从文件系统到关系型数据库的演进史,再看 Markdown 在 AI 时代的下一站
最近一段时间,关于数据库行业是否正在消失的讨论明显变多了。
理由看起来也很充分:
- Agent 可以直接用 Markdown 作为 memory
- 向量数据库正在替代关系数据库
- 越来越多应用不再显式设计 schema
- 很多系统甚至不再"选择数据库"
如果只看这些现象,很容易得出一个结论:
数据库正在退场。
但如果把时间尺度拉长一点,就会发现真正发生变化的并不是数据库的重要性,而是数据抽象层正在迁移。
今天我们面对的,并不是数据库是否还重要的问题,而是是否正在进入一个新的数据抽象层时代------就像当年关系型数据库是在文件系统无法支撑应用复杂度之后诞生的一样。
数据库没有消失,只是范式变了。
一、关系型数据库并不是技术升级,而是一层新的抽象
关系型数据库的出现,并不是一次简单的技术进步,而是一种抽象层的跃迁。
早期计算机系统的数据组织方式非常直接:
- 应用程序管理文件
- 程序定义格式结构
- 程序决定访问路径
这种方式在单程序时代完全有效。但随着系统规模增长,很快暴露出结构性问题:
- 数据无法共享
- 结构变化影响整个系统
- 并发访问不可控
- 复杂查询难以实现
- 数据结构难以演进
关系模型真正解决的问题不是"如何存储数据",而是:
如何让多个程序共享状态。
它第一次实现了数据的逻辑独立性,使应用程序不再依赖底层存储路径,并围绕这一能力建立起统一的数据模型、查询语言、事务机制、一致性保证和索引体系。
数据库从诞生之初,就是一层 shared state abstraction layer。
理解这一点非常重要,因为今天我们面对的问题,与当年文件系统时代其实非常相似。
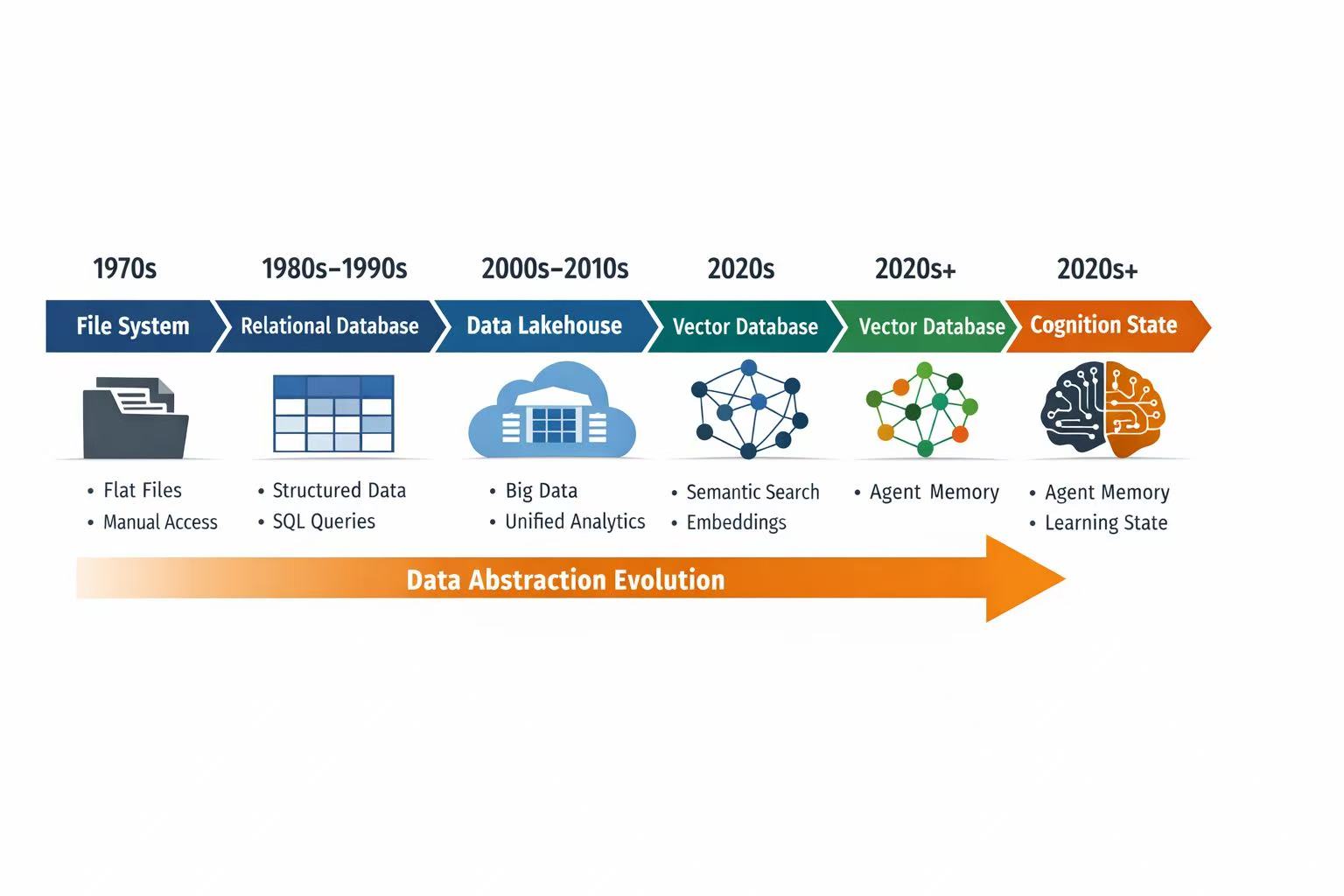
二、Markdown 正在重复文件系统当年的角色
进入 AI 时代之后,越来越多系统开始使用:
- Markdown
- JSON
- 向量索引
- 对象存储
构建 memory layer。
在很多场景中,这确实有效。例如:
- 个人知识库
- 轻量级 Agent memory
