常量的定义
#define 宏常量
通常在代码最上面定义,表示一个常量
#define 常量名 常量值
#ifndef
其通常为搭配#define使用,用以检查某个宏是否未被定义,若未定义则编译后续代码,直到#endif或#else。
const关键字
const修饰的变量
通常在定义变量前面加入const
const 数据类型 常量名 = 常量值
上述定义的两种方式,当你在后续的代码中再次给同一变量赋值,那么程序会报错
const修饰函数
使用const类修饰的函 数只能是类中的成员函数,其又如下特性:
1、const是函数签名的一部分,同名、同参数的
const版本和非const版本构成合法重载。2、函数内部禁止修改类的非静态、非
mutable成员变量,哪怕是无意的修改,编译器也会直接报错。3、函数内部只能调用其他
const成员函数,禁止调用非const成员函数(防止间接修改对象)。4、非const对象优先调用非
const版本,无对应版本时,可兼容调用const版本。
对于函数加不加const的议论
简单来说只要同时满足语法上不修改非 mutable 成员同时业务上不改变核心状态,就必须加 const。
非mutable成员表示类中没有被mutable关键字修饰的非静态成员变量。
左值和右值
左值:有名字、可以取地址的对象(比如变量
x)右值:没名字、不能取地址的临时对象(比如
10、x+5、返回值的临时对象)
关键字
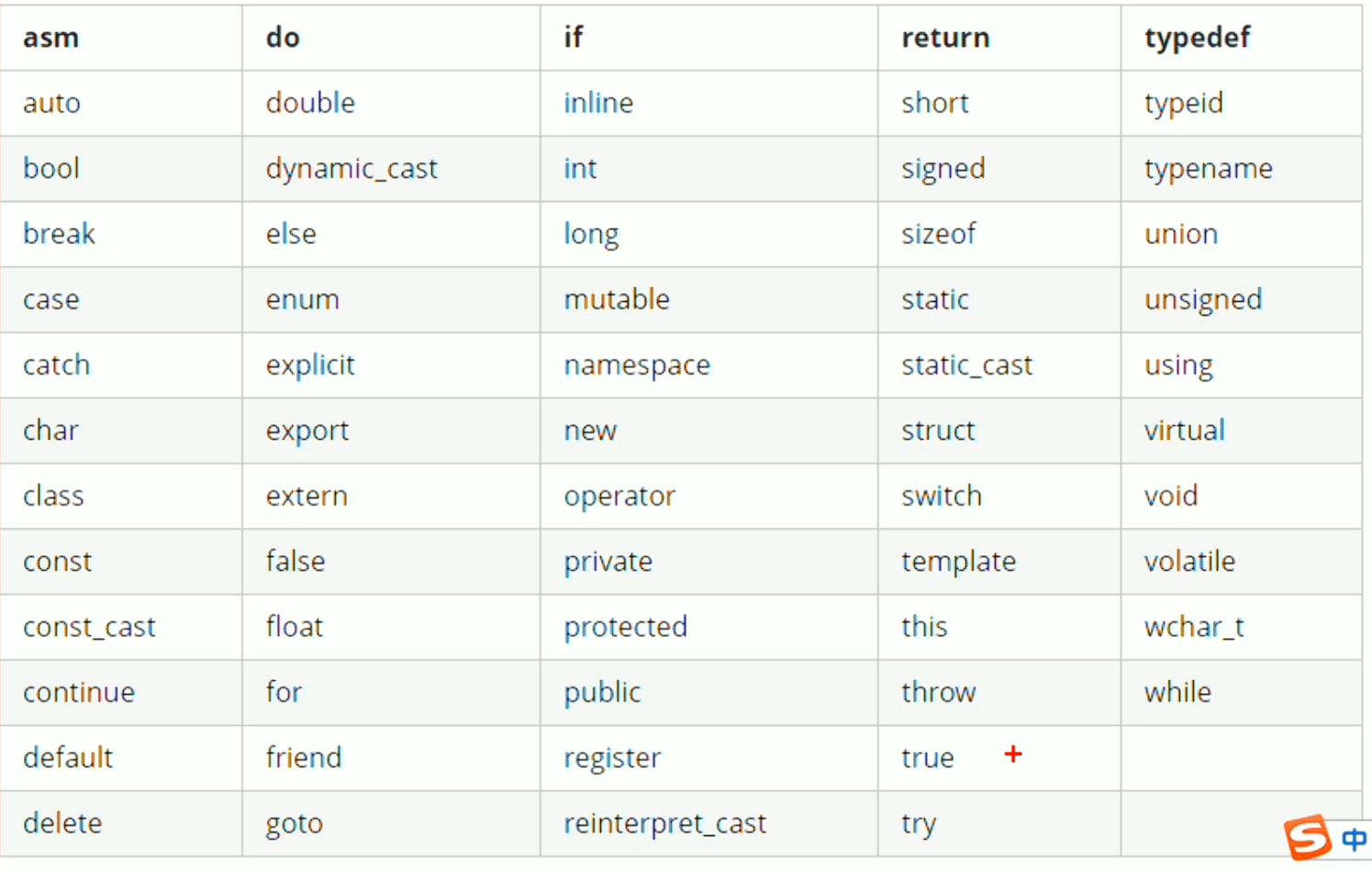
类型别名
类型别名是一个名字,它是某种类型的同义词。使用类型别名让复杂的类型名字变得简单明了、易于理解和使用,还有助于程序员清楚地知道使用该类型的真实目的。
关键字定义--typedef
class Fraction { ····· }; int main(){ typedef Fraction F; F f(3, 5); return 0; }
别名声明--using
class Fraction { ····· }; using F = Fraction; int main(){ F f(3, 5); return 0; }
数据类型
整数
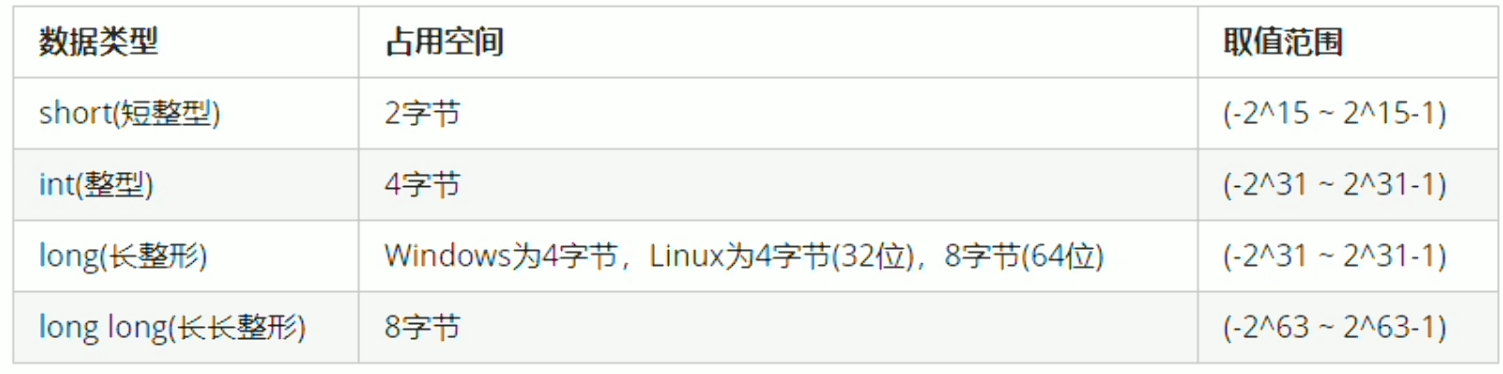
在short、long、long long后面添加int,其程序无误
判断输入是否为整数
bool isInt(int p) {
// 检查输入是否失败
while (cin.fail()) {
// 重置错误状态标志
cin.clear();
// 清空输入缓冲区中剩余的错误字符
cin.ignore(numeric_limits<streamsize>::max(), '\n');
return false;
}
return true;
}如上述代码,一共需要进行三步,检查是否错误,重置状态,然后清空缓冲区。
cin.fail()用于检测标准输入流
cin是否处于错误状态,典型场景如目标变量为int却输入了字符串等类型不匹配的情况。错误发生后:
cin的错误标志位会被置位;
导致错误的输入数据会残留在输入缓冲区中;
目标变量可能未被成功赋值(或按规则设为默认值,如
int可能为 0)。因此若不先重置错误标志位,cin将无法继续执行后续输入操作;若同时不清理缓冲区,残留的错误数据会导致后续读取持续失败。
浮点数
单精度--float
双精度--double

