KL散度是变分推断和信息论中的核心概念。
KL散度基础
KL散度(Kullback-Leibler Divergence) 衡量两个概率分布 PPP 和 QQQ 之间的差异,定义为:
DKL(P∥Q)=∫p(x)logp(x)q(x)dx=Ex∼Plogp(x)q(x)D_{KL}(P \parallel Q) = \int p(x) \log \frac{p(x)}{q(x)} dx = \mathbb{E}_{x \sim P}\left\\log \\frac{p(x)}{q(x)}\\rightDKL(P∥Q)=∫p(x)logq(x)p(x)dx=Ex∼Plogq(x)p(x)
KL散度不是对称的 :DKL(P∥Q)≠DKL(Q∥P)D_{KL}(P \parallel Q) \neq D_{KL}(Q \parallel P)DKL(P∥Q)=DKL(Q∥P),这引出了两种不同方向的变体。
1. 正向KL散度(Forward KL)
定义
DKL(P∥Q)=Ex∼Plogp(x)q(x)D_{KL}(P \parallel Q) = \mathbb{E}_{x \sim P}\left\\log \\frac{p(x)}{q(x)}\\rightDKL(P∥Q)=Ex∼Plogq(x)p(x)
别名
- Inclusive KL(包容性KL)
- Moment-matching(矩匹配)
- I-projection(信息投影)
核心特性
| 特性 | 说明 |
|---|---|
| 期望采样 | 从真实分布 PPP 采样 |
| 优化目标 | 在 PPP 有质量的地方,QQQ 必须有质量 |
| 零避免 | P(x)>0P(x) > 0P(x)>0 时,要求 Q(x)>0Q(x) > 0Q(x)>0 |
| 行为模式 | 覆盖模式(Covering Mode) |
- 这意味着 Q 必须覆盖所有 P 有概率的区域【mass-covering 】,不能漏掉任何模式【zero-avoiding】,否则 KL散度就会无限大。
- 反过来对于P(x)=0但Q(x)>0的区域,正向KL惩罚很小。所以 Q 可以在 P 支撑集外随意取值,只要不牺牲对 P 内部的拟合。
直观理解
正向KL要求 QQQ 覆盖 PPP 的所有支持区域。如果 PPP 在某处有概率质量,QQQ 也必须在那里有质量,否则会产生无穷大的惩罚(logp0=∞\log \frac{p}{0} = \inftylog0p=∞)。