- RAG demo 系统
- 单用户上下文管理
这些系统通常具有共同特点:
- 低并发
- 弱一致
- 追加写入
- 查询简单
在这种条件下:
Markdown + embedding index
确实可以运行。
但这并不意味着数据库不再需要。
这意味着系统仍然处于一个典型的 pre-relational 阶段。
今天的 Markdown,很像当年的 flat file。
它解决的是表达问题,而不是状态问题。
它提供:
- 可读性
- 可交换性
- 弱结构表达
- 知识记录
但它没有解决:
- 并发控制
- 事务一致性
- 权限隔离
- 复杂查询
- schema 演进
- 状态恢复
最新的 Agent memory 研究已经开始系统性描述这些限制。例如 ICLR 2025 的 conversational memory 工作指出,长期 memory 的关键问题不再是"存多少上下文",而是如何构造可压缩、可检索、可演化的 memory unit。
这说明 memory 正在从文本缓存走向结构化状态系统。
三、Agent 时代的新约束已经出现,而且正在迅速放大
关系型数据库诞生的原因,是文件系统无法承载应用规模。
今天类似的压力正在重新出现。
但这一次不是来自程序,而是来自 Agent。
如果未来的软件系统需要同时运行数万、数亿甚至数万亿 Agent,那么数据基础设施面对的对象将不再是程序,而是认知体。
数据库将不再管理数据记录,而是管理认知轨迹:
- context
- reasoning
- tool calls
- knowledge
- observations
- tasks
数据库开始管理的是:
state trajectories
而不是:
data rows
与此同时,并发模型也正在发生变化。
传统数据库面对的是多程序并发,而未来数据库面对的是多 Agent 并发。
程序通常是确定性的,而 Agent 通常是非确定性的。
这意味着:
- 状态合并
- 版本控制
- 冲突检测
- 推理路径协调
都会成为数据库级问题。
MemoryAgentBench 已经把 Agent memory 能力拆解为:
- retrieval
