一、发展史概览
人工智能的发展并非一蹴而就,而是一场跨越七十余年、由一系列关键突破所驱动的波澜壮阔的史诗。回顾其历程,我们可以清晰地看到三个特征鲜明的阶段,每一阶段都以前一阶段的理论和实践为基础,最终引爆了今天我们所见到的 AI 革命:
-
萌芽期(1950-2005):从最初的理论构想,到符号主义的试错,再到统计学习与早期神经网络的初步探索,我们完成了从人工规则到数据驱动的基础转型。
-
探索沉淀期(2006-2019):深度学习的落地,CV 与 NLP 领域的技术井喷,我们攒齐了大模型所需的所有技术拼图,为爆发期做好了所有准备。
-
迅猛发展期(2020 - 至今):模型规模化、对齐技术、开源生态、推理能力相继爆发,AI 从实验室技术,变成了人人可用的产品,开启了全民 AI 的时代。
二、萌芽期(1950-2005)
这是人工智能的童年时代,我们对机器智能的探索,从最朴素的构想开始,一步步试探着前进。
一切的起点:AI 的诞生
1950 年,阿兰・图灵发表了《计算机器与智能》,提出了著名的图灵测试,第一次提出了 "机器能否思考" 这一终极问题,为人工智能的诞生埋下了思想的种子。
1956 年,约翰・麦卡锡在达特茅斯会议上,首次提出了 "人工智能" 这一术语,标志着人工智能作为一个独立的科学领域,正式诞生。
符号主义的试错
最开始,科学家们认为,智能就是逻辑规则的组合:只要把人类的知识写成一条条 IF-THEN 规则,机器就能像人一样思考。
1966 年,世界上第一个聊天机器人ELIZA 诞生,通过简单的模式匹配,第一次让人类感受到了机器 "聊天" 的可能;1970 年的SHRDLU系统,在限定的积木世界里,实现了简单的人机交互。
同期的中国,也开启了中文 NLP 的早期探索:1980 年代,中科院自动化所依托 863 计划,攻克了中文分词的难题,解决了 "乒乓球拍卖完了" 这类歧义句的拆分问题,分词准确率达到了 92.3%,为中文大模型埋下了第一颗种子。
早期神经网络的探索
在视觉领域,1980 年,日本学者福岛邦彦提出了神经认知机 ,被视为卷积神经网络(CNN)的雏形,它引入了 "感受野" 的概念,模拟了生物视觉的处理方式。1998 年,Yann LeCun 提出了LeNet-5,奠定了现代 CNN 的基本结构,成功应用于手写数字识别。
在语言领域,1990 年代,n-gram 统计语言模型 诞生,第一次让机器摆脱了人工规则的束缚;2003 年,Bengio 团队提出了神经概率语言模型 ,第一次引入了词嵌入的概念,让模型能理解词语的语义;同年,成熟的LSTM 长短期记忆网络,解决了长句子的记忆问题,成为了接下来十几年 NLP 的主流架构。
到 2005 年,我们终于完成了从规则到数据驱动的转型,AI 的萌芽阶段,正式结束。
三、探索沉淀期(2006-2019)
进入 21 世纪,随着大数据和 GPU 计算的出现,神经网络焕发新生,进入了 "深度学习" 时代。这一阶段不仅是 CNN 的复兴,更是全新模型架构的井喷期。
深度学习的起点:AlexNet 的突破
2012 年,在 ImageNet 图像识别大赛上,AlexNet横空出世,它以远超亚军的成绩夺冠,将计算机的识别错误率,从之前的 26%,直接降到了 15%,震惊了整个学术界。
这是深度学习的标志性事件,它第一次证明了,深度神经网络,在复杂的视觉任务上,能远超传统的机器学习方法,正式宣告了深度学习浪潮的到来。
