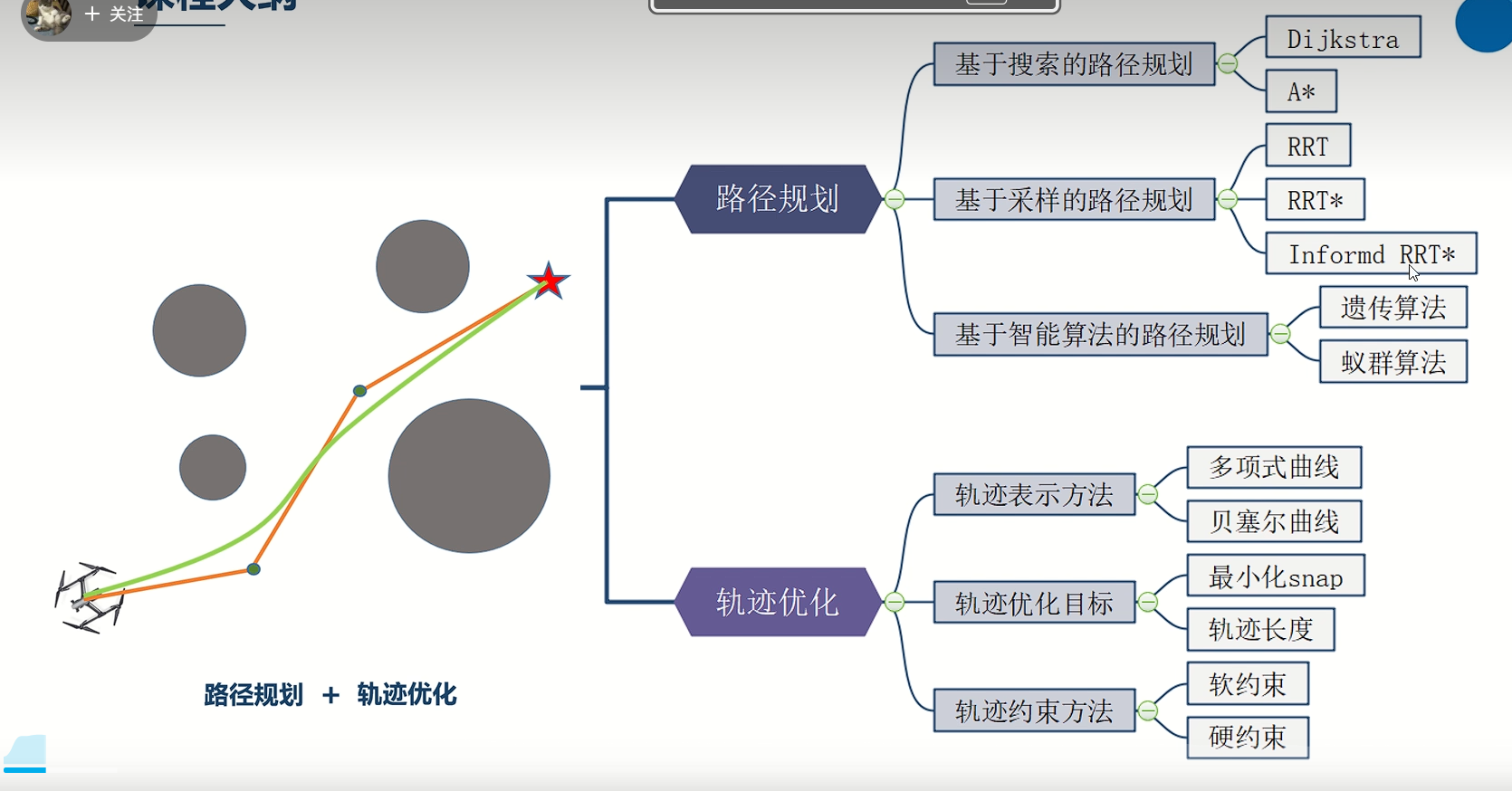
一、RRT
RRT算法我认为讲解比较好的链接
机器人路径规划、轨迹优化课程-第五讲-RRT算法原理和代码讲解_哔哩哔哩_bilibili
可视化过程
初始化树 T,将 q_start 作为根节点 for 迭代次数 from 1 to 最大迭代: # 1. 随机采样(带目标偏置) if rand() < p_goal: q_rand = q_goal # 小概率直接采样目标,加速收敛 else: q_rand = 空间C中均匀随机采样点 # 2. 找树上最近节点 q_near = 树T中距离 q_rand 最近的节点 # 3. 沿 q_near→q_rand 方向走一步,生成新点 q_new = 从 q_near 向 q_rand 移动步长 Δq 得到的点 # 4. 