
20260414Python制作童话故事音频
背景需求:
这几天用Python制作AI视频的背景旁白,对话等
使用了三个库
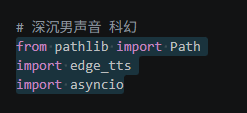
1. pathlib.Path
-
类型:Python 标准库
-
用途:面向对象的文件系统路径操作
-
功能:处理文件路径、目录、文件读写等
2. edge_tts
-
类型 :第三方库(需要安装:
pip install edge-tts) -
用途:文本转语音(Text-to-Speech)
-
功能:使用 Microsoft Edge 的在线语音服务将文本转换为音频
3. asyncio
-
类型:Python 标准库
-
用途:异步 I/O 框架
-
功能:编写并发代码,处理异步操作(如网络请求、文件读写等、用
用Python制作音频又快又好,还可以调试速度。
我就想到日常教学中一个问题:来园活动玩桌面玩具,8:40分左右收玩具坐下后,我们通常播放一个QQ音乐里面的"童话故事",让幼儿安静下来,准备喝牛奶。
 但是搜索童话故事,有三个问题
但是搜索童话故事,有三个问题
1、听不见:有些故事声音太轻,或者伴奏音乐太响,小孩子只听声音,看不到画面,注意力分散了。和同伴交头接耳打闹!
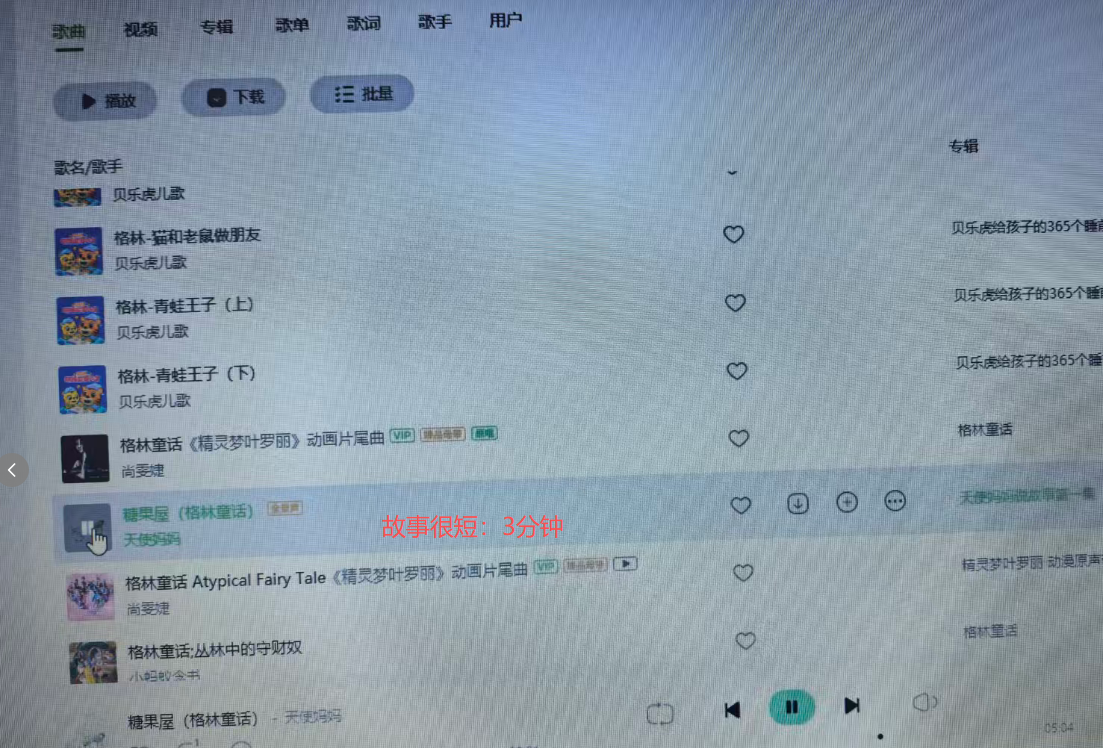
2、时长短、要收费:故事太短了,3分钟以内,会自动播放吓一跳,但有些要收费放不了,就会反复放之前可以播放的故事。
"听过了!换一个"小孩子们嚷着。
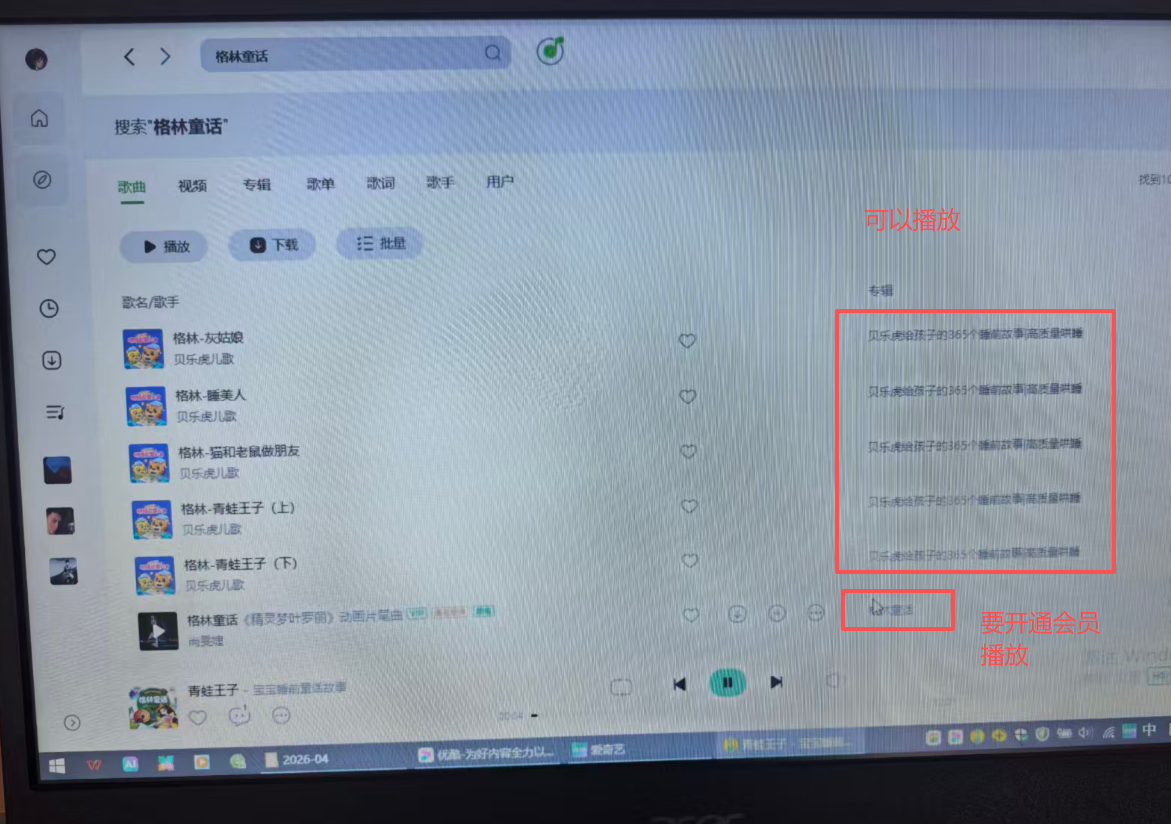
3、关闭繁琐:关闭QQ音乐时,总是习惯性按右上角的×,但声音还在记录发出。必须按里面的暂停按钮,或者关闭右下角的QQ音乐APP按钮才能完全停止声音。鼠标不灵活,点按钮很费劲。
基于以上问题,我想用Python直接生成童话故事mp3,转移到电脑里,让幼儿聆听自制的童话故事音频。
制作过程:
昨天正好听了《青蛙王子》,我先做这个故事的全文

文字太多了,放到一个TXT里
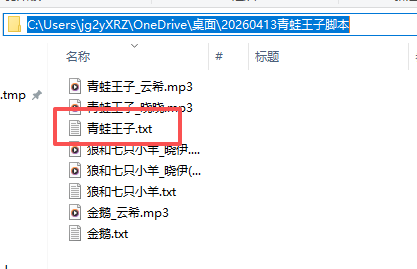

问问如何读取一整个TXT
python
# 男播音 云希 青蛙王子
from pathlib import Path
import edge_tts
import asyncio