- test-time learning
- long-horizon reasoning
- selective forgetting
这些能力本质上对应数据库中的索引、更新、压缩与恢复机制。
与此同时,token 成本正在成为新的访问路径约束。
ICLR 2026 的 MEM1 工作进一步证明:
简单扩展 context window 无法解决长期 memory 问题,系统必须维护一个 compact internal state。
另一类研究(如 ACON)则直接把 context compression 定义为长程 Agent 的核心系统问题。
这说明:
context engineering 正在成为新的 schema 设计
harness engineering 正在成为新的事务系统
新的数据抽象层正在形成。
四、训练正在成为新的数据基础设施问题
另一个正在发生但常被忽视的变化是,训练本身正在从一次性离线过程变成持续的在线过程。
在传统机器学习系统中,模型训练发生在部署之前,而数据库负责管理部署之后的业务状态。
但在 Agent 系统中:
- retrieval
- reflection
- tool feedback
- test-time learning
正在不断改变模型行为本身。
这意味着 memory 不再只是推理阶段的辅助组件,而正在成为训练过程的一部分。
当学习成为持续状态演化过程时,数据库所管理的对象也从业务数据扩展为认知状态,甚至进一步扩展为学习状态。
换句话说:
- 过去数据库管理的是业务状态
- 今天数据库开始管理认知状态
- 未来数据库可能管理学习状态
这是数据库范式迁移正在发生的另一个重要信号。
五、下一代数据库正在指向统一认知状态空间
如果关系型数据库解决的是:
multi-program shared state
那么下一代数据库需要解决的是:
multi-agent shared cognition state
这种状态不是单一类型的数据,而是一个多维状态空间:
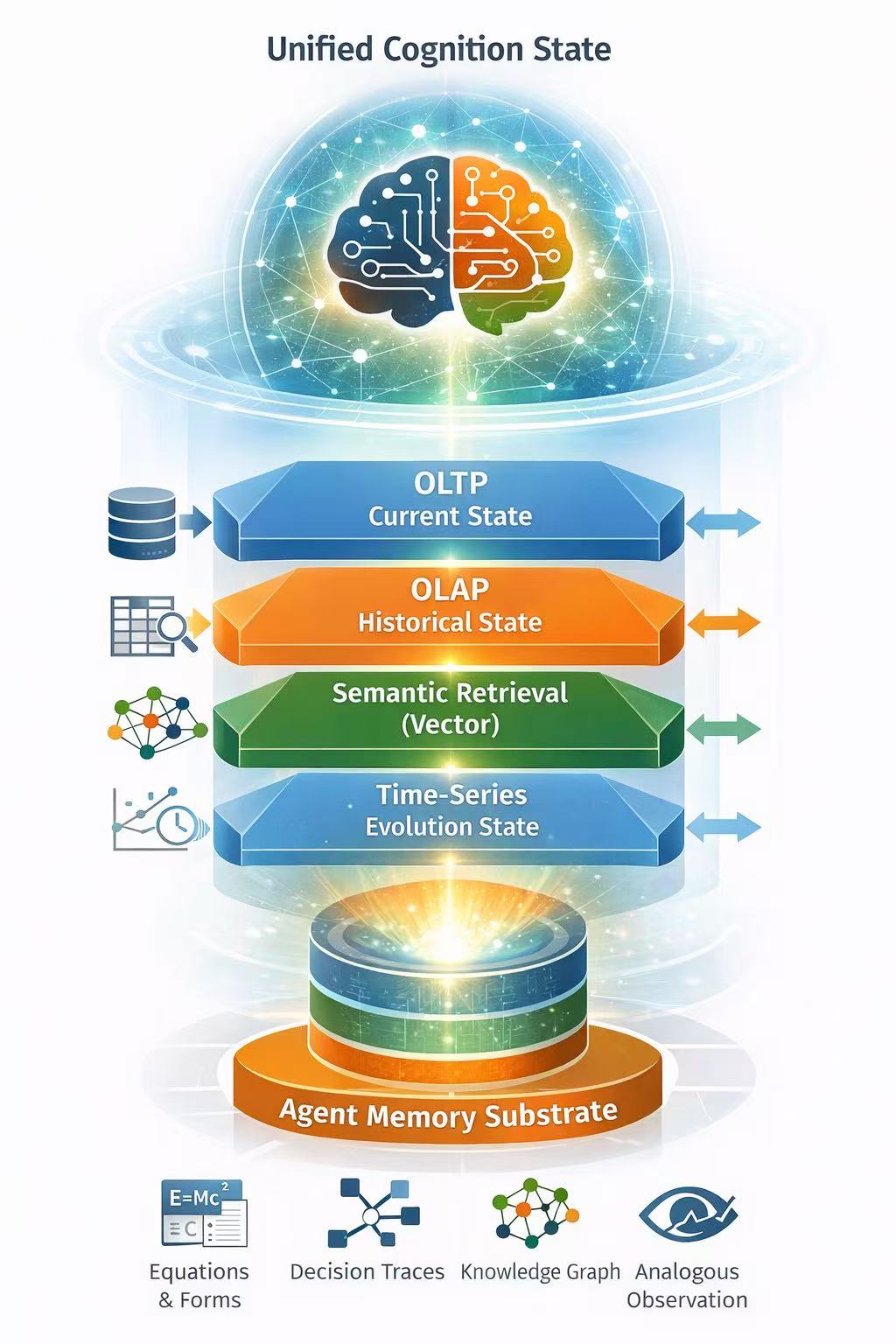
- 当前状态(OLTP)