变分推断中的应用
在变分自编码器(VAE)的标准形式中使用:
LELBO=Eq(z∣x)logp(x∣z)−DKL(q(z∣x)∥p(z))\mathcal{L}{ELBO} = \mathbb{E}{q(z|x)}\\log p(x\|z) - D_{KL}(q(z|x) \parallel p(z))LELBO=Eq(z∣x)logp(x∣z)−DKL(q(z∣x)∥p(z))
这里用正向KL约束后验 q(z∣x)q(z|x)q(z∣x) 接近先验 p(z)p(z)p(z),导致 q(z∣x)q(z|x)q(z∣x) 倾向于覆盖先验的全部区域。正向 KL 散度具有"zero forcing"的特性,这种逼近方式对于模型外推性要求高的任务非常重要。
2. 反向KL散度(Reverse KL)
定义
DKL(Q∥P)=Ex∼Qlogq(x)p(x)D_{KL}(Q \parallel P) = \mathbb{E}_{x \sim Q}\left\\log \\frac{q(x)}{p(x)}\\rightDKL(Q∥P)=Ex∼Qlogp(x)q(x)
别名
- Exclusive KL(排他性KL)
- Mode-seeking(模态寻找)
- M-projection(矩投影)
核心特性
| 特性 | 说明 |
|---|---|
| 期望采样 | 从近似分布 QQQ 采样 |
| 优化目标 | 在 QQQ 有质量的地方,PPP 必须有质量 |
| 零允许 | QQQ 可以在 PPP 为零的地方为零 |
| 行为模式 | 模态寻找模式(Mode-Seeking Mode) |
- zero-forcing 特性:它会强迫 Q 在 P 概率密度低的地方取零值,从而 Q 的支撑集是 P 支撑集的子集。这对于外推性要求高的任务非常重要,因为模型不会在未见过的输入区域随意给出高概率(避免过度自信的外推)。
- 外推性要求高的任务(例如在训练数据分布之外进行预测,如物理模拟、风险建模、序列预测等)需要模型保持保守:当输入远离训练数据时,模型应该输出低置信度或接近先验,而不是给出高概率的猜测。
- 如果使用 mass-covering(正向 KL,覆盖所有模式),近似分布 Q 会在 P 的支撑集外也分配一些概率,这可能导致在外推区域给出非零甚至较大的概率值,造成"过度外推"。