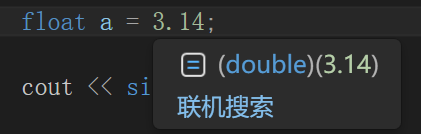
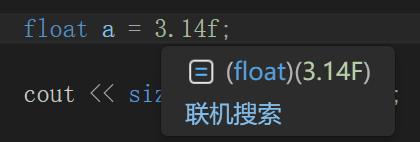
在书写代码时,系统一般默认加了小数点的数为双精度(double),即便前面定义的是float
但是其在后续会通过前面的关键字float将a的数据类型转化为float,因此为了避免这个不必要的转化,一般可以在使用float定义后加入一个f,其结果都是一样的。
同时对于浮点数来说,系统默认显示为6为有效数字(尽管float和double都保存有不止6为的有效数字)。
字符型
char
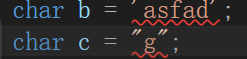
字符型内部接收变量时只接收单引号的字符变量,其变量所占内存为1,同时单引号里面也只能有一个字母
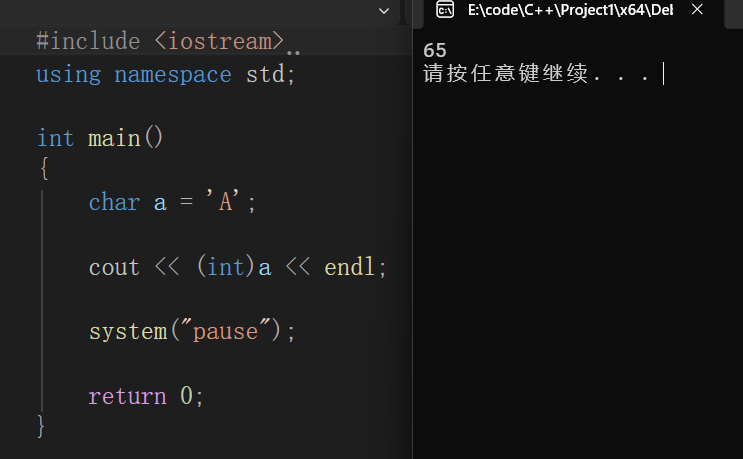
同时其在内存中储存时通过AC码进行保存的,要查看则在输出中加入(int)
其中A--65,a--97
字符串
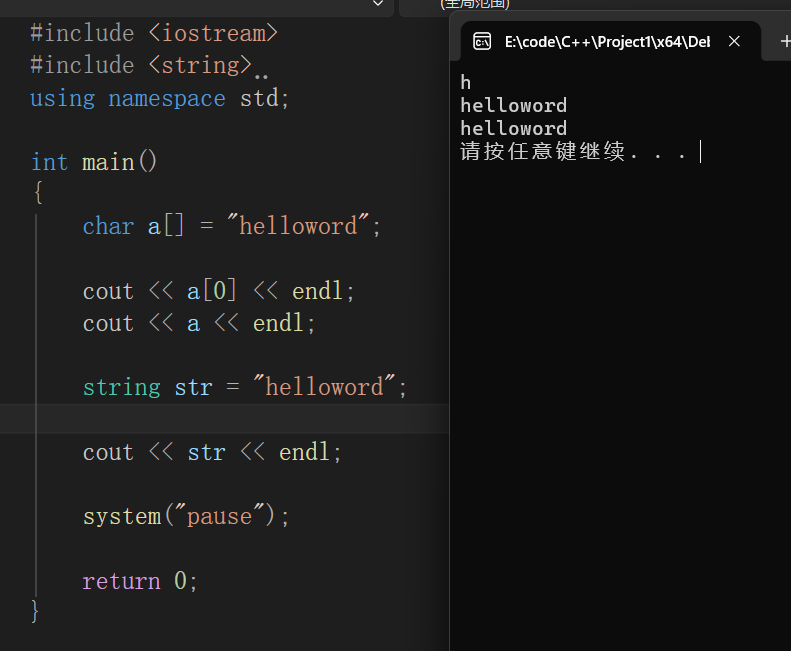
char 变量名\[\] = "字符串值"
string 变量名 = "字符串值"
两种命名方式后续都需要使用双引号"",与上面的字符类型相区别
第一种类型在变量后需要添加中括号\[\],如果没有添加则表示字符类型
第二种类型更加常用,但是在前面需要添加一个头文件库<string>
类型截断--单引号与char之间的关系
int main()
{
char str1[2];
str1[0] = 'str';
cout << "The string is: " << str1[0] << endl;
system("pause");
return 0;
}如上述代码,该定义为一个字符型数组,传入的str却是字符串,但是传入str的又是单引号,单引号只能包裹一个字符(如'a','1'),但这里的单引号却包含了一个字符串,这看起来是要报错,但是结果却正确运行了,同时输出了r。
这是因为多字符类型传入编译器后都是int类型,即AC码,而非char,这是代码的强制规定:单引号里超过 1 个字符,它的类型自动变成int。
同时我们都知道int占4个字节,而char占1个字节,因此这便出现了类型截断,编译器会自动舍弃前面的3个字节,从而将'str'中最后一位字符赋值给str10,从而输出r。即便你赋值的不止4位如st10='asfagagaa',编译器会将前面的全部舍弃,只保留最后四个字符(4个字节),然后再将其转化为AC码,转化为char时触发类型截断,再次保留最后一位a。
中文字符与英文字符的区别
int main()
{
char str1[] = "阿斯弗;啊方法";
cout << "The string is: " << str1[6] << endl;
system("pause");
return 0;
}如上面的代码,该代码会输出;,但是如果输出str1其他位的元素,则不会输出任何东西。
这是因为再GBK编码下,中文默认占2个字符,而英文则占一个字符,因此其实str1中在str0、str1中共同储存着'阿'这个字,从而导致只输出一位的元素而终端没有任何印刷。
宽字符
如果确实想要通过字符来访问中文,那么就需要使用宽字符或专门的字符串库。
#include <iostream>
#include <windows.h>
#include <fcntl.h>
#include <io.h>
int main() {
// 将标准输出设置为 UTF-16 宽字符模式
_setmode(_fileno(stdout), _O_U16TEXT);
// 使用宽字符数组 wchar_t 和宽字符串 L
wchar_t str1[] = L"阿斯弗;啊方法";
// 输出第 1 个字符(索引 0):'阿'
std::wcout << L"The string is: " << str1[0] << std::endl;
// 输出第 4 个字符(索引 3):';'
std::wcout << L"The 4th char is: " << str1[3] << std::endl;
system("pause");
return 0;
}字符型的增添
字符型的本质就是一个char类型的指针,其返回的是这个char类型的地址,当你要对字符型进行增添操作时,需要自定义一个匿名对象
string pm = "ABCDEFGHIJKL"; for (for i = 0; i < string.size(); i++) { string p = string("玩家") + pm[num]; }如上述代码,直接书写"玩家"这一变量,其最后得到的是char数据类型,而不是string,因此需要在"玩家"前面增加一个string类型的强转换。
布尔型
bool 变量名 = true/false
true/false不能大写,必须全部小写
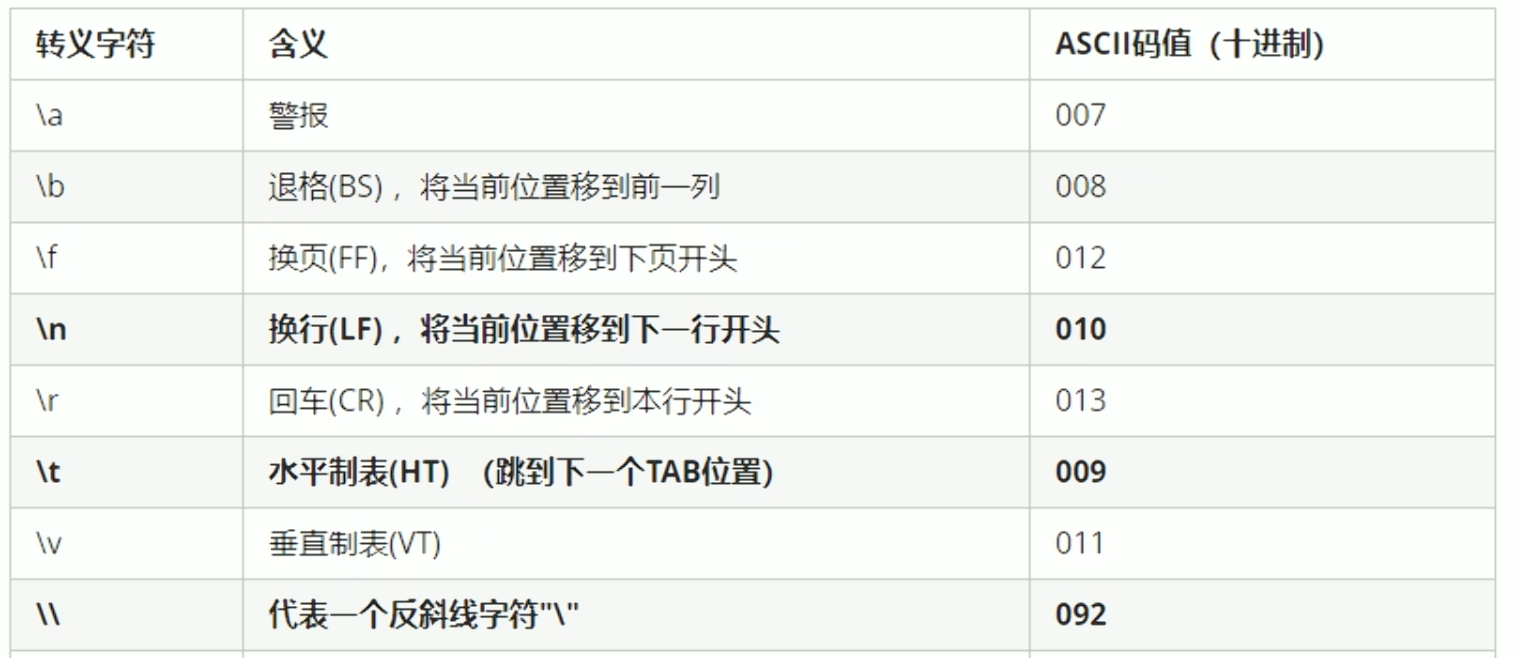
转义字符

