
这篇文章围绕一个近期火热的问题:为什么 Hermes Agent 能在 GitHub 上迅速登上月度榜单、累计拿下近 8 万颗 Star,并且「从 OpenClaw 迁移到 Hermes,是最明智的选择」的说法会广泛传播?
要把这件事讲明白,最好的顺序不是直接从"怎么安装、怎么用"讲起,而是先回到最根本的问题:Agent 到底缺什么?Hermes 解决了什么?它的学习循环到底如何运作?
只有先看清底层设计,后续再理解它的技能系统、记忆体系和多平台接入时,才不会觉得"又是一个套壳聊天机器人"。
一、Agent 的记忆现状:能记住,但得你来操心
在正式拆解 Hermes 之前,先退一步看一个很多人没有想清楚的问题:
现在的 Agent 真的什么都记不住吗?
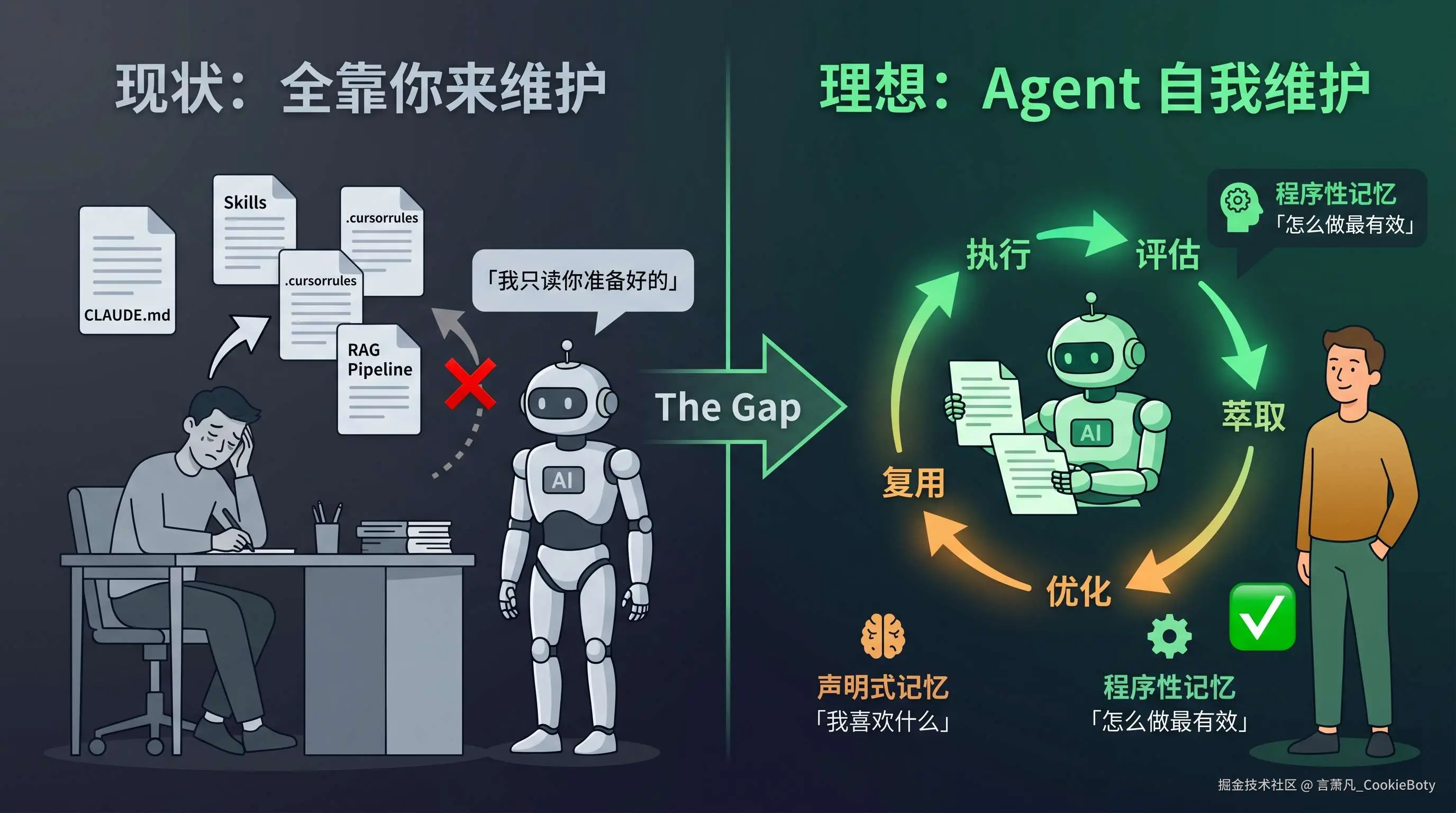
其实不是。过去一年,主流开发工具已经在记忆增强上做了大量探索:
- CLAUDE.md / AGENTS.md:在项目根目录放一份上下文文件,每次会话自动加载,让 Agent 「记住」项目约定和编码规范;
- Skills / Rules 文件 :OpenClaw 的 Skills 市场、Cursor 的
.cursorrules,通过预定义的行为规范来引导 Agent; - RAG(检索增强生成):把代码库、文档库接入向量数据库,让 Agent 在回答时检索相关上下文;
- ChatGPT Memory / Claude Projects:跨会话记住用户偏好,或通过项目知识库提供长期上下文。
这些机制确实有效------它们让 Agent 不再是裸奔的「失忆患者」。但如果你用得久一点,就会发现一个共同的瓶颈:
所有的记忆,都需要你来创建和维护。
你得自己写 CLAUDE.md,自己挑选和安装 Skills,自己搭建 RAG 流水线,自己更新过时的 Rules 文件。Agent 本身并不会从一次次的使用中「学到」什么------它只是忠实地读取你预先准备好的资料。
换句话说,当前的记忆增强方案解决的是 「能不能记住」 的问题,但没有解决 「谁来维护这些记忆」 的问题:
| 维度 | 当前主流方案 | 理想状态 |
|---|---|---|
| 记忆创建 | 人工编写(CLAUDE.md、Skills、Rules) | Agent 自动从实践中萃取 |
| 记忆更新 | 手动维护,过时了要自己改 | 自动迭代,淘汰过时内容 |
| 记忆类型 | 偏向声明式(「我喜欢什么」) | 包含程序性(「怎么做最有效」) |
| 学习闭环 | ❌ 没有反馈→优化的自动回路 | ✅ 执行→评估→萃取→优化→复用 |
这就好比一家公司给每个新员工发了一本厚厚的操作手册(CLAUDE.md),也建了一个庞大的知识库(RAG),但这些手册和知识库全靠老员工手动更新------而真正在一线干活的人(Agent),干完活就走,从来不往手册里补一个字。
二、Hermes Agent 是什么:一句话定位
Hermes Agent 是由 Nous Research 开发的开源 Agent 框架,采用 MIT 协议。
它的官方定位只有一句话:
"The agent that grows with you" ------ 与你共同成长的 Agent。
听着像营销口号,但这句话背后对应的是一套非常具体的工程实现:
- 内置闭环学习循环:任务完成后自动萃取技能,下次遇到类似任务即可复用并持续优化;
- 四层持久化记忆:跨会话保留你的偏好、决策模式与历史上下文;
- 自我进化的技能系统:技能并非人工编写的静态脚本,而是 Agent 自动总结、迭代的结构化经验;
- 多模型自由切换:支持 18+ 模型提供商(OpenAI、Anthropic、OpenRouter、DeepSeek、Kimi 等),一行命令即可切换;