# ========== 配置区域 ==========
# 文本文件所在文件夹
TEXT_FOLDER = Path(r"C:\Users\jg2yXRZ\OneDrive\桌面\20260413青蛙王子脚本") # 修改为你的文件夹路径
TEXT_FILE_NAME = "青蛙王子.txt" # 文本文件名
# 音频输出路径
SAVE_DIR = TEXT_FOLDER
SAVE_DIR.mkdir(parents=True, exist_ok=True)
# 播音员音色
VOICE = "zh-CN-YunyangNeural" # 男播音
# 音频参数
RATE = "-20%" # 语速稍慢
PITCH = "+0Hz" # 标准音调
VOLUME = "+10%" # 音量适中
# ============================
async def generate_audio():
# 构建完整的文本文件路径
txt_path = TEXT_FOLDER / TEXT_FILE_NAME
# 检查文件是否存在
if not txt_path.exists():
print(f"❌ 错误:找不到文件 {txt_path}")
return
# 读取文本文件内容(UTF-8编码)
with open(txt_path, "r", encoding="utf-8") as f:
text_content = f.read()
# 去除首尾空白
text_content = text_content.strip()
if not text_content:
print("❌ 错误:文本文件为空")
return
# 生成音频文件名(与txt文件名相同,扩展名改为mp3)
audio_filename = txt_path.stem + ".mp3" # 1.txt → 1.mp3
out = SAVE_DIR / audio_filename
# 生成语音
tts = edge_tts.Communicate(
text_content,
VOICE,
rate=RATE,
pitch=PITCH,
volume=VOLUME
)
await tts.save(str(out))
print(f"✅ 已生成:{audio_filename}")
print(f"📁 来源文件:{txt_path}")
print(f"📊 文本总字数:{len(text_content)} 字")
print(f"💾 保存位置:{out}")
if __name__ == "__main__":