词向量革命:NLP 的深度学习突破
2013 年,Google 的Word2Vec诞生,它通过无监督学习,将单词映射为高维空间中的向量,使得语义相似的词在向量空间中也彼此接近,实现了 "国王 - 男人 + 女人 = 女王" 的神奇语义推理,一下子成为了所有 NLP 任务的标配。
中文领域,哈工大、腾讯相继推出了针对中文优化的词向量工具,覆盖了百万级的中文词汇,为中文 NLP 的发展打下了基础。
中国科学家的高光:何凯明的 ResNet
2015 年,中国科学家何凯明,在 ImageNet 大赛上,提出了ResNet 残差网络,他带领团队,把计算机的识别错误率,再次缩减到了 3%,这一成绩,第一次超越了人类的识别能力,震惊了整个学术界。
这是中国科学家在深度学习领域的第一个世界级突破,ResNet 也成为了之后所有 CV 模型的基础架构,直到今天,依然是计算机视觉领域的核心基石。
大模型的基石:Transformer 的诞生
2017 年,Google 发表了划时代的论文《Attention Is All You Need》,提出了Transformer 架构。它完全摒弃了传统的循环(RNN)和卷积结构,核心是自注意力机制,能够并行处理序列数据,并高效捕捉长距离依赖关系。
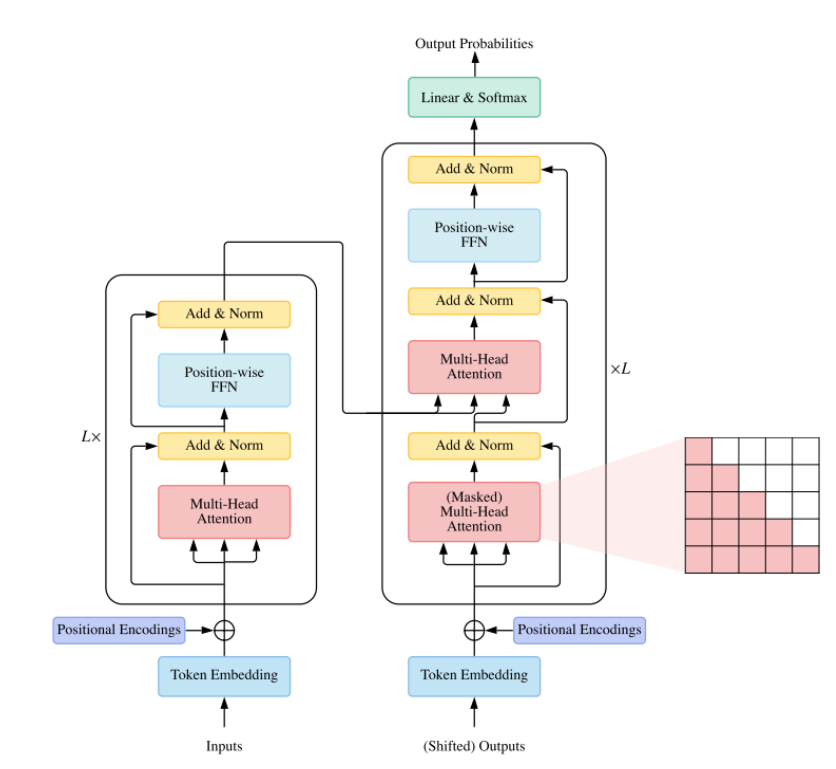
这一架构,彻底颠覆了之前的 RNN、CNN 架构,把训练效率提升了几十倍,为我们训练超大的模型,打下了最重要的基础,直到今天,它依然是所有大模型的核心架构。
预训练范式的双路线
Transformer 诞生之后,预训练的两条路线很快出现:
2018 年,OpenAI 推出了GPT-1 ,展示了通过海量无标注文本进行预训练,再在特定任务上微调的有效性;同年,Google 推出了BERT ,它通过 "掩码语言模型" 更好地理解上下文语义,在 11 项 NLP 任务上刷新了纪录。

2019 年,OpenAI 发布了GPT-2,参数涨到了 15 亿,第一次展示了零样本学习的能力,让所有人看到了生成式模型的潜力。
到 2019 年,所有的技术基础都已经沉淀完成,我们已经准备好,迎接 AI 的爆发了。
四、迅猛发展期(2020 - 至今)
2020 年之后,AI 的发展进入了 "指数级" 的迅猛爆发期。其核心驱动力是:当模型参数、数据量和算力规模突破某个临界点后,会涌现出令人惊叹的新能力。
规模化爆发:参数量的暴力美学
2020 年,OpenAI 推出拥有 1750 亿参数的GPT-3。它展示了强大的上下文学习(In-Context Learning) 和指令遵循(Instruction Following) 能力,几乎无需微调就能完成各式各样的任务。
同期,DeepMind 发现了缩放定律:模型的性能,会随着参数量、数据量、算力的增加,呈幂律增长,只要不断堆资源,模型的能力就会不断提升,这给了整个行业巨大的信心。
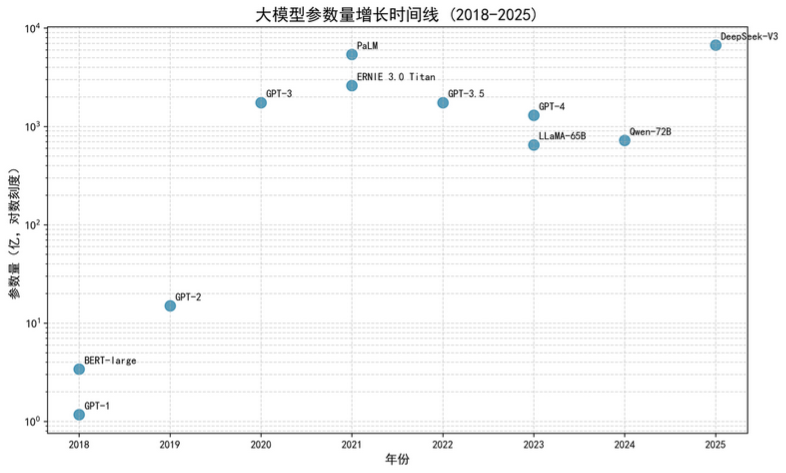
整个行业开始了参数量的竞赛,AI 的能力,迎来了第一次爆发。
全民 AI 的起点:ChatGPT 的 iPhone 时刻