- 多平台网关:原生支持 Telegram、Discord、Slack、WhatsApp 等 12+ 消息平台。
Hermes Agent vs OpenClaw:设计哲学的根本差异
很多人把 Hermes 当成 OpenClaw 的替代品,但两者的设计出发点完全不同:
| 维度 | OpenClaw(龙虾) | Hermes Agent(爱马仕) |
|---|---|---|
| 核心架构 | 网关(Gateway)------ 调度中心 | 引擎(Engine)------ 执行循环 |
| 设计重心 | 怎么把消息送到 Agent | Agent 怎么变得越来越强 |
| 技能系统 | 人工编写 + 社区市场(ClawHub) | Agent 自动萃取 + 自我迭代 |
| 记忆体系 | 工作区文件级记忆 | SQLite + 全文检索 + 分层记忆 |
| 多 Agent | 配置文件联合多个 Agent | 单一 Agent 框架,能力自增长 |
| 适合场景 | 一次性任务、工具覆盖广 | 重复性任务、长期使用 |
一句话总结:OpenClaw 像一个开箱即用的万能遥控器,Hermes 像一个跟着你越干越熟练的长期助理。
技能系统的差异:Hermes vs OpenClaw Skills vs CLAUDE.md
这个差异值得单独拿出来看,因为它直接反映了三种框架对「知识维护责任」的不同分配:
| 维度 | Hermes 技能 | OpenClaw Skills | CLAUDE.md |
|---|---|---|---|
| 创建方式 | Agent 自动萃取 | 人工编写 + 社区共享 | 用户手动编写 |
| 更新机制 | 自动迭代优化 | 手动更新 / 社区 PR | 手动修改 |
| 个性化 | 完全个性化 | 通用 + 部分配置 | 完全个性化 |
| 学习成本 | 零(全自动) | 中(需找 / 装 / 配) | 低(写一次) |
| 知识积累 | 越用越多 | 取决于社区活跃度 | 不会自动增长 |
三、Hermes 的核心引擎:闭环学习循环
这是 Hermes 最关键的设计,也是它区别于所有其他 Agent 框架的根本所在。
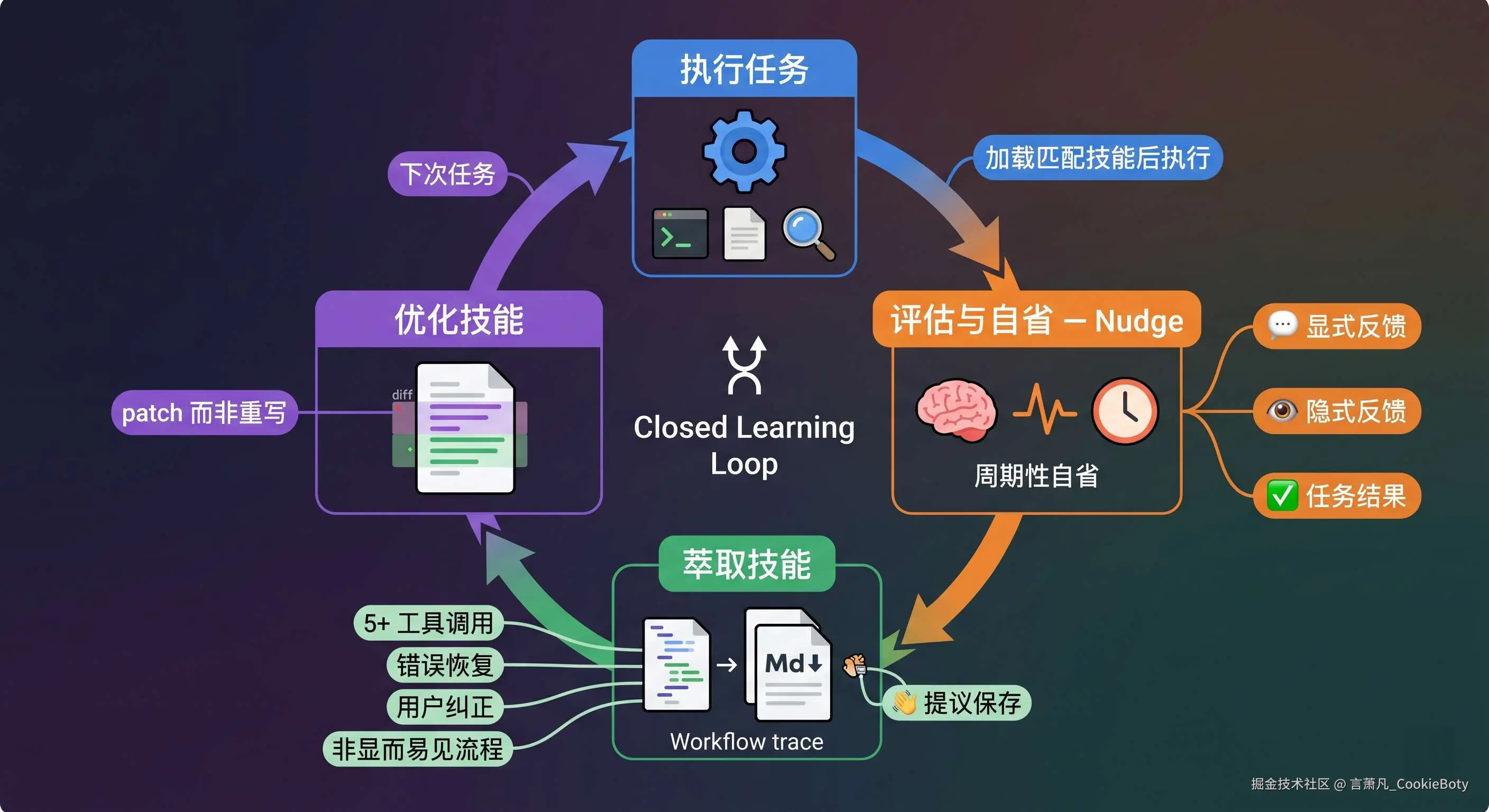
1. 学习循环的四个阶段
Hermes 的核心是一套 Closed Learning Loop(闭环学习循环),拆开来看有四个阶段:
yaml
执行任务 → 评估与自省 → 萃取技能 → 优化技能
↑ |
└──────────── 下次任务 ←────────────────┘阶段一:执行任务
和其他 Agent 一样,接到指令后拆解目标、调用工具、产出结果。新任务进来时,系统会先搜索技能库,找到相关的技能直接套用,不用每次从头推理。这一步本身没有什么特别。
阶段二:评估与自省(Nudge 机制)
这是整个学习循环的驱动力。Hermes 内置了一套 Periodic Nudge(周期性自省提示)机制------Agent 在对话过程中会被定期提示去回顾刚刚发生的事情,主动决定哪些信息值得持久化保存。
评估信号来自三个维度:
- 显式反馈:用户主动纠正 Agent 的做法,例如「函数名用 snake_case」;
- 隐式反馈:用户的行为推断------是否直接采纳输出、是否追问同一问题;
- 任务结果:执行是否成功、是否遇到错误后最终恢复。
Nudge 机制确保记忆保持精选状态,而非变成一个无差别的日志堆积场。正如官方所述:Agent「nudges itself to persist knowledge」------它会自我推动去沉淀知识。
阶段三:萃取技能
Agent 在以下情况会提议创建新技能:
- 完成了复杂任务(通常涉及 5 次以上工具调用)且成功;
