开篇:那个让我意识到问题的早晨
4月初,一个普通的周一。
我在飞书看到一条消息,切到浏览器查资料,切回来复制粘贴给卷卷,等它回复,再把结论贴回飞书。
整个过程:7次切换,4次复制粘贴,2分钟。
我突然停下来想:
我在用一个 AI,还是在给 AI 打下手?
工具链没打通,AI 再强也是孤岛。
第一课:什么叫工具链协同
单工具用法:
我 → 卷卷 → 我工具链用法:
飞书消息 → 卷卷 → 飞书文档
GitHub PR → 卷卷 → Review 评论
日历事件 → 卷卷 → 会议纪要 → 飞书区别在哪?
信息自己流动,我只做决策。
第二课:飞书深度集成
我的痛点
每天早上:
- 飞书有 30 条消息
- 有 5 个文档需要更新
- 有 3 个会议需要纪要
以前:全部手动。现在:卷卷处理 80%。
配置思路
在 AGENTS.md 里加一个飞书专属 Agent:
## FeishuAgent
### 职责
- 监听飞书消息,识别需要处理的任务
- 自动生成会议纪要并写入飞书文档
- 定时推送日报到指定群
### 触发条件
- 关键词:「帮我整理」「生成纪要」「写到文档」
- 定时:每天 18:00 生成日报
### 权限
- 读:消息、日历、文档
- 写:文档、群消息(需确认)实际效果
会议结束后,我说一句:「整理一下今天的会议」
卷卷自动:
- 拉取会议录音转写
- 提取关键决策和 Action Item
- 写入飞书文档
- @相关人确认
以前 30 分钟,现在 3 分钟。
第三课:GitHub 集成
我的痛点
代码 Review 是我最烦的事。
不是不想做,是太费时间。一个 PR 少则 200 行,多则 2000 行。
配置方式
## CodeReviewAgent
### 触发
- 新 PR 创建
- PR 更新
### 流程
1. 拉取 diff
2. 先跑 linter(规范问题不用 AI)
3. 只把有疑问的部分给 AI 分析
4. 生成 Review 评论,标注严重程度
5. 自动回复到 PR
### 模型路由
- 格式问题:跳过 AI
- 逻辑问题:claude-sonnet
- 安全问题:gpt-4(不省这个钱)真实数据
接入前:每个 PR 平均花 25 分钟 接入后:我只看卷卷标注的「需要人工确认」部分,平均 8 分钟
节省 68% 的 Review 时间。
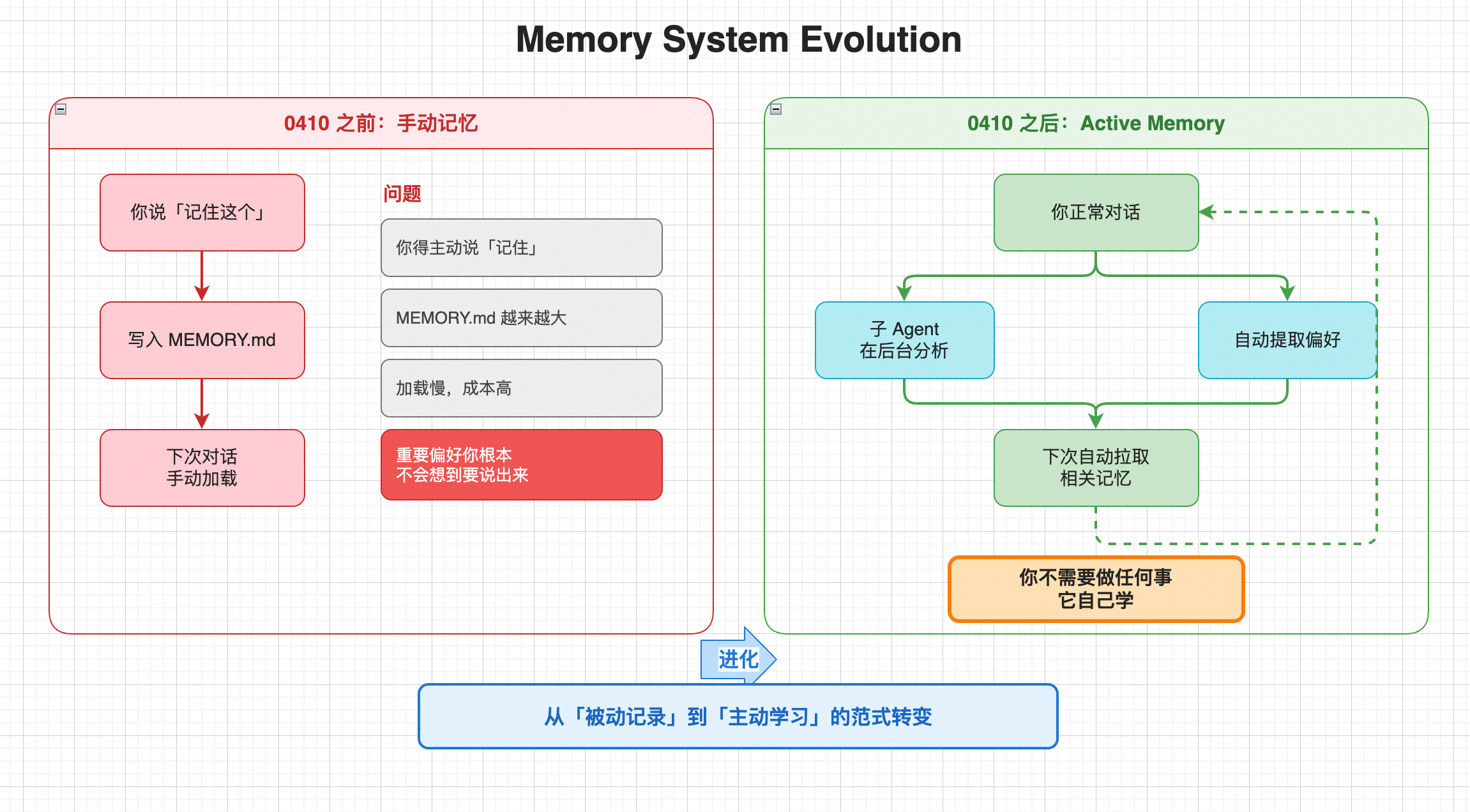
第四课:结合 0410 新功能------Active Memory
0410 版本上线了一个我等了很久的功能:Active Memory 插件。
以前的问题:
我告诉卷卷「我不喜欢太长的回复」,它记住了。 下次新对话,又忘了。 我得重新说一遍。
Active Memory 解决了这个问题。
它怎么工作
你说话 → Active Memory 子 Agent 自动检索相关偏好 → 注入当前对话不需要你手动说「记住这个」。 不需要每次对话都贴一遍 USER.md。
它在后台自动做了。
我的配置
在 MEMORY.md 里,我现在只保留结构化的偏好标签:
## 偏好标签
- 回复长度:简洁,不超过 200 字
- 代码风格:Python,加注释