碰撞检测 if 线段 (q_near, q_new) 不与障碍物碰撞: 将 q_new 加入树 T 建立 q_near → q_new 的父子边 # 5. 检查是否到达目标 if distance(q_new, q_goal) < 阈值: 从 q_new 回溯父节点到 q_start,得到路径 返回路径 返回 未找到路径
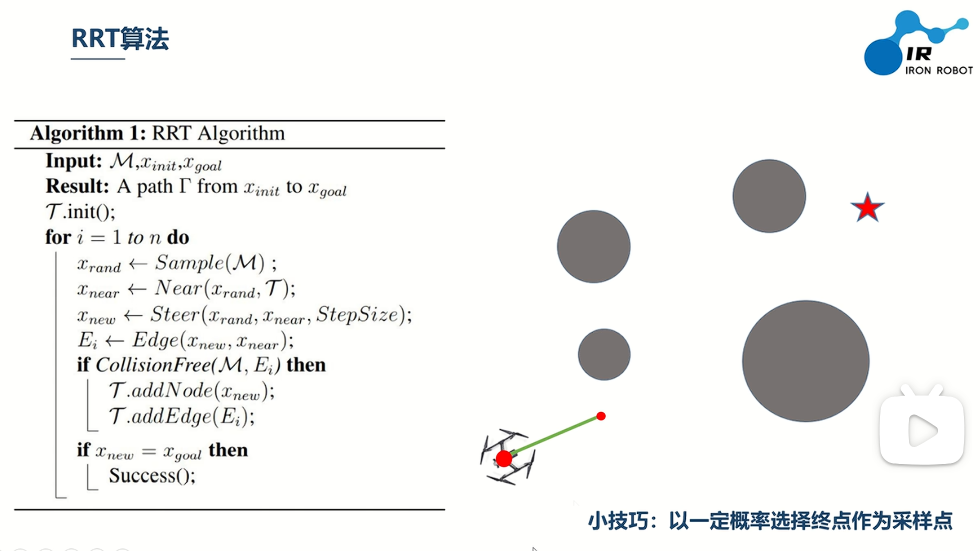
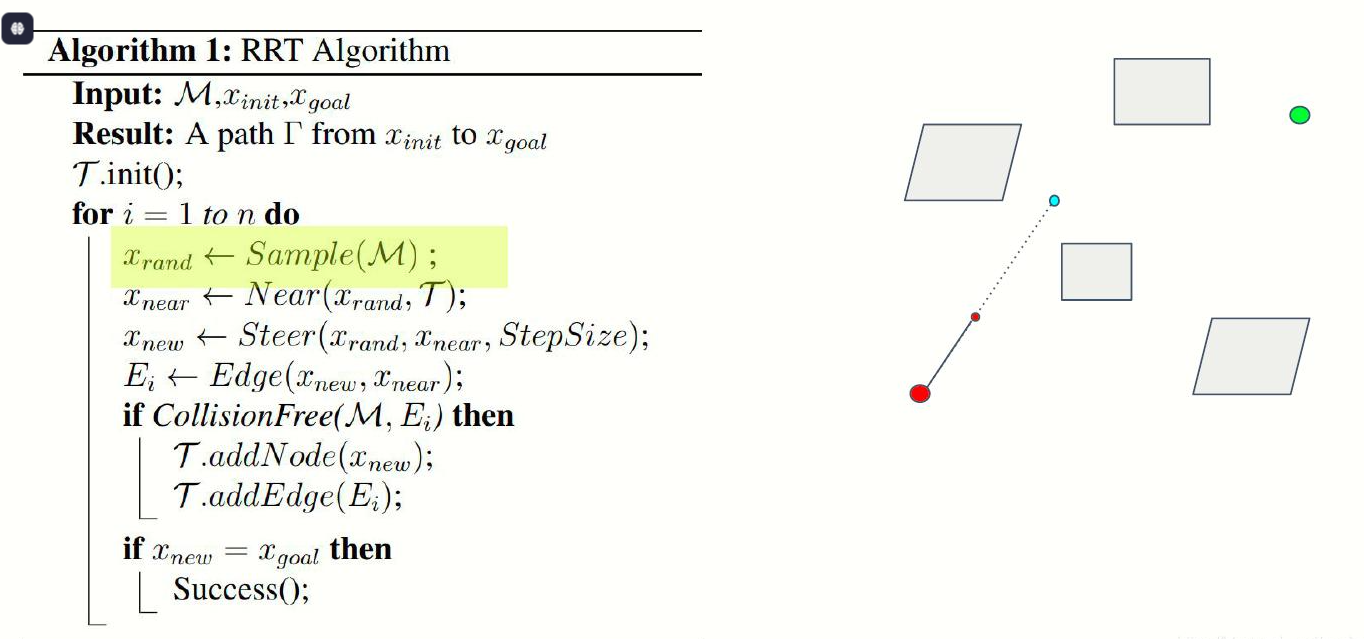
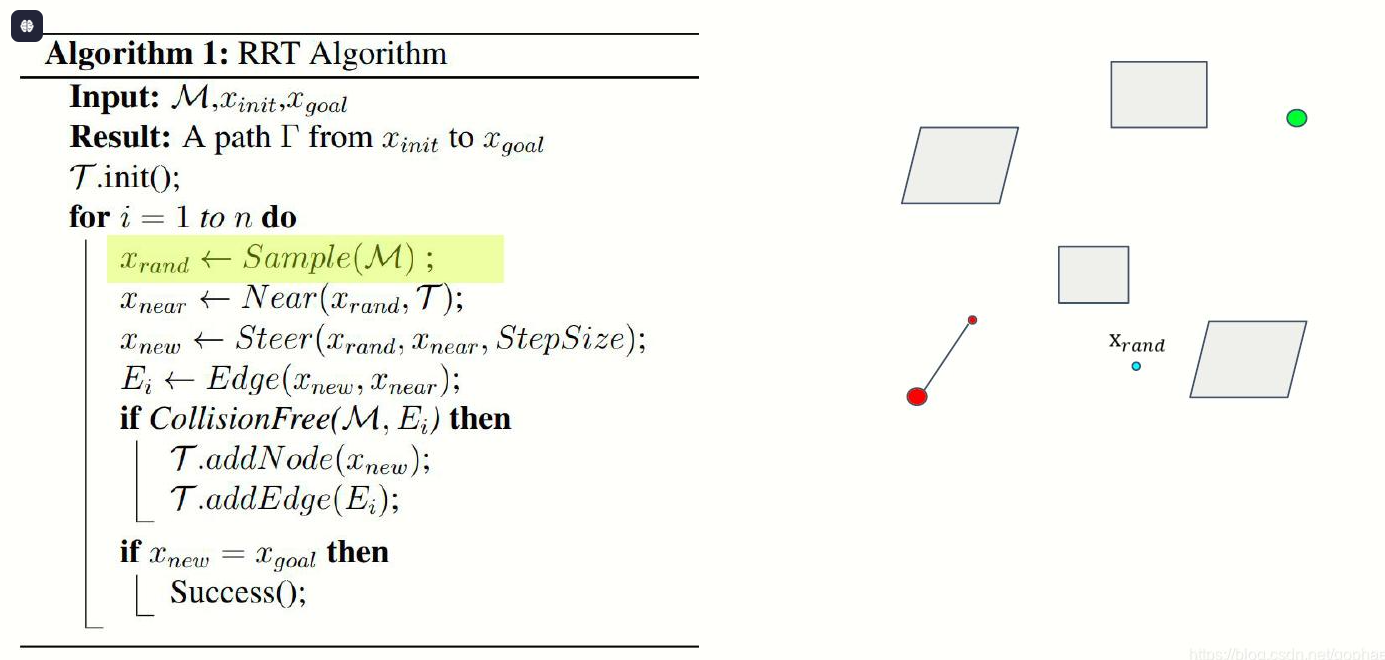
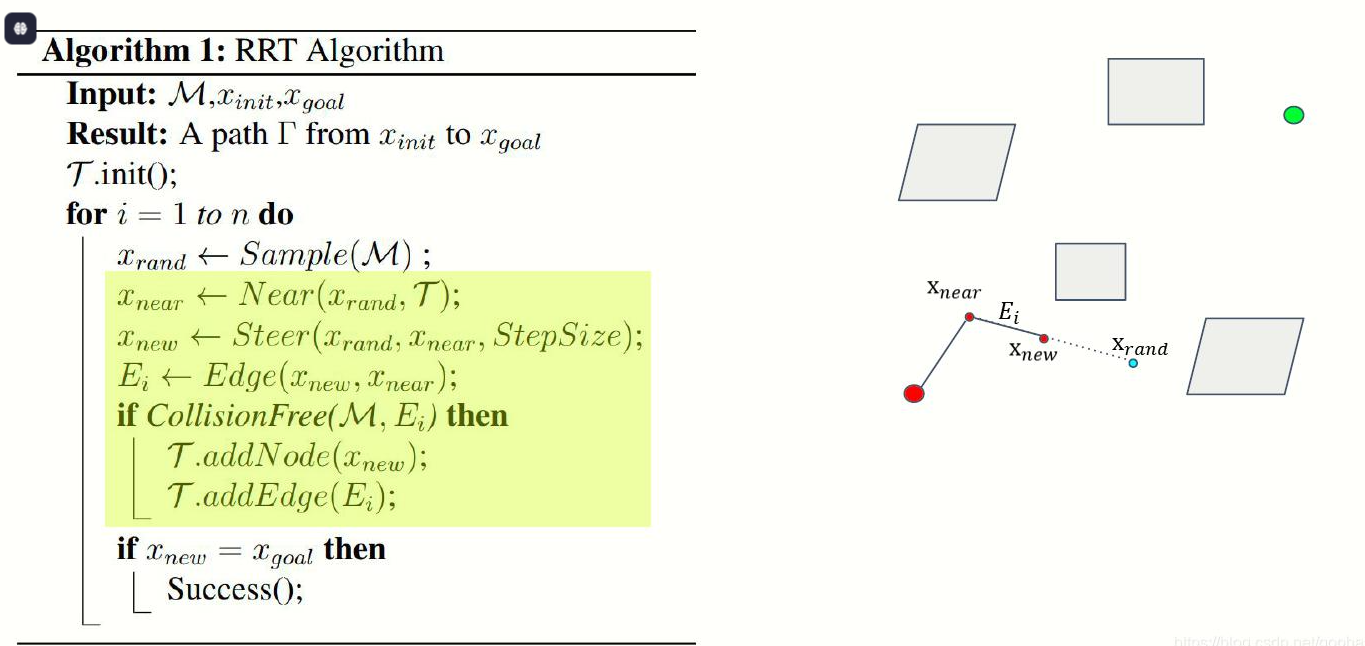
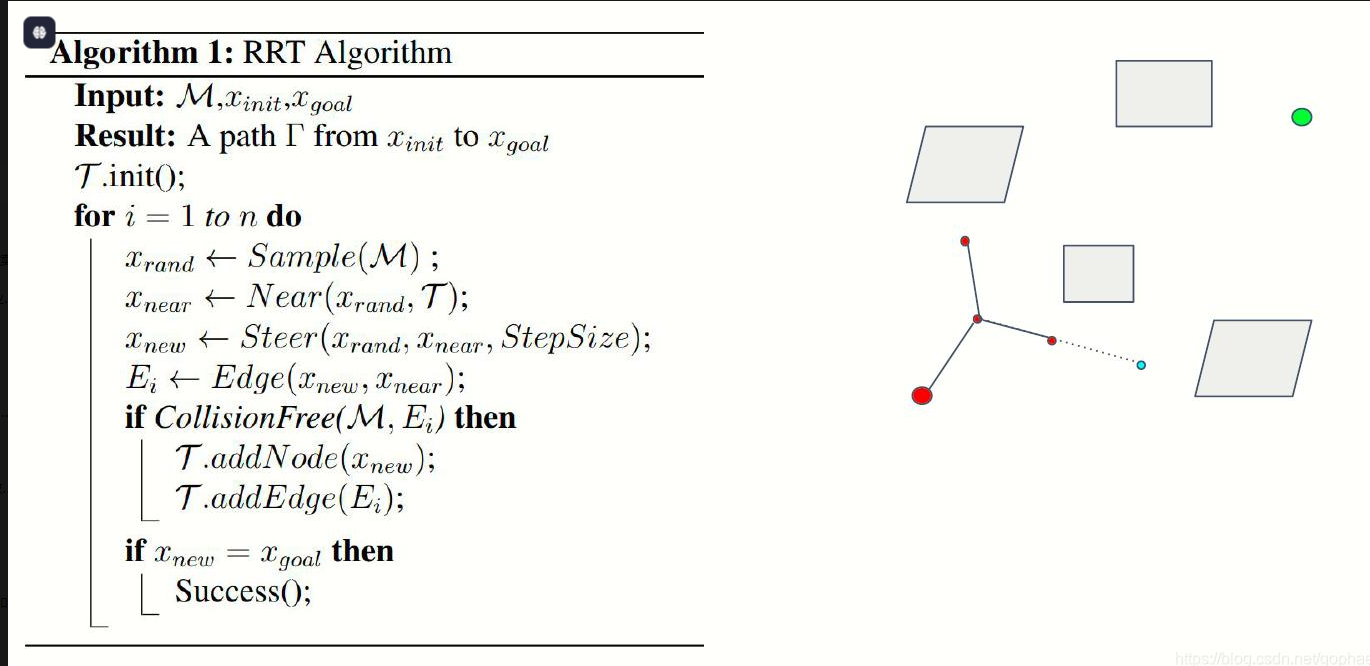