asyncio.run(generate_audio())
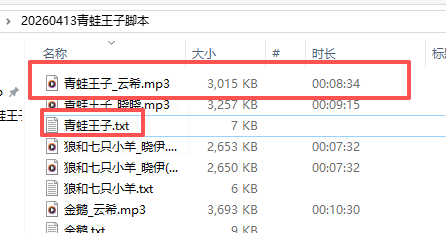
print("\n🎉 音频生成完成!")10秒左右就生成一个8分钟的音频,"男声-云希"的声音比较响亮
继续问问小班孩子喜欢什么样的童话故事


继续做了《金鹅》《狼的七只小羊》
这个故事适合女声
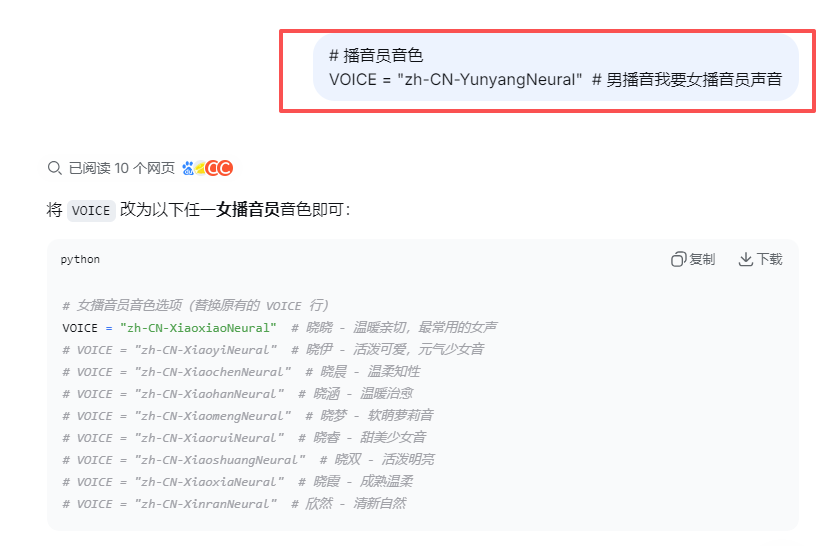
python
# 女播音员,晓晓 晓伊 青蛙王子\狼和七只小羊
from pathlib import Path
import edge_tts
import asyncio
# ========== 配置区域 ==========
# 文本文件所在文件夹
TEXT_FOLDER = Path(r"C:\Users\jg2yXRZ\OneDrive\桌面\20260413青蛙王子脚本") # 修改为你的文件夹路径
# TEXT_FILE_NAME = "青蛙王子.txt" # 文本文件名
TEXT_FILE_NAME = "狼和七只小羊.txt" # 文本文件名
# 音频输出路径
SAVE_DIR = Path(r"C:\Users\jg2yXRZ\OneDrive\桌面\20260413青蛙王子脚本")
TEXT_FILE_NAME1="青蛙王子女.txt"
SAVE_DIR.mkdir(parents=True, exist_ok=True)
# 播音员音色
# VOICE = "zh-CN-XiaoxiaoNeural" # 晓晓 - 温暖亲切,最常用的女声
VOICE = "zh-CN-XiaoyiNeural" # 晓伊 - 活泼可爱,元气少女音
# VOICE = "zh-CN-XiaochenNeural" # 晓晨 - 温柔知性
# VOICE = "zh-CN-XiaohanNeural" # 晓涵 - 温暖治愈
# VOICE = "zh-CN-XiaomengNeural" # 晓梦 - 软萌萝莉音
# VOICE = "zh-CN-XiaoruiNeural" # 晓睿 - 甜美少女音
# VOICE = "zh-CN-XiaoshuangNeural" # 晓双 - 活泼明亮
# VOICE = "zh-CN-XiaoxiaNeural" # 晓霞 - 成熟温柔
# VOICE = "zh-CN-XinranNeural" # 欣然 - 清新自然
# 音频参数
RATE = "-20%" # 语速稍慢