- 在执行过程中遇到了错误或死胡同,最终找到了可行路径;
- 用户纠正了 Agent 的做法;
- 发现了非显而易见的工作流程。
注意,技能创建并非完全静默的后台行为------Agent 会提议保存(offer to save)某次做法为技能,而非无感自动完成。创建后的技能以结构化 Markdown 文件存储,通常包含:
- When to Use:什么情况下应该使用这个技能;
- Procedure:具体的执行步骤和工具调用序列;
- Pitfalls:执行过程中发现的坑和边界条件;
- Verification:如何判断这个技能是否执行成功。
一个典型的技能文件长这样:
markdown
# 技能:GitHub Issue 分类与优先级标注
## 触发条件
- 用户要求对一批 GitHub Issue 进行分类
- Issue 数量超过 10 个
## 执行步骤
1. 读取 Issue 列表(标题 + 正文前 200 字)
2. 按以下维度分类:Bug / Feature / Enhancement / Question
3. 根据关键词和影响范围标注优先级:P0-P3
4. 输出为 Markdown 表格格式
## 注意事项
- 用户偏好中文标签,不要用英文
- P0 判定标准:涉及数据丢失或服务宕机
- 分类不确定时标注「待确认」而非强行归类
## 验证标准
- 所有 Issue 都已分类,无遗漏
- P0 类 Issue 已单独标注提醒技能不是静态资产,而是 有生命周期的活文档------连续多次不被匹配到的技能会自动降权归档,保证技能库始终是活的。
阶段四:优化技能
技能不是「存了就不动」的。下次遇到类似任务,系统会拿新的执行结果和旧技能比对。如果发现了更好的方法,Agent 通过 skill_manage 工具的 patch 操作自动更新技能文档------只修改变化的部分,而非全量重写。选择 patch 而非全量 edit 有两个考虑:一是正确性 (全量重写可能打破已正常工作的部分),二是效率 (patch 的 token 消耗远低于重写)。
2. 用一句话理解学习循环
普通 Agent 记住的是「你说过什么」,Hermes 记住的是「怎么做最有效」。
这就是 程序性记忆(Procedural Memory) 的核心概念:不是记住数据,而是记住方法。就像一个人学骑自行车,你不需要记住每次蹬踏的角度,你记住的是「平衡感」和「节奏」。
四、Hermes 的记忆体系:四层架构
学习循环解决的是「怎么做」的问题,记忆体系解决的则是「记住什么」的问题。
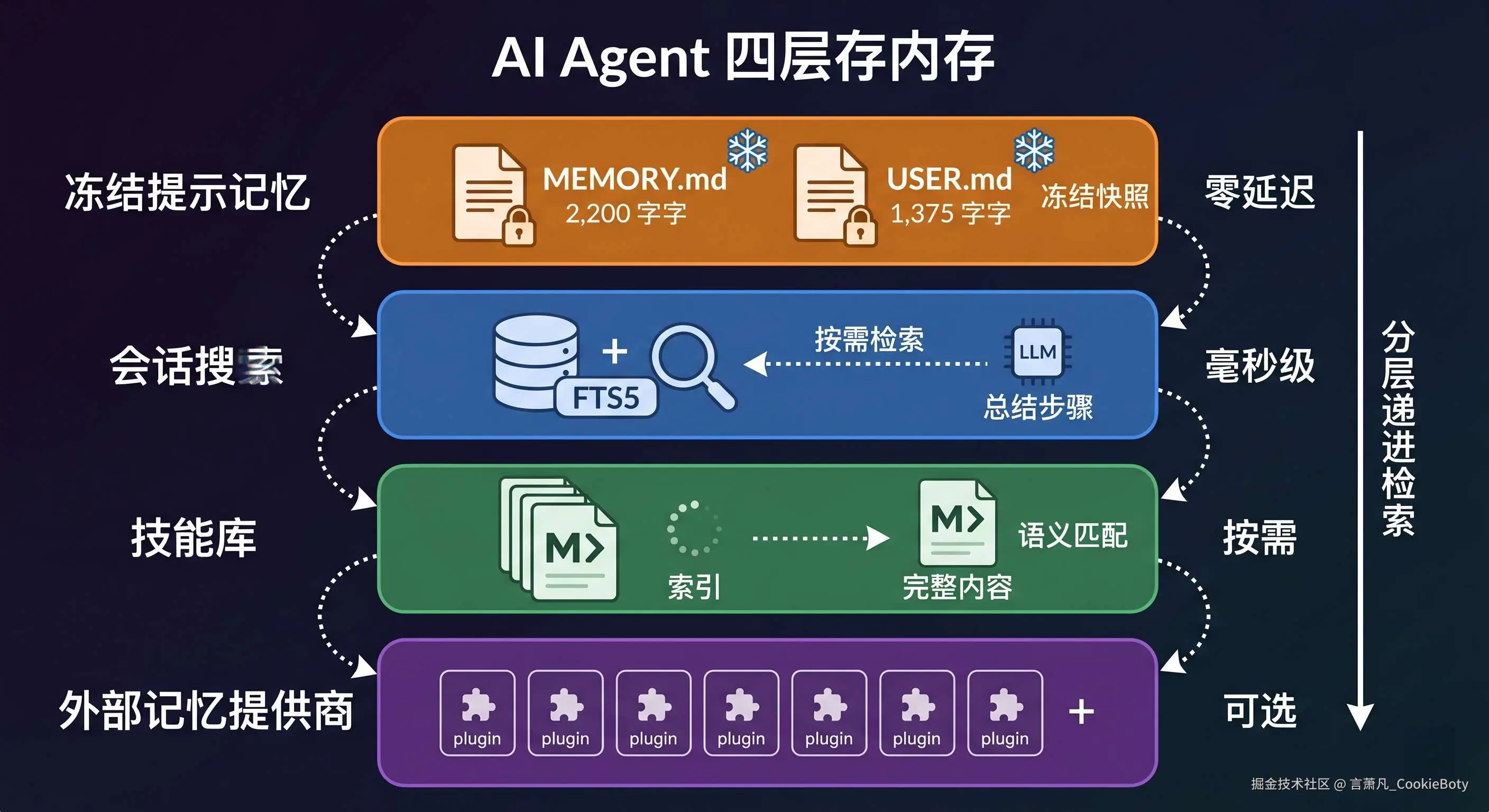
Hermes 把记忆分成了四个层级,每一层解决不同频率和粒度的信息需求:
第一层:冻结提示记忆(MEMORY.md + USER.md)
这一层由两个 Markdown 文件组成,存放在 ~/.hermes/memories/ 目录下,是 Agent 最核心的「热记忆」:
- MEMORY.md(上限 2,200 字符,约 800 tokens):存储环境事实和工作流偏好------项目规范、常用部署路径、编码约定等客观信息;
- USER.md(上限 1,375 字符,约 500 tokens):存储关于你这个人的行为档案,包括四类追踪维度:
| 追踪维度 | 具体内容 | 效果 |
|---|---|---|
| 格式偏好 | 你习惯条列式还是长段落 | 用几次后不再问你要什么格式 |
| 决策记录 | 你过去遇到类似情况怎么选 | 同类问题自动参考历史决策 |
| 任务模式 | 你最常跑哪类任务、什么时间跑 | 主动预测你的下一步需求 |
| 反馈信号 | 你接受/修改/拒绝的频率 | 持续校准输出质量 |