数组
一维数组
数据中所有的元素都是同一个数据类型

int socre[10];
int socre[10] = {99, 80};
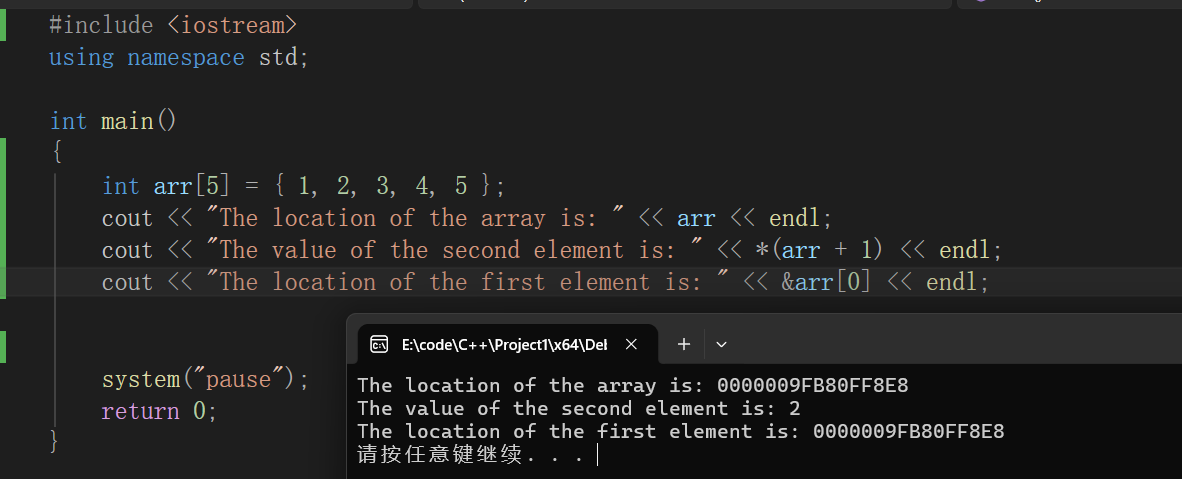
int socre[] = {99 ,80};查看一维数组、元素地址并利用指针反求元素
直接输出数组名即可
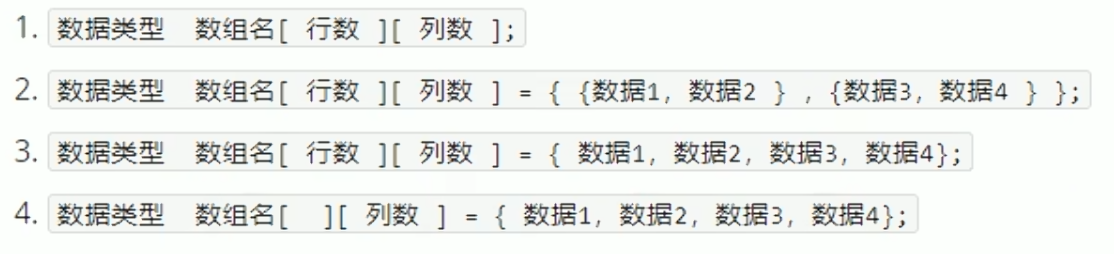
二维数组
数组的传入
指针传入
数组名作为参数时,会退化为指向数组首元素的指针,因此必须额外传一个大小参数,否则函数不知道数组有多长。
这样传入较为灵活,但是不够安全,且丢失了数组的 "大小信息"。
#include <iostream> // 参数 arr 实际上是 int*,size 是数组长度 void printArray(int arr[], int size) { for (int i = 0; i < size; i++) { std::cout << arr[i] << " "; } std::cout << std::endl; } int main() { int nums[] = {1, 2, 3, 4, 5}; int len = sizeof(nums) / sizeof(nums[0]); printArray(nums, len); return 0; }
引用传入
如果想让函数只接受固定大小的数组,并保留数组的大小信息,可以传数组的引用。
如上述,这样传入十分安全且有数组的大小信息,但是只能传输固定大小的数组。
#include <iostream> void printArray(int (&arr)[5]) { int size = sizeof(arr) / sizeof(arr[0]); for (int i = 0; i < size; ++i) { std::cout << arr[i] << " "; } std::cout << std::endl; } int main() { int nums[] = {1, 2, 3, 4, 5}; printArray(nums); return 0; }
模板化传入
结合模板,可以让函数接受任意类型、任意大小的数组,同时保留大小信息。
将为通用,同时类型安全,也含有数组的大小,但是会生成多个函数实例,增加代码的阅读难度。
#include <iostream> template <typename T, int N> void printArray(const T (&arr)[N]) { for (int i = 0; i < N; ++i) { std::cout << arr[i] << " "; } std::cout << std::endl; } int main() { int nums[] = {1, 2, 3, 4, 5}; double doubles[] = {1.1, 2.2, 3.3}; printArray(nums); // 自动推导 T=int, N=5 printArray(doubles); // 自动推导 T=double, N=3 return 0; }
STL库中vector函数
vector动态数组比原生数组更安全、更易用。
这是现代c++最为常用的数组编写和传入。
#include <iostream> #include <vector> // 传引用(避免拷贝),如果不修改内容,建议加 const void printVector(const std::vector<int>& vec) { for (int num : vec) { std::cout << num << " "; } std::cout << std::endl; } int main() { std::vector<int> nums = {1, 2, 3, 4, 5}; printVector(nums); // 直接传,不用管大小 return 0; }
模板实现vector函数
template<typename T> class myArray { private: T* Arrayaddress; int len; int size; public: myArray(int len) { cout << "构造函数" << endl; this->len = len; this->size = 0; this->Arrayaddress = new T[len]; } myArray(const myArray& arr) { cout << "拷贝函数" << endl; this->len = arr.len; this->size = arr.size; //不能直接使用new T(*arr.Arrayaddress)来进行深拷贝 //因为Arrayaddress为数组,单个对象则可以 this->Arrayaddress = new T[arr.len]; for (int i = 0;i < arr.size;i++) { this->Arrayaddress[i] = arr.Arrayaddress[i]; } } myArray& operator=(const myArray& arr) { cout << "operator=函数" << endl; //自赋值判断 if (this == &arr) { return *this; } //数组是否为空判断 if (this->Arrayaddress != NULL) { delete[] this->Arrayaddress; this->Arrayaddress = NULL; } this->len = arr.len; this->size = arr.size; this->Arrayaddress = new T[arr.len]; for (int i = 0;i < arr.size;i++) { this->Arrayaddress[i] = arr.Arrayaddress[i]; } return *this; } myArray& save_data(T data[], int data_size) { if (data_size + this->size > this->len) { cout << "容量不足,请重新创建数组,剩余容量" << (this->len - this->size) << endl; return *this; } for (int i = 0; i < data_size; i++) { this->Arrayaddress[i + this->size] = data[i]; } this->size += data_size; return *this; } myArray& delete_fin_data() { if (this->size == 0) { cout << "数组已空,无法删除尾元素" << endl; return *this; } this->size--; return *this; } myArray& delete_data(int index) { //需要注意index是从0开始算的 if (index < 0 || index >= this->size) { cout << "传入下标错误" << endl; return *this; } //牢记size比索引大1 //如果i<size,在i=size-1时,i+1=size,而size大于索引,导致越界 for (int i = index;i < (this->size -1);i++) { this->Arrayaddress[i] = this->Arrayaddress[i + 1]; } this->size--; return *this; } myArray& add_data(const T data, int index) { //需要注意index是从0开始算的 //但我们可以在size+1的地方,也就是数组的结尾部分添加值 if (index < 0 || index > this->size) { cout << "传入下标错误" << endl; return *this; } else if (this->size + 1 > this->len) { cout << "容量不足,请重新创建数组,剩余容量" << (this->len - this->size) << endl; return *this; } for (int i = this->size;i > index;i--) { this->Arrayaddress[i] = this->Arrayaddress[i - 1]; } this->Arrayaddress[index] = data; //由于索引多一个0,因此size本身就比数组的索引大1 //故而在对最后一个元素添加时,会造成越界问题 this->size++; return *this; } T& operator[](int index) { if (index < 0 || index >= this->size) { cout << "传入下标错误" << endl; return; } cout << "数组中第" << index << "个元素为:" << this->Arrayaddress[index] << endl; return this->Arrayaddress[index]; } int get_size() { return this->size; } int get_len() { return this->len; } ~myArray() { for (int i = 0; i < this->size; i++) { cout << this->Arrayaddress[i] << endl; } //不要忘了Arrayaddress为数组,要在delete后面添加[] delete[] this->Arrayaddress; this->Arrayaddress = nullptr; } };
存入不同类型的数据
存任意类型--std::any
#include <any> std::any arr[] = { 10, 3.14, "hello", 'A' };
指定允许存放类型--std::variant
#include <variant> using MyType = std::variant<int, double, string, char>; MyType arr[] = { 10, 3.14, "hello" };
多态实现
class Base {}; class Int : public Base {}; class Str : public Base {}; Base* arr[] = { new Int, new Str };
数据类型相关关键字
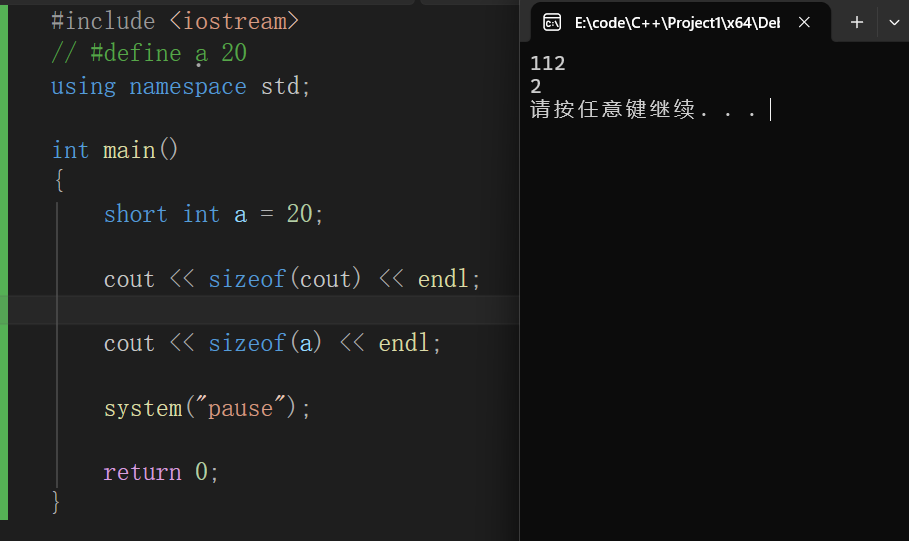
统计数据类型所占内存的大小--sizeof
sizeof()--内部可以是变量和关键字,单位为字节
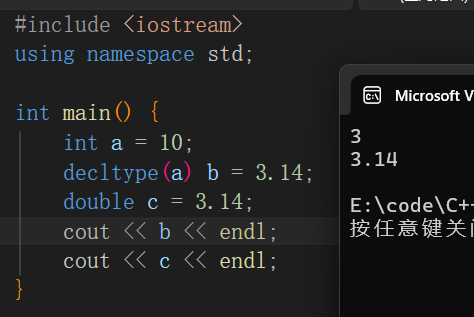
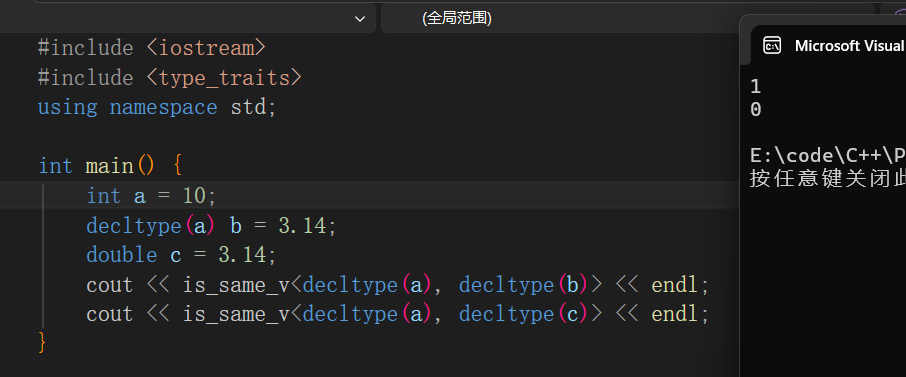
获取类型本身--decltype
该关键字不可以用以判断或者输出,是直接拿到变量类型的关键字,一般用于定义新变量。
判断两个变量类型是否相同--is_same_v
该关键字是<type_traits>库中的,其只能用来判断
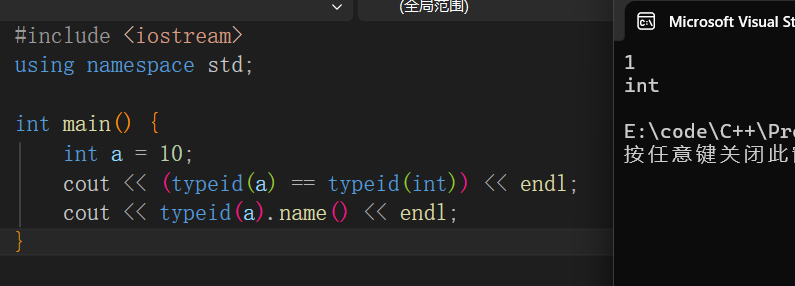
获取变量/表达式的类型信息--typeid
输出类型的名字--typeid(a).name()
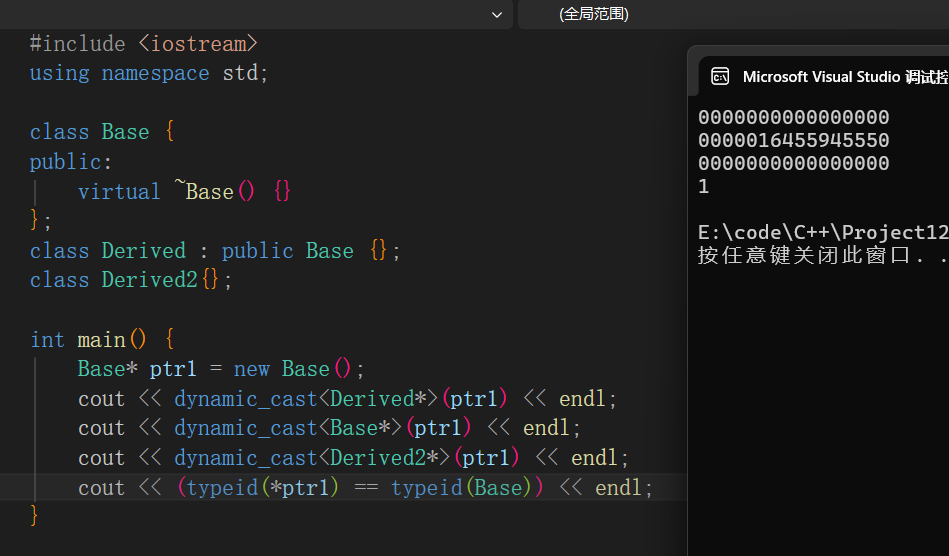
判断多态对象--typeid或dynamic_cast
dynamic_cast<目标类型*>(指针)
dynamic_cast输出的是多态的地址,当其输出为nullptr,则表示该元素类型不为该多态类型,可以直接放进if中判断。
强制转化类型--static_cast
int a = 10; a = static_cast<double>(a);
运算符
算术运算符
^表示异或运算符,而非次方
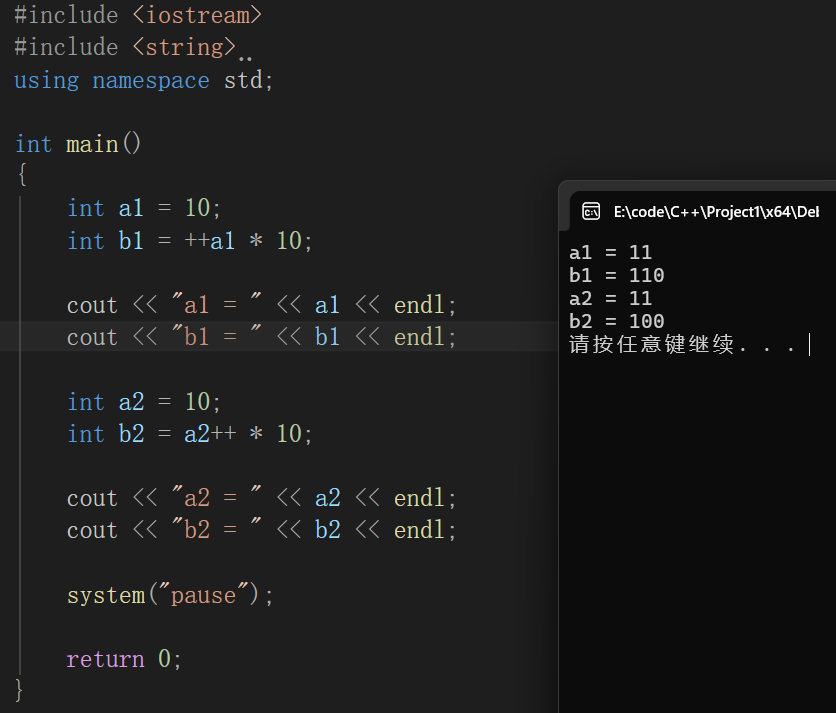
前置递增
a=2;b=++a;------->a=3;b=3;
后置递增
a=2;b=a++;------->a=3;b=2;
前置递减
a=2;b=--a;------->a=1;b=1;
后置递减
a=2;b=a--;------->a=1;b=2;
前置:先加/减1,再进行表达式运算
后置:先进行表达式运算,再加/减1
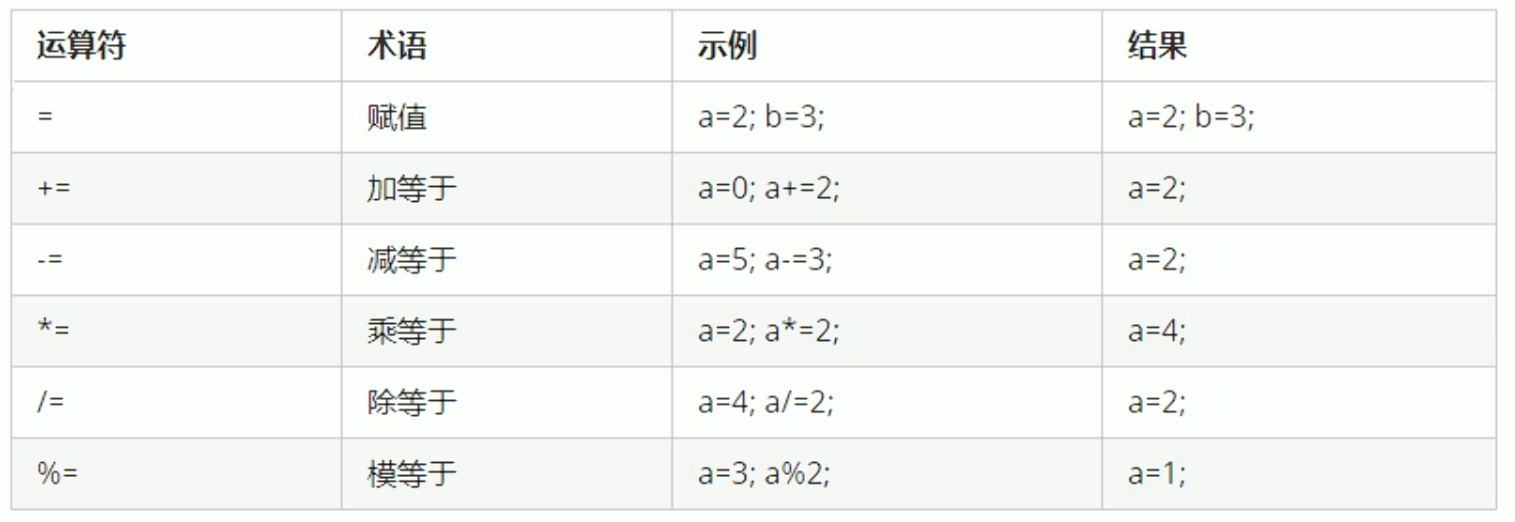
赋值运算符
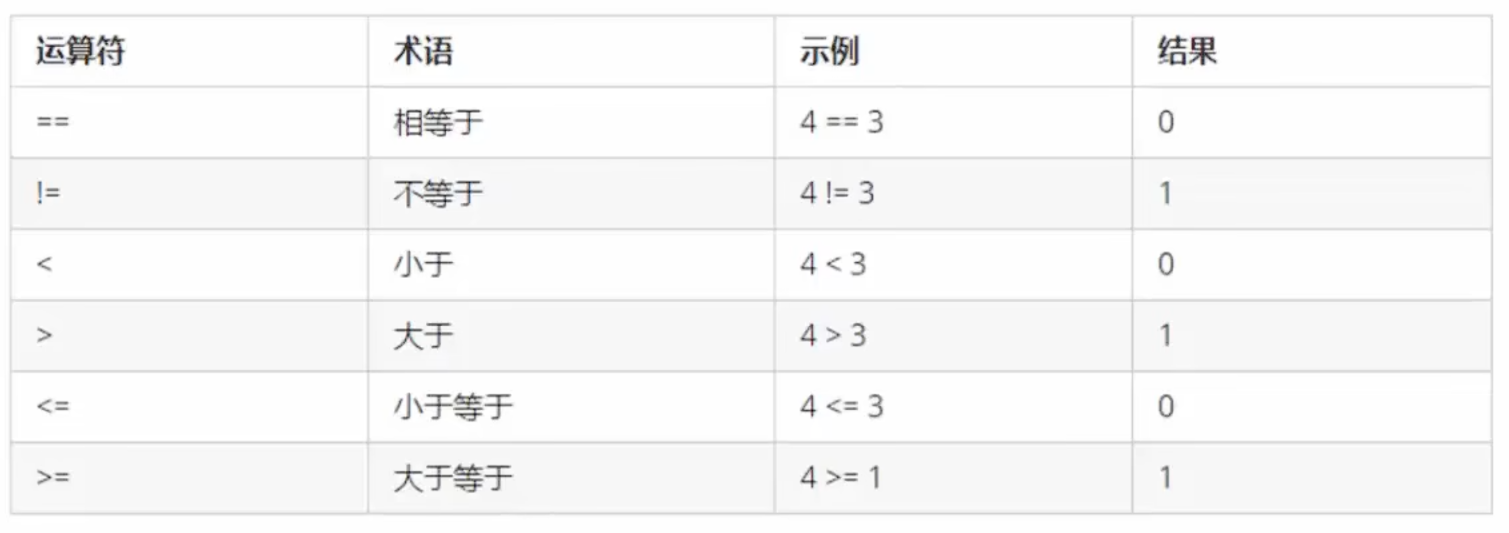
比较运算符
逻辑运算符