PITCH = "+0Hz" # 标准音调
VOLUME = "+10%" # 音量适中
# ============================
async def generate_audio():
# 构建完整的文本文件路径
txt_path = TEXT_FOLDER / TEXT_FILE_NAME
# 检查文件是否存在
if not txt_path.exists():
print(f"❌ 错误:找不到文件 {txt_path}")
return
# 读取文本文件内容(UTF-8编码)
with open(txt_path, "r", encoding="utf-8") as f:
text_content = f.read()
# 去除首尾空白
text_content = text_content.strip()
if not text_content:
print("❌ 错误:文本文件为空")
return
# 生成音频文件名(与txt文件名相同,扩展名改为mp3)
audio_filename = txt_path.stem + ".mp3" # 1.txt → 1.mp3
out = SAVE_DIR / audio_filename
# 生成语音
tts = edge_tts.Communicate(
text_content,
VOICE,
rate=RATE,
pitch=PITCH,
volume=VOLUME
)
await tts.save(str(out))
print(f"✅ 已生成:{audio_filename}")
print(f"📁 来源文件:{txt_path}")
print(f"📊 文本总字数:{len(text_content)} 字")
print(f"💾 保存位置:{out}")
if __name__ == "__main__":
asyncio.run(generate_audio())
print("\n🎉 音频生成完成!")用男声云希做了《金鹅》,用女声晓晓《公主与青蛙》、女声晓伊《狼和七只小羊》
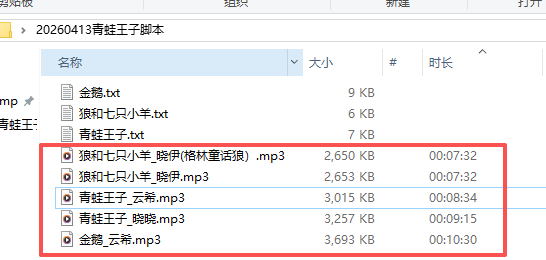
《狼》里面第一次,把"格林童话"和"狼和七只小羊"写在一行,写过音频里面念的是"格林童话狼"+"和七只小羊"

测试多次后无果,用换行,才变成"格林童话"+"狼和七只小羊"

最后把音频放到教室左面上播放
20260414Python制作童话故事音频