关键设计:冻结快照机制。 每次新会话启动时,这两个文件的内容作为「冻结快照」一次性注入 system prompt,会话中途的写入会实时落盘,但 不会改变当前会话的 prompt。这样做的原因是保护前缀缓存(prefix cache)------如果 system prompt 频繁变动,LLM 提供商的 KV-cache 就会失效,延迟和成本都会飙升。
容量限制是故意设计的:合计约 1,300 tokens 的空间,迫使 Agent 只保留最有价值的信息。当记忆满了,Agent 会自动合并或替换条目来腾出空间。Agent 通过统一的 memory 工具管理记忆,支持 add(追加)、replace(替换)和 remove(删除)三种操作。
第二层:会话搜索(Session Search)
所有历史对话都存在 SQLite 数据库(~/.hermes/state.db)里,配合 FTS5 全文检索引擎 ,支持中英文分词。这一层不会主动注入 prompt,而是 按需调用 ------当常驻记忆里找不到答案时,Agent 使用 session_search 工具检索历史。
检索流程分两步:
- FTS5 按相关度排序匹配消息,取 Top-N 个会话;
- 调用辅助 LLM(通常是更便宜的小模型)对检索结果做摘要,提炼出与当前问题最相关的信息。
这种「检索 + LLM 摘要」的两阶段设计是经典 RAG 模式。FTS5 的优势在于零外部依赖、毫秒级查询,且 SQLite 文件天然可移植。
第三层:技能库(Skills)
上一节讲的技能文档就存在这里(~/.hermes/skills/)。每个技能是一个独立的 Markdown 文件,通过语义检索匹配到当前任务。
与常驻记忆不同,技能库采用 渐进式加载策略 :系统只在 prompt 中注入技能索引(标题和触发条件),需要时才通过 skill_view() 拉取完整内容,避免 token 膨胀。
| 维度 | MEMORY.md / USER.md | Skills |
|---|---|---|
| 注入方式 | 每轮自动注入 system prompt | 按需加载,只在匹配时注入 |
| 容量 | 合计约 3,575 字符 | 单个技能可达 100,000 字符,数量无限 |
| 结构 | 扁平的事实列表 | 结构化步骤 + 前置条件 + 参考资料 |
| 可执行性 | 参考信息 | Agent 按步骤逐条执行 |
第四层:可选外部记忆提供商
Hermes 内置支持 8 种外部记忆提供商插件,包括 Honcho、Mem0、Supermemory、OpenViking、Hindsight、Holographic、RetainDB 和 ByteRover。
外部提供商与内置记忆 并行运行(additive),而非替换。它们带来的增强能力包括:
- 跨会话语义画像:Honcho 的辩证式用户建模,通过 Q&A 和语义搜索建立深度用户理解;
- 知识图谱:将零散事实组织成结构化的关系网络;
- 自动事实抽取:对话结束后,后台线程自动从对话中抽取持久事实,无需手动标记。
配置方式也很简单:
bash
hermes memory setup # 选择并配置一个提供商
hermes memory status # 查看当前激活状态这一层是可选的,适合需要深度个性化和跨设备一致性的高级场景。
四层协作:分层递进的检索策略
Hermes 的记忆检索不是简单地「搜索全部历史」,而是 分层递进:
markdown
第一层:冻结提示记忆 → 直接读取,零延迟
↓ 如果不够
第二层:会话搜索 → FTS5 检索 + LLM 摘要
↓ 如果还不够
第三层:技能库 → 语义检索,按需加载
↓ 如果还不够