二、RRT*
RRT*(RRT-Star)是 RRT 算法的渐近最优改进版本 ,由 Karaman 和 Frazzoli 在 2011 年提出。它在保留 RRT "随机采样、快速探索" 核心优势的基础上,通过 父节点重选 和 邻域重连 两个关键操作,实现了 路径代价渐近收敛到最优解 的特性,是高维空间路径规划领域的经典算法。
- 父节点重选:新节点来时,不直接连接最近点,而是在附近找一个能让 "到起点路径代价最小" 的点当爸爸。
- 邻域重连:新节点可能让周围老节点的路更短,于是切断老节点和旧爸爸的连接,改认新爸爸。

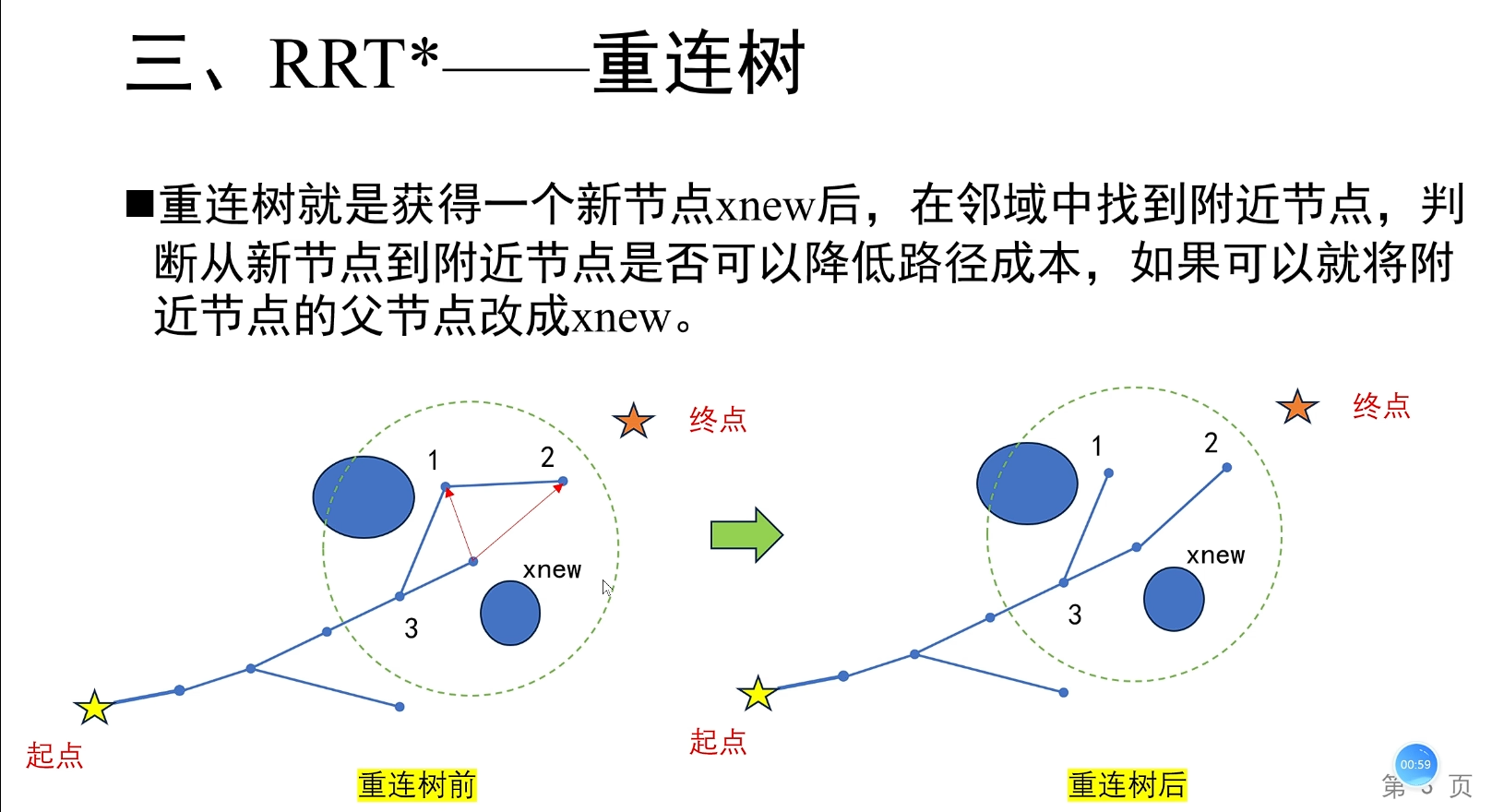
三、Informed RRT*