- 日报格式:bullet points,不超过 5 条
- 会议纪要:只要决策和 Action,不要过程Active Memory 会自动在合适的时候拉取这些标签。
MEMORY.md 从 47KB 瘦身到 8KB,但卷卷记住的东西反而更准了。
第五课:结合 0410 新功能------macOS Talk 模式
0410 上线了本地 MLX 语音提供商。
我用了一周,说说真实感受。
适合的场景
开车时:「卷卷,帮我把刚才的想法整理成一条 MEMORY」 走路时:「今天下午 3 点的会议,提醒我提前 15 分钟」 双手占用时:「把这个任务加到今天的 TODO」
不适合的场景
复杂的技术讨论------还是打字更精确。 需要粘贴代码的时候------语音没法传代码。
一个小技巧
语音 + 文字混用:
用语音说需求,卷卷理解后,我再用文字补充细节。
语音负责「说清楚要什么」,文字负责「说清楚怎么做」。
第六课:我的完整工具链配置图
输入层
├── 飞书消息 → FeishuAgent
├── GitHub PR → CodeReviewAgent
├── 语音输入 → Talk 模式
└── 直接对话 → 主 Agent
处理层(卷卷)
├── Active Memory 自动拉取偏好
├── 任务路由到对应 Agent
├── 模型路由(按复杂度选模型)
└── 成本监控(上一篇讲的)
输出层
├── 飞书文档
├── GitHub 评论
├── 日历提醒
└── 直接回复整个链路,我只需要在「输入」和「决策」两个环节出现。
第七课:打通工具链的三个原则
原则1:数据只流动一次
信息从 A 到 B,不要经过我的手。 我的手一碰,就会出错,就会延迟。
原则2:人只做判断,不做搬运
搬运信息是机器的事。 判断对不对是人的事。
原则3:先打通高频场景
不要一次接入所有工具。
我的顺序:
- 飞书(每天用 50 次)
- GitHub(每天用 10 次)
- 日历(每天用 5 次)
- 其他(按需)
先把最高频的打通,ROI 最高。
写在最后
三个月前,我把卷卷当聊天工具用。
现在,它是我工作流的一部分。
区别不在于卷卷变聪明了。
区别在于:我把它放到了正确的位置上。
工具链不是技术问题,是设计问题。
你得想清楚:信息从哪来,到哪去,谁来决策。
想清楚了,接入很简单。
工具链配置检查清单
飞书集成
- FeishuAgent 配置完成
- 消息监听关键词设置
- 文档写入权限确认
- 日报定时推送测试
GitHub 集成
- CodeReviewAgent 配置完成
- linter 规则配置
- 模型路由规则设置
- PR 评论格式确认
Active Memory
- 插件已启用
- MEMORY.md 改为结构化标签格式
- 偏好标签整理完成
- 测试自动拉取是否准确
语音模式(macOS)
- MLX 语音提供商配置
- 常用语音指令测试
- fallback 语音确认
下一篇预告
《Active Memory 深度玩法------让卷卷真正「认识」你》
- Active Memory 的底层机制
- 怎么设计让它记得准的偏好标签
- 记忆分层:短期 / 长期 / 永久
- 我的 MEMORY.md 完整模板
记忆,是 AI 从工具变成伙伴的关键。