选择结构
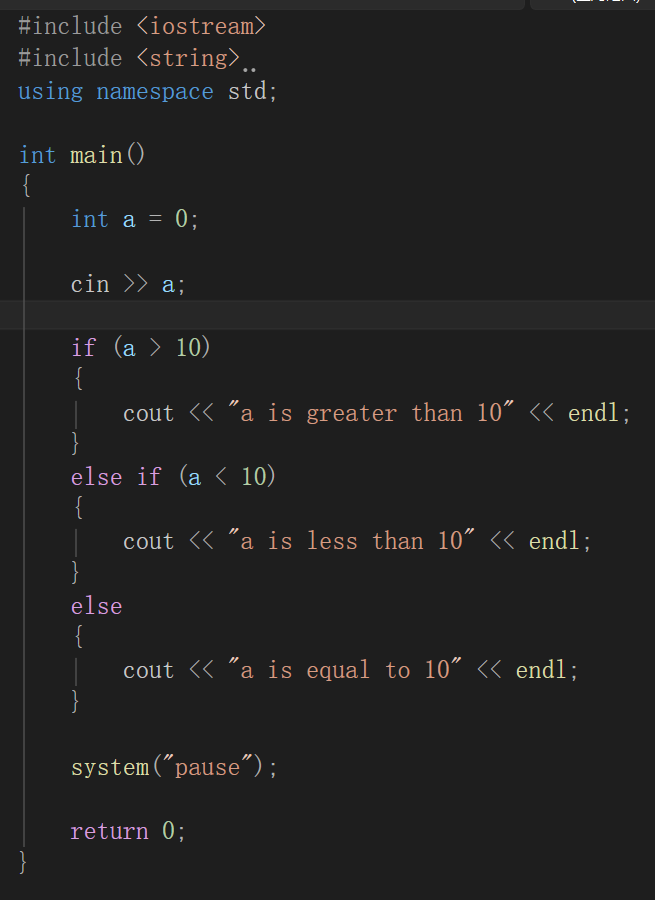
多行选择--if-else if-else
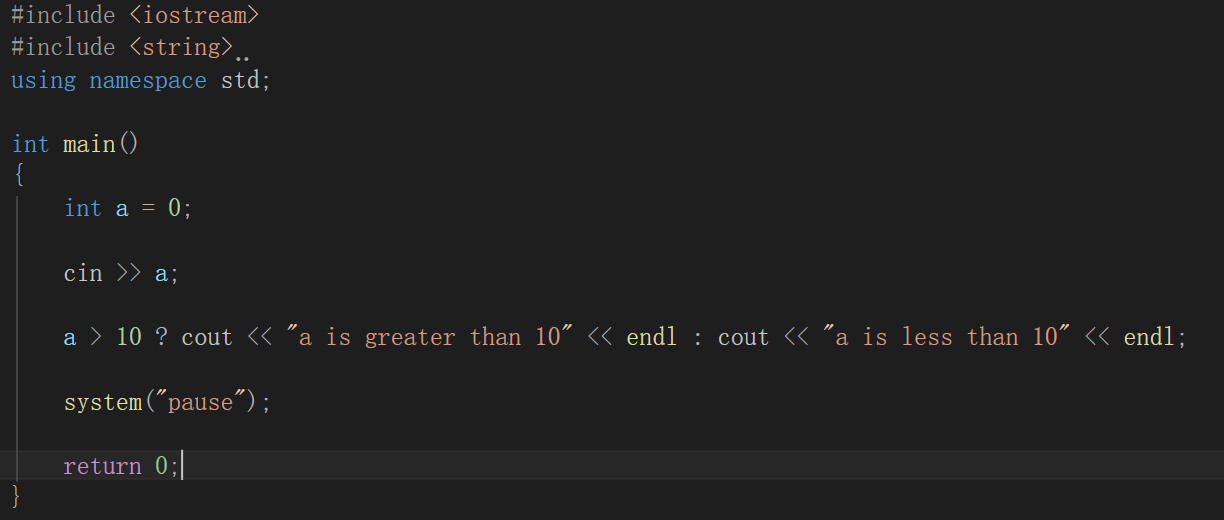
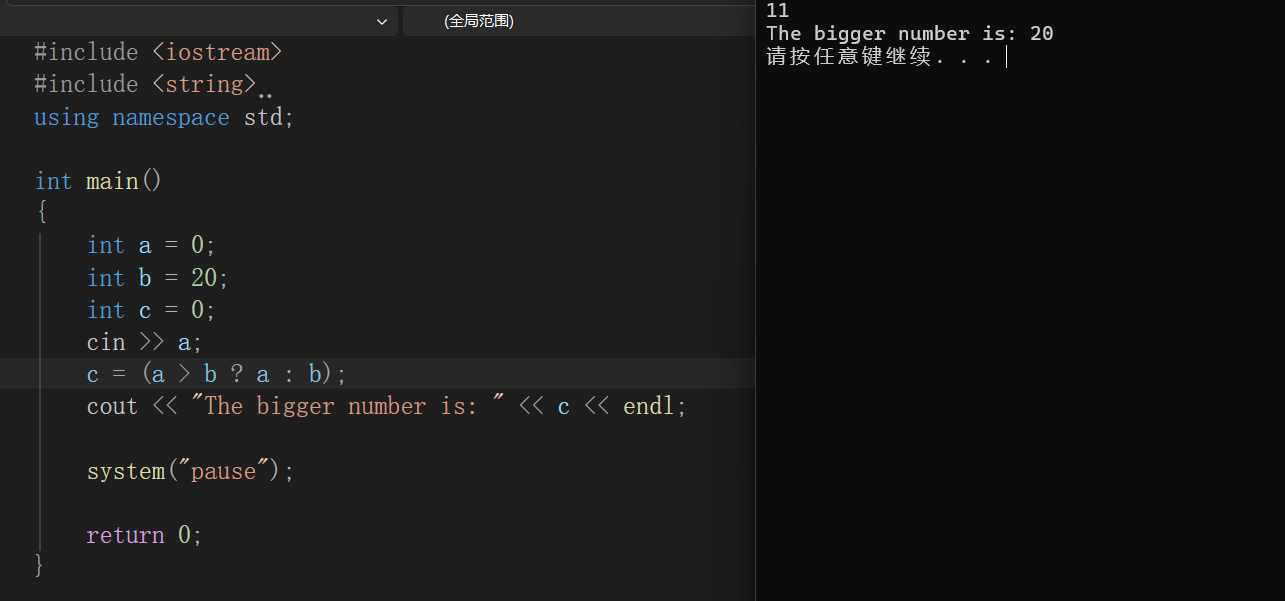
三目运算符
表达式1 ? 表达式2 : 表达式3
如果表达式1的值为真,执行表达式2,并返回表达式2的结果
如果表达式1的值为假,执行表达式3,并返回表达式3的结果
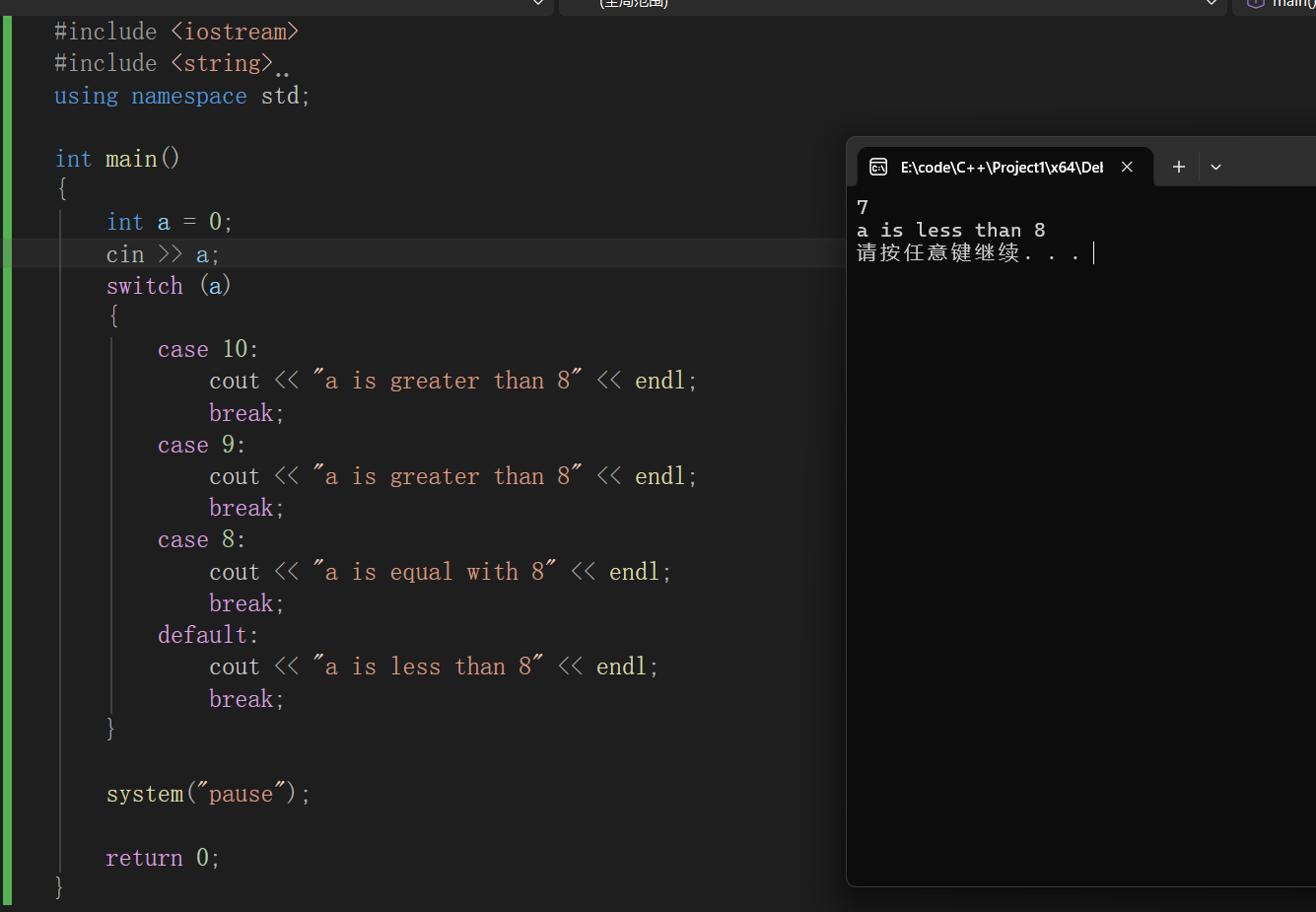
多条件--switch-case-default
循环结构
while循环
while (循环条件) {循环语句}
#include <iostream> using namespace std; int main() { int num = 0; cout << "Enter a number: " << endl; cin >> num; int num1 = 10; int count = 0; while (num != num1) { count++; cout << "Enter a new number: " << endl; cin >> num1; // 判断输入的数字是否合法 // 如果输入的数字不合法,提示用户重新输入 // 判断输入的数字与目标数字的关系 if (num == num1) { cout << "Good! The numbers are the same." << endl; } else if (num > num1){ cout << "Small. Please try again." << endl; } else { cout << "Big. Please try again." << endl; } } cout << "Congratulations! You found the number in " << count << " tries." << endl; system("pause"); return 0; }就上述代码而言,当你给num输入为一个字符时,num会接受你给的字符,然后将其转化为整数(int),但是当输入为字符时,系统便会出现一直重复一句话的情况。
这是因为字符无法转化为整数,因此cin函数内部会报错,但是这个报错不会提示而影响函数的运行,仅仅只是返回一个bool类型的false即0,也就是说目前的num为0。
如果刚好num1最开始的赋值也为0,那么函数便不会进入while循环,但是如果num1不为0(如上),那么就进入循环,进入循环后,依次执行前面两句代码,在第三句代码中卡住,然后直接跳过。
cin >> num1;这是因为cin的缓存区仍然保持者之前传入的字符,在调用cin时,系统会读取缓存区的值,从而导致cin函数无法使用,进而程序便直接跳过了这句代码,向下执行,这时num=0,num=10,程序无法跑出while循环,导致其一直输出"Big. Please try again."
do...while循环
do{循环语句}while(循环条件)
for循环
for(起始表达式;条件表达式;末尾表达式)(循环语句;)
程序流程结构
break--跳出
continue--继续
goto--跳转
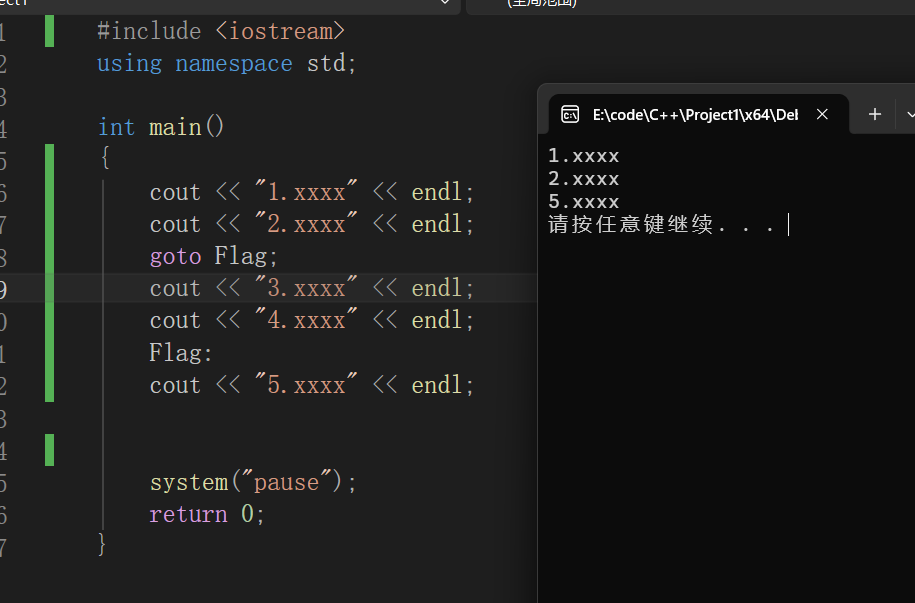
作用域
作用域即是变量在代码中的有效活动范围,其中以花括号({})作为起始和结束标志。在作用域结束后,其中的变量全部销毁,同时作用域中一定要避免起相同名字。
void test(int a) { // int a = 10; // 报错!参数 a 已经在函数作用域里了 } int main() { int i = 10; // int i = 20; // 编译报错! // 同一个 main 的 {} 里,不能定义两个都叫 i 的变量 double j = 3.14; int j = 5; // 也报错!哪怕类型不同,名字一样也不行 return 0; }