Informed RRT *(信息引导 RRT*)是 RRT * 的高效加速版本,核心是:找到第一条路径后,只在 "可能更优" 的椭圆区域内采样,彻底砍掉无效探索,收敛速度比标准 RRT* 快几倍到一个量级。
- 刚找到路:椭圆很大,包含大部分空间
- 每找到更短路:椭圆自动缩小
- 最优时:椭圆缩成一条直线(起点→终点)

算法流程如下:
输入参数
- 起点 qstart、目标点 qgoal、状态空间 C(含障碍物)
- 步长 Δq、最大迭代次数 Nmax、目标偏置概率 pgoal
- 邻域半径参数 γ、目标阈值 ϵ(判断节点是否接近目标)
输出
- 起点到目标的渐近最优路径
阶段 1:全局探索(和 RRT* 一致,找第一条可行路径)
这一阶段的目标是 快速找到任意一条可行路径,并记录其代价 cbest(初始最优路径长度)。
- 初始化树
- 构建以 qstart 为根的树 T,初始化 cost(qstart)=0,cbest=∞(初始最优代价设为无穷大)。
- *循环采样扩展(同 RRT )**对每次迭代 k=1,2,...,Nmax:
- 随机采样:以概率 pgoal 采样 qgoal,否则全空间随机采样 qrand。
- 找最近邻:在树 T 中找到离 qrand 最近的节点 qnear。
- 生成新节点:从 qnear 向 qrand 方向移动步长 Δq,得到 qnew。
- 碰撞检测:若线段 qnear→qnew 无碰撞,则继续;否则跳过本次迭代。
- 父节点重选:在 qnew 邻域内,找能让 cost(qnew) 最小的节点 qmin 作为父节点。
- 邻域重连:遍历 qnew 邻域节点,若经过 qnew 的路径代价更低,则更新邻域节点的父节点。
- 检查目标 :若 distance(qnew,qgoal)<ϵ,则将 qgoal 加入树,回溯得到路径,计算其代价 ccurrent。
