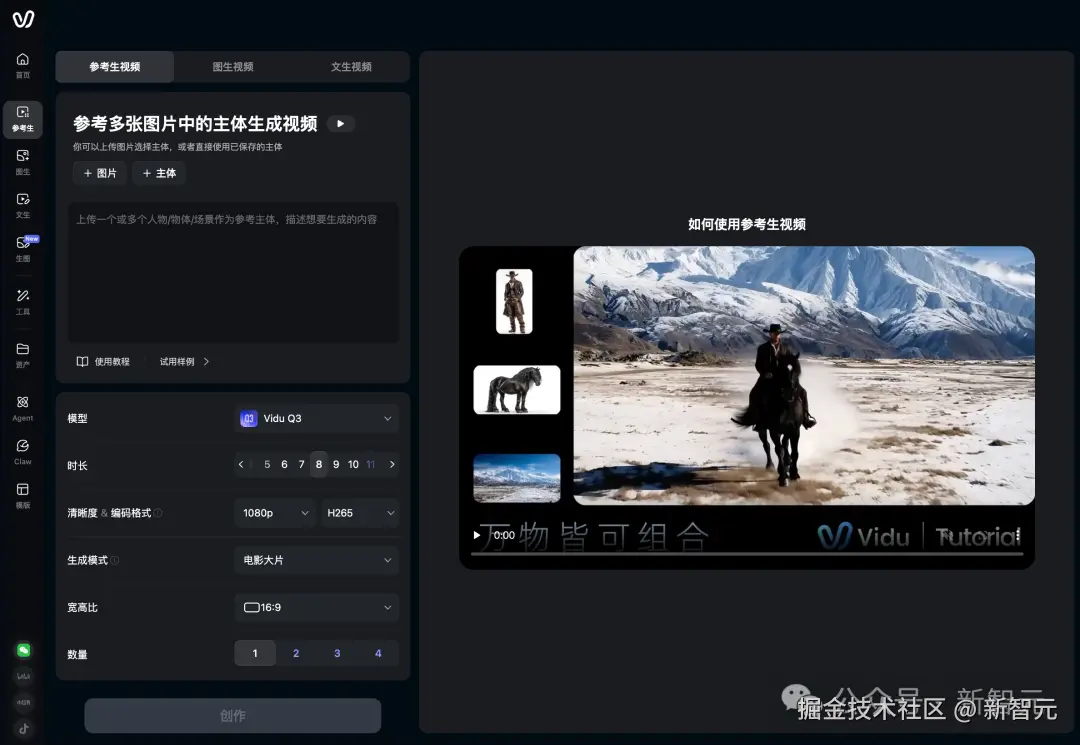
登陆 Vidu.cn 或 Vidu.API ,即可快速使用最新的 Q3「参考生」视频。
输入专属邀请码:XZYN3,登陆 Vidu.cn。注册即送 500 积分。
高燃漫剧
漫剧,是过去两年 AI 内容工业化跑得最快的赛道之一。
低成本、短周期、可批量生产,这些特性天然契合 AI 视频的能力边界。
但也正因为漫剧对「量」的极致追求,它把 AI 视频最致命的那块短板暴露得淋漓尽致------一致性。
一部大约 60 分钟的漫剧,每分钟三四十个镜头,每段 AI 生成的素材只有 5--10 秒。
这就意味着,整部剧是由上千段片段硬拼而成。
过去,AI 模型最大的问题,是每一张图之间彼此独立:人物的脸换了一点、服装纹样飘了一点、道具位置跳了一帧,观众瞬间出戏。
创作者在剪辑台前熬夜重抽素材的痛苦,几乎是整个行业的共同记忆。
一个能够支持批量生产与快速迭代、同时把主角、场景、道具死死锁住的模型,是漫剧工业化真正的分水岭。
丢给 Vidu Q3 一张红围巾校服少年的立绘,让它生成一个「热血少年觉醒变身」的短片。

结果令人震撼,狂风的怒吼、电流的尖啸、大地的碎裂声在这一秒疯狂交织、层层递进,将情绪推向了最顶峰。
最关键的突破点在于:复杂的特效变化下,男主形象始终如一。
总言之,Vidu Q3 在视觉、听觉与场景三个关键维度上,将四大场景的应用推向了新的高光时刻。
伟大的技术
最终都将隐形于无形
纵观科技史,任何一项伟大的技术,其最终的宿命都是「隐形」。
当电动机刚发明时,人们惊叹于电流的魔力;但当大工业时代到来时,电动机隐身于工厂的流水线中,人们只看到源源不断产出的精美商品。
今天的 AI 视频行业,正在经历同样的蜕变。
Vidu Q3 通过极尽复杂的底层算法攻坚,通过从 Q1 到 Q3 的艰难跋涉,换来的,恰恰是创作者极其简单的「为剧而生」。
它终结了那个需要靠算运气、抽盲盒才能得到一段好视频的时代;它把 AI 视频从猎奇者的「玩具箱」,搬到了专业创作者的「工作台」上。
「万物可参」,参考的不仅是现实世界的像素,更是人类无尽的想象力**。**
当你在 Vidu App 中敲下第一行剧本,当 Vidu Claw 为你自动生成第一组分镜,当 Vidu Q3 用它极具张力的音效和电影级的光影,把你脑海中那个原本只敢做梦的庞大宇宙完美呈现时,你会深刻地意识到:
不要用做盲盒的逻辑,去奢望大工业时代的轰鸣。
AI 视频的「前戏」已经结束,属于创作者的、由新质生产力驱动的「大航海时代」,在 Vidu Q3 按下回车键的那一刻,正式拉开了帷幕。
在这个充满无限可能的时代,最好的故事,不再受制于资本的傲慢与工业的繁琐。
最好的故事,才刚刚开始。
登陆 Vidu.cn 或 Vidu.API ,即可快速使用最新的 Q3「参考生」视频。
输入专属邀请码:XZYN3,登陆 Vidu.cn。注册即送 500 积分。
参考资料:
本文使用 markdown.com.cn 排版