嵌套作用域
最为经典的便是for循环中嵌套一个for循环(冒泡排序),外部的作用域和内部的作用域也属于两个不同的作用域。
int main() { int i = 100; // 外层 main 的 {} cout << "外层的i: " << i << endl; // 输出 100 { // 内层嵌套的 {} int i = 200; // 可以定义同名变量 cout << "内层的i: " << i << endl; // 输出 200 } cout << "回到外层的i: " << i << endl; // 输出 100(内层的 i 已经销毁了) return 0; }
函数
定义
返回值类型 函数名 (参数列表){
函数体语句
return表达式
}
函数返回值
万能指针返回--void*
void*可以接受任何类型的数据地址,但是拿到void*后必须强转回原来的类型才可以读写数据
class func{}; void* test(){ return new func; } func* f = (func*)test();
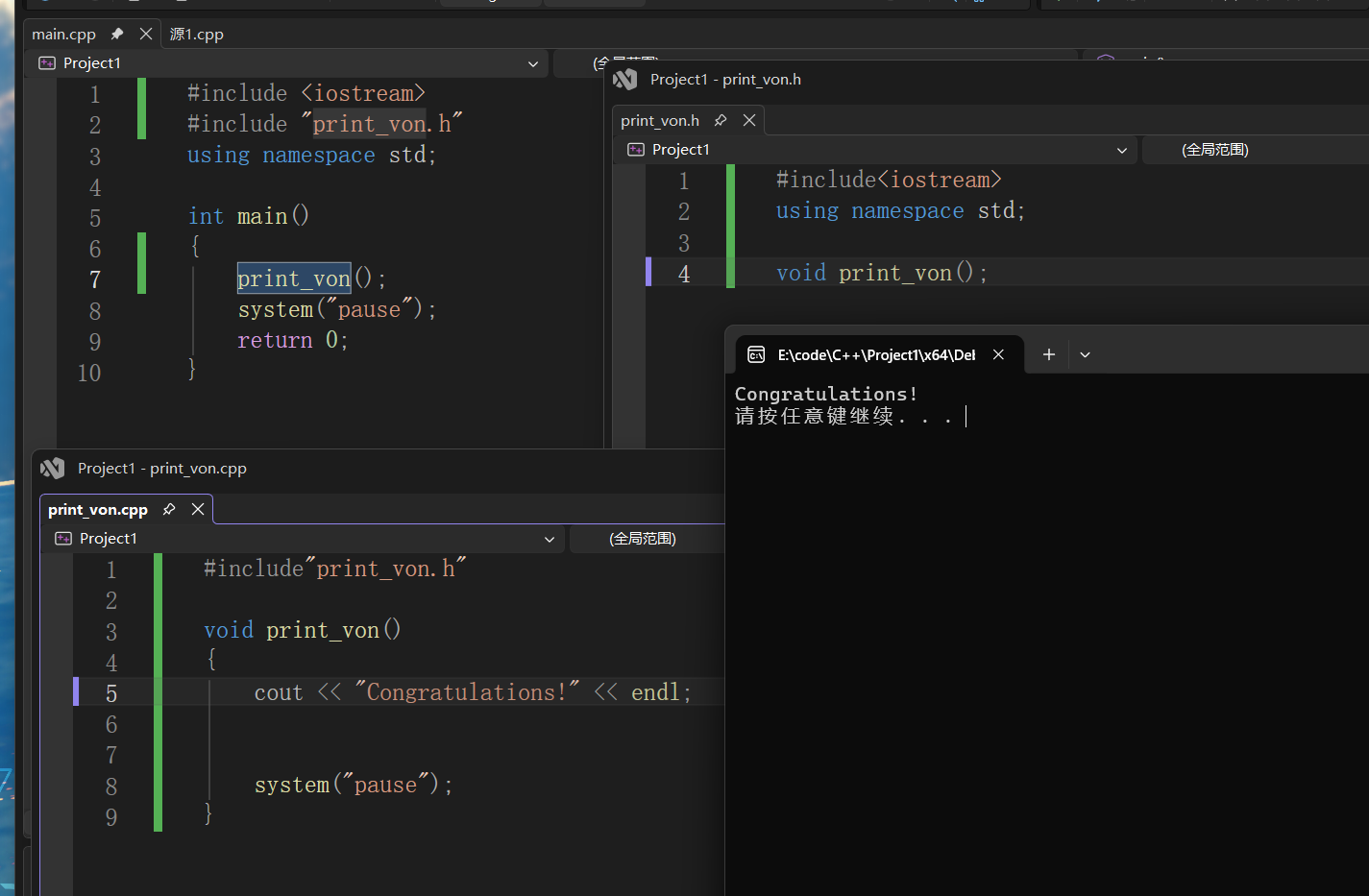
分文件编写
1、创建后缀名为.h的头文件
2、创建后缀名为.cpp的源文件
3、在头文件中写函数的声明
4、在源文件中写函数的定义
函数占位参数
返回值类型 函数名 (数据类型){}
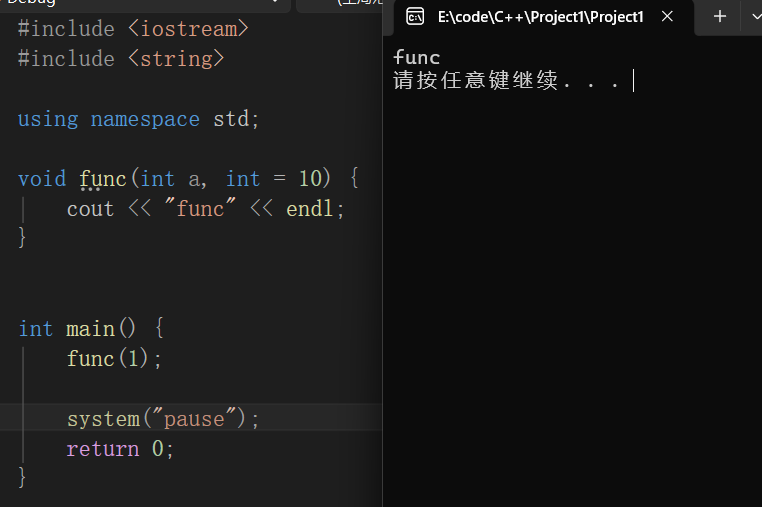
函数重载
作用
函数名可以重复,提高复用性
满足的条件
同一作用域下;
函数名称相同;
函数类型不同/个数不同/顺序不同,但是返回值不可以作为函数重载的条件
#include <iostream> #include <string> using namespace std; double calculateArea(double radius) { // 圆:1个参数(半径) return 3.14 * radius * radius; } double calculateArea(double width, double height) { // 矩形:2个参数(宽、高) return width * height; } double calculateArea(double side, string str) { // 正方形:1个参数(边长+形状) return side * side; } // 调用时更直观,参数区分场景 int main() { cout << calculateArea(5) << endl; // 圆 cout << calculateArea(4, 6) << endl; // 矩形 cout << calculateArea(3, "square") << endl; // 正方形 system("pause"); return 0; }
注意事项
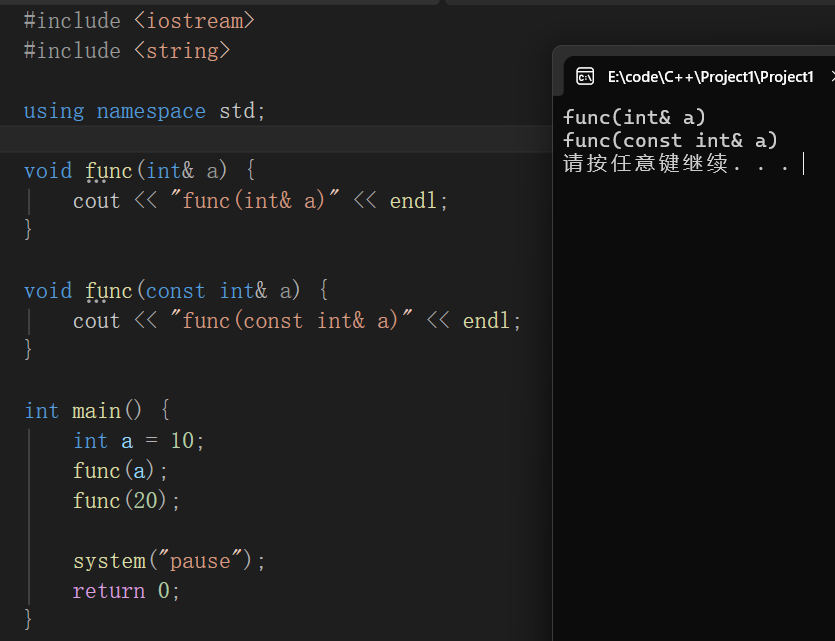
加入const也属于不同的类型,这是因为const改变了变量的权限,一般变量都是可读可写的,但是加入const会导致变量可读不可写
为什么下面的const int& a可以直接使用20来调用,这是因为int& a = 10是不合法的,而const int& a = 10是合法的,详细查看后面特殊符号中的注意
指针--*
定义
数据类型* 指针变量名
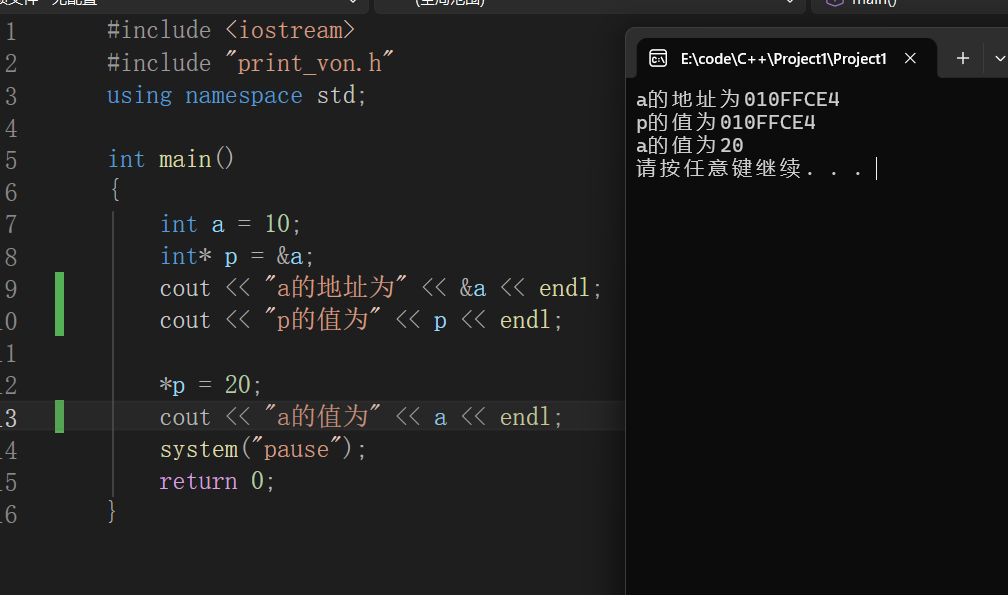
其中我们通过int* p来定义指针,int*表示的是数据类型,p表示的为常值的地址,这个*便是编译器用来区分普通int和储存地址的int。
*在定义时是类型修饰符,表示该变量为指针
*在使用时是解引用运算符,表示访问指针指向的内存值
同时指针的内存在32为中占4个字节,在64为中占8个字节
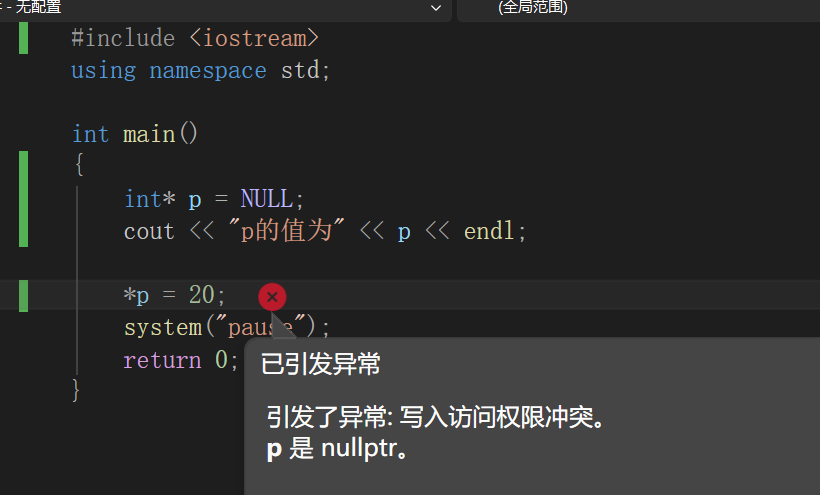
空指针