- 若 ccurrent<cbest,则更新 cbest=ccurrent,进入阶段 2。
阶段 2:椭圆约束精修(核心改进,优化到最优路径)
这一阶段的核心是 只在椭圆内采样,椭圆的范围由当前最优代价 cbest 决定,每次找到更优路径就缩小椭圆,直到收敛。
- 构建约束椭圆
- 椭圆参数计算 (以 2D 空间为例):
- 焦点:qstart 和 qgoal
- 两焦点间直线距离:cmin=distance(qstart,qgoal)(理论最短路径)
- 椭圆半长轴:a=cbest/2
- 椭圆半焦距:f=cmin/2
- 椭圆半短轴:b=(a**2−f**2)**1/2
- 坐标变换:将全局坐标系转换为以两焦点连线为 x 轴的局部坐标系,方便生成椭圆内的随机点。
- 椭圆内采样优化 继续循环迭代,采样范围从 "全空间" 改为 "椭圆内" ,其余操作和 RRT* 一致:
- 椭圆内采样 :不再全空间采样,而是只在椭圆区域内生成随机点 qrand(保证 qrand 满足 ∥qrand−qstart∥+∥qrand−qgoal∥≤cbest)。
- 重复 RRT 扩展操作*:找最近邻 → 生成新节点 → 碰撞检测 → 父节点重选 → 邻域重连。
- 更新最优路径 :若新路径代价 ccurrent<cbest,则更新 cbest=ccurrent,并重新计算椭圆参数(椭圆会自动缩小)。
- 终止条件
- 达到最大迭代次数 Nmax;
- 椭圆半短轴 b 小于设定阈值(椭圆几乎缩成一条直线,路径接近最优)。
阶段 3:路径回溯
从 qgoal 开始,沿着父节点指针回溯到 qstart,得到最终的最优路径。