- 历史状态(OLAP)
- 语义状态(Vector)
- 演化状态(Time-series)
数据库社区其实已经沿着这个方向前进。
PVLDB 2025 的向量数据库研究明确将 vector store 定义为 LLM 系统的 long-term memory substrate;
GraphRAG 研究则开始把 retrieval 扩展为结构化 reasoning path,而不仅仅是语义匹配。
当数据基础设施需要支持数万、数亿甚至数万亿 Agent 时,数据库将第一次成为认知基础设施。
系统必须支持:
- decision trace
- reasoning history
- tool invocation lineage
- state evolution timeline
权限模型也将发生变化:
从
user → table
转变为
- agent → memory region
- agent → tool state
- agent → world model fragment
数据库的角色正在从:
data storage layer
转变为:
cognition state infrastructure layer
Markdown 不会消失,但它不会成为终点。
它更可能成为下一代数据抽象层出现之前的入口格式,并沿着这样的路径演进:
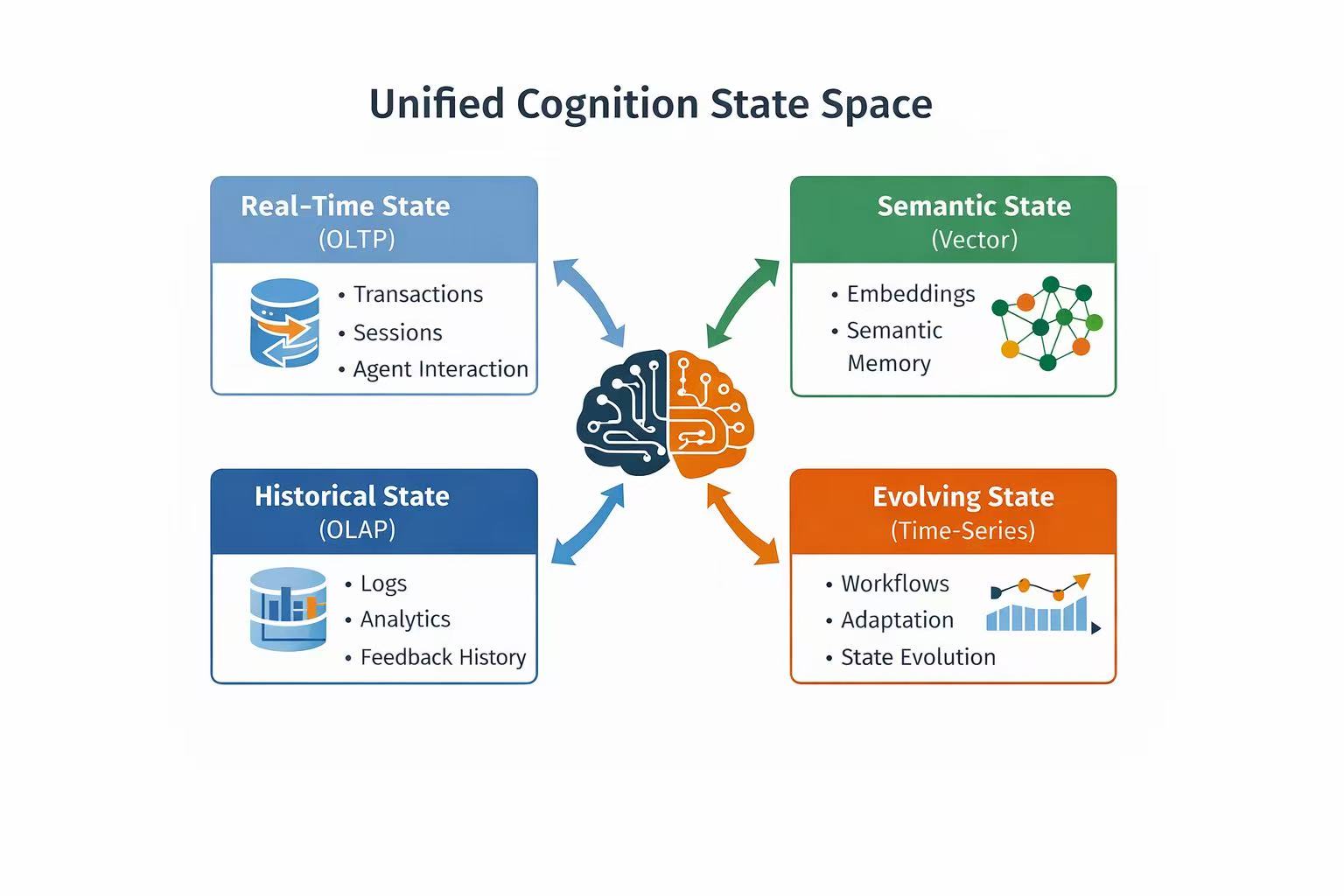
Markdown
→ metadata
→ chunking
→ embedding
→ vector index
→ relational state
→ agent memory substrate
在这个过程中:
Markdown 从 storage format 变成 interface format。
真正的数据层仍然需要新的数据库抽象。
六、数据库没有消失,只是进入了新的位置
文件系统并没有消失,它只是退到了数据库下面。
关系型数据库也不会消失,它可能正在退到 Agent memory 的下面。
Markdown 不是数据库的终点,它只是下一层数据库诞生之前的入口格式。
数据库没有死。
只是范式变了。