const修饰指针

int a = 10; int b = 20; const int* p = &a //常量指针 int* const p = &a //指针常量 const int* const p = &a //综合常量指针:指针的指向可以修改,但是指针指向的值不可以修改
*p = 20 //错误 p = &b //正确指针常量:指针的指向不可以修改,但是指针指向的值可以修改
*p = 20 //正确 p = &b //错误综合:指针的指向不可以修改,指针指向的值也不可以修改
*p = 20 //错误 p = &b //错误
仿指针类--Pointer-like Classes
仿指针类本质是行为像指针的类,需要通过运算符重载来实现(operator*、operator->、operator[])。
最为典型的是STL的智能指针(unique_ptr、shared_ptr)和STL迭代器,其自身更加安全、简洁,同时会自动释放内存。
class MyClass { public: void DoSomething() { cout << "MyClass 执行操作" << endl; } }; class SmartPtr { private: MyClass* raw_ptr; // 底层持有原生指针 public: explicit SmartPtr(MyClass* p) : raw_ptr(p) {} ~SmartPtr() { delete raw_ptr; cout << "SmartPtr 析构,自动释放内存" << endl; } // 重载 operator*:解引用,返回对象的引用 MyClass& operator*() const { return *raw_ptr; } // 重载 operator->:成员访问,返回原生指针 MyClass* operator->() const { return raw_ptr; } }; int main() { SmartPtr ptr(new MyClass()); ptr->DoSomething(); // 调用 operator-> (*ptr).DoSomething(); // 调用 operator* return 0; }
特殊符号
单符号--&
获取变量地址
&加在变量前,返回这个变量在内存中的地址,是指针的 "配套工具"。
用处:
给指针赋值(
int* p = &a);函数传参时传递变量地址(实现 "输出型参数"),即直接在函数空间中修改主函数的值。
引用--对指针相似,更加常用
数据类型 &别名 = 原名
#include "isInt.h" bool isInt(const string& str) { if (str.empty()) { return false; // 空字符串不是整数 } size_t start = 0; for (size_t i = start; i < str.size(); ++i) { if (!isdigit(str[i])) { return false; // 发现非数字字符 } } return true; // 全部字符都是数字 }
定义
在变量 / 参数声明时,&加在类型后,定义一个引用变量(本质是原变量的 "别名"),操作引用等价于操作原变量。该引用不占内存,可以提高效率。
用处
函数参数(避免拷贝,提升效率,比如 const string& str);
提升效率是因为直接使用string str接受字符串时,系统会使用一个新的内存储存这个局部变量,而使用&则可以直接操作原始字符串的内存,效率极高。
下面的在函数返回值中使用也是如此,使用&返回可以直接操作原始字符串的内存。
函数返回值(避免返回值拷贝,比如返回容器元素);
简化代码(给长变量名起短别名)。
引用必须初始化
int &b; //错误引用在初始化后,不可以改变
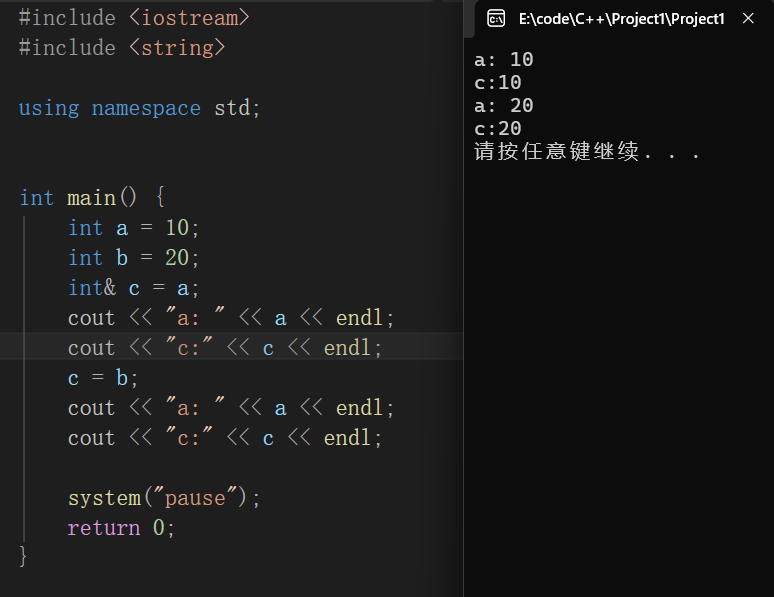
如图其为赋值操作而非更改引用
&c = b; //错误
int& a和const int& a之间的区别
在前面我们提到了这两个的合法性,这里详细说明一下为什么。
普通引用(int& a)必须绑定到一个有内存地址的变量上,而10是字面量,没有持久的内存地址,因此不允许。
const引用可以绑定到右值。此时编译器会在后台生成一个临时对象来存储10,并让引用绑定到这个临时对象上,同时延长临时对象的生命周期。
类外和类内
对于类外
类外,比如main函数中引用一个类,其必须要实例化,因此在类外一般不使用&接收一个类
对于类内
在后面的章节我们可以知道,抽象类(含有纯虚函数)无法初始化,而无法初始化的类,我们无法使用常规方法进行调用,因此一般需要加入一个&表示对于这个抽象类的引用
#include <iostream> #include <string> using namespace std; class Cpu { public: virtual void cal() = 0; }; class InterCpu :public Cpu { public: void cal() { cout << "InterCpu is calculating" << endl; } }; class Computer { public: Cpu& cpu; //不可以使用Cpu cpu,因此Cpu是抽象类无法初始化 Computer(Cpu& cpu):cpu(cpu){ cpu.cal(); } }; int main() { InterCpu cpu;//不可以使用InterCpu& cpu,因为在类外调用类需要对类实例化 Computer computer(cpu); system("pause"); return 0; }
双符号--&&
按位与运算符
对两个整数的二进制每一位做 "与运算":只有对应位都为1时,结果位才为1,否则为0。
万能引用/转发引用
仅出现在模板 /auto类型推导场景。也是c++泛型编程的 "基石级特性",在标准库中十分常见。
当其类型是推导出来的(如模板、auto),其语法含有&&(T&&、auto&&),同时没有const等关键字修饰时,其作为万能引用。可以绑定到任意类型,常与forward连用。
#include <iostream> #include <string> #include <utility> using namespace std; void process(string& s) { cout << "处理左值 string" << endl; } void process(const string& s) { cout << "处理const左值 string" << endl; } void process(string&& s) { cout << "处理右值 string" << endl; } void process(const string&& s) { cout << "处理const右值 string" << endl; } // 完美转发的中间函数 template<typename T> void forwarder(T&& s) { process(forward<T>(s)); // 完美转发,自动匹配正确的process重载 } int main() { string s1 = "左值"; const string s2 = "const左值"; forwarder(s1); forwarder(s2); forwarder(string("右值")); forwarder(move(s2)); return 0; }
右值引用
当&&不涉及类型推导(比如明确写死了类型,如int&&),它就是右值引用,用来绑定到 "临时对象"(右值)。可以避免不必要的拷贝,大幅提升性能。常用于解决深浅拷贝的性能问题,与深拷贝同时使用。
class BigData { public: char* data; int size; BigData(int s) : size(s) { data = new char[size]; } // 深拷贝解决左值场景的安全问题 BigData(const BigData& other) { size = other.size; data = new char[size]; memcpy(data, other.data, size); } // 移动构造函数(&&)解决右值场景的性能问题 BigData(BigData&& other) noexcept { size = other.size; data = other.data; // 直接接管原对象的内存指针(不分配新内存!) other.data = nullptr; // 原对象置空,防止析构时释放 other.size = 0; cout << "【移动构造】没分配内存,直接转移所有权(零成本!)" << endl; } ~BigData() { if (data) { // 只有非空才释放,防止移动后的原对象重复释放 delete[] data; } } };
自动推导类型关键字
让编译器自动帮你判断变量或函数的类型,不需要手动写。
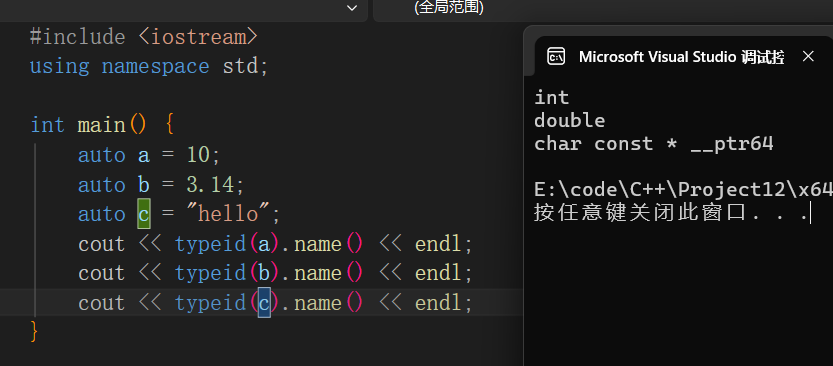
普通变量自动推导
需要注意的是,auto关键字会自动屏蔽const和&,如果想要保留,需要在对应位置添加相应的关键字。