第四层:外部提供商 → 语义画像 + 知识图谱这种分层设计有一个关键优势:大多数请求在前两层就能获得足够的上下文,不需要每次都搜索全量历史。 这既节省了 Token(更少的上下文注入),也降低了延迟。
记忆体系 vs OpenClaw 的对比
💡 OpenClaw 的记忆是工作区里的 Markdown 文件------你看得见、摸得着,倾向于把更多内容塞入 prompt,以文件为真相源。Hermes 则更激进:严格限制热记忆容量,以 SQLite 为历史真相源,prompt 仅作缓存快照,并将 prompt 稳定性 视为一等约束(服务于前缀缓存)。Hermes 不需要你手动管理记忆,Agent 自己决定什么值得记、什么时候该合并或淘汰。这是两种完全不同的设计取舍------OpenClaw 更「搜索导向」,Hermes 更「缓存导向」。
五、如何设计一个 Hermes:从零开始的架构思维
如果你不只是想用 Hermes,而是想理解它的设计思路,甚至想自己做一个类似的系统,那么这一节是最重要的。
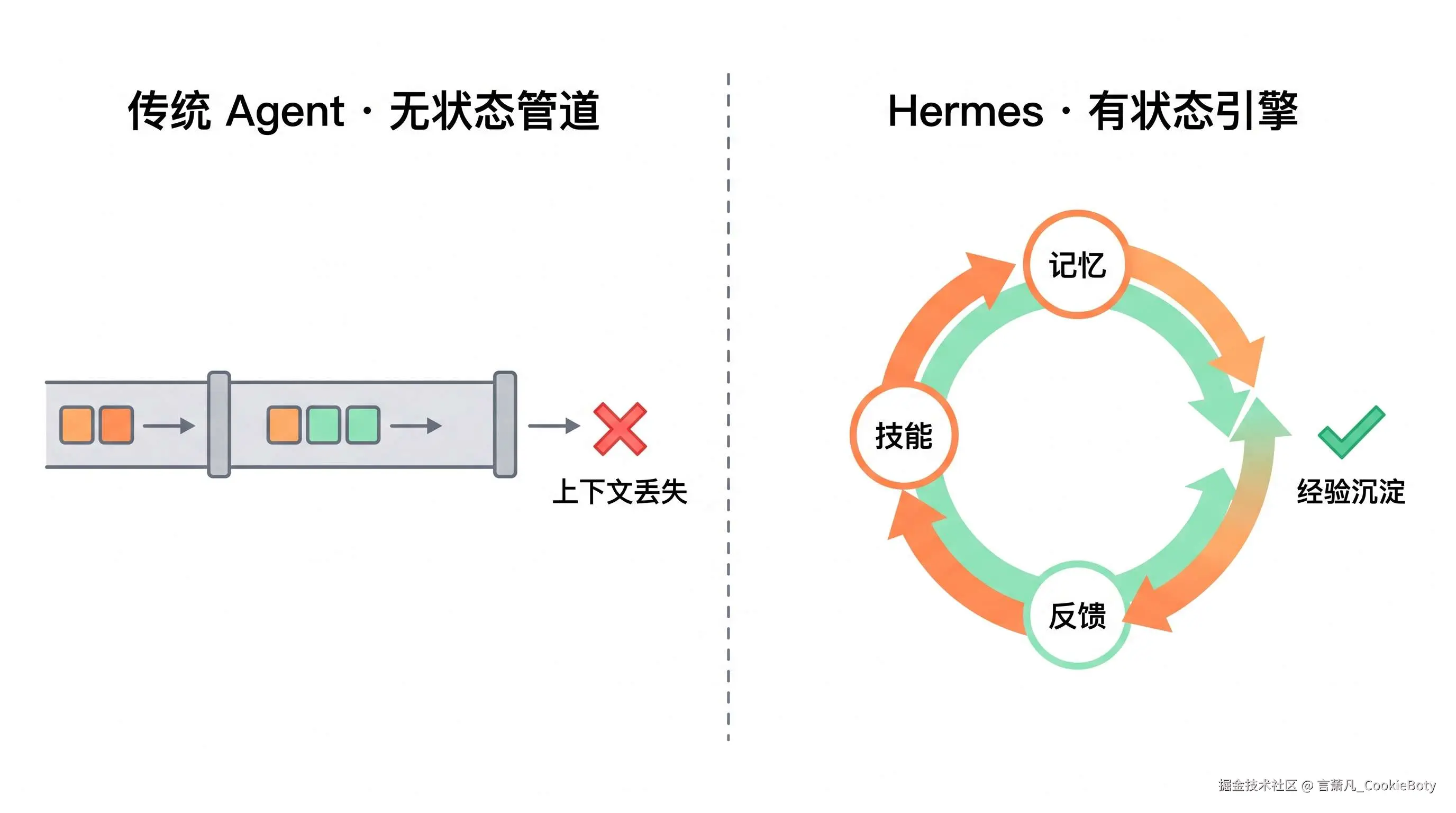
1. 设计原则:从「无状态管道」到「有状态引擎」
传统 Agent 的架构可以简化为:
css
[用户输入] → [Prompt 组装] → [模型调用] → [输出结果]这是一个 无状态管道:每次请求独立,前后没有关联。
Hermes 的架构则是:
css
[用户输入]
↓
[记忆检索] → 从历史中召回相关上下文
↓
[技能匹配] → 从技能库中找到可复用的方法
↓
[Prompt 组装] → 融合记忆 + 技能 + 当前输入
↓
[模型调用] → 执行推理
↓
[结果输出] → 返回给用户
↓
[反馈采集] → 用户是否接受、修改、拒绝
↓
[经验沉淀] → 更新记忆 / 萃取技能 / 优化画像这是一个 有状态引擎:每次执行都会改变系统自身的状态,让下一次执行变得更好。
2. 核心模块拆解
如果你要自己设计一个类 Hermes 系统,至少需要以下六个核心模块:
objectivec
┌─────────────────────────────────────────────┐
│ Hermes Agent │
├──────────┬──────────┬───────────────────────┤
│ 执行引擎 │ 记忆系统 │ 技能系统 │
│ │ │ │
│ - 工具调用 │ - 常驻记忆 │ - 技能萃取 │
│ - 推理链路 │ - 历史检索 │ - 技能检索 │
│ - 错误恢复 │ - 用户画像 │ - 技能优化 │
├──────────┴──────────┴───────────────────────┤
│ 模型抽象层 │
│ OpenAI / Anthropic / OpenRouter / 本地模型 │
├─────────────────────────────────────────────┤
│ 平台网关层 │
│ CLI / Telegram / Discord / Slack / API │
└─────────────────────────────────────────────┘3. 关键设计决策
决策一:技能粒度怎么定?
技能太粗(「做研究」),匹配率低、复用价值差。技能太细(「在 Google 搜索某个关键词并点击第三个结果」),又会导致技能库爆炸。
Hermes 的策略是 以任务复杂度为门槛:只有涉及 5 次以上工具调用的任务,才会触发技能萃取。这保证了每个技能都有足够的信息密度。
决策二:记忆该存什么、该忘什么?
全存不现实(上下文窗口装不下),全不存又回到了无状态管道。Hermes 的方案是 分层存储 + 按需召回:
- 高频信息 → 常驻记忆,每次都带;
- 低频信息 → 全量历史,搜索时才调用;
- 过时信息 → 自动降权,不会主动浮现。