- 如果使用 zero-forcing(反向 KL),Q 在 P 概率极低的区域会被强迫置零,因此对于训练分布以外的输入,模型会输出非常低的概率(或高不确定性)。这符合安全外推的需求:不知道就是不知道,不要瞎猜。
直观理解
反向KL允许 QQQ 忽略 PPP 的某些模态。只要 QQQ 放置质量的地方 PPP 也有质量即可,QQQ 可以只拟合 PPP 的某一个或几个主要模态。
典型应用
- 生成对抗网络(GAN) :隐式最小化 DKL(pdata∥pmodel)D_{KL}(p_{data} \parallel p_{model})DKL(pdata∥pmodel) 的变体
- 变分推断中的IWAE:重要性加权自编码器
- 强化学习:策略优化中的TRPO/PPO算法
3. 对称KL散度(Symmetric KL / Jeffreys Divergence)
定义
为了克服KL散度的不对称性,定义对称版本:
J(P,Q)=DKL(P∥Q)+DKL(Q∥P)\mathcal{J}(P, Q) = D_{KL}(P \parallel Q) + D_{KL}(Q \parallel P)J(P,Q)=DKL(P∥Q)+DKL(Q∥P)
=∫(p(x)−q(x))logp(x)q(x)dx= \int (p(x) - q(x)) \log \frac{p(x)}{q(x)} dx=∫(p(x)−q(x))logq(x)p(x)dx
别名
- Jeffreys散度(Jeffreys Divergence)
- J散度
- 双向KL
核心特性
| 特性 | 说明 |
|---|---|
| 对称性 | J(P,Q)=J(Q,P)\mathcal{J}(P, Q) = \mathcal{J}(Q, P)J(P,Q)=J(Q,P) ✓ |
| 惩罚强度 | 对差异的双向惩罚 |
| 数学形式 | 结合了覆盖和模态寻找的特性 |
| 计算成本 | 需要计算两个方向的KL |
应用场景
- 统计检验:作为距离度量更公平
- 分布对齐:需要双向约束的任务
- 最优传输:与Wasserstein距离的替代方案
三种KL散度的对比图示
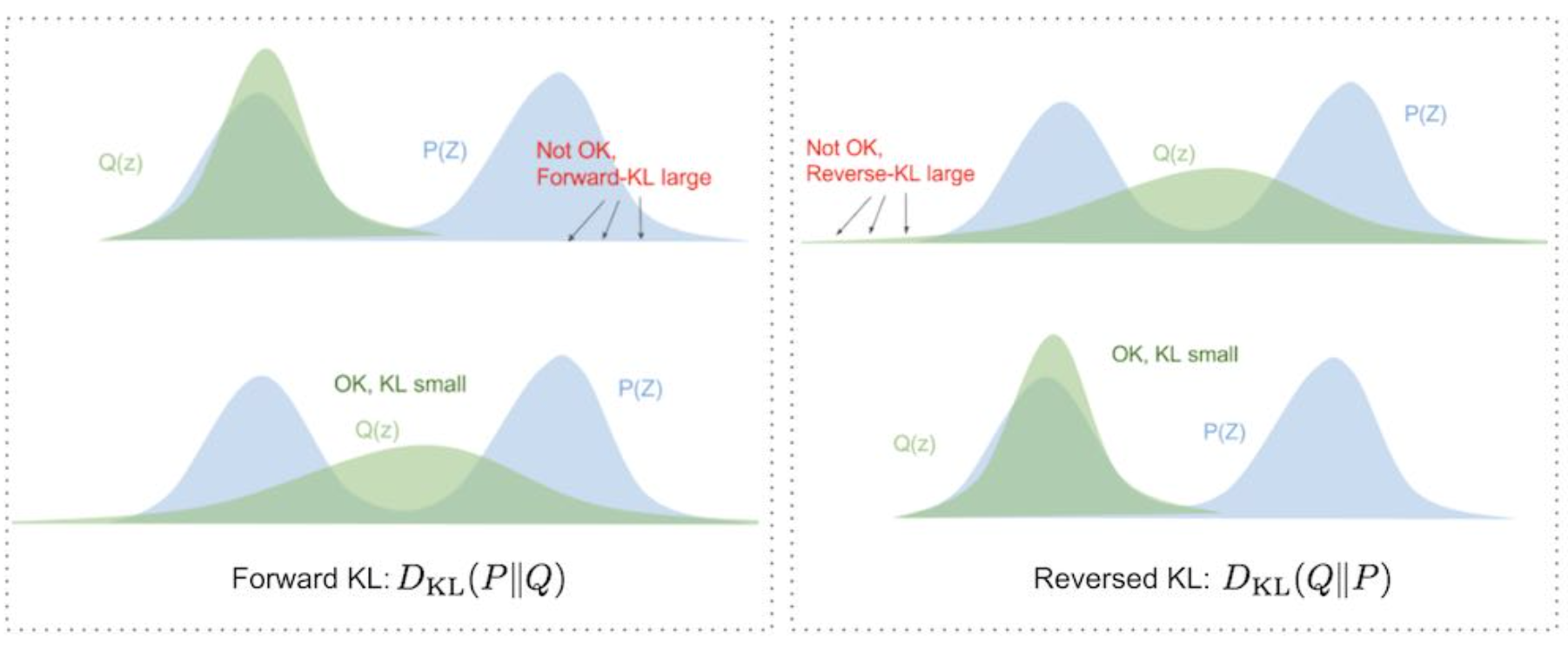
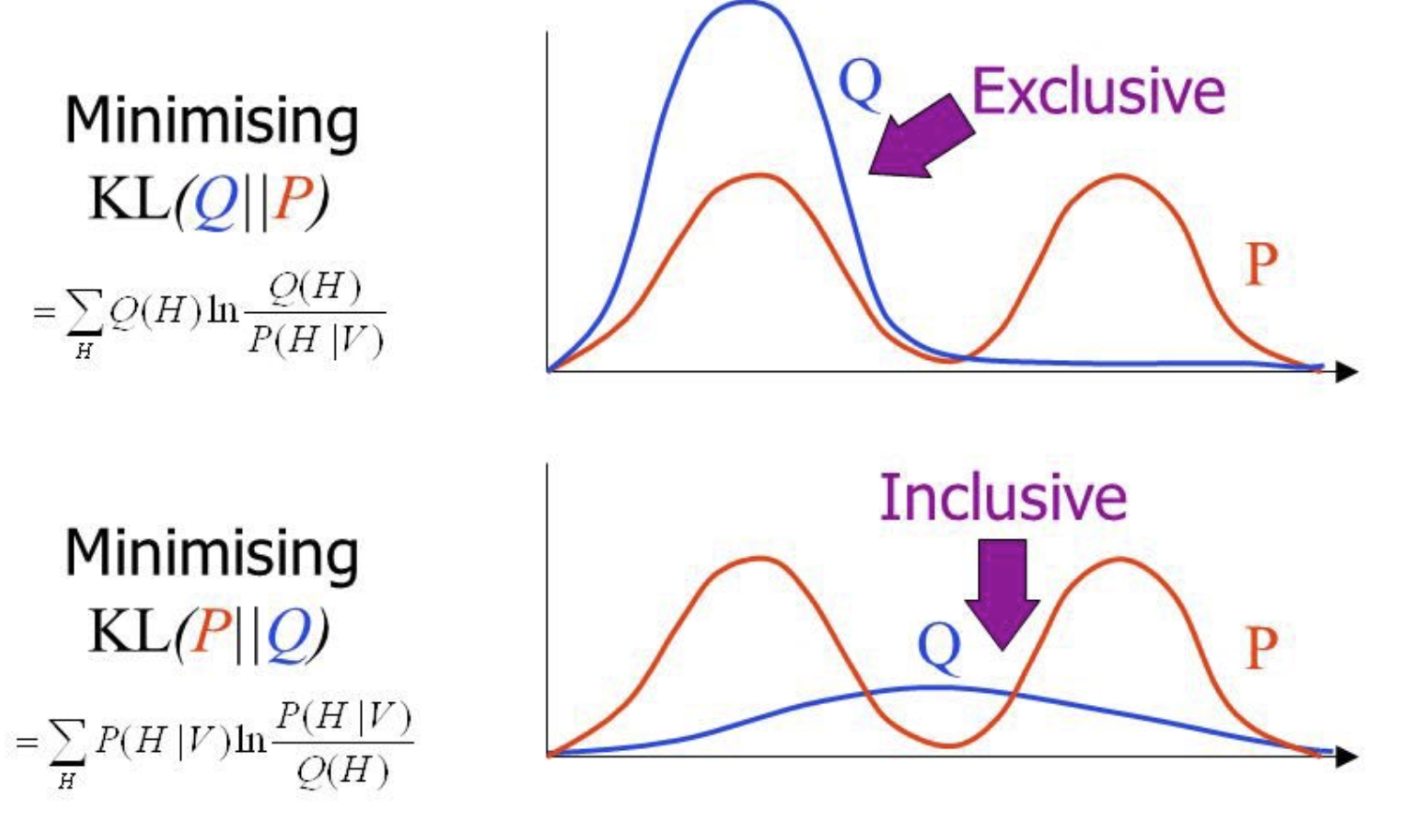
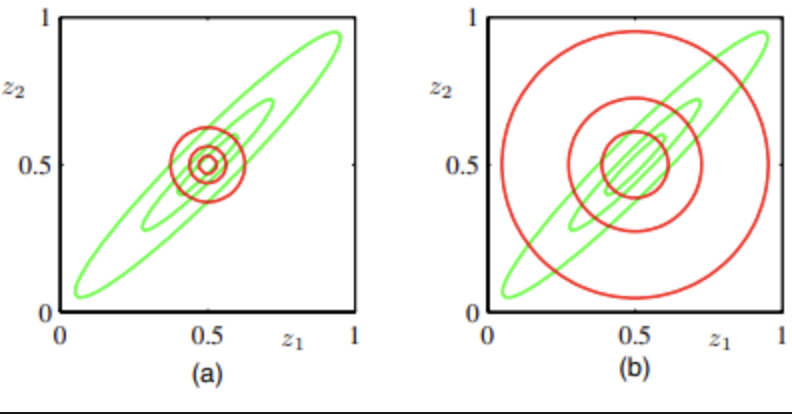