迭代器变量自动推导
这是最为常用的一个用法,其主要使用在STL库容器中。
vector<int> v = {1,2,3}; //vector<int>::iterator it = v.begin(); auto it = v.begin(); // 编译器自动推导出迭代器类型
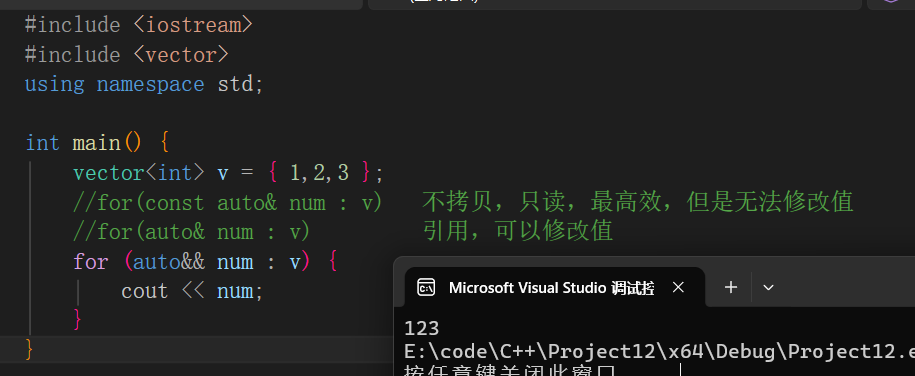
范围for循环
添加&&将其变为万能引用,提高函数的性能和兼容性。也可以不使用&&。
函数返回值类型
使用auto自动推导函数返回值类型
auto add(int a, int b) { return a + b; // 自动推导出返回 int }
函数参数类型--c++20及以上
使用auto代替函数参数的类型,其等价于一个函数的模板,这是在c++20以后需的版本才可以使用的语法。
//template <typename T1, typename T2> //void func(T1 a, T2 b) void func(auto a, auto b)同时其还可以根据变量的不同特性,选择添加const、&或&&
结构体
定义

#include <iostream>
#include <string>
using namespace std;
struct Student
{
string name;
int age;
int score;
}s3;
int main()
{
Student s1;
s1.name = "张三";
s1.age = 20;
s1.score = 90;
Student s2 = { "李四", 22, 95 };
s3.name = "王五";
s3.age = 21;
s3.score = 92;
system("pause");
return 0;
}和python中类的定义相似
结构体数组

#include <iostream>
#include <string>
using namespace std;
struct Student
{
string name;
int age;
int score;
}s3;
int main()
{
Student stuArray[3] = {
{"张三", 20, 90},
{"李四", 21, 85},
{"王五", 19, 92}
};
stuArray[2].name = "赵六";
stuArray[2].age = 23;
stuArray[2].score = 95;
for (int i = 0; i < 3; i++) {
cout << "姓名: " << stuArray[i].name << "\t"
<< "年龄: " << stuArray[i].age << "\t"
<< "成绩: " << stuArray[i].score << "\t"
<< endl;
}
system("pause");
return 0;
}
结构体指针
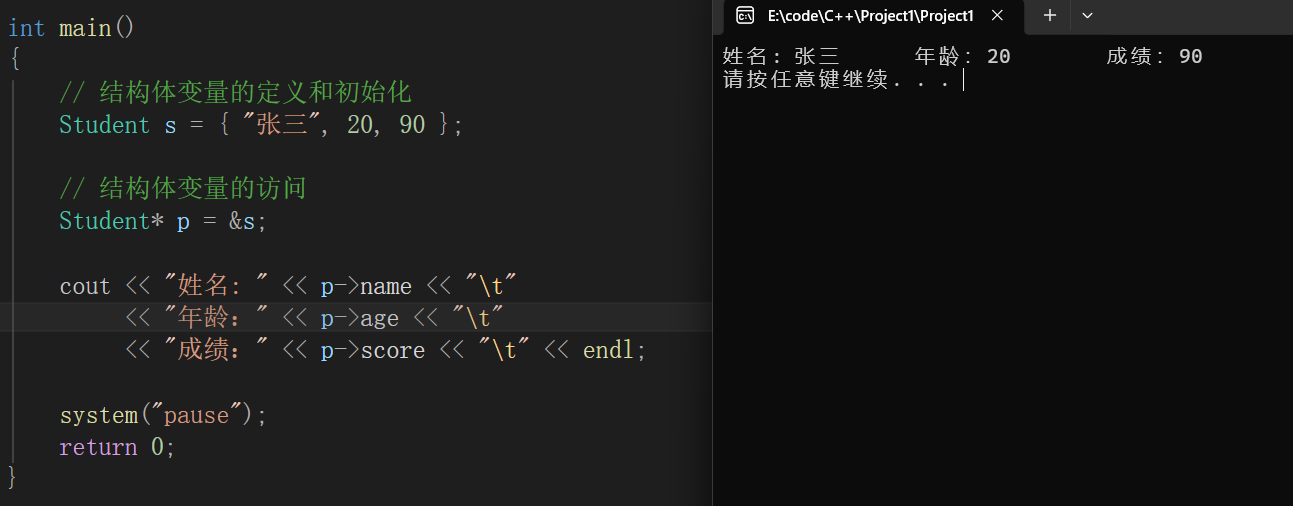
指针变量的类型也需要使用结构体变量实例,如果要访问结构体里面的值,直接使用"->"即可
结构体嵌套结构体
#include <iostream>
#include <string>
using namespace std;
struct Student
{
string name;
int age;
int score;
};
struct Teacher
{
string name;
int age;
string subject;
Student stu; // 结构体嵌套
};
int main()
{
Teacher t1 = { "张老师", 30, "语文", {"李华", 18, 90} };
Teacher t2;
t2.name = "王老师";
t2.age = 35;
t2.subject = "数学";
t2.stu.name = "张三";
t2.stu.age = 19;
t2.stu.score = 95;
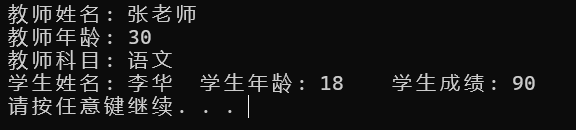
cout << "教师姓名: " << t1.name << "\n"
<< "教师年龄: " << t1.age << "\n"
<< "教师科目: " << t1.subject << "\n"
<< "学生姓名: " << t1.stu.name << "\t"
<< "学生年龄: " << t1.stu.age << "\t"
<< "学生成绩: " << t1.stu.score << "\t" << endl;
system("pause");
return 0;
}
结构体做函数参数
#include <iostream>
#include <string>
using namespace std;
struct Student
{
string name;
int age;
int score;
};
// 传值方式
void printStudent1(Student s)
{
cout << "姓名:" << s.name << endl;
cout << "年龄:" << s.age << endl;
cout << "成绩:" << s.score << endl;
}
// 传地址方式
void printStudent2(Student* p)
{
cout << "姓名:" << p->name << endl;
cout << "年龄:" << p->age << endl;
cout << "成绩:" << p->score << endl;
}
int main()
{
Student s1;
s1.name = "张三";
s1.age = 20;
s1.score = 90;
printStudent1(s1);
printStudent2(&s1);
system("pause");
return 0;
}一共有两种传递方式,一种为直接传值,另一种为传送地址
上下两种传递方式,第一种方式其看着更加简单易理解,但是由于其每一次运行都会将结构体中所有的数据拷贝一份,加入该结构体中含一个较大的数组等,这对于内存的占用会很大。
但是第二种直接传入指针,指针不管其内部值多少,指针都只会占4个字节的内存。但是如果使用第二种方式时你在函数内部改变了内部某个值,那么外部结构体的值也会随之改变。
因此为了避免对内部值的写入,可以参考上文种const的用法,在Student* p前面加入一个const则会修改p的权限为不可写入。
面向对象
内存分区

代码区

全局区

栈区

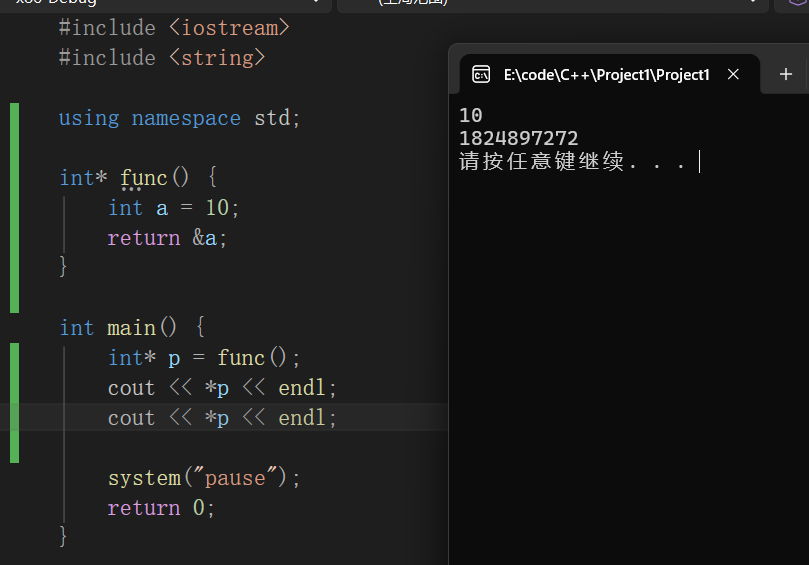
不返回局部变量的地址的原因如下:
局部变量即是在某一个函数中的自定义,且前面没有static、const等修饰的变量,这个函数可以是main主函数,也可以是自己定义的函数,但是每当该函数执行结束后,系统便会释放内存,清空函数里面的变量、代码等。
因此这也可以说明为什么main函数中可以返回局部变量的地址,但是其他函数不可以返回局部变量的地址,因此main函数是代码的主体,main函数执行结束,一般也标志着程序执行的结束。
同时严谨来说,这不叫返回局部变量的地址,而是在函数内部使用局部变量的地址。
堆区

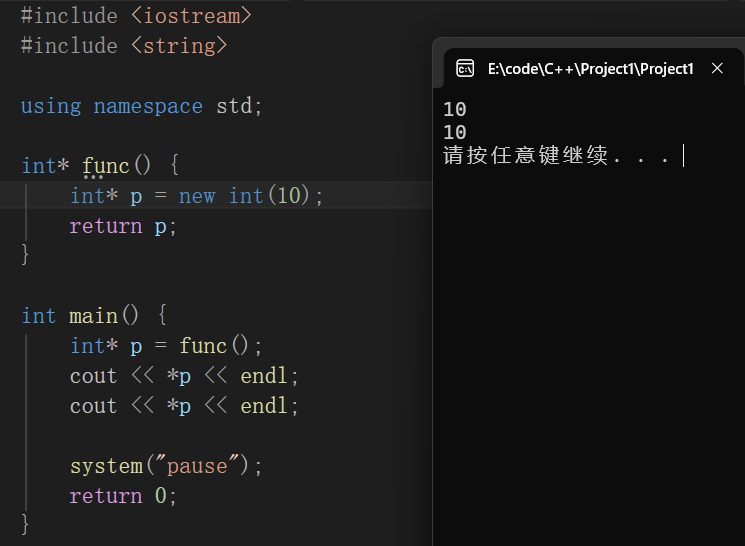
指针本身为局部变量,但是指针中存放的数据为堆区的数据
new/delete操作符