决策三:如何评估一次执行是否「成功」?
这是最难的部分。Hermes 采用的是 隐式反馈,而非显式评分:
📊 隐式反馈信号矩阵
- 用户直接使用 → 强正向信号(权重 1.0)
- 用户小幅修改 → 弱正向信号(权重 0.6)
- 用户大幅修改 → 弱负向信号(权重 0.3)
- 用户完全丢弃 → 强负向信号(权重 0.0)
- 用户追问同一问题 → 执行失败信号
这套机制的好处是 零摩擦------用户不需要额外点「好评」或「差评」,系统从你的行为本身就能推断出效果。
决策四:模型层怎么解耦?
Hermes 的模型抽象层设计得非常干净。切换模型只需要一行命令:
bash
hermes model系统会列出所有可用的提供商和模型,选择后即生效。这意味着:
- 技能系统不依赖某个特定模型;
- 记忆系统不绑定任何厂商格式;
- 用户可以根据任务复杂度灵活切换大小模型。
这和上一篇《省 Token 实战手册》里讲的「模型路由」思路完全一致:杀鸡别用牛刀,简单任务用小模型,复杂推理才上大模型。
六、实战:从安装到第一个自动生成的技能
讲完原理,我们来看 Hermes 的实际操作。
1. 一行命令安装
Hermes 支持 Linux、macOS(原生)和 Windows(通过 WSL2),Android 用户可通过 Termux 安装。
bash
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash安装完成后重载 shell:
bash
source ~/.zshrc # 如果是 bash 用 source ~/.bashrc2. 首次启动与模型配置
bash
hermes首次启动会进入设置向导。也可以随时用 hermes setup 重新配置。
模型切换:
bash
hermes model系统会列出所有可用的提供商:
| 提供商 | 说明 | 配置方式 |
|---|---|---|
| Nous Portal | 订阅制,零配置 | OAuth 登录 |
| OpenRouter | 200+ 模型可选 | 输入 API Key |
| OpenAI | GPT 系列模型 | API Key |
| Anthropic | Claude 系列 | Claude Code 认证或 API Key |
| DeepSeek | DeepSeek API | 设置 DEEPSEEK_API_KEY |
| 自定义端点 | vLLM / Ollama / 任何兼容 API | 设置 Base URL + API Key |
3. 从 OpenClaw 迁移
如果你之前是 OpenClaw 用户,一行命令即可迁移:
bash
hermes claw migrate --dry-run # 先预览
hermes claw migrate # 确认执行这会把你的设置、记忆、技能和 API 密钥全部导入 Hermes。
4. 观察技能自动生成
当你完成几个稍复杂的任务后(比如「帮我调研某个开源项目并输出结构化报告」),Hermes 会自动在技能目录下生成新的技能文件。
你可以通过以下方式查看:
bash
hermes skills browse # 浏览所有可用技能
hermes skills inspect <name> # 查看某个技能的详情这就是学习循环在实际运行中的体现:你没有手动写任何规则,Agent 自己总结出了可复用的方法论。
七、深入原理:Hermes 为什么能「越用越强」
前面讲了「是什么」和「怎么做」,这一节要回答的是「为什么」------ 从技术原理层面解释 Hermes 学习循环的工作机制。
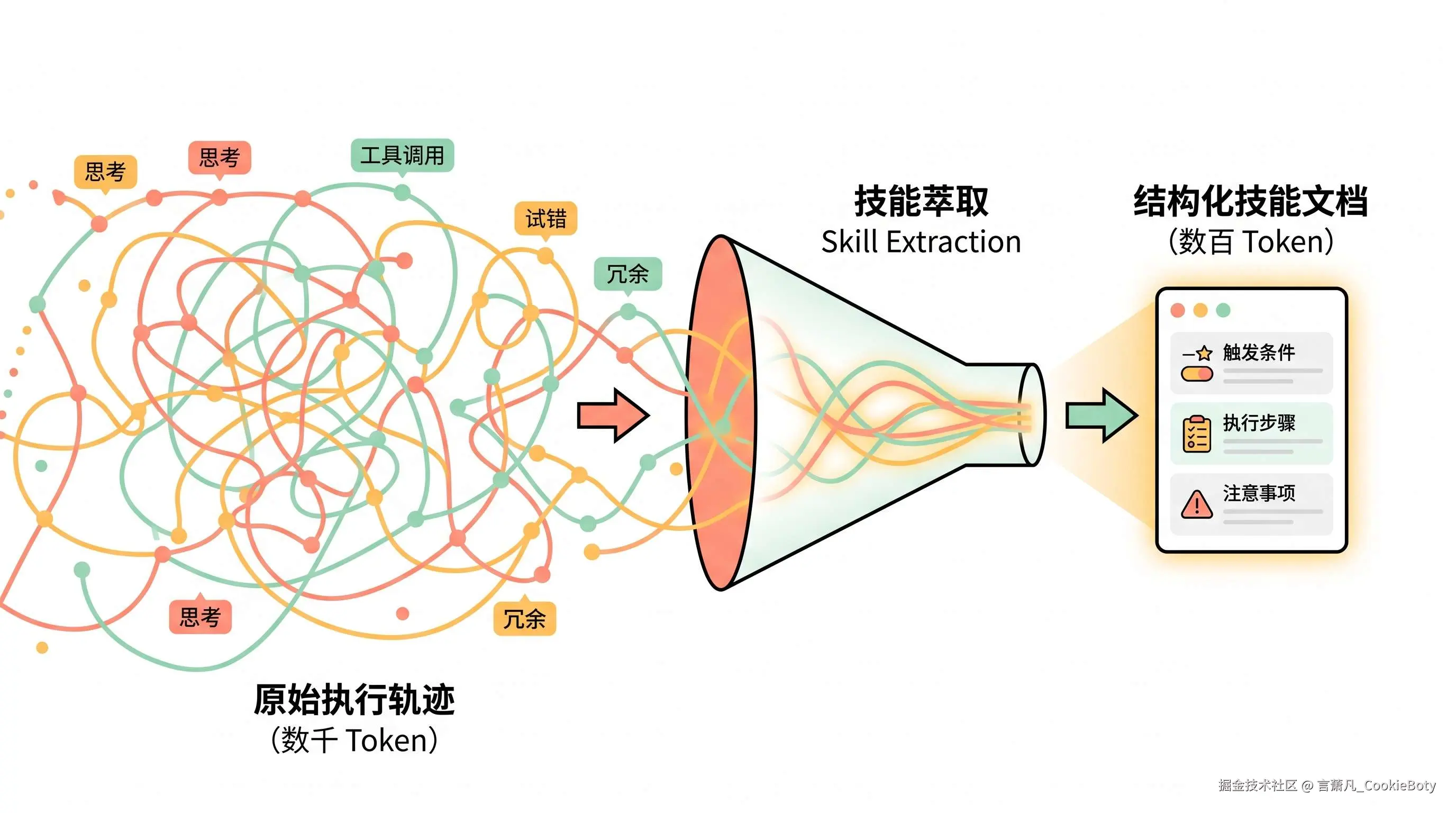
1. 技能萃取的本质:从执行轨迹到压缩知识