- 左:反向KL,右:正向KL
VAE用正向KL → 潜在空间要覆盖所有可能的编码
GAN用反向KL → 生成器只关注生成最逼真的样本(一个模态)
关键差异总结
| 维度 | 正向KL DKL(P∥Q)D_{KL}(P\parallel Q)DKL(P∥Q) | 反向KL DKL(Q∥P)D_{KL}(Q\parallel P)DKL(Q∥P) | 对称KL J(P,Q)\mathcal{J}(P,Q)J(P,Q) |
|---|---|---|---|
| 采样来源 | 真实分布 PPP | 近似分布 QQQ | 两者都需要 |
| 零惩罚 | QQQ 不能为零(P>0P>0P>0处) | PPP 不能为零(Q>0Q>0Q>0处) | 双向约束 |
| 典型行为 | 覆盖所有模态 | 锁定单一模态 | 折中方案 |
| 方差特性 | 高估方差 | 低估方差 | 适中估计 |
| 优化难度 | 通常更易优化 | 可能更稳定 | 计算成本高 |
| 主要应用 | VAE, 变分推断 | GAN, 模式寻找 | 统计距离度量 |
实际选择指南
- 需要完整分布表示 → 使用正向KL(如VAE的潜在空间学习)
- 需要高质量样本 → 使用反向KL(如GAN生成清晰图像)
- 需要公平距离度量 → 使用对称KL 或考虑Wasserstein距离
- 多模态分布 → 正向KL避免模态坍塌,反向KL可能丢失模态
这三种KL散度的选择直接决定了概率模型是追求全面覆盖 还是精确拟合,是生成模型和推断算法设计的核心考量。
附录:补充信息
变分推断
变分推断是一种用于近似复杂概率模型中无法直接计算的后验分布 的机器学习方法。当我们根据观测数据去推断未知变量(比如模型参数)的概率分布时,根据贝叶斯公式,这个后验分布的计算往往涉及高维积分,在数学上难以处理或计算量极大。变分推断的做法是,从一组已知的、简单的分布族中,挑选一个最接近真实后验分布的分布来作为近似。
它的核心思想可以概括为三步:
1.设定一个候选分布族(比如高斯分布族)。这个分布族形式上简单、易于计算。
2.定义一个衡量两个分布接近程度的指标。通常使用KL散度(Kullback-Leibler divergence),它衡量了候选分布与真实后验分布之间的差异。
3.通过优化找到最优候选分布。调整候选分布的参数,使其与真实后验分布的KL散度最小化。这个优化过程通常利用证据下界来间接进行。