使用new创建数组时,内存除了自身元素的内存开销外,还有一个计数器的开销,这又是delete删除时,为什么其知道调用几次析构函数的原因。
创建数组
void func2() { int* arr = new int [5] {1, 2, 3, 4, 5}; }比如这个,又5个int类型的元素,一个int类型占4个字节,因此自身元素的内存开销为20,同时在这些元素的最上方,堆区还会记录new创建元素的个数,这里为5,因此最终占用内存24字节。
释放数据
数组:
delete[] arr;局部变量:
delete arr;
内存申请/释放
new和delete的底层函数是通过malloc/free来书写的
内存申请/释放关键字需包含头文件
<cstdlib>。返回的
void*通常需要强制转换为目标类型指针。分配失败时返回
NULL(C++11 起也可返回nullptr)。必须通过配套的
free()函数手动释放内存,否则会造成内存泄漏。
随机内存申请--malloc
malloc是C++中用于动态内存分配的标准库函数,从堆区申请指定字节数的连续内存空间,并返回指向该内存起始地址的 void* 指针。
void* malloc(size_t num, size_t size);
num为元素个数,size为每个元素的大小,总分配的大小为num*size。
内存申请并初始化为0--calloc
分配一块连续的内存,并将每一位初始化为0。
void* calloc(size_t num, size_t size);
num为元素个数,size为每个元素的大小,总分配的大小为num*size。
调整已分配内存的大小--realloc
对之前已经分配好的内存块进行扩容或缩容。
void* calloc(void* ptr, size_t new_size);
ptr为之前返回的指针,new_size为调整后的新大小。
如果扩容成功且原位置后有足够空间,返回值可能等于原
ptr。如果原位置空间不足,它会在堆中找一块新的足够大的内存,自动拷贝原数据,并自动释放原指针,返回新指针。
如果
ptr为NULL,则行为等同于malloc(new_size)。如果
new_size为 0,则行为等同于free(ptr)。
内存释放--free
free是C++标准库中,与malloc/calloc/realloc配套的动态内存释放函数,核心作用是释放之前从堆区申请的动态内存,将其归还给系统,避免内存泄漏。
void free(void* ptr);
ptr必须是之前由 malloc、calloc、realloc 成功申请内存时返回的指针;传入
NULL是完全安全的,此时free不会执行任何操作。free仅释放
ptr指向的堆内存块的使用权,不会修改ptr变量本身的值。释放后ptr仍指向原来的内存地址,但该地址已无权合法访问,会变成野指针,工程规范中通常建议free后立即将ptr置为NULL。
new和delete函数重载--申请内存池
new和delete函数重载最大的意义在于自定义一个内存池,因为频繁调用会导致性能开销和内存碎片。
同时如果重载了new,那么必须重载delete;如果重载了new\[\],那么必须重载delete\[\],否则可能导致内存泄漏或未定义行为。
内存池的作用
预先申请一大块内存,然后在内部高效地分配给对象。
减少系统调用次数,提升分配 / 释放速度。
重载分为全局重载和类内重载,全局重载会影响所有使用默认 new/delete 的代码,而类内重载仅对特定类及其派生类生效,但是优先级高于全局版本。
new/delete单个元素或数组全局/类内重载

上述全局重载的示意图,全局重载和类内重载基本相同,只是所处的作用域不同而已,因此这里不过多介绍类内重载。
new/delete()类内重载--placement new
placement new是指带额外参数的operator new重载,其和普通的new不太一样,下面我们以operator new(size_t size, void* start);
当重载了这个placement new时,一般来说是不需要写对应的operator delete(void*, void*)。
同时也一定不可以显式的去调用delet p来删除堆区的数据,因为这是一个未定义行为,会导致程序崩溃。
此外正常情况下,即便你重载了delete函数,其本身也不会去调用它,除非你的构造函数可能抛出异常,因此为了安全,我们仍然必须提供一个对应的delete重载版本,尽管可能不会使用它。
最后的堆区函数需要销毁,正常情况下都是显式调用析构函数来销毁对象。
#include <iostream> #include <new> #include <stdexcept> class foo { public: foo(int x) { std::cout << "构造函数被调用,准备抛异常..." << std::endl; throw std::runtime_error("构造失败"); } // 重载 placement new static void* operator new(size_t size, void* ptr) { std::cout << "调用 placement new" << std::endl; return ptr; // 直接返回传入的指针 } // 对应的 placement delete // 参数列表必须和 new 对应 static void operator delete(void* mem, void* ptr) { std::cout << "调用 placement delete(因为构造抛异常了)" << std::endl; // 这里通常什么都不做,因为 placement new 没分配内存 } }; int main() { char buffer[sizeof(foo)]; try { foo* p = new (buffer) foo(7); p->~foo(); // 使用显式调用析构函数来销毁对象 } catch (...) { std::cout << "捕获异常" << std::endl; } return 0; }
文件操作
C++中对文件操作需要包含头文件<fstream>
文件类型
文本文件--文件以文本的ASCII码形式储存在计算机中
二进制文件--文件以文本的二进制形式储存在计算机中,用户一般不能直接读懂它

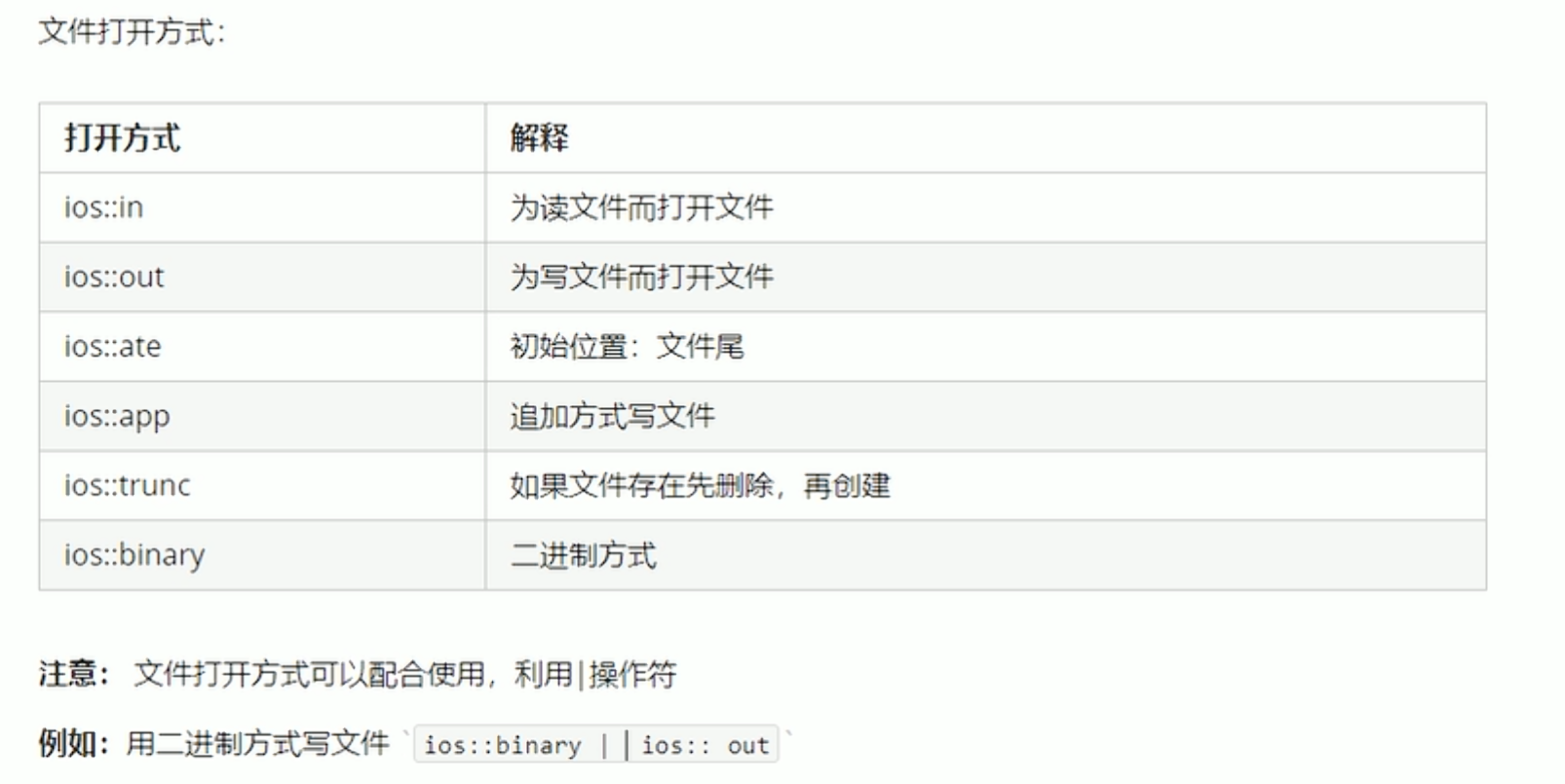
文件打开方式
在使用trunc删除清空原文件内容时,需要和out模式共同使用,否则会导致下次写入文件无法成功,再次写入才可以成功。
同时对于是否打开文件,可以使用is_open来进行验证
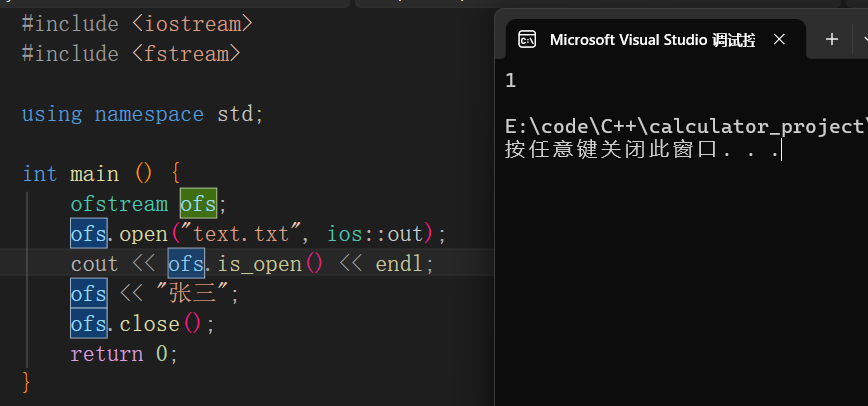
写文本文件

读文本文件

读数据的三种方式--判断文章内容是否为空
第一种
string buf; while (ifs >> buf) //数据按空格分割 { cout << buf << endl; }ifs>>buf的意思便是将ifs中所有的数据逐个流向buf,当该数据不为空时,返回true,否则返回false
第二种
string buf; while (getline(ifs, buf)) //数据按段分割 { cout << buf << endl; }getline(ifs, buf)的意思便是将ifs中所有的数据按段分割逐个流向buf,当该数据不为空时,返回true,否则返回false
第三种
char buf[1024] = {0}; while (ifs.getline(buf, sizeof(buf))) { cout << buf << endl; }ifs.getline(buf, sizeof(buf)的意思便是将ifs中所有的数据按段分割逐个流向buf,当该数据不为空时,返回true,否则返回false
以特殊字符分割文件
c++的默认库中只有以空格来分割文件的函数(getline),如果你不想要重新调取另外的库(如github上的csv库),则需要自己构建,以下以csv文件为例。
csv文件如果使用文本打开,那么其之间的元素都是,相连接,因此需要实现一个,分割文件的函数。
// 按分隔符分割字符串 vector<string> split(const string& s, char delimiter) { vector<string> tokens; string token; istringstream tokenStream(s); while (getline(tokenStream, token, delimiter)) { tokens.push_back(token); } return tokens; } void find_csv() { ifstream ifs("winner.csv", ios::in); if (ifs.is_open()) { string buf; vector<vector<string>> csvData; if (!getline(ifs, buf)) { cout << "文件中无内容" << endl; } while (getline(ifs, buf)) { vector<string> row = split(buf, ','); for (const auto& cell : row) { //以[]来分割各个元素 cout << "[" << cell << "]"; } cout << endl; } ifs.close(); } else { cout << "文件无法打开" << endl; } }其主要内容在上面的函数,其需要包含头文件#include <sstream>
istringstream tokenStream(s)把字符串 s 变成一个 "可以像读文件一样读" 的流。
while (getline(tokenStream, token, delimiter))则是循环从管道里读东西,读到delimiter就停下。其中tokenStream是刚才的字符串管道,token每次读到的一小段内容。
tokens.push_back(token)则是把刚才拿到的那一格,放进数组里存起来。
写二进制文件
二进制方式写文件主要利用流对象调用成员函数write
函数原型
//字符指针buffer指向内存中一段储存空间。len是读写的字节数
ostream& write(const char * buffer, int len);
class Person { public: char Name[64]; int Age; }; void test() { ofstream ofs("person.txt", ios::out | ios::binary); if (!ofs.is_open()) { cout << "文件打开失败" << endl; return; } Person p = { "张三", 18 }; ofs.write((const char*)&p, sizeof(Person)); ofs.close(); }
读二进制文件
二进制方式读文件主要利用流对象调用成员函数read
函数原型
//字符指针buffer指向内存中一段储存空间。len是读写的字节数
istream& read(char * buffer, int len);
class Person { public: char Name[64]; int Age; }; void test() { ifstream ifs("person.txt", ios::out | ios::binary); if (!ifs.is_open()) { cout << "文件打开失败" << endl; return; } Person p; ifs.read((char*)&p, sizeof(Person)); cout << p.Age << endl; cout << p.Name << endl; ifs.close(); }这和上面写文件还有一个区别在于类p不能使用const,因为在p前面加入const会导致p中的数据无法修改,从而与read的功能相矛盾。