Agent 在执行任务时会产生一条完整的「执行轨迹」:
css
[用户指令] → [思考1] → [工具调用1] → [结果1]
→ [思考2] → [工具调用2] → [结果2]
→ [思考3] → [最终输出]这条轨迹包含了大量信息,但也包含了大量噪音(试错、冗余步骤、重复查询等)。
技能萃取做的事情,本质上就是 对执行轨迹的有损压缩:
原始轨迹(数千 Token)→ 结构化技能文档(数百 Token)压缩的原则是:
- 保留:关键决策点、有效的工具调用序列、边界条件;
- 丢弃:失败的尝试、重复的查询、无关的中间输出。
这和人类学习的过程非常相似:你做了一道难题,不会把草稿纸上的每一行都背下来,而是提炼出「解题思路」。
2. 技能匹配的机制:Prompt 内索引 + LLM 自主判断
Hermes 的技能匹配并不是一个独立的向量检索管道,而是一套更轻量的 「渐进式加载」 设计:
第一步:索引注入
系统在 prompt 中注入技能索引(每个技能的标题和触发条件摘要),而不是完整内容。这样既让 Agent 知道「有哪些技能可用」,又不会撑爆 token 预算。
第二步:LLM 自主判断
由 LLM 本身根据当前任务描述和索引信息,判断哪个技能与当前任务相关。这本质上是一种「阅读理解式匹配」------模型在推理过程中自行决定是否需要某个技能。
第三步:按需拉取
当 Agent 判断需要某个技能时,通过 skill_view() 工具拉取完整内容。这样只有真正被使用的技能才会占用上下文窗口。
scss
[当前任务] + [技能索引] → LLM 自主判断相关性
↓
skill_view() 拉取完整内容
↓
注入 Prompt → 按步骤执行这个设计的精妙之处在于:不需要额外的向量数据库或 Embedding 模型,全部利用 LLM 本身的理解能力完成匹配,保持了系统的简洁性和零外部依赖。
3. 记忆检索的分层策略
Hermes 的记忆检索不是简单地「搜索全部历史」,而是与第四章介绍的四层记忆架构对应,采用 分层递进 的检索策略:
markdown
第一层:冻结提示记忆(MEMORY.md + USER.md)→ 直接读取,零延迟
↓ 如果不够
第二层:会话搜索 → FTS5 检索 + LLM 摘要
↓ 如果还不够
第三层:技能库 → 索引匹配,按需加载
↓ 如果还不够
第四层:外部提供商 → 语义画像 + 知识图谱这种分层设计的核心优势是 热/冷分离:大多数请求在前两层就能获得足够的上下文,不需要每次都搜索全量历史。这既节省了 Token(更少的上下文注入),也降低了延迟。
4. 更深层的进化:Atropos RL 训练管道
Hermes 的「越用越强」主要体现在两个层面:
第一层面:技能与记忆的积累(每个用户都会体验到)
这是普通用户日常使用中感知到的「越用越强」------技能库不断扩展,记忆持续优化,同类任务的处理速度和质量逐渐提升。这一切都发生在 prompt 层面,不涉及模型权重更新。
第二层面:模型层面的强化学习(面向模型训练者的可选能力)
Nous Research 在 Hermes 中内置了 Atropos RL 训练管道。Agent 跑任务时产生的工具调用轨迹可以被导出,作为模型微调的训练数据。这意味着:
- 执行轨迹可以用于针对工具调用精度和多步规划的专项微调;
- Nous Research 自家的 Hermes 模型系列就是通过这套管道优化的;
- 用户可以将自己的使用数据导出,训练专属的本地模型。
⚠️ 重要区分: Atropos RL 管道是一个面向模型训练者的可选功能,不是每个用户自动触发的行为。普通用户日常体验到的「越用越强」主要来自第一层面(技能与记忆积累),而非模型权重更新。但这套管道的存在,让 Hermes 成为了少数能「让模型本身也跟着你收敛」的框架之一------记忆在迭代,技能在迭代,连模型本身都可以跟着你的使用习惯收敛。