2022 年 11 月,ChatGPT的发布是 AI 发展史上的 "iPhone 时刻"。它通过基于人类反馈的强化学习(RLHF)技术,让大模型能够以非常自然、有用、无害的方式与人类对话,使 AI 技术真正走向大众。

发布仅仅 5 天,ChatGPT 的用户就突破了 100 万,两个月后月活破亿,成为了史上增长最快的消费级应用,第一次让普通用户感受到了大模型的力量,全民 AI 时代正式到来。
开源生态的爆发:LLaMA 与百模大战
2023 年,Meta 的LLaMA彻底点燃了开源生态。原本只对研究人员开放的模型,权重意外泄露,整个开源社区瞬间引爆:斯坦福用 300 美元就把 7B 的模型微调成了接近 GPT-3.5 的 Alpaca,开发者甚至把模型量化后跑在了 MacBook 上。

Meta 很快顺水推舟,发布了完全开源可商用的 LLaMA 2,大模型的门槛被一下子拉到了最低。同期,中国的 "百模大战" 拉开序幕,百度文心、阿里通义、腾讯混元等,都开源了自己的模型,整个中国的 AI 生态彻底活了。
推理能力的突破:从模式匹配到真正的思考
2024 年 9 月,OpenAI 的o1 模型,标志着大模型在复杂推理(尤其是数学和科学计算)上达到了新的高度,它不再是简单的模式匹配,而是能进行 "思考" 和 "演算"。
而真正点燃新一波 AI 浪潮的,是来自中国的深度求索。2024 年 12 月到 2025 年春节期间,深度求索公司的 DeepSeek v3 和 DeepSeek R1 相继发布,再次点燃了全球的 AI 浪潮。
DeepSeek R1 在数学和代码能力上的表现尤为亮眼,它的推理能力,对标甚至超越了闭源的顶级模型,证明了国产大模型,已经在全球第一梯队中占据了重要的位置,中国的 AI 技术,已经从跟跑,走到了领跑。
多模态的狂奔
同期,多模态的突破也接踵而至:CLIP 实现了图文对齐,DALL-E 实现了文生图,2024 年 OpenAI 的Sora,实现了文生视频,能生成长达 1 分钟的高清逼真视频,再次震惊了整个行业。
中国的科学家也很快跟上,ERNIE-ViLG 的文生图、Qwen-VL 的跨模态推理、生数科技的 Vidu 文生视频,我们在多模态领域,也实现了从跟跑到领跑的跨越。
现在的大模型,已经不再是只能处理文本的工具,它能看、能听、能说、能生成图片和视频,真正成为了能理解整个世界的通用模型。
五、本节小结
回顾这七十余年的发展:
-
萌芽期,我们从图灵测试走到了数据驱动,完成了最基础的探索;
-
沉淀期,我们从 AlexNet 走到了 Transformer,攒齐了所有的技术拼图;
-
爆发期,我们从规模化走到了推理能力,把 AI 从实验室带到了每个人的身边。
我们见证了一个个标志性的突破:
1950 年的图灵测试,1956 年的 AI 诞生,2012 年 AlexNet 开启深度学习,2015 年何凯明超越人类,2017 年 Transformer 奠定基石,2022 年 ChatGPT 开启全民 AI,2025 年 DeepSeek 点燃新的浪潮。
我们曾经以为规则就是智能,后来发现数据才是;我们曾经以为 LSTM 就是极限,后来发现 Transformer 能做到更多;我们曾经以为模型大到一定程度就会停滞,后来发现缩放定律告诉我们,还有无限的可能。
这就是人工智能的发展史,一部人类探索机器智能的奋斗史,而这,仅仅是一个开始。这场由算法、数据与算力共同驱动的革命,才刚刚拉开最精彩的序幕。