八、设计启示:如果你要自己造一个「会学习的 Agent」
把 Hermes 的设计拆完之后,可以提炼出几条可复用的设计原则:
原则一:先有反馈通道,再谈学习
没有反馈,就没有学习信号。Hermes 之所以能学习,前提是它有一套隐式反馈采集机制。
如果你要设计自己的学习型 Agent,第一件事不是「怎么做技能萃取」,而是 「怎么知道这次做得好不好」。
原则二:技能要有生命周期
很多人设计知识系统时,只考虑了「怎么存」,没考虑「怎么淘汰」。技能库如果只增不减,最终会变成一个充满过时信息的垃圾场。
Hermes 的做法是:连续 N 次不被匹配到的技能自动降权归档。 这保证了技能库始终是活的。
原则三:记忆要分层,不要全量注入
上下文窗口是稀缺资源。把所有历史都塞进 Prompt,不仅浪费 Token,还会降低模型的注意力精度。
Hermes 的分层记忆设计,本质上就是在 用检索代替注入------只在需要的时候,才把相关记忆拿出来。
原则四:模型层要解耦
不要把学习系统和某个特定模型绑死。技能、记忆、用户画像都应该是 模型无关的,这样当更好的模型出现时,你可以无缝切换。
原则五:从单 Agent 开始,不要一上来就多 Agent
Hermes 的设计选择是「单一 Agent 框架,能力自增长」,而不是 OpenClaw 那样的「多 Agent 联合」。这降低了系统复杂度,也让学习循环更容易收敛。
多 Agent 协作当然有价值,但如果单个 Agent 的能力都没有收敛,加再多 Agent 也只是在分散问题。
九、Hermes 的局限与取舍
任何技术方案都有边界,Hermes 也不例外。
1. 初始学习期的体验不如 OpenClaw
Hermes 的能力增长需要时间积累。前几次使用时,它和普通 Agent 的差别并不大。OpenClaw 由于可以直接安装社区技能,在开箱体验上往往更好。
2. 技能萃取依赖模型质量
如果底层模型的推理能力不够强,萃取出来的技能质量也会打折。用 GPT-4o-mini 去萃取复杂研发技能,效果肯定不如 Claude 3.5 Sonnet。
3. 对重复性任务收益最大
如果你的使用场景是每天都不一样的一次性任务,Hermes 的学习循环几乎无法发挥作用。它最适合的场景是:你有大量相似但不完全相同的重复性任务。
4. 隐私与安全考量
Hermes 会持久化存储你的对话历史、偏好和行为模式。如果你在处理敏感信息,需要额外注意数据存储的安全性和访问控制。
十、结论:Agent 的下一个范式
回顾整篇文章,Hermes Agent 真正的创新不在于它接入了多少平台、支持了多少模型,而在于它提出了一个全新的 Agent 设计范式:
从「无状态的推理管道」到「有状态的学习引擎」。
这个范式转换意味着:
- Agent 不再是「用完即弃的工具」,而是「持续进化的搭档」;
- 用户的每一次使用都不再是孤立的,而是在为 Agent 的成长提供养分;
- 技能不再是开发者预设的,而是 Agent 从实践中自己总结的。
Hermes 这次确实给了 Agent 一个新方向:它让 Agent 从一个用完归零的工具,变成了能从失败里学到东西、能记住教训的一种搭档关系。
这也是为什么它的口号不是「最强大的 Agent」或「最万能的助手」,而是那句简单但野心巨大的:
The agent that grows with you.
写在最后 🧪
这里是言萧凡的 AI 编程实验室 。 我会在这里持续记录和分享 AI 工具、编程实践 ,以及那些值得沉淀下来的高效工作方法。 不只聊概念,也尽量分享能直接上手、能够复用的经验。 希望这间小小的实验室,能陪你一起探索、实践和成长。2026 年,一起进步。
有兴趣的话可以添加我的微信号一起交流,不仅是编程也可以